2.Pandas数据预处理
2.1 数据清洗
以titanic数据为例。
df = pd.read_csv('titanic.csv')
2.1.1 缺失值
(1)缺失判断
df.isnull()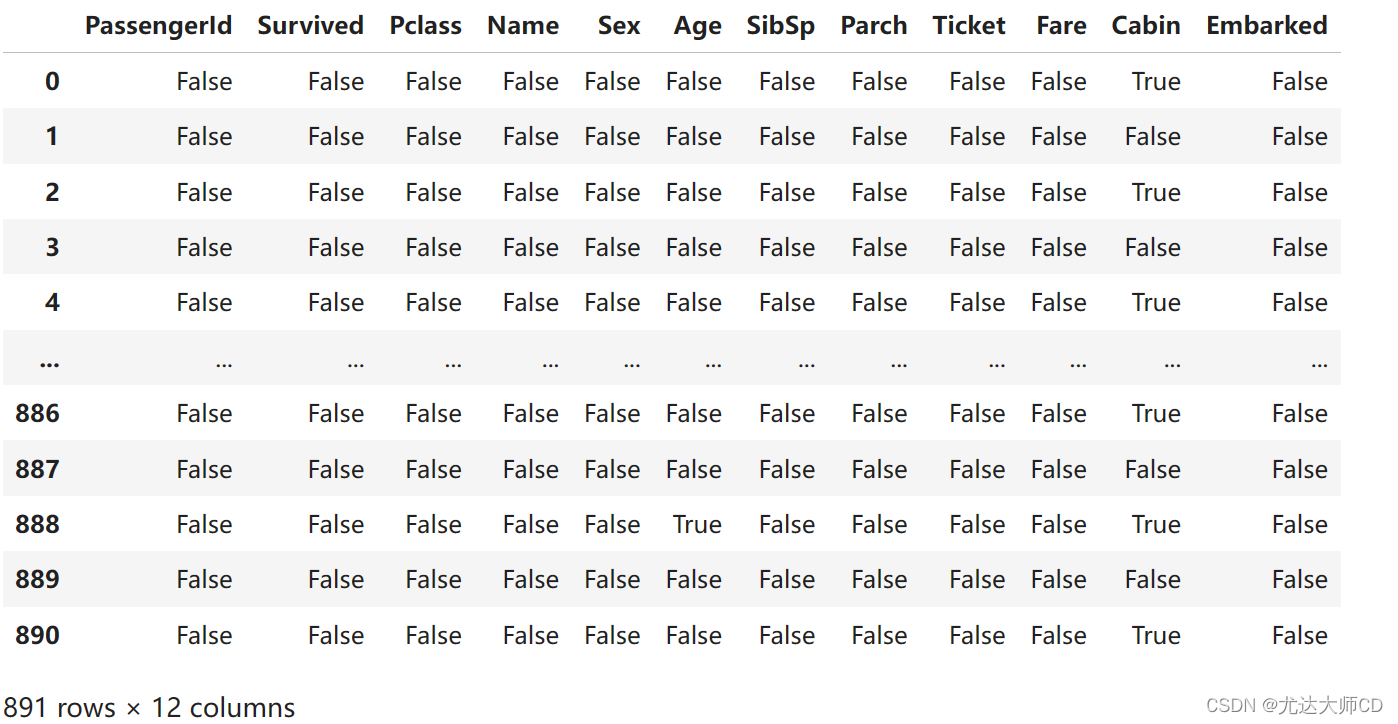
(2)缺失统计
# 列缺失统计
df.isnull().sum(axis=0)
# 行缺失统计
df.isnull().sum(axis=1)
# 统计缺失率
df.isnull().mean(axis=0)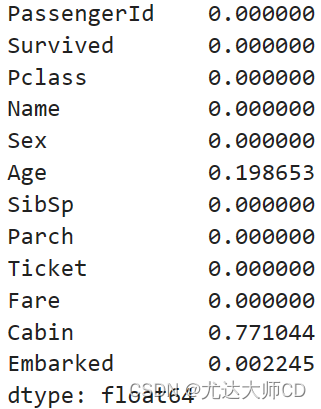
(3)缺失删除
# 删除有缺失值的行
df.dropna(axis=0)
# 删除有缺失值的列
df.dropna(axis=1)
# 删除至少有两个缺失值的行
df.dropna(thresh=2)
# 指定判断缺失值的列范围
df.dropna(subset=['Survived','Pclass'])
# 指定某列的缺失值删除
df['Sex'].dropna()(4)缺失筛选
# 筛选有缺失值的行
df.loc[df.isna().any(1)]
# 筛选有缺失值的列
df.loc[:,df.isna().any()]
# 查询没有缺失值的行
df.loc[~(df.isna().any(1))]
# 查询没有缺失值的列
df.loc[:,~(df.isna().any())] ### 筛选缺失率大于0.7的列
# 设置缺失率阈值
cutoff = 0.7
cond = df.isnull().mean(axis=0) > 0.7
# 缺失率>0.7的变量
drop_list = [k for k,v in cond.to_dict().items() if v==True]
# 缺失率<=0.7的变量
keep_list = [k for k,v in cond.to_dict().items() if v==False]
# 缺失率大于0.7的列
df[drop_list]
# 缺失率小于0.7的列
df[keep_list](5)缺失填充
### fillna()函数填充
# 将所有缺失值填充为0
df.fillna(0)
# 将缺失值填充为指定字符
df.fillna('x')
# 指定字段填充,此处用均值
df.Age.fillna(df['Age'].mean())
# 只替换一个 df.fillna(0, limit=1) ### replace()函数填充
# 将指定列的空值替换成指定值
df.replace({'Age':{np.nan:df['Age'].mean()}}) ### mask()函数替换
tc = df['Age'].mean()
cond = df['Age'].isnull()==True
df['Age'] = df['Age'].mask(cond, tc) ### interpolate()插值填充
df.Age.interpolate() #默认线性插值2.1.2 重复值
(1)重复查询
df.duplicated(subset=['name', 'birthday'], keep='first') # 按姓名和生日查询,除第一个重复值以外的其余重复值都被筛选出来(2)重复统计
# 对user列查重并统计重复数量
df.duplicated(subset=['user'], keep=False).sum(axis=0) # keep=False所有重复值都被筛选出来 # 对user列查重并统计重复率
df.duplicated(subset=['user'], keep=False).mean(axis=0)(3)重复删除
# 对全部列去重,在原数据frame上生效
df.drop_duplicates(inplace=True) # 对user列去重,在原数据frame上生效
df.drop_duplicated(subset=['user'], inplace=True) # 对user、hobby列去重,保留最后一个重复行
df.drop_duplicated(subset=['user','hobby'],keep='last',inplace=True)(4)索引重置
# 索引重置
df.drop_duplicates(subset=['user'],keep='first').reset_index(drop=True)(5)先排序再去重
当重复数据有排序行时,一定要对数据排序后在进行去重处理。
# 排序
df = df.sort_values(by=['user','price'],ascending=True).reset_index(drop=True) # 去重
