CnosDB有主复制演进历程

分布式存储系统的复杂性涉及数据容灾备份、一致性、高并发请求和大容量存储等问题。本文结合CnosDB在分布式环境下的演化历程,分享如何将分布式理论应用于实际生产,以及不同实现方式的优缺点和应用场景。
分布式系统架构模式
分布式存储系统下按照数据复制方式的不同,常分为两种模式:主从模式、无主节点模式。
主从模式
主从模式以Raft分布式算法为代表,Raft 算法是 Diego Ongaro 和 John Ousterhout 于 2013 年发表的《In Search of an Understandable Consensus Algorithm》中提出;从工程案例etcd实现之后,Raft算法开始大放异彩。
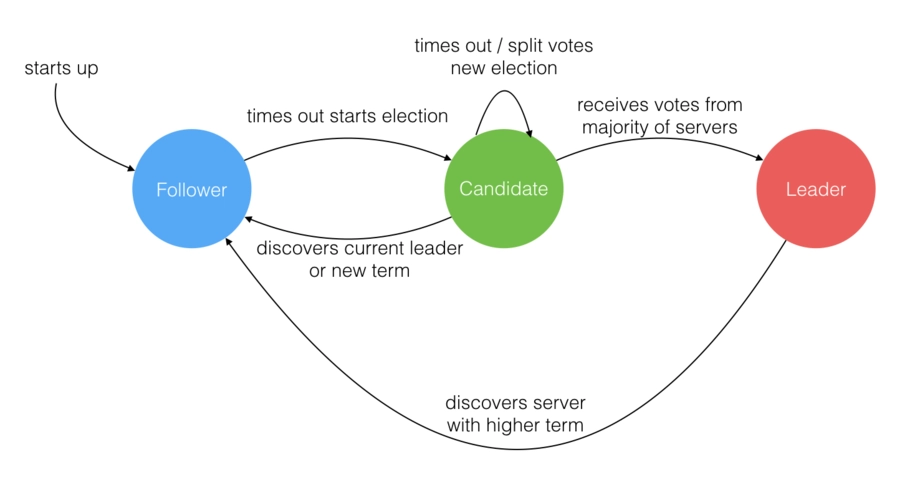
Raft分布式算法流程
无主模式
无主模式以亚马逊的Dynamo模型为代表,其理论来源于亚马逊在2007年发表的《Dynamo: Amazon’s Highly Available Key-value Store》,在该论文中论述了一种无主节点的数据库设计方案,像Cassandra、Riak等都是基于此理论实现。
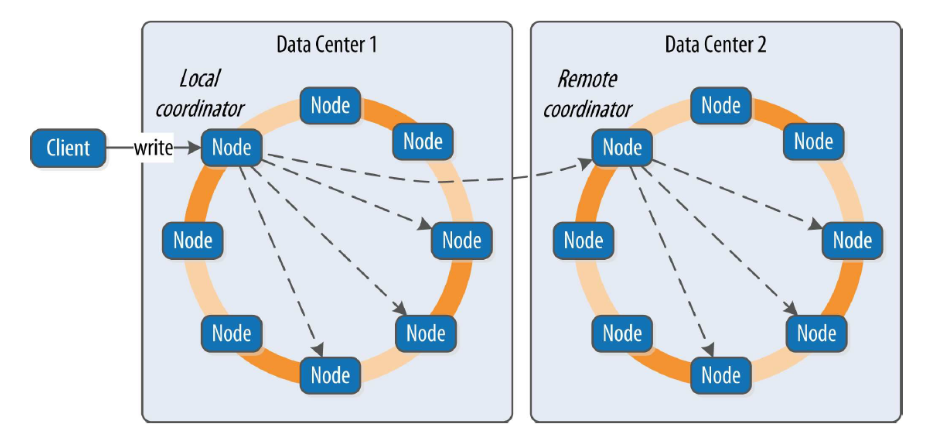
Cassandra数据写入流程
CnosDB整体架构
CnosDB 架构中主要包括了两类进程: cnosdb、cnosdb-meta。cnosdb负责数据的写入、查询、以及存储;cnosdb-meta负责元数据存储,像用户、租户、Database、Table、以及数据分布等相关信息。
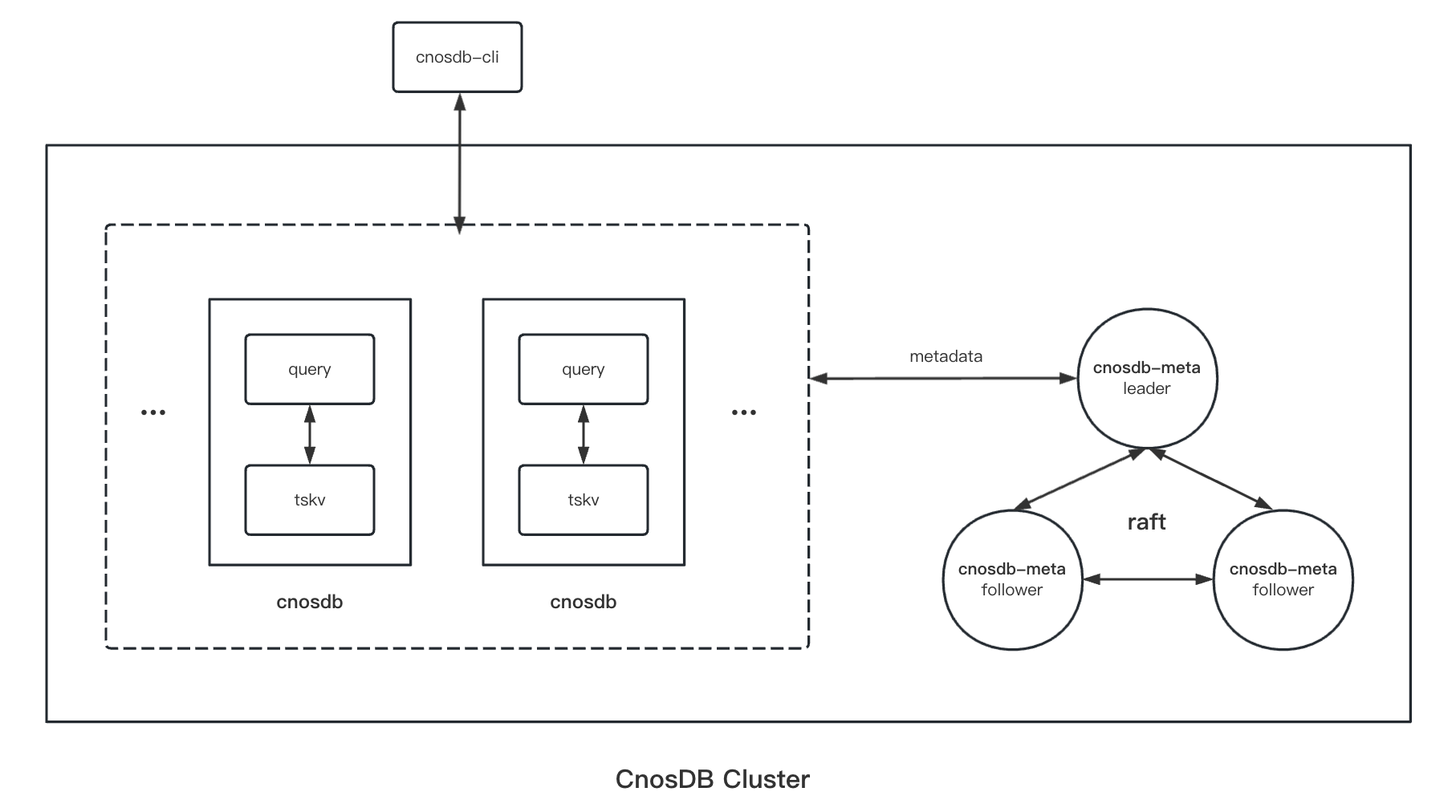
Meta服务
CnosDB的Meta服务是有主节点的分布式系统,通过 Raft 一致性协议实现的供CnosDB使用的一套分布式配置中心。作为配置中心要求具有较高的数据一致性,在有主模式下较容易实现这一点,这是我们采用有主模式实现Meta服务的主要原因。
CnosDB对访问频繁的Meta数据在本地有一份Cache,正常情况下直接访问本地Cache,降低用户的请求时延以及对Meta服务的访问压力;通过订阅Meta服务的数据变更日志来更新本地缓存数据。
上面提到Meta数据的本地缓存是通过订阅变更的方式进行同步,这必然会带来本地缓存与Meta服务数据不一致性的问题。对于这个问题我们根据对数据的不同使用场景做了不同处理;在可以容忍这种不一致性的地方直接读取本地缓存,像绝大多数的正常的读写流程都不需要访问Meta服务,这极大降低了用户访问时延;如果需要高度一致性的场景直接访问Meta服务获取最新的数据,像创建数据库、表结构的变更等。
