目录自动清洗
文章目录
- 前言
- 一、需求分析
- 二、操作步骤详解(标准章节)
- 1. 提取文章目录
- 2. 更改保存目录.txt
- 3. 二级标题前面加4个空格
- 4. 在章字和节字后面添加一个空格
- 5. 在页码前面加上=>符号
- 6. 代码完全体
- 三、进阶一(有章无节+小数二级标题)
- 1. 二级标题前面加4个空格
- 2. 在标题里面添加一个空格
- 3. 在页码前面加上=>符号
- 4. 去除=>符号和汉字之间的冗余符号
- 5. 删除空行
- 6. 代码完全体
- 7. 进阶说明
- 拓展与补充
- 1. content = file.read() 与 lines = file.readlines() 读取文件的区别
- 总结
前言
为了巩固所学的知识,作者尝试着开始发布一些学习笔记类的博客,方便日后回顾。当然,如果能帮到一些萌新进行新技术的学习那也是极好的。作者菜菜一枚,文章中如果有记录错误,欢迎读者朋友们批评指正。
(博客的参考源码可以在我主页的资源里找到,如果在学习的过程中有什么疑问欢迎大家在评论区向我提出)
一、需求分析

1. 这是一个标准的章节目录,我们需要保留目录的前两级标题,也就是包含章和节字的标题
2. 需要在二级标题所在行最前面空4个格子,一级标题不用
3. 需要在章和节字的后面加上一个空格
4. 需要在页码前面加上=>符号
5. 示例效果如下:

二、操作步骤详解(标准章节)
1. 提取文章目录
1. 图片识别文字提取文章目录
http://183.62.34.62:8004/docs#/defaul/text_detection_text_system_analysis_menus__post
2. 使用方法
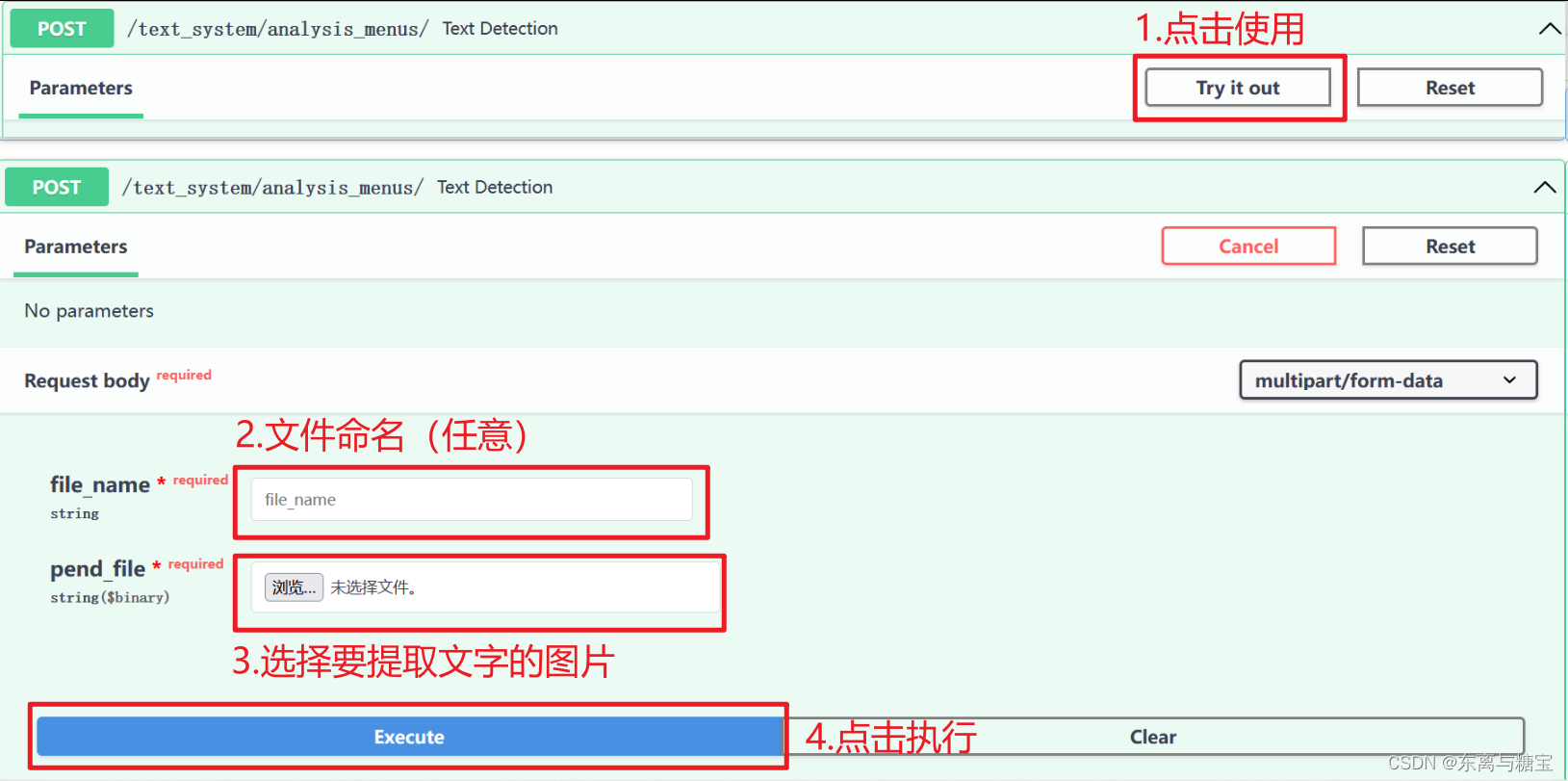
3. 识别示例
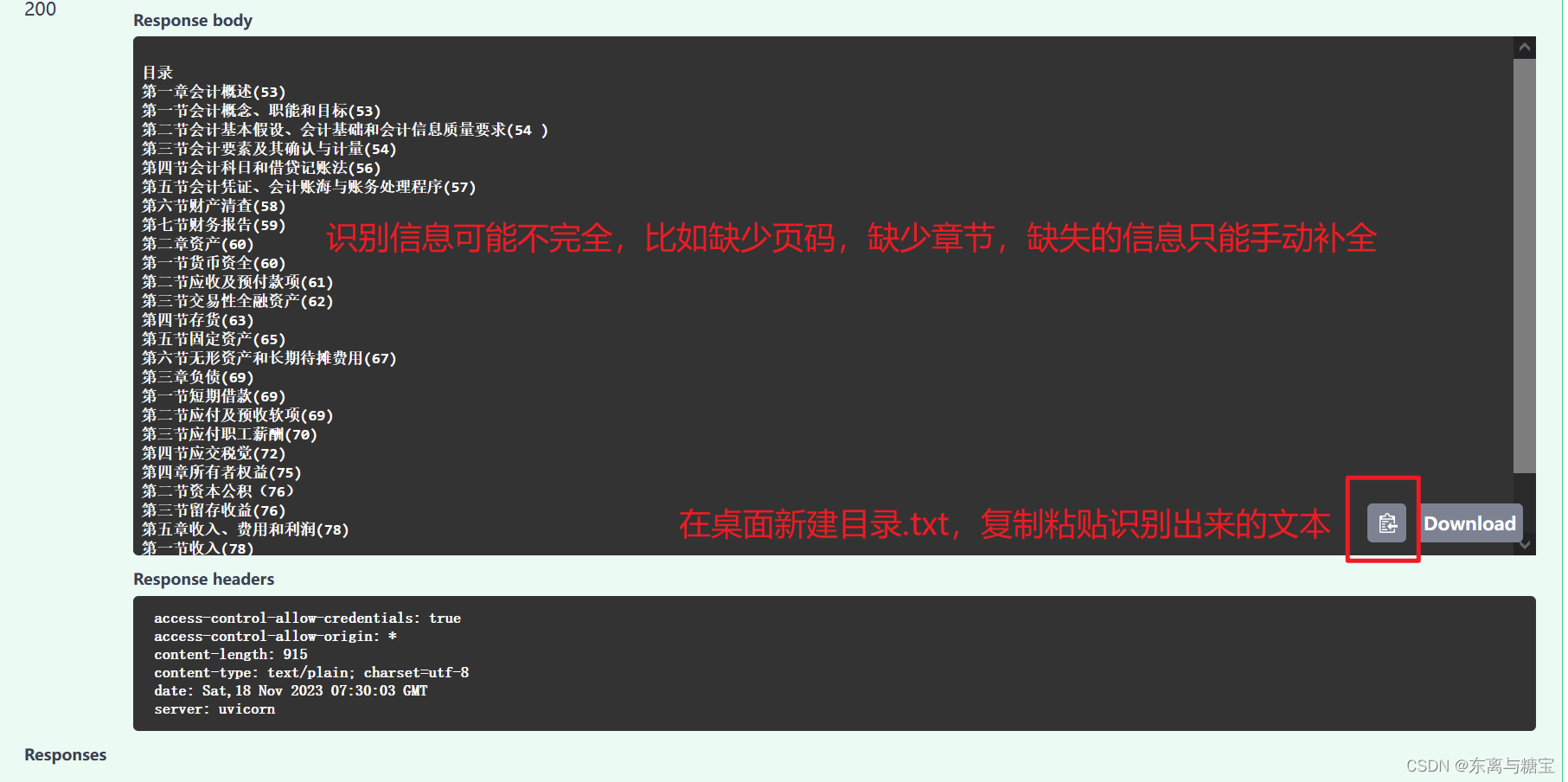
2. 更改保存目录.txt
你可以使用Python中的open函数来打开文件,read方法读取文件内容,然后对内容进行修改,最后使用write方法将修改后的内容写回文件。以下是一个简单的例子:
import os
# 获取桌面路径
desktop_path = os.path.join(os.path.expanduser("~"), "Desktop")# 目标文件路径
file_path = os.path.join(desktop_path, "目录.txt")# 打开文件并读取内容
with open(file_path, 'r', encoding='utf-8') as file:content = file.read()# 修改内容(这里只是一个简单的例子)
modified_content = content.replace('章', '章666')# 将修改后的内容写回文件
with open(file_path, 'w', encoding='utf-8') as file:file.write(modified_content)
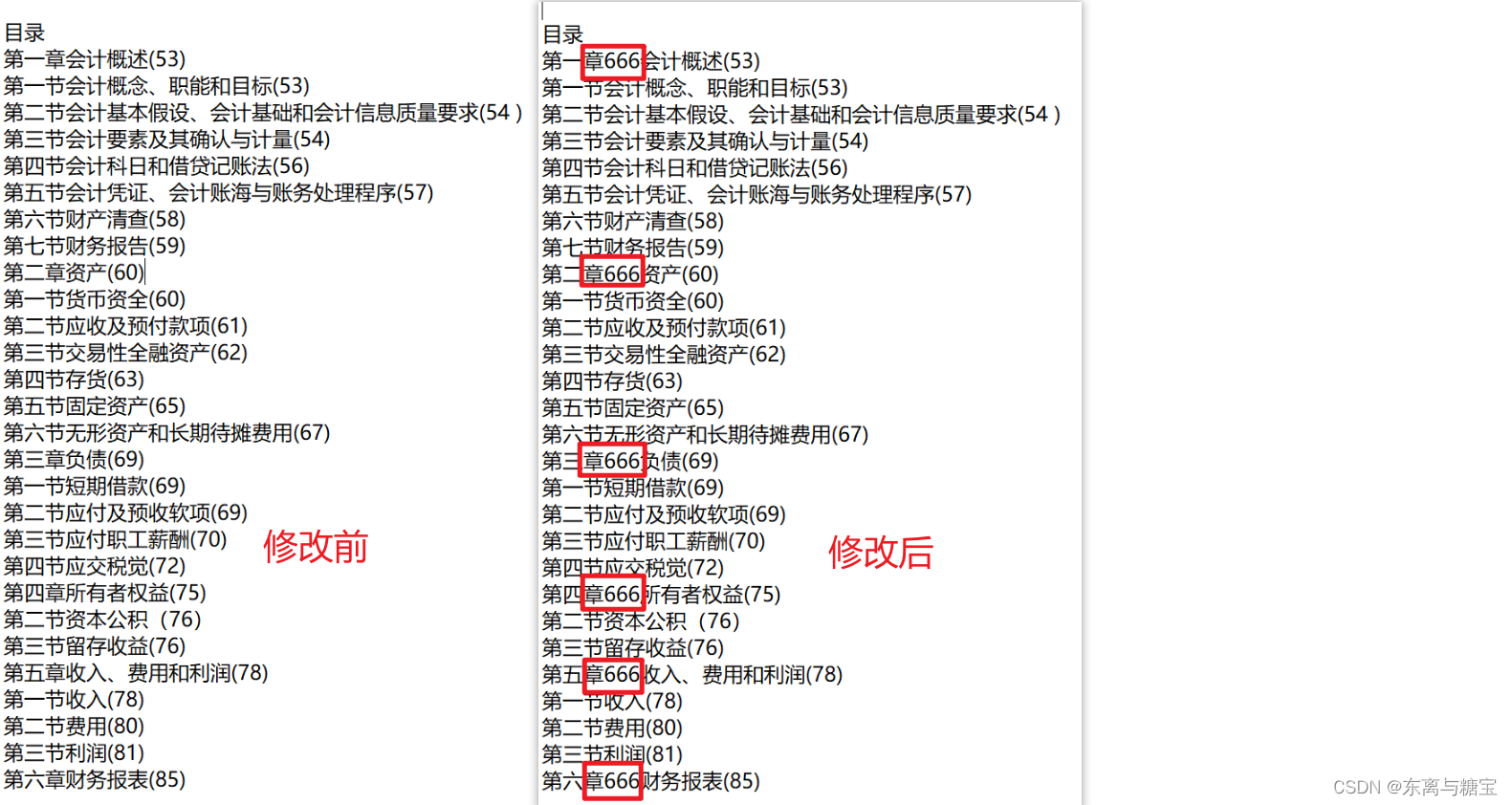
请确保你有足够的权限读取和写入文件。此外,这只是一个简单的例子,如果需要进行更复杂的操作,可以使用正则表达式或其他处理方式来实现。
3. 二级标题前面加4个空格
# 去除空格line = line.replace(" ", "")if '节' in line:# 二级标题添加4个空格line = ' ' * 4 + line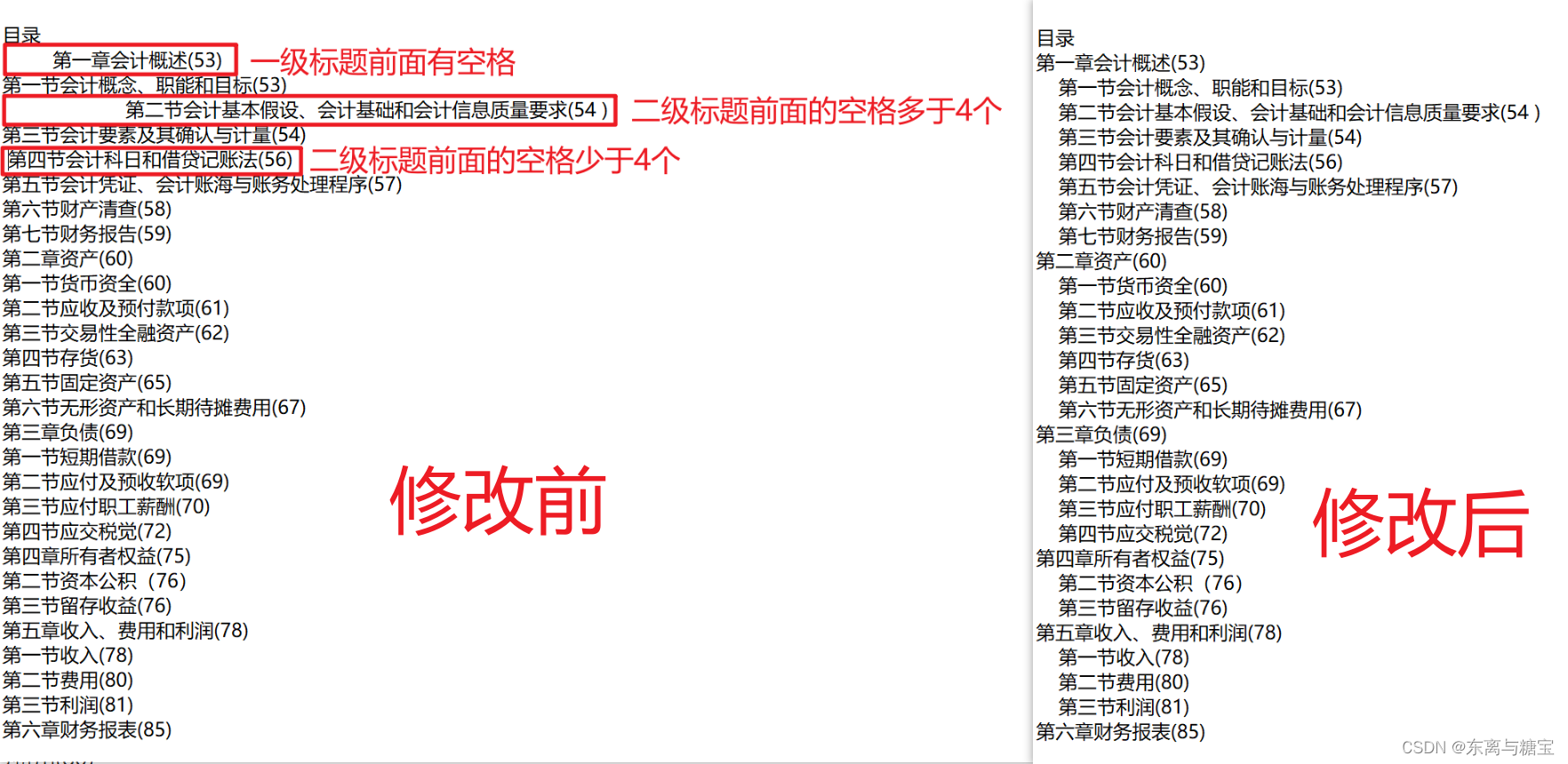
lstrip(' ') 是 Python 字符串方法,用于删除字符串开头(左侧)的指定字符。在这里,' ' 表示空格字符。
4. 在章字和节字后面添加一个空格
# 使用正则表达式在'章'或'节'后面添加一个空格line = re.sub(r'(章|节)(?![ ])', r'\1 ', line)
5. 在页码前面加上=>符号
