教程:使用 Keras 优化神经网络
一、介绍
在 我 之前的文章中,我讨论了使用 TensorFlow 实现神经网络。继续有关神经网络库的系列文章,我决定重点介绍 Keras——据说是迄今为止最好的深度学习库。
我 从事深度学习已经有一段时间了,据我所知,处理神经网络时最困难的事情是无休止的参数调整范围。随着神经网络深度的增加,处理所有参数变得越来越困难。大多数情况下,人们依靠直觉和经验来调整它。事实上,关于这个话题的研究仍然很猖獗。
值得庆幸的是,我们有 Keras,它可以处理大量艰苦的工作并提供更简单的界面!
在 这篇文章中,我将分享我在深度学习方面的工作经验。我们将首先概述 Keras、其功能以及与其他库的区别。然后,我们将了解 Keras 中神经网络的简单实现。然后,我将带您进行神经网络参数调整的实践练习。
、目录
- Keras:概述
- Keras:优点
- Keras:限制
- 使用神经网络解决问题的一般方法
- 从“识别数字”的简单 Keras 实现开始
- 神经网络中需要注意的超参数
- 亲自动手(参数调整)
- 从这往哪儿走?
- 其他资源
二、Keras:概述
keras 是一个高级库,专门用于构建神经网络模型。它是用 Python 编写的,并且与 Python – 2.7 和 3.5 兼容。Keras 专为快速执行想法而开发。它具有简单且高度模块化的界面,使得创建复杂的神经网络模型变得更加容易。该库抽象了低级库,即 Theano 和 TensorFlow,以便用户不受这些库的“实现细节”的影响。
Keras 的主要特点是:
- 模块化: 构建神经网络所需的模块包含在一个简单的界面中,以便 Keras 更易于最终用户使用。
- 简约: 实现简短而简洁。
- 可扩展性: 为 Keras 编写新模块非常容易,并使其适合高级研究。
2.1 Keras:优点
作为一个高级库和更简单的界面,Keras 无疑是最好的深度学习库之一。与其他库相比,Keras 的几个突出特点是:
- 与 Theano 和 TensorFlow 相比,它吸收了这两个库的所有优点,并试图提供更好的“用户体验”。
- 由于 Keras 是一个 Python 库,由于 Python 作为编程语言固有的简单性,它更容易被公众使用。
- 与 Keras 相比,类似的库是 Lasagne,但使用过这两个库后,我可以说 Keras 更容易使用。
考虑到上述原因,Keras 作为深度学习库越来越受欢迎也就不足为奇了。
2.2 Keras:局限性
- 我认为对 Theano / TensorFlow 等低级库的依赖是一把双刃剑。这是因为 Keras 无法“走出这些库的领域”。例如,Theano 和 TensorFlow 都不支持 Nvidia 以外的 GPU(目前)。因此,Keras 也没有相应的支持。
- 与 Lasagne 不同的是,Keras 完全抽象了低级语言。因此,在构建自定义操作时灵活性较差。
- 我要说的最后一点是 Keras 相对较新。第一个版本于 2015 年初发布,此后经历了许多更改。虽然 Keras 已经在生产中使用,但在为生产部署 keras 模型之前应该三思而后行。
三、神经网络解决问题的一般方法
神经网络是一种特殊类型的机器学习 (ML) 算法。因此,与每个 ML 算法一样,它遵循数据预处理、模型构建和模型评估的常见 ML 工作流程。为了简洁起见,我列出了如何解决神经网络问题的 To-D0 列表。
- 检查这是否是神经网络比传统算法带来提升的问题(请参阅上一节中的清单)
- 调查哪种神经网络架构最适合所需的问题
- 通过您选择的语言/库定义神经网络架构。
- 将数据转换为正确的格式并将其分批
- 根据您的需要对数据进行预处理
- 增强数据以增加规模并制作更好的训练模型
- 将批次馈送到神经网络
- 训练并监控训练和验证数据集的变化
- 测试您的模型并保存以供将来使用
四、从“识别数字”的简单 Keras 实现开始
在 开始此实验之前,请确保您的系统中安装了 Keras。参考官方安装指南。我们将使用 Tensorflow 作为后端,因此请确保您已在配置文件中完成此操作。如果没有,请按照此处给出的步骤操作。
在 这里,我们解决了深度学习实践问题—— 识别数字。让我们看一下我们的问题陈述:
我 们的问题是图像识别问题,从给定的 28 x 28 图像中识别数字。我们有一部分图像用于训练,其余图像用于测试我们的模型。首先,下载训练和测试文件。数据集包含所有图像的压缩文件,train.csv 和 test.csv 都有相应的训练和测试图像的名称。数据集中不提供任何附加功能,仅以“.png”格式提供原始图像。
开始吧:
第 0 步:准备
a) 导入所有必要的库
%pylab inline
import os
import numpy as np
import pandas as pd
from scipy.misc import imread
from sklearn.metrics import accuracy_scoreimport tensorflow as tf
import keras
b) 让我们设置一个种子值,以便我们可以控制模型的随机性
# To stop potential randomness
seed = 128
rng = np.random.RandomState(seed)c) 第一步是设置目录路径,以确保安全!
root_dir = os.path.abspath('../..')
data_dir = os.path.join(root_dir, 'data')
sub_dir = os.path.join(root_dir, 'sub')
# check for existence
os.path.exists(root_dir)
os.path.exists(data_dir)
os.path.exists(sub_dir)第 1 步:数据加载和预处理
a) 现在让我们读取数据集。这些文件采用 .csv 格式,并具有文件名和相应的标签
train = pd.read_csv(os.path.join(data_dir, 'Train', 'train.csv'))
test = pd.read_csv(os.path.join(data_dir, 'Test.csv'))sample_submission = pd.read_csv(os.path.join(data_dir, 'Sample_Submission.csv'))train.head()t | 文件名 | 标签 | |
|---|---|---|
| 0 | 0.png | 4 |
| 1 | 1.png | 9 |
| 2 | 2.png | 1 |
| 3 | 3.png | 7 |
| 4 | 4.png | 3 |
b) 让我们看看我们的数据是什么样的!我们读取图像并显示它。
img_name = rng.choice(train.filename)
filepath = os.path.join(data_dir, 'Train', 'Images', 'train', img_name)img = imread(filepath, flatten=True)pylab.imshow(img, cmap='gray')
pylab.axis('off')
pylab.show()i c) 将上图表示为numpy数组,如下所示

