强化学习各种符号含义解释
:状态
: 动作
: 奖励
: 奖励函数
: 非终结状态
: 全部状态,包括终结状态
: 动作集合
ℛ : 奖励集合
: 转移矩阵
: 离散时间步
: 回合内最终时间步
: 时间t的状态
: 时间t动作
: 时间t的奖励,通常为随机量,且由
和
决定
: 回报
: n步回报
:
折扣回报
: 策略
: 根据确定性策略
, 状态s时所采取的动作
: 根据随机性策略
, 在状态s时执行动作a的概率
: 根据状态s和动作a,使得状态转移成
且获得奖励r的概率
: 根据转态s和动作a,使得状态转移成
的概率
: 根据策略
,状态s的价值(回报期望)
: 根据最优策略,状态s的价值
: 动作价值函数,根据策略
,在状态s时执行动作a的价值
: 根据最优策略,在状态s时执行动作a的价值
: 状态价值函数的估计
: 动作价值函数的估计
:
状态,动作,奖励的轨迹
:
, 奖励折扣因子
: 根据
-贪婪策略,执行随机动作的概率
: 步长
: 资格迹的衰减速率
是轨迹
的
-折扣化回报,
是轨迹的概率:
,对于
是起始状态分布
,
是起始状态分布
是策略
的期望回报,
: 对于这个公式的理解为策略
可以产生很多轨迹
,产生每个轨迹的概率为
,而每个轨迹
的奖励为
,所以总的策略
可以获得的奖励的期望就是所有轨迹的概率乘与该轨迹的奖励的积分。对于右边期望描述的就是对于服从策略
的轨迹
,求轨迹的奖励值
的期望。
是最优策略,最优策略就是能够获得最大的策略期望的策略,即为
是状态s在策略
下的价值,也就是这个状态能够获得的期望回报。
是状态s在最优策略
下的价值,也就是这个状态能够在最优策略下获得的期望回报,最终都转化为了奖励的计算。
是状态s在策略
下执行动作a的价值(期望回报)
是状态s在最优策略下执行动作a的价值(期望回报)
是对MRP(Markov Reward Process)中从状态s开始的状态价值的估计
是对MDP(Markov Decision Process)中在线状态价值函数的估计,给定策略
,有期望回报:
其中MP,MRP,MDP参考:MP、MRP、MDP(第二节) - 知乎 (zhihu.com)
是对MDP下在线动作价值函数的估计,给定策略
,有期望回报:
是对MDP下最优动作价值函数的估计,根据最优策略,有期望回报:
是对MDP下最优动作价值函数的估计,根据最优策略,有期望回报:
是对状态s和动作a的优势估计函数:
在线状态价值函数和在线动作价值函数
的关系:
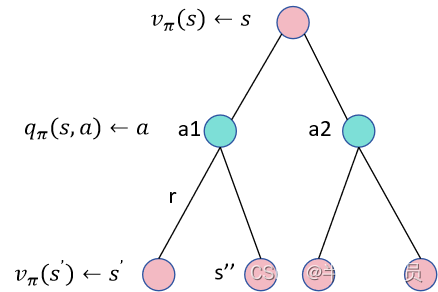
如上图所示:状态s对应多个动作a1,a2,执行一个动作之后,又可能转移到多个状态中去, 所以的值就是在状态s之下能够采取的所有动作的动作价值函数的期望,即为
另一种写法:
这里写的是和
之间的关系,同理另外一种转换关系是,执行一个动作之后得到的及时奖励值+下一个状态的状态价值函数的折扣,即为
,
是在状态s执行动作a转移到s'的概率,这样就把
和
关联起来了。另一种写法如下:
最优状态价值函数和最优动作价值函数
的关系是:
上面的公式很好理解,在最优策略下,给一个状态s,这个策略肯定能够选到最好的动作去执行,那么当前状态的价值函数就不是去求所有动作价值函数的期望了,而是就等于动作价值函数最大的那个值。
是在最优策略下,状态s执行的最优动作
在线动作价值函数的贝尔曼方程:
另外一种写法是:
上面是 和
的关系,下面是
和
的关系:
另外一种写法是:
最优状态价值函数的贝尔曼方程:
另外一种写法是:
最优动作价值函数的贝尔曼方程:
另外一种写法是:
相关文章:
强化学习各种符号含义解释
:状态 : 动作 : 奖励 : 奖励函数 : 非终结状态 : 全部状态,包括终结状态 : 动作集合 ℛ : 奖励集合 : 转移矩阵 : 离散时间步 : 回合内最终时间步 : 时间t的状态 : 时间t动作 : 时间t的奖励,通常为随机量,且由和决定 : 回报 : n步…...

