关于Flume-Kafka-Flume的模式进行数据采集操作


测试是否连接成功:
在主节点flume目录下输入命令:
bin/flume-ng agent -n a1 -c conf/ -f job/file_to_kafka.conf -Dflume.root.logger=info,console
# 这个file_to_kafka.conf文件就是我们的配置文件

然后在另一台节点输入命令进行消费数据:
kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic topic_log

然后再开一个主节点终端,在这个主节点上面在对应生成数据的文件追加数据

这样就可以看见第一个主节点的终端和消费节点上面有数据变化了!

下面这个是配置拦截器,把json格式的内容进行消费,其他的进行拦截
Flume采集数据到kafka的配置conf文件内容:
#定义组件
#1、定义source、channel、agent名称
a1.sources = r1
a1.channels = c1
#配置source#2、描述source
a1.sources.r1.type = TAILDIR#指定监控的组名
a1.sources.r1.filegroups = f1#指定f1组监控的路径
a1.sources.r1.filegroups.f1 = /opt/software/applog/log/app.*#指定断点续传的文件
a1.sources.r1.positionFile = /opt/software/flume/taildir_position.json
# 配置拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.gmall.flume.interceptor.ETLInterceptor$Builder
#配置channel#3、描述channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel#指定kafka集群
a1.channels.c1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092#指定数据写到kafka哪个topic
a1.channels.c1.kafka.topic = topic_log#是否以Event对象的形式写入kafka
a1.channels.c1.parseAsFlumeEvent = false
#组装#4、关联source->channel
a1.sources.r1.channels = c1
如果一开始测试我们flume和kafka是否能成功采集数据的时候,我们应该先把拦截器的两行配置先删除,后面再根据我们需要的内容进行拦截对应的内容。就比如:我们期望我们采集到数据是json格式的,如果不是json格式的话,我们就放弃这个数据。
具体操作:
(1)创建Maven工程flume-interceptor
(2)创建包:com.gugu.gmall.flume.interceptor
(3)在pom.xml文件中添加如下配置
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
在com.gugu.gmall.flume.utils包下创建JSONUtil类
package com.gugu.gmall.flume.utils;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.fastjson.JSONException;public class JSONUtil {
/*
* 通过异常判断是否是json字符串
* 是:返回true 不是:返回false
* */public static boolean isJSONValidate(String log){try {JSONObject.parseObject(log);return true;}catch (JSONException e){return false;}}
}在com.gugu.gmall.flume.interceptor包下创建ETLInterceptor类
package com.gugu.gmall.flume.interceptor;import com.atguigu.gmall.flume.utils.JSONUtil;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;import java.nio.charset.StandardCharsets;
import java.util.Iterator;
import java.util.List;public class ETLInterceptor implements Interceptor {@Overridepublic void initialize() {}@Overridepublic Event intercept(Event event) {//1、获取body当中的数据并转成字符串byte[] body = event.getBody();String log = new String(body, StandardCharsets.UTF_8);//2、判断字符串是否是一个合法的json,是:返回当前event;不是:返回nullif (JSONUtil.isJSONValidate(log)) {return event;} else {return null;}}@Overridepublic List<Event> intercept(List<Event> list) {Iterator<Event> iterator = list.iterator();while (iterator.hasNext()){Event next = iterator.next();if(intercept(next)==null){iterator.remove();}}return list;}public static class Builder implements Interceptor.Builder{@Overridepublic Interceptor build() {return new ETLInterceptor();}@Overridepublic void configure(Context context) {}}@Overridepublic void close() {}
}然后进行打包,复制到我们flume下的lib目录下就可以了!
然后再和上面测试一样进行测试连接,是否成功把非json格式的数据拦截成功!

