开发者分享 | Ascend C算子开发及单算子调用
本文分享自《AscendC算子开发及单算子调用》,作者:goldpancake。
笔者在阅读Ascend C官方文档的过程中发现,对于初学者来说,尤其是第一次接触异构编程思想的初学者,有部分内容是无需特别关注的,例如算子工程的相关的CmakeLists.txt,以及单算子调用的一些通用工具类文件。同时,在环境配置的过程中,也发现了一些需要注意的地方,特此记录备忘。
1 环境准备
笔者的硬件及系统环境如下:
-
操作系统:openEuler release 20.03 (LTS-SP3)
-
设备:Ascend 910
开发环境需要准备三个run包,分别是驱动、固件和cann-toolkit开发套件,笔者这里使用当前的最新版本CANN开发套件,版本号为7.0.RC1.alpha003,并在昇腾社区下载好对应驱动和固件的run包。
1.1 安装流程
上述准备的三个包,按照驱动 -> 固件 -> CANN开发套件包的顺序来安装。
首先安装驱动,执行如下命令:
/path/to/Ascend-hdk-910-npu-driver_23.0.rc2_linux-aarch64.run --full --install-for-all注意:笔者使用root用户进行安装,以full模式执行run包,并加上install-for-all选项来为所有用户安装。
接下来安装固件,执行如下命令:
/path/to/Ascend-hdk-910-npu-firmware_6.4.12.1.241.run --full驱动和固件都安装完成后,最好重启一次系统:
reboot重启完成后,安装CANN开发套件包:
path/to/Ascend-cann-toolkit_7.0.RC1.alpha003_linux-aarch64.run --full --install-for-all安装完成后,开发环境就准备好了。
1.2 安装过程中可能的问题
笔者在安装过程中,遇到了一个问题,很蠢,但值得注意。
问题的表现是,在按照上述的流程安装好开发环境之后,除root用户外的其他普通用户使用msopgen工具生成算子工程时,出现了权限不足的问题。但因为加上了install-for-all选项,所以不应该是CANN包的权限问题。然后又查看msopgen的代码发现,该工具将python解释器指定为了root用户下的conda环境中的解释器。
#!/root/miniconda3/bin/python3
# coding=utf-8
"""
Function:
This file mainly involves main function of op generation module.
Copyright Information:
Huawei Technologies Co., Ltd. All Rights Reserved © 2020
"""原来是root用户下的conda配置为了默认激活base环境,笔者安装时没有注意这一点,导致在CANN包安装的过程中,选择到了conda环境下的python解释器,这样一来,其他用户肯定是没有权限的。在关闭base环境重新安装CANN包后,问题解决。
2 算子开发流程
至此,环境准备好后,开始正式的算子开发步骤。
2.1 算子工程配置文件
CANN包中提供了一个自动生成算子工程的工具msopgen,该工具可以通过一个json配置文件来生成完整的算子工程,具体的编写方式请参考Ascend C官方文档。
这里以sinh算子为例,该算子是一元操作,所以只需要一个输入,且输出形状与输入形状一致。根据该特征来编写json文件,为了贴合Ascend C官方建议的编程范式,将文件命名为sinh_custom.json。为了简洁,这里我们只实现一种数据类型的操作。
[{"op": "SinhCustom","language": "cpp","input_desc": [{"name": "x","param_type": "required","format": ["ND"],"type": ["fp16"]}],"output_desc": [{"name": "y","param_type": "required","format": ["ND"],"type": ["fp16"]}]}
]2.2 生成算子工程
创建一个文件夹用作算子工程目录,使用msopgen工具执行如下命令来生成算子工程。
mkdir /path/to/SinhCustom
/path/to/msopgen gen -i /path/to/sinh_custom.json -c ai_core-Ascend910 -lan cpp -out /path/to/SinhCustom命令行会输出类似如下的信息:
2023-10-07 14:58:42 (942445) - [INFO] Start to generate AI Core operator files.
2023-10-07 14:58:42 (942445) - [INFO] Start to parse the ir template:/path/to/SinhCustom/sinh_custom.json
2023-10-07 14:58:42 (942445) - [INFO] Start to parse the op: SinhCustom
2023-10-07 14:58:42 (942445) - [INFO] Start to parse the input_desc: x
2023-10-07 14:58:42 (942445) - [INFO] Start to parse the output_desc: y
2023-10-07 14:58:42 (942445) - [WARNING] The "attr" value is invalid or no "attr" exists in the map.
2023-10-07 14:58:42 (942445) - [INFO] Start to check the type and format between the inputs/outputs in IR template.
2023-10-07 14:58:42 (942445) - [INFO] Start to generate a new project.
2023-10-07 14:58:42 (942445) - [INFO] File /path/to/SinhCustom/cmake/config.cmake generated successfully.
2023-10-07 14:58:42 (942445) - [INFO] File /path/to/SinhCustom/op_host/sinh_custom_tiling.h generated successfully.
2023-10-07 14:58:42 (942445) - [INFO] File /path/to/SinhCustom/op_host/sinh_custom.cpp generated successfully.
2023-10-07 14:58:42 (942445) - [INFO] File /path/to/SinhCustom/op_kernel/sinh_custom.cpp generated successfully.
2023-10-07 14:58:42 (942445) - [INFO] File /path/to/SinhCustom/framework/tf_plugin/tensorflow_sinh_custom_plugin.cc generated successfully.
2023-10-07 14:58:42 (942445) - [INFO] File /path/to/SinhCustom/framework/tf_plugin/CMakeLists.txt generated successfully.
2023-10-07 14:58:42 (942445) - [INFO] Generation completed.此时会发现指定的输出目录只已经生成了一系列的算子工程文件。
SinhCustom
├── build.sh
├── cmake
├── CMakeLists.txt
├── CMakePresets.json # 这个配置项需要修改
├── framework
├── op_host
│ ├── CMakeLists.txt
│ ├── sinh_custom.cpp # 算子host侧核心逻辑
│ └── sinh_custom_tiling.h # 算子tiling结构体定义
├── op_kernel
│ ├── CMakeLists.txt
│ └── sinh_custom.cpp # 算子kernel侧核心逻辑
├── scripts
└── sinh_custom.json # 笔者此处将工程配置文件和算子工程目录放在了一起我们只需要专注于上述带有注释的几个文件即可。
此处先修改与算子核心逻辑无关的配置项CMakePresets.json,官方文档中也描述的非常清楚,只需要将ASCEND_CANN_PACKAGE_PATH配置项修改为实际的CANN包安装路径即可。在root用户下安装的默认路径为/usr/local/Ascend/ascend-toolkit/latest。
以上将所有无关算子逻辑的内容修改完毕,接下来就可以专注于算子开发了。
2.3 算子逻辑开发
官方文档中推荐先实现kernel侧的逻辑,但笔者有一些不同的看法。我推荐先实现算子tiling结构体的定义与具体策略,这样做的好处是,可以提前将tiling策略所需的变量确定下来,并且借助于CANN包只提供的一系列宏,这一过程并不需要很大的工作量。在实现kernel侧逻辑的过程中,这些变量将有助于思考数据在逻辑核上如何具体分配和执行,当然这只是笔者的观点,可以根据自己的编程习惯作调整。
2.3.1 tiling结构体定义及策略实现
首先确定tiling过程中所需的变量,参考官方样例,需要定义整块、尾块的个数及其中的元素个数,还需要定义最小对齐单位。op_host/sinh_custom_tiling.h代码如下:
#ifndef SINH_CUSTOM_TILING_H // 头文件保护记得加上,自动生成的文件中不包含
#define SINH_CUSTOM_TILING_H
#include "register/tilingdata_base.h"namespace optiling
{BEGIN_TILING_DATA_DEF(TilingData)TILING_DATA_FIELD_DEF(uint32_t, formerNum); // 整块个数TILING_DATA_FIELD_DEF(uint32_t, tailNum); // 尾块个数TILING_DATA_FIELD_DEF(uint32_t, formerLength); // 整块内元素个数TILING_DATA_FIELD_DEF(uint32_t, tailLength); // 尾块内元素个数TILING_DATA_FIELD_DEF(uint32_t, alignNum); // 最小对齐单位,元素个数END_TILING_DATA_DEF;REGISTER_TILING_DATA_CLASS(SinhCustom, TilingData)
}#endif然后在op_host/sinh_custom.cpp中实现具体的tiling策略,代码如下:
namespace optiling
{constexpr uint32_t BLOCK_DIM = 24; // 划分核心数量constexpr uint32_t SIZE_OF_HALF = 2; // 数据类型的字节数constexpr uint32_t BLOCK_SIZE = 32; // 昇腾设备上的数据block为32字节constexpr uint32_t ALIGN_NUM = BLOCK_SIZE / SIZE_OF_HALF; // 最小对齐单位static ge::graphStatus TilingFunc(gert::TilingContext *context){TilingData tiling;uint32_t totalLength = context->GetInputTensor(0)->GetShapeSize();context->SetBlockDim(BLOCK_DIM);// 使输入向上对齐uint32_t totalLengthAligned = ((totalLength + ALIGN_NUM - 1) / ALIGN_NUM) * ALIGN_NUM;// 计算整块和尾块个数uint32_t formerNum = (totalLengthAligned / ALIGN_NUM) % BLOCK_DIM;uint32_t tailNum = BLOCK_DIM - formerNum;// 计算整块和尾块的元素个数uint32_t formerLength = ((totalLengthAligned / BLOCK_DIM + ALIGN_NUM - 1) / ALIGN_NUM) * ALIGN_NUM;uint32_t tailLength = (totalLengthAligned / BLOCK_DIM / ALIGN_NUM) * ALIGN_NUM;// 设置tiling参数tiling.set_formerNum(formerNum);tiling.set_tailNum(tailNum);tiling.set_formerLength(formerLength);tiling.set_tailLength(tailLength);tiling.set_alignNum(ALIGN_NUM);// 以下为固定写法,不用纠结tiling.SaveToBuffer(context->GetRawTilingData()->GetData(), context->GetRawTilingData()->GetCapacity());context->GetRawTilingData()->SetDataSize(tiling.GetDataSize());context->SetTilingKey(1);size_t *currentWorkspace = context->GetWorkspaceSizes(1);currentWorkspace[0] = 0;return ge::GRAPH_SUCCESS;}
