计算机毕设 深度学习 大数据 股票预测系统 - python lstm
文章目录
- 0 前言
- 1 课题意义
- 1.1 股票预测主流方法
- 2 什么是LSTM
- 2.1 循环神经网络
- 2.1 LSTM诞生
- 2 如何用LSTM做股票预测
- 2.1 算法构建流程
- 2.2 部分代码
- 3 实现效果
- 3.1 数据
- 3.2 预测结果
- 项目运行展示
- 开发环境
- 数据获取
- 最后
0 前言
🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
🚩 深度学习 大数据 股票预测系统
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
1 课题意义
利用神经网络模型如果能够提高对股票价格的预测精度,更好地掌握股票价格发展趋势,这对于投资者来说可以及时制定相应的发展策略,更好地应对未来发生的不确定性事件,对于个人来说可以降低投资风险,减少财产损失,实现高效投资,具有一定的实践价值。
1.1 股票预测主流方法
股票市场复杂、非线性的特点使我们难以捉摸其变化规律,目前有很多预测股票走势的论文和算法。
定量分析从精确的数据资料中获得股票发展的价值规律,通过建立模型利用数学语言对股市的发展情况做出解释与预测。
目前常用的定量分析方法有:
- 传统时间序列预测模型
- 马尔可夫链预测
- 灰色系统理论预测
- 遗传算法
- 机器学习预测等方法
2 什么是LSTM
LSTM是长短期记忆网络(LSTM,Long Short-Term Memory),想要理解什么是LSTM,首先要了解什么是循环神经网络。
2.1 循环神经网络
对于传统的BP神经网络如深度前馈网络、卷积神经网络来说,同层及跨层之间的神经元是独立的,但实际应用中对于一些有上下联系的序列来说,如果能够学习到它们之间的相互关系,使网络能够对不同时刻的输入序列产生一定的联系,像生物的大脑一样有“记忆功能”,这样的话我们的模型也就会有更低的训练出错频率及更好的泛化能力。
JordanMI提出序列理论,描述了一种体现“并行分布式处理”的网络动态系统,适用于语音生成中的协同发音问题,并进行了相关仿真实验,ElmanJL认为连接主义模型中对时间如何表示是至关重要的,1990年他提出使用循环连接为网络提供动态内存,从相对简单的异或问题到探寻单词的语义特征,网络均学习到了有趣的内部表示,网络还将任务需求和内存需求结合在一起,由此形成了简单循环网络的基础框架。
循环神经网络(RNN)之间的神经元是相互连接的,不仅在层与层之间的神经元建立连接,而且每一层之间的神经元也建立了连接,隐藏层神经元的输入由当前输入和上一时刻隐藏层神经元的输出共同决定,每一时刻的隐藏层神经元记住了上一时刻隐藏层神经元的输出,相当于对网络增添了“记忆”功能。我们都知道在输入序列中不可避免会出现重复或相似的某些序列信息,我们希望RNN能够保留这些记忆信息便于再次调用,且RNN结构中不同时刻参数是共享的,这一优点便于网络在不同位置依旧能将该重复信息识别出来,这样一来模型的泛化能力自然有所上升。
RNN结构如下:
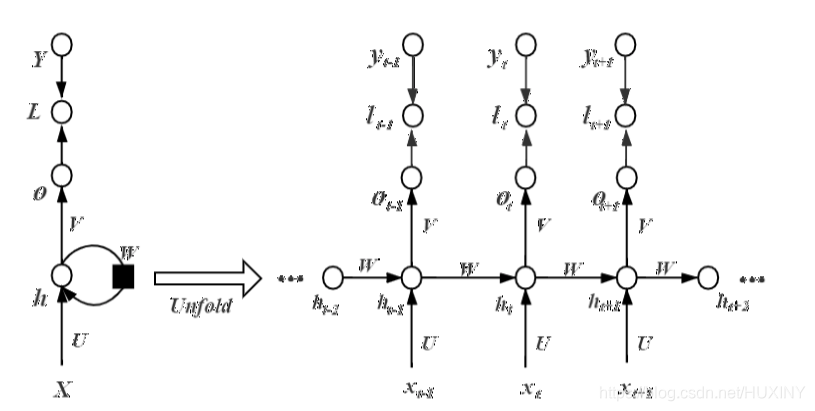
2.1 LSTM诞生
RNN在解决长序列问题时未能有良好的建模效果,存在长期依赖的弊端,对此HochreiterS等人对神经单元做出了改进,引入自循环使梯度信息得以长时间持续流动,即模型可以拥有长期记忆信息,且自循环权重可以根据前后信息进行调整并不是固定的。作为RNN的一种特殊结构,它可以根据前后输入情况决定历史信息的去留,增进的门控机制可以动态改变累积的时间尺度进而控制神经单元的信息流,这样神经网络便能够自己根据情况决定清除或保留旧的信息,不至于状态信息过长造成网络崩溃,这便是长短期记忆(LSTM)网络。随着信息不断流入,该模型每个神经元内部的遗忘门、输入门、输出门三个门控机制会对每一时刻的信息做出判断并及时进行调整更新,LSTM模型现已广泛应用于无约束手写识别、语音识别、机器翻译等领域。
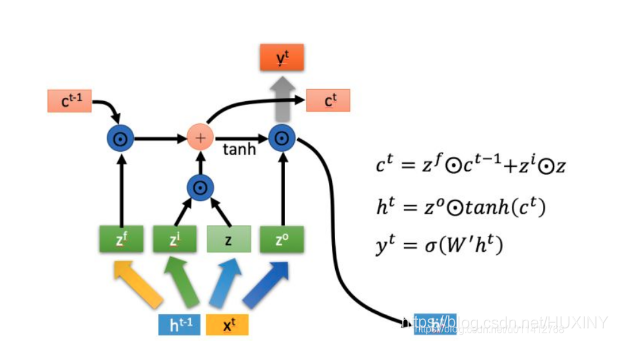
2 如何用LSTM做股票预测
2.1 算法构建流程