df = df.drop_duplicated(subset=['user'],keep='first').reset_index(drop=True)2.1.3 数据替换
(1)loc/iloc赋值
# 第1行第3列的数据替换为4
df.iloc[0:1,2:3] = 4 # 将Age均值替换空值
df.loc[(df['Age'].isnull()==True), 'Age'] = df['Age'].mean() # 将Pclass3以上替换为'3+'
df['Pclass'] = df['Pclass'].astype(str) df.loc[(df['Pclass']>=3), 'Pclass'] = '3+'(2)replace替换
### 指定值替换
# 数值替换
s.replace(to_replace=0, value=5)
# 字符替换
df.replace(to_replace='S', value='C')
# 空值替换
df.replace(to_replace='.', value=np.nan)
# 列表一一替换
df.replace(to_replace=[0,1,2,3,4], value=[4,3,2,1,0])
# to_replace为字典时
s.replace(to_replace={0:10, 1:100}) # 此时按字典映射进行替换,value不再指定替换值 df.replace(to_replace={'Age':0.42,'Pclass':2}, value=18) # 此时字典键为列名,值为被替换值,value为替换值
df = df.replace(to_replace={'Age':{0.42,18, 0.67:18}}) # 作为嵌套字典,指定将某列中的具体数据按字典映射替换,value不再指定替换值 ### method替换
# 将1,2 替换为它们前一个值
s.replace([1,2], method='ffill')
# 将1,2替换为它们后一个值
s.replace([1,2], method='bfill') ### 正则表达式替换
# 将Futrelle开头的值替换为FAA
df.replace(to_replace=r'^Futrelle.*',value='FAA',regex=True)
# 多个规则均替换为同样的值
df.replace(regex=[r'^Futrelle.*', r'Braund.*'], value='FAA').head()
# 多个正则级对应的替换内容
df.replace(regex={r'^Futrelle.*':'FAA', r'^Braund.*':'BAA'})2.2 文本处理
主要是针对series.str.func的应用。
2.2.1 文本格式
(1)大小写变换
# 字符全部变成小写
s.str.lower()
# 字符全部大写
s.str.upper()
# 每个单词首字母大写
s.str.title()
# 字符串第一个字母大写
s.str.capitalize()
# 大小写字母转换
s.str.swapcase()(2)格式判断
s.str.isalpha # 是否为字母
s.str.isnumeric # 是否为数字0-9
s.str.isalnum # 是否由字母和数字组成
s.str.isupper # 是否为大写
s.str.islower # 是否为小写
s.str.isdigit # 是否为数字(3)文本对齐
# 居中对齐,宽度为8,其余用*填充
s.str.center(8, fillchar='*')
# 左对齐,宽度为8,其余用*填充
s.str.ljust(8, fillchar='*')
# 右对齐,宽度为8,其余用*填充
s.str.rjust(8, fillchar='*')
# 自定义对齐方式,参数可调整宽度,对齐方向,填充字符
s.str.pad(width=8, side='both', fillchar='*')(4)计数编码
s.str.count('b') # 字符串中包括指定字母的数量
s.str.len() # 字符串长度
s.str.encode('utf-8') # 字符编码
s.str.decode('utf-8') # 字符解码2.2.2 文本拆分
# 使用方法
s.str.split('x', n=1)
# 举例
df.Email.str.split('@')
# expand=True 可以让拆分的内容扩展成单独一列
df.Email.str.split('@', expand=True)
# 同时通过@和.进行拆分成三部分
df.Email.str.split('@|\.', expand=True)2.2.3 文本替换