}2.3.2 kernel侧实现
有了上述实现的tiling策略,我们就可以根据数据划分的逻辑来确定kernel侧的具体实现。根据官方推荐的矢量编程范式,我们可以先将算子类的框架写出来,再慢慢填充内容。在op_kernel/sinh_custom.cpp中写出算子类框架。
using namespace AscendC; // 记得开启AscendC命名空间
constexpr int32_t BUFFER_NUM = 2; // TQue的缓冲数量,此处开启双Bufferclass KernelSinh
{
public:__aicore__ inline KernelSinh() {} // 类构造函数,无须任何代码__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, // 初始化函数的参数为输入、输出uint32_t formerNum, uint32_t tailNum, // 以及上面定义的一系列tiling参数uint32_t formerLength, uint32_t tailLength,uint32_t alignNum) { /* TODO */ }__aicore__ inline void Process() { /* TODO */ }private:__aicore__ inline void CopyIn() { /* TODO */ }__aicore__ inline void Compute() { /* TODO */ }__aicore__ inline void CopyOut() { /* TODO */ }private:/* TODO */
};第一步,分析算子类的私有数据成员。
首先一定需要的是用来管理内存的Tpipe,同时需要输入输出分别对应的TQue和GlobalTensor,同时每个逻辑核还需要直到当前处理的数据个数,所以需要一个变量tileLength来确定分片大小。
第二步,分析算子。
公式:$$ {\bf y}=\text{sinh}({\bf x})=\frac{e^{\bf x}-e^{-{\bf x}}}{2.0} $$
可以观察到,我们需要计算两个中间结果,分别是$e^{\bf x}$和$e^{-{\bf x}}$,所以需要相应的数据结构来存放这两个中间结果,Ascend C提供的TBuf可以很好的承担这一责任。
至此我们就将算子类需要的私有数据成员确定了下来。
TPipe pipe; // 用于操作队列
TBuf<QuePosition::VECCALC> tempBuf; // 存放中间结果
TQue<QuePosition::VECIN, BUFFER_NUM> inQueueX; // 输入队列
TQue<QuePosition::VECOUT, BUFFER_NUM> outQueueY; // 输出队列
GlobalTensor<DTYPE_X> xGm; // 输入数据对应的GM内存空间
GlobalTensor<DTYPE_Y> yGm; // 输出数据对应的GM内存空间
uint32_t tileLength; // 每个逻辑核需要知道分片数据个数第三步,完善算子类的初始化函数Init()。
在该函数中我们需要为GlobalTensor分配内存,并初始化相应的TQue,同时需要针对某些变量做合法性判断。
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y,uint32_t formerNum, uint32_t tailNum,uint32_t formerLength, uint32_t tailLength,uint32_t alignNum)
{if (GetBlockIdx() < formerNum){// 处理整块逻辑this->tileLength = formerLength;xGm.SetGlobalBuffer((__gm__ DTYPE_X *)x + formerLength * GetBlockIdx(), formerLength);yGm.SetGlobalBuffer((__gm__ DTYPE_Y *)y + formerLength * GetBlockIdx(), formerLength);}else{// 处理尾块逻辑this->tileLength = tailLength;xGm.SetGlobalBuffer((__gm__ DTYPE_X *)x + formerLength * formerNum + tailLength * (GetBlockIdx() - formerNum), tailLength);yGm.SetGlobalBuffer((__gm__ DTYPE_Y *)y + formerLength * formerNum + tailLength * (GetBlockIdx() - formerNum), tailLength);}ASSERT(alignNum != 0 && "align num can not be zero!");pipe.InitBuffer(inQueueX, BUFFER_NUM, (((this->tileLength + alignNum - 1) / alignNum) * alignNum) * sizeof(half));pipe.InitBuffer(outQueueY, BUFFER_NUM, (((this->tileLength + alignNum - 1) / alignNum) * alignNum) * sizeof(half));
}第四步,完成算子最核心的部分:根据矢量编程范式实现算子计算逻辑。
__aicore__ inline void CopyIn()
{LocalTensor<DTYPE_X> xLocal = inQueueX.AllocTensor<DTYPE_X>();DataCopy(xLocal, xGm, this->tileLength); // GM -> LMinQueueX.EnQue<DTYPE_X>(xLocal);
}
__aicore__ inline void Compute()
{LocalTensor<DTYPE_X> xLocal = inQueueX.DeQue<DTYPE_X>();LocalTensor<DTYPE_Y> yLocal = outQueueY.AllocTensor<DTYPE_Y>();pipe.InitBuffer(tempBuf, this->tileLength * sizeof(DTYPE_X));LocalTensor<DTYPE_X> tempLocal = tempBuf.Get<DTYPE_X>(this->tileLength);// 计算exp(x)Exp(yLocal, xLocal, this->tileLength);// 计算-xhalf nagOne(-1.0);Muls(tempLocal, xLocal, nagOne, this->tileLength);// 计算exp(-x)Exp(tempLocal, tempLocal, this->tileLength);// 计算exp(x)-exp(-x)Sub(yLocal, yLocal, tempLocal, this->tileLength);// 计算最终结果half denominator(0.5);Muls(yLocal, yLocal, denominator, this->tileLength);outQueueY.EnQue<DTYPE_Y>(yLocal);inQueueX.FreeTensor(xLocal);
}
__aicore__ inline void CopyOut()
{LocalTensor<DTYPE_Y> yLocal = outQueueY.DeQue<DTYPE_Y>();DataCopy(yGm, yLocal, this->tileLength); // LM -> GMoutQueueY.FreeTensor(yLocal);
}实现的具体细节与接口可以参考Ascend C官方文档。
第五步,将Process()函数补全,并完善核函数。
__aicore__ inline void Process()
{CopyIn();Compute();CopyOut();
}extern "C" __global__ __aicore__ void
sinh_custom(GM_ADDR x, GM_ADDR y, GM_ADDR workspace, GM_ADDR tiling)
{GET_TILING_DATA(tiling_data, tiling);KernelSinh op;op.Init(x, y,tiling_data.formerNum, tiling_data.tailNum,tiling_data.formerLength, tiling_data.tailLength,tiling_data.alignNum);if (TILING_KEY_IS(1)){op.Process();}
}至此就完成了kernel侧的实现。
2.3.3 host侧实现
我们回到op_host/sinh_custom.cpp,关于类型推导函数,这个算子输入输出的形状一致。msopgen生成的算子工程中,默认即为输入输出形状一致,所以无须改动。如果在写其他复杂算子的时候,需要仔细分析数据形状的变化。关于算子原型注册,也无须改动。
现在就完成了整个算子的逻辑,可以执行build.sh来验证有没有编译时错误,若没有错误则可以进行运行时验证。
3 核函数调用
笔者直接将官方的核函数调用样例拿来做了一些修改,需要修改的地方如下。
kernel_invocation
├── cmake
├── CMakeLists.txt
├── data_utils.h
├── input
├── main.cpp # 需要修改
├── output
├── run.sh # 需要修改
├── add_custom.cpp # 替换为自己的算子实现
├── add_custom.py # 需要修改
└── verify_result.py # 添加的代码,用于验证结果首先,将官方样例中的add_custom.cpp替换为自己实现的kernel侧算子,笔者这里的名称为sinh_custom.cpp。同时为了CPU侧调试,需要添加一个核函数的包装函数,代码如下。
#ifndef __CCE_KT_TEST__
void sinh_custom_do(uint32_t blockDim, void *l2ctrl, void *stream, uint8_t *x, uint8_t *y)
{sinh_custom<<<blockDim, l2ctrl, stream>>>(x, y);
}
#endif注意:为了快速验证逻辑,在核函数验证过程中未使用动态tiling,所以没有之前提到的那些tiling参数。
然后是sinh_custom.py,官方样例中是add_custom.py,这里修改文件名称,因为后面的run.sh中是通过算子文件名来调用这一python脚本的。
由于本算子只需要一个输入向量,所以只生成一个input数据,然后修改golden数据的生成方式,调用numpy中与算子功能相同的函数来计算,注意数据类型,代码如下。
import numpy as npdef gen_golden_data_simple():np.random.seed(42)input_x = np.random.randn(8, 2048).astype(np.float16)golden = np.sinh(input_x).astype(np.float16)print(f'-----------------------{input_x[0][0]}')input_x.tofile("./input/input_x.bin")golden.tofile("./output/golden.bin")if __name__ == "__main__":gen_golden_data_simple()main.cpp中要调整相应的内存申请等操作,只需要一个input,CPU侧调试和NPU侧调试的代码都需要修改,具体如下。
#include <stdio.h>#include "data_utils.h"
#ifndef __CCE_KT_TEST__
#include "acl/acl.h"
extern void sinh_custom_do(uint32_t coreDim, void *l2ctrl, void *stream, uint8_t *x, uint8_t *y);
#else
#include "tikicpulib.h"
extern "C" __global__ __aicore__ void sinh_custom(GM_ADDR x, GM_ADDR y);
#endifint32_t main(int32_t argc, char *argv[])