2.2 部分代码
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import pandas as pd
import mathdef LSTMtest(data):n1 = len(data[0]) - 1 #因为最后一位为labeln2 = len(data)print(n1, n2)# 设置常量input_size = n1 # 输入神经元个数rnn_unit = 10 # LSTM单元(一层神经网络)中的中神经元的个数lstm_layers = 7 # LSTM单元个数output_size = 1 # 输出神经元个数(预测值)lr = 0.0006 # 学习率train_end_index = math.floor(n2*0.9) # 向下取整print('train_end_index', train_end_index)# 前90%数据作为训练集,后10%作为测试集# 获取训练集# time_step 时间步,batch_size 每一批次训练多少个样例def get_train_data(batch_size=60, time_step=20, train_begin=0, train_end=train_end_index):batch_index = []data_train = data[train_begin:train_end]normalized_train_data = (data_train - np.mean(data_train, axis=0)) / np.std(data_train, axis=0) # 标准化train_x, train_y = [], [] # 训练集for i in range(len(normalized_train_data) - time_step):if i % batch_size == 0:# 开始位置batch_index.append(i)# 一次取time_step行数据# x存储输入维度(不包括label) :X(最后一个不取)# 标准化(归一化)x = normalized_train_data[i:i + time_step, :n1]# y存储labely = normalized_train_data[i:i + time_step, n1, np.newaxis]# np.newaxis分别是在行或列上增加维度train_x.append(x.tolist())train_y.append(y.tolist())# 结束位置batch_index.append((len(normalized_train_data) - time_step))print('batch_index', batch_index)# print('train_x', train_x)# print('train_y', train_y)return batch_index, train_x, train_y# 获取测试集def get_test_data(time_step=20, test_begin=train_end_index+1):data_test = data[test_begin:]mean = np.mean(data_test, axis=0)std = np.std(data_test, axis=0) # 矩阵标准差# 标准化(归一化)normalized_test_data = (data_test - np.mean(data_test, axis=0)) / np.std(data_test, axis=0)# " // "表示整数除法。有size个sampletest_size = (len(normalized_test_data) + time_step - 1) // time_stepprint('test_size$$$$$$$$$$$$$$', test_size)test_x, test_y = [], []for i in range(test_size - 1):x = normalized_test_data[i * time_step:(i + 1) * time_step, :n1]y = normalized_test_data[i * time_step:(i + 1) * time_step, n1]test_x.append(x.tolist())test_y.extend(y)test_x.append((normalized_test_data[(i + 1) * time_step:, :n1]).tolist())test_y.extend((normalized_test_data[(i + 1) * time_step:, n1]).tolist())return mean, std, test_x, test_y# ——————————————————定义神经网络变量——————————————————# 输入层、输出层权重、偏置、dropout参数# 随机产生 w,bweights = {'in': tf.Variable(tf.random_normal([input_size, rnn_unit])),'out': tf.Variable(tf.random_normal([rnn_unit, 1]))}biases = {'in': tf.Variable(tf.constant(0.1, shape=[rnn_unit, ])),'out': tf.Variable(tf.constant(0.1, shape=[1, ]))}keep_prob = tf.placeholder(tf.float32, name='keep_prob') # dropout 防止过拟合# ——————————————————定义神经网络——————————————————def lstmCell():# basicLstm单元# tf.nn.rnn_cell.BasicLSTMCell(self, num_units, forget_bias=1.0,# tate_is_tuple=True, activation=None, reuse=None, name=None) # num_units:int类型,LSTM单元(一层神经网络)中的中神经元的个数,和前馈神经网络中隐含层神经元个数意思相同# forget_bias:float类型,偏置增加了忘记门。从CudnnLSTM训练的检查点(checkpoin)恢复时,必须手动设置为0.0。# state_is_tuple:如果为True,则接受和返回的状态是c_state和m_state的2-tuple;如果为False,则他们沿着列轴连接。后一种即将被弃用。# (LSTM会保留两个state,也就是主线的state(c_state),和分线的state(m_state),会包含在元组(tuple)里边# state_is_tuple=True就是判定生成的是否为一个元组)# 初始化的 c 和 a 都是zero_state 也就是都为list[]的zero,这是参数state_is_tuple的情况下# 初始state,全部为0,慢慢的累加记忆# activation:内部状态的激活函数。默认为tanh# reuse:布尔类型,描述是否在现有范围中重用变量。如果不为True,并且现有范围已经具有给定变量,则会引发错误。# name:String类型,层的名称。具有相同名称的层将共享权重,但为了避免错误,在这种情况下需要reuse=True.#basicLstm = tf.nn.rnn_cell.BasicLSTMCell(rnn_unit, forget_bias=1.0, state_is_tuple=True)# dropout 未使用drop = tf.nn.rnn_cell.DropoutWrapper(basicLstm, output_keep_prob=keep_prob)return basicLstmdef lstm(X): # 参数:输入网络批次数目batch_size = tf.shape(X)[0]time_step = tf.shape(X)[1]w_in = weights['in']b_in = biases['in']# 忘记门(输入门)# 因为要进行矩阵乘法,所以reshape# 需要将tensor转成2维进行计算input = tf.reshape(X, [-1, input_size])input_rnn = tf.matmul(input, w_in) + b_in# 将tensor转成3维,计算后的结果作为忘记门的输入input_rnn = tf.reshape(input_rnn, [-1, time_step, rnn_unit])print('input_rnn', input_rnn)# 更新门# 构建多层的lstmcell = tf.nn.rnn_cell.MultiRNNCell([lstmCell() for i in range(lstm_layers)])init_state = cell.zero_state(batch_size, dtype=tf.float32)# 输出门w_out = weights['out']b_out = biases['out']# output_rnn是最后一层每个step的输出,final_states是每一层的最后那个step的输出output_rnn, final_states = tf.nn.dynamic_rnn(cell, input_rnn, initial_state=init_state, dtype=tf.float32)output = tf.reshape(output_rnn, [-1, rnn_unit])# 输出值,同时作为下一层输入门的输入pred = tf.matmul(output, w_out) + b_outreturn pred, final_states# ————————————————训练模型————————————————————def train_lstm(batch_size=60, time_step=20, train_begin=0, train_end=train_end_index):# 于是就有了tf.placeholder,# 我们每次可以将 一个minibatch传入到x = tf.placeholder(tf.float32,[None,32])上,# 下一次传入的x都替换掉上一次传入的x,# 这样就对于所有传入的minibatch x就只会产生一个op,# 不会产生其他多余的op,进而减少了graph的开销。X = tf.placeholder(tf.float32, shape=[None, time_step, input_size])Y = tf.placeholder(tf.float32, shape=[None, time_step, output_size])batch_index, train_x, train_y = get_train_data(batch_size, time_step, train_begin, train_end)# 用tf.variable_scope来定义重复利用,LSTM会经常用到with tf.variable_scope("sec_lstm"):pred, state_ = lstm(X) # pred输出值,state_是每一层的最后那个step的输出print('pred,state_', pred, state_)# 损失函数# [-1]——列表从后往前数第一列,即pred为预测值,Y为真实值(Label)#tf.reduce_mean 函数用于计算张量tensor沿着指定的数轴(tensor的某一维度)上的的平均值loss = tf.reduce_mean(tf.square(tf.reshape(pred, [-1]) - tf.reshape(Y, [-1])))# 误差loss反向传播——均方误差损失# 本质上是带有动量项的RMSprop,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。# Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳.train_op = tf.train.AdamOptimizer(lr).minimize(loss)saver = tf.train.Saver(tf.global_variables(), max_to_keep=15)with tf.Session() as sess:# 初始化sess.run(tf.global_variables_initializer())theloss = []# 迭代次数for i in range(200):for step in range(len(batch_index) - 1):# sess.run(b, feed_dict = replace_dict)state_, loss_ = sess.run([train_op, loss],feed_dict={X: train_x[batch_index[step]:batch_index[step + 1]],Y: train_y[batch_index[step]:batch_index[step + 1]],keep_prob: 0.5})# 使用feed_dict完成矩阵乘法 处理多输入# feed_dict的作用是给使用placeholder创建出来的tensor赋值# [batch_index[step]: batch_index[step + 1]]这个区间的X与Y# keep_prob的意思是:留下的神经元的概率,如果keep_prob为0的话, 就是让所有的神经元都失活。print("Number of iterations:", i, " loss:", loss_)theloss.append(loss_)print("model_save: ", saver.save(sess, 'model_save2\\modle.ckpt'))print("The train has finished")return thelosstheloss = train_lstm()# 相对误差=(测量值-计算值)/计算值×100%test_y = np.array(test_y) * std[n1] + mean[n1]test_predict = np.array(test_predict) * std[n1] + mean[n1]acc = np.average(np.abs(test_predict - test_y[:len(test_predict)]) / test_y[:len(test_predict)])print("预测的相对误差:", acc)print(theloss)plt.figure()plt.plot(list(range(len(theloss))), theloss, color='b', )plt.xlabel('times', fontsize=14)plt.ylabel('loss valuet', fontsize=14)plt.title('loss-----blue', fontsize=10)plt.show()# 以折线图表示预测结果plt.figure()plt.plot(list(range(len(test_predict))), test_predict, color='b', )plt.plot(list(range(len(test_y))), test_y, color='r')plt.xlabel('time value/day', fontsize=14)plt.ylabel('close value/point', fontsize=14)plt.title('predict-----blue,real-----red', fontsize=10)plt.show()prediction()
需要完整代码工程的同学,请联系学长获取
3 实现效果
3.1 数据
采集股票数据