(1)replace替换
# 将email种的com都替换为cn
df.Email.str.replace('com', 'cn')# 将@之前的名字都替换为xxx
df.Email.str.replace('(.*?)@', 'xxx@')# 将替换内容传递给lambda隐函数实现字符大写功能
df.Email.str.replace('(.*?)@', lambda x:x.group().upper())(2)切片替换
df.Email.str.slice_replace(start=1, stop=2, repl='XX')(3)重复替换
df.name.str.repeat(repeats=2)2.2.4 文本拼接
(1)单Series序列拼接
# name列series直接拼接
df.name.str.cat()# 设置sep分隔符为'-'
df.name.str.cat(sep='-')# 将缺失值设置为*
df.name.str.cat(sep='-', na_rep='*')(2)多series序列拼接
# 设置others后,cat会将series和others定义的序列进行拼接
df.name.str.cat(others=['*']*6)# 多列拼接
df.name.str.cat([df.Email, df.level], sep='-', na_rep='*')2.2.5 文本提取
# extrac
df.Email.extract(pat='(,*?)@(.*).com')# extractall多返回一列match
df.Email.extractall(pat='(,*?)@(.*).com')2.2.6 文本查询
### find:返回原字符串的位置,没有返回-1
df.Email.str.find('@')### findall:支持正则表达式
df.Email.str.findall('(,*?)@(.*).com')2.2.7 文本包含
配合loc用于查询。
df.loc[df.Email.str.contains('com|Mike', na=False)]2.2.8 文本哑变量
df.name.str.get_dummies()2.3 时间处理
2.3.1 时间类型
| Timestamp | 最基础的时间类,表示某个确切的时间点。在绝大多数的场景中的时间数据都是Timestamp形式的事件类型 |
| Period | 表示单个时间跨度,或者某个时间段,例如某一天,某一小时等。 |
| Timedelta | Timedelta表示不同单位的时间,例如1天、1.5小时、3分钟、4秒等,并非具体的某个时间段。 |
| DatetimeIndex | 一组Timestamp构成的index |
| PeriodtimeIndex | 一组Period构成的index |
| TimedeltaIndex | 一组Timedelta构成的index |
### 创建方式
# 时间戳创建
pd.Timestamp(1990,1,1)# 时间差创建
pd.Timedelta('1days 1minute')# 时间周期创建
pd.Period(2023, freq='M')2.3.2 时间类型转换
(1)to_datetime
df = pd.to_datetime(df)
df['a'] = pd.to_datetime(df['a'], format='%Y.%m.%d')(2)to_timedelta
pd.to_timedelta(['1days 1minute', '2days 2minute'])2.3.2 时间类型属性
(1)Timestamp
可以实现时间信息的提取、判断、格式变换。
# 属性
s.dt.date # 转换为object类型的日期
s.dt.year
s.dt.quarter # 季节
s.dt.month
s.dt.hour
s.dt.minute
s.dt.second
s.dt.nanosecond # 纳秒
s.dt.weekday # 工作日第几天
s.dt.day # 一个月当中的第几日
s.dt.day_of_week # 一周中第几天
s.dt.day_of_year # 一年中第几天
s.dt.dayofweek
s.dt.dayofyear
s.dt.days_in_month # 时间所在月份总天数
s.dt.daysinmonth
s.dt.is_month_start # 是否为月初
s.dt.is_month_end # 是否为月末
s.dt.is_quarter_start # 是否为季度第一天