{size_t inputByteSize = 8 * 2048 * sizeof(uint16_t);size_t outputByteSize = 8 * 2048 * sizeof(uint16_t);uint32_t blockDim = 8;#ifdef __CCE_KT_TEST__uint8_t *x = (uint8_t *)AscendC::GmAlloc(inputByteSize);uint8_t *y = (uint8_t *)AscendC::GmAlloc(outputByteSize);ReadFile("./input/input_x.bin", inputByteSize, x, inputByteSize);AscendC::SetKernelMode(KernelMode::AIV_MODE);ICPU_RUN_KF(sinh_custom, blockDim, x, y);WriteFile("./output/output_y.bin", y, outputByteSize);AscendC::GmFree((void *)x);AscendC::GmFree((void *)y);
#elseCHECK_ACL(aclInit(nullptr));aclrtContext context;int32_t deviceId = 0;CHECK_ACL(aclrtSetDevice(deviceId));CHECK_ACL(aclrtCreateContext(&context, deviceId));aclrtStream stream = nullptr;CHECK_ACL(aclrtCreateStream(&stream));uint8_t *xHost, *yHost;uint8_t *xDevice, *yDevice;CHECK_ACL(aclrtMallocHost((void **)(&xHost), inputByteSize));CHECK_ACL(aclrtMallocHost((void **)(&yHost), outputByteSize));CHECK_ACL(aclrtMalloc((void **)&xDevice, inputByteSize, ACL_MEM_MALLOC_HUGE_FIRST));CHECK_ACL(aclrtMalloc((void **)&yDevice, outputByteSize, ACL_MEM_MALLOC_HUGE_FIRST));ReadFile("./input/input_x.bin", inputByteSize, xHost, inputByteSize);CHECK_ACL(aclrtMemcpy(xDevice, inputByteSize, xHost, inputByteSize, ACL_MEMCPY_HOST_TO_DEVICE));sinh_custom_do(blockDim, nullptr, stream, xDevice, yDevice);CHECK_ACL(aclrtSynchronizeStream(stream));CHECK_ACL(aclrtMemcpy(yHost, outputByteSize, yDevice, outputByteSize, ACL_MEMCPY_DEVICE_TO_HOST));WriteFile("./output/output_y.bin", yHost, outputByteSize);CHECK_ACL(aclrtFree(xDevice));CHECK_ACL(aclrtFree(yDevice));CHECK_ACL(aclrtFreeHost(xHost));CHECK_ACL(aclrtFreeHost(yHost));CHECK_ACL(aclrtDestroyStream(stream));CHECK_ACL(aclrtDestroyContext(context));CHECK_ACL(aclrtResetDevice(deviceId));CHECK_ACL(aclFinalize());
#endifreturn 0;
}原样例中的验证方式是求md5和,但由于核函数中调用了Exp、Muls等API,所以精度可能会有损失,不适合用md5sum的方式来验证。这里就需要引入新的文件verify_result.py,这里使用了numpy.isclose函数来进行验证,这也是官方单算子API调用的结果验证方式。
import sys
import math
import numpy as npdef data_compare(file1, file2,file3):input1 = np.fromfile(file1, dtype=np.float16)print("input1: ", input1)golden = np.fromfile(file2, dtype=np.float16)output = np.fromfile(file3, dtype=np.float16)print("output: ", output)print("-------------golden is :")print("golden: ", golden)different_element_results = np.isclose(output, golden,rtol=5e-2,atol=1e-3,equal_nan=True)different_element_indexes = np.where(different_element_results != np.array((True,)))[0]if different_element_indexes.size == 0:print("result correct!")else:print("result error!")return 0 if different_element_indexes.size == 0 else 1if __name__ == '__main__':intput_file1 = sys.argv[1]golden_file = sys.argv[2]output_file = sys.argv[3]cmp_result = data_compare(intput_file1, golden_file, output_file)if (cmp_result == 0):sys.exit(0)else:sys.exit(1)最后是修改run.sh脚本,需要修改的只有最后验证结果的部分。
原样例的验证方式是md5sum:
echo "md5sum: ";md5sum output/*.bin修改为调用脚本判断:
echo "result verification: " python3 verify_result.py ./input/input_x.bin ./output/golden.bin ./output/output_y.bin4 单算子API调用
单算子调用是通过自动生成的两段式API来执行的,为了快速验证,同样是将官方样例中的单算子API调用样例拿来做了一些修改。需要修改的几处关键代码如下。
aclnn_online_model
├── build
├── inc
├── README.md
├── run
│ └── out
│ ├── execute_sinh_op
│ ├── result_files
│ └── test_data
│ ├── config
│ └── data
│ ├── generate_data.py # 生成测试数据脚本,需要修改
├── run.sh # 需要修改
├── scripts
│ └── verify_result.py # 调整验证方式,例如相对和绝对误差参数等
└── src├── CMakeLists.txt # 需要修改├── common.cpp├── main.cpp # 需要修改├── operator_desc.cpp└── op_runner.cpp # 需要修改具体细节如下。
generate_data.py中,按照算子来修改测试数据生成方式。本算子需要half类型的测试数据,故代码改为:
import numpy as np
a = np.random.randn(8, 2048).astype(np.float16)
a.tofile('input_0.bin')verify_result.py中,根据实际读取的输入和输出,利用np.isclose来进行比较,该函数详细用法参考numpy官方文档。
import sys
import math
import numpy as npdef data_compare(file1, file2):input1 = np.fromfile(file1, dtype=np.float16)print("input1: ", input1)golden = np.sinh(input1).astype(np.float16)output = np.fromfile(file2, dtype=np.float16)print("output: ", output)print("-------------golden is :")print("golden: ", golden)different_element_results = np.isclose(output, golden,rtol=5e-2,atol=1e-3,equal_nan=True)different_element_indexes = np.where(different_element_results != np.array((True,)))[0]return 0 if different_element_indexes.size == 0 else 1if __name__ == '__main__':intput_file1 = sys.argv[1]output_file = sys.argv[2]cmp_result = data_compare(intput_file1, output_file)if (cmp_result == 0):sys.exit(0)else:sys.exit(1)main.cpp中,需要将CreateOpDesc()函数根据具体的输入输出来做修改。
OperatorDesc CreateOpDesc()
{std::vector<int64_t> shape{8, 2048};aclDataType dataType = ACL_FLOAT16;aclFormat format = ACL_FORMAT_ND;OperatorDesc opDesc;opDesc.AddInputTensorDesc(dataType, shape.size(), shape.data(), format);opDesc.AddOutputTensorDesc(dataType, shape.size(), shape.data(), format);return opDesc;
}op_runner.cpp中将两段式API修改为自己算子的API,请善用Ctrl + F搜索关键代码进行修改,具体的API名称可以查看算子目录下的build_out/autogen目录。
...
auto ret = aclnnSinhCustomGetWorkspaceSize(inputTensor_[0], outputTensor_[0], &workspaceSize, &handle);
...
INFO_LOG("Execute aclnnSinhCustomGetWorkspaceSize success, workspace size %lu", workspaceSize);
...
if (aclnnSinhCustom(workspace, workspaceSize, handle, stream) != ACL_SUCCESS)
{...
}
INFO_LOG("Execute aclnnSinhCustom success");
...接着修改src/CMakeLists.txt。
set(AUTO_GEN_PATH "../SinhCustom/build_out/autogen") # 16行# 50行以后,修改可执行文件的名称
add_executable(execute_sinh_op${AUTO_GEN_PATH}/aclnn_sinh_custom.cppoperator_desc.cppop_runner.cppmain.cppop_runner.cppcommon.cpp
)target_link_libraries(execute_sinh_opascendclacl_op_compilernnopbasestdc++
)install(TARGETS execute_sinh_op DESTINATION ${CMAKE_RUNTIME_OUTPUT_DIRECTORY})最后修改run.sh脚本中关于路径的部分。
修改完成后,就可以执行run.sh脚本进行单算子API调用了。
INFO: acl executable run success!
input1: [ 0.468 -0.2585 -3.066 ... 0.9136 -1.117 -1.368 ]
output: [ 0.485 -0.2615 -10.71 ... 1.047 -1.365 -1.837 ]
-------------golden is :
golden: [ 0.4854 -0.2615 -10.71 ... 1.046 -1.364 -1.837 ]
INFO: compare golden data success!出现上述提示证明算子通过验证。
5 Ascend C学习资源
Ascend C配套丰富的学习资料,包括教程文档、交流社区、案例代码等,这些资源将帮助您理解Ascend C编程语言的各种概念和技巧,为您的自主学习提供便利。
相关文章:

开发者分享 | Ascend C算子开发及单算子调用
本文分享自《AscendC算子开发及单算子调用》,作者:goldpancake。 笔者在阅读Ascend C官方文档的过程中发现,对于初学者来说,尤其是第一次接触异构编程思想的初学者,有部分内容是无需特别关注的,例如算子工…...
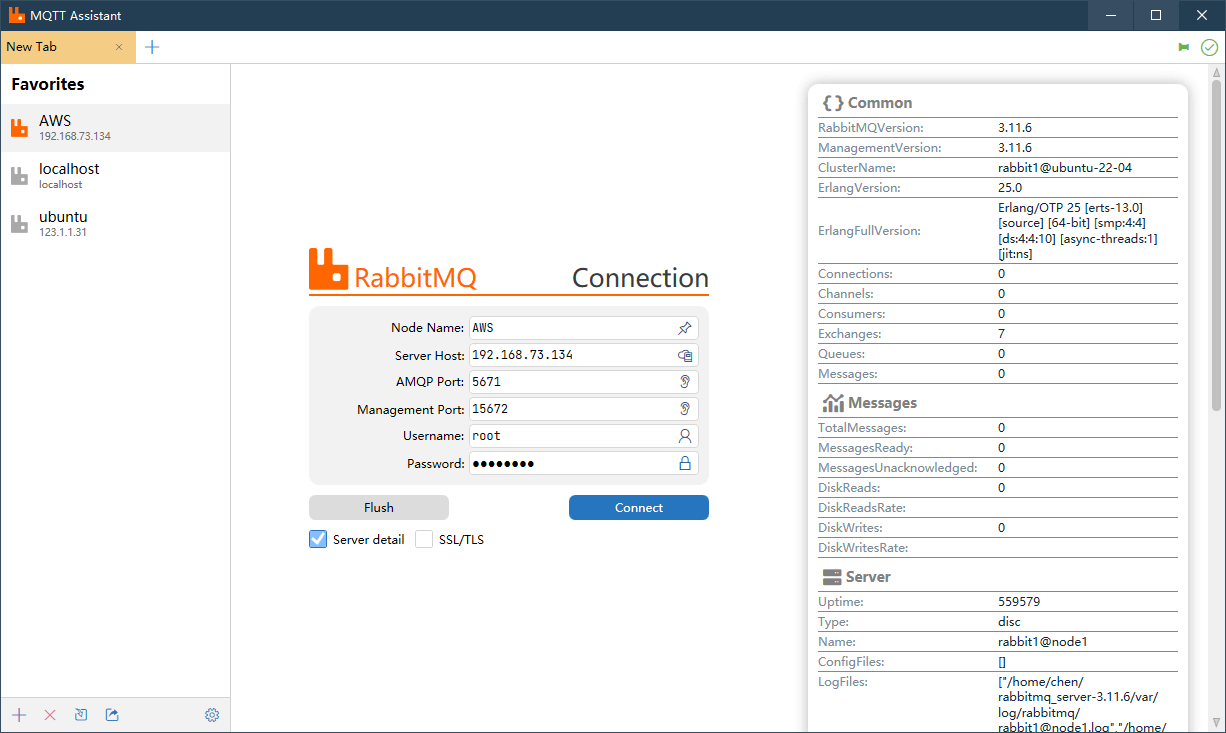
如何在 Linux 上部署 RabbitMQ
如何在 Linux 上部署 RabbitMQ 文章目录 如何在 Linux 上部署 RabbitMQ安装 Erlang从预构建的二进制包安装从源代码编译 Erlang RabbitMQ 的安装使用 RabbitMQ Assistant 连接 RabbitMQ Assistant 是一款优秀的RabbitMQ 可视化管理工具,提供丰富的管理功能。下载地址…...
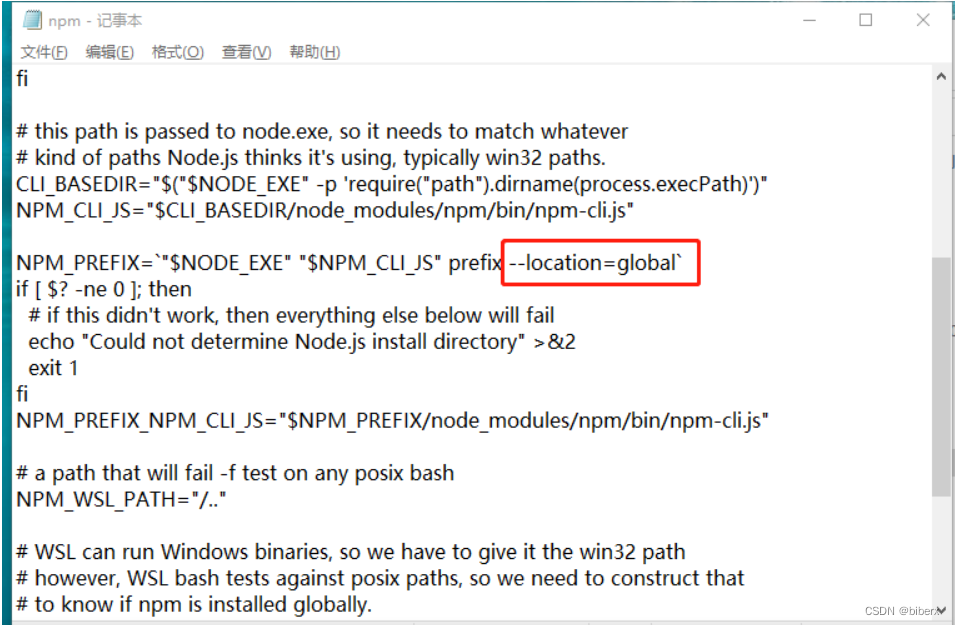
解决更换NodeJs版本后npm -v返回空白
一、问题描述 win11电脑上输入cmd进入控制台,输入 node --version 有正常返回安装的nodejs的版本号 再输入 npm -v 返回空白。正常情况应该是要返回版本号。 二、问题背景 最近准备学习vue,在不久前已经安装了NodeJs和python。运行了好几个开源项…...