任选几支股票作为研究对象。
3.2 预测结果



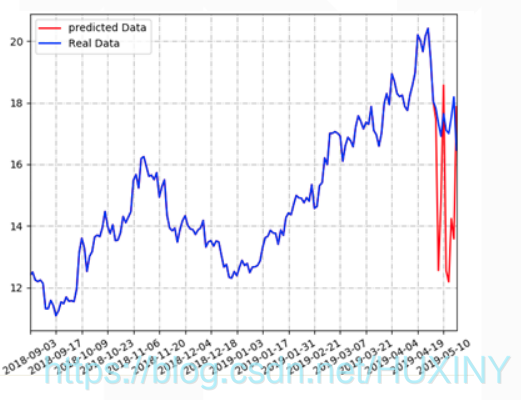
项目运行展示
废话不多说, 先展示项目运行结果, 后面才进行技术讲解
对某公司的股票进行分析和预测 :

开发环境
如果只运行web项目,则只需安装如下包:
-
python 3.6.x
-
django >= 2.1.4 (或者使用conda安装最新版)
-
pandas >= 0.23.4 (或者使用conda安装最新版)
-
numpy >= 1.15.2 (或者使用conda安装最新版)
*apscheduler = 2.1.2 (请用pip install apscheduler==2.1.2 安装,conda装的版本不兼容)
如果需要训练模型或者使用模型来预测(注:需要保证本机拥有 NVIDIA GPU以及显卡驱动),则还需要安装: -
tensorflow-gpu >= 1.10.0 (可以使用conda安装最新版。如用conda安装,cudatoolkit和cudnn会被自动安装)
-
cudatoolkit >= 9.0 (根据自己本机的显卡型号决定,请去NVIDIA官网查看)
-
cudnn >= 7.1.4 (版本与cudatoolkit9.0对应的,其他版本请去NVIDIA官网查看对应的cudatoolkit版本)
-
keras >= 2.2.2 (可以使用conda安装最新版)
-
matplotlib >= 2.2.2 (可以使用conda安装最新版)
