2023.11.16 hivesql高阶函数之开窗函数
目录
1.开窗函数的定义
2.数据准备
3.开窗函数之排序
需求:用三种排序方法查询学生的语文成绩排名,并降序显示
4.开窗函数分组
需求:按照科目来分类,使用三种排序方式来排序学生的成绩
5.聚合函数与分组配合使用
6.聚合函数同时和分组以及排序关键字配合使用
--需求1:求出每个用户的总pv数,展示所有信息 默认第一行到最后一行
--需求2:求出每个用户截止到当天,累积的总pv数 默认第一行到当前行
做题思路,开窗函数核心:保证输出结果的记录数和输入的数据记录数一致
7.窗口范围控制
1.默认第一行到当前行
2.第一行到当前行,等效于rows between ..不写,默认就是第一行到当前行
3.向前3行到当前行
4.向前3行 向后1行
5.当前行到最后一行,第一行到最后一行
8.其他函数
1.ntile平分:
注意ntile规则:尽量平均分配 ,优先满足最小(编号1)的桶,彼此最多不相差1个。
1.开窗函数的定义
- 窗口:可以理解为操作数据的范围,窗口有大有小,本窗口中操作的数据有多有少。
- 可以简单地解释为类似于聚合函数的计算函数,但是通过GROUP BY子句组合的常规聚合会隐藏正在聚合的各个行,最终输出一行
-而窗口函数聚合后还可以访问当中的各个行,并且可以将这些行中的某些属性添加到结果集中。
开窗函数格式: select ... 开窗函数 over(partition by 分组字段名 order by 排序字段名 asc|desc) ... from 表名;