CnosDB服务
CnosDB服务负责数据的写入、读取和存储,是一套类Dynamo的无主节点存储系统。
CnosDB按照两个维度对数据进行分片存储:时间分片与Hash分片。
时间分片:由于时序数据库本身的特征,按照时间维度进行分片有其天然的优势。CnosDB每隔一段时间创建一个Bucket,每个Bucket都有起始、结束时间用于存储对应时间段内的数据。每当系统容量不足时,添加新的存储节点;在创建新的Bucket时也将优先使用空闲容量最多的新节点,已有数据也不需要移动,这完美地解决了集群扩容与数据存储容量的问题。
Hash分片:时间分片完美地解决了存储容量的问题;在一个分布式集群环境下,会有多台机器提供服务,如若每个Bucket只分布在一台机器节点上,则整个系统的写入性能受限于单台机器。时序数据库还有另外一个概念是SeriesKey,按SeriesKey进行Hash分片可以分割成不同的ReplicaSet(复制组),每个ReplicaSet内的一个副本称其为Vnode,每个Vnode分散在不同的存储节点上,一个ReplicaSet内的多个Vnode按照类Dynamo方式进行副本间数据同步;Vnode是CnosDB进行数据分片管理的基本单元,采用Hash分片的方式解决了系统吞吐量的问题。
如下图所示,在时间维度上每隔一段时间创建一个Bucket,每个Bucket有两个复制组(用不同颜色来区分),每个复制组有两个副本(一个Bucket内相同颜色的Vnode有两个)分别落在不同的存储节点上。
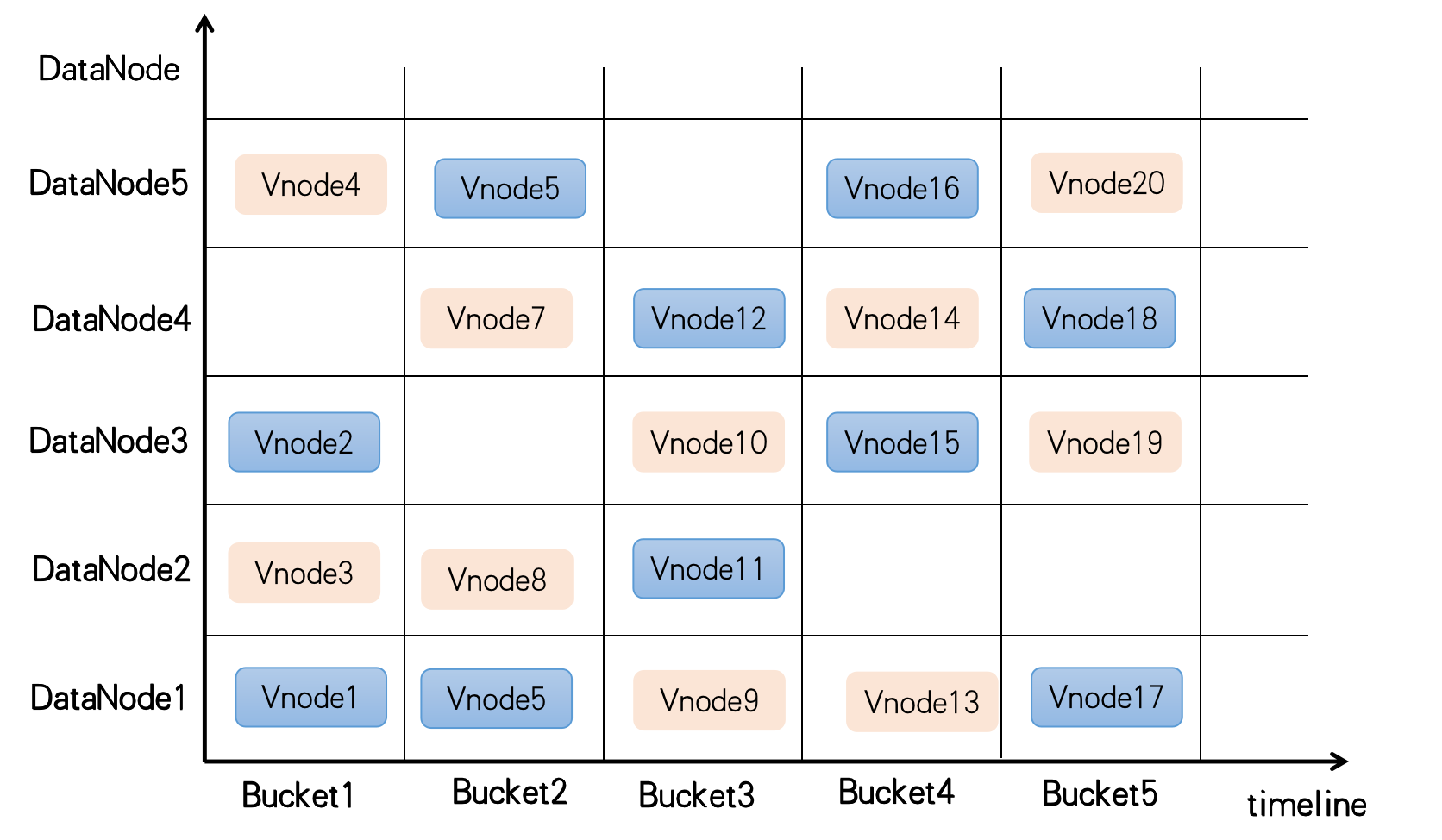
当前面临问题
按照时间、Hash两个维度进行分片解决分布式存储下容量与性能问题;但由于每个复制组内的数据复制方式是类Dynamo的无主节点模式,这带来一些新问题:
数据一致性:在无主节点的分布式存储系统中解决数据不一致性问题方式也有很多,像Cassandra中采用以最后写入者为准,Riak中的向量时钟等;再配合读修复、反熵、提示移交(Hinted Handoff)等一整套机制达到数据的最终一致性。这一整套机制实现起来是较为复杂的,也会极大拖累系统的整体性能,CnosDB当前也只是实现了部分机制。
数据订阅与同步:在无主节点的分布式存储系统中由于数据写入无顺序性,这导致做数据订阅也是一个难以解决的问题。在无主节点的模式中数据写入的统一的入口就是计算节点的接口层,但是在计算存储分离的强大背景下,通常计算层都是无状态的,在这一层做数据订阅难以保证订阅服务不丢失数据。
当Raft遇上CnosDB
为解决上述问题,我们转投有主模式寻求解决方案。
