Hadoop学习总结(MapRdeuce的词频统计)
MapRdeuce编程示例——词频统计
一、MapRdeuce的词频统计的过程
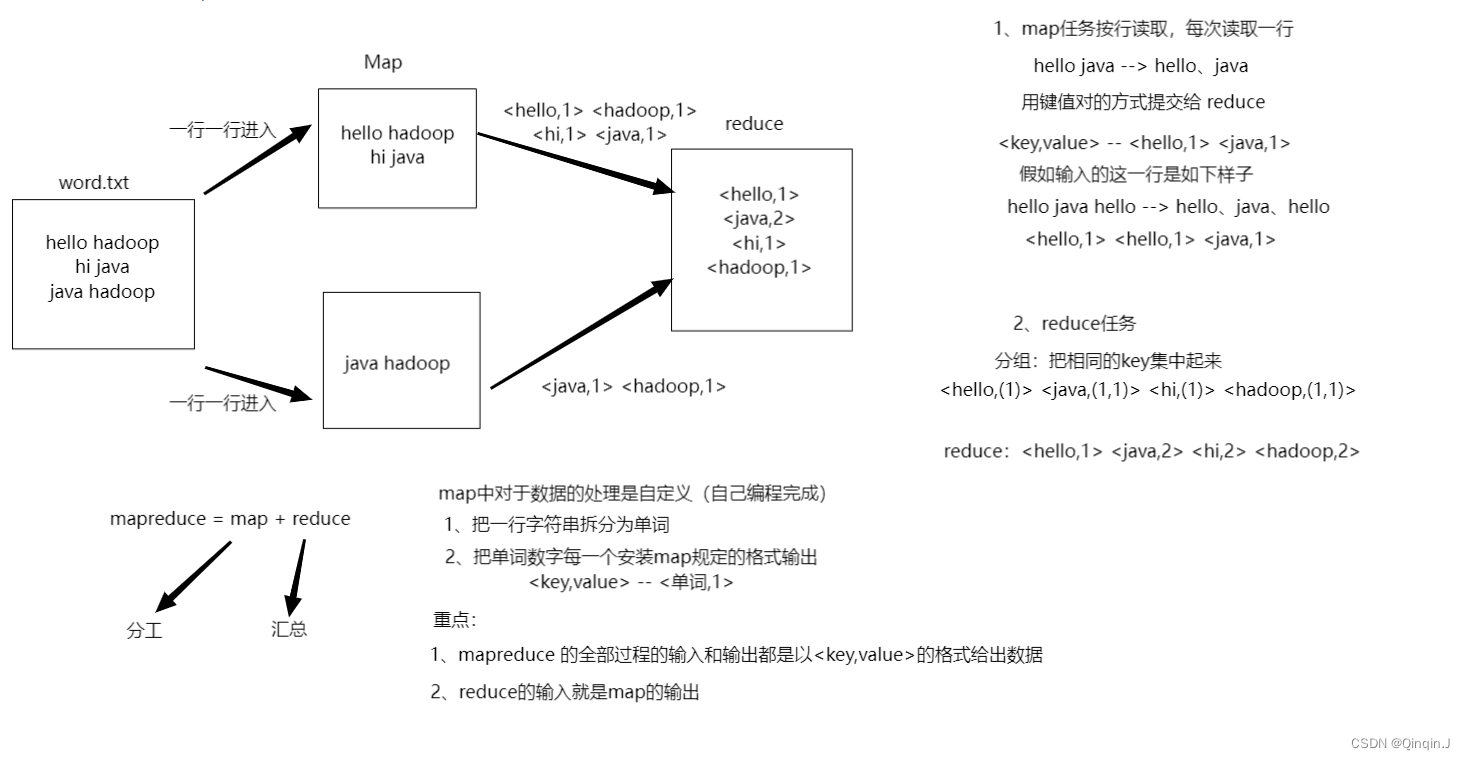
二、编程过程
1、Mapper 组件
WordcountMapper.java
package com.itcast.mrdemo;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;/*** Map 需要指定四个泛型,用来限定输入和输出的 key 和 value 的类型** hadoop 有自己的数据类型,不使用 java 的数据类型,对应的 java 类型名字后面 + Writable 就是 hadoop 类型* String 除外,String 对于的 hadoop 类型叫做 Text* <2, "java">* */
public class WordcountMapper extends Mapper<LongWritable, Text,Text,IntWritable> {//重写Ctrl+o@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {/*** 1、把一行字符串拆分成单词 "hello java"* 2、把单词、数字每一个按照 map 规定的格式输出*/// 把 hadoop 类型转换为 java 类型(接收传入进来的一行文本,把数据类型转换为 String 类型)String line = value.toString();// 把字符串拆分为单词String[] words = line.split(" ");//使用 for 循环把单词数组胡每个单词输出for (String word : words){context.write(new Text(word), new IntWritable(1));}}
}
2、Reducer 组件
WordcountReducer.java
package com.itcast.mrdemo;import org.apache.hadoop.io.IntWritable;
//import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;/*** Reduce 需要指定四个泛型,用来限定输入和输出的 key 和 value 的类型* 1、Map 的输出就是 Reduce 的输入* 2、Reduce 的输出是 <"java", 2>*/
public class WordcountReducer extends Reducer<Text,IntWritable,Text,IntWritable> {@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable value : values){sum ++;}context.write(key,new IntWritable(sum));}
}
3、MapRdeuce 运行模式
MapRdeuce 程序的运行模式主要有两种
(1)本地运行模式
在当前的开发环境模拟 MapRdeuce 执行环境,处理的数据及输出结果在本地操作系统WordcountDriver.java
package com.itcast.mrdemo;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class WordcountDriver{public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {//通过 Job 来封装本次 MR 的相关信息Configuration conf = new Configuration();//System.setProperty("HADOOP_USER_NAME","root");//配置 MR 运行模式,使用 local 表示本地模式,可以省略conf.set("mapreduce.framework.name","local");Job job = Job.getInstance(conf);//指定 MR Job jar 包运行主类job.setJarByClass(WordcountDriver.class);//指定本次 MR 所有的 Mapper Reducer 类job.setMapperClass(WordcountMapper.class);job.setReducerClass(WordcountReducer.class);//设置业务逻辑 Mapper 类的输出 key 和 value 的数据类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);//设置业务逻辑 Reducer 类的输出 key 和 value 的数据类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);//使用本地模式指定处理的数据所在的位置FileInputFormat.setInputPaths(job,"D:/homework2/Hadoop/mr/input");//使用本地模式指定处理完成之后的结果所保存的位置FileOutputFormat.setOutputPath(job, new Path("D:/homework2/Hadoop/mr/output"));//提交程序并且监控打印程序执行情况boolean res = job.waitForCompletion(true);//执行成功输出 0 ,不成功输出 1System.exit(res ? 0 : 1);}
}
运行结果为:

(2)集群运行模式
-
*在HDFS中创建文件
在HDFS中的/input目录下有word.txt文件,且文件中编写有内容(内容随意编写)

-
*对 WordcountDriver.java 修改
修改WordcountDriver.java中的路径为HDFS上的路径
package com.itcast.mrdemo;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class WordcountDriver{public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {//通过 Job 来封装本次 MR 的相关信息Configuration conf = new Configuration();//System.setProperty("HADOOP_USER_NAME","root");//配置 MR 运行模式,使用 local 表示本地模式,可以省略conf.set("mapreduce.framework.name","local");Job job = Job.getInstance(conf);//指定 MR Job jar 包运行主类job.setJarByClass(WordcountDriver.class);//指定本次 MR 所有的 Mapper Reducer 类job.setMapperClass(WordcountMapper.class);job.setReducerClass(WordcountReducer.class);//设置业务逻辑 Mapper 类的输出 key 和 value 的数据类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);//设置业务逻辑 Reducer 类的输出 key 和 value 的数据类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);//使用本地模式指定处理的数据所在的位置FileInputFormat.setInputPaths(job,"/input");//使用本地模式指定处理完成之后的结果所保存的位置FileOutputFormat.setOutputPath(job, new Path("/output"));//提交程序并且监控打印程序执行情况boolean res = job.waitForCompletion(true);//执行成功输出 0 ,不成功输出 1System.exit(res ? 0 : 1);}
}
-
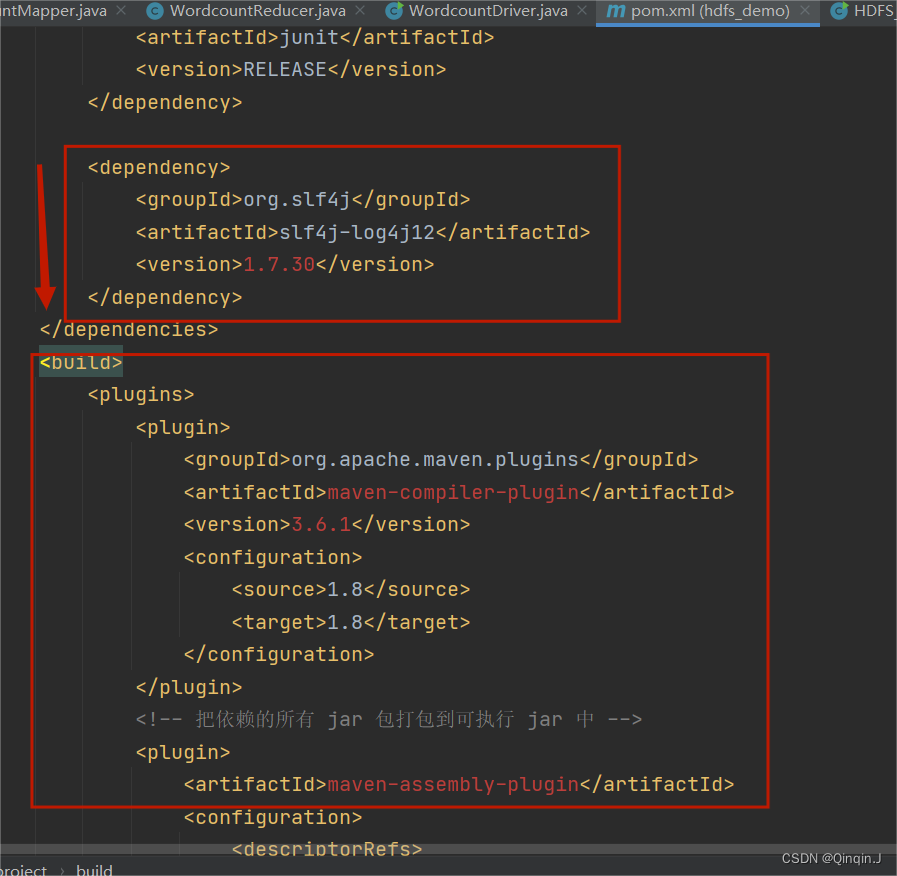
*对pom.xml添加内容
<dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.30</version></dependency> <build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.6.1</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin><!-- 把依赖的所有 jar 包打包到可执行 jar 中 --><plugin><artifactId>maven-assembly-plugin</artifactId><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build>在这个位置进行添加
*在resources创建文件
在resources创建文件log4j.properties
添加以下内容
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n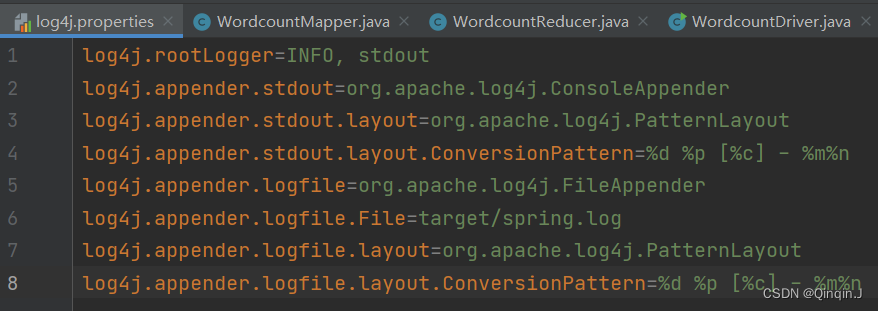
-
*打包成jar包
双击,进行打包
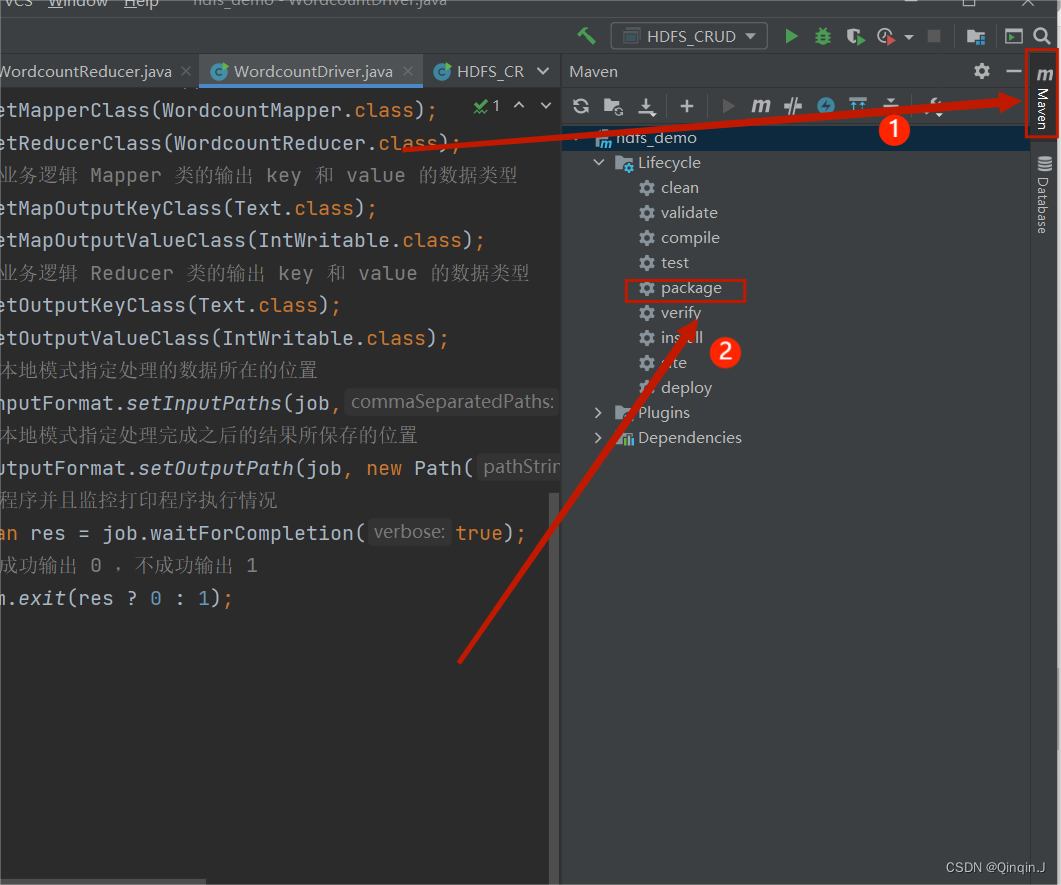
结果出现以下字段则打包成功
-
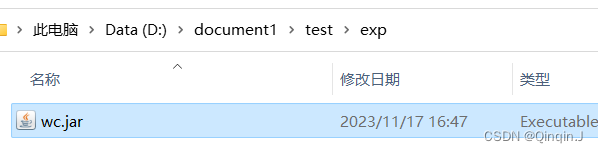
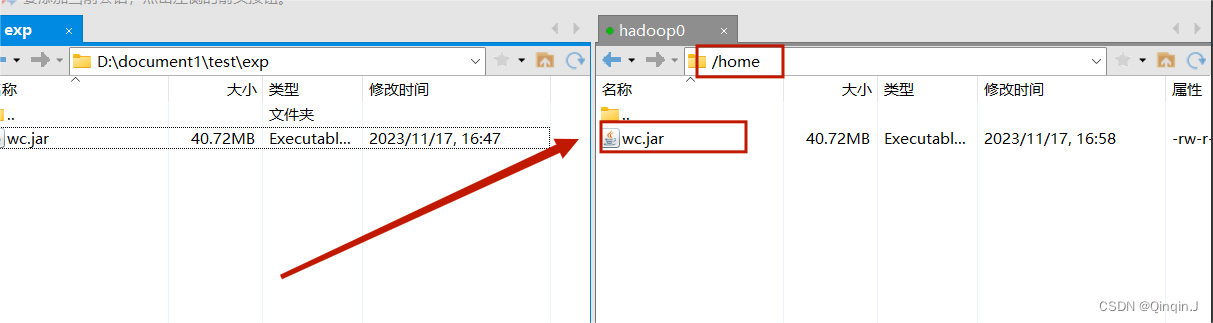
*上传到虚拟机的home目录下
右键打开