感谢各位的观看,创作不易,能不能给哥们来一个点赞呢!!!
好了,今天的分享就这么多了,有什么不清楚或者我写错的地方,请多多指教!
私信,评论我呗!!!!!!
关注我下一篇不迷路哦!
相关文章:
关于Flume-Kafka-Flume的模式进行数据采集操作
测试是否连接成功: 在主节点flume目录下输入命令: bin/flume-ng agent -n a1 -c conf/ -f job/file_to_kafka.conf -Dflume.root.loggerinfo,console # 这个file_to_kafka.conf文件就是我们的配置文件 然后在另一台节点输入命令进行消费数据: kafka-cons…...
WeTab--颜值与实力并存的浏览器插件
一.前言 现在的浏览器花花绿绿,有大量的广告与信息,令人目不暇接。有没有一款好用的浏览器插件可以解决这个问题呢?我愿称WeTab为版本答案。 WeTab的界面: 干净又整洁。最最关键的是还有智能AI供你服务。 这个WeTabAI就像chatgp…...

【整理】HTTP相关版本对比
1. HTTP/1 超文本传输协议,处于计算机网络中的应用层,HTTP是建立在TCP协议之上,所以HTTP协议的瓶颈及其优化技巧都是基于TCP协议本身的特性。 缺陷: 连接无法复用 ---------- 每次请求经历三次握手和慢启动HOLB(队头…...
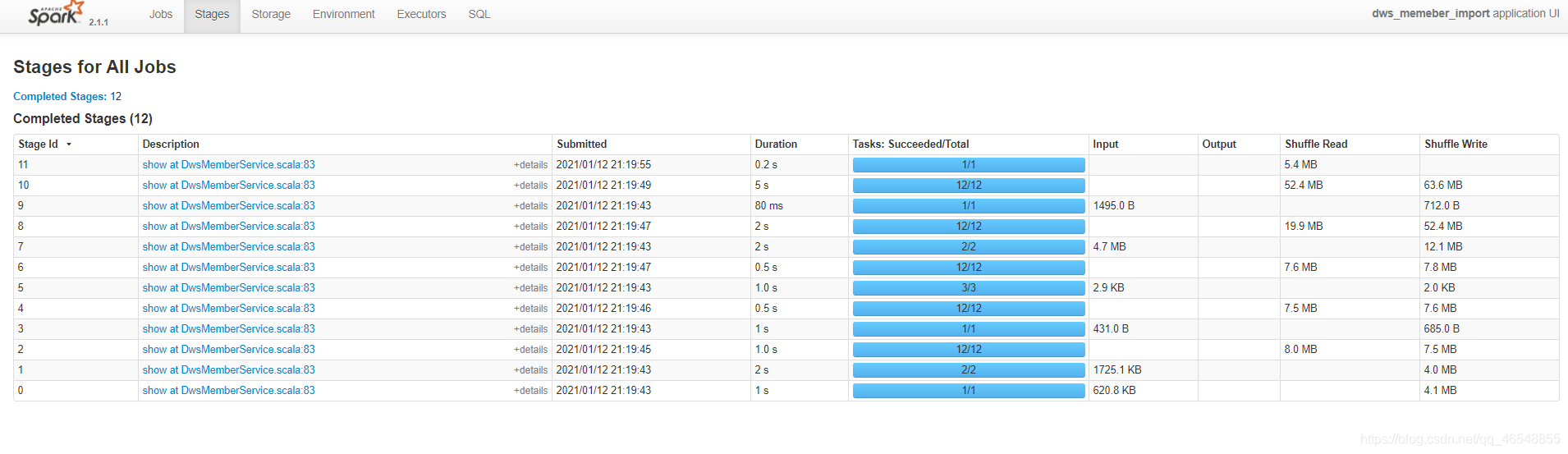
spark性能调优 | 默认并行度
Spark Sql默认并行度 看官网,默认并行度200 https://spark.apache.org/docs/2.4.5/sql-performance-tuning.html#other-configuration-options 优化 在数仓中 task最好是cpu的两倍或者3倍(最好是倍数,不要使基数) 拓展 在本地 task需要自己设置&a…...
Python-pptx教程之二操作已有PPT模板文件
文章目录 简单的案例找到要修改的元素修改幻灯片中的文本代码使用示例 修改幻灯片的图片代码使用示例 删除幻灯片代码使用示例 获取PPT中所有的文本内容获取PPT中所有的图片总结 在上一篇中我们已经学会了如何从零开始生成PPT文件,从零开始生成较为复杂的PPT是非常消…...