半同步方案:最开始我们参考Kafka设计了一个半同步方案。在Kafka中通过下面几个参数来控制服务在不同模式下运行,给用户灵活自由的选择。(不熟悉的读者,具体参数含义可以查阅网络信息)
-
acks
-
复制因子(副本数)
-
min.insync.replicas
此方案最大优点就是灵活,用户需要什么样的一致性、可靠性等级系统都可以通过参数进行配置;我们考虑到实现的难度、时间关系以及之后的稳定性,暂停了此方案。
其他方案:我们还讨论了主备节点的方案;由于CnosDB系统是多租户的,每个租户甚至每个Database要求的副本数都不一致,导致有些副本节点比较空闲、而像主节点则会压力比较大,造成机器间负载不均衡,资源的浪费等。
最终,我们选择了成熟的Raft方案,确切说是Multi-raft的方式,CnosDB中每个ReplicaSet都是一个Raft复制组。
为什么选择Raft
自采用Raft共识算法实现的etcd发布以后,Raft算法被公认为易于理解、相对易于实现的一套分布式共识算法,在数据的一致性、稳定性、可靠性等方面都得到众多产品的验证。
Raft是有主模式,会很好满足对数据一致性的要求;同时做数据订阅也极其容易(一种方式是作为集群的Learner节点存在,再一种方式是直接读取 Raft Logs)。
再就是CnosDB的Meta服务已经采用Raft。CnosDB主程序再也没有理由不去拥抱Raft。
关于Raft开源社区也有众多开源实现,几乎成为当前分布式系统下的标准算法,我们也并没有必要从头开始造轮子,而是选择了openraft方案。
Raft在CnosDB中应用
在CnosDB 中一个ReplicaSet就是一个Raft复制组,一个ReplicaSet由分布在不同机器上的多个Vnode副本组成,这些Vnode便构成了该Raft复制组的成员节点。
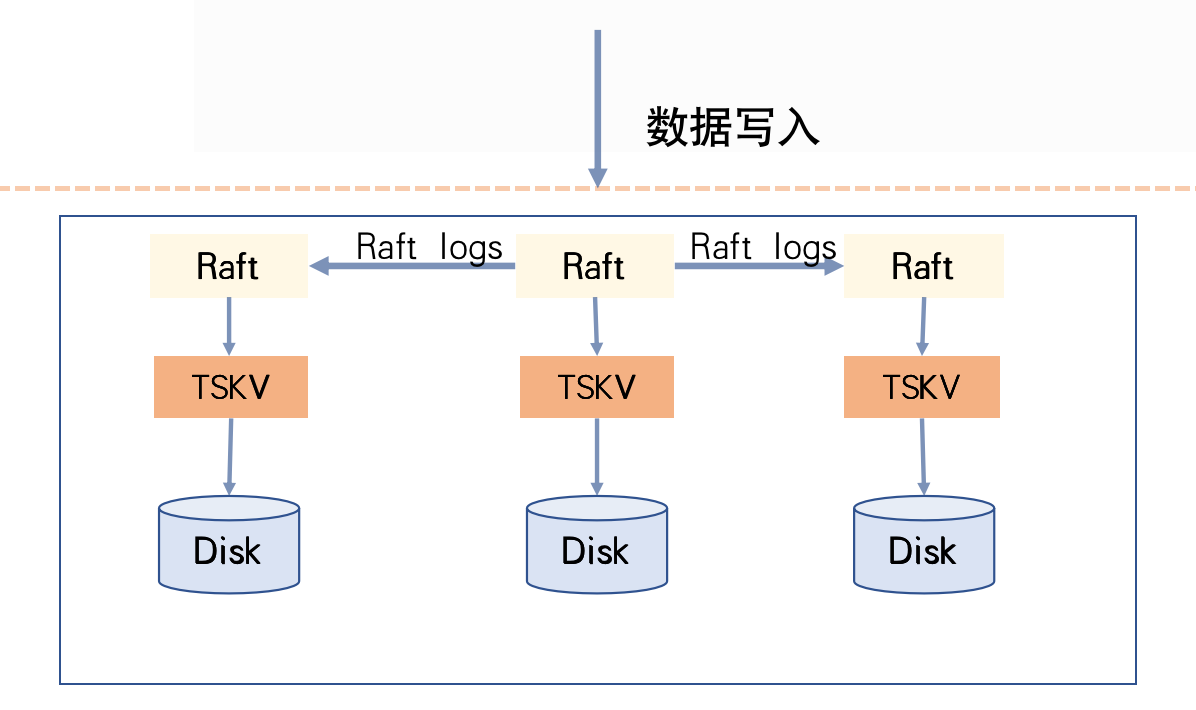
Raft在CnosDB中使用
数据写入过程:在CnosDB中每次写入都对应Raft复制组中的一次提交。服务接收到请求后判断本节点是否是此次写入对应Raft复制组的主节点,不是则进行请求转发;如果是则通过Raft协议进行写入,按照Raft协议在每个Vnode节点下产生一条Raft Log Entry,CnosDB会以WAL的形式记录到此Vnode目录下。
有超过半数Vnode节点记录WAL成功后,由Raft协议驱动进入下一个阶段——Apply阶段;在CnosDB中Apply阶段较为简单,只是写Memcache,主节点Apply成功后就响应客户端成功。
服务重启后Memcache中的数据通过WAL进行恢复。Memcache是由上层的Raft协议驱动刷盘,每次Memcache的刷盘都是作为一个Snapshot而存在。