-- 如果有分组操作,select后的字段要么在聚合函数内,要么在group by 后出现
-- 开窗函数: hive和mysql8都能使用
-- 开窗函数本质在表后新增了一列
-- 聚合开窗函数: max min sum avg count
2.数据准备
数据文件score.txt
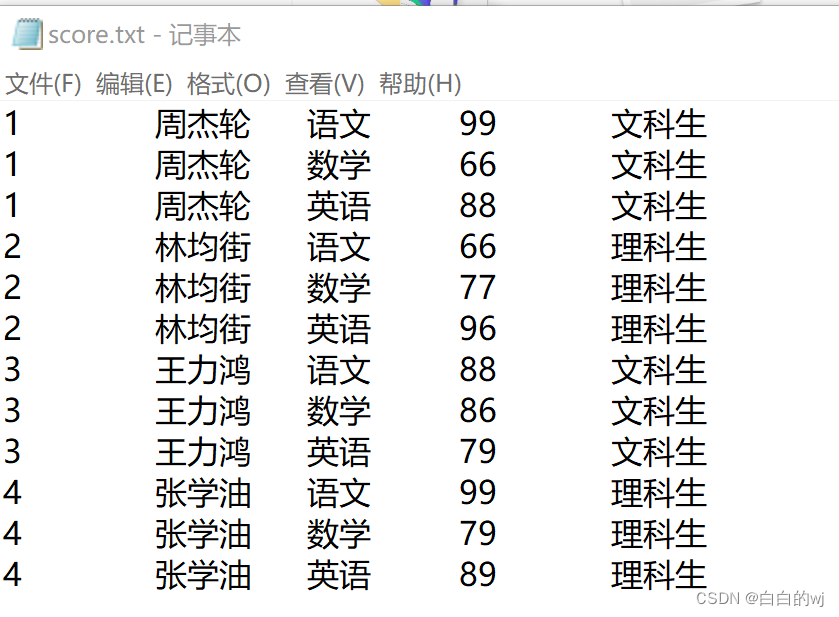
--数据准备
create table students(s_id int,s_name string,subject string,score double,class string
)row format delimited
fields terminated by '\t';--加载数据
load data inpath '/input/score.txt' into table students;--验证数据
select * from students;
3.开窗函数之排序
--查询最高分的学生
select max(score) from students; -- 99
-- 聚合函数配合over()使用,也可以叫开窗函数--查询最高分的学生,并附上他的名字
select s_name,max(score) over() --每一个学生都会匹配一个最高分,数据不正确
from students;
-- 排序开窗函数: row_number rank dense_rank
-- 排序函数必须配合over(order by 排序字段 asc|desc)
row_number: 巧记: 1234 特点: 唯一且连续
dense_rank: 巧记: 1223 特点: 并列且连续
rank : 巧记: 1224 特点: 并列不连续
需求:用三种排序方法查询学生的语文成绩排名,并降序显示
select s_name,subject,score,row_number() over (order by score desc ) ,--唯一且连续dense_rank() over (order by score desc ) ,--并列且连续rank() over (order by score desc ) --并列不连续
from students
where subject = '语文';
4.开窗函数分组
-- 开窗函数分组
-- 注意不能用group by ,需要使用partition by,可以理解成partition by是group by的子句
-- 演示排序函数和分组配合使用: 先分组再组内排序
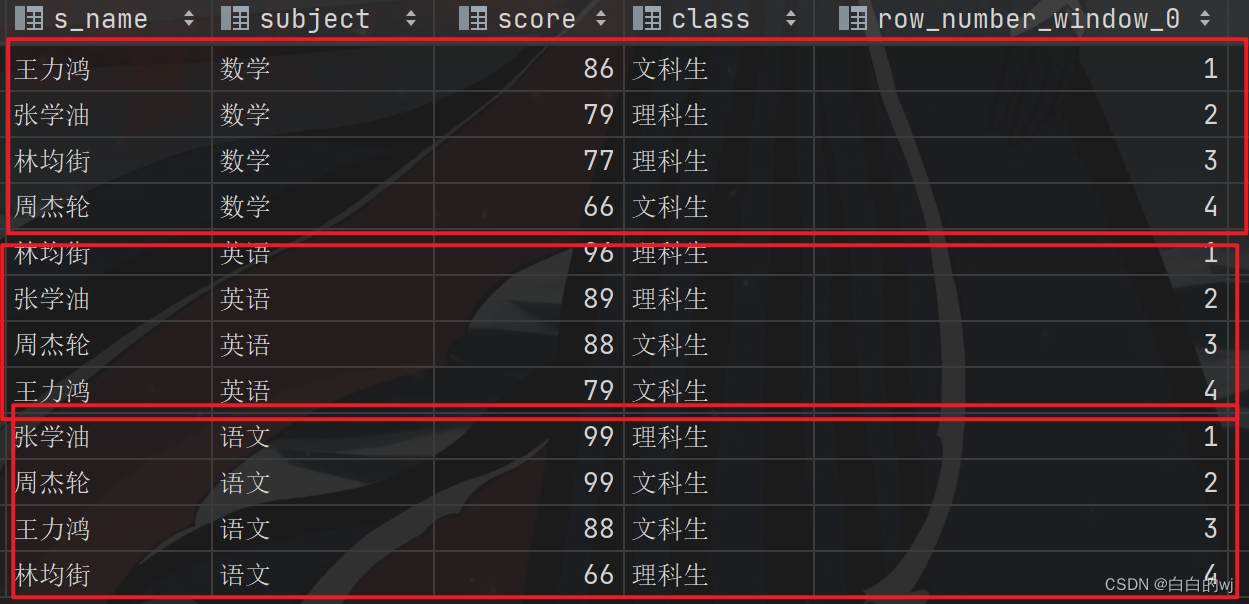
需求:按照科目来分类,使用三种排序方式来排序学生的成绩
select *,row_number() over (partition by subject order by score desc ),dense_rank() over (partition by subject order by score desc ),rank() over (partition by subject order by score desc )
from students;
5.聚合函数与分组配合使用
-- 演示聚合函数和分组配合使用
-- 普通分组
select s_name,max(score)
from students group by s_name;查询每个学生的信息,按照文理科分类,以及平均分
-- 开窗分组
select *,avg(score) over(partition by class)
from students;6.聚合函数同时和分组以及排序关键字配合使用
-- 演示聚合函数同时和分组以及排序关键字配合使用
-- 数据准备
---建表并且加载数据
create table website_pv_info(cookieid string,createtime string, --daypv int
) row format delimited
fields terminated by ',';-- 建表
create table website_url_info (cookieid string,createtime string, --访问时间url string --访问页面
) row format delimited
fields terminated by ',';-- 加载数据
load data inpath '/input/website_pv_info.txt' into table website_pv_info;
load data inpath '/input/website_url_info.txt' into table website_url_info;-- 查询数据
select * from website_pv_info;
select * from website_url_info; 