# 匹配并去除最外层的英文括号pattern_en = r'\(([\d\s]+)\)'line = re.sub(pattern_en, r'\1', line)# 匹配并去除最外层的中文括号及其内部内容(包括空格)pattern = r'(([^)]+))'line = re.sub(pattern, r'\1', line)line = line.replace(" ", "")# 确保每行只有一个 =>if '=>' not in line:# 在每行数字前加上 =>line = re.sub(r'(\d+)', r'=>\1', line)
6. 代码完全体
# 获取桌面路径
import os
import redesktop_path = os.path.join(os.path.expanduser("~"), "Desktop")# 目标文件路径
file_path = os.path.join(desktop_path, "目录.txt")# 打开文件并读取内容
with open(file_path, 'r', encoding='utf-8') as file:lines = file.readlines()modified_lines = []
for line in lines:# 去除空格line = line.replace(" ", "")# 匹配并去除最外层的英文括号pattern_en = r'\(([\d\s]+)\)'line = re.sub(pattern_en, r'\1', line)# 匹配并去除最外层的中文括号及其内部内容(包括除数字和空格以外的字符)pattern = r'(([^)]+))'line = re.sub(pattern, r'\1', line)# 确保每行只有一个 =>if '=>' not in line:# 在每行数字前加上 =>line = re.sub(r'(\d+)', r'=>\1', line)# 使用正则表达式在'章'或'节'后面添加一个空格line = re.sub(r'(章|节)(?![ ])', r'\1 ', line)if '节' in line:# 二级标题添加4个空格line = ' ' * 4 + linemodified_lines.append(line)
# 将修改后的内容写回文件
with open(file_path, 'w', encoding='utf-8') as file:file.writelines(modified_lines)# 读取文件内容
with open(file_path, 'r', encoding='utf-8') as file:content = file.read()print(content)三、进阶一(有章无节+小数二级标题)

