力扣刷题篇之位运算
系列文章目录
目录
系列文章目录
前言
一、位运算的基本运算
二、位运算的技巧
三、布隆过滤器
总结
前言
本系列是个人力扣刷题汇总,本文是数与位。刷题顺序按照[力扣刷题攻略] Re:从零开始的力扣刷题生活 - 力扣(LeetCode)
位运算其实之前的 左程云算法与数据结构代码汇总之排序(Java)-CSDN博客
也有总结到过。 原数异或0等于本身,原数异或本身等于0。异或可以看作无进位相加。

一、位运算的基本运算
136. 只出现一次的数字 - 力扣(LeetCode)


class Solution {public int singleNumber(int[] nums) {int result=0;for(int num:nums){result=result^num;}return result;}
}
190. 颠倒二进制位 - 力扣(LeetCode)
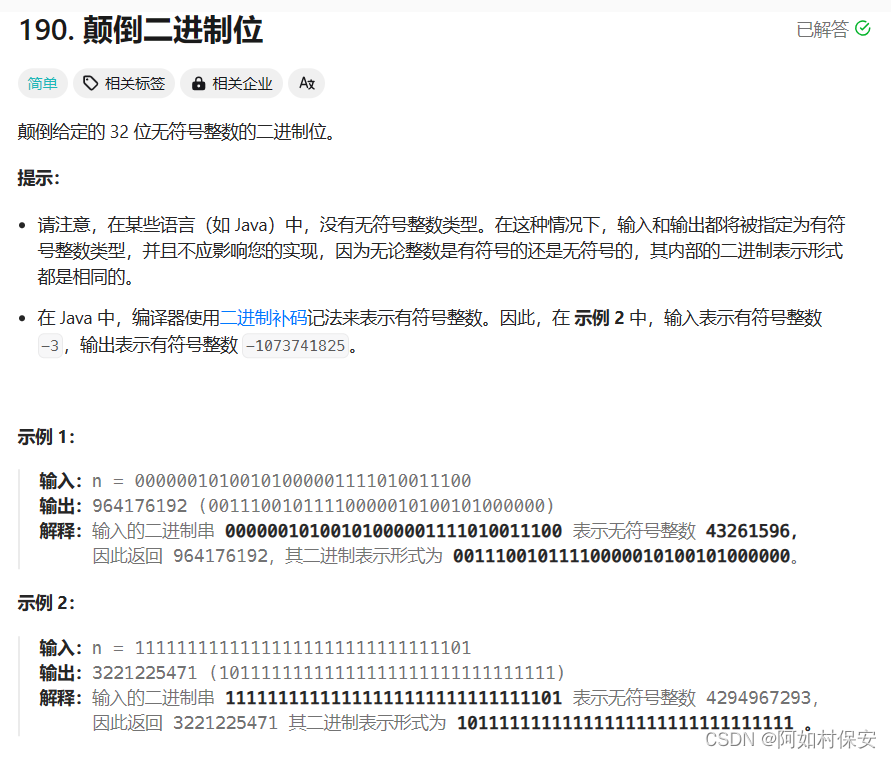

通过循环,将 result 左移一位,然后将 n 的最低位加到 result 中,最后右移 n,处理下一位。重复这个过程直到处理完 n 的所有位。
public class Solution {// you need treat n as an unsigned valuepublic int reverseBits(int n) {int result = 0;for (int i = 0; i < 32; i++) {// 将 result 左移一位,空出最低位result <<= 1;// 取 n 的最低位,加到 result 中result |= (n & 1);// 右移 n,继续处理下一位n >>= 1;}return result;}
}

191. 位1的个数 - 力扣(LeetCode)


通过循环,将 n 与 1 进行位与操作,统计最低位是否为 1,然后将 n 右移一位,继续处理下一位,直到 n 的所有位都处理完。
public class Solution {// you need to treat n as an unsigned valuepublic int hammingWeight(int n) {int count = 0;while (n != 0) {// 将 n 与 1 进行位与操作,统计最低位是否为 1count += (n & 1);// 将 n 右移一位n >>>= 1;}return count;}
}