--需求1:求出每个用户的总pv数,展示所有信息 默认第一行到最后一行
cookie是记住用户记录的一个文件,代表一个用户
select *,sum(pv) over (partition by cookieid)
from website_pv_info; 
--需求2:求出每个用户截止到当天,累积的总pv数 默认第一行到当前行
--sum(...) over( partition by... order by ... ),在每个分组内,连续累积求和
select *,sum(pv) over (partition by cookieid order by createtime)
from website_pv_info;做题思路,开窗函数核心:保证输出结果的记录数和输入的数据记录数一致


7.窗口范围控制
rows between
- preceding:往前
- following:往后
- current row:当前行
- unbounded:起点
- unbounded preceding 表示从前面的起点 第一行
- unbounded following:表示到后面的终点 最后一行
1.默认第一行到当前行
select cookieid,createtime,pv,sum(pv) over(partition by cookieid order by createtime) as pv1
from website_pv_info;
2.第一行到当前行,等效于rows between ..不写,默认就是第一行到当前行
select cookieid,createtime,pv,sum(pv) over(partition by cookieid order by createtimerows between unbounded preceding and current row) as pv2
from website_pv_info;3.向前3行到当前行
--向前3行至当前行
select cookieid,createtime,pv,sum(pv) over(partition by cookieid order by createtimerows between 3 preceding and current row) as pv4
from website_pv_info;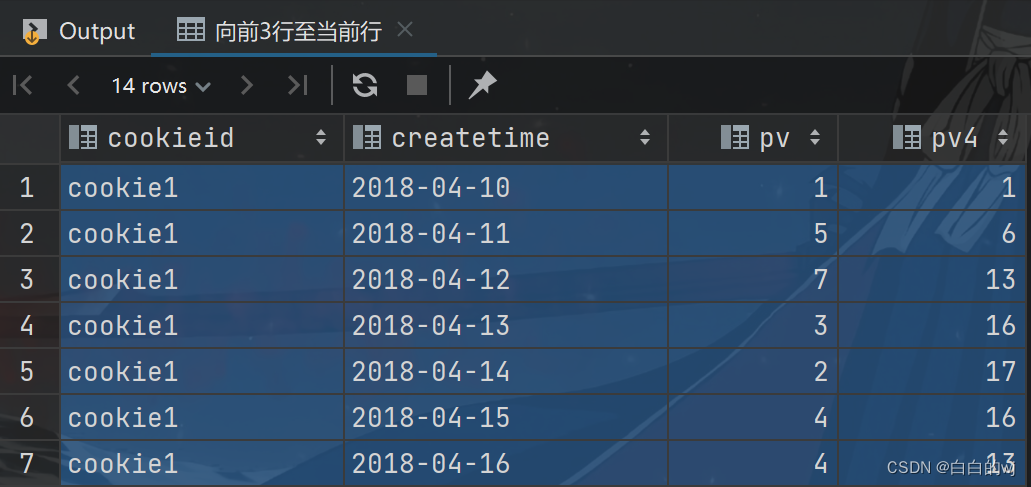
1+5+7=13 , 1+5+7+3=16 , 5+7+3+2=17 , 7+3+2+4=16 , 3+2+4+4=13
相当于查询今天以及前三天的总浏览量,在现实中常称为网站的'最近3天访问量'.
4.向前3行 向后1行
select cookieid,createtime,pv,sum(pv) over(partition by cookieid order by createtimerows between 3 preceding and 1 following) as pv5
from website_pv_info;