数据获取
训练模型的数据,即10个公司的历史股票数据。获取国内上市公司历史股票数据, 并以csv格式保存下来。csv格式方便用pandas读取,输入到LSTM神经网络模型, 用于训练模型以及预测股票数据。
最后
相关文章:
计算机毕设 深度学习 大数据 股票预测系统 - python lstm
文章目录 0 前言1 课题意义1.1 股票预测主流方法 2 什么是LSTM2.1 循环神经网络2.1 LSTM诞生 2 如何用LSTM做股票预测2.1 算法构建流程2.2 部分代码 3 实现效果3.1 数据3.2 预测结果项目运行展示开发环境数据获取 最后 0 前言 🔥 这两年开始毕业设计和毕业答辩的要…...
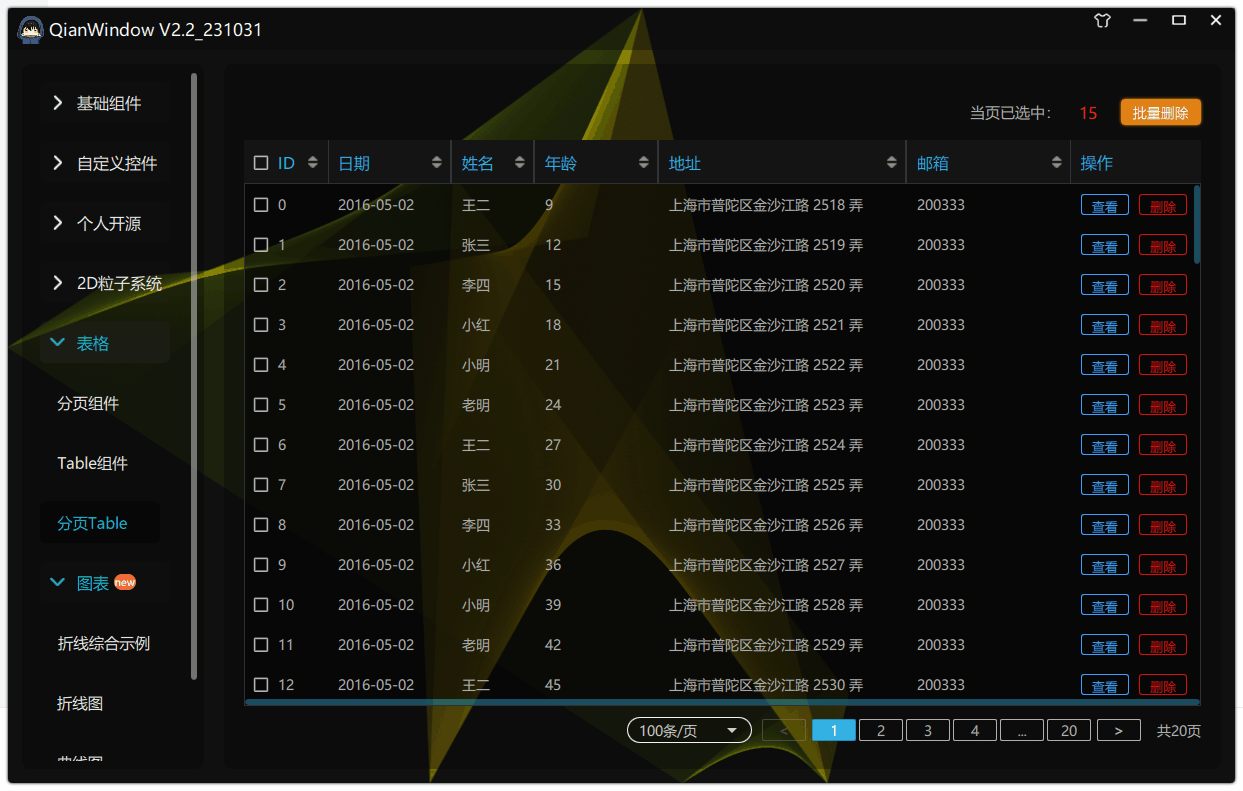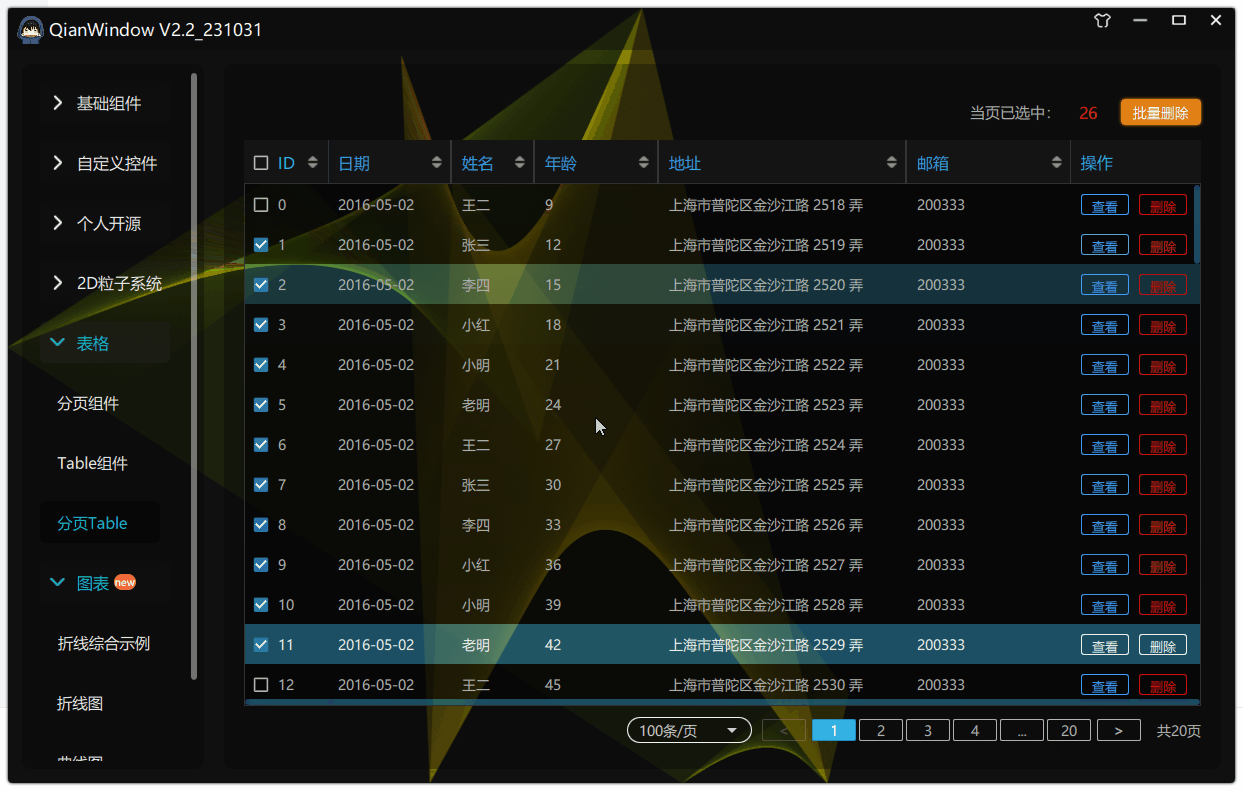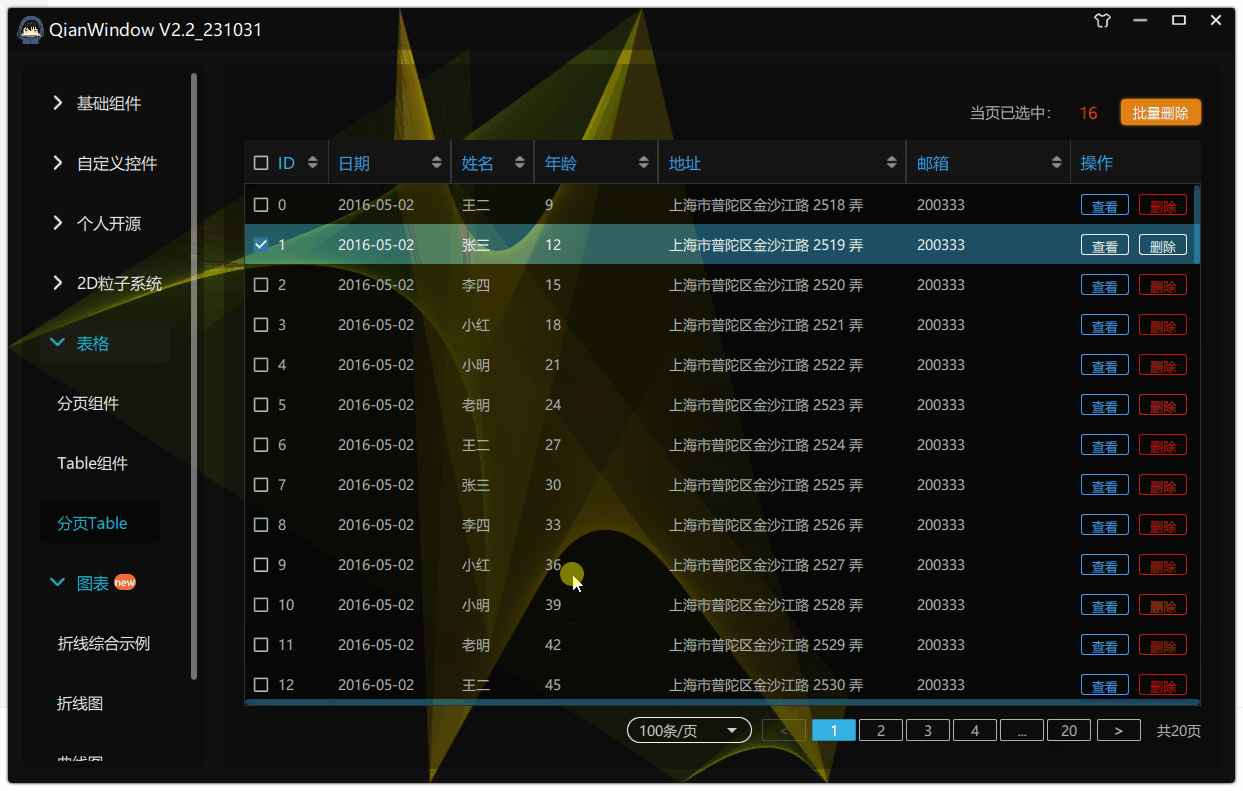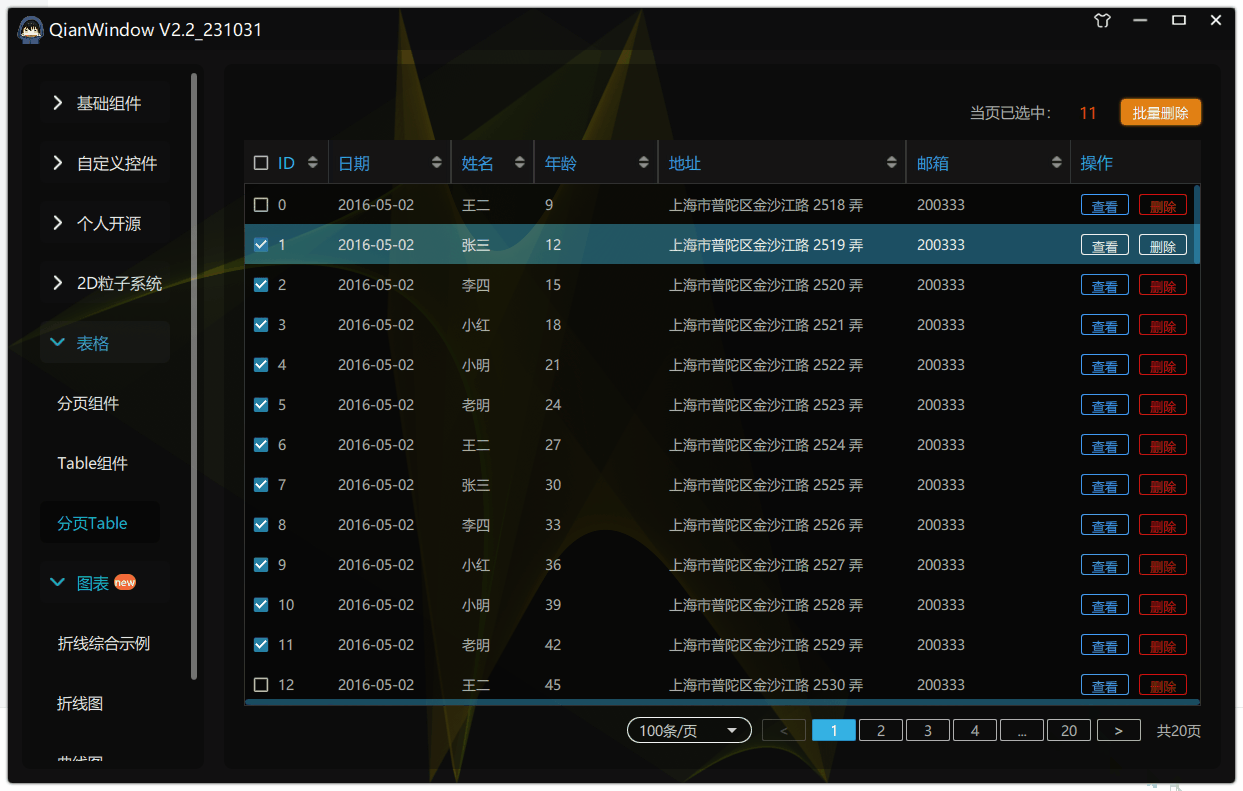
97.qt qml-自定义Table之实现ctrl与shift多选
我们之前实现了:93.qt qml-自定义Table优化(新增:水平拖拽/缩放自适应/选择使能/自定义委托)-CSDN博客 实现选择使能的时候,我们只能一行行去点击选中,非常麻烦,所以本章我们实现ctrl多选与shift多选、 所以在Table控件新增两个属性: 1.实现介绍 ctrl多选实现原理:当我…...