重命名为wc

随便复制到一个目录下
使用远程连接工具(Xshell或者SecurityCRT)进行上传
-
*进行集群运行
进入home目录
cd /home
ll
在 WordcountDriver.java下复制路径

hadoop jar wc.jar com.itcast.mrdemo.WordcountDriver运行结果
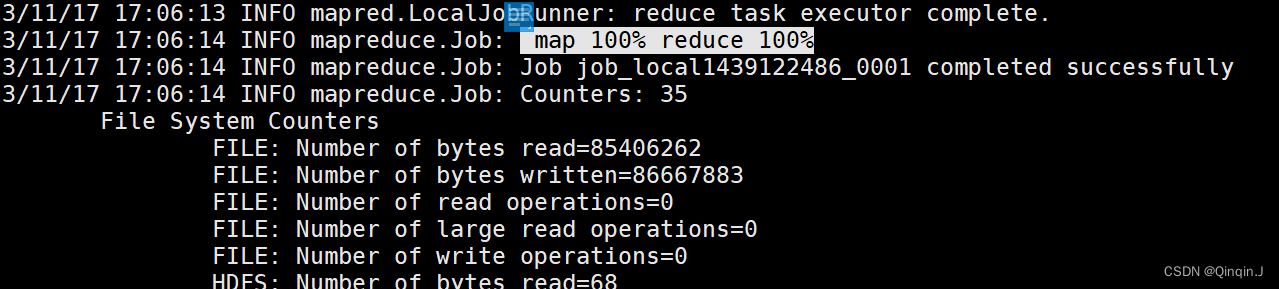
-
*查看HDFS 集群
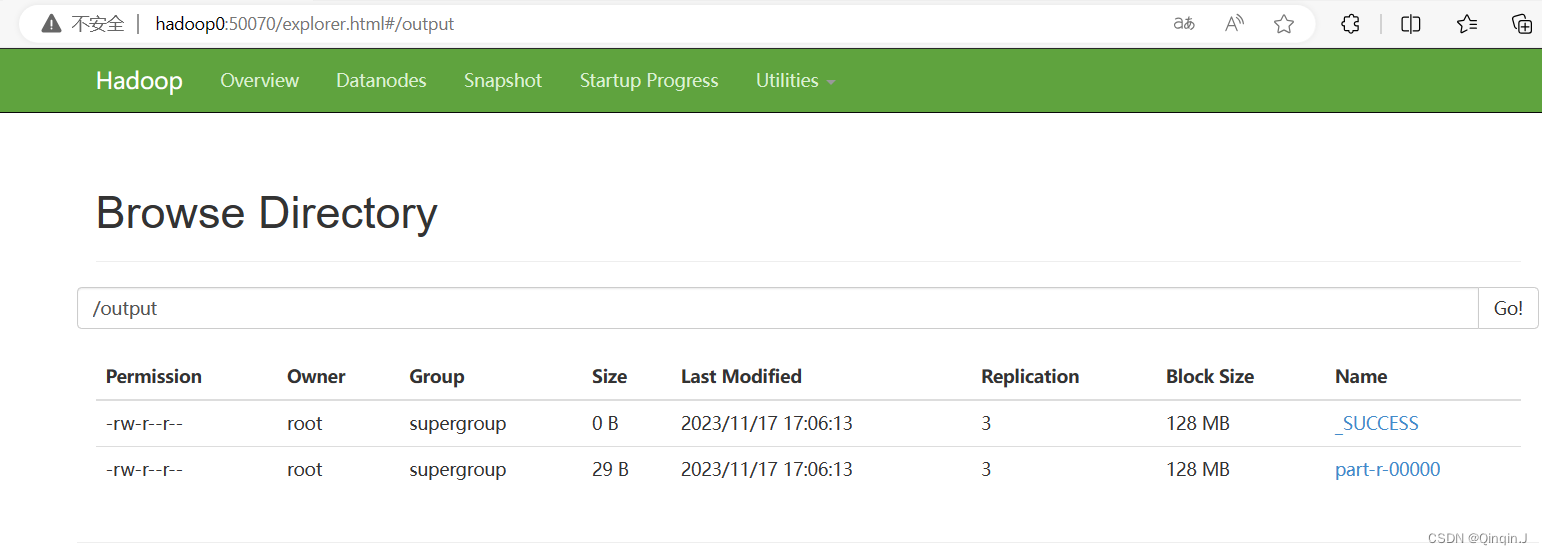
进行查看
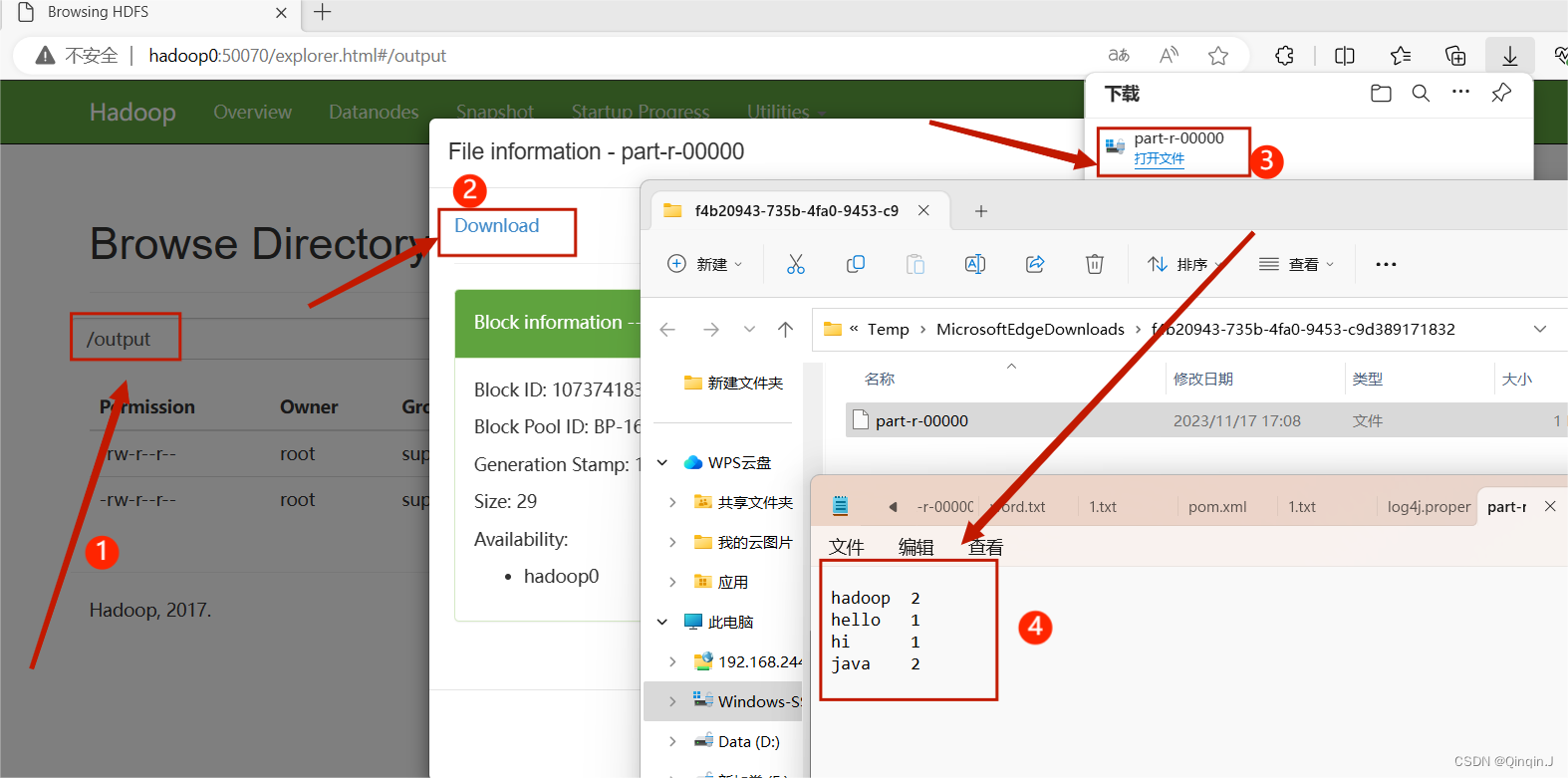
集群运行成功
4、运行前准备操作
现在目录下创建一个文本
编写内容(随意编写)

