文本向量化
文本向量化表示的输出比较
import timeimport torch
from transformers import AutoTokenizer, AutoModelForMaskedLM, AutoModel# simcse相似度分数
def get_model_output(model, tokenizer, text_str):"""验证文本向量化表示的输出:param model: 模型的名称:param tokenizer: tokenizer:param text_str: 文本内容 可以只一个str, 也可以是一个str_list:return: 返回该文本向量表示形式"""# 返回的类似一个字典类型# padding 表示填充max_len CLS + text + [SEP] return_tensors="pt" 返回pytorch类型的张量# 如果不加这个return_tensors="pt"参数 input_ids等key的value就不是tensor而是listinputs_text = tokenizer(text_str, return_tensors="pt", padding=True)print_inputs_source(**inputs_text)with torch.no_grad():outputs_source = model(**inputs_text)last_hidden_states = outputs_source.last_hidden_state # shape (b_s, max_len, 768)# 一般我们会使用的三个模型输出 建议使用 pooling_outputlast_cls_embedding = outputs_source.last_hidden_state[:, 0, :] # shape (b_s, 768) 每个文本的CLS 表示 这个是固定的last_hidden_states_mean = outputs_source.last_hidden_state.mean(dim=1) # shape (b_s, 768) 这个表示会有问题 对(b_s, max_len, 768) 进行平均池化得到的pooling_output = outputs_source.pooler_output # shape (b_s, 768) 每个文本的CLS之后在进入一次池化(全连接层)得到pool_output 这个表示也是固定的last_hidden_states_pooling = model.pooler(last_hidden_states)print("last_hidden_states shape {}".format(last_hidden_states.shape))print("last_CLS_embedding shape {}".format(last_cls_embedding.shape))print("last_hidden_states_pool shape {}".format(last_hidden_states_pooling.shape))print("last_hidden_states_mean shape {}".format(last_hidden_states_mean.shape))print("pool_output shape {}".format(pooling_output.shape))print("equal last_pool and pool_output: {}".format(torch.equal(pooling_output, last_hidden_states_pooling)))print("last_hidden_states embedding {}".format(last_hidden_states))print("last_hidden_states mead {}".format(last_hidden_states_mean))print("last_cls_embedding embedding {}".format(last_cls_embedding))print("pool_output {}".format(pooling_output))def print_inputs_source(input_ids, token_type_ids, attention_mask):"""打印模型tokenizer之后的内容:param input_ids::param token_type_ids::param attention_mask::return:"""print("input_ids: {}".format(input_ids))print("token_type_ids: {}".format(token_type_ids))print("attention_mask: {}".format(attention_mask))if __name__ == '__main__':"""字典的拆包"""# "D:\program\pretrained_model\ESimCSE-ext-chinese-bert-wwm""""Erlangshen-SimCSE-110M-ChineseESimCSE-ext-chinese-bert-wwm 这里的tokenier_config文件用的是sup-simcse的sup-simcse-bert-base-uncased"bert-base-uncased""""start_run_time = time.time()prefix_path = "D:/program/pretrained_model/" # 本地路径前缀model_path = prefix_path + "bert-base-uncased"model = AutoModel.from_pretrained(model_path)tokenizer = AutoTokenizer.from_pretrained(model_path)text_str = "中国"text_list = ["中国", "今天是个好日子"]get_model_output(model, tokenizer, text_list)
1. CLS表示整个文本
outputs_source.hidden_states[-1][:, 0, :]这行代码是用来从模型的输出中提取最后一层的所有单词的第一个位置(通常是 [CLS] 标记)的隐藏状态。
1.1 关键代码:
outputs_source = model(**inputs_text) last_hidden_states = outputs_source.last_hidden_state # shape (b_s, max_len, 768)
pooling_outputsentence_embedding = outputs_source.last_hidden_state[:, 0, :] # shape (b_s, 768) 每个文本的CLS 表示 这个是固定的
这里首先得到模型的最后一层隐藏状态的输出last_hidden_state,shape (b_s, max_len, 768)
然后选出CLS这个token的表示将其作为整个句子的表示
1.2 整体代码
import timeimport torch
from transformers import AutoTokenizer, AutoModelForMaskedLM, AutoModel# simcse相似度分数
def get_model_output(model, tokenizer, text_str):"""验证文本向量化表示的输出:param model: 模型的名称:param tokenizer: tokenizer:param text_str: 文本内容 可以只一个str, 也可以是一个str_list:return: 返回该文本向量表示形式"""# 返回的类似一个字典类型# padding 表示填充max_len CLS + text + [SEP] return_tensors="pt" 返回pytorch类型的张量inputs_text = tokenizer(text_str, return_tensors="pt", padding=True)# print_inputs_source(**inputs_text)with torch.no_grad():outputs_source = model(**inputs_text)last_hidden_states = outputs_source.last_hidden_state # shape (b_s, max_len, 768)# 一般我们会使用的三个模型输出 建议使用 pooling_outputsentence_embedding = outputs_source.last_hidden_state[:, 0, :] # shape (b_s, 768) 每个文本的CLS 表示 这个是固定的print("last_hidden_state shape: {}".format(last_hidden_states.shape))print("cls_embedding shape: {}".format(sentence_embedding.shape))print("last_cls_embedding: {}".format(sentence_embedding))return sentence_embeddingdef print_inputs_source(input_ids, token_type_ids, attention_mask):"""打印模型tokenizer之后的内容 CLS + text + SEP:param input_ids::param token_type_ids::param attention_mask::return:"""print("input_ids: {}".format(input_ids))print("token_type_ids: {}".format(token_type_ids))print("attention_mask: {}".format(attention_mask))if __name__ == '__main__':start_run_time = time.time()prefix_path = "D:/program/pretrained_model/" # 本地路径前缀model_path = prefix_path + "bert-base-uncased"model = AutoModel.from_pretrained(model_path)tokenizer = AutoTokenizer.from_pretrained(model_path)text_str = "中国"text_list = ["中国", "今天是个好日子"]get_model_output(model, tokenizer, text_str)end_run_time = time.time()used_time = end_run_time-start_run_timeprint("消耗时间为: {}秒".format(used_time))
输出结果: 中国 的文本表示如下