运行软件报错mfc140.dll丢失?分享mfc140.dll丢失的解决方法
小伙伴们,你是否也有过这样的经历:每当碰到诸如" mfc140.dll 丢失 "之类的烦人错误时,你是不是会一头雾水,完全不知道从何下手去解决?不要担心,接下来咱就给你提供这样一篇实用教程,教…...

milvus数据库-连接
Milvus 支持 19530 和 9091 两个端口: 端口 19530 用于 gRPC 和 RESTful API。 这是您使用不同 Milvus SDK 或 HTTP 客户端连接到 Milvus 服务器时的默认端口。 端口 9091 用于 Kubernetes 内的指标收集、pprof 分析和运行状况探测。 它用作管理端口。 1.连接到数…...

ios + vue3 Teleport + inset 兼容性问题
目录 1,问题表现2,解决步骤1,teleport 的问题2,inset 的问题3,teleport 的问题之二 1,问题表现 使用 vue3 的 Teleport 实现的 dialog 弹窗,但是在 ios app 中嵌套的 h5 中无法打开。 直接在io…...
)
计蒜客T1654 数列分段(C语言实现)
【题目描述】对于给定的一个长度为n的正整数数列ai,现要将其分成连续的若干段,并且每段和不超过m(可以等于m),问最少能将其分成多少段使得满足要求。 【输入格式】第一行包含两个正整数n,m,表示…...
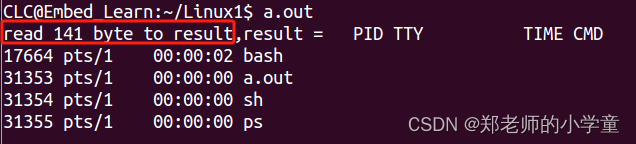
Linux进程——system函数、popen函数
system函数(执行shell 命令) 头文件 #include <stdlib.h> 函数定义 int system(const char * string); 函数说明 system()会调用fork()产生子进程,由子进程来调用/bin/sh-c string来执行参数string字符串所代表的命令,…...
【智能家居】5、主流程设计以及外设框架编写与测试
目录 一、主流程设计 1、工厂模式结构体定义 (1)指令工厂 inputCmd.h (2)外设工厂 controlDevices.h 二、外设框架编写 1、创建外设工厂对象bathroomLight 2、编写相关函数框架 3、将浴室灯相关操作插入外设工厂链表等待被调…...
详解ssh远程登录服务
华子目录 简介概念功能 分类文字接口图形接口 文字接口ssh连接服务器浅浅介绍一下加密技术凯撒加密加密分类对称加密非对称加密非对称加密方法(也叫公钥加密) ssh两大类认证方式:连接加密技术简介密钥解析 ssh工作过程版本协商阶段密钥和算法…...