更详细的过程可以参考Raft协议相关文档。
数据读取过程:根据查询条件,数据读取最终会落到每个Vnode上。在CnosDB的计划中是优先读取主节点的Vnode,这会带来较高的数据一致性;由于CnosDB是一个Multi-raft实现方式,主节点是分散在各个节点并不会造成主从节点负载不均匀的问题。
新的问题
Raft共识算法在如下场景下并没有说明如何处理:
-
读写Raft log发生错误
-
Apply时发生错误
上述两项错误通常为IO错误,发生上述错误时系统将陷入一种未知的状态,当前CnosDB的做法是尽量提前预检查规避错误的发生,也参考了etcd的处理方式如果遇到不可处理的未知场景,将由人工介入处理。
启用Raft算法
在配置文件中只需要把配置项using_raft_replication设置为true即可。
using_raft_replication = true总结
CnosDB在2.4版本中引入Raft共识算法,在保住了CnosDB高性能、高可用性、易维护性的提前下,将会使得CnosDB 查询具有更高的数据一致性,同时为后面待实现的数据订阅、同步、数据异构处理做足了前期准备。
随着CnosDB各项功能的完善,未来将会在更广泛的使用场景中发挥更大的作用。后期我们会推出更多的测试报告、以及使用场景供大家参考,欢迎各位关注我们,我们共同成长。
CnosDB简介
CnosDB是一款高性能、高易用性的开源分布式时序数据库,现已正式发布及全部开源。
欢迎关注我们的社区网站:https://cn.cnosdb.com
相关文章:
CnosDB有主复制演进历程
分布式存储系统的复杂性涉及数据容灾备份、一致性、高并发请求和大容量存储等问题。本文结合CnosDB在分布式环境下的演化历程,分享如何将分布式理论应用于实际生产,以及不同实现方式的优缺点和应用场景。 分布式系统架构模式 分布式存储系统下按照数据复…...
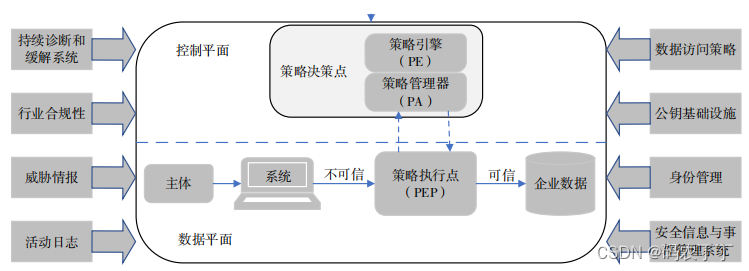
【前沿学习】美国零信任架构发展现状与趋势研究
转自:美国零信任架构发展现状与趋势研究 摘要 为了应对日趋严峻的网络安全威胁,美国不断加大对零信任架构的研究和应用。自 2022 年以来,美国发布了多个零信任战略和体系架构文件,开展了多项零信任应用项目。在介绍美国零信任战略…...
)
Toolformer论文阅读笔记(简略版)
文章目录 引言方法限制结论 引言 大语言模型在zero-shot和few-shot情况下,在很多下游任务中取得了很好的结果。大模型存在的限制:无法获取最新的信息、无法进行精确的数学计算、无法理解时间的推移等。这些限制可以通过扩大模型规模一定程度上解决&…...