201. 数字范围按位与 - 力扣(LeetCode)

通过找到 left 和 right 二进制表示的最长公共前缀来解决。因为对于任何不同的位,按位与的结果一定是 0。
class Solution {public int rangeBitwiseAnd(int left, int right) {int shift = 0;// 找到最长公共前缀while (left < right) {left >>= 1;right >>= 1;shift++;}// 将最长公共前缀左移,右边用零填充return left << shift;}
}
338. 比特位计数 - 力扣(LeetCode)


class Solution {public int[] countBits(int n) {int[] ans = new int[n+1];ans[0] = 0;for(int i = 1; i <= n; i++) {ans[i] = ans[i >> 1] + i % 2;}return ans;}
}
二、位运算的技巧
260. 只出现一次的数字 III - 力扣(LeetCode)


这个之前就总结过了。
先全部异或,再找从右边开始两个数不同的第一位(为1的位);通过&其补码获得,最后分两组进行异或。
class Solution {public int[] singleNumber(int[] nums) {int xorAll = 0;for(int x:nums){xorAll ^= x;}int lowBit = xorAll & -xorAll;int[] ans = new int[2];int a1 = 0, a2 = 0;for(int x:nums){if((x & lowBit) != 0){a1 ^= x;}else{a2 ^= x;}}return new int[]{a1,a2};}
}
342. 4的幂 - 力扣(LeetCode)


class Solution {public boolean isPowerOfFour(int n) {long i = 1;while(i < n){i*=4;}return i == n;}
}
371. 两整数之和 - 力扣(LeetCode)

利用了异或运算和与运算的性质,避免使用传统的加法运算符。
class Solution {public int getSum(int a, int b) {//当进位数没有了,证明计算完成while (b != 0) {//计算不进位的数int tempA = a ^ b;//计算进位的数int tempB = (a & b) << 1;a = tempA;b = tempB;}return a;}
}
三、布隆过滤器
705. 设计哈希集合 - 力扣(LeetCode)


这种之前哈希表已经总结过了
class MyHashSet {/** Initialize your data structure here. */boolean[] map = new boolean[1000005];public MyHashSet() {}public void add(int key) {map[key] = true;}public void remove(int key) {map[key] = false;}/** Returns true if this set contains the specified element */public boolean contains(int key) {return map[key] == true;}
}/*** Your MyHashSet object will be instantiated and called as such:* MyHashSet obj = new MyHashSet();* obj.add(key);* obj.remove(key);* boolean param_3 = obj.contains(key);*/
// class MyHashSet {// /** Initialize your data structure here. */
// boolean[] map = new boolean[1000005];
// public MyHashSet() {// }// public void add(int key) {
// map[key] = true;
// }// public void remove(int key) {
// map[key] = false;
// }// /** Returns true if this set contains the specified element */
// public boolean contains(int key) {
// return map[key] == true;
// }
// }// /**
// * Your MyHashSet object will be instantiated and called as such:
// * MyHashSet obj = new MyHashSet();
// * obj.add(key);
// * obj.remove(key);
// * boolean param_3 = obj.contains(key);
// */class MyHashSet {private static final int BASE = 769;private LinkedList[] data;/** Initialize your data structure here. */public MyHashSet() {data = new LinkedList[BASE];for (int i = 0; i < BASE; ++i) {data[i] = new LinkedList<Integer>();}}public void add(int key) {int h = hash(key);Iterator<Integer> iterator = data[h].iterator();while (iterator.hasNext()) {Integer element = iterator.next();if (element == key) {return;}}data[h].offerLast(key);}public void remove(int key) {int h = hash(key);Iterator<Integer> iterator = data[h].iterator();while (iterator.hasNext()) {Integer element = iterator.next();if (element == key) {data[h].remove(element);return;}}}/** Returns true if this set contains the specified element */public boolean contains(int key) {int h = hash(key);Iterator<Integer> iterator = data[h].iterator();while (iterator.hasNext()) {Integer element = iterator.next();if (element == key) {return true;}}return false;}private static int hash(int key) {return key % BASE;}
}
706. 设计哈希映射 - 力扣(LeetCode)