1+5+7+3+2=18 , 5+7+3+2+4=21
5.当前行到最后一行,第一行到最后一行
--当前行至最后一行
select cookieid,createtime,pv,sum(pv) over(partition by cookieid order by createtime
rows between current row and unbounded following) as pv6
from website_pv_info;--第一行到最后一行 也就是分组内的所有行
select cookieid,createtime,pv,sum(pv) over(partition by cookieid order by createtime
rows between unbounded preceding and unbounded following) as pv6
from website_pv_info;8.其他函数
1.ntile平分:
注意ntile规则:尽量平均分配 ,优先满足最小(编号1)的桶,彼此最多不相差1个。
其他开窗函数: ntile lag和lead first_value和last_value
ntile(x)功能: 将分组排序之后的数据分成指定的x个部分(x个桶)
注意ntile规则:尽量平均分配 ,优先满足最小(编号1)的桶,彼此最多不相差1个。
lag: 用于统计窗口内往上第n行值
lead:用于统计窗口内往下第n行值
first_value: 取分组内排序后,截止到当前行,第一个值
last_value : 取分组内排序后,截止到当前行,最后一个值
注意: 窗口函数结果都是单独生成一列存储对应数据
-- 演示ntile
--把每个分组内的数据均匀分为3桶
SELECTcookieid,createtime,pv,ntile(3) OVER(PARTITION BY cookieid ORDER BY createtime) AS rn2
FROM website_pv_info
ORDER BY cookieid,createtime;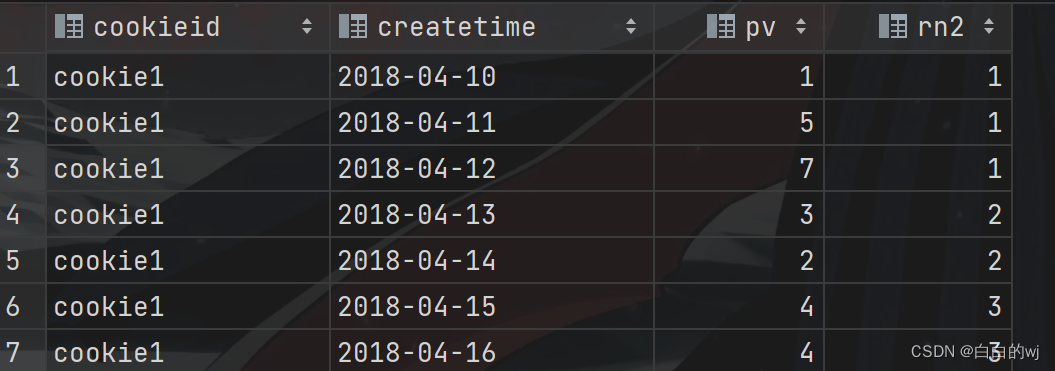
--需求:统计每个用户pv数最多的前3分之1天。
--理解:将数据根据cookieid分 根据pv倒序排序 排序之后分为3个部分 取第一部分
with tmp as (SELECTcookieid,createtime,pv,NTILE(3) OVER(PARTITION BY cookieid ORDER BY pv DESC) AS rnFROM website_pv_info)
SELECT * from tmp where rn =1;
--lag 用于统计窗口内往上第n行值
select cookieid, createtime, url,row_number() over (partition by cookieid order by createtime) rn,lag(createtime, 1) over (partition by cookieid order by createtime) la1,lag(createtime, 2, '2000-01-01 00:00:00') over (partition by cookieid order by createtime) la2
from website_url_info;--lead 用于统计窗口内往下第n行值
select cookieid, createtime, url,row_number() over (partition by cookieid order by createtime) rn,lead(createtime, 1) over (partition by cookieid order by createtime) la1,lead(createtime, 2, '2000-01-01 00:00:00') over (partition by cookieid order by createtime) la2
from website_url_info;--FIRST_VALUE 取分组内排序后,截止到当前行,第一个值
select cookieid, createtime, url,row_number() over (partition by cookieid order by createtime) rn,first_value(url) over (partition by cookieid order by createtime) fv
from website_url_info;--LAST_VALUE 取分组内排序后,截止到当前行,最后一个值
select cookieid, createtime, url,row_number() over (partition by cookieid order by createtime) rn,last_value(url) over (partition by cookieid order by createtime rows between unbounded preceding and unbounded following) fv
from website_url_info;相关文章:
2023.11.16 hivesql高阶函数之开窗函数
目录 1.开窗函数的定义 2.数据准备 3.开窗函数之排序 需求:用三种排序方法查询学生的语文成绩排名,并降序显示 4.开窗函数分组 需求:按照科目来分类,使用三种排序方式来排序学生的成绩 5.聚合函数与分组配合使用 6.聚合函数同时和分组以及排序关键字配合使用 --需求1&…...

QTableWidget常用信号的功能
2023年11月18日,周六上午 itemPressed(QTableWidgetItem *item):当某个项目被按下时发出信号。itemClicked(QTableWidgetItem *item):当某个项目被单击时发出信号。itemDoubleClicked(QTableWidgetItem *item):当某个项目被双击时…...