d) 为了更轻松地进行数据操作,我们将所有图像存储为 numpy 数组
temp = []
for img_name in train.filename:image_path = os.path.join(data_dir, 'Train', 'Images', 'train', img_name)img = imread(image_path, flatten=True)img = img.astype('float32')temp.append(img)train_x = np.stack(temp)train_x /= 255.0
train_x = train_x.reshape(-1, 784).astype('float32')temp = []
for img_name in test.filename:image_path = os.path.join(data_dir, 'Train', 'Images', 'test', img_name)img = imread(image_path, flatten=True)img = img.astype('float32')temp.append(img)test_x = np.stack(temp)test_x /= 255.0
test_x = test_x.reshape(-1, 784).astype('float32')
train_y = keras.utils.np_utils.to_categorical(train.label.values)于 这是一个典型的机器学习问题,为了测试模型的正常运行,我们创建了一个验证集。我们将训练集与验证集的分割大小设为 70:30
split_size = int(train_x.shape[0]*0.7)train_x, val_x = train_x[:split_size], train_x[split_size:]
train_y, val_y = train_y[:split_size], train_y[split_size:]
train.label.ix[split_size:] 第 2 步:模型构建
a) 现在是主要部分了!让我们定义我们的神经网络架构。我们定义一个具有 3 层输入、隐藏层和输出的神经网络。输入和输出中的神经元数量是固定的,因为输入是我们的 28 x 28 图像,输出是表示类别的 10 x 1 向量。我们在隐藏层中有 50 个神经元。在这里,我们使用Adam作为优化算法,它是梯度下降算法的有效变体。keras 中还有许多其他可用的优化器(请参阅此处)。如果您不理解这些术语,请查看有关神经网络基础知识的文章,以更深入地了解其工作原理。
# define vars
input_num_units = 784
hidden_num_units = 50
output_num_units = 10epochs = 5
batch_size = 128# import keras modulesfrom keras.models import Sequential
from keras.layers import Dense# create model
model = Sequential([Dense(output_dim=hidden_num_units, input_dim=input_num_units, activation='relu'),Dense(output_dim=output_num_units, input_dim=hidden_num_units, activation='softmax'),
])# compile the model with necessary attributes
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
b) It’s time to train our modeltrained_model = model.fit(train_x, train_y, nb_epoch=epochs, batch_size=batch_size, validation_data=(val_x, val_y))# 第 3 步:模型评估
a)为了用我们自己的眼睛测试我们的模型,让我们可视化它的预测
pred = model.predict_classes(test_x)img_name = rng.choice(test.filename)
filepath = os.path.join(data_dir, 'Train', 'Images', 'test', img_name)img = imread(filepath, flatten=True)test_index = int(img_name.split('.')[0]) - train.shape[0]print "Prediction is: ", pred[test_index]pylab.imshow(img, cmap='gray')
pylab.axis('off')
pylab.show()
p预测为:8