1. 二级标题前面加4个空格
如果章字不在行内,则初步认定他为二级标题
# 去除空格line = line.replace(" ", "")if '章' not in line:# 二级标题添加4个空格line = ' ' * 4 + line
2. 在标题里面添加一个空格
# 使用正则表达式在'章'或'节'后面添加一个空格,仅在后面没有空格的情况下line = re.sub(r'(章|节)(?![ ])', r'\1 ', line)# 在小数点后添加空格line = re.sub(r'(\.\d)', r'\1 ', line)
3. 在页码前面加上=>符号
# 匹配并去除最外层的英文括号pattern_en = r'\(([\d\s]+)\)'line = re.sub(pattern_en, r'\1', line)# 匹配并去除最外层的中文括号及其内部内容(包括除数字和空格以外的字符)pattern = r'(([^)]+))'line = re.sub(pattern, r'\1', line)# 确保每行只有一个 =>if '=>' not in line:# 在页码数字前添加 =>(只在行尾)line = re.sub(r'(\d+)$', r'=>\1', line)
4. 去除=>符号和汉字之间的冗余符号
# 去除中文汉字和'=>整体符号左边的冗余符号pattern = r'([\u4e00-\u9fff]+)[^\w\s]+=>'line = re.sub(pattern, r'\1=>', line)
5. 删除空行
# 去除空格line = line.replace(" ", "")if len(line) == 1:continue
6. 代码完全体
# 获取桌面路径
import os
import redesktop_path = os.path.join(os.path.expanduser("~"), "Desktop")# 目标文件路径
file_path = os.path.join(desktop_path, "目录.txt")# 打开文件并读取内容
with open(file_path, 'r', encoding='utf-8') as file:lines = file.readlines()modified_lines = []
for line in lines:# 去除空格line = line.replace(" ", "")# 使用正则表达式在'章'或'节'后面添加一个空格,仅在后面没有空格的情况下line = re.sub(r'(章|节)(?![ ])', r'\1 ', line)# 在小数点后添加空格line = re.sub(r'(\.\d)', r'\1 ', line)if '章' not in line:# 二级标题添加4个空格line = ' ' * 4 + line# 匹配并去除最外层的英文括号pattern_en = r'\(([\d\s]+)\)'line = re.sub(pattern_en, r'\1', line)# 匹配并去除最外层的中文括号及其内部内容(包括除数字和空格以外的字符)pattern = r'(([^)]+))'line = re.sub(pattern, r'\1', line)# 确保每行只有一个 =>if '=>' not in line:# 在页码数字前添加 =>(只在行尾)line = re.sub(r'(\d+)$', r'=>\1', line)modified_lines.append(line)
# 将修改后的内容写回文件
with open(file_path, 'w', encoding='utf-8') as file:file.writelines(modified_lines)# 读取文件内容
with open(file_path, 'r', encoding='utf-8') as file:content = file.read()print(content)7. 进阶说明
1. 兼容标准章节版本
2. 章和章之间识别为第二级目录
3. 只在标题末尾页码数字添加=>符号
4. 去除箭头和汉字之间识别出来的冗余符号
5. 去除空行
拓展与补充
1. content = file.read() 与 lines = file.readlines() 读取文件的区别
在 Python 中,file.read() 和 file.readlines() 两者可以在同一个文件句柄中使用,但是要注意的是,file.read() 会读取整个文件内容为一个字符串,而 file.readlines() 会读取整个文件内容并将每一行作为一个字符串放入列表中
如果你使用了 file.read(),那么之后再使用 file.readlines() 将不会得到任何内容,因为文件指针已经在文件的末尾。如果需要再次读取文件,你可以使用 file.seek(0) 将文件指针重新定位到文件的开头
以下是一个演示的例子:
# 使用 file.read()
with open('example.txt', 'r', encoding='utf-8') as file:content = file.read()print(content)# 使用 file.readlines(),注意在上面使用了 file.read() 之后,需要重新打开文件或者使用 file.seek(0)
with open('example.txt', 'r', encoding='utf-8') as file:file.seek(0)lines = file.readlines()print(lines)
总的来说,两者是可以在同一个文件句柄中使用的,只是需要注意文件指针的位置。
总结
欢迎各位留言交流以及批评指正,如果文章对您有帮助或者觉得作者写的还不错可以点一下关注,点赞,收藏支持一下。
(博客的参考源码可以在我主页的资源里找到,如果在学习的过程中有什么疑问欢迎大家在评论区向我提出)
相关文章:
目录自动清洗
文章目录 前言一、需求分析二、操作步骤详解(标准章节)1. 提取文章目录2. 更改保存目录.txt3. 二级标题前面加4个空格4. 在章字和节字后面添加一个空格5. 在页码前面加上>符号6. 代码完全体 三、进阶一(有章无节小数二级标题)1…...

