Python | 机器学习之逻辑回归


🌈个人主页:Sarapines Programmer
🔥 系列专栏:《人工智能奇遇记》
🔖少年有梦不应止于心动,更要付诸行动。
目录结构
1. 机器学习之逻辑回归概念
1.1 机器学习
1.2 逻辑回归
2. 逻辑回归
2.1 实验目的
2.2 实验准备
2.3 实验题目
2.4 实验内容
2.5 实验心得
致读者
1. 机器学习之逻辑回归概念
1.1 机器学习
传统编程要求开发者明晰规定计算机执行任务的逻辑和条条框框的规则。然而,在机器学习的魔法领域,我们向计算机系统灌输了海量数据,让它在数据的奔流中领悟模式与法则,自主演绎未来,不再需要手把手的指点迷津。
机器学习,犹如三千世界的奇幻之旅,分为监督学习、无监督学习和强化学习等多种类型,各具神奇魅力。监督学习如大师传道授业,算法接收标签的训练数据,探索输入与输出的神秘奥秘,以精准预测未知之境。无监督学习则是数据丛林的探险者,勇闯没有标签的领域,寻找隐藏在数据深处的秘密花园。强化学习则是一场与环境的心灵对话,智能体通过交互掌握决策之术,追求最大化的累积奖赏。
机器学习,如涓涓细流,渗透各行各业。在图像和语音识别、自然语言处理、医疗诊断、金融预测等领域,它在智慧的浪潮中焕发生机,将未来的可能性绘制得更加丰富多彩。
1.2 逻辑回归
逻辑回归是一种用于解决二分类问题的统计学习方法。尽管其名字中包含"回归"一词,但实际上,逻辑回归是一种分类算法,用于预测一个样本属于两个类别中的哪一个。
逻辑回归的核心思想是通过一个称为"逻辑函数"或"sigmoid函数"的特殊函数,将线性组合的输入特征映射到0和1之间的概率值。该函数的输出可以被解释为属于正类别的概率。在二分类问题中,逻辑回归通过设置一个阈值(通常为0.5),将概率大于阈值的样本预测为正类别,而概率小于阈值的样本预测为负类别。
逻辑回归模型的训练过程涉及到找到最适合拟合训练数据的参数,通常使用最大似然估计等方法来实现。由于其简单、高效且易于解释的特点,逻辑回归在实际应用中广泛用于医学、社会科学、经济学等领域的二分类问题。
机器学习源文件![]() https://download.csdn.net/download/m0_57532432/88521177?spm=1001.2014.3001.5503
https://download.csdn.net/download/m0_57532432/88521177?spm=1001.2014.3001.5503
2. 逻辑回归
2.1 实验目的
(1)加深对有监督学习的理解和认识;
(2)了解逻辑回归的损失函数;
(3)掌握逻辑回归的优化方法;
(4)了解sigmoid函数;
(5)了解逻辑回归的应用场景;
(6)应用LogisticRegression实现逻辑回归预测;
(7)理解精确率、召回率指标的区别。
2.2 实验准备
(1)安装机器学习必要库,如NumPy、Pandas、Scikit-learn等;
(2)配置环境用来运行 Python、Jupyter Notebook和相关库等内容。
2.3 实验题目
假设你是某大学招生主管,你想根据两次考试的结果决定每个申请者的录取机会。现有以往申请者的历史数据,可以此作为训练集建立逻辑回归模型,并用其预测某学生能否被大学录取。请按要求完成实验。建议使用 python 编程实现。
数据集:
文件 ex2data1.txt 为该实验的数据集,第一列、第二列分别表示申请者两次考试的成绩,第三列表示录取结果(1 表示录取,0 表示不录取)。2.4 实验内容
总体步骤:
1.请导入数据并进行数据可视化,观察数据分布特征。(建议用 python 的matplotlib)
2.将逻辑回归参数初始化为 0,然后计算代价函数(cost function)并求出初始值。
3.选择一种优化方法求解逻辑回归参数。
4.某学生两次考试成绩分别为 42、85,预测其被录取的概率。
5.画出分类边界。
具体内容:
1.导入数据并进行数据可视化,观察数据分布特征。(建议用 python 的matplotlib)