Pytorch torch.dot、torch.mv、torch.mm、torch.norm的用法详解
torch.dot的用法: 使用numpy求点积,对于二维的且一个二维的维数为1 torch.mv的用法: torch.mm的用法 torch.norm 名词解释:L2范数也就是向量的模,L1范数就是各个元素的绝对值之和例如:...
Jave 定时任务:使用Timer类执行定时任务为何会发生任务阻塞?如何解决?
IDE:IntelliJ IDEA 2022.2.3 x64 操作系统:win10 x64 位 家庭版 JDK: 1.8 文章目录 一、Timer类是什么?二、Timer类主要由哪些部分组成?1.TaskQueue2. TimerThread 三、示例代码分析四、自定义TimerTask为什么会发生任务相互阻塞的…...
Visual Studio Code配置c/c++环境
Visual Studio Code配置c/c环境 1.创建项目目录2.vscode打开项目目录3.项目中添加文件4.文件内容5.配置编译器6.配置构建任务7.配置调试设置 1.创建项目目录 d:\>mkdir d:\c语言项目\test012.vscode打开项目目录 3.项目中添加文件 4.文件内容 #include <iostream> u…...

漏洞利用工具的编写
预计更新网络扫描工具的编写漏洞扫描工具的编写Web渗透测试工具的编写密码破解工具的编写漏洞利用工具的编写拒绝服务攻击工具的编写密码保护工具的编写情报收集工具的编写 漏洞利用工具是一种常见的安全工具,它可以利用系统或应用程序中的漏洞来获取系统权限或者窃…...