Vue理解01
项目建立流程 项目文件夹终端vue ui可视化新建项目(需要一些时间)vscode打开项目npm run serve运行 架构理解: 首先打开的页面默认是index.htmlindex.html默认引用main.jsmain.js引用需要的页面,默认App.vue。Vue示例挂载可以在…...
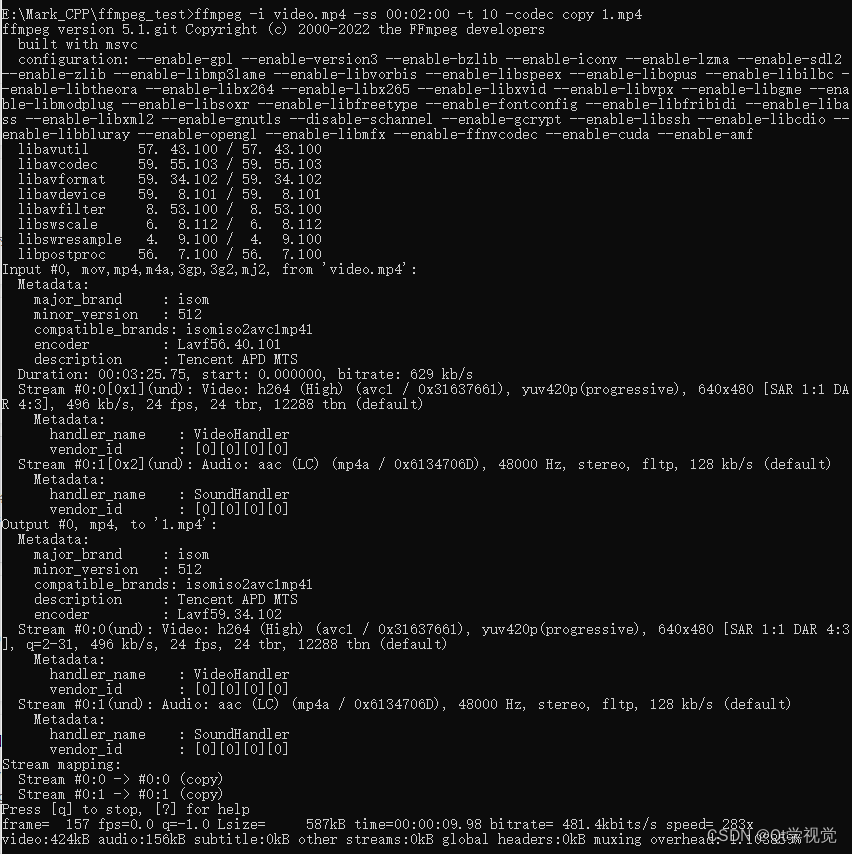
4、FFmpeg命令行操作8
生成测试文件 找三个不同的视频每个视频截取10秒内容 ffmpeg -i 沙海02.mp4 -ss 00:05:00 -t 10 -codec copy 1.mp4 ffmpeg -i 复仇者联盟3.mp4 -ss 00:05:00 -t 10 -codec copy 2.mp4 ffmpeg -i 红海行动.mp4 -ss 00:05:00 -t 10 -codec copy 3.mp4 如果音视…...
【MySQL】索引与事务
作者主页:paper jie_博客 本文作者:大家好,我是paper jie,感谢你阅读本文,欢迎一建三连哦。 本文录入于《MySQL》专栏,本专栏是针对于大学生,编程小白精心打造的。笔者用重金(时间和精力)打造&a…...

切换为root用户后,conda:未找到命令
问题:切换为root用户后,conda:未找到命令 结论详细用户切换配置路径 结论 问题:切换为root用户后,conda:未找到命令 (anaconda) 解决:在~/.bashrc配置里增加conda的路径 详细 用户切换 1 切…...

Qt退出界面
void Dialog::on_pushButton_clicked() {if(ui->lineEdit->text() "admin" && ui->lineEdit_2->text() "123"){accept();//退出} }...