LangChain 3使用Agent访问Wikipedia和llm-math计算狗的平均年龄
接着前两节的Langchain,继续实现Langchain中的Agent LangChain 实现给动物取名字,LangChain 2模块化prompt template并用streamlit生成网站 实现给动物取名字 代码实现 # 从langchain库中导入模块 from langchain.llms import OpenAI # 从langchain.l…...
wpf devexpress绑定grid到总计和分组统计
此主题描述了如何在gridcontrol中的视图模型和显示定义总计和分组统计 在视图模型中指定统计 1、创建 SummaryItemType 枚举你想要在GridControl中显示的统计类型: public enum SummaryItemType { Max, Count, None } 2、创建一个grid统计描述类 public class S…...
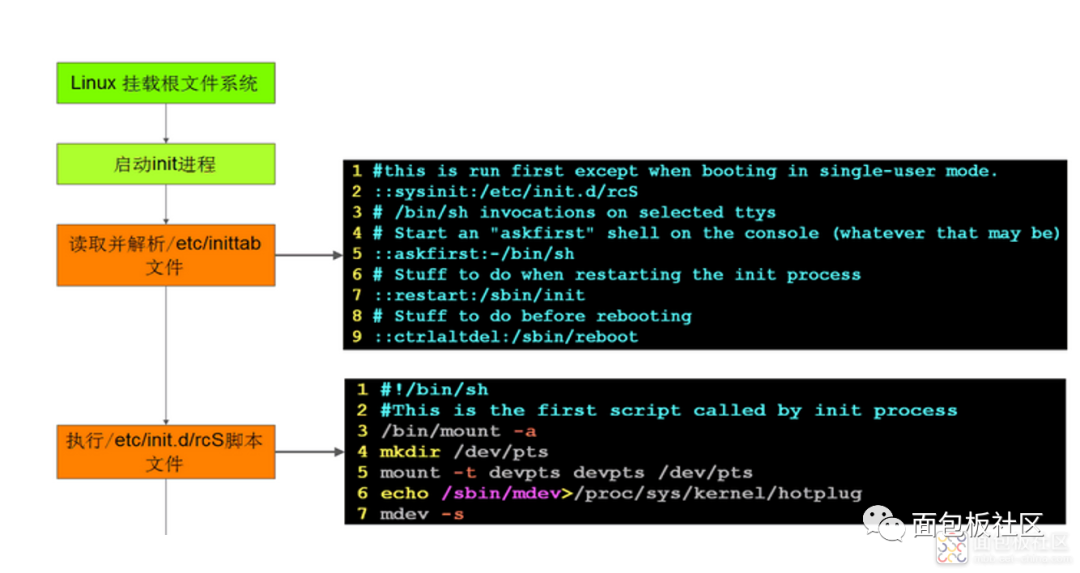
嵌入式 Linux 移植与系统启动方法
1、Linux系统启动与U-Boot 所谓移植就是把程序代码从一种运行环境转移到另一种运行环境。对于内核移植来说,主要是从一种硬件平台转移到另一种硬件平台上运行。 体系结构级别的移植是指在不同体系结构平台上Linux内核的移植,例如,在ARM、MI…...
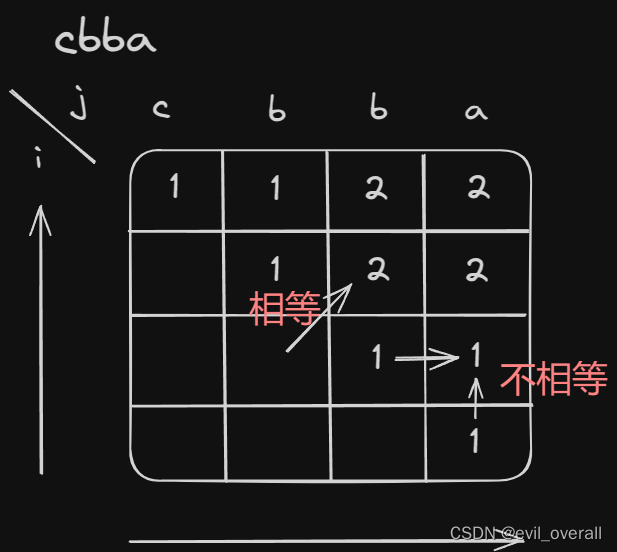
代码随想录算法训练营|五十六天
回文子串 647. 回文子串 - 力扣(LeetCode) dp含义:表示区间内[i,j]是否有回文子串,有true,没有false。 递推公式:当s[i]和s[j]不相等,false;相等时,情况一,…...
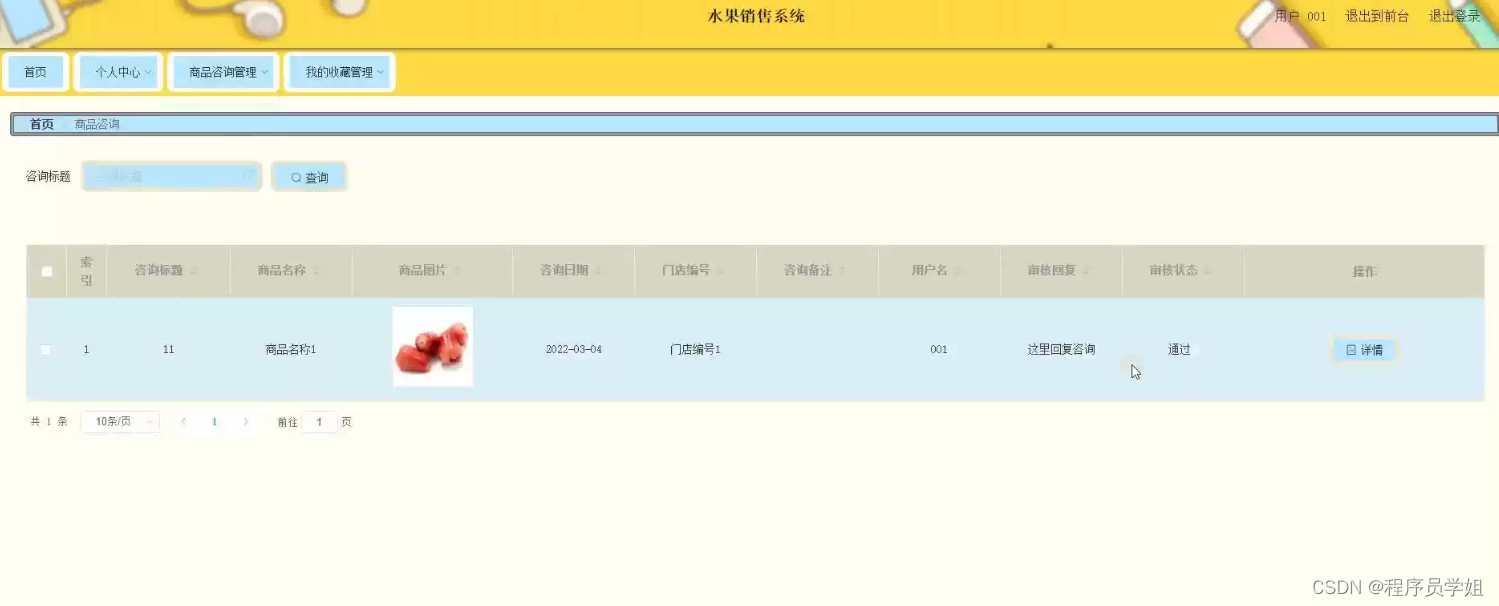
基于django水果蔬菜生鲜销售系统
基于django水果蔬菜生鲜销售系统 摘要 基于Django的水果蔬菜生鲜销售系统是一种利用Django框架开发的电子商务平台,旨在提供高效、便捷的购物体验,同时支持水果蔬菜生鲜产品的在线销售。该系统整合了用户管理、产品管理、购物车、订单管理等核心功能&…...
【数据结构】快速排序算法你会写几种?
👦个人主页:Weraphael ✍🏻作者简介:目前正在学习c和算法 ✈️专栏:数据结构 🐋 希望大家多多支持,咱一起进步!😁 如果文章有啥瑕疵 希望大佬指点一二 如果文章对你有帮助…...