【ES常用查询】基于ElasticsearchRestTemplate及NativeSearchQuery的查询
包含当前es所有的查询, 需要什么代码直接照搬,改个参数就行! 用的好请务必给我点赞!!!感谢爱你们!!! (周末更 筒) 为啥写这篇文章呢ÿ…...

全志XR806基于http的无线ota功能实验
XR806不仅硬件功能多,XR806也提供了功能极其丰富的SDK,几天体验下来非常容易上手。常见的功能几乎都有相应的cmd或demo实现,HAL也做得非常全面,非常适合快速开发。这一点超级好评!本文章要实现的无线OTA也基于该SDK。 …...
)
2023年11月15号期中测验选择题(Java)
本篇续接《2023年11月15号期中测验判断题(Java)》->传送门 2-1 以下程序运行结果是 public class Test extends Father{private String name"test";public static void main(String[] args){Test test new Test();System.out.println(tes…...

C# static关键字详解
在C#中,static关键字有许多重要的用途。以下是关于如何使用static关键字的一些详细信息: 静态类(Static Classes):静态类是不能实例化的类,它的所有成员都是静态的。静态类常常用作工具类或帮助类ÿ…...

开发一款回合制游戏,需要注意什么?
随着游戏行业的蓬勃发展,回合制游戏因其深度的策略性和令人着迷的游戏机制而受到玩家们的热烈欢迎。如果你计划投身回合制游戏的开发领域,本文将为你提供一份详细的指南,从游戏设计到发布,助你成功打造一款引人入胜的游戏。 1. 游…...
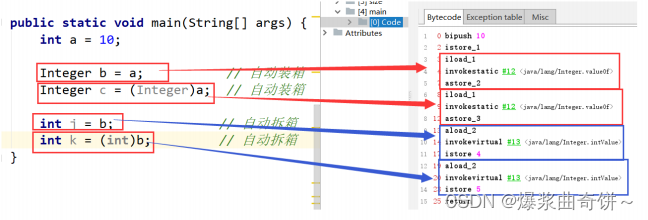
java的包装类
目录 1. 包装类 1.1 基本数据类型和对应的包装类 1.2 装箱和拆箱 1.3 自动装箱和自动拆箱 1. 包装类 在Java中,由于基本类型不是继承自Object,为了在泛型代码中可以支持基本类型,Java给每个基本类型都对应了 一个包装类型。 若想了解…...
】线性结构和非线性结构)
【数据结构(一)】线性结构和非线性结构
文章目录 线性结构和非线性结构1. 线性结构2. 非线性结构 线性结构和非线性结构 数据结构包括:线性结构和非线性结构。 1. 线性结构 线性结构作为最常用的数据结构,其特点是数据元素之间存在一对一的线性关系。线性结构有两种不同的存储结构ÿ…...
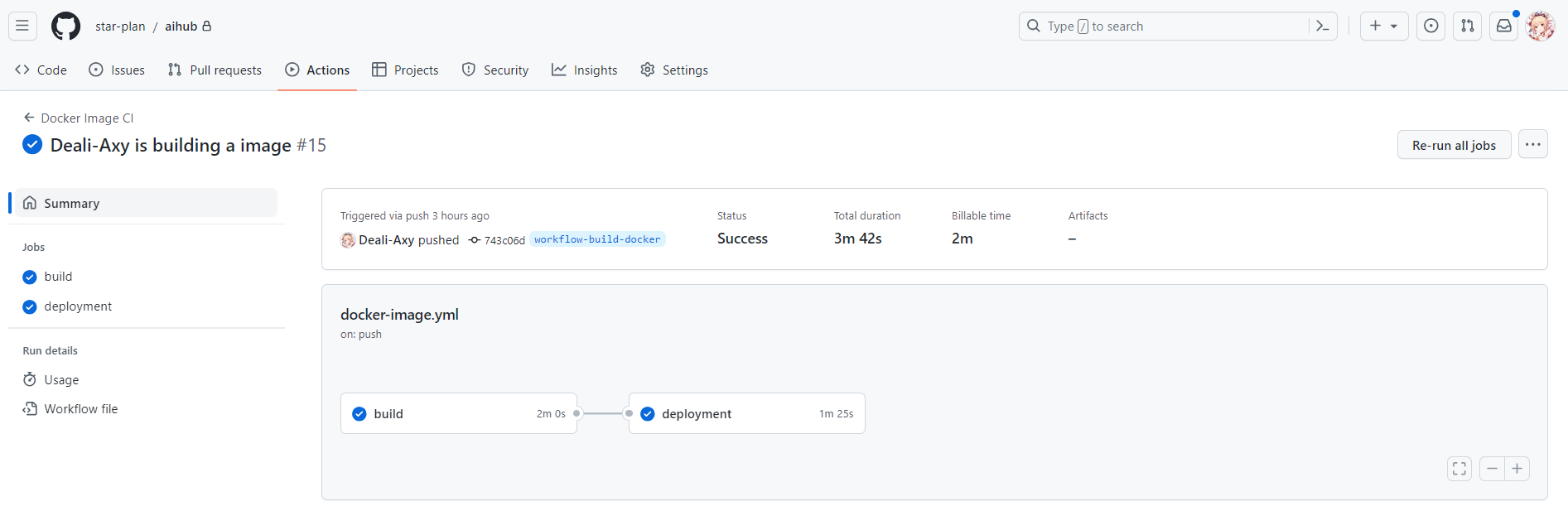
持续集成指南:GitHubAction 自动构建+部署AspNetCore项目
前言 之前研究了使用 GitHub Action 自动构建和发布 nuget 包:开发现代化的.NetCore控制台程序:(4)使用GithubAction自动构建以及发布nuget包 现在更进一步,使用 GitHub Action 在其提供的 runner 里构建 docker 镜像,之后提交到阿…...
--容器)
Docker 笔记(三)--容器
Docker 笔记(三)–容器 记录Docker 安装操作记录,便于查询。 参考 链接: Docker 入门到实战教程(三)镜像和容器链接: docker run中的-itd参数正确使用链接: docker官方文档链接: 阿里云Debian 镜像链接: Debian 全球镜像站链接: Debian/Ub…...

gd32关于IO引脚配置的一些问题
一、gd32f103的PA15问题 1、 #define GPIO_SWJ_NONJTRST_REMAP ((uint32_t)0x00300100U) /*!< full SWJ(JTAG-DP SW-DP),but without NJTRST */ #define GPIO_SWJ_SWDPENABLE_REMAP ((uint32_t)0x00300200U) /*!< JTAG-DP disabled and SW-DP enab…...

QT小记:警告Use multi-arg instead
"Use multi-arg instead" 是一个提示,建议使用 QObject::tr() 函数的多参数版本来处理多个占位符,而不是使用单参数版本。 在 Qt 中,tr() 是用于进行文本翻译(国际化)的函数。它允许你在应用程序中使用多种…...

皮肤性病科专家谭巍主任提出HPV转阴后饮食七点建议
HPV转阴是每一位感染者都期盼的,因为转阴所以健康,只有转为阴性才意味着不具备传染性,从此也不必再害怕将病毒传染给家人的风险,也不必再担忧持续感染而引发的健康风险。总之,HPV转阴是预示感染者恢复健康与否的主要标…...

快速弄懂C++中的智能指针
智能指针是C中的一个对象,它的行为类似于指针,但它提供了自动的内存管理功能。当智能指针超出作用域时(比如说在函数中使用智能指针指向了一个对象,当该函数结束时会自动销毁该对象),它会自动删除其所指向的…...
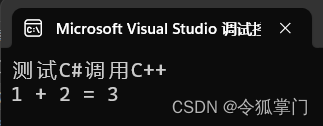
C#调用C++ dll教程
文章目录 一、创建C dll项目二、C#程序员调用C dll三、C与C#数据类型对应基本数据类型对应表C指针类型与C#类型 在使用C#开发客户端时,有时需要调用C dll,本篇博客来介绍C#程序如何调用C dll。 一、创建C dll项目 首先使用VS2022创建C dll项目…...