b)我们看到我们的模型即使非常简单也表现良好。现在我们用我们的模型创建一个提交
sample_submission.filename = test.filename; sample_submission.label = pred
sample_submission.to_csv(os.path.join(sub_dir, 'sub02.csv'), index=False) 五、神经网络中需要注意的超参数
我觉得,与任何其他机器学习算法相比,超参数调整是神经网络中最难的。如果应用网格搜索,你会觉得很疯狂,因为在调整神经网络时有很多参数。
注意:我在下面的文章《使用 TensorFlow 实现神经网络简介》中讨论了有关何时应用神经网络的更多细节
优化神经网络时需要注意的一些重要参数是:
- 建筑类型
- 层数
- 一层中神经元的数量
- 正则化参数
- 学习率
- 使用的优化/反向传播技术的类型
- 辍学率
- 重量共享
此外,根据架构类型,可能还有更多的超参数。例如,如果您使用卷积神经网络,则必须查看超参数,例如卷积滤波器大小、池化值等。
选择好的参数的最佳方法是了解您的问题领域。研究以前对数据应用的技术,最重要的是向有经验的人询问对问题的见解。这是确保获得“足够好”的神经网络模型的唯一方法。
以下是一些有关训练神经网络的提示和技巧的资源。(资源 1、资源 2、资源 3)
六、亲自动手
让我们利用超参数的知识开始调整我们的神经网络模型。
- 正如我们之前所做的那样,我们重做所有先决条件。让我们导入模块
import os
import numpy as np
import pandas as pd
from scipy.misc import imread
from sklearn.metrics import accuracy_score
import tensorflow as tf
import kerasfrom keras.models import Sequential
from keras.layers import Dense, Activation, Dropout, Convolution2D, Flatten, MaxPooling2D, Reshape, InputLayer- %和以前一样,设置种子值
# To stop potential randomness
seed = 128
rng = np.random.RandomState(seed)- 设置路径以供进一步使用
root_dir = os.path.abspath('../..')
data_dir = os.path.join(root_dir, 'data')
sub_dir = os.path.join(root_dir, 'sub')# check for existence
os.path.exists(root_dir)
os.path.exists(data_dir)
os.path.exists(sub_dir)- r读取数据集并将其转换为可用的形式
train = pd.read_csv(os.path.join(data_dir, 'Train', 'train.csv'))
test = pd.read_csv(os.path.join(data_dir, 'Test.csv'))sample_submission = pd.read_csv(os.path.join(data_dir, 'Sample_Submission.csv'))temp = []
for img_name in train.filename:image_path = os.path.join(data_dir, 'Train', 'Images', 'train', img_name)img = imread(image_path, flatten=True)img = img.astype('float32')temp.append(img)train_x = np.stack(temp)train_x /= 255.0
train_x = train_x.reshape(-1, 784).astype('float32')temp = []
for img_name in test.filename:image_path = os.path.join(data_dir, 'Train', 'Images', 'test', img_name)img = imread(image_path, flatten=True)img = img.astype('float32')temp.append(img)test_x = np.stack(temp)test_x /= 255.0
test_x = test_x.reshape(-1, 784).astype('float32')train_y = keras.utils.np_utils.to_categorical(train.label.values)- 将我们的训练数据分为训练和验证
split_size = int(train_x.shape[0]*0.7)train_x, val_x = train_x[:split_size], train_x[split_size:]
train_y, val_y = train_y[:split_size], train_y[split_size:]- 让我们开始我们的调整吧!让我们将模型更改为“宽”,即增加隐藏层中的神经元数量
# define vars
input_num_units = 784
hidden_num_units = 500
output_num_units = 10
epochs = 5
batch_size = 128model = Sequential([Dense(output_dim=hidden_num_units, input_dim=input_num_units, activation='relu'),Dense(output_dim=output_num_units, input_dim=hidden_num_units, activation='softmax'),
])- 我们来测试一下这个模型
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])trained_model_500 = model.fit(train_x, train_y, nb_epoch=epochs, batch_size=batch_size, validation_data=(val_x, val_y))m - 我们看到这个模型的表现明显比以前好!现在,我们尝试使模型变得“深”,而不是“宽”。我们添加了四个隐藏层,每个隐藏层有 50 个神经元
#
# define vars
input_num_units = 784
hidden1_num_units = 50
hidden2_num_units = 50
hidden3_num_units = 50
hidden4_num_units = 50
hidden5_num_units = 50
output_num_units = 10epochs = 5
batch_size = 128model = Sequential([Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation='relu'),Dense(output_dim=hidden2_num_units, input_dim=hidden1_num_units, activation='relu'),Dense(output_dim=hidden3_num_units, input_dim=hidden2_num_units, activation='relu'),Dense(output_dim=hidden4_num_units, input_dim=hidden3_num_units, activation='relu'),Dense(output_dim=hidden5_num_units, input_dim=hidden4_num_units, activation='relu'),Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation='softmax'),])- 对这个模型的表现有什么猜测吗?
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])trained_model_5d = model.fit(train_x, train_y, nb_epoch=epochs, batch_size=batch_size, validation_data=(val_x, val_y)) 看来我们没有得到我们所期望的。这可能是因为我们的模型可能过度拟合。为了解决这个问题,我们使用了一种称为 dropout 的方法。Dropout 本质上是随机关闭模型的某些部分,这样它就不会“过度学习”某个概念(要了解有关 Dropout 的更多信息,请查看有关神经网络核心概念的文章)
看来我们没有得到我们所期望的。这可能是因为我们的模型可能过度拟合。为了解决这个问题,我们使用了一种称为 dropout 的方法。Dropout 本质上是随机关闭模型的某些部分,这样它就不会“过度学习”某个概念(要了解有关 Dropout 的更多信息,请查看有关神经网络核心概念的文章)
# define vars
input_num_units = 784
hidden1_num_units = 50
hidden2_num_units = 50
hidden3_num_units = 50
hidden4_num_units = 50
hidden5_num_units = 50
output_num_units = 10epochs = 5