生活总是自己的,请尽情打扮,尽情可爱,,
同色系拼接羽绒服了解一下 穿上时尚感一下子就突显出来了 90白鸭绒填充,不仅时尚还保暖 设计感满满的羽绒服不考虑一下吗?...
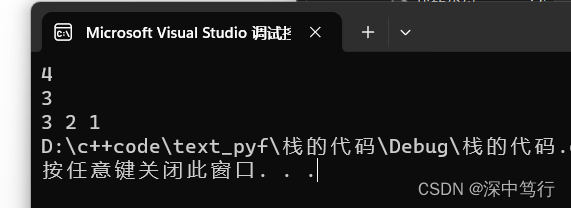
栈和队列的初始化,插入,删除,销毁。
目录 题外话 顺序表和链表优缺点以及特点 一.栈的特点 二. 栈的操作 2.1初始化 2.2 栈的销毁 2.3 栈的插入 2.3 输出top 2.4 栈的删除 2.5 输出栈 题外话 顺序表和链表优缺点以及特点 特点:顺序表,逻辑地址物理地址。可以任意访问,…...

重温《Unix设计哲学》
重温Unix设计哲学 这个世界是复杂的,但往往本质的东西都是简单的。这些原则,不光是用在程序开发,也适用于架构设计,产品设计等等地方。 简洁原则:以简洁为美 不要为了满足自己的虚荣心,企图搞一些花哨的东…...
AIGC创作系统ChatGPT源码,AI绘画源码,支持最新GPT-4-Turbo模型,支持DALL-E3文生图
一、AI创作系统 SparkAi创作系统是基于OpenAI很火的ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如…...

Spring条件注解@Conditoinal+ Profile环境切换应用@Profile
Spring条件注解 一、创建一个maven项目 <dependencies><dependency><groupId>org.springframework</groupId><artifactId>spring-context</artifactId><version>5.1.5.RELEASE</version></dependency> </dependenc…...

Scrum框架中的Sprint
上图就是sprint里要做的事。Sprint是scrum框架的核心,是所有的想法、主意转换为价值的地方。所有实现产品目标的必要工作都在sprint里完成,这些工作主要包括Sprint 计划(Sprint planning)、每日站会(Daily Scrum&#…...

openfeign、nacos获取接口提供方真实IP
源码分析 client 是 LoadBalancerFeignClient org.springframework.cloud.openfeign.ribbon.LoadBalancerFeignClient#execute public Response execute(Request request, Request.Options options) throws IOException {try {URI asUri URI.create(request.url());String c…...
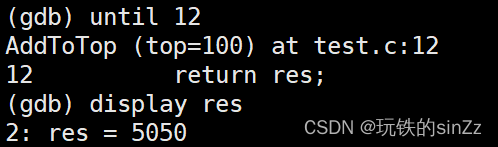
Linux系统编程学习 NO.9——git、gdb
前言 本篇文章简单介绍了Linux操作系统中两个实用的开发工具git版本控制器和gdb调试器。 git 什么是git? git是一款开源的分布式版本控制软件。它不仅具有网络功能,还是服务端与客户端一体的软件。它可以高效的处理程序项目中的版本管理。它是Linux内…...

【联邦学习+区块链】TORR: A Lightweight Blockchain for Decentralized Federated Learning
文章目录 I.CONTRIBUTIONII. ASSUMPTIONS AND THREAT MODELA. AssumptionsB. Threat Model III. SYSTEM DESIGNA. Design OverviewB. Block DesignC. InitializationD. Role SelectionE. Storage ProtocolF. Aggregation ProtocolG. Proof of ReliabilityH. Blockchain Consens…...

《网络协议》08. 概念补充
title: 《网络协议》08. 概念补充 date: 2022-10-06 18:33:04 updated: 2023-11-17 10:35:52 categories: 学习记录:网络协议 excerpt: 代理、VPN、CDN、网络爬虫、无线网络、缓存、Cookie & Session、RESTful。 comments: false tags: top_image: /images/back…...