图3-1
运行结果:
图3-2
代码:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import tickerdef plot_data():# 首先需要读取数据
raw_data = pd.read_csv("data/data.csv") # 从名为 "data.csv" 的文件中读取原始数据
raw_data.columns = ['first', 'second', 'admited'] # 为数据的列添加标签,分别为 'first', 'second', 'admited'# 接下来将数据中的 0 和 1 分开存储
admit_array_x = [] # 存储通过测试的数据的第一次考试成绩
admit_array_y = [] # 存储通过测试的数据的第二次考试成绩
not_admit_array_x = [] # 存储未通过测试的数据的第一次考试成绩
not_admit_array_y = [] # 存储未通过测试的数据的第二次考试成绩for i in range(raw_data.shape[0]):if raw_data.iloc[i][2] == 1:admit_array_x.append(raw_data.iloc[i][0])admit_array_y.append(raw_data.iloc[i][1])else:not_admit_array_x.append(raw_data.iloc[i][0])not_admit_array_y.append(raw_data.iloc[i][1])# 设置标题和横纵坐标的标注plt.xlabel("Exam 1 score")
# 设置 x 轴标签为 "Exam 1 score"plt.ylabel("Exam 2 score") # 设置 y 轴标签为 "Exam 2 score"# 设置通过测试和不通过测试数据的样式。# marker: 记号形状, color: 颜色, s: 点的大小, label: 标注plt.scatter(not_admit_array_x, not_admit_array_y, marker='o', color='red', s=15, label='Not admitted')plt.scatter(admit_array_x, admit_array_y, marker='x', color='green', s=15, label='Admitted')# 标注的显示位置:右上角plt.legend(loc='upper right')# 设置坐标轴上刻度的精度为一位小数。
# 因为训练数据中的分数的小数点太多,
# 若不限制坐标轴上刻度显示的精度,会影响最终散点图的美观度plt.gca().xaxis.set_major_formatter(ticker.FormatStrFormatter('%.1f'))plt.gca().yaxis.set_major_formatter(ticker.FormatStrFormatter('%.1f'))# 显示图像
plt.show()plot_data() #绘制图像
源码分析:
- 函数plot_data()被定义用于绘制散点图。它的主要功能是读取原始数据,并根据通过测试和未通过测试的两类数据的考试成绩创建相应的数组。数据读取是通过调用pd.read_csv()方法来实现的,从名为"data.csv"的文件中读取数据,并为数据的列添加了相应的标签,即'first'、'second'和'admited'。假设数据集的结构为三列。
- 在创建了用于存储通过测试和未通过测试数据的考试成绩的空数组后,使用循环遍历数据集的每一行。通过检查"admited"列的值,将考试成绩数据分别存储到对应的数组中。当"admited"列的值为1时,表示该数据是通过测试的,将该行的第一次考试成绩添加到admit_array_x数组中,将第二次考试成绩添加到admit_array_y数组中。当"admited"列的值不为1时,表示该数据未通过测试,将相应的考试成绩分别添加到not_admit_array_x和not_admit_array_y数组中。
- 在数据准备完毕后,对图形进行设置。首先设置图的标题和横纵坐标的标注。将x轴标签设置为"Exam 1 score",表示第一次考试成绩,将y轴标签设置为"Exam 2 score",表示第二次考试成绩。
- 接下来使用plt.scatter()函数绘制散点图。通过设置不同的参数来指定通过测试和未通过测试数据的样式。未通过测试数据使用圆形作为标记(marker='o'),通过测试数据使用叉号作为标记(marker='x')。未通过测试数据的颜色设置为红色(color='red'),通过测试数据的颜色设置为绿色(color='green')。点的大小设置为15(s=15)。同时,通过设置标注的参数(label='Not admitted'和label='Admitted'),为未通过测试和通过测试的数据添加相应的标注。
- 使用plt.legend()函数将标注显示在右上角。
- 为了提高坐标轴刻度的可读性和美观度,使用plt.gca().xaxis.set_major_formatter()和plt.gca().yaxis.set_major_formatter()函数设置坐标轴上刻度的精度为一位小数。这里使用ticker.FormatStrFormatter('%.1f')指定显示格式为保留一位小数。
- 最后调用plt.show()函数显示图像,将图像呈现在屏幕上。
- 在定义完函数之后,调用plot_data()函数即可执行绘制图像的操作,根据数据绘制出相应的散点图。
2.将逻辑回归参数初始化为 0,然后计算代价函数(cost function)并求出初始值。

图3-3
代码:
def init_data():# 将数据初始化data = pd.read_csv("data/data.csv") # 从名为 "data.csv" 的文件中读取数据data.columns = ['first', 'second', 'admited'] # 为数据的列添加标签,分别为 'first', 'second', 'admited'# 尝试对数据进行标准化column_list = list(data.columns) # 获取数据集中的列名列表min_value = [] # 存储每一列的最小值max_value = [] # 存储每一列的最大值for j in range(data.shape[1] - 1):min_value.append(data[column_list[j]].min()) # 计算每一列的最小值并存储max_value.append(data[column_list[j]].max()) # 计算每一列的最大值并存储for i in range(data.shape[0]):# 对每一个数据点进行标准化,将其转换为0到1之间的值data.loc[i, column_list[j]] = (data.loc[i, column_list[j]] - min_value[j]) / (max_value[j] - min_value[j])data_x = data.iloc[:, 0:2] # 特征值,取第一列和第二列作为特征data_y = data.iloc[:, -1] # 标签,取最后一列作为标签return data_x.values, data_y.values, min_value, max_value
3.选择一种优化方法求解逻辑回归参数。