计算机毕设 深度学习 大数据 股票预测系统 - python lstm
文章目录 0 前言1 课题意义1.1 股票预测主流方法 2 什么是LSTM2.1 循环神经网络2.1 LSTM诞生 2 如何用LSTM做股票预测2.1 算法构建流程2.2 部分代码 3 实现效果3.1 数据3.2 预测结果项目运行展示开发环境数据获取 最后 0 前言 🔥 这两年开始毕业设计和毕业答辩的要…...
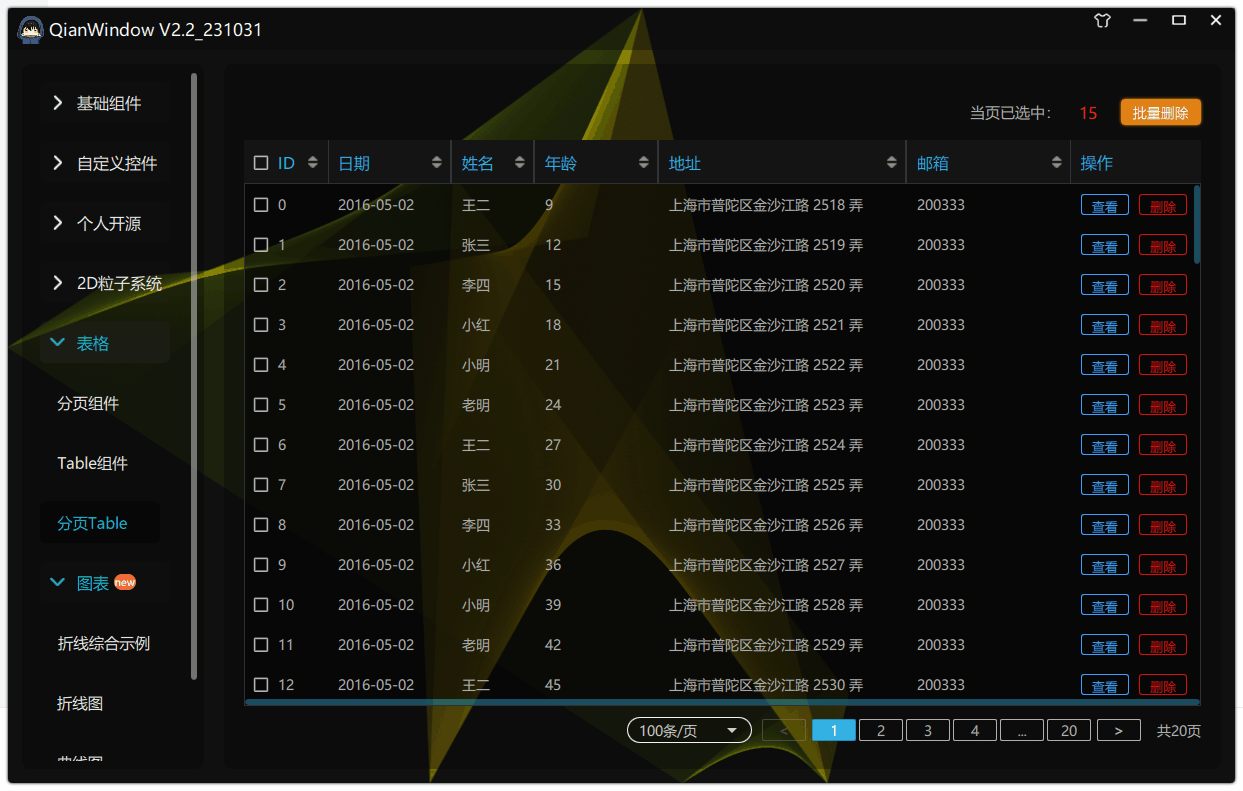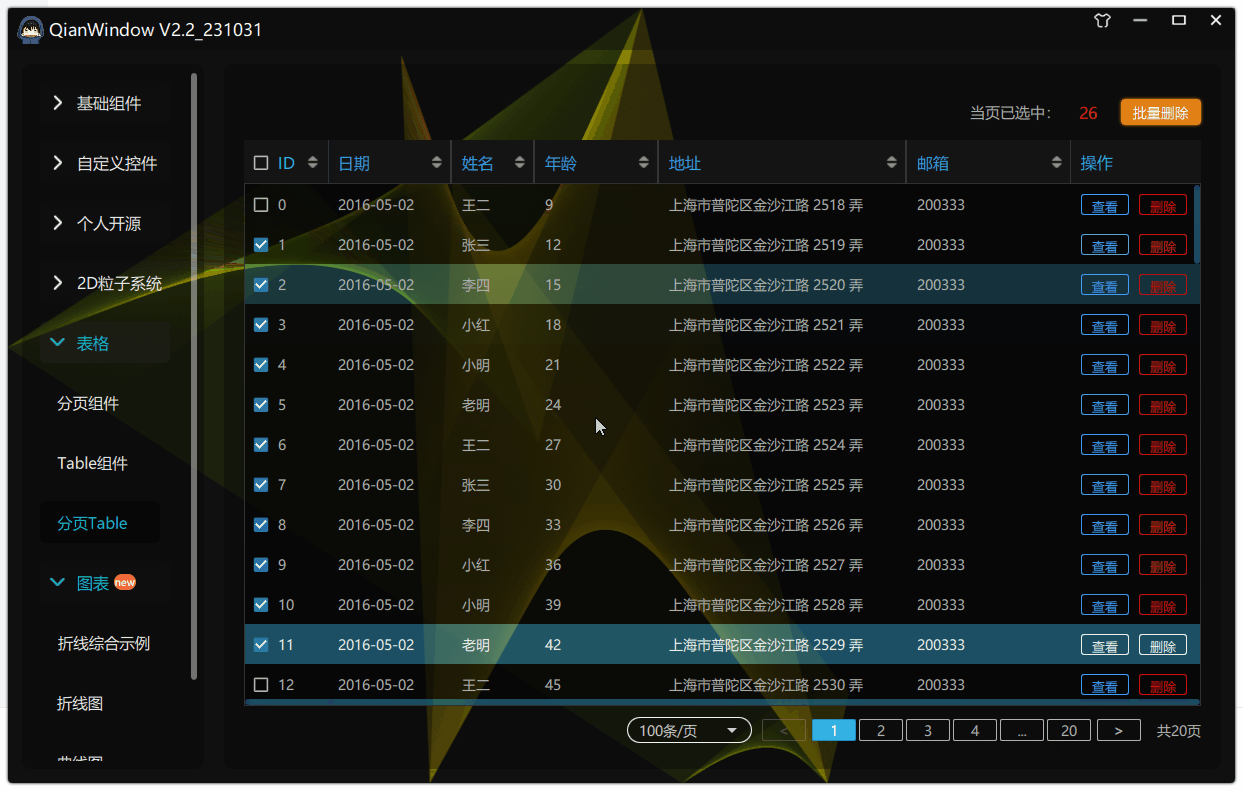