s.dt.is_quarter_end # 是否为季度最后一天
s.dt.is_year_start
s.dt.is_year_end
s.dt.is_leap_year # 是否为闰年
s.dt.time # 获取时分秒的具体时间
s.dt.timetz # 获取时分秒的具体时间+时区
s.dt.freq # 频率
s.dt.unit # 时间最小单位# 函数
s.dt.as_unit('s') # 转换最小单位精度
s.dt.ceil(freq='d') # 按指定频率向上取整
s.dt.floor(freq='d') # 按指定频率向下取整
s.dt.round(freq='d') # 按指定频率四舍五入
s.dt.day_name() # 时间对应的星期数,英文字符串
s.dt.month_name() # 时间对应的月份,英文字符串
s.dt.normalize() # 时间转换到midnight半夜
s.dt.strftime(date_format='%Y-%M-%D') # 转换时间格式,转换后对象为object
s.dt.isocalendar() # 日历函数,返回三个字段:年、一年中第几周、一周中第几天
s.dt.to_period() # 转换为period类型
s.dt.to_pydatetime() # 以numpy array形式返回Python中定义的时间差类型对象(2)TimeDelta
# 函数
s.dt.as_unit('s') # 转换最小单位精度
s.dt.ceil(freq='d') # 按指定频率向上取整
s.dt.floor(freq='d') # 按指定频率向下取整
s.dt.round(freq='d') # 按指定频率四舍五入
s.dt.day_name() # 时间对应的星期数,英文字符串
s.dt.month_name() # 时间对应的月份,英文字符串
s.dt.normalize() # 时间转换到midnight半夜
s.dt.strftime(date_format='%Y-%M-%D') # 转换时间格式,转换后对象为object
s.dt.isocalendar() # 日历函数,返回三个字段:年、一年中第几周、一周中第几天
s.dt.to_period() # 转换为period类型
s.dt.to_pydatetime() # 以numpy array形式返回Python中定义的时间差类型对象# 函数
s.dt.as_unit('s') # 转换最小单位精度
s.dt.ceil(freq='d') # 按指定频率向上取整
s.dt.floor(freq='d') # 按指定频率向下取整
s.dt.round(freq='d') # 按指定频率四舍五入
s.dt.to_pytimedelta() # 以numpy array形式返回Python中定义的时间差类型对象# 将时间差的成分进行分解,并转化为具体的数值
s.dt.components# 转换为以秒单位的数值
s.dt.total_seconds()(3)Period
# 属性
df.dt.day # 每个周期的天数
df.dt.day_of_week # 一周中的第几天
df.dt.day_of_year # 一年中的第几天
df.dt.dayofweek
df.dt.dayofyear
df.dt.days_in_month # 一月中的第几天
df.dt.daysinmonth
df.dt.start_time # 一个周期的开始时间
df.dt.end_time # 一个周期的结束时间
df.dt.is_leap_year # 所在年是否为闰年
df.dt.freq # 频率
df.dt.year # 时间所在年
df.dt.quarter # 时间所在季节
df.dt.month
df.dt.week
df.dt.hour
df.dt.weekday # 时间所在一周中的第几天
df.dt.weekofyear # 时间在一年中的第几周# 函数
df.dt.to_timestamp() # 转换为时间戳类型
df.dt.asfreq(freq='Q') # 改变周期频率为季度
df.dt.striftime(date_format='%Y-%m-%d') # 改变时间格式相关文章:
2.Pandas数据预处理
2.1 数据清洗 以titanic数据为例。 df pd.read_csv(titanic.csv) 2.1.1 缺失值 (1)缺失判断 df.isnull() (2)缺失统计 # 列缺失统计 df.isnull().sum(axis0) # 行缺失统计 df.isnull().sum(axis1) # 统计缺失率 df.isnu…...