图3-4

图3-5
运行结果:
图3-6
代码:
# 与逻辑回归有关的函数# 定义 sigmoid 函数,用于将输入值映射到0到1之间
def sigmoid(z):return 1 / (1 + np.exp(-z))# 定义代价函数,用于计算逻辑回归模型的代价
def cost_function(X, y, theta):m = len(y) # 样本数量h = sigmoid(np.dot(X, theta)) # 计算假设函数的预测值J = -(1/m) * np.sum(y * np.log(h) + (1-y) * np.log(1-h)) # 代价函数表达式return J# 定义梯度下降函数,用于更新模型参数
def gradient_descent(X, y, theta, alpha, num_iterations):m = len(y) # 样本数量J_history = [] # 存储每次迭代的代价值for i in range(num_iterations):h = sigmoid(np.dot(X, theta)) # 计算假设函数的预测值gradient = np.dot(X.T, (h - y)) / m # 计算梯度theta = theta - alpha * gradient # 更新模型参数cost = cost_function(X, y, theta) # 计算当前模型参数下的代价J_history.append(cost) # 将代价添加到代价历史列表中
return theta, J_history# 逻辑回归主函数
# 从 CSV 文件读取数据
data = pd.read_csv('data/data.csv')
data.columns = ['first','second','admited']# 提取特征和标签
data_x, data_y, min_value, max_value = init_data()# 初始化参数
theta = np.zeros(2) # 将权重初始设置为0
alpha = 0.01 # 学习率
num_iterations = 1000 # 迭代次数# 训练逻辑回归模型
theta, J_history = gradient_descent(data_x, data_y, theta, alpha, num_iterations)# 绘制代价函数的变化曲线
plt.plot(J_history) # 绘制迭代次数与代价值之间的关系曲线
plt.xlabel('iteration') # 设置x轴标签
plt.ylabel('cost value') # 设置y轴标签
plt.title('curve of cost values') # 设置图的标题为"cost values的变化曲线"
# 显示图像
plt.show()
源码分析:
- 这里定义了逻辑回归相关的函数,包括sigmoid函数、代价函数和梯度下降函数。然后在逻辑回归主函数中读取数据,提取特征和标签,并初始化模型参数。通过调用梯度下降函数进行模型训练,并绘制代价函数的变化曲线,以评估模型的训练效果。这些步骤构成了一个基本的逻辑回归训练过程。
- sigmoid函数。sigmoid函数将输入值映射到0到1之间的范围是逻辑回归中的核心函数之一。逻辑回归的目标是将线性加权和的输出转化为概率值,而sigmoid函数正是用于实现这个转化过程。
- 代价函数cost_function。该函数用于计算逻辑回归模型的代价。它接受输入数据X、标签y和模型参数theta作为参数,并根据逻辑回归的代价函数公式计算代价J。代价函数是衡量模型预测结果与实际标签之间差异的指标,逻辑回归的目标是最小化代价函数,以找到最优的模型参数。
- 梯度下降函数gradient_descent。该函数用于更新模型参数,以使代价函数逐步降低。它接受输入数据X、标签y、模型参数theta、学习率alpha和迭代次数num_iterations作为参数。在每次迭代中,函数通过计算假设函数的预测值h和计算梯度gradient来更新模型参数theta。梯度下降算法通过沿着梯度的反方向更新参数,使得代价函数逐步减小,从而逐步接近最优解。在每次迭代结束后,函数还计算当前模型参数下的代价cost,并将代价值添加到代价历史列表J_history中。
- 在逻辑回归主函数中,首先从CSV文件中读取数据,并将数据的列标签设置为'first'、'second'和'admited'。这些列标签指定了数据集中各列的含义。
- 调用函数init_data()来提取特征和标签。该函数的具体实现在代码中并未给出,但可以假设它用于对原始数据进行处理,提取特征和标签,并进行必要的数据预处理步骤。提取得到的特征存储在data_x中,标签存储在data_y中。
- 初始化模型参数theta为0,学习率alpha为0.01,迭代次数num_iterations为1000。这些参数将用于训练逻辑回归模型。
- 调用梯度下降函数gradient_descent进行模型训练。函数传入输入数据data_x、标签data_y、模型参数theta、学习率alpha和迭代次数num_iterations。函数将返回更新后的模型参数theta和代价历史列表J_history。
- 使用matplotlib库绘制代价函数的变化曲线。函数使用plt.plot()将迭代次数与代价值之间的关系绘制成曲线图。通过设置x轴标签为'iteration',y轴标签为' cost value',以及图的标题为'curve of cost values',可以更直观地观察训练过程中代价函数的变化情况。最后,调用plt.show()函数显示绘制的图像,使得代价函数的变化曲线可见。
- 这个曲线图对于评估模型的训练效果非常有用。如果代价函数的值在每次迭代后都逐渐减小,说明模型的训练是有效的,参数在朝着最优值的方向更新。
训练模型:

图3-7
运行结果:

图3-8

图3-9
代码:
########## 使用测试集进行测试 #####################
# 读取测试集数据
test_data = pd.read_csv('data/data_test.csv')
test_data.columns = ['first','second','admited']# 测试集数据标准化
column_list = list(test_data.columns)
for j in range(test_data.shape[1]-1):for i in range(test_data.shape[0]):test_data.loc[i,column_list[j]] = (test_data.loc[i,column_list[j]]-min_value[j]) / (max_value[j]-min_value[j])
test_data_x = test_data.iloc[:,0:2].values
test_data_y = test_data.iloc[:,-1].values# 输入 sigmoid 函数进行预测
prediction = sigmoid(np.dot(test_data_x, theta))
print(prediction)# 输出正确率
num = 0 # 预测正确的个数
for i in range(len(prediction)):if prediction[i] > 0.5:temp_value = 1else:temp_value = 0if test_data_y[i] == temp_value:num = num + 1
print(f"模型的正确率为:{num/len(prediction)}")################# 绘制决策边界 #################
# 定义决策边界的阈值
threshold = 0.5# 生成网格点
x_min, x_max = data_x[:, 0].min() - 0.01, data_x[:, 0].max() + 0.01
y_min, y_max = data_x[:, 1].min() - 0.01, data_x[:, 1].max() + 0.01
h = 0.0001 # 网格点的间隔
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))# 对网格点进行预测
X_grid = np.c_[xx.ravel(), yy.ravel()]
Z = np.dot(X_grid, theta)
Z = sigmoid(Z)
Z = Z.reshape(xx.shape)# 绘制决策边界和分类结果
plt.contourf(xx, yy, Z, alpha=0.8)
# 绘制决策边界
plt.scatter(data_x[:, 0], data_x[:, 1], c=data_y)
# 绘制样本点
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Decision Boundary')
plt.show()
源码分析:
1.读取测试集数据:
- 从名为'data_test.csv'的文件中读取测试集数据,并将列名改为'first'、'second'和'admited'。
2.测试集数据标准化:
- 获取列名列表column_list。
- 对每一列进行标准化,即将每个元素减去最小值(min_value[j]),然后除以最大值和最小值的差值(max_value[j]-min_value[j]),使得数据在0到1之间。
- 提取标准化后的特征值(test_data_x)和标签值(test_data_y)。
3.使用sigmoid函数进行预测:
- 根据预测模型的参数(theta)和测试集特征值(test_data_x),计算预测概率值(prediction)。这里使用np.dot函数进行矩阵乘法,将特征值和参数进行相乘,并通过sigmoid函数将结果映射到0到1之间的概率值。
4.输出正确率:
- 初始化变量num为0,用于记录预测正确的个数。
- 遍历每个预测概率值(prediction)。
- 如果预测概率值大于0.5,将临时变量temp_value设为1,否则设为0。
- 如果测试集标签值(test_data_y)等于临时变量temp_value,表示预测正确,将num加1。
- 计算并输出模型的正确率。
5.绘制决策边界:
- 定义决策边界的阈值为0.5。
- 获取数据集中特征1和特征2的最小值和最大值,并略微扩展范围,生成一个网格点矩阵(xx, yy)。
- 对网格点进行预测,即根据模型参数(theta)和网格点特征值(X_grid)计算预测概率值(Z)。将预测概率值通过sigmoid函数进行映射,并重新调整形状为与网格点相同。
- 使用contourf函数绘制决策边界的等高线,alpha参数设置透明度。
- 使用scatter函数绘制数据集中的样本点,c参数根据标签值(data_y)设置样本点的颜色。
- 添加x轴和y轴标签,设置标题,并展示图像。
6.定义决策边界的阈值:
- 将决策边界的阈值设为0.5,即当预测概率值大于0.5时,将其判定为正类,否则为负类。
7.生成网格点:
- 获取数据集中特征1和特征2的最小值和最大值,并稍微扩展范围。
- 定义一个间隔大小h,用于生成网格点。
- 利用np.meshgrid函数生成一个网格点矩阵(xx, yy),其中xx和yy分别是特征1和特征2在网格上的坐标值。
8.对网格点进行预测:
- 将网格点矩阵(xx, yy)转换为一维数组形式,便于进行预测。
- 利用np.dot函数计算预测概率值(Z),即将网格点特征值与模型参数(theta)进行矩阵乘法。
- 将预测概率值(Z)通过sigmoid函数进行映射,将其转换为0到1之间的概率值。
- 将预测概率值(Z)重新调整形状,使其与网格点矩阵(xx, yy)的形状相同。
9.绘制决策边界和分类结果:
- 使用contourf函数绘制决策边界的等高线,将预测概率值(Z)作为填充颜色,alpha参数设置透明度。
- 使用scatter函数绘制数据集中的样本点,特征1和特征2作为坐标,标签值(data_y)决定样本点的颜色。
- 添加x轴和y轴标签,设置标题。
- 显示绘制的图像。
4.某学生两次考试成绩分别为 42、85,预测其被录取的概率。