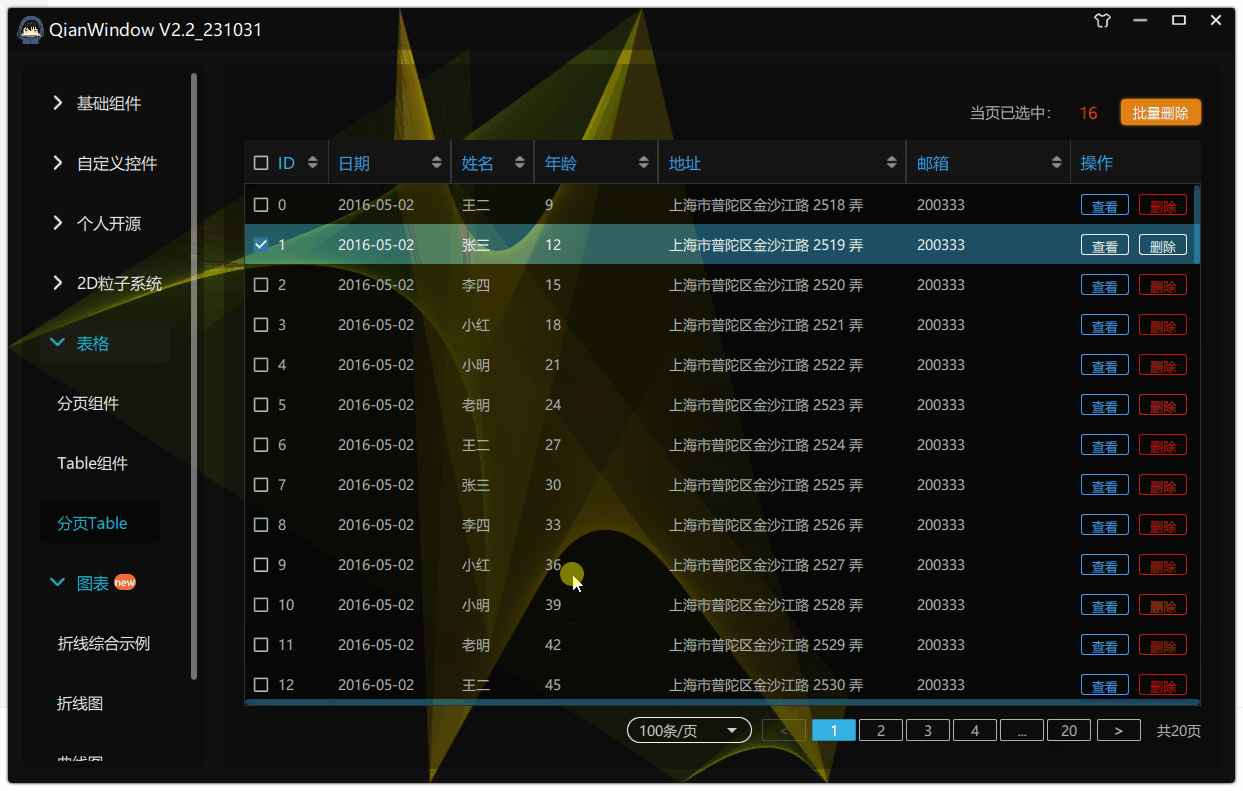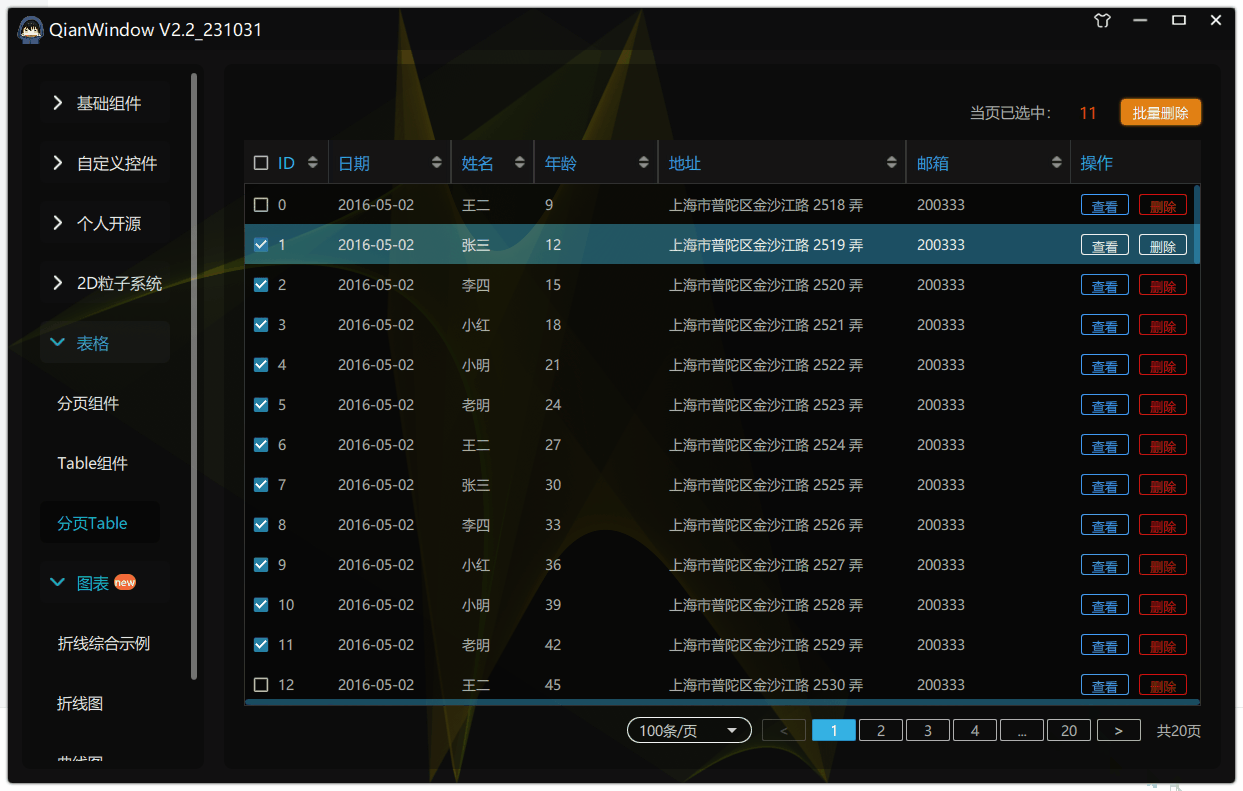
97.qt qml-自定义Table之实现ctrl与shift多选
我们之前实现了:93.qt qml-自定义Table优化(新增:水平拖拽/缩放自适应/选择使能/自定义委托)-CSDN博客 实现选择使能的时候,我们只能一行行去点击选中,非常麻烦,所以本章我们实现ctrl多选与shift多选、 所以在Table控件新增两个属性: 1.实现介绍 ctrl多选实现原理:当我…...