batch_size = 128dropout_ratio = 0.2model = Sequential([Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation='relu'),Dropout(dropout_ratio),Dense(output_dim=hidden2_num_units, input_dim=hidden1_num_units, activation='relu'),Dropout(dropout_ratio),Dense(output_dim=hidden3_num_units, input_dim=hidden2_num_units, activation='relu'),Dropout(dropout_ratio),Dense(output_dim=hidden4_num_units, input_dim=hidden3_num_units, activation='relu'),Dropout(dropout_ratio),Dense(output_dim=hidden5_num_units, input_dim=hidden4_num_units, activation='relu'),Dropout(dropout_ratio),Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation='softmax'),])- 现在让我们检查一下我们的准确性
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])trained_model_5d_with_drop = model.fit(train_x, train_y, nb_epoch=epochs, batch_size=batch_size, validation_data=(val_x, val_y))m - 似乎有些不对劲。看来我们的模型表现得不够好。原因之一可能是我们没有充分发挥模型的潜力。将我们的训练周期增加到 50 并检查一下!
#
input_num_units = 784
hidden1_num_units = 50
hidden2_num_units = 50
hidden3_num_units = 50
hidden4_num_units = 50
hidden5_num_units = 50
output_num_units = 10epochs = 50
batch_size = 128
model = Sequential([Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation='relu'),Dropout(0.2),Dense(output_dim=hidden2_num_units, input_dim=hidden1_num_units, activation='relu'),Dropout(0.2),Dense(output_dim=hidden3_num_units, input_dim=hidden2_num_units, activation='relu'),Dropout(0.2),Dense(output_dim=hidden4_num_units, input_dim=hidden3_num_units, activation='relu'),Dropout(0.2),Dense(output_dim=hidden5_num_units, input_dim=hidden4_num_units, activation='relu'),Dropout(0.2),Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation='softmax'),
])- 嗯,我很高兴看到会发生什么。你是?
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])trained_model_5d_with_drop_more_epochs = model.fit(train_x, train_y, nb_epoch=epochs, batch_size=batch_size, validation_data=(val_x, val_y)) 是的!这很好。我们看到准确性有所提高。(作为一项可选任务,您可以尝试增加纪元数来训练更多)让我们尝试另一件事,我们使我们的模型既深又广!我们还实施了之前学到的所有调整。为了更快地获得结果,我们减少了训练次数。但如果您愿意,您可以自由增加它们。
是的!这很好。我们看到准确性有所提高。(作为一项可选任务,您可以尝试增加纪元数来训练更多)让我们尝试另一件事,我们使我们的模型既深又广!我们还实施了之前学到的所有调整。为了更快地获得结果,我们减少了训练次数。但如果您愿意,您可以自由增加它们。
input_num_units = 784
hidden1_num_units = 500
hidden2_num_units = 500
hidden3_num_units = 500
hidden4_num_units = 500
hidden5_num_units = 500
output_num_units = 10epochs = 25
batch_size = 128model = Sequential([Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation='relu'),Dropout(0.2),Dense(output_dim=hidden2_num_units, input_dim=hidden1_num_units, activation='relu'),Dropout(0.2),Dense(output_dim=hidden3_num_units, input_dim=hidden2_num_units, activation='relu'),Dropout(0.2),Dense(output_dim=hidden4_num_units, input_dim=hidden3_num_units, activation='relu'),Dropout(0.2),Dense(output_dim=hidden5_num_units, input_dim=hidden4_num_units, activation='relu'),Dropout(0.2),Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation='softmax'),])- #请原谅我的剧透,但很明显我们的模型会比之前所有的模型都要好。
- 还是让我们检查一下
m
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])trained_model_deep_n_wide = model.fit(train_x, train_y, nb_epoch=epochs, batch_size=batch_size, validation_data=(val_x, val_y))
看来我们打破了所有记录!让我们将此模型提交给解决方案检查器
pred = model.predict_classes(test_x)sample_submission.filename = test.filename; sample_submission.label = predsample_submission.to_csv(os.path.join(sub_dir, 'sub03.csv'), index=False)p - 作为最后的调整,我们将尝试更改模型的类型。到目前为止,我们制作了多层感知器(MLP)。现在让我们将其更改为卷积神经网络。(要深入了解卷积神经网络 (CNN),请阅读本文)。运行 CNN 所必需的一件事是它需要以特定的格式进行排列。因此,让我们重塑数据并将其输入 CNN。
# reshape datatrain_x_temp = train_x.reshape(-1, 28, 28, 1)
val_x_temp = val_x.reshape(-1, 28, 28, 1)# define vars
input_shape = (784,)
input_reshape = (28, 28, 1)conv_num_filters = 5
conv_filter_size = 5pool_size = (2, 2)hidden_num_units = 50
output_num_units = 10epochs = 5
batch_size = 128model = Sequential([InputLayer(input_shape=input_reshape),Convolution2D(25, 5, 5, activation='relu'),MaxPooling2D(pool_size=pool_size),Convolution2D(25, 5, 5, activation='relu'),MaxPooling2D(pool_size=pool_size),Convolution2D(25, 4, 4, activation='relu'),Flatten(),Dense(output_dim=hidden_num_units, activation='relu'),Dense(output_dim=output_num_units, input_dim=hidden_num_units, activation='softmax'),
])model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])trained_model_conv = model.fit(train_x_temp, train_y, nb_epoch=epochs, batch_size=batch_size, validation_data=(val_x_temp, val_y))# 这个结果让你大吃一惊,不是吗?即使训练时间如此短,表现却好得多!这证明更好的架构肯定可以提高处理神经网络时的性能。
是时候放下辅助轮了。您可以尝试很多事情,需要进行很多调整。尝试一下,让我们知道效果如何!
七、下一步该去哪里?
现在,您已经了解了 Keras 的基本概述以及实现神经网络的实践经验。您还有很多事情可以做。例如,我非常喜欢使用keras 来构建图像类比。在这个项目中,作者训练一个神经网络来理解图像,并将学习到的属性重新创建到另一个图像。如下所示,前两张图像作为输入给出,模型在第一张图像上进行训练,并在将输入作为第二张图像时给出输出作为第三张图像。