利用NVIDIA DALI读取视频帧
1. NVIDIA DALI简介 NVIDIA DALI全称是NVIDIA Data Loading Library,是一个用GPU加速的数据加载和预处理库,可用于图像、视频和语音数据的加载和处理,从而为深度学习的训练和推理加速。 NVIDIA DALI库的出发点是,深度学习应用中…...

TSINGSEE青犀AI智能分析+视频监控工业园区周界安全防范方案
一、背景需求分析 在工业产业园、化工园或生产制造园区中,周界防范意义重大,对园区的安全起到重要的作用。常规的安防方式是采用人员巡查,人力投入成本大而且效率低。周界一旦被破坏或入侵,会影响园区人员和资产安全,…...
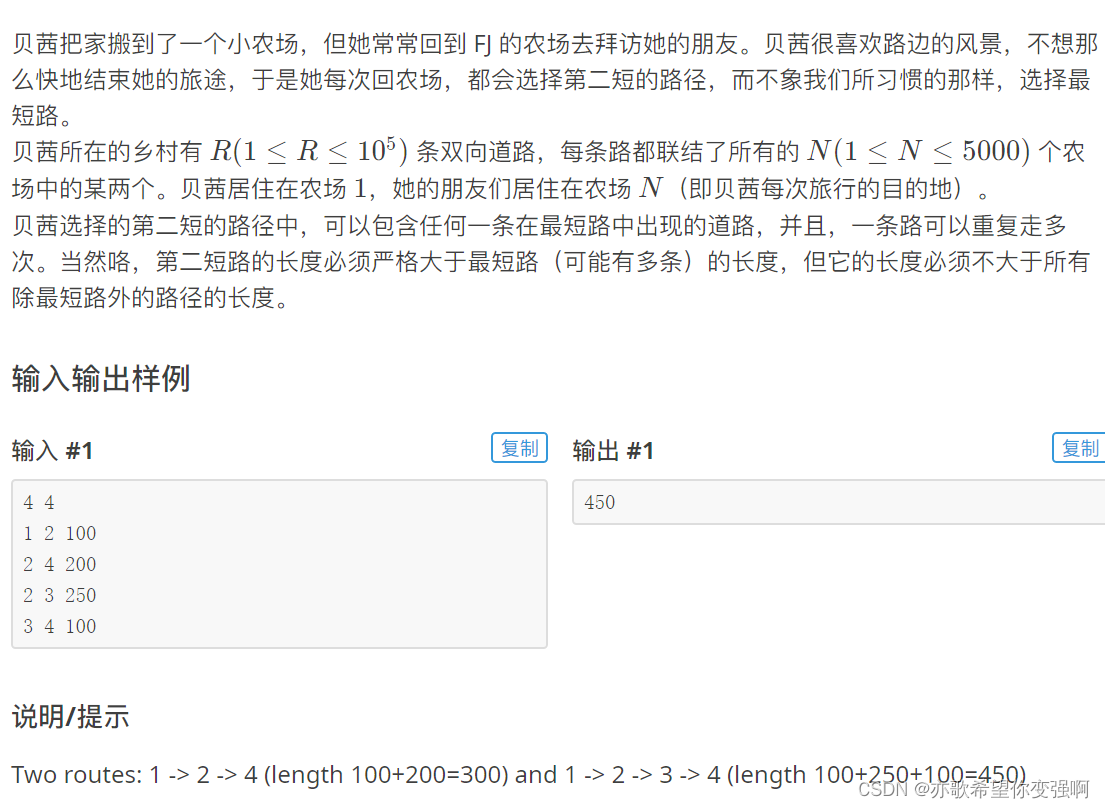
【算法每日一练]-图论(保姆级教程 篇5(LCA,最短路,分层图)) #LCA #最短路计数 #社交网络 #飞行路线 # 第二短路
今天讲最短路统计和分层图 目录 题目:LCA 思路: 题目:最短路计数 思路: 题目:社交网络 思路: 题目:飞行路线 思路: 题目:第二短路 思路: 题目&a…...
德迅云安全为您介绍关于抗D盾的一些事
抗D盾概述: 抗D盾是新一代的智能分布式云接入系统,接入节点采用多机房集群部署模式,隐藏真实服务器IP,类似于网站CDN的节点接入,但是“抗D盾”是比CDN应用范围更广的接入方式,适合任何TCP 端类应用包括&am…...