c++实现Any类,让一个类型指向其他任意类型
在c中,对于以上任务,容易想到的是一个基类类型指向其所有派生类。因此设计一个Any类,其里面有一个成员基类Base类,其派生类可以是数据date,但是你不知道date到底是什么东西,所以需要使用模版。所以其结构为…...
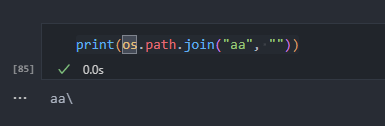
os.path.join函数用法
os.path.join()是Python中用于拼接文件路径的函数,它可以将多个字符串拼接成一个路径,并且会根据操作系统的规则自动使用合适的路径分隔符。 注:Linux用的是/分隔符,而Windows才用的是\。 该函数属于os.path模块,因此在…...

vscode Prettier配置
常用配置项: .prettierrc.json 是 Prettier 格式化工具的配置文件 {"printWidth": 200, // 指定行的最大长度"tabWidth": 2, // 指定缩进的空格数"useTabs": false, // 是否使用制表符进行缩进,默认为 false"singl…...
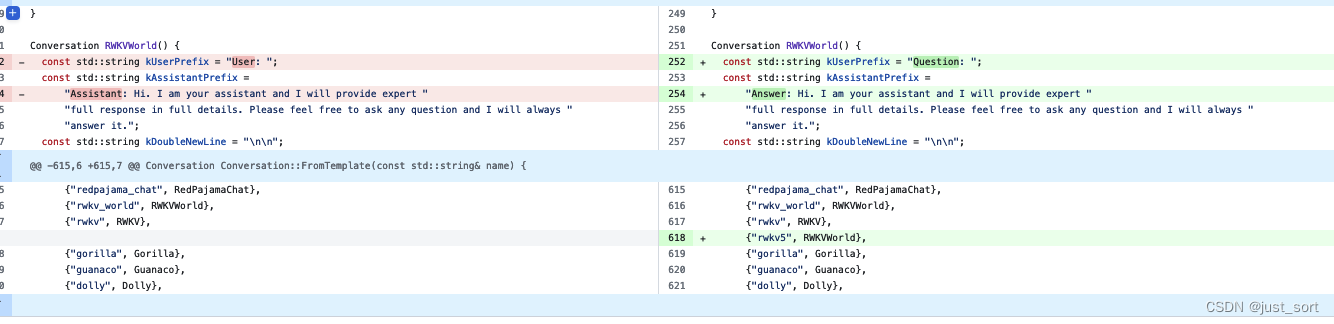
MLC-LLM 支持RWKV-5推理以及对RWKV-5的一些思考
自从2023年3月左右,chatgpt火热起来之后,我把关注的一些知乎帖子都记录到了这个markdown里面,:https://github.com/BBuf/how-to-optim-algorithm-in-cuda/tree/master/large-language-model-note ,从2023年3月左右到现…...
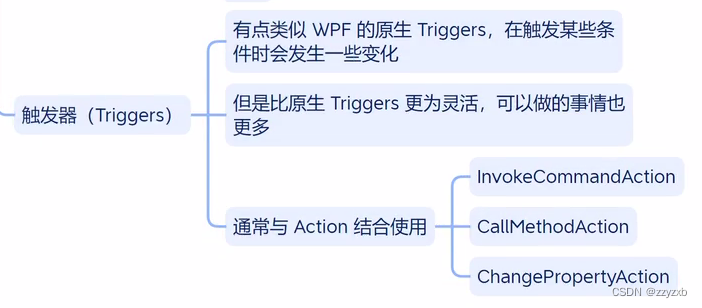
WPF中行为与触发器的概念及用法
完全来源于十月的寒流,感谢大佬讲解 一、行为 (Behaviors) behaviors的简单测试 <Window x:Class"Test_05.MainWindow"xmlns"http://schemas.microsoft.com/winfx/2006/xaml/presentation"xmlns:x"http://schemas.microsoft.com/winf…...