class MyHashMap {static int n=6774;int[] s;int[] v;public MyHashMap() {s=new int[n];v=new int[n];Arrays.fill(s,n);}public void put(int key, int value) {int k=f(key);s[k]=key;v[k]=value;}public int get(int key) {int k=f(key);if(s[k]==n) return -1;return v[k];}public void remove(int key) {v[f(key)]=-1;}public int f(int x){int k=x%n;while(s[k]!=x&&s[k]!=n){k++;if(k==n) k=0;}return k;}
}/*** Your MyHashMap object will be instantiated and called as such:* MyHashMap obj = new MyHashMap();* obj.put(key,value);* int param_2 = obj.get(key);* obj.remove(key);*/
1044. 最长重复子串 - 力扣(LeetCode)

基于DC3算法的后缀数组构建,并使用后缀数组求解最长重复子串问题
DC3算法,该算法用于构建后缀数组。后缀数组构建完成后,根据height数组找到最长的重复子串。这个还要仔细研究
class Solution {public static String longestDupSubstring(String s) {int length = s.length();int[] arr = new int[length];for (int i = 0; i < length; i++) {arr[i] = s.charAt(i);}DC3 dc3 = new DC3(arr);int[] height = dc3.getHeight();int[] suffix = dc3.getSuffix();int max = height[0];// height中的最大值int maxIndex = -1;// height中的最大值的下标for (int i = 1; i < length; i++) {if (height[i] > max) {maxIndex = i;max = height[i];}}return maxIndex == -1 ? "" : s.substring(suffix[maxIndex]).substring(0, max);}private static class DC3{private final int[] suffix;// 后缀数组,里面的元素按照字典序从小到大排.suffix[a]=b表示b对应的后缀排第a名private final int[] rank;// suffix的伴生数组,含义和suffix相反.rank[a]=b表示a对应的后缀排第b名private final int[] height;// height[i]表示第i名后缀和第i-1名后缀的最长公共前缀的长度,i从0开始,i表示名次public int[] getSuffix() {return suffix;}public int[] getRank() {return rank;}public int[] getHeight() {return height;}public DC3(int[] arr) {suffix = suffix(arr);// 求arr的后缀数组rank = rank(suffix);height = height(arr);}private int[] height(int[] arr) {int length = arr.length;int[] result = new int[length];for (int i = 0, value = 0; i < length; i++) {if (rank[i] != 0) {if (value > 0) {value--;}int pre = suffix[rank[i] - 1];while (i + value < length && pre + value < length && arr[i + value] == arr[pre + value]) {value++;}result[rank[i]] = value;}}return result;}private int[] rank(int[] suffix) {int length = suffix.length;int[] result = new int[length];// 将suffix数组的下标和元素值互换即可for (int i = 0; i < length; i++) {result[suffix[i]] = i;}return result;}private int[] suffix(int[] arr) {int max = getMax(arr);int length = arr.length;int[] newArr = new int[length + 3];System.arraycopy(arr, 0, newArr, 0, length);return skew(newArr, length, max + 1);}private int[] skew(int[] arr, int length, int num) {// eg:下标为0,3,6,9,12...属于s0类;下标为1,4,7,10,13...属于s1类;下标为2,5,8,11,14...属于s2类;int n0 = (length + 2) / 3;// s0类个数int n1 = (length + 1) / 3;// s1类个数int n2 = length / 3;// s2类个数int n02 = n0 + n2;// s02类的个数// 按照定义,n0个数要么比n1和n2多1个,要么相等.