【数据标注】Label Studio用于机器学习标注
原文作者:我辈李想 版权声明:文章原创,转载时请务必加上原文超链接、作者信息和本声明。 文章目录 前言一、使用 Label Studio标注数据1.版本控制 二、Label Studio绑定机器学习后端三、重写机器学习后端四、通过api执行Label Studio动作 前言…...

py字符串转字符串数组
在Python中,你可以使用列表(list)来存储多个字符串。如果你有一个字符串,并且想要将其转换为字符串数组,你可以使用列表推导式(list comprehension)。这是一个简单的例子: # 原始字…...
强化学习各种符号含义解释
:状态 : 动作 : 奖励 : 奖励函数 : 非终结状态 : 全部状态,包括终结状态 : 动作集合 ℛ : 奖励集合 : 转移矩阵 : 离散时间步 : 回合内最终时间步 : 时间t的状态 : 时间t动作 : 时间t的奖励,通常为随机量,且由和决定 : 回报 : n步…...

Axure基础详解二十:中继器随机抽奖效果
效果演示 组件 一、中继器 建立一个“中继器”内部插入一个“正方形”,给“正方形”添加一个【样式效果】>>【选中状态】填充背景为红色,字体白色。在中继器表格中插入两列数据函数:【xuhao】(序号列,按12345……填写&…...

企业信息化与电子商务>供应链信息流
1.供应链信息流概念 供应链信息流是指整个供应链上信息的流动。它是一种虚拟形态,包括了供应链上的供需信息和管理信息,它伴随着物流的运作而不断产生。因此有效的供应链管理作为信息流的管理主要作用在于及时在供应链中传递需求和供给信息,…...
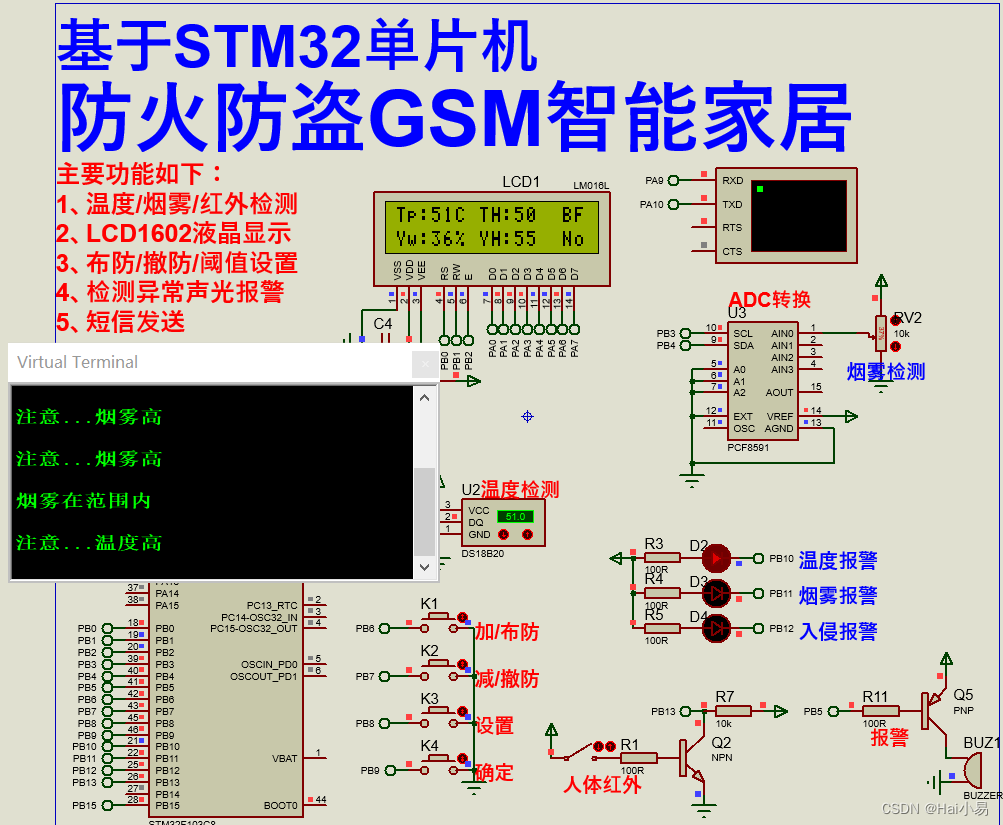
【Proteus仿真】【STM32单片机】防火防盗GSM智能家居设计
文章目录 一、功能简介二、软件设计三、实验现象联系作者 一、功能简介 本项目使用Proteus8仿真STM32单片机控制器,使用声光报警模块、LCD1602显示模块、DS18B20温度、烟雾传感器模块、按键模块、PCF8591 ADC模块、红外检测模块等。 主要功能: 系统运行…...
快速入门ESP32——开发环境配置PlatformIO IDE
相关文章 快速入门ESP32——开发环境配置Arduino IDE 快速入门ESP32——开发环境配置PlatformIO IDE 一、下载安装二、验证 一、下载安装 下载安装 vscode 安装PlatformIO插件 创建工程 二、验证 写一个简单的函数来验证一下功能 void setup() {// put your setup cod…...