图3-10
代码:
# 当输入为42和85时,计算通过概率
# 标准化输入值
x1 = (42 - min_value[0]) / (max_value[0] - min_value[0])
x2 = (85 - min_value[1]) / (max_value[1] - min_value[1])
# 将输入值转换为数组
arr = np.array((x1, x2))
# 计算最终通过概率
print(f"通过概率为:{sigmoid(np.dot(arr, theta))}")5.画出分类边界。
分类边界在第三步已经完成,如图3-9。
2.5 实验心得
本次实验运用逻辑回归算法进行学生考试成绩和录取结果的分类预测,实现了数据可视化、参数初始化、代价函数计算、梯度下降优化、预测和决策边界绘制等关键步骤。
数据可视化阶段通过matplotlib库创建散点图,生动展示通过和不通过考试学生在两次考试成绩上的分布特征,直观呈现数据的分布情况。
参数初始化和代价函数计算中,将逻辑回归参数初始化为0,定义sigmoid函数和代价函数,用于映射输入值、度量预测与实际标签的差距,以及评估模型准确性。
在梯度下降优化中,通过迭代更新模型参数,减小代价函数的值,以找到最优模型参数。
预测阶段利用训练好的模型参数对测试集进行预测,计算模型的准确率,通过sigmoid函数输出的预测值表示学生被录取的概率。
决策边界绘制中,定义决策边界的阈值,生成网格点,通过对网格点预测和contourf函数绘制决策边界,直观观察模型的分类效果。使用scatter函数将训练集样本点绘制在图上,以不同颜色表示通过和不通过考试的学生,全面展示了模型的分类结果。
此实验深入理解了逻辑回归算法的原理和应用,并通过代码实现了相关功能。
致读者
风自火出,家人;君子以言有物而行有恒
相关文章:
Python | 机器学习之逻辑回归
🌈个人主页:Sarapines Programmer🔥 系列专栏:《人工智能奇遇记》🔖少年有梦不应止于心动,更要付诸行动。 目录结构 1. 机器学习之逻辑回归概念 1.1 机器学习 1.2 逻辑回归 2. 逻辑回归 2.1 实验目的…...
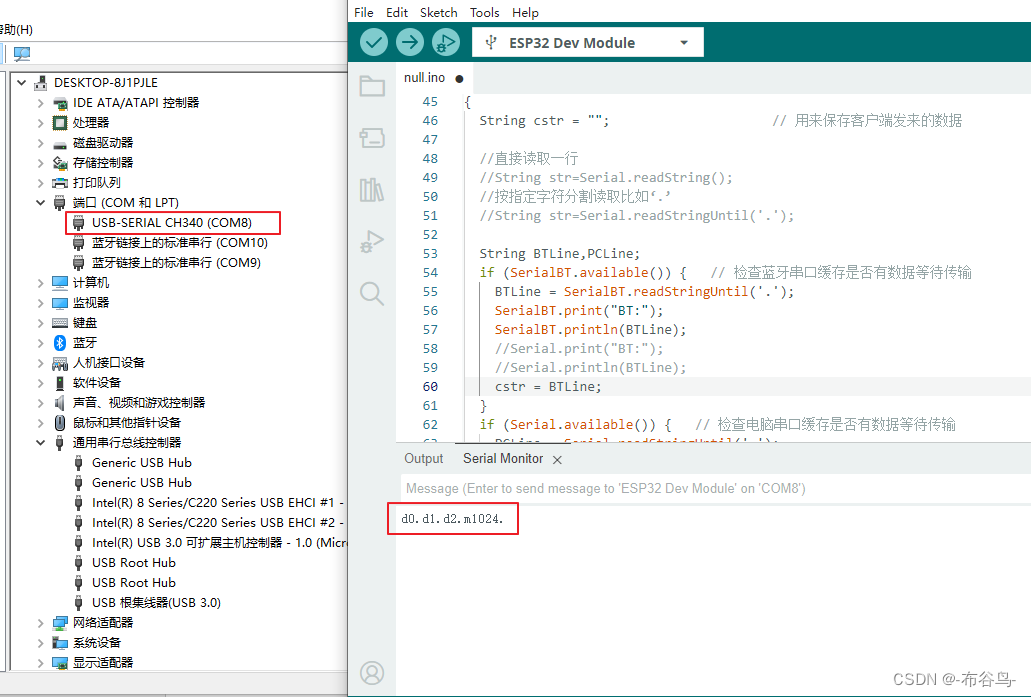
手机,蓝牙开发板,TTL/USB模块,电脑四者之间的通讯
一,意图 通过手机蓝牙连接WeMosD1R32开发板,开发板又通过TTL转USB与电脑连接.手机通过蓝牙控制开发板上的LED灯的开,关,闪等动作,在电脑上打开串口监视工具观察其状态.也可以通过电脑上的串口监视工具来控制开发板上LED灯的动作,而在手机蓝牙监测工具中显示灯的状态. 二,原料…...
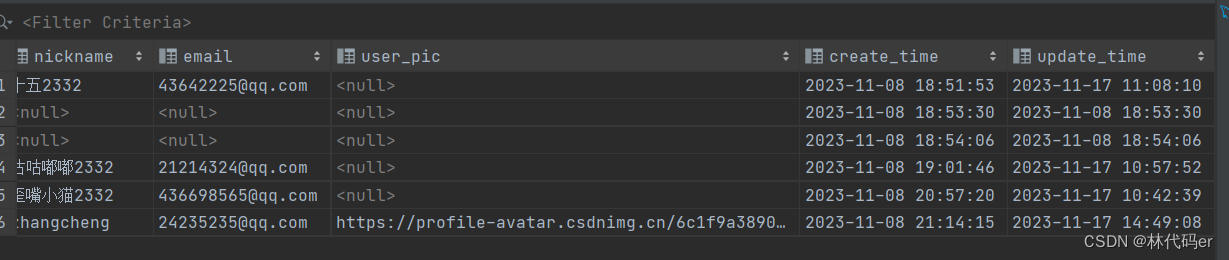
Springboot更新用户头像
人们通常(为徒省事)把一个包含了修改后userName的完整userInfo对象传给后端,做完整更新。但仔细想想,这种做法感觉有点二,而且浪费带宽。 于是patch诞生,只传一个userName到指定资源去,表示该请求是一个局部更新&#…...
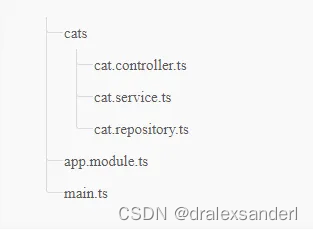
Express.js 与 Nest.js对比
Express.js 与 Nest.js对比 自从 Node.js 发布以来,Javascript 在后端领域的使用有所增加。由于 Node.js 的使用越来越多,每天都会有新的框架和工具发布。Express 和 Nest 是使用 Node.js 创建后端应用程序的最著名的框架之一,在本文中&…...
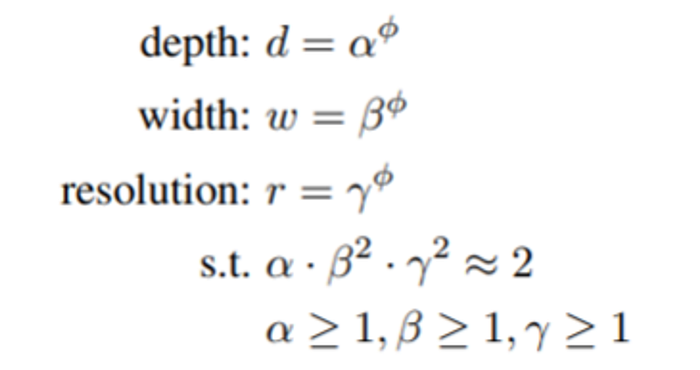
总结 CNN 模型:将焦点转移到基于注意力的架构
一、说明 在计算机视觉时代,卷积神经网络(CNN)几十年来一直是主导范式。直到 2021 年 Vision Transformers (ViTs) 出现,这个领域才开始发生变化。现在,是时候采用受 Transformer 架构启发的基于注意力的模型了&#x…...
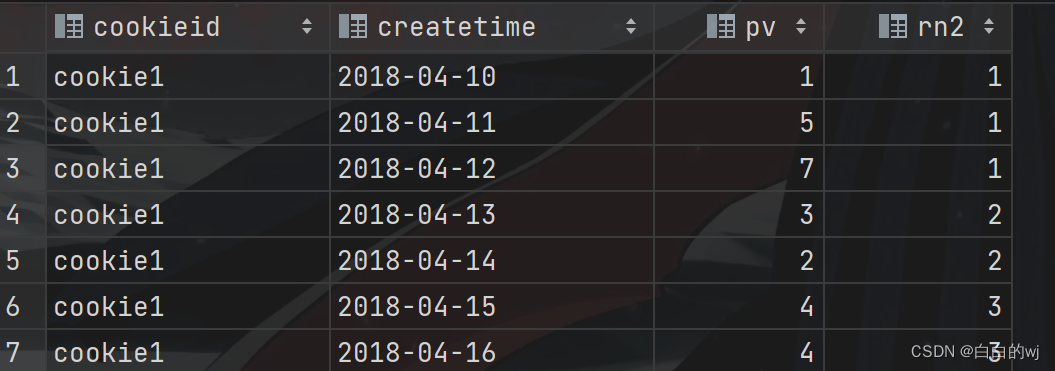
2023.11.16 hivesql高阶函数之开窗函数
目录 1.开窗函数的定义 2.数据准备 3.开窗函数之排序 需求:用三种排序方法查询学生的语文成绩排名,并降序显示 4.开窗函数分组 需求:按照科目来分类,使用三种排序方式来排序学生的成绩 5.聚合函数与分组配合使用 6.聚合函数同时和分组以及排序关键字配合使用 --需求1&…...