因此s12的大小用n02而不是n12是为了处理边界条件,防止数组越界判断int[] s12 = new int[n02 + 3];int[] sf12 = new int[n02 + 3];// 记录s12类的排名// 统计s12类下标都有哪些,放到s12中for (int i = 0, j = 0; i < length + (n0 - n1); i++) {if (i % 3 != 0) {s12[j++] = i;}}// 将s12类排序,排序结果最终会放到sf12中radixPass(arr, s12, sf12, 2, n02, num);// 按照"个位数"排序,结果放到sf12中radixPass(arr, sf12, s12, 1, n02, num);// 按照"十位数"排序,结果放到s12中radixPass(arr, s12, sf12, 0, n02, num);// 按照"百位数"排序,结果放到sf12中int rank = 0; // 记录了排名int ascii1 = -1, ascii2 = -1, ascii3 = -1;// 记录了3个字符的ascii码for (int i = 0; i < n02; i++) {if (ascii1 != arr[sf12[i]] || ascii2 != arr[sf12[i] + 1] || ascii3 != arr[sf12[i] + 2]) {rank++;ascii1 = arr[sf12[i]];ascii2 = arr[sf12[i] + 1];ascii3 = arr[sf12[i] + 2];}if (sf12[i] % 3 == 1) {s12[sf12[i] / 3] = rank;// 计算s1类的排名} else {// sf12[i]的值只有s1或s2类的,因此走到这里必定是s2类的s12[sf12[i] / 3 + n0] = rank;// 计算s2类的排名}}if (rank < n02) {sf12 = skew(s12, n02, rank + 1);// 递归调用直到有序,有序的排名结果放到sf12中for (int i = 0; i < n02; i++) {s12[sf12[i]] = i + 1;}} else {// 若s12已经有序了,则根据s12直接得到sf12即可for (int i = 0; i < n02; i++) {sf12[s12[i] - 1] = i;}}// 对s0类进行排序,排序结果放到sf0中int[] s0 = new int[n0];int[] sf0 = new int[n0];for (int i = 0, j = 0; i < n02; i++) {if (sf12[i] < n0) {s0[j++] = 3 * sf12[i];}}radixPass(arr, s0, sf0, 0, n0, num);int[] suffix = new int[length];// 记录最终排序for (int p = 0, t = n0 - n1, k = 0; k < length; k++) {int i = sf12[t] < n0 ? sf12[t] * 3 + 1 : (sf12[t] - n0) * 3 + 2;int j = sf0[p];if (sf12[t] < n0 ? abOrder(arr[i], s12[sf12[t] + n0], arr[j], s12[j / 3]): abOrder(arr[i], arr[i + 1], s12[sf12[t] - n0 + 1], arr[j], arr[j + 1], s12[j / 3 + n0])) {suffix[k] = i;t++;if (t == n02) {for (k++; p < n0; p++, k++) {suffix[k] = sf0[p];}}} else {suffix[k] = j;p++;if (p == n0) {for (k++; t < n02; t++, k++) {suffix[k] = sf12[t] < n0 ? sf12[t] * 3 + 1 : (sf12[t] - n0) * 3 + 2;}}}}return suffix;}private void radixPass(int[] arr, int[] input, int[] output, int offset, int limit, int num) {int[] barrel = new int[num];// 桶// 统计各个桶中元素的数量for (int i = 0; i < limit; i++) {barrel[arr[input[i] + offset]]++;}for (int i = 0, sum = 0; i < num; i++) {int temp = barrel[i];barrel[i] = sum;sum += temp;}// 将本趟基排结果放到output中for (int i = 0; i < limit; i++) {output[barrel[arr[input[i] + offset]]++] = input[i];}}// 比较(x1,y1)和(x2,y2)的字典序,前者<=后者返回trueprivate boolean abOrder(int x1, int y1, int x2, int y2) {return (x1 < x2) || (x1 == x2 && y1 <= y2);}// 比较(x1,y1,z1)和(x2,y2,z2)的字典序,前者<=后者返回trueprivate boolean abOrder(int x1, int y1, int z1, int x2, int y2, int z2) {return (x1 < x2) || (x1 == x2 && abOrder(y1, z1, y2, z2));}// 获取数组的最大值private int getMax(int[] arr) {int max = Integer.MIN_VALUE;for (int i : arr) {max = Math.max(max, i);}return max;}}
}
211. 添加与搜索单词 - 数据结构设计 - 力扣(LeetCode)