2. pooler_output表示整个文本
outputs_source.pooler_output 表示从模型的输出中提取的池化器输出(pooler output)。
在BERT模型中,经过最后一层的所有隐藏状态被经过一些池化操作,得到一个被称为"pooler output"的表示。这个表示通常被用于下游任务的输入,因为它是整个句子/序列的一个紧凑的表示。
所以,outputs_source.pooler_output 就是源文本(或输入文本)通过池化器得到的表示。
2.1 关键代码
outputs_source = model(**inputs_text)sentence_embedding = outputs_source.pooler_output # shape (b_s, max_len, 768)
这里相当于是把最后一层隐藏状态通过一个全连接层然后在进行输出表示整个句子
2.2 整体代码
import timeimport torch
from transformers import AutoTokenizer, AutoModelForMaskedLM, AutoModel# simcse相似度分数
def get_model_output(model, tokenizer, text_str):"""验证文本向量化表示的输出:param model: 模型的名称:param tokenizer: tokenizer:param text_str: 文本内容 可以只一个str, 也可以是一个str_list:return: 返回该文本向量表示形式"""# 返回的类似一个字典类型# padding 表示填充max_len CLS + text + [SEP] return_tensors="pt" 返回pytorch类型的张量inputs_text = tokenizer(text_str, return_tensors="pt", padding=True)# print_inputs_source(**inputs_text)with torch.no_grad():outputs_source = model(**inputs_text)sentence_embedding = outputs_source.pooler_output # shape (b_s, max_len, 768)# 一般我们会使用的三个模型输出 建议使用 pooling_output# sentence_embedding = outputs_source.last_hidden_state[:, 0, :] # shape (b_s, 768) 每个文本的CLS 表示 这个是固定的print("pooling_embedding shape: {}".format(sentence_embedding.shape))print("pooling_embedding: {}".format(sentence_embedding))return sentence_embeddingdef print_inputs_source(input_ids, token_type_ids, attention_mask):"""打印模型tokenizer之后的内容 CLS + text + SEP:param input_ids::param token_type_ids::param attention_mask::return:"""print("input_ids: {}".format(input_ids))print("token_type_ids: {}".format(token_type_ids))print("attention_mask: {}".format(attention_mask))if __name__ == '__main__':start_run_time = time.time()prefix_path = "D:/program/pretrained_model/" # 本地路径前缀model_path = prefix_path + "bert-base-uncased"model = AutoModel.from_pretrained(model_path)tokenizer = AutoTokenizer.from_pretrained(model_path)text_str = "中国"text_list = ["中国", "今天是个好日子"]get_model_output(model, tokenizer, text_str)end_run_time = time.time()used_time = end_run_time-start_run_timeprint("消耗时间为: {}秒".format(used_time))
输出结果: 中国 的文本表示如下