神经网络调优仍然被认为是“黑暗艺术”。因此,不要期望在第一次尝试中就能获得最好的模型。构建、评估和重申,这就是你成为更好的神经网络实践者的方法。
您应该知道的另一点是,还有其他方法可以确保您获得“足够好”的神经网络模型,而无需从头开始训练。预训练和迁移学习等技术对于了解何时实施神经网络模型来解决现实生活问题至关重要。
八、其他资源
- Keras 官方存储库
- keras 资源精选列表
- Keras 用户组
相关文章:
教程:使用 Keras 优化神经网络
一、介绍 在 我 之前的文章中,我讨论了使用 TensorFlow 实现神经网络。继续有关神经网络库的系列文章,我决定重点介绍 Keras——据说是迄今为止最好的深度学习库。 我 从事深度学习已经有一段时间了,据我所知,处理…...

什么是PWA(Progressive Web App)?它有哪些特点和优势?
聚沙成塔每天进步一点点 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 欢迎来到前端入门之旅!感兴趣的可以订阅本专栏哦!这个专栏是为那些对Web开发感兴趣、刚刚踏入前端领域的朋友们量身打造的。无论你是完全的新手还是有一些基础的开发…...

深入理解MongoDB的CRUD操作
MongoDB,一个广受欢迎的NoSQL数据库,以其灵活的文档模型、强大的查询能力和易于扩展的特性而著称。对于初学者和经验丰富的开发人员来说,熟练掌握MongoDB的增删改查(CRUD)操作是至关重要的。本博客将深入探讨如何在Mon…...
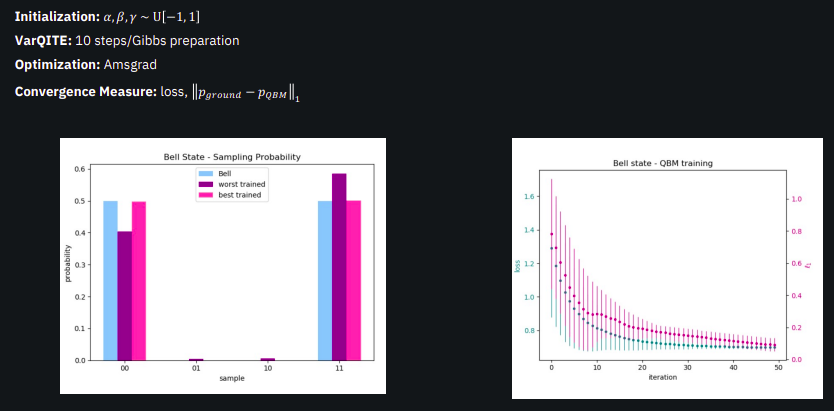
使用量子玻尔兹曼机推进机器学习:新范式
一、说明 量子玻尔兹曼机(QBM)是量子物理学和机器学习的前沿融合。通过利用叠加和纠缠等量子特性的力量,QBM 可以同时探索多个解决方案,使其异常擅长解决复杂问题。它使用量子位(量子计算的构建模块)以传统…...
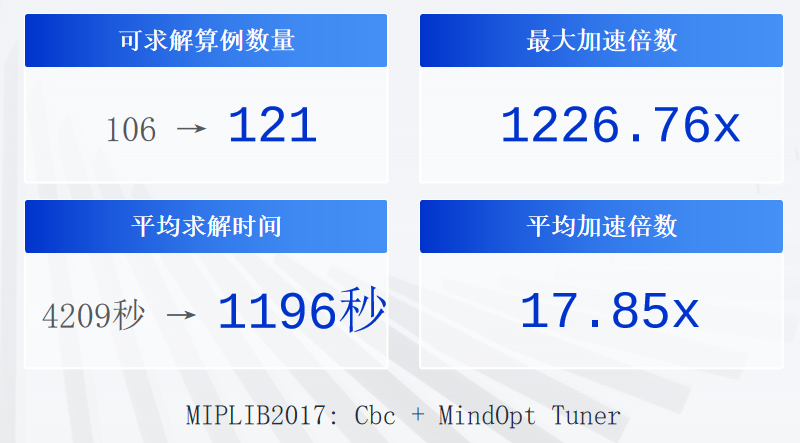
优化|优化求解器自动调参
原文信息:MindOpt Tuner: Boost the Performance of Numerical Software by Automatic Parameter Tuning 作者:王孟昌 (达摩院决策智能实验室MindOpt团队成员) 一个算法开发者,可能会幻想进入这样的境界:算…...
vite vue3配置eslint和prettier以及sass
准备 教程 安装eslint 官网 vue-eslint ts-eslint 安装eslint yarn add eslint -D生成配置文件 npx eslint --init安装其他插件 yarn add -D eslint-plugin-import eslint-plugin-vue eslint-plugin-node eslint-plugin-prettier eslint-config-prettier eslint-plugin…...

C语言第入门——第十六课
目录 一、分治策略与递归 二、递归 1.求解n的阶乘 2.输入整数、倒序输出 3.输入整数、正序输出 4.计算第n位Fibonacci数列 编辑5.无序整数数组打印 6.找到对应数组下标 一、分治策略与递归 在我们遇到大问题的时候,我们的正确做法是将它分解成小问题&a…...

IntelliJ IDEA 快捷键 Windows 版本
前言:常用快捷键 IntelliJ IDEA编辑器大受欢迎的原因之一是它的智能提示和丰富的快捷键,在日常开发中熟练的使用快捷键会大大提升开发的效率,本篇文章就笔者日常开发中的总结,把常用的、好用的快捷键做一个列表,方便…...