5、Error while running command to get file permissions : java.io.IOException: (null) entry in command string: null ls -F D:\homework2\Hadoop\mr\input\word.txt
出现以下错误

解决方法一
下载winutils.exe和hadoop.dll放到C:\Windows\System32
链接:https://pan.baidu.com/s/1XwwUD9j3YT2AJMUNHmyzhw
提取码:q7i7
解决方法二
输入指定文本路径

然后运行
相关文章:
Hadoop学习总结(MapRdeuce的词频统计)
MapRdeuce编程示例——词频统计 一、MapRdeuce的词频统计的过程 二、编程过程 1、Mapper 组件 WordcountMapper.java package com.itcast.mrdemo;import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; …...

PPT基础入门
目录 相关设置快捷键shift 快捷键Ctrl 快捷键Ctrl Shift 组合快捷键快捷键总结 相关设置 设置撤回次数 自动保存 图片压缩 字体嵌入:目的是在不同的电脑上保留已经设置好的字体 多格式导出 (1)可以导出PDF (2)可以导…...

Java 语言关键字有哪些
Java 语言关键字有哪些 分类关键字访问控制privateprotectedpublic类,方法和变量修饰符abstractclassextendsfinalimplementsinterfacenativenewstaticstrictfpsynchronizedtransientvolatileenum程序控制breakcontinuereturndowhileifelseforinstanceofswitchcase…...

Go vs Rust:文件上传性能比较
在本文中,主要测试并比较了Go—Gin和Rust—Actix之间的多部分文件上传性能。 设置 所有测试都在配备16G内存的 MacBook Pro M1 上执行。 软件版本为: Go v1.20.5Rust v1.70.0 测试工具是一个基于 libcurl 并使用标准线程的自定义工具,能…...
C# NAudio 音频库
C# NAudio 音频库 NAudio安装NAudio简述简单示例1录制麦克风录制系统声卡WAV格式播放MP3格式播放AudioFileReader读取播放音频MediaFoundationReader 读取播放音频 NAudio安装 项目>NuGet包管理器 搜索NAudio点击安装,自动安装依赖库。 安装成功后工具箱会新增…...
springcloudalibaba-3
一、Nacos Config入门 1. 搭建nacos环境【使用现有的nacos环境即可】 使用之前的即可 2. 在微服务中引入nacos的依赖 <!-- nacos配置依赖 --><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-…...

异步复位同步释放与同步复位打拍
参考链接:复位系列之异步复位同步释放与同步复位打拍...

使用Python进行二维图像的三维重建
2D图像的三维重建是从一组2D图像中创建对象或场景的三维模型的过程。这个技术广泛应用于计算机视觉、机器人技术和虚拟现实等领域。 在本文中,我们将解释如何使用Python执行从2D图像到三维重建的过程。我们将使用TempleRing数据集作为示例,逐步演示这个过…...

go-zero微服务的使用
一、入门案例 1、使用goland创建一个工程 2、新建一个user.proto syntax "proto3";package user; // 这个地方表示生成的go的包名叫user option go_package "./user";message UserInfoRequest {int64 userId 1; }message UserInfoResponse {int64 user…...