class WordDictionary {private WordDictionary[] items; // 数组用于存储子节点boolean isEnd; // 表示当前节点是否是一个单词的结束节点public WordDictionary() {items = new WordDictionary[26]; // 初始化子节点数组}// 向 WordDictionary 中添加单词public void addWord(String word) {WordDictionary curr = this;int n = word.length();// 逐个字母遍历单词for (int i = 0; i < n; i++) {int index = word.charAt(i) - 'a';// 如果当前节点的子节点数组中没有对应字母的节点,则创建一个新的节点if (curr.items[index] == null) {curr.items[index] = new WordDictionary();}curr = curr.items[index]; // 继续向下遍历}curr.isEnd = true; // 将单词的最后一个字母节点的 isEnd 设置为 true,表示这是一个单词的结束}// 搜索给定的单词public boolean search(String word) {return search(this, word, 0);}// 递归搜索单词private boolean search(WordDictionary curr, String word, int start) {int n = word.length();// 如果已经遍历完单词,判断当前节点是否是一个单词的结束节点if (start == n) {return curr.isEnd;}char c = word.charAt(start);// 如果当前字母不是通配符 '.',直接查找对应的子节点if (c != '.') {WordDictionary item = curr.items[c - 'a'];return item != null && search(item, word, start + 1);}// 如果字母是通配符 '.',遍历当前节点的所有子节点,递归调用 search 方法for (int j = 0; j < 26; j++) {if (curr.items[j] != null && search(curr.items[j], word, start + 1)) {return true;}}return false;}
}

总结
布隆过滤器这里难一点,其他都很简单,开心!
DC3算法还要去搞清楚一下。
相关文章:
力扣刷题篇之位运算
系列文章目录 目录 系列文章目录 前言 一、位运算的基本运算 二、位运算的技巧 三、布隆过滤器 总结 前言 本系列是个人力扣刷题汇总,本文是数与位。刷题顺序按照[力扣刷题攻略] Re:从零开始的力扣刷题生活 - 力扣(LeetCode࿰…...

asp.net core mvc 控制器使用配置
一、在根目录 添加 mysettings.json 文件 mysettings.json 文件代码如下: {"MySettings": {"Name": "独立配置文件","Site": "lt"} }appsettings.json 文件代码如下: {"Logging": {&quo…...

Hadoop学习总结(MapRdeuce的词频统计)
MapRdeuce编程示例——词频统计 一、MapRdeuce的词频统计的过程 二、编程过程 1、Mapper 组件 WordcountMapper.java package com.itcast.mrdemo;import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; …...

PPT基础入门
目录 相关设置快捷键shift 快捷键Ctrl 快捷键Ctrl Shift 组合快捷键快捷键总结 相关设置 设置撤回次数 自动保存 图片压缩 字体嵌入:目的是在不同的电脑上保留已经设置好的字体 多格式导出 (1)可以导出PDF (2)可以导…...

Java 语言关键字有哪些
Java 语言关键字有哪些 分类关键字访问控制privateprotectedpublic类,方法和变量修饰符abstractclassextendsfinalimplementsinterfacenativenewstaticstrictfpsynchronizedtransientvolatileenum程序控制breakcontinuereturndowhileifelseforinstanceofswitchcase…...