2023-2024华为ICT大赛-计算赛道-广东省省赛初赛-高职组-部分赛题分析【2023.11.18】
2023-2024华为ICT大赛 计算赛道 广东省 省赛 初赛 高职组 部分赛题 分析【2023.11.18】 文章目录 单选题tpcds模式中存在表customer,不能成功删除tpcds模式是( )以下哪个函数将圆转换成矩形( )下列哪个选项表示依赖该D…...
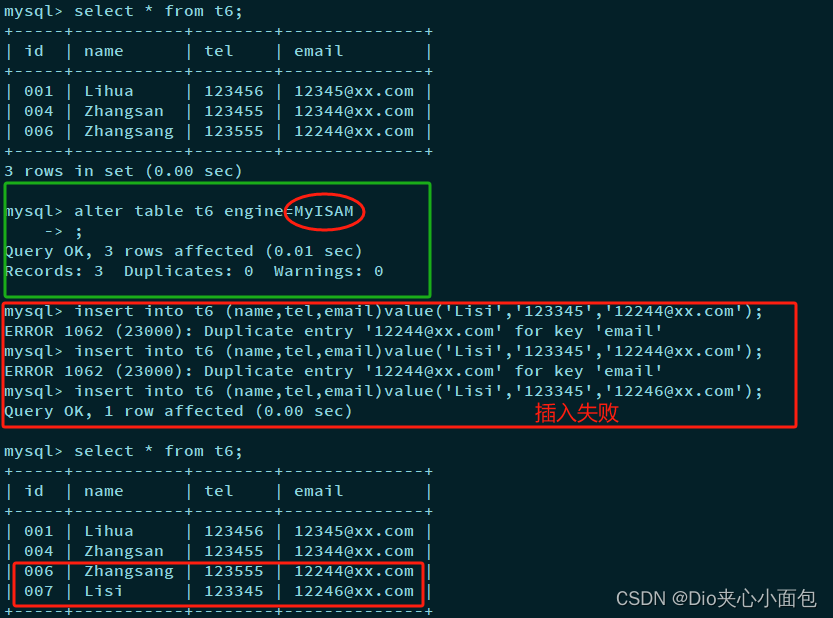
『 MySQL数据库 』数据库之表的约束
文章目录 前言 💻空属性约束(非空约束) 🔖default约束(默认值约束,缺省) 🔖列描述comment 🔖数字类型长度zerofill 🔖主键primary key 🔖📍 追加主键 📍📍 删除主键 &…...
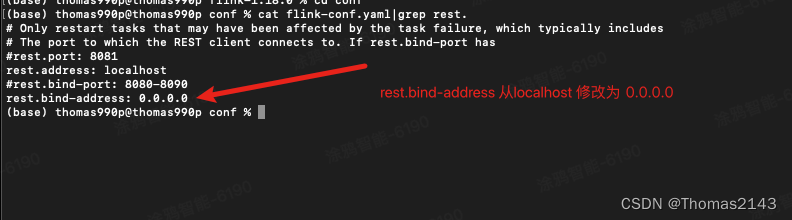
flink 8081 web页面无法被局域网内其他机器访问
实现 http://localhost:8081/#/overview 可以被局域网其他机器访问...
零基础安装分布式数据服务注册系统
一、先安装VM虚拟机,安装最新的ubuntu22系统, 先安装mysql, sudo apt install mysql-server sudo mysql_secure_installation 根据自己需求选择 密码安全级别时,选择n 删除匿名用户?(按y|Y表示是&…...