C# IEnumerable<T>介绍
IEnumerable 是 C# 中的一个接口,它是 .NET Framework 中的集合类型的基础。任何实现了 IEnumerable 接口的对象都可以进行 foreach 迭代。 IEnumerable 只有一个方法,即 GetEnumerator,该方法返回一个 IEnumerator 对象。IEnumerator 对象用…...

九洲
《九洲》 作者/罗光记 九洲春色映朝阳, 洲渚风光似画廊。 柳絮飘飞花似雪, 九州繁华共锦裳。 水波荡漾鱼儿跃, 洲边鸟语唤晨光。 春风拂过千里岸, 九洲儿女笑语扬。...

基于Genio 700 (MT8390)芯片的AR智能眼镜方案
AR眼镜是一种具有前所未有发展机遇的设备,无论是显示效果、体积还是功能都有明显的提升。AR技术因其智能、实时、三维、多重交互和开放世界的特点备受关注。 AR眼镜集成了AR技术、语音识别、智能控制等多项高科技功能,可以帮助用户实现更加便捷、高效、个…...
锐捷OSPF认证
一、知识补充 1、基本概述 OSPF区域认证和端口认证是两种不同的认证机制,用于增强OSPF协议的安全性。 OSPF区域认证(OSPF Area Authentication):这种认证机制是基于区域的。在OSPF网络中,每个区域都可以配置一个区域…...