3. 利用最后隐藏状态的mean进行表示
3.1 关键代码
outputs_source = model(**inputs_text)sentence_embedding = outputs_source.last_hidden_state.mean(dim=1) # shape (b_s, max_len, 768)
这里是利用last_hidden_state的mean进行表示 但这个表示如果利用批量文本向量化的时候可能会出现问题,因为mean的时候会考虑padding, cls_embedding, 和pool_embedding就不会出现这种情况
3.2 整体代码
import timeimport torch
from transformers import AutoTokenizer, AutoModelForMaskedLM, AutoModel# simcse相似度分数
def get_model_output(model, tokenizer, text_str):"""验证文本向量化表示的输出:param model: 模型的名称:param tokenizer: tokenizer:param text_str: 文本内容 可以只一个str, 也可以是一个str_list:return: 返回该文本向量表示形式"""# 返回的类似一个字典类型# padding 表示填充max_len CLS + text + [SEP] return_tensors="pt" 返回pytorch类型的张量inputs_text = tokenizer(text_str, return_tensors="pt", padding=True)# print_inputs_source(**inputs_text)with torch.no_grad():outputs_source = model(**inputs_text)sentence_embedding = outputs_source.last_hidden_state.mean(dim=1) # shape (b_s, max_len, 768)# 一般我们会使用的三个模型输出 建议使用 pooling_output# sentence_embedding = outputs_source.last_hidden_state[:, 0, :] # shape (b_s, 768) 每个文本的CLS 表示 这个是固定的print("last_mean_embedding shape: {}".format(sentence_embedding.shape))print("last_mean_embedding: {}".format(sentence_embedding))return sentence_embeddingdef print_inputs_source(input_ids, token_type_ids, attention_mask):"""打印模型tokenizer之后的内容 CLS + text + SEP:param input_ids::param token_type_ids::param attention_mask::return:"""print("input_ids: {}".format(input_ids))print("token_type_ids: {}".format(token_type_ids))print("attention_mask: {}".format(attention_mask))if __name__ == '__main__':start_run_time = time.time()prefix_path = "D:/program/pretrained_model/" # 本地路径前缀model_path = prefix_path + "bert-base-uncased"model = AutoModel.from_pretrained(model_path)tokenizer = AutoTokenizer.from_pretrained(model_path)text_str = "中国"text_list = ["中国", "今天是个好日子"]get_model_output(model, tokenizer, text_str)end_run_time = time.time()used_time = end_run_time-start_run_timeprint("消耗时间为: {}秒".format(used_time))输出结果: 中国 的文本表示如下