Oxygen XML Editor 26版新功能
▲ 搜索“大龙谈智能内容”关注GongZongHao▲ 2023年10月26日,罗马尼亚SyncRO Soft公司发布Oxygen XML Editor、Oxygen Web Author和Oxygen Publish Engine 26版本。 1. Oxygen XML Editor 26新功能简介 AI助手 帮助写作者通过执行重复任务、审查语法、生成结构…...
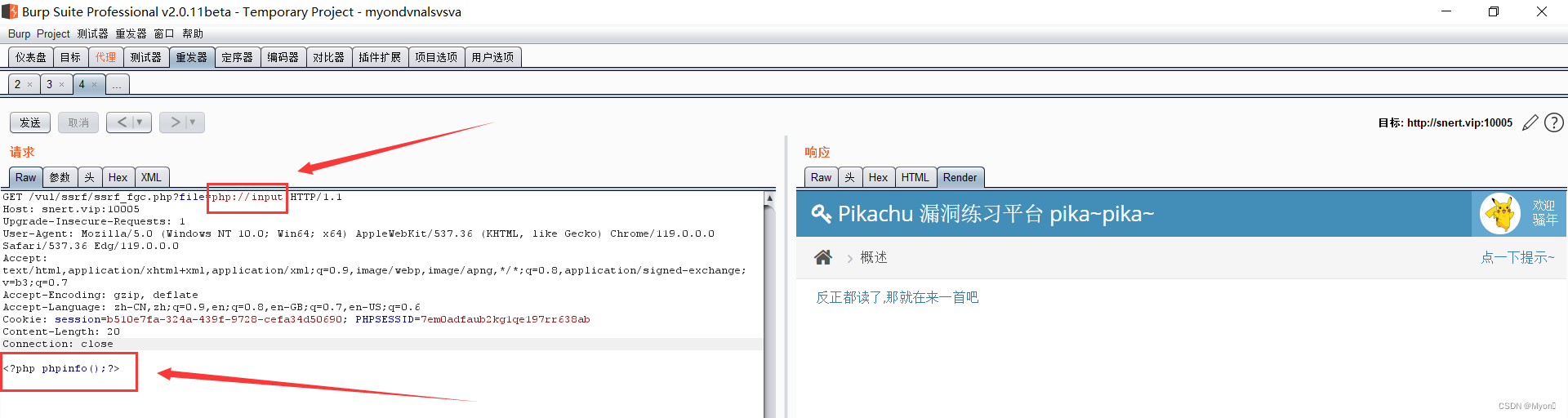
Pikachu漏洞练习平台之SSRF(服务器端请求伪造)
注意区分CSRF和SSRF: CSRF:跨站请求伪造攻击,由客户端发起; SSRF:是服务器端请求伪造,由服务器发起。 SSRF形成的原因大都是由于服务端提供了从其他服务器应用获取数据的功能,但又没有对目标…...

WPF异步编程
在WPF应用程序中进行异步编程是非常重要的,因为这有助于保持用户界面的响应性,特别是当执行长时间运行的操作时,例如访问网络资源、进行大量的数据处理或调用耗时的I/O操作。 WPF的异步编程通常围绕以下几个关键概念: Dispatcher…...

同态加密定义,四大发展阶段总结,FHE系统正式定义-全同态加密
目录 同态加密定义 为什么采用电路模型? 四大发展阶段 总结 FHE系统正式定义...