M2 Mac Xcode编译报错 ‘***.framework/‘ for architecture arm64
In /Users/fly/Project/Pods/YYKit/Vendor/WebP.framework/WebP(anim_decode.o), building for iOS Simulator, but linking in object file built for iOS, file /Users/fly/Project/Pods/YYKit/Vendor/WebP.framework/WebP for architecture arm64 这是我当时编译模拟器时报…...

Python算法题2023 输出123456789到98765432中完全不包含2023的数有多少
题目: 无输入,只需输出结果🤐 这个数字比较大,小伙伴们运行的时候要给代码一点耐心嗷つ﹏⊂ ,下面是思路,代码注释也很详细,大致看一下吧(^∀^●)…...
SpringBoot整合Thymeleaf
Thymeleaf 支持 HTML 原型,可以让前端工程师在浏览器中直接打开查看样式,也可以让后端工程师结合真实数据查看显示效果 Thymeleaf 除了展示基本的 HTML ,进行页面渲染之外,也可以作为一个 HTML 片段进行渲染,例如我们在…...

OpenAI的多函数调用(Multiple Function Calling)简介
我在六月份写了一篇关于GPT 函数调用(Function calling) 的博客https://blog.csdn.net/xindoo/article/details/131262670,其中介绍了函数调用的方法,但之前的函数调用,在一轮对话中只能调用一个函数。就在上周,OpenAI…...
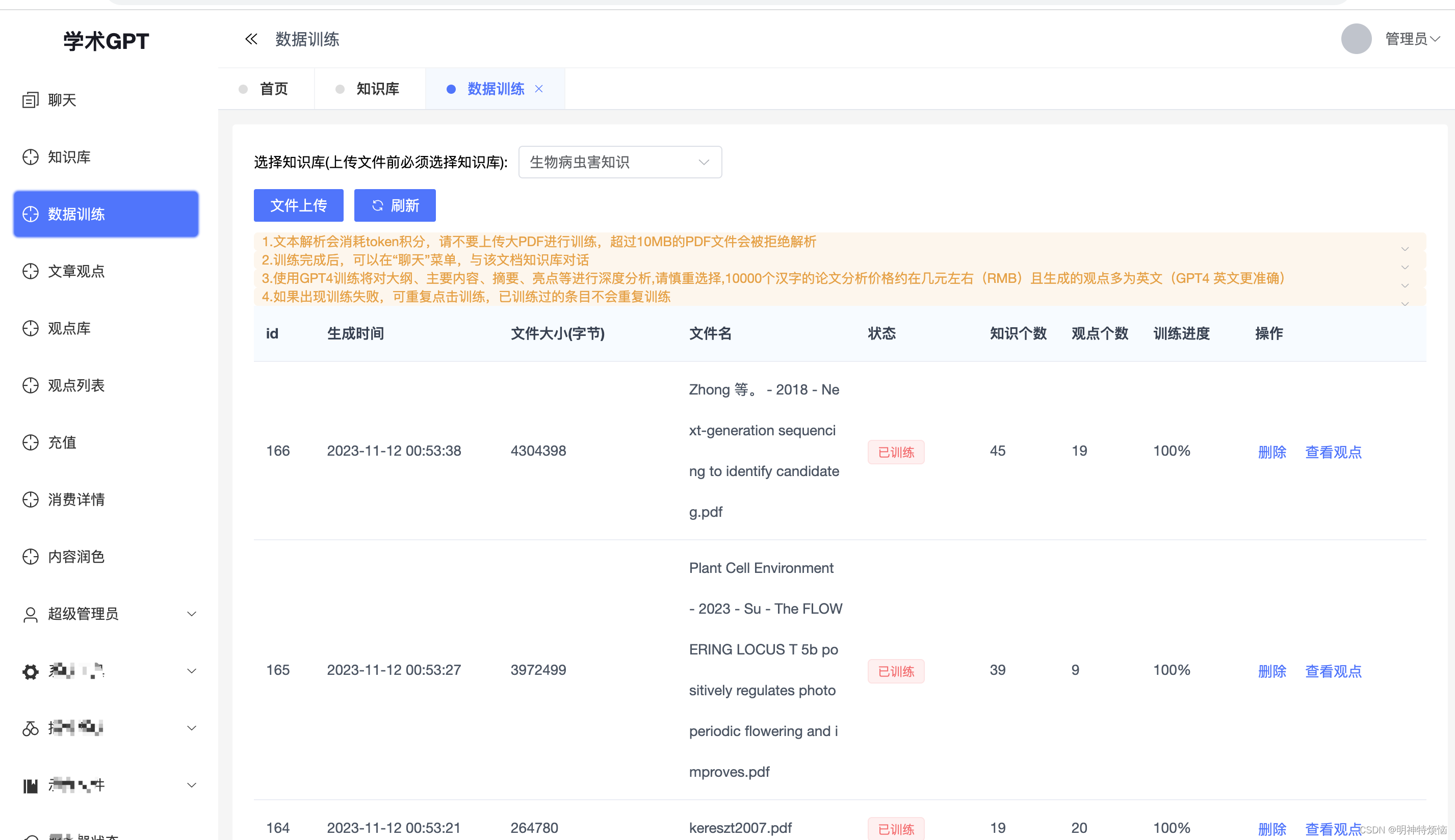
在国内购买GPT服务前的一定要注意!!!
本人已经入坑GPT多日,从最开始的应用GPT到现在的自己研发GPT,聊聊我对使用ChatGPT的一些思考,有需要使用GPT的朋友或者正在使用GPT的朋友,一定要看完这篇文章,可能会比较露骨,也算是把国内知识库、AI的套路…...
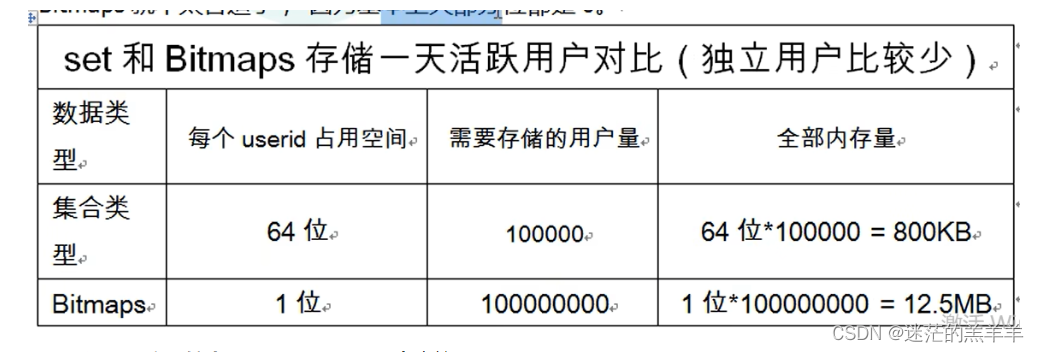
Redis新操作
1.Bitmaps 1.1概述 Bitmaps可以对位进行操作,实际上它就是一个字符串,可以将Bitmaps想象为一个以位为单位的数组,数组中的每个元素只能存储0或者1,数组的下标在Bitmaps被称为偏移量。 setbit key offset value:设置o…...