ChatGPT之父被OpenAI解雇
首席技术官 Mira Murati 任命临时首席执行官领导 OpenAI;山姆阿尔特曼(Sam Altman)离开公司。 阿尔特曼先生的离职是在董事会经过深思熟虑的审查程序之后进行的,审查程序得出的结论是,他在与董事会的沟通中始终不坦诚…...
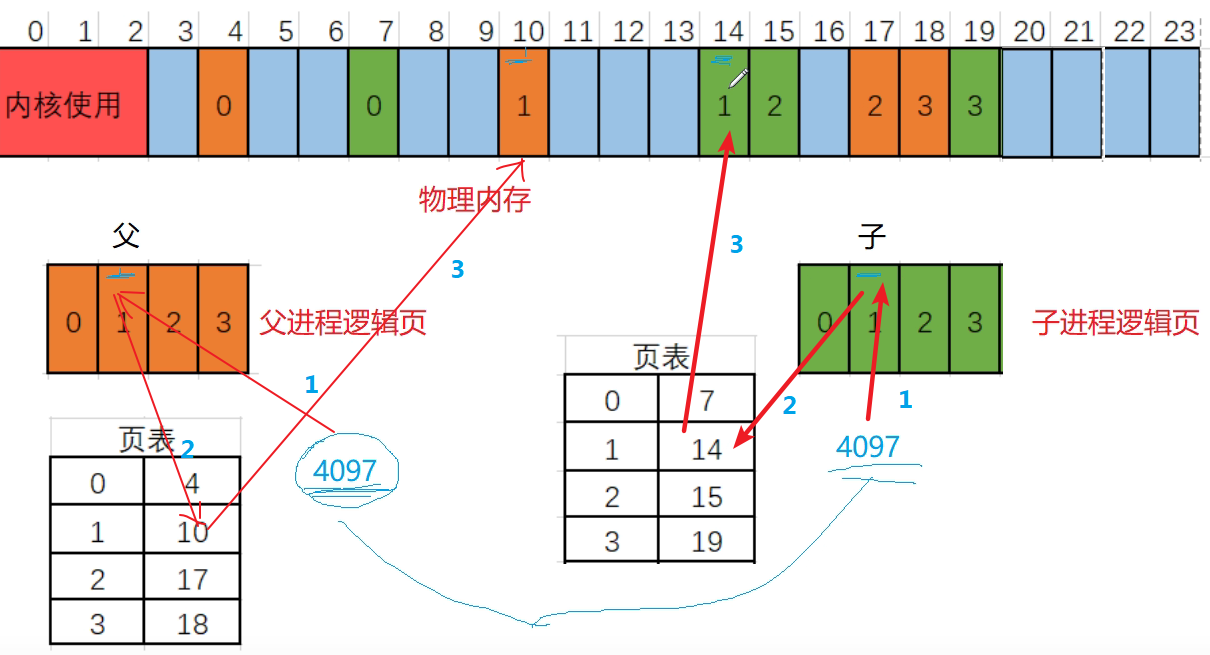
linux中利用fork复制进程,printf隐藏的缓冲区,写时拷贝技术,进程的逻辑地址与物理地址
1.prinf隐藏的缓冲区 1.思考:为什么会有缓冲区的存在? 2.演示及思考? 1).演示缓存区没有存在感 那为什么我们感觉不到缓冲区的存在呢?我们要打印东西直接就打印了呢? 我们用代码演示一下: 比如打开一个main.c,输入内容如下: #include <stdio.h>int main(){printf…...