QTableWidget常用信号的功能
2023年11月18日,周六上午 itemPressed(QTableWidgetItem *item):当某个项目被按下时发出信号。itemClicked(QTableWidgetItem *item):当某个项目被单击时发出信号。itemDoubleClicked(QTableWidgetItem *item):当某个项目被双击时…...

Vue理解01
项目建立流程 项目文件夹终端vue ui可视化新建项目(需要一些时间)vscode打开项目npm run serve运行 架构理解: 首先打开的页面默认是index.htmlindex.html默认引用main.jsmain.js引用需要的页面,默认App.vue。Vue示例挂载可以在…...
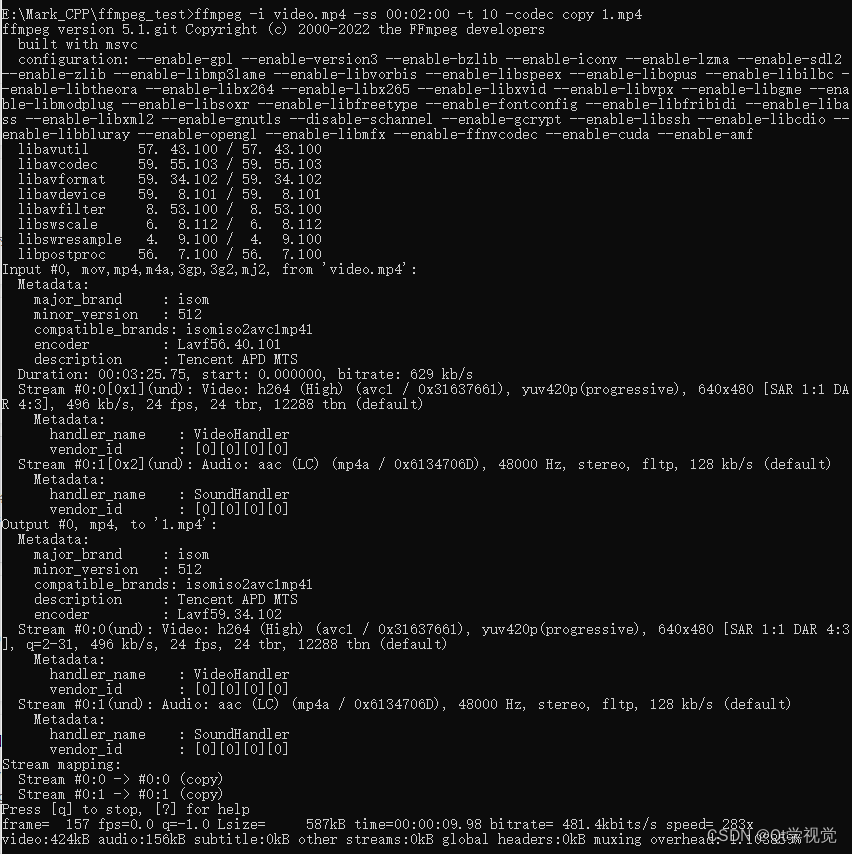
4、FFmpeg命令行操作8
生成测试文件 找三个不同的视频每个视频截取10秒内容 ffmpeg -i 沙海02.mp4 -ss 00:05:00 -t 10 -codec copy 1.mp4 ffmpeg -i 复仇者联盟3.mp4 -ss 00:05:00 -t 10 -codec copy 2.mp4 ffmpeg -i 红海行动.mp4 -ss 00:05:00 -t 10 -codec copy 3.mp4 如果音视…...
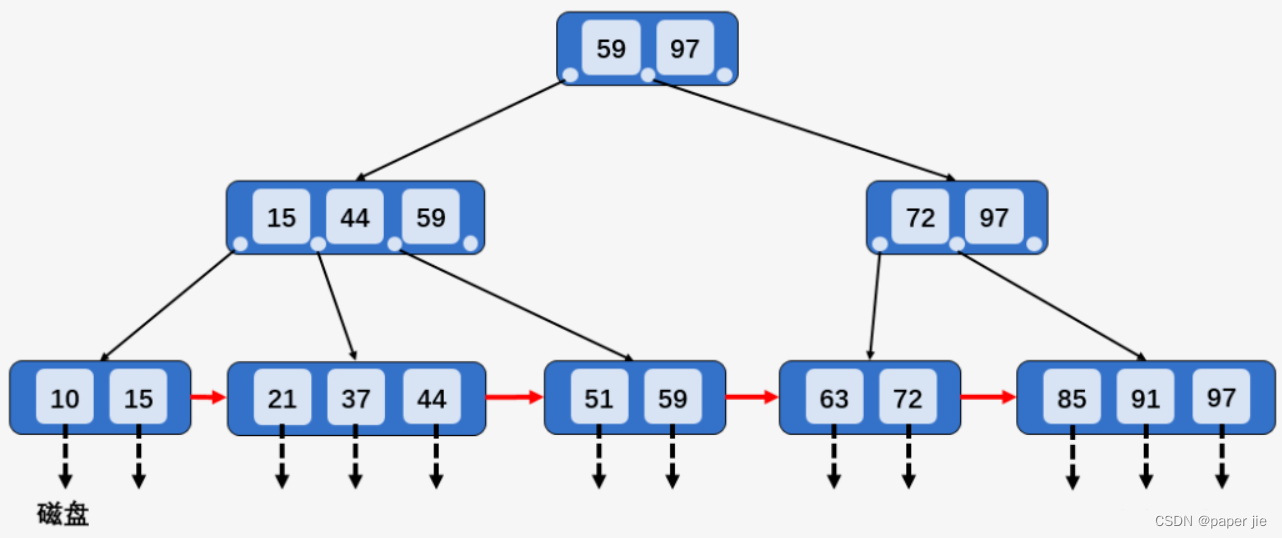
【MySQL】索引与事务
作者主页:paper jie_博客 本文作者:大家好,我是paper jie,感谢你阅读本文,欢迎一建三连哦。 本文录入于《MySQL》专栏,本专栏是针对于大学生,编程小白精心打造的。笔者用重金(时间和精力)打造&a…...