Axure基础详解二十:中继器随机抽奖效果
效果演示 组件 一、中继器 建立一个“中继器”内部插入一个“正方形”,给“正方形”添加一个【样式效果】>>【选中状态】填充背景为红色,字体白色。在中继器表格中插入两列数据函数:【xuhao】(序号列,按12345……填写&…...

企业信息化与电子商务>供应链信息流
1.供应链信息流概念 供应链信息流是指整个供应链上信息的流动。它是一种虚拟形态,包括了供应链上的供需信息和管理信息,它伴随着物流的运作而不断产生。因此有效的供应链管理作为信息流的管理主要作用在于及时在供应链中传递需求和供给信息,…...
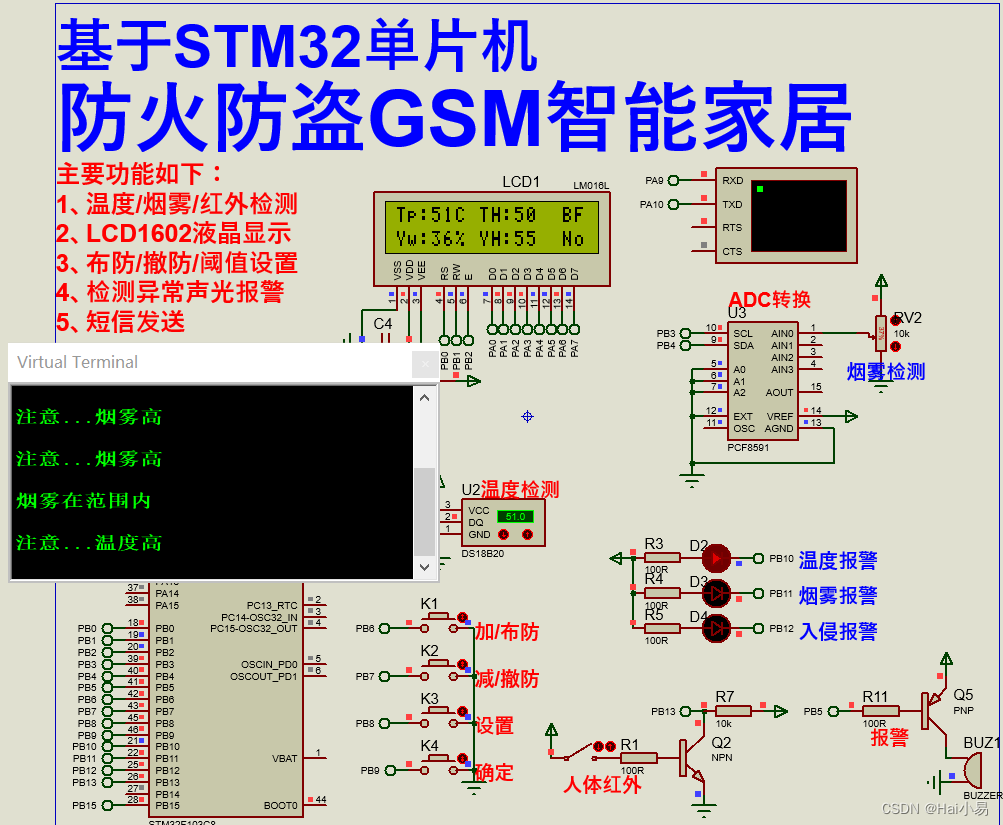
【Proteus仿真】【STM32单片机】防火防盗GSM智能家居设计
文章目录 一、功能简介二、软件设计三、实验现象联系作者 一、功能简介 本项目使用Proteus8仿真STM32单片机控制器,使用声光报警模块、LCD1602显示模块、DS18B20温度、烟雾传感器模块、按键模块、PCF8591 ADC模块、红外检测模块等。 主要功能: 系统运行…...
快速入门ESP32——开发环境配置PlatformIO IDE
相关文章 快速入门ESP32——开发环境配置Arduino IDE 快速入门ESP32——开发环境配置PlatformIO IDE 一、下载安装二、验证 一、下载安装 下载安装 vscode 安装PlatformIO插件 创建工程 二、验证 写一个简单的函数来验证一下功能 void setup() {// put your setup cod…...