2023最新最全【OpenMV】 入门教程
1. 什么是OpenMV OpenMV 是一个开源,低成本,功能强大的 机器视觉模块。 OpenMV上的机器视觉算法包括 寻找色块、人脸检测、眼球跟踪、边缘检测、标志跟踪 等。 以STM32F427CPU为核心,集成了OV7725摄像头芯片,在小巧的硬件模块上&a…...

【Java并发编程三】线程的基本使用一
基本使用一 将类继承Runnable,创建Thread,然后调用Thread的start方法启动: package myTest;public class myTest implements Runnable {public static void main(String[] args) throws InterruptedException {myTest test new myTest();Th…...

企业邮箱认证指南:安全与高效的邮箱认证方法
企业邮箱是专门为企业提供的电子邮件服务,安全性和专业性更高。在开始使用企业邮箱之前,很多人会有一些问题,比如企业邮箱需要认证吗、如何开通企业邮箱,以及哪款企业邮箱好。 1、企业邮箱在使用前需要认证吗? 答案是肯…...
)
Django(八、如何开启事务、介绍长见的字段类型和参数)
文章目录 ORM事务操作开启事务 常见的字段类型和参数ORM还支持用户自定义字段类型ORM常用字段参数外键相关参数 ORM事务操作 引入事务 1.事务的四大特性原子性、一致性、隔离性、持久性 2.相关SQL关键字start transaction;rollback;commit;savapoint; 3.相关重要概念脏读、幻…...
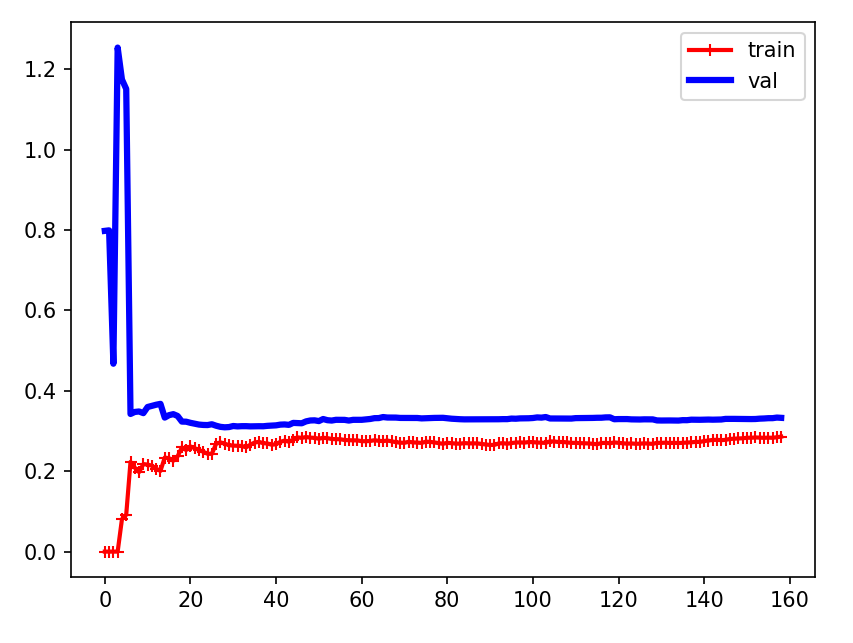
机器学习第5天:多项式回归与学习曲线
文章目录 多项式回归介绍 方法与代码 方法描述 分离多项式 学习曲线的作用 场景 学习曲线介绍 欠拟合曲线 示例 结论 过拟合曲线 示例 结论 多项式回归介绍 当数据不是线性时我们该如何处理呢,考虑如下数据 import matplotlib.pyplot as plt impo…...
MSYS2介绍及工具安装
0 Preface/Foreword 1 MSYS2 官网:MSYS2...

Swift开发中:非逃逸闭包、逃逸闭包、自动闭包的区别
1. 非逃逸闭包(Non-Escaping Closure) 定义:默认情况下,在 Swift 中闭包是非逃逸的。这意味着闭包在函数结束之前被调用并完成,它不会“逃逸”出函数的范围。内存管理:由于闭包在函数返回前被调用…...