Go vs Rust:文件上传性能比较
在本文中,主要测试并比较了Go—Gin和Rust—Actix之间的多部分文件上传性能。 设置 所有测试都在配备16G内存的 MacBook Pro M1 上执行。 软件版本为: Go v1.20.5Rust v1.70.0 测试工具是一个基于 libcurl 并使用标准线程的自定义工具,能…...
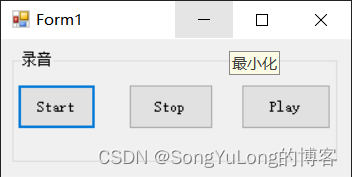
C# NAudio 音频库
C# NAudio 音频库 NAudio安装NAudio简述简单示例1录制麦克风录制系统声卡WAV格式播放MP3格式播放AudioFileReader读取播放音频MediaFoundationReader 读取播放音频 NAudio安装 项目>NuGet包管理器 搜索NAudio点击安装,自动安装依赖库。 安装成功后工具箱会新增…...
springcloudalibaba-3
一、Nacos Config入门 1. 搭建nacos环境【使用现有的nacos环境即可】 使用之前的即可 2. 在微服务中引入nacos的依赖 <!-- nacos配置依赖 --><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-…...

异步复位同步释放与同步复位打拍
参考链接:复位系列之异步复位同步释放与同步复位打拍...

使用Python进行二维图像的三维重建
2D图像的三维重建是从一组2D图像中创建对象或场景的三维模型的过程。这个技术广泛应用于计算机视觉、机器人技术和虚拟现实等领域。 在本文中,我们将解释如何使用Python执行从2D图像到三维重建的过程。我们将使用TempleRing数据集作为示例,逐步演示这个过…...

go-zero微服务的使用
一、入门案例 1、使用goland创建一个工程 2、新建一个user.proto syntax "proto3";package user; // 这个地方表示生成的go的包名叫user option go_package "./user";message UserInfoRequest {int64 userId 1; }message UserInfoResponse {int64 user…...

Java排序算法之基数排序
基数排序(Radix Sort)是一种线性时间复杂度的排序算法,其时间复杂度为O(d(nk)),其中d是数字的位数,k是进制数。基数排序是一种非比较排序算法,它按照数位的大小来进行排序。它可以处理正整数、负整数和小数…...
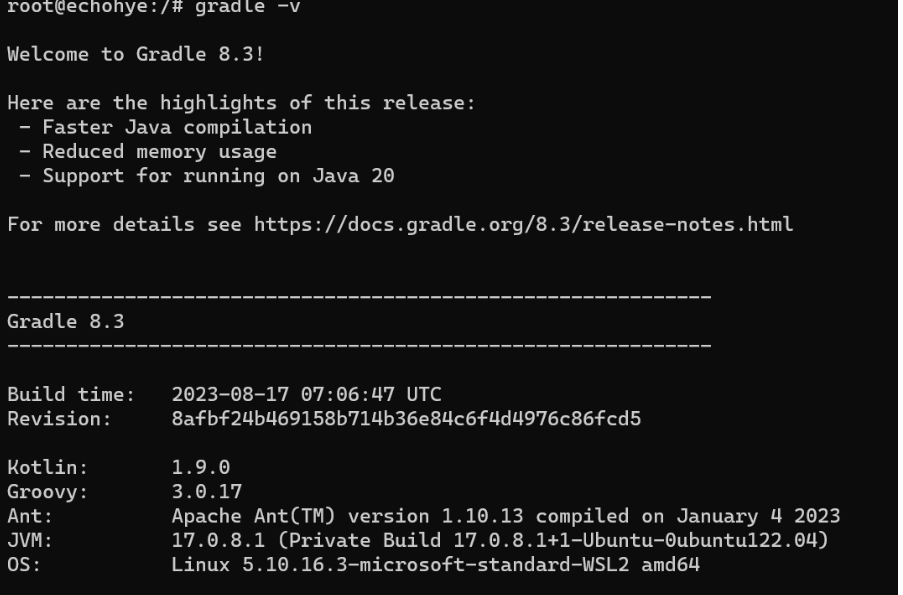
Ubuntu20.0中安装Gradle
下载Gradle到temp文件夹 wget https://services.gradle.org/distributions/gradle-8.3-bin.zip -P /tmp 然后解压文件到/opt/gradle目录 sudo unzip -d /opt/gradle /tmp/gradle-8.3.zip 配置Gradle环境变量 接下来我们会创建一个gradle.sh文件来保存Gradle的环境变量 sudo…...