Panda3d 外部硬件接口介绍
Panda3d 外部硬件接口介绍 文章目录 Panda3d 外部硬件接口介绍键盘支持(Keyboard Support)轮询接口击键事件原始键盘事件鼠标支持(Mouse Support)鼠标模式绝对鼠标模式相对鼠标模式受限鼠标模式验证鼠标模式多个鼠标(Multiple Mice )Linux 下的多个鼠标(Multiple Mice u…...
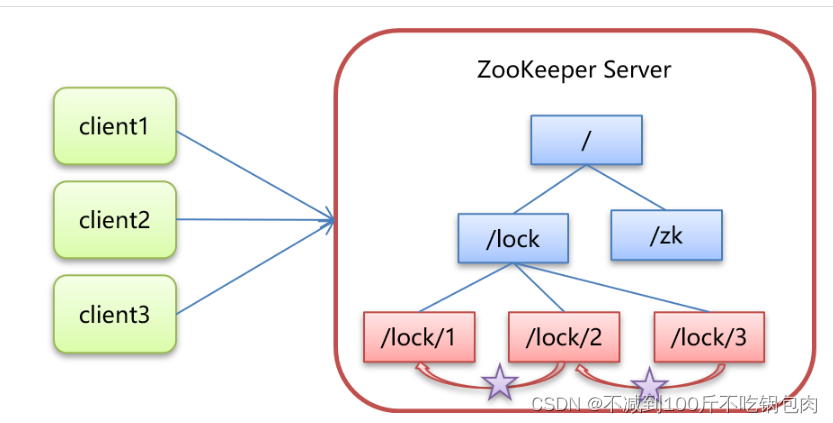
解决Redis分布式锁宕机出现不可靠问题-zookeeper分布式锁
核心思想:当客户端要获取锁,则创建节点,使用完锁,则删除该节点。 客户端获取锁时,在 lock 节点下创建临时顺序节点。然后获取 lock下面的所有子节点,客户端获取到所有的子节点之后,如果发现自己…...
mac系统安装docker desktop
Docker的基本概念 Docker 包括三个基本概念: 镜像(Image):相当于是一个 root 文件系统。比如官方镜像 ubuntu:16.04 就包含了完整的一套 Ubuntu16.04 最小系统的 root 文件系统。比如说nginx,mysql,redis等软件可以做成一个镜像。容器&#…...

【机器学习基础】机器学习的基本术语
🚀个人主页:为梦而生~ 关注我一起学习吧! 💡专栏:机器学习 欢迎订阅!后面的内容会越来越有意思~ 💡往期推荐: 【机器学习基础】机器学习入门(1) 【机器学习基…...

区别Vue 2.0 和 Vue 3.0
Vue 3.0 是在 Vue 2.0 的基础上进行了重大的更新和改进。下面列举了一些主要的区别: 性能优化 Proxy 取代 Object.defineProperty:Vue 3.0 中使用 Proxy 监听数据的变化,相比 Vue 2.0 使用 Object.defineProperty,性能有所提升。…...

react antd下拉选择框选项内容换行
下拉框选项字太多,默认样式是超出就省略号,需求要换行全展示,选完在选择框里还是要省略的 .less: .aaaDropdown {:global {.ant-select-dropdown-menu-item {white-space: pre-line !important;word-break: break-all !important;}} } html…...

图像分类(一) 全面解读复现AlexNet
解读 论文原文:http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf Abstract-摘要 翻译 我们训练了一个庞大的深层卷积神经网络,将ImageNet LSVRC-2010比赛中的120万张高分辨率图像分为1000个不…...