Oxygen XML Editor 26版新功能
▲ 搜索“大龙谈智能内容”关注GongZongHao▲ 2023年10月26日,罗马尼亚SyncRO Soft公司发布Oxygen XML Editor、Oxygen Web Author和Oxygen Publish Engine 26版本。 1. Oxygen XML Editor 26新功能简介 AI助手 帮助写作者通过执行重复任务、审查语法、生成结构…...
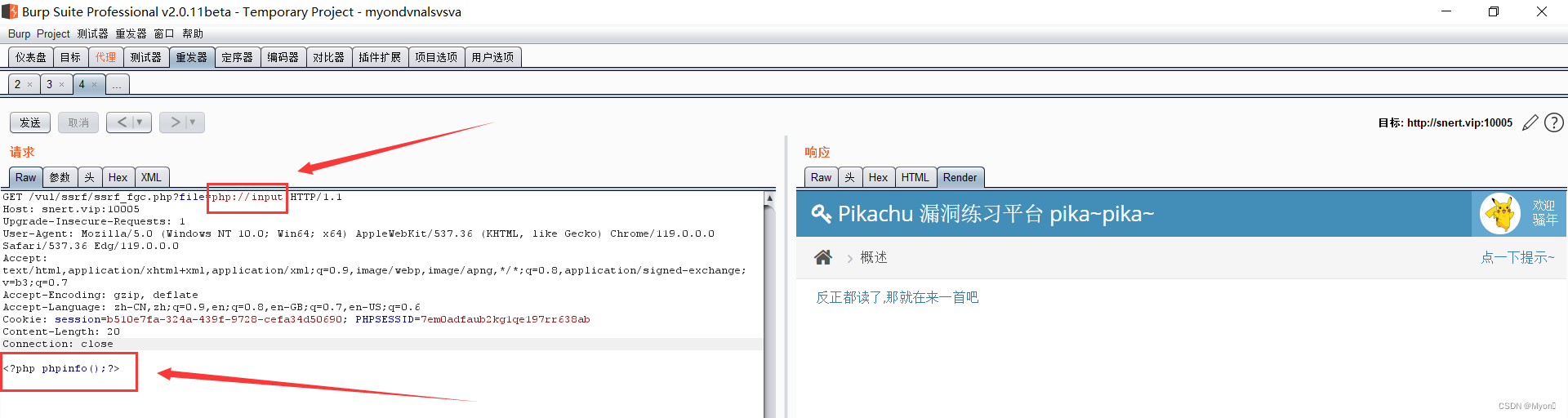
Pikachu漏洞练习平台之SSRF(服务器端请求伪造)
注意区分CSRF和SSRF: CSRF:跨站请求伪造攻击,由客户端发起; SSRF:是服务器端请求伪造,由服务器发起。 SSRF形成的原因大都是由于服务端提供了从其他服务器应用获取数据的功能,但又没有对目标…...

WPF异步编程
在WPF应用程序中进行异步编程是非常重要的,因为这有助于保持用户界面的响应性,特别是当执行长时间运行的操作时,例如访问网络资源、进行大量的数据处理或调用耗时的I/O操作。 WPF的异步编程通常围绕以下几个关键概念: Dispatcher…...

同态加密定义,四大发展阶段总结,FHE系统正式定义-全同态加密
目录 同态加密定义 为什么采用电路模型? 四大发展阶段 总结 FHE系统正式定义...

网上的搜索
Internet中蕴含的信息资源非常丰富,但如何在这浩瀚如海的信息空间内快速找到自己所需要的资源呢?我们需要借助于搜索引擎。在网络上,提供搜索功能的网站非常多,如百度、谷歌、搜狗等,另外有一些门户网站也提供了搜索功能…...

【算法-哈希表2】快乐数 和 两数之和
今天,带来哈希表相关算法的讲解。文中不足错漏之处望请斧正! 理论基础点这里 1. 快乐数 分析题意 出题者已经把题意明确告诉我们了: 对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。然后重复这个过程直到这个数变为 1&am…...