【Java并发编程六】多线程越界问题
ArrayList()越界错误 import java.util.ArrayList; public class myTest implements Runnable {static ArrayList<Integer> a new ArrayList<>(10);public static void main(String[] args) throws InterruptedException {Thread t1 new Thread(new myTest());T…...

聊聊httpclient的disableConnectionState
序 本文主要研究一下httpclient的disableConnectionState disableConnectionState org/apache/http/impl/client/HttpClientBuilder.java /*** Disables connection state tracking.*/public final HttpClientBuilder disableConnectionState() {connectionStateDisabled t…...
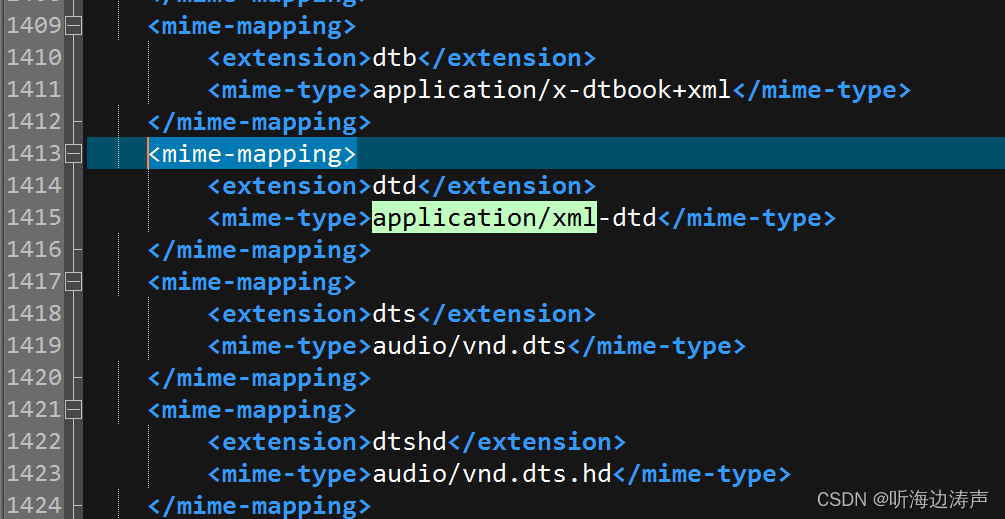
Tomcat web.xml文件中的mime-mapping
在Tomcat安装目录的conf/web.xml文件中,定义了大量的<mime-mapping>元素,例如: 其中<extension>指定了文件的扩展名,<mime-type>指定了mime类型,放在<mime-mapping>元素中,就是将…...

【Java 进阶篇】JQuery 事件绑定:`on` 与 `off` 的奇妙舞曲
在前端开发的舞台上,用户与页面的互动是一场精彩的表演。而 JQuery,作为 JavaScript 的一种封装库,为这场表演提供了更为便捷和优雅的事件绑定方式。其中,on 和 off 两位主角,正是这场奇妙舞曲中的核心演员。在这篇博客…...

模块化Common JS 和 ES Module
目录 历程 1.几个函数:全局变量的污染,模块间没有联系 2.对象:暴露成员,外部可修改 3.立即执行函数:闭包实现模块私有作用域 common JS module和Module 过程 模块依赖:深度优先遍历、父 -> 子 -…...
基于java web个人财务管理系统
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:采用JSP技术开发 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目&#x…...

soc估计:DESIGN AND DEVELOPMENT OF SoC ESTIMATION MODEL USING MACHINE LEARNING
这是一篇印度那边学生的毕业论文,唯一要记录的是里面提到了一个特征构造的思想,记录如下: 论文思想: 特征选用速度、电流、电压、温度、平均电压、平均电流、平均速度,模型用cnnlstmlrlr 平均特征计算方式:…...