输出结果: 如果输入文本为text_list(批量向量化)那么输出结果如下

这里可以发现中国的文本表示变化了 说明padding填充影响了mean的结果
所以这种方法慎重使用
4. 总结:
4.1 三种表示方法
model(**inputs_text).last_hidden_state.mean(dim=1)model(**inputs_text).last_hidden_state[:, 0, :]model(**inputs_text).pooler_output
4.2 last_hidden_state 和 pooler_output的区别以及转化
参考博客: https://blog.csdn.net/ningyanggege/article/details/132206331
last_hidden_states = model(**inputs_text).last_hidden_state
model.pooler(last_hidden_state) == model(**inputs_text).pooler_output
import timeimport torch
from transformers import AutoTokenizer, AutoModelForMaskedLM, AutoModel# simcse相似度分数
def get_model_output(model, tokenizer, text_str):"""验证文本向量化表示的输出:param model: 模型的名称:param tokenizer: tokenizer:param text_str: 文本内容 可以只一个str, 也可以是一个str_list:return: 返回该文本向量表示形式"""# 返回的类似一个字典类型# padding 表示填充max_len CLS + text + [SEP] return_tensors="pt" 返回pytorch类型的张量inputs_text = tokenizer(text_str, return_tensors="pt", padding=True)# print_inputs_source(**inputs_text)with torch.no_grad():outputs_source = model(**inputs_text)pooling_embedding = outputs_source.pooler_output # shape (b_s, max_len, 768)last_pool_embedding = model.pooler(outputs_source.last_hidden_state)# 一般我们会使用的三个模型输出 建议使用 pooling_output# sentence_embedding = outputs_source.last_hidden_state[:, 0, :] # shape (b_s, 768) 每个文本的CLS 表示 这个是固定的print("valid equals {}".format(torch.equal(pooling_embedding, last_pool_embedding)))return pooling_embeddingif __name__ == '__main__':start_run_time = time.time()prefix_path = "D:/program/pretrained_model/" # 本地路径前缀model_path = prefix_path + "bert-base-uncased"model = AutoModel.from_pretrained(model_path)tokenizer = AutoTokenizer.from_pretrained(model_path)text_str = "中国"text_list = ["中国", "今天是个好日子"]get_model_output(model, tokenizer, text_str)end_run_time = time.time()used_time = end_run_time-start_run_timeprint("消耗时间为: {:.2f}秒".format(used_time))水平有限 如有问题欢迎指正交流
参考博客: https://blog.csdn.net/ningyanggege/article/details/132206331
相关文章:
文本向量化
文本向量化表示的输出比较 import timeimport torch from transformers import AutoTokenizer, AutoModelForMaskedLM, AutoModel# simcse相似度分数 def get_model_output(model, tokenizer, text_str):"""验证文本向量化表示的输出:param model: 模型的…...

java--贪吃蛇
import javax.swing.*; import java.awt.*; import java.awt.event.*; import java.util.Random;public class Snake extends JFrame implements KeyListener, ActionListener, MouseListener {int slong 2;//蛇当前长度//蛇坐标int[] Snakex new int[100];int[] Snakey new…...
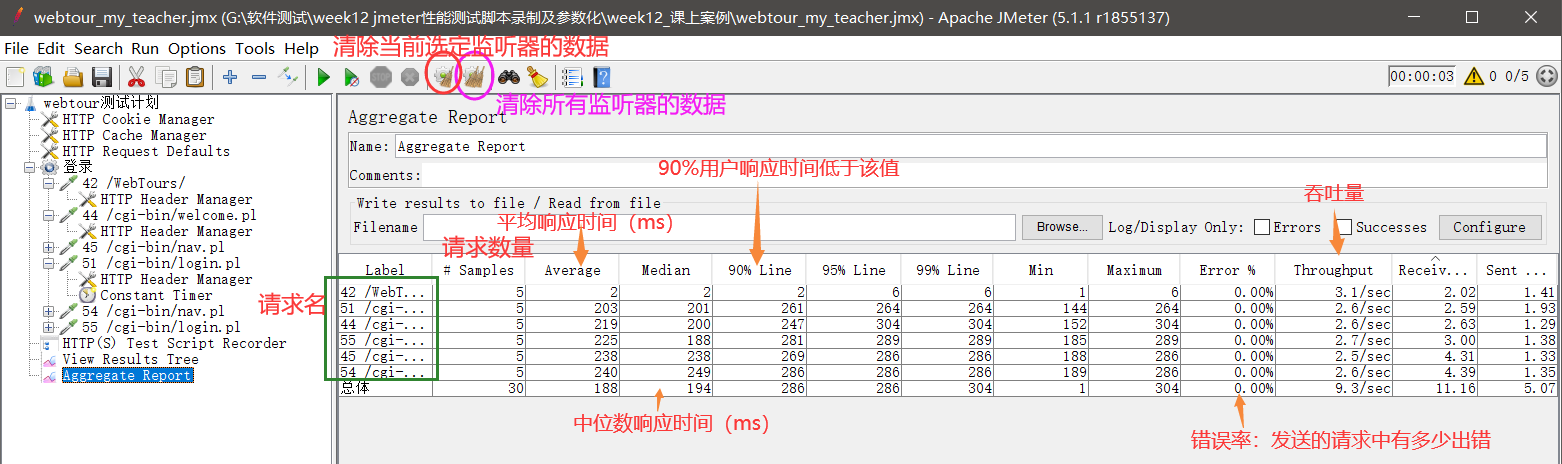
录制第一个jmeter性能测试脚本2(http协议)
我们手工编写了一个测试计划,现在我们通过录制的方式来实现那个测试计划。也就是说‘’测试计划目标和上一节类似:让5个用户在2s内登录webtour,然后进入 页面进行查看。 目录 一.性能测试脚本录制的原理 二、性能测试脚本录制的实操&#…...