JAXB实现XML和Bean相互转换
目录 XML和Bean转换工具简介JAXB简介Java Bean类XMLUtil工具类 另一篇转换方式 xstream实现xml和java bean 互相转换 XML和Bean转换工具简介 Java中实现XML和Bean的转换的方式或插件有以下几种: JAXB(Java Architecture for XML Binding)&…...

视频剪辑技巧:简单步骤,批量剪辑并随机分割视频
随着社交媒体平台的广泛普及和视频制作需求的急剧增加,视频剪辑已经成为了当今社会一项不可或缺的技能。然而,对于许多初学者来说,视频剪辑可能是一项令人望而生畏的复杂任务。可能会面临各种困难,如如何选择合适的软件和硬件、如…...

终极LXMusic音源配置指南:三步解决全网音乐播放难题
终极LXMusic音源配置指南:三步解决全网音乐播放难题 【免费下载链接】LXMusic音源 lxmusic(洛雪音乐)全网最新最全音源 项目地址: https://gitcode.com/guoyue2010/lxmusic- 你是否经常遇到音乐软件资源不全、音质不佳的问题ÿ…...

LeetCode IPO问题题解
LeetCode IPO问题题解 题目描述 给定初始资本 w,最多完成 k 个项目。每个项目有利润和最低资本要求。找到能够获得的最大资本。 示例: 输入:capital [0,1,2,3], profits [1,2,3,5], k 2, w 0输出:4 解题思路 方法&#…...

DouZero AI斗地主助手:基于深度学习的终极实战指南
DouZero AI斗地主助手:基于深度学习的终极实战指南 【免费下载链接】DouZero_For_HappyDouDiZhu 基于DouZero定制AI实战欢乐斗地主 项目地址: https://gitcode.com/gh_mirrors/do/DouZero_For_HappyDouDiZhu 还在为欢乐斗地主的复杂决策而烦恼吗?…...

Windows风扇控制终极方案:从噪音困扰到静音高效的完整实战指南
Windows风扇控制终极方案:从噪音困扰到静音高效的完整实战指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Tre…...
)
ROS Melodic下用Mapviz+天地图API显示GPS轨迹(保姆级避坑指南)
ROS Melodic下Mapviz与天地图API的高精度GPS轨迹可视化实战 在机器人定位与导航开发中,将GPS轨迹叠加到卫星地图上是验证算法效果的基础需求。对于国内开发者而言,直接使用Google Maps等国际服务常面临访问限制和偏移问题。本文将深入讲解如何在ROS Mel…...

深入UE渲染管线:从.usf文件到FGlobalShader,理解全局Shader的完整生命周期与最佳实践
深入UE渲染管线:从.usf文件到FGlobalShader,理解全局Shader的完整生命周期与最佳实践 当我们需要在Unreal Engine中实现一个全新的后处理效果或定制底层渲染管线时,全局Shader(Global Shader)往往是必经之路。与材质编…...

从数据备份到模型部署:深入理解Numpy的.npy/.npz文件在机器学习流水线中的角色
从数据备份到模型部署:深入理解Numpy的.npy/.npz文件在机器学习流水线中的角色 在机器学习项目的完整生命周期中,数据的高效存储与快速读取往往是决定工程效率的关键因素之一。当我们谈论数据处理工具时,Numpy无疑是Python生态中不可忽视的核…...

Pearcleaner:Mac应用彻底清理的终极解决方案,告别数字垃圾困扰
Pearcleaner:Mac应用彻底清理的终极解决方案,告别数字垃圾困扰 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 还在为Mac应用卸载后残…...
)
【例题2】The XOR Largest Pair(信息学奥赛一本通- P1472)
【题目描述】在给定的 N 个整数 A1,A2,…,AN 中选出两个进行异或运算,得到的结果最大是多少?【输入】第一行一个整数 N。第二行 N 个整数 Ai 。【输出】一个整数表示答案。【输入样例】5 2 9 5 7 0【输出样例】14【提示】对于 100% 的数据࿰…...

每天节省25分钟!淘宝淘金币全自动任务脚本终极指南
每天节省25分钟!淘宝淘金币全自动任务脚本终极指南 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/ta/taojinbi 你是否厌…...