Java排序算法之基数排序
基数排序(Radix Sort)是一种线性时间复杂度的排序算法,其时间复杂度为O(d(nk)),其中d是数字的位数,k是进制数。基数排序是一种非比较排序算法,它按照数位的大小来进行排序。它可以处理正整数、负整数和小数…...
Ubuntu20.0中安装Gradle
下载Gradle到temp文件夹 wget https://services.gradle.org/distributions/gradle-8.3-bin.zip -P /tmp 然后解压文件到/opt/gradle目录 sudo unzip -d /opt/gradle /tmp/gradle-8.3.zip 配置Gradle环境变量 接下来我们会创建一个gradle.sh文件来保存Gradle的环境变量 sudo…...

【Java并发编程六】多线程越界问题
ArrayList()越界错误 import java.util.ArrayList; public class myTest implements Runnable {static ArrayList<Integer> a new ArrayList<>(10);public static void main(String[] args) throws InterruptedException {Thread t1 new Thread(new myTest());T…...

聊聊httpclient的disableConnectionState
序 本文主要研究一下httpclient的disableConnectionState disableConnectionState org/apache/http/impl/client/HttpClientBuilder.java /*** Disables connection state tracking.*/public final HttpClientBuilder disableConnectionState() {connectionStateDisabled t…...
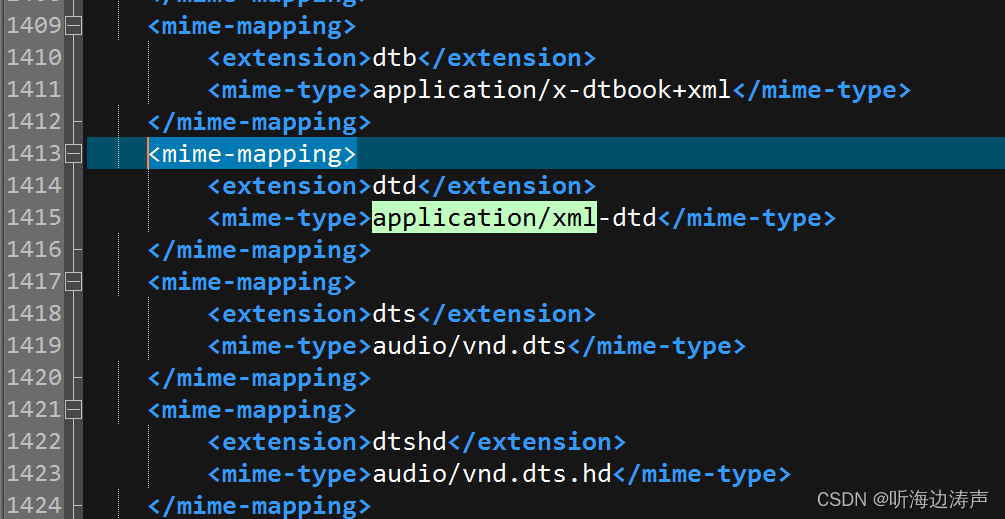
Tomcat web.xml文件中的mime-mapping
在Tomcat安装目录的conf/web.xml文件中,定义了大量的<mime-mapping>元素,例如: 其中<extension>指定了文件的扩展名,<mime-type>指定了mime类型,放在<mime-mapping>元素中,就是将…...

【Java 进阶篇】JQuery 事件绑定:`on` 与 `off` 的奇妙舞曲
在前端开发的舞台上,用户与页面的互动是一场精彩的表演。而 JQuery,作为 JavaScript 的一种封装库,为这场表演提供了更为便捷和优雅的事件绑定方式。其中,on 和 off 两位主角,正是这场奇妙舞曲中的核心演员。在这篇博客…...

模块化Common JS 和 ES Module
目录 历程 1.几个函数:全局变量的污染,模块间没有联系 2.对象:暴露成员,外部可修改 3.立即执行函数:闭包实现模块私有作用域 common JS module和Module 过程 模块依赖:深度优先遍历、父 -> 子 -…...
基于java web个人财务管理系统
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:采用JSP技术开发 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目&#x…...

soc估计:DESIGN AND DEVELOPMENT OF SoC ESTIMATION MODEL USING MACHINE LEARNING
这是一篇印度那边学生的毕业论文,唯一要记录的是里面提到了一个特征构造的思想,记录如下: 论文思想: 特征选用速度、电流、电压、温度、平均电压、平均电流、平均速度,模型用cnnlstmlrlr 平均特征计算方式:…...
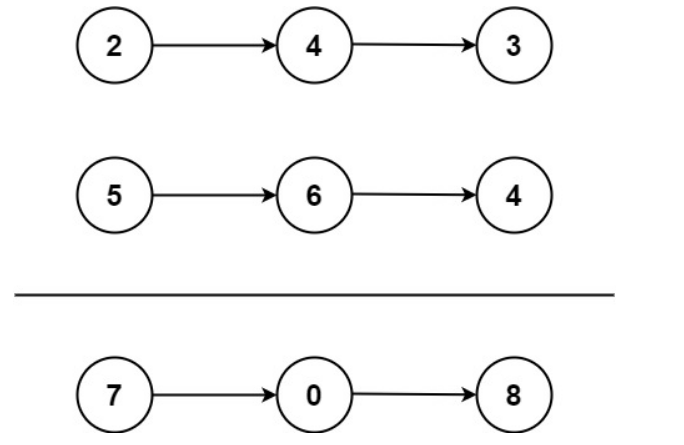
2、LeetCode之两数相加
给你两个非空的链表,表示两个非负的整数。它们每位数字都是按照逆序的方式存储的,并且每个节点只能存储一位数字。请你将两个数相加,并以相同形式返回一个表示和的链表。你可以假设除了数字0之外,这两个数都不会以0开头。 输入&am…...