C#访问修饰符
C#中的访问修饰符用于控制类型成员(如字段、属性、方法等)的访问级别。以下是C#中常用的访问修饰符: public:公共访问级别,没有任何访问限制。在任何其他类或程序集中都可以访问标记为 public 的成员。 private&#…...

anaconda中安装pytorch和TensorFlow环境并在不同环境中安装kernel
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️ 👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…...
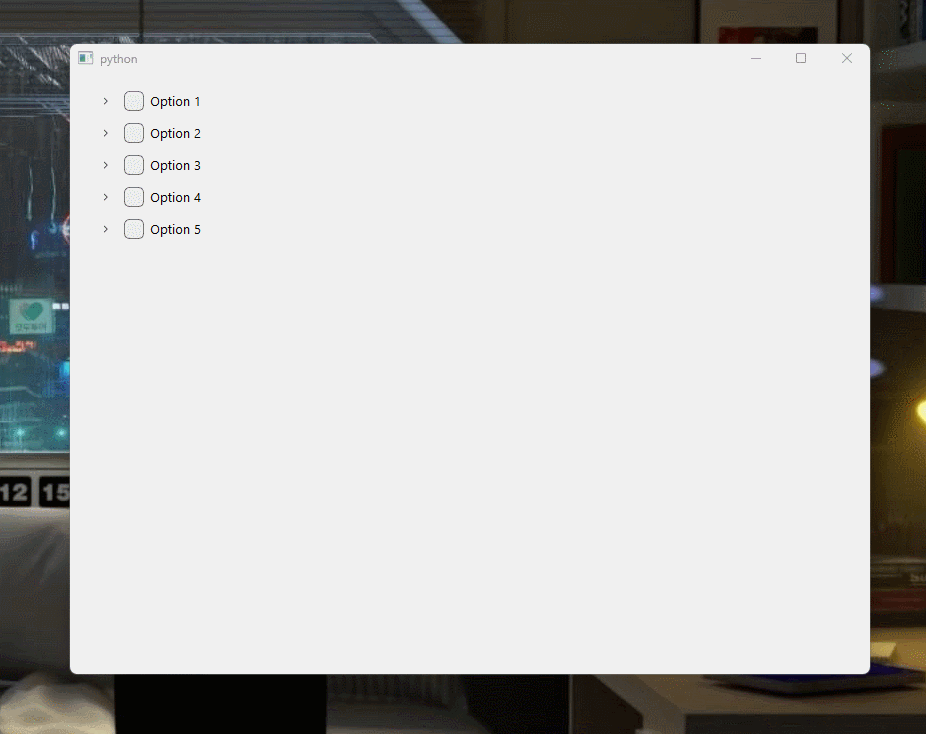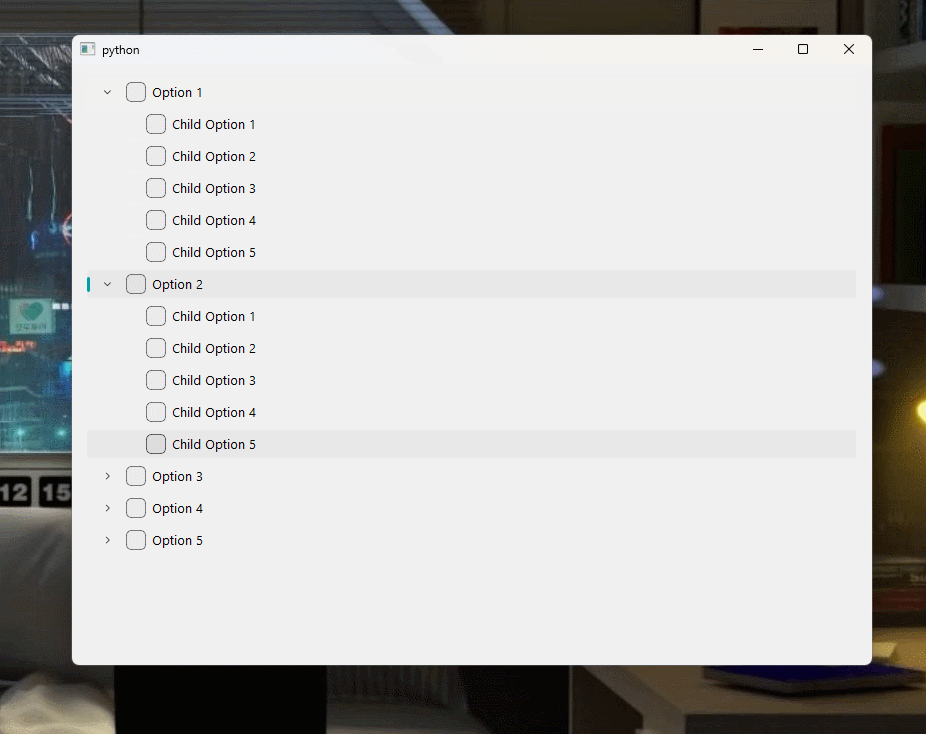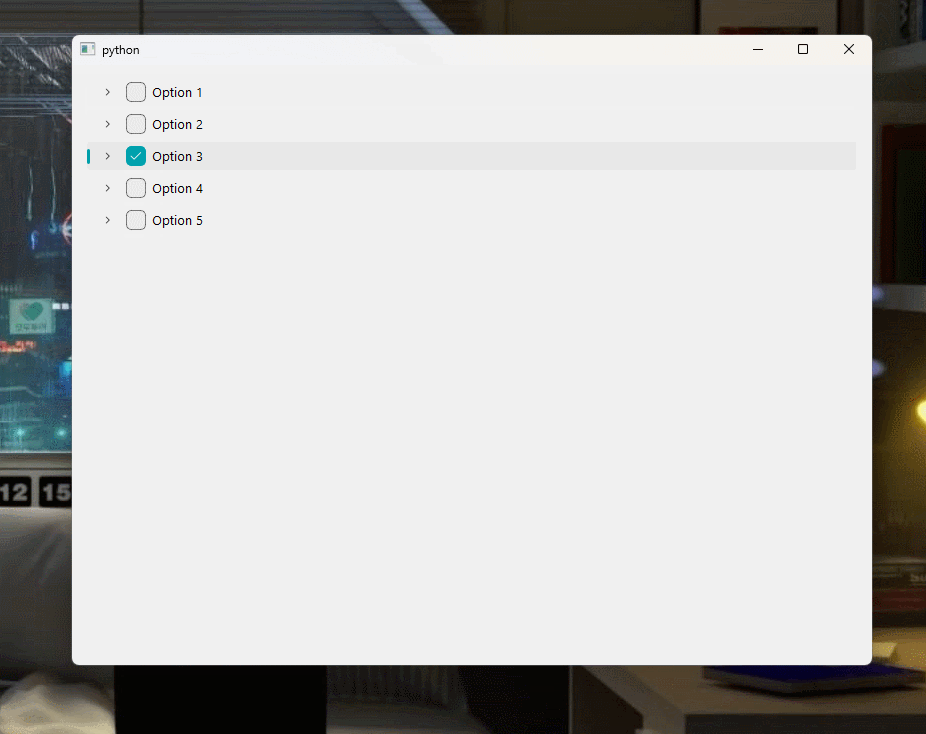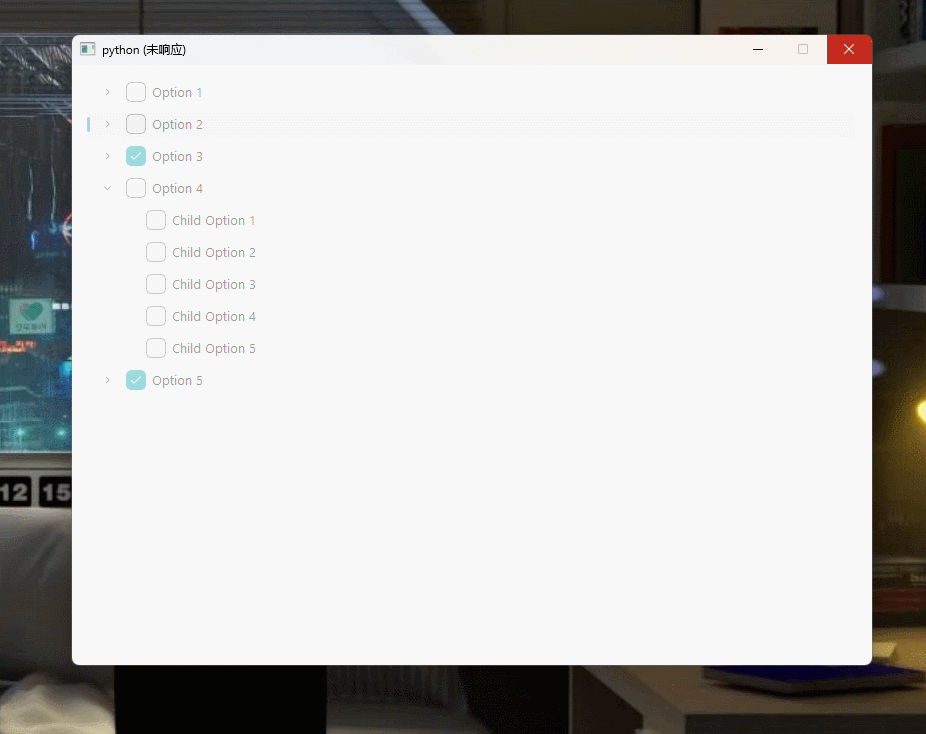
记一次解决Pyqt6/Pyside6添加QTreeView或QTreeWidget导致窗口卡死(未响应)的新路历程,打死我都想不到是这个原因
文章目录 💢 问题 💢🏡 环境 🏡📄 代码💯 解决方案 💯⚓️ 相关链接 ⚓️💢 问题 💢 我在窗口中添加了一个 QTreeWidget控件 ,但是程序在运行期间,只要鼠标进入到 QTreeWidget控件 内进行操作,时间超过几秒中就会出现窗口 未响应卡死的 状态 🏡 环境 �…...