栈结构应用-进制转换-辗转相除法
// 定义类class Stack{// #items [] 前边加#变为私有 外部不能随意修改 内部使用也要加#items []pop(){return this.items.pop()}push(data){this.items.push(data)}peek(){return this.items[this.items.length-1]}isEmpty(){return this.items.length 0}size(){return th…...
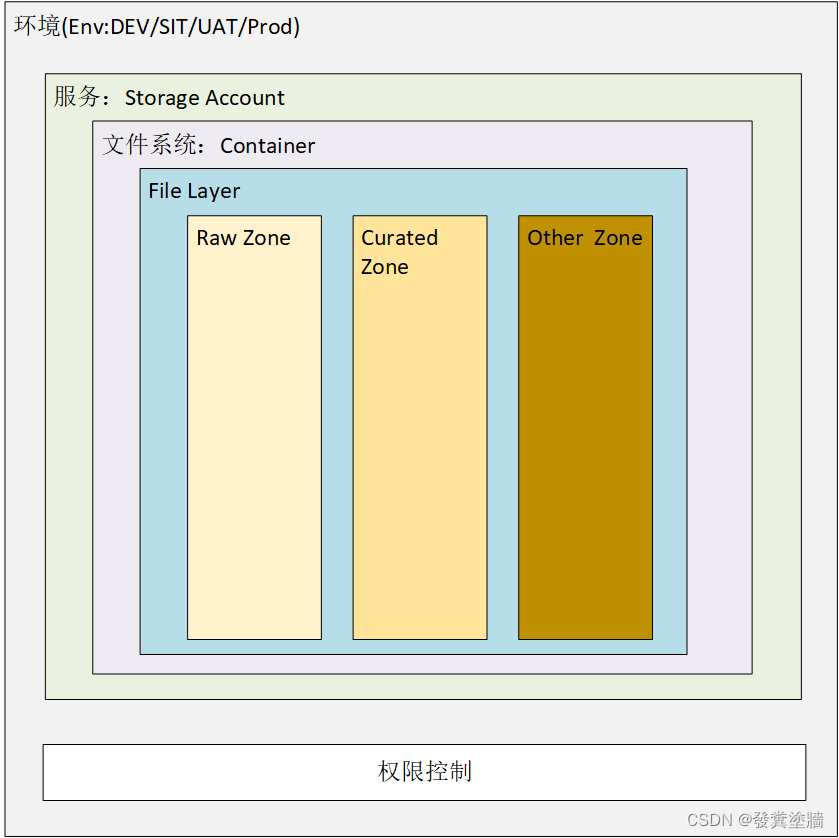
【Azure 架构师学习笔记】-Azure Storage Account(6)- File Layer
本文属于【Azure 架构师学习笔记】系列。 本文属于【Azure Storage Account】系列。 接上文 【Azure 架构师学习笔记】-Azure Storage Account(5)- Data Lake layers 前言 上一文介绍了存储帐户的概述,还有container的一些配置,在…...
idea 环境搭建及运行java后端源码
1、 idea 历史版本下载及安装 建议下载和我一样的版本,2020.3 https://www.jetbrains.com/idea/download/other.html,idea分为专业版本(Ultimate)和社区版本(Community),前期可以下载专业版本…...
)
保姆级教程:从WOS下载文献到Citespace出图,手把手搞定科研可视化(附避坑指南)
科研可视化实战:从WOS数据采集到Citespace图谱优化的完整指南 第一次打开Citespace时,看着满屏的英文参数和报错提示,我盯着屏幕发了十分钟呆——这大概是每个科研新手都会经历的"震撼教育"。文献计量分析本应是揭示知识脉络的利器…...

3分钟搞定Windows和Office激活:KMS_VL_ALL_AIO智能脚本使用指南
3分钟搞定Windows和Office激活:KMS_VL_ALL_AIO智能脚本使用指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为系统激活烦恼吗?Windows提示许可证过期,…...

如何通过 SEO 优化提高企业品牌的曝光度
SEO优化提高企业品牌曝光度的关键策略 在当今数字化时代,企业品牌的曝光度直接关系到其市场竞争力和商业成功。SEO(搜索引擎优化)是提升企业品牌在搜索引擎中排名的重要手段。本文将详细探讨如何通过SEO优化提高企业品牌的曝光度,…...

MySQL解析器的性能优化:从理论到实践
MySQL解析器的性能优化:从理论到实践 引言 作为一名在数据深渊里捞了十几年 Bug 的女码农,我见过太多因为解析器性能问题导致的数据库瓶颈。在 MySQL 数据库中,解析器的性能直接影响 SQL 语句的处理速度和系统的整体性能。今天,我…...
ostringstream清空缓存的正确姿势:str()与clear()的深度解析
1. 为什么ostringstream清空缓存这么让人困惑? 第一次用ostringstream的时候,我也被它坑过。记得当时写了个日志记录功能,反复往同一个ostringstream对象里写入内容,结果发现每次输出的日志都越积越长。我本能地调用了clear()&…...

Ansible Playbook在JumpServer中的高级用法:自动化运维效率提升技巧
Ansible Playbook在JumpServer中的高阶实战:效率倍增的自动化运维策略 开篇:当堡垒机遇上自动化运维 想象一下这样的场景:凌晨三点,服务器突然告警,传统运维需要手动登录每台机器检查状态,而熟练使用Ansibl…...

PX4仿真环境下的XTDrone实战:解决roslaunch常见错误的5个技巧
PX4仿真环境下的XTDrone实战:解决roslaunch常见错误的5个技巧 在无人机开发领域,PX4与ROS的结合为开发者提供了强大的仿真和测试平台。XTDrone作为基于PX4和ROS的开源无人机仿真框架,已经成为许多开发者和研究团队的首选工具。然而࿰…...

Karp的21个NPC问题:从理论到实践的经典探索
1. Karp与NPC问题的历史背景 1971年,Stephen Cook在论文《The Complexity of Theorem Proving Procedures》中首次提出了NP完全性的概念,并证明了布尔可满足性问题(SAT)属于NP完全问题。这一突破性工作为计算复杂性理论奠定了基石…...

4步轻松搞定Windows系统优化:Win11Debloat让你的电脑重获新生
4步轻松搞定Windows系统优化:Win11Debloat让你的电脑重获新生 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter…...

ROS Melodic/Noetic下,为Jetson Xavier NX源码编译Realsense-ROS 2.3.1与SDK 2.48.0的完整流程
ROS Melodic/Noetic下为Jetson Xavier NX源码编译Realsense-ROS 2.3.1与SDK 2.48.0的完整指南 在机器人视觉领域,Intel RealSense深度相机凭借其出色的性能与稳定性成为众多开发者的首选。然而,当我们将目光投向Jetson Xavier NX这样的边缘计算平台时&am…...