java游戏制作-拼图游戏
一.制作主界面 首先创建一个Java项目命名为puzzlegame 结果:】 二.设置界面 代码: 三.初始化界面 代码: 优化代码: 四.添加图片 先在Java项目中创建图片文件夹,将图片导入其中 管理图片: 五.打乱图片顺序...

使用sklearn报AttributeError: ‘NoneType‘ object has no attribute ‘split‘
错误原因 在使用scikit-learn的时候报AttributeError: NoneType object has no attribute split Exception ignored on calling ctypes callback function: <function _ThreadpoolInfo._find_modules_with_dl_iterate_phdr..match_module_callback at 0x7fb757978160> T…...

C++学习 --map
目录 1, 什么是map 2, 创建map 2-1, 标准数据类型 2-2, 自定义数据类型 2-3, 其他创建方式 3, 操作map 3-1, 赋值 3-2, 插入元素(insert) 3-2-1, 插入标准数据类…...

基于Qt QList和QMap容器类示例
## QList<T> QList<T>容器是一个数组列表,特点如下: 1.大多数情况下可以用QList。像prepend()、append()和insert()这种操作,通常QList比QVector快的多。这是因为QList是基于index标签存储它的元素项在内存中(虽然内存不连续,这点与STL的list 是一样的),比…...
Flask学习一:概述
搭建项目 安装框架 pip install Flask第一个程序 from flask import Flaskapp Flask(__name__)app.route(/) def hello_world():return "Hello World"if __name__ __main__:app.run()怎么说呢,感觉还不错的样子。 调试模式 if __name__ __main__:a…...
)
LeetCode:689. 三个无重叠子数组的最大和(dp C++)
目录 689. 三个无重叠子数组的最大和 题目描述: 实现代码与解析: dp 原理思路: 滑动窗口: 原理思路: 689. 三个无重叠子数组的最大和 题目描述: 给你一个整数数组 nums 和一个整数 k ,找…...

Leetcode—206.反转链表【简单】
2023每日刷题(三十三) Leetcode—206.反转链表 头插法实现代码 /*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/ struct ListNode* reverseList(struct ListNode* head) {if(head NULL…...

Linux - 内存 - 预留内存占用分析
说明 Linux启动log中会显示平台的内存信息,公司SOC平台,物理DRAM实际size是128M,但是启动log中total size不足128MB,并且预留内存(82272K reserved)过多,启动log如下: Memory: 480…...
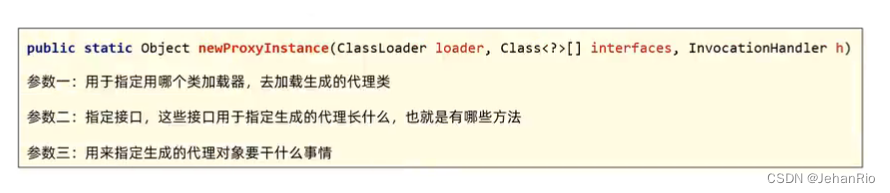
Java学习之路 —— Java高级
文章目录 前言1. 单元测试2. 反射2.1 获取Class对象的三种方式2.2 获取类的构造器的方法2.3 获取类的成员变量2.4 获取类的成员方法2.5 反射的作用 3. 注解3.1 自定义注解3.2 注解的原理3.3 元注解3.4 注解的解析 4. 动态代理5. 总结 前言 终于走到新手村的末端了,…...
git使用及常用命令
在初入公司中,若使用的是git管理工具,需要做以下步骤: 1,常用命令在: (1),git config --global user.name xxx(名字) //若不设置 那么下次提交代码时会报错 其次该设置名字和…...
)
vue 学习 -- day36(分析工程结构)
//引入的不再是Vue构造函数了,引入的是一个名为createApp的工厂函数 import { createApp } from vue import App from ./App.vue //创建应用实例对象——app(类似于之前Vue2中的vm,但app比vm更“轻”,它少了很多属性和方法) const app creat…...