pip命令大全
pip命令手册 原版 Usage: pip <command> [options]Commands:install Install packages.download Download packages.uninstall Uninstall packages.freeze Output installed packages…...

Redis篇---第二篇
系列文章目录 文章目录 系列文章目录前言一、为什么 使用 Redis 而不是用 Memcache 呢?二、为什么 Redis 单线程模型效率也能那么高?三、说说 Redis 的线程模型前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站,这…...

【LeetCode刷题日志】232.用栈实现队列
🎈个人主页:库库的里昂 🎐C/C领域新星创作者 🎉欢迎 👍点赞✍评论⭐收藏✨收录专栏:LeetCode 刷题日志🤝希望作者的文章能对你有所帮助,有不足的地方请在评论区留言指正,…...
Service 的测试)
单元测试实战(二)Service 的测试
为鼓励单元测试,特分门别类示例各种组件的测试代码并进行解说,供开发人员参考。 本文中的测试均基于JUnit5。 单元测试实战(一)Controller 的测试 单元测试实战(二)Service 的测试 单元测试实战&#x…...
LabVIEW和NIUSRP硬件加快了认知无线电开发
LabVIEW和NIUSRP硬件加快了认知无线电开发 对于电视频谱,主用户传输有两种类型:广播电视和节目制作和特殊事件(PMSE)设备。广播塔的位置已知,且覆盖电视传输塔(复用器)附近的某个特定地理区域(称为排除区域…...
)
嵌入式软件工程师面试题——2025校招社招通用(十六)
说明: 面试群,群号: 228447240面试题来源于网络书籍,公司题目以及博主原创或修改(题目大部分来源于各种公司);文中很多题目,或许大家直接编译器写完,1分钟就出结果了。但…...

白盒测试之测试用例设计方法
白盒测试之测试用例设计方法 什么是白盒测试白盒测试的特点白盒测试的设计方法静态设计方法动态设计方法语句覆盖分支(判定)覆盖条件覆盖判定条件覆盖组合覆盖路径覆盖总结 什么是白盒测试 按照测试方法分类,测试可以分为白盒测试和黑盒测试两种。 白盒测试也称结构…...

在CentOS 7上关闭SELinux
要在CentOS 7上关闭SELinux,可以按照以下步骤进行操作: 临时关闭SELinux(不建议使用): setenforce 0但是这种方式只对当前启动有效,重启系统后会失效。 2. 永久关闭SELinux: vi /etc/selinux…...

基于单片机温湿度PM2.5报警系统
**单片机设计介绍, 基于单片机温湿度PM2.5报警设置系统 文章目录 一 概要二、功能设计设计思路 三、 软件设计原理图 五、 程序六、 文章目录 一 概要 单片机温湿度PM2.5报警设置系统是一种智能化的环境检测与报警系统。它主要由单片机、传感器、液晶显示屏、蜂鸣器…...