重生之我必去大厂java开发
JavaDreamer 重生之我必去大厂java开发。主线任务进入大厂java开发。 author :developer_zxh GitHub | Gitee 本项目记录了本人从中国科学院大学硕士研究生开始,如何进入大工 java 开发岗位的学习记录(目前在校未求职,加入后此状…...
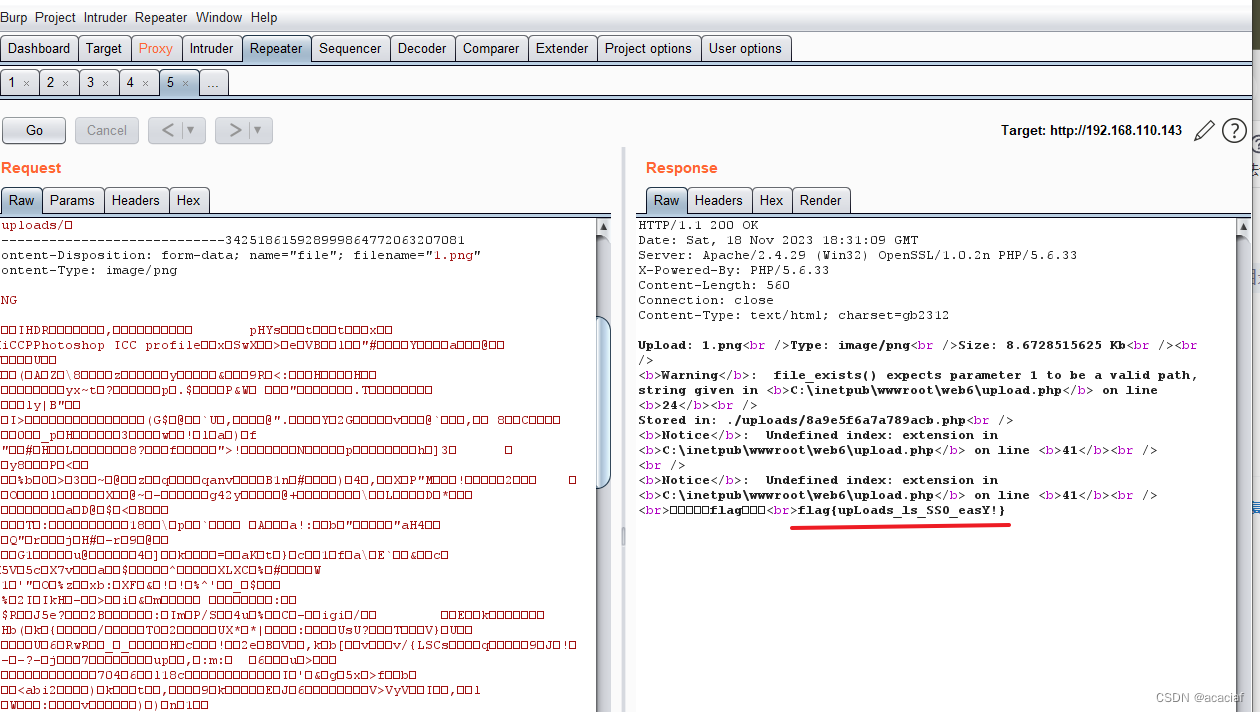
2023年中职“网络安全“—Web 渗透测试②
2023年中职“网络安全“—Web 渗透测试② Web 渗透测试任务环境说明:1.访问http://靶机IP/web1/,获取flag值,Flag格式为flag{xxx};2.访问http://靶机IP/web2/,获取flag值,Flag格式为flag{xxx};3.访问http://靶机IP/web…...
【整顿C盘】pycharm、chrome等软件,缓存移动
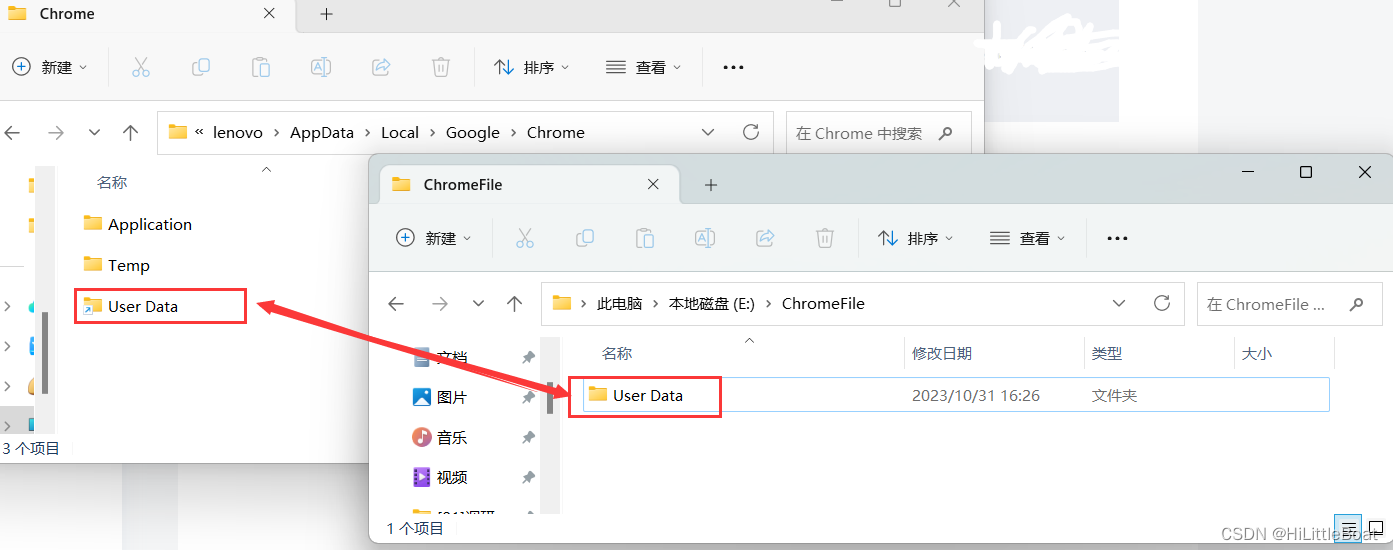
C盘爆了,特来找一下巨大的软件缓存,特此记录,跟随的各大教程,和自己的体会 一、爆炸家族JetBrains 这个适用于pycharm、idea、webstorm等等,只要是JetBrains家的,2020版本以上,都是一样的方法 p…...