AI与精益创业结合驱动产品创新的方法论
1. 人工智能与精益创业方法如何驱动产品创新在当今快速变化的商业环境中,初创企业面临着前所未有的竞争压力。传统产品开发模式往往需要数月甚至数年的周期,投入大量资源后才发现市场并不买账。这种"闭门造车"的方式在数字化时代显得越来越力不…...

Java的背景知识及快速入门
Java的背景知识1.Java的历史知识Java是哪家公司的产品?Java是美国Sun(Stanford University Network,斯坦福大学网络公司)公司在1995年推出的一 门计算机高级编程语言。但是在2009年是Sun公司被Oracle(甲骨文࿰…...

3D光学流技术在机器人动作生成中的应用与优化
1. 3D光学流技术解析与机器人动作生成3D光学流技术是计算机视觉领域的重要突破,它通过分析物体在三维空间中的连续运动轨迹,为机器人动作规划提供了前所未有的精确度。传统2D光学流仅能捕捉平面运动信息,而3D光学流则能完整重建物体在XYZ三个…...

【DeepSeek边缘部署实战指南】:20年架构师亲授5大避坑法则与3步极简上线法
更多请点击: https://codechina.net 第一章:DeepSeek边缘部署的演进逻辑与核心挑战 随着大模型从云端向终端下沉,DeepSeek系列模型在边缘侧的部署正经历从“能跑”到“稳跑”、从“单点适配”到“全栈协同”的范式跃迁。这一演进并非单纯的技…...

通过curl命令快速测试Taotoken的API连通性与返回
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken的API连通性与返回 在集成大模型服务时,直接使用curl命令进行API测试是一种高效且通用的…...
,附可直接复用的Prompt模板)
【AI翻译避坑指南】:92%用户忽略的5个ChatGPT翻译陷阱(含术语一致性崩塌、文化错译、被动语态误判),附可直接复用的Prompt模板
更多请点击: https://intelliparadigm.com 第一章:ChatGPT翻译质量怎么样 ChatGPT 在多语种翻译任务中展现出较强的上下文理解与语义连贯能力,尤其在非技术类通用文本(如日常对话、新闻摘要、文学性段落)中常能生成自…...

使用Taotoken后API调用延迟与账单透明度的实际体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken后API调用延迟与账单透明度的实际体验 1. 引言 对于需要调用多种大模型API的开发者而言,统一接入和成本管…...
)
DeepSeek企业私有化部署隐私加固手册(含密钥轮转SOP、审计日志留存策略、跨境传输断点协议)
更多请点击: https://kaifayun.com 第一章:DeepSeek企业私有化部署隐私保护总览 DeepSeek大模型的企业私有化部署,以“数据不出域、模型可审计、推理可管控”为核心设计原则,构建端到端的隐私保护技术栈。该方案支持在客户自有I…...

2026年AI论文平台实测排行,哪款真正适合毕业定稿?
2026 年学术 AI 论文工具已形成全流程、理工 / 社科、英文 / 中文、免费 / 付费的清晰分化。综合实测排行与场景适配,千笔AI 是中文全能首选,DeepSeek 学术版是理工开源首选,毕业之家是国内毕业专属首选。 一、2026 年实测排行 TOP5…...

Agent协议标准化:互操作性的未来
Agent协议标准化:互操作性的未来 一、引言 钩子:你是否遇到过这些Agent协作的痛点? 你花了3天时间基于OpenAI GPT-4开发了一个客户需求分析Agent,能自动解析用户对话生成需求文档,但当你想把生成的需求文档同步给公司内部基于Llama 3部署的产品排期Agent时,却发现两个A…...