切换为root用户后,conda:未找到命令
问题:切换为root用户后,conda:未找到命令 结论详细用户切换配置路径 结论 问题:切换为root用户后,conda:未找到命令 (anaconda) 解决:在~/.bashrc配置里增加conda的路径 详细 用户切换 1 切…...

Qt退出界面
void Dialog::on_pushButton_clicked() {if(ui->lineEdit->text() "admin" && ui->lineEdit_2->text() "123"){accept();//退出} }...

【数据标注】Label Studio用于机器学习标注
原文作者:我辈李想 版权声明:文章原创,转载时请务必加上原文超链接、作者信息和本声明。 文章目录 前言一、使用 Label Studio标注数据1.版本控制 二、Label Studio绑定机器学习后端三、重写机器学习后端四、通过api执行Label Studio动作 前言…...

py字符串转字符串数组
在Python中,你可以使用列表(list)来存储多个字符串。如果你有一个字符串,并且想要将其转换为字符串数组,你可以使用列表推导式(list comprehension)。这是一个简单的例子: # 原始字…...
强化学习各种符号含义解释
:状态 : 动作 : 奖励 : 奖励函数 : 非终结状态 : 全部状态,包括终结状态 : 动作集合 ℛ : 奖励集合 : 转移矩阵 : 离散时间步 : 回合内最终时间步 : 时间t的状态 : 时间t动作 : 时间t的奖励,通常为随机量,且由和决定 : 回报 : n步…...

Axure基础详解二十:中继器随机抽奖效果
效果演示 组件 一、中继器 建立一个“中继器”内部插入一个“正方形”,给“正方形”添加一个【样式效果】>>【选中状态】填充背景为红色,字体白色。在中继器表格中插入两列数据函数:【xuhao】(序号列,按12345……填写&…...

企业信息化与电子商务>供应链信息流
1.供应链信息流概念 供应链信息流是指整个供应链上信息的流动。它是一种虚拟形态,包括了供应链上的供需信息和管理信息,它伴随着物流的运作而不断产生。因此有效的供应链管理作为信息流的管理主要作用在于及时在供应链中传递需求和供给信息,…...
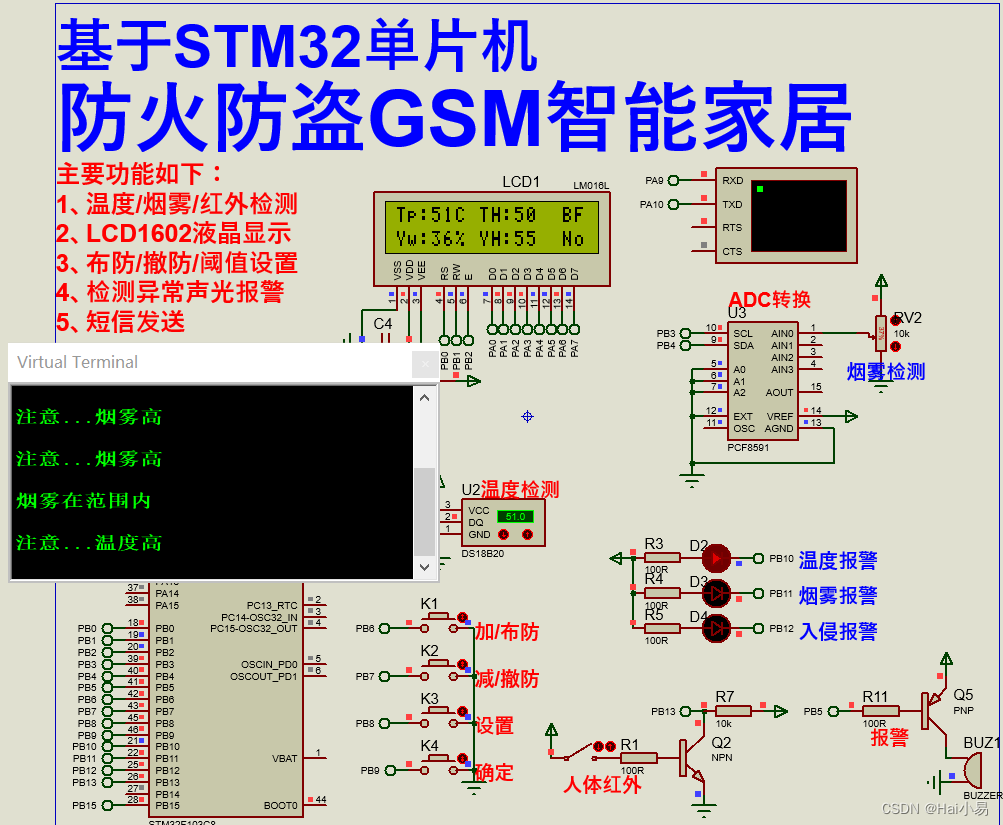
【Proteus仿真】【STM32单片机】防火防盗GSM智能家居设计
文章目录 一、功能简介二、软件设计三、实验现象联系作者 一、功能简介 本项目使用Proteus8仿真STM32单片机控制器,使用声光报警模块、LCD1602显示模块、DS18B20温度、烟雾传感器模块、按键模块、PCF8591 ADC模块、红外检测模块等。 主要功能: 系统运行…...
快速入门ESP32——开发环境配置PlatformIO IDE
相关文章 快速入门ESP32——开发环境配置Arduino IDE 快速入门ESP32——开发环境配置PlatformIO IDE 一、下载安装二、验证 一、下载安装 下载安装 vscode 安装PlatformIO插件 创建工程 二、验证 写一个简单的函数来验证一下功能 void setup() {// put your setup cod…...