MR外包团队:MR、XR混合现实技术应用于游戏、培训,心理咨询、教育成为一种创新的各行业MR、XR形式!
随着VR、AR、XR、MR混合现实等技术逐渐应用于游戏开发、心理咨询、培训、教育各个领域,为教育、培训、心理咨询等行业带来了全新的可能性。MR、XR游戏开发、心理咨询是利用虚拟现实技术模拟真实场景,让学生身临其境地参与学习和体验,从而提高…...

【P1008 [NOIP1998 普及组] 三连击】
[NOIP1998 普及组] 三连击 题目背景 本题为提交答案题,您可以写程序或手算在本机上算出答案后,直接提交答案文本,也可提交答案生成程序。 题目描述 将 1 , 2 , … , 9 1, 2, \ldots , 9 1,2,…,9 共 9 9 9 个数分成 3 3 3 组ÿ…...
机器学习算法——集成学习
目录 1. Bagging 1. Bagging Bagging(bootstrap aggregating:自举汇聚法)也叫装袋法,其思想是通过将许多相互独立的学习器的结果进行结合,从而提高整体学习器的泛化能力,是一种并行集成学习方法。 工作流…...
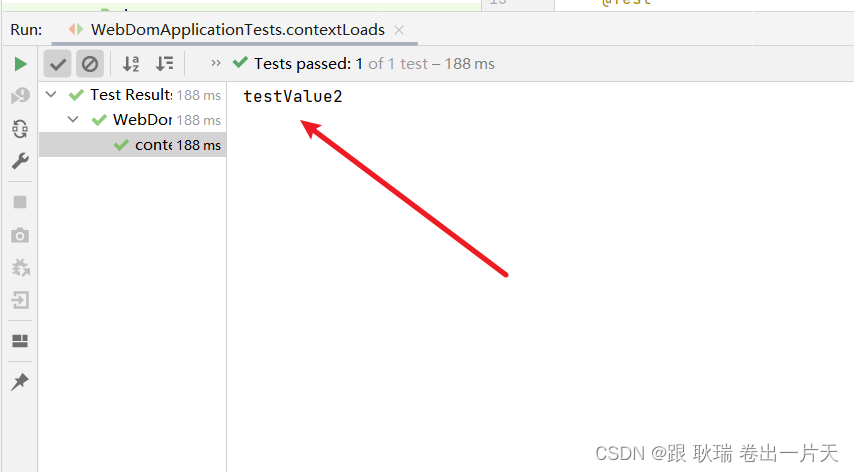
java springboot在当前测试类中添加临时属性 不影响application和其他范围
目前 我们的属性基本都写在 application.yml 里面了 但是 如果 我们只是想做一下临时变量的测试 有没有办法实现呢? 显然是有的 这里 我们还是先在application.yml中去写一个 test属性 下面加个prop 然后 我们尝试在测试类中 获取一下这个属性 直接用 Value 读取…...

原型网络Prototypical Network的python代码逐行解释,新手小白也可学会!!由于工作量大,准备整8个系列完事,-----系列5
文章目录 前言一、原始程序---计算原型,开始训练,计算损失二、每一行代码的详细解释2.1 粗略分析2.2 每一行代码详细分析 前言 承接系列4,此部分属于原型类中的计算原型,开始训练,计算损失函数。 一、原始程序—计算原…...

milvus数据库的数据管理-插入数据
一、插入数据 1.准备数据 数据必须与数据库中定义的字段元数据一致,与集合的模式匹配 import random data [[i for i in range(2000)],[str(i) for i in range(2000)],[i for i in range(10000, 12000)],[[random.random() for _ in range(2)] for _ in range(2…...
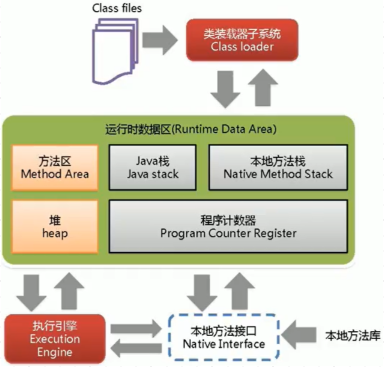
系列一、请谈谈你对JVM的理解?Java8的虚拟机有什么更新?
一、请谈谈你对JVM的理解?Java8的虚拟机有什么更新? JVM是Java虚拟机的意思。它是建立在操作系统之上的,由类加载器子系统、本地方法栈、Java栈、程序计数器、方法区、堆、本地方法库、本地方法接口、执行引擎组成。 (1࿰…...