颜色矩阵滤镜ColorMatrixFilter 简单使用技巧
滤镜是对现有的图片颜色的一种处理方法。而矩阵则做为滤镜的一种很有效的控制数据表达方式。我们先看下颜色的RGB的效果图: 接着我们看下颜色矩阵的结构: ColorMatrixFilter为4行5列的二维矩阵,第一行表示红色,第二行表示绿色,第三行表示红色,第四行表示透明值。前四列表…...

Arm平台调试工具链全解析与实战指南
1. Arm参考设计平台调试工具全指南作为一名长期从事Arm平台开发的工程师,我深知调试工具链的选择和使用对项目效率的决定性影响。本文将系统梳理Arm参考设计平台(RDP)的全套调试资源,涵盖从基础工具配置到高级调试技巧的完整知识体系。重要提示ÿ…...
原理与边缘计算应用实践)
脉冲神经网络(SNN)原理与边缘计算应用实践
1. 脉冲神经网络技术解析:从生物启发的计算范式到普适计算实践脉冲神经网络(SNN)作为第三代神经网络模型,其设计灵感直接来源于生物神经系统的运作机制。与传统人工神经网络(ANN)相比,SNN最显著…...

Armv9 SME架构FMOP4A指令:混合精度矩阵运算优化
1. SME架构与FMOP4A指令概述 在现代处理器架构中,矩阵运算性能直接决定了AI推理和科学计算的效率。Armv9引入的SME(Scalable Matrix Extension)架构通过ZA瓦片寄存器和专用矩阵指令集,为浮点密集型计算提供了硬件级加速方案。其中…...

June安全防护手册:保护你的论坛免受常见Web攻击的10个技巧
June安全防护手册:保护你的论坛免受常见Web攻击的10个技巧 【免费下载链接】june June is a forum (Deprecated) 项目地址: https://gitcode.com/gh_mirrors/ju/june 在当今数字时代,论坛安全防护已成为每个网站管理员必须面对的重要课题。June作…...
)
鸿蒙数理体系创作说明 (鸿蒙数学一阶完结后更新说明)
本套鸿蒙数学体系,并非凭空独创,而是站在华夏千年古数根基之上,融合西方近代数理实证体系,双向重构、文明合一所诞生的全新本源数理框架。一、本体系继承、吸纳的【华夏传统古数核心本源】整套体系的底层大道骨架、思维范式、宇宙…...
)
Codex入门17-上下文管理(高手秘技:如何让AI精准理解你的百万行大型项目)
Codex入门17-上下文管理(高手秘技:如何让AI精准理解你的百万行大型项目) 📌 文章简介:上下文窗口是 AI 编程的"生命线"——它决定了 AI 能"看到"多少代码、"理解"多少架构。本文深入解析上下文窗口的本质,详解 Codex 如何自动收集项目信息…...
 全面使用指南)
Netcat (nc) 全面使用指南
Netcat 被誉为网络工具中的"瑞士军刀",是一个功能强大的网络调试和诊断工具。它可以在 TCP/UDP 协议下进行连接、监听、端口扫描、文件传输和代理转发等操作。 一、安装与基本语法 1.1 安装方法 操作系统安装命令Ubuntu/Debiansudo apt install netcat…...

如何安装OpenClaw?2026年京东云部署及配置Token Plan详细攻略
如何安装OpenClaw?2026年京东云部署及配置Token Plan详细攻略。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token Plan兼容主流…...

2026最新个人AI编程软件实测盘点:独立开发者做副业高效开发必备
2026最新个人AI编程软件实测盘点:独立开发者做副业高效开发必备很多独自做开发的从业者常会疑惑,零基础能不能借助智能工具快速写出可用程序?低成本状态下有没有适配全栈杂活、适合快速试错的AI编程软件?面对市面上品类繁杂的辅助…...