Oxygen XML Editor 26版新功能
▲ 搜索“大龙谈智能内容”关注GongZongHao▲ 2023年10月26日,罗马尼亚SyncRO Soft公司发布Oxygen XML Editor、Oxygen Web Author和Oxygen Publish Engine 26版本。 1. Oxygen XML Editor 26新功能简介 AI助手 帮助写作者通过执行重复任务、审查语法、生成结构…...

PromptFlow:企业级AI应用编排与全生命周期管理工具详解
1. 项目概述:PromptFlow,一个被低估的AI应用编排利器如果你最近在折腾大语言模型应用,从简单的聊天机器人到复杂的多步推理工作流,大概率会听到“LangChain”、“LlamaIndex”这些名字。它们确实火,社区活跃࿰…...

别再拿冰河木马当玩具了!从一次真实的渗透测试复盘,聊聊Windows XP时代的安全漏洞与防御思路
从冰河木马看Windows XP时代的安全漏洞与现代防御启示 2000年代初的互联网环境与今天截然不同。那时,Windows XP系统占据着绝对市场份额,而安全意识对大多数用户来说还是个陌生概念。正是在这样的背景下,"冰河"这类远程控制工具得以…...

个人股票数据中枢构建指南:从多源聚合到Python量化分析
1. 项目概述:一个为个人投资者打造的股票数据中枢如果你和我一样,是个喜欢自己动手折腾、对市场数据有“洁癖”的个人投资者,那你肯定也经历过这样的烦恼:想分析一只股票,数据源五花八门,格式千奇百怪&…...

Diablo Edit2:终极暗黑破坏神2存档编辑器完全指南
Diablo Edit2:终极暗黑破坏神2存档编辑器完全指南 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 你是否厌倦了在暗黑破坏神2中反复刷装备的枯燥过程?是否因为技能点分配失…...

ComfyUI-Manager插件不显示问题终极指南:从原理到实战的完整解决方案
ComfyUI-Manager插件不显示问题终极指南:从原理到实战的完整解决方案 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable…...

基于知识图谱与NLP技术的小说文本结构化分析实战
1. 项目概述:当小说遇见知识图谱 如果你和我一样,既是个技术爱好者,又是个小说迷,那你肯定有过这样的体验:读完一本情节复杂、人物关系盘根错节的小说后,合上书页,脑子里却一团乱麻。谁是谁的盟…...

终极指南:使用XNBCLI高效解包打包星露谷物语XNB游戏资源文件
终极指南:使用XNBCLI高效解包打包星露谷物语XNB游戏资源文件 【免费下载链接】xnbcli A CLI tool for XNB packing/unpacking purpose built for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/xn/xnbcli XNB文件是星露谷物语等XNA游戏引擎使用…...

Godot引擎集成CEF实现Web混合渲染:gdcef项目架构与实战指南
1. 项目概述与核心价值最近在折腾一个老项目的现代化改造,需要把传统的桌面应用嵌入到Web视图中,实现混合渲染。在技术选型时,我绕不开一个名字:CEF,也就是Chromium Embedded Framework。它几乎是桌面应用内嵌浏览器控…...

Arm Neoverse CMN-650错误处理与事务管理机制解析
1. Arm Neoverse CMN-650错误处理机制深度解析在现代多核处理器系统中,错误处理机制的设计直接影响着系统的可靠性和稳定性。Arm Neoverse CMN-650作为一款高性能一致性网状网络,其错误处理架构展现了精妙的设计理念。1.1 HN-I节点的错误分类与处理HN-I&…...

开源机械爪应用宝库:从视觉分拣到项目实战全解析
1. 项目概述:一个开源“机械爪”用例的灵感宝库如果你对机器人、自动化或者开源硬件感兴趣,最近在GitHub上闲逛时,可能刷到过一个叫hesamsheikh/awesome-openclaw-usecases的仓库。光看名字,就能猜个八九不离十:这是一…...