用照片预测人的年龄【图像回归】
在图像分类任务中,卷积神经网络 (CNN) 是非常强大的神经网络架构。 然而,鲜为人知的是,它们同样能够执行图像回归任务。 图像分类和图像回归任务之间的基本区别在于分类任务中的目标变量(我们试图预测的东西)不是连续…...

Fork项目新分支如何同步
这里以seata项目为示例: 一、添加Fork仓库的源仓库 git remote add seata gitgithub.com:seata/seata.git二、fetch git fetch seata...

机器学习结合基因无关通路映射:从临床数据挖掘新药靶点
1. 项目概述:当机器学习遇见代谢通路,如何从数据中“挖”出新药靶点?在生物医学研究的前沿,我们正面临一个核心矛盾:一方面,我们拥有海量的临床数据,比如血糖、血压、BMI等指标;另一…...

用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑
用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑 当你第一次面对"换硬币"这类组合问题时,那种既兴奋又困惑的感觉我至今记忆犹新。作为C语言初学者,理解多重循环的运作机制就像在迷宫中寻找出口——每次你以为找到了…...

终极鼠标连点器使用指南:3分钟掌握高效自动化技巧
终极鼠标连点器使用指南:3分钟掌握高效自动化技巧 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,操作…...

基于ATmega2560与ISD1700的智能语音时钟:硬件选型、软件架构与避坑指南
1. 项目概述与核心价值去年折腾那个用ATMega328驱动三块显示屏的时钟时,我主要精力都花在了如何在320x240的TFT屏幕上把时间、日期和图标画得又准又好看上。项目在《Elektor》杂志上发表后,一位热心的读者给我提了个新想法:能不能做个会“说话…...

厨房空调技术白皮书:从风冷到水冷,制冷系统在厨房场景中的工程化演进
厨房空调是暖通行业近三年技术迭代最密集的细分品类。从最初的"凉霸"(本质是风扇),到风冷分体式,再到水冷一体式,每代技术都在解决上一代没有覆盖的用户痛点。本文以工程技术视角,梳理四代厨房制…...

解密高校教师必会的Gemini 3.1 Pro五大科研隐藏技能:从论文评估到创新点锁定
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 科研路上,有人发完顶刊顺利晋升,有人还在为创新点抓耳挠腮。 大多数教…...

深度解析网络设备权限管理工具:中兴光猫工厂模式与Telnet服务完整指南
深度解析网络设备权限管理工具:中兴光猫工厂模式与Telnet服务完整指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 在当今网络设备管理领域,获取设备完整控制…...

RevSSH反向SSH隧道:无公网IP设备的安全远程运维方案
1. 这不是又一个SSH封装工具——RevSSH解决的是“根本性连接悖论”你有没有遇到过这样的场景:一台部署在客户内网的嵌入式设备,没有公网IP,NAT穿透失败,防火墙策略死死锁住所有入向端口,连ICMP都被禁了;或者…...

告别坐标点击!用Poco精准定位UI控件,让你的Airtest安卓自动化脚本更稳定
告别坐标点击!用Poco精准定位UI控件,让你的Airtest安卓自动化脚本更稳定每次UI微调就导致脚本大面积失效?分辨率变化让精心编写的自动化测试瞬间崩溃?作为从坐标点击转型到控件识别的实践者,我深刻理解这种挫败感。三年…...

零基础怎么学Agent?这个工程师考试内容拆给你看
站在 AI Agent(智能体)爆发的十字路口,很多既没有深厚算法背景、也没有丰富写代码经验的“小白”常常感到迷茫:动辄谈及的大模型交互、复杂的业务编排,零基础真的能学会吗? 事实上,智能体开发早…...