OpenHarmony系统编译环境
1. 推荐系统Ubuntu 2204 2. 必须安装的软件 apt-get install curl build-essential gcc g make ninja-build cmake libffi-dev e2fsprogs pkg-config flex bison perl bc openssl libssl-dev libelf-dev binutils binutils-dev libdwarf-dev u-boot-tools mtd-utils cpio de…...
:解放代码责任链,提升灵活性与可维护性)
二十三种设计模式全面解析-职责链模式(Chain of Responsibility Pattern):解放代码责任链,提升灵活性与可维护性
在软件开发中,我们经常面临处理请求或事件的情况。有时候,我们需要将请求或事件依次传递给多个对象进行处理,但又不确定哪个对象最终会处理它。这时候,职责链模式(Chain of Responsibility Pattern)就能派上…...

通过制作llama_cpp的docker镜像在内网离线部署运行大模型
对于机器在内网,无法连接互联网的服务器来说,想要部署体验开源的大模型,需要拷贝各种依赖文件进行环境搭建难度较大,本文介绍如何通过制作docker镜像的方式,通过llama.cpp实现量化大模型的快速内网部署体验。 一、llam…...
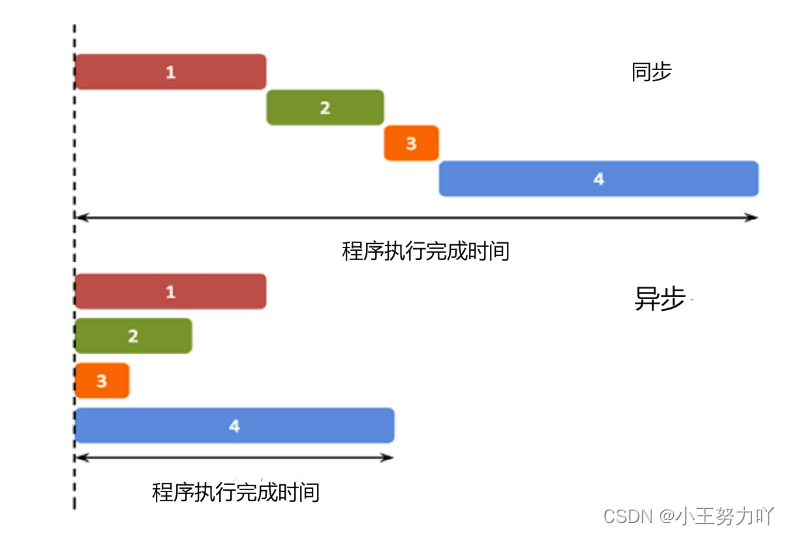
JavaScript 异步编程
异步的概念 异步(Asynchronous, async)是与同步(Synchronous, sync)相对的概念。 在我们学习的传统单线程编程中,程序的运行是同步的(同步不意味着所有步骤同时运行,而是指步骤在一个控制流序…...
linux课程第一课------命令的简单的介绍
作者前言 🎂 ✨✨✨✨✨✨🍧🍧🍧🍧🍧🍧🍧🎂 🎂 作者介绍: 🎂🎂 🎂 🎉🎉🎉…...

XLua热更新框架原理和代码实战
安装插件 下载Xlua插件:https://github.com/Tencent/xLua 下载完成后,把Asset文件夹下的文件拖入自己的工程Asset中,看到Unity编辑器上多了个Xlua菜单,说明插件导入成功 Lua启动代码 新建一个空场景,场景中什么都不…...

Hive客户端hive与beeline的区别
hive与beeline简介 1、背景2、hive3、beeline4、hive与beeline的关系 1、背景 Hive的hive与beeline命令都可以为客户端提供Hive的控制台连接。两者之间有什么区别或联系吗? Hive-cli(hive)是Hive连接hiveserver2的命令行工具,从Hive出生就一直存在&…...
<MySQL> 什么是数据库索引?数据库索引的底层结构是什么?
目录 一、什么是数据库索引? 1.1 索引的概念 1.2 索引的特点 1.3 索引的适用场景 1.4 索引的使用 1.4.1 创建索引 1.4.2 查看索引 1.4.3 删除索引 二、数据库索引的底层结构是什么? 2.1 数据库中的 B树 长啥样? 2.2 B树为什么适合做数据库索…...