Blender-Armatures
导航 (返回顶部) 1. Blender-Armatures 1.1 骨架位置1.2 分类1.3 骨骼结构 2. 编辑 2.1 骨骼扭转2.2 拆分 split2.3 分离骨骼 separate2.4 切换方向 3. 镜像编辑 3.1 镜像挤出3.2 命名惯例3.3 对称 4. 属性 4.1 属性结构表4.2 柔性骨骼 Bendy Bones4.3 姿态4.4 关系 5. 骨骼约束…...

云原生安全新思路:基于DPU智能网卡的IPsec卸载实战,为K8s节点通信加密‘减负’
云原生安全新思路:基于DPU智能网卡的IPsec卸载实战 在Kubernetes集群中,节点间的网络通信安全一直是DevOps团队关注的焦点。传统IPsec加密方案虽然能有效保护数据传输,却不可避免地消耗大量主机CPU资源。当集群规模扩大时,这种加密…...

SOCD Cleaner:游戏按键智能优化工具,告别操作冲突的终极方案
SOCD Cleaner:游戏按键智能优化工具,告别操作冲突的终极方案 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 在竞技游戏和动作游戏中,精准的操作响应是胜利的关键。然而&…...

老板出幻觉了!过度相信 AI,迟早要暴雷…
不怕 AI 出幻觉,就怕用户出幻觉~ 对打工牛马来说,更怕老板出幻觉。①最近,某位后端童鞋忍不了,发帖吐槽公司老板/高层过度迷信“AI 全自动写代码”。他表示这会留下维护隐患,难出好产品…… 迟早完蛋。PS:你…...

统信UOS/麒麟KYLINOS用户看过来:除了Termius,这款开源免费的SSH工具electerm更香!
国产操作系统用户的SSH工具新选择:electerm深度体验报告 对于统信UOS和麒麟KYLINOS用户而言,远程服务器管理是日常工作中的高频需求。Termius作为老牌SSH工具确实表现不俗,但今天我们要探讨的electerm,或许能给你带来意想不到的惊…...
)
告别FPN信息瓶颈:手把手图解Gold-YOLO的‘聚合-分发’机制(附代码逐行解读)
告别FPN信息瓶颈:手把手图解Gold-YOLO的‘聚合-分发’机制(附代码逐行解读) 在目标检测领域,YOLO系列模型凭借其出色的实时性能一直占据主导地位。然而,随着应用场景的复杂化,传统特征金字塔网络ÿ…...
)
用STM32F103C8T6驱动总线舵机:手把手教你实现机械臂逆运动学(附完整代码)
STM32F103C8T6驱动总线舵机实现机械臂逆运动学全流程解析 第一次尝试用STM32控制机械臂时,看着六个关节不知如何协调运动,直到理解了逆运动学原理才豁然开朗。本文将带你从零实现一个基于STM32F103C8T6的四自由度机械臂控制系统,重点解决如何…...

收藏必备!VSCode 超详细入门教程 从安装到精通
系统下载 1、KALI安装版 https://pan.quark.cn/s/483c664db4fb 2、KALI免安装版 https://pan.quark.cn/s/23d4540a800b 3、下载所有Kali系统 https://pan.quark.cn/s/7d8b9982012f 4、KALI软件源 https://pan.quark.cn/s/33781a6f346d 5、所有Linux系统 https://pan.…...

探索罗技鼠标宏:掌握PUBG压枪技术的完整路径
探索罗技鼠标宏:掌握PUBG压枪技术的完整路径 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 在《绝地求生》这款竞技性极强的射击游戏…...

编写同城公益捐书物资登记流转程序,统计闲置书籍物资,对接公益捐赠渠道。
一个完全去营销化、偏工程与社会创新视角的 Python 示例项目,定位为创新与创业实验课程原型,不绑定任何公益平台、不引导捐赠渠道、不涉及任何机构背书,仅作为物资登记与流转建模工具。 同城公益捐书物资登记流转程序 ——基于物资生命周期管…...