C# using语句使用介绍
在C#中,using语句有两种主要用途:一是引入命名空间,二是提供一种简便的方式来处理资源的清理(主要用于实现了 IDisposable 接口的对象)。 引入命名空间:using 语句用于引入命名空间,从而可以在代…...
 201. 数字范围按位与 (位运算))
leetcode (力扣) 201. 数字范围按位与 (位运算)
文章目录 题目描述思路分析完整代码 题目描述 给你两个整数 left 和 right ,表示区间 [left, right] ,返回此区间内所有数字 按位与 的结果(包含 left 、right 端点)。 示例 1: 输入:left 5, right 7 输出…...
Flutter笔记: 在Flutter应用中使用SQLite数据库
Flutter笔记 在Flutter应用中使用SQLite数据库(基于sqflite) 作者:李俊才 (jcLee95):https://blog.csdn.net/qq_28550263 邮箱 :291148484163.com 本文地址:https://blog.csdn.net/q…...
OpenAI GPT5计划泄露
OpenAI的首席执行官萨姆奥特曼在最近接受《金融时报》的专访时,分享了OpenAI未来发展的一些新动向。此外,他还透露了关于即将到来的GPT-5模型以及公司对AGI的长期目标的一些细节。 奥特曼指出: 1.OpenAI正在开发GPT-5,一种更先进的…...

【面试经典150 | 数学】Pow(x, n)
文章目录 写在前面Tag题目来源题目解读解题思路方法一:快速幂-递归方法二:快速幂-迭代 其他语言python3 写在最后 写在前面 本专栏专注于分析与讲解【面试经典150】算法,两到三天更新一篇文章,欢迎催更…… 专栏内容以分析题目为主…...

封装比较好的登录页面
封装比较好的登录页面 只在setup()函数中写流程,将逻辑代码抽离出来 <template><div class"wrapper"><img class"wrapper__img" srchttp://www.dell-lee.com/imgs/vue3/user.png /><div class"wrapper__input"&…...

如何使用Flask request对象处理请求
在 Flask 中,request 对象是处理 HTTP 请求的重要工具之一。它提供了许多属性和方法,可以帮助我们获取请求的相关信息和数据。本文将向你介绍 request 对象的常用方法以及如何在 Flask 应用程序中使用它。 1. 获取请求方法 首先,让我们看一…...
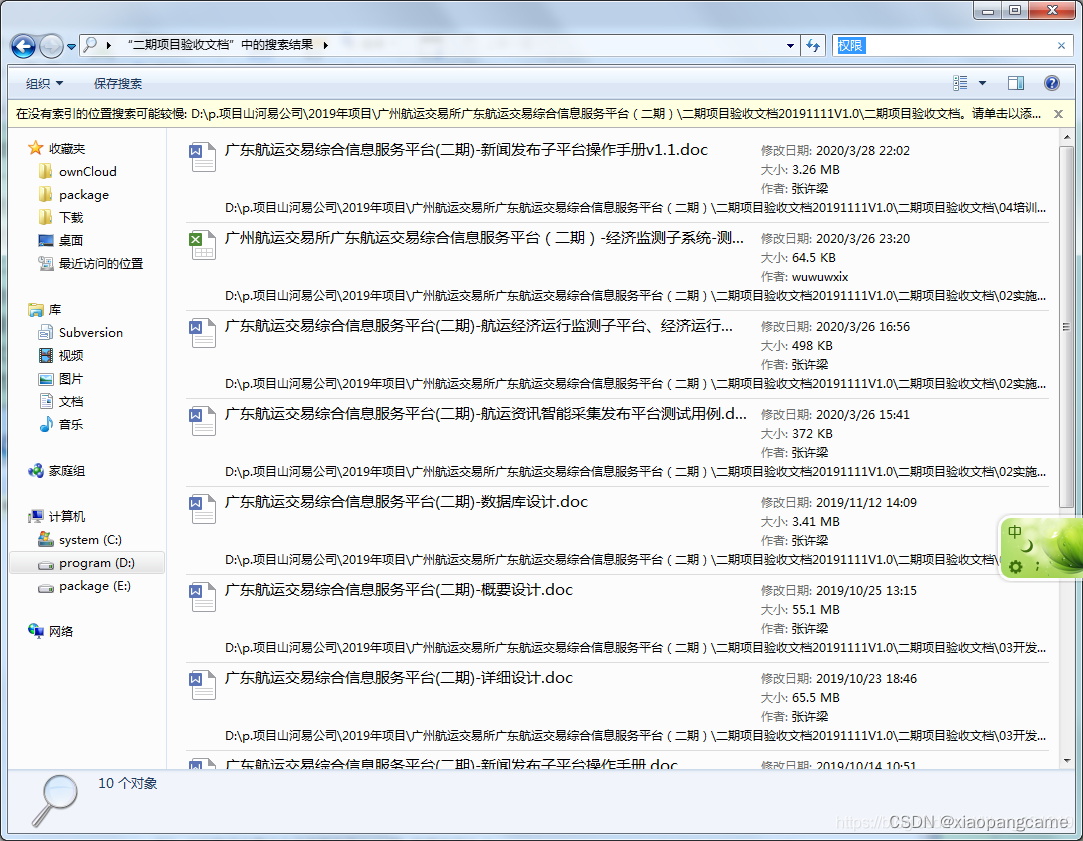
快速搜索多个word、excel等文件中内容
如何快速搜索多个word、excel等文件中内容 操作方法 以win11系统为介绍对象。 首先我们打开“我的电脑”-->“文件夹选项”-->“搜索”标签页,在“搜索内容”下方选择:"始终搜索文件名和内容(此过程可能需要几分钟)"。然后…...
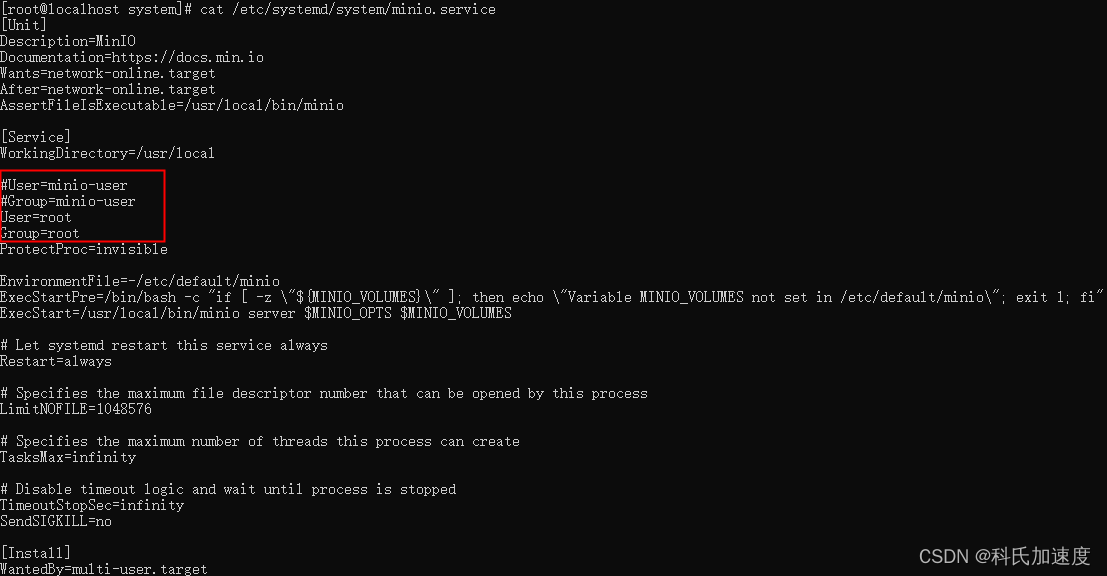
Minio安装
环境 centos8,关闭防火墙 minio-20231101183725版本 参考官网:部署 MinIO:单节点单硬盘 — 适用于 Linux 的 MinIO 对象存储 单例 下载rpm,用中国镜像 wget https://dl.minio.org.cn/server/minio/release/linux-amd64/arch…...