Legacy iOS Kit终极指南:解锁旧iOS设备的完整控制权
Legacy iOS Kit终极指南:解锁旧iOS设备的完整控制权 【免费下载链接】Legacy-iOS-Kit An all-in-one tool to restore/downgrade, save SHSH blobs, jailbreak legacy iOS devices, and more 项目地址: https://gitcode.com/gh_mirrors/le/Legacy-iOS-Kit 在…...

PyTorch 2.8多场景实操:科研训练+工程推理+内容创作的统一技术底座
PyTorch 2.8多场景实操:科研训练工程推理内容创作的统一技术底座 1. 为什么选择PyTorch 2.8作为统一技术底座 PyTorch 2.8作为当前最主流的深度学习框架之一,已经成为学术界和工业界的首选工具。这个基于RTX 4090D 24GB显卡深度优化的镜像,…...
)
三自由度机械手-工业机器人(说明书+CAD图纸)
三自由度机械手作为工业机器人领域的典型代表,其核心作用在于通过三个独立运动轴的协同控制,实现末端执行器在三维空间内的精准定位与灵活操作。这种结构通过旋转、俯仰与伸缩三个方向的复合运动,能够覆盖工作空间内的任意目标点,…...

【完整源码+数据集+部署教程】光纤缺陷检测系统源码分享[一条龙教学YOLOV8标注好的数据集一键训练_70+全套改进创新点发刊_Web前端展示]
一、背景意义 随着光纤通信技术的迅猛发展,光纤作为信息传输的主要媒介,其质量的优劣直接影响到通信系统的性能和稳定性。光纤在生产、运输和安装过程中,可能会出现各种缺陷,如划痕、气泡、折弯等,这些缺陷不仅会导致信…...
)
HDMI接口没声音?手把手教你用InfoFrame调试音频流(附Audio InfoFrame解析)
HDMI音频调试实战:用Audio InfoFrame精准定位无声问题 当4K显示器亮起而音响沉默时,工程师的调试噩梦就开始了。上周在调试一块定制开发板时,HDMI视频输出完美,但音频系统始终沉默——这不是简单的"线材接触不良"能解释…...

AI绘画杀死UI设计师?幸存者在开发岗位的复仇
在数字技术的狂潮中,AI绘画工具的崛起如海啸般席卷设计行业。短短几年间,Midjourney、Stable Diffusion等AI平台已能10秒生成上百张海报,基础美工岗招聘量骤降35%,薪资停滞在4-6K区间。无数UI设计师面临失业危机,仿佛一…...

不止是打字机效果:手把手教你用SpannableStringBuilder打造Android富文本AI对话界面
超越基础文本渲染:用SpannableStringBuilder构建专业级AI对话界面 在移动应用开发中,AI对话界面的用户体验往往决定了产品的专业度。传统的TextView虽然能显示文字,但要实现类似DeepSeek等专业AI产品的交互效果,需要深入掌握Andro…...

三次握手,四次挥手速记版
本文同步发表于微信公众号,微信搜索 程语新视界 即可关注,每个工作日都有文章更新 三次握手和四次挥手是 TCP 协议中建立与关闭连接的关键机制,常因流程抽象而难以记忆。结合权威资料和通俗类比,以下是清晰、易记的要点&#…...

国内专业的铣打机厂家哪家专业
在制造业蓬勃发展的今天,铣打机作为轴类零件加工的关键设备,其性能和质量直接影响着生产效率和产品质量。面对市场上众多的铣打机厂家,该如何选择一家专业可靠的呢?今天就为大家介绍一家在行业内颇具口碑的企业——无锡通亚数控智…...

Android安全漏洞案例分析:血淋淋的教训
Android安全漏洞案例分析:血淋淋的教训 Android安全漏洞案例分析:血淋淋的教训 案例一:Secret Token泄露导致账户劫持 漏洞危害:攻击者获取用户全部权限 某社交App在客户端硬编码了API密钥,攻击者通过反编译获取密钥…...