恕我直言,大模型对齐可能无法解决安全问题,我们都被表象误导了
是否听说过“伪对齐”这一概念? 在大型语言模型(LLM)的评估中,研究者发现了一个引人注目的现象:当面对多项选择题和开放式问题时,模型的表现存在显著差异。这一差异根源在于模型对复杂概念的理解不够全面&…...

Apache Airflow (九) :Airflow Operators及案例之BashOperator及调度Shell命令及脚本
🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客 🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。 🔔 博主个人B栈地址:豹哥教你大数据的个人空间-豹…...

d2s-editor:暗黑破坏神2存档修改终极实战宝典
d2s-editor:暗黑破坏神2存档修改终极实战宝典 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 还在为暗黑破坏神2的刷装备、练级、属性点分配而烦恼吗?d2s-editor为你带来全新的单机游戏体验——这是一款基…...

从零到一:RK3588s平台imx415双目相机模组点亮与ISP调优实战
1. 环境准备:从零搭建开发环境 第一次接触RK3588s平台时,最头疼的就是环境搭建。我用的Firefly AIO-3588S-JD4开发板配套资料比较分散,光是找齐所有软件包就花了半天时间。这里分享下我的踩坑经验: 硬件清单必须严格核对&#x…...

三步构建高效笔记迁移系统:Obsidian Importer完全指南
三步构建高效笔记迁移系统:Obsidian Importer完全指南 【免费下载链接】obsidian-importer Obsidian Importer lets you import notes from other apps and file formats into your Obsidian vault. 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian-import…...

从零到一搭建 AI Agent 财务分析系统
一、核心目标拆解(先对齐业务) 你的系统要支撑 4 类核心场景: 财务报告自动生成 + 智能解读 智能问答 + 异常预警 财务预测、预算编制、风险识别 对接业务部门,推动需求落地 基于这个目标,我给你定了 **「轻量化 MVP → 企业级生产」两阶段架构 **,兼顾快速出 Demo 和长…...

手一滑,我把整个店都报上了活动
做Temu最怕什么?不是没单,不是被压价,是手滑。 去年有一次,我打算给店里十几个新款报个日常活动冲冲量。打开Temu商家后台,店铺营销,营销活动,找到合适的活动场次点了“去报名”。报名页里商品…...

别熬大夜改 PPT 了!Paperxie AI PPT,一键搞定毕业论文答辩
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPThttps://www.paperxie.cn/ppt/createhttps://www.paperxie.cn/ppt/create 论文终稿刚定稿,答辩 PPT 的空白页面就开始让人焦虑。打开 PowerPoint,对着 “新建幻灯片” 发愣&am…...

CentOS 7最小化安装后,如何用VNC Viewer远程连接GNOME桌面?实测避坑指南
CentOS 7最小化安装后构建GNOME远程桌面的完整实践指南 当你面对一台仅完成最小化安装的CentOS 7服务器,突然需要图形界面完成某些复杂配置时,这套从零构建GNOME桌面环境并通过VNC安全访问的解决方案,将成为你的技术救星。不同于常规教程&…...
)
手把手教你给STM32H743的0.96寸OLED屏移植STemWin(裸机+FreeRTOS双版本)
STM32H743与0.96寸OLED的STemWin深度移植实战:裸机与RTOS双环境解析 在嵌入式图形界面开发领域,STemWin作为ST官方推出的图形库解决方案,以其高效的渲染性能和丰富的控件资源,成为STM32开发者构建人机界面的首选。本文将聚焦STM32…...

电机选型与控制实战指南:从直流、步进到伺服电机
1. 电机选型:从理解需求开始选电机,听起来像是硬件工程师或者资深创客的活儿,但只要你玩过Arduino小车、做过3D打印机,或者想给家里的模型加个能动的部件,这事儿就绕不开。我刚开始接触项目时,也犯过迷糊&a…...

2026年工程师必知:20个AI核心术语,构建真正AI产品的第一性原理指南
面向真正构建AI产品的工程师——而非仅止于空谈者的第一性原理指南 坦诚而言,市面上绝大多数"AI术语汇编"类文章,其目标受众是那些希望在会议中显得见多识广的人。而本文,则专为那些真正动手构建的人而写。两者之间,存…...