运行软件报错mfc140.dll丢失?分享mfc140.dll丢失的解决方法
小伙伴们,你是否也有过这样的经历:每当碰到诸如" mfc140.dll 丢失 "之类的烦人错误时,你是不是会一头雾水,完全不知道从何下手去解决?不要担心,接下来咱就给你提供这样一篇实用教程,教…...

2605.VGGT-Omega 论文解读: 3D重建的Scaling Law, Register Attention效率革命 | Oxford+Meta CVPR26 Oral
VGGT-Omega: Scaling Feed-Forward 3D Reconstruction Jianyuan Wang, Minghao Chen, Shangzhan Zhang, Nikita Karaev, Johannes Schonberger, et al. Visual Geometry Group, Oxford Meta AI | CVPR 2026 Oral | arXiv 2605.15195 Paper | Project Page 一句话总结 VGGT-Om…...

一次搞懂内存取证:用Volatility3和Cobalt Strike分析工具复现VNCTF‘来一把紧张刺激的CS’
实战内存取证:从Volatility3到Cobalt Strike信标分析全解析 在网络安全事件响应中,内存取证往往是发现高级威胁的最后一道防线。当攻击者使用文件无落地的技术时,传统的磁盘取证可能一无所获,而内存中却保留着攻击行为的完整痕迹。…...
 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南)
SAP-ABAP:变量、常量、结构与内表声明(10篇博客合集) 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南
变量、常量、结构与内表声明(10篇博客合集) 第五篇:声明时的键值设计技巧:结构与内表的主键、非主键配置指南如果把内表比作一张内存中的“数据库表”,那么键就是这张表的索引甚至主键。键的设计直接决定了数据的唯一性…...

科华UPS电源全品类汇总:选型与场景适配指南
科华UPS电源作为国内智慧电能领域的主流产品,覆盖家用、办公、机房、工业等全场景,产品系列丰富、规格齐全,但多数用户在选型时,常因分不清系列差异、功率适配、架构类型而踩坑。本文系统汇总科华UPS电源的核心分类、主流系列、核…...

电信运营商每月处理海量工单,如何不再出错?基于AI Agent的端到端自动化解决方案
在2026年的电信行业,海量工单处理已不再仅仅是效率问题,而是合规与生存的底线。随着2026年5月20日《电信和互联网服务 基础电信企业网上营业厅服务规范》国家标准的正式实施,监管层对“信息透明、流程闭环、计费精准”的要求达到了前所未有的…...

在多轮对话应用中观察Taotoken计费对成本的影响
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多轮对话应用中观察Taotoken计费对成本的影响 效果展示类,结合一个需要维护长上下文的多轮对话应用案例,…...

为什么鸿蒙 App 最终都会走向状态驱动?
子玥酱 (掘金 / 知乎 / CSDN / 简书 同名) 大家好,我是 子玥酱,一名长期深耕在一线的前端程序媛 👩💻。曾就职于多家知名互联网大厂,目前在某国企负责前端软件研发相关工作,主要聚…...

基于USB ACA模式实现安卓手机边玩边充的游戏手柄设计
1. 项目缘起:当手机性能过剩,却败给了触摸屏几年前,我清理手机游戏时,发现一个挺无奈的现象:性能足以媲美掌机的智能手机里,只剩下一些慢节奏的平台解谜或者数独。那些曾经让我在掌机上废寝忘食的赛车、动作…...

如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析
如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析 【免费下载链接】Magpie-LuckyDraw 🏅A fancy lucky-draw tool supporting multiple platforms💻(Mac/Linux/Windows/Web/Docker) 项目地址: https…...

为什么你的Midjourney雾效总像“水汽”而非“山岚”?——资深CG总监拆解大气散射物理模型在--v 6.1中的3层映射偏差
更多请点击: https://kaifayun.com 第一章:为什么你的Midjourney雾效总像“水汽”而非“山岚”? Midjourney 生成的雾气常呈现为均匀、半透明、边界模糊的“水汽感”——厚重、潮湿、缺乏层次与呼吸感。这并非模型能力不足,而是提…...