redis三种集群方式
redis有三种集群方式:主从复制,哨兵模式和集群。 1.主从复制 主从复制原理: 从服务器连接主服务器,发送SYNC命令; 主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所…...

别再为单细胞数据批次效应发愁了!手把手教你用Harmony算法搞定整合分析
单细胞数据整合实战:用Harmony消除批次效应的完整指南当你在不同时间、不同实验室或使用不同平台获得多个单细胞RNA测序数据集时,最令人头疼的问题莫过于批次效应——这种技术性差异会掩盖真实的生物学信号。想象一下,你精心设计的实验因为数…...

Web安全 - 国密 SSL / TLCP 接入手把手系列
文章目录这个系列覆盖什么系列目录本系列和已有文档的关系权威资料入口这是一套面向“从来没接过国密 SSL”的开发者写的系列博客。它以本工程 gm-ssl-client 为主线,先补齐 SSL/TLS、国密算法、TLCP、证书、Java Provider 等基础知识,再一步一步讲清楚如…...

Flutter国际化与本地化完全指南
Flutter国际化与本地化完全指南 引言 国际化是构建全球化应用的关键环节,Flutter提供了完善的国际化支持。本文将深入探讨Flutter中的国际化和本地化技术。 一、基础配置 1.1 添加依赖 dependencies:flutter_localizations:sdk: flutterintl: ^0.18.11.2 更新main.d…...

为什么你的ChatGPT故事没人看?揭秘3个被99%人忽略的叙事熵值指标及实时优化方案
更多请点击: https://codechina.net 第一章:为什么你的ChatGPT故事没人看?揭秘3个被99%人忽略的叙事熵值指标及实时优化方案 当一篇关于ChatGPT的实操笔记获得不到50次阅读,问题往往不在模型能力,而在人类注意力的底层…...

机器学习海气耦合模型Ola:解耦训练与滞后集合预报实战
1. 项目概述:当机器学习遇见海气耦合在气候预测这个领域里摸爬滚打了十几年,我见过太多复杂的物理模型和让人头大的耦合方案。传统的海气耦合模型,比如那些基于物理方程组的数值模式,虽然机理清晰,但计算成本高得吓人&…...

第39天:SQL详解之DQL
Python学习100天(从入门到精通系列文章) 文章目录 Python学习100天(从入门到精通系列文章) 前言 一、基本查询与投影 1.1 查询所有列 1.2 投影与别名 二、数据筛选(WHERE 子句) 2.1 等值与比较筛选 2.2 多条件组合(AND / OR) 2.3 范围查询(BETWEEN) 2.4 CASE 表达式与…...

5分钟实现Windows三指拖拽:macOS手势体验的终极解决方案
5分钟实现Windows三指拖拽:macOS手势体验的终极解决方案 【免费下载链接】ThreeFingersDragOnWindows Enables macOS-style three-finger dragging functionality on Windows Precision touchpads. 项目地址: https://gitcode.com/gh_mirrors/th/ThreeFingersDrag…...

机器学习在考古学中的应用:从数据准备到模型选择的完整工作流指南
1. 考古学中的机器学习:从“黑箱”工具到研究伙伴如果你是一位考古学家,面对堆积如山的陶片、覆盖数平方公里的遥感影像,或是成千上万个需要分类的动物骨骼碎片,你是否曾感到力不从心?十年前,处理这些数据可…...

多保真度机器学习加速卟啉-粘土体系激子动力学模拟
1. 项目概述:当机器学习遇见量子化学,破解卟啉-粘土体系能量转移之谜在人工光合作用和下一代太阳能电池材料的研发前沿,科学家们一直致力于模仿自然界的高效光捕获系统。想象一下,植物和某些细菌中的叶绿素分子,能够近…...

零起点Python机器学习快速入门【1.1】
1.4 机器学习经典案例目前人工智能、机器学习正处于黄金时期,各种应用随处可见,以下是一些常见的机器学习应用案例。 机器人客服:当你拨打移动、银行等公司的服务热线时,大部分都是通过人工智能技术合成的电脑客服在和你沟通&am…...