网上的搜索
Internet中蕴含的信息资源非常丰富,但如何在这浩瀚如海的信息空间内快速找到自己所需要的资源呢?我们需要借助于搜索引擎。在网络上,提供搜索功能的网站非常多,如百度、谷歌、搜狗等,另外有一些门户网站也提供了搜索功能…...

【算法-哈希表2】快乐数 和 两数之和
今天,带来哈希表相关算法的讲解。文中不足错漏之处望请斧正! 理论基础点这里 1. 快乐数 分析题意 出题者已经把题意明确告诉我们了: 对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。然后重复这个过程直到这个数变为 1&am…...
)
Win10下CUDA 11.7和PyTorch保姆级安装避坑指南(含Anaconda换源与驱动检查)
Win10深度学习环境配置全攻略:从CUDA到PyTorch的零失败实践 刚接触深度学习的新手往往在第一步——环境配置上就遭遇重重阻碍。驱动版本混乱、下载速度缓慢、环境变量缺失、版本兼容性问题……这些看似简单的步骤背后隐藏着无数可能让初学者崩溃的"坑"。本…...

3大核心优势:为什么GanttProject能让你秒懂项目管理
3大核心优势:为什么GanttProject能让你秒懂项目管理 【免费下载链接】ganttproject Official GanttProject repository. 项目地址: https://gitcode.com/gh_mirrors/ga/ganttproject 你是否曾经面对复杂的项目计划感到无从下手?GanttProject这款免…...

ARM Cortex-M3内存映射与外设配置详解
1. ARM Cortex-M3 SMM系统架构解析在嵌入式系统开发中,系统内存映射(System Memory Map, SMM)是连接处理器内核与各类外设的关键桥梁。ARM Cortex-M3处理器通过精心设计的SMM架构,为开发者提供了灵活而高效的硬件资源配置方案。V2M-MPS2开发板作为ARM官方…...

工业 DC-DC 性能深度对比解析|钡特电源 DF1-05D15LS 与 E0515S-1WR3 封装互通
在工业控制、仪器仪表、低功耗传感设备等场景中,1W 级隔离工业 DC-DC 模块因体积小、功率密度高、适配性强,成为硬件研发工程师常用的直流电源模块核心器件。随着国产化进程加速,国产工业 DC-DC 模块在性能、稳定性、性价比上逐步实现突破&am…...

AGIAgent框架实践:从LLM到可编程智能体的工程化之路
1. 项目概述:从AGI到AGIAgent的实践跨越最近在GitHub上看到一个挺有意思的项目,叫agi-hub/AGIAgent。光看名字,可能很多朋友会立刻联想到“通用人工智能”或者“AI智能体”,觉得这又是一个宏大叙事下的概念性项目。但实际深入探究…...

如何快速掌握DevPod:开源远程开发环境的完整指南
如何快速掌握DevPod:开源远程开发环境的完整指南 【免费下载链接】devpod Codespaces but open-source, client-only and unopinionated: Works with any IDE and lets you use any cloud, kubernetes or just localhost docker. 项目地址: https://gitcode.com/g…...

NoFences:完全免费的Windows桌面分区工具终极指南
NoFences:完全免费的Windows桌面分区工具终极指南 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 还在为杂乱的Windows桌面而烦恼吗?每天在散落各处的…...

微服务设计终极指南:从单体到分布式的服务拆分原则与实践
微服务设计终极指南:从单体到分布式的服务拆分原则与实践 【免费下载链接】CodeGuide :books: 本代码库是作者小傅哥多年从事一线互联网 Java 开发的学习历程技术汇总,旨在为大家提供一个清晰详细的学习教程,侧重点更倾向编写Java核心内容。如…...

2026年青岛GEO优化服务商TOP5,哪家性价比最高?
行业痛点分析青岛地区GEO(生成式引擎优化)领域面临显著的技术挑战。据行业调研显示,超65%的本地企业存在“错配展现”问题,非目标区域消耗了20%以上的营销预算,导致获客成本平均上升30%。同时,AI大模型&…...

博客生成器架构设计:基于LLM与模块化流水线的自动化内容创作实践
1. 项目概述:一个博客生成器的诞生与价值在内容创作领域,效率和质量是永恒的矛盾。作为一名写了十几年博客的“老鸟”,我深知从灵光一闪到一篇结构清晰、排版美观的文章发布,中间有多少琐碎的步骤:构思大纲、撰写内容、…...