利用Taotoken模型广场为不同业务场景快速选型合适模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken模型广场为不同业务场景快速选型合适模型 为聊天机器人、代码生成助手或内容创作工具挑选一个合适的大模型࿰…...

游戏交易税、年龄锁与拒付账单:APP出海全球合规风暴
上周,监管与平台的合规重拳,密集落在了游戏交易、未成年人保护和支付链条上。几项变化直接且锋利,对出海游戏厂商而言,已不再是远期预警,而是迫在眉睫的执行项。 美国州级监管:直指游戏内购与停服责任 科…...

在Windows电脑上体验酷安社区:酷安UWP桌面版完全指南
在Windows电脑上体验酷安社区:酷安UWP桌面版完全指南 【免费下载链接】Coolapk-UWP 一个基于 UWP 平台的第三方酷安客户端 项目地址: https://gitcode.com/gh_mirrors/co/Coolapk-UWP 你是否曾经想过,如果能在电脑上刷酷安会是怎样的体验…...

书匠策AI:论文写作小白也能一键“搞定“毕业论文?深度拆解这个AI神器到底有多香!
微信公众号搜一搜:书匠策AI | 官网直达:www.shujiangce.com 各位同学、各位在论文苦海里挣扎的"秃头星人"们,今天咱们来聊一个让我最近疯狂安利的东西——书匠策AI。 别急着划走,这不是广告,这…...

终于蹲到了!“能读一半就是赚到”的《编码》精装版来了
前言:介绍一本好书 《编码》的第1版出版于1999年9月,从非常简单的概念开始讲解计算机工作的基础原理,帮助零基础的读者理解计算机的底层逻辑,建立计算机世界观。出版后立即收获全球范围内的广泛好评,成为影响几代程序员…...

ARM架构浮点运算与FPEXC/FPSCR寄存器详解
1. ARM架构浮点运算基础在嵌入式系统和移动计算领域,ARM处理器凭借其高效的能耗比占据主导地位。浮点运算作为科学计算、图形处理和机器学习的基础,其性能直接影响着整个系统的表现。ARM架构通过专门的浮点运算单元和配套的寄存器系统,为开发…...

Omnara:构建AI智能体统一控制中心,实现人机双向实时协同
1. 项目概述:从“沉默执行者”到“可对话的队友”如果你和我一样,在日常开发或自动化流程中重度依赖各类AI助手,比如Claude Code、Cursor的Agent模式,或者用n8n编排复杂的工作流,那你一定遇到过这样的困境:…...

手机号快速查询QQ号:3步找回遗忘账号的实用指南
手机号快速查询QQ号:3步找回遗忘账号的实用指南 【免费下载链接】phone2qq 项目地址: https://gitcode.com/gh_mirrors/ph/phone2qq 你是否曾经因为忘记QQ号而无法登录?手机号查询QQ号工具正是为你量身打造的解决方案!这款基于Python…...

Redis优化与Redis Stack
一 性能优化:让Redis跑得更快、更稳内存淘汰策略:Redis内存满了怎么删数据?推荐用volatile-lru(优先删最近最少用、且设了过期时间的key),避免内存溢出。系统内核优化:vm.swappiness1࿱…...

Confluence数据迁移踩坑实录:从物理机到K8s集群,我是如何无损迁移200G知识库的?
Confluence企业级数据迁移实战:从物理架构到Kubernetes的无缝过渡 当企业知识库规模突破200GB时,迁移不再是简单的备份还原操作。去年我们团队将一个运行7年的Confluence实例从老旧物理服务器迁移到Kubernetes集群,期间经历了数据库崩溃、文件…...