TensorRT量化工具pytorch_quantization代码解析(二)
有些地方看的不是透彻,后续继续补充!
继续看张量量化函数,代码位于:tools\pytorch-quantization\pytorch_quantization\tensor_quant.py
ScaledQuantDescriptor
量化的支持描述符:描述张量应该如何量化。QuantDescriptor和张量定义了量化张量。
class ScaledQuantDescriptor():def __init__(self, num_bits=8, name=None, **kwargs):if not isinstance(num_bits, int):raise TypeError("num_bits must be an integer, not {}.".format(type(num_bits)))if num_bits < 0:raise ValueError("num_bits must be >= 0, not {}.".format(num_bits))if num_bits == 0:logging.error("num_bits is 0. This will result in the tensor being quantized to all zeros."" This mode should only be used for debugging purposes.")self._num_bits = num_bitsif not isinstance(name, str) and name is not None:raise TypeError("name must be a string or None, not {}.".format(type(name)))self._name = nameself._fake_quant = kwargs.pop('fake_quant', True)self._axis = kwargs.pop('axis', None)if self._axis is not None:logging.debug("Meaning of axis has changed since v2.0. Make sure to update.")self._learn_amax = kwargs.pop('learn_amax', False)if self._learn_amax and self._axis is not None:raise TypeError("axis is ignored and must be None when learn_amax is true, got {}.".format(type(self._axis)))amax = kwargs.pop('amax', None)if amax is not None:if not isinstance(amax, float) and not isinstance(amax, list) and not isinstance(amax, np.ndarray):raise TypeError("amax must be float, list or ndarray, not {}".format(type(amax)))# Make it single precision arrayself._amax = np.array(amax, dtype=np.float32)else:self._amax = amaxself._scale_amax = kwargs.pop('scale_amax', None)self._calib_method = kwargs.pop('calib_method', "max")self._unsigned = kwargs.pop('unsigned', False)self._narrow_range = kwargs.pop('narrow_range', False)if kwargs:raise TypeError("Unused keys: {}".format(kwargs.keys()))
参数:
- num_bits:int,量化位数,用于计算比例因子。默认值8。
- name:看起来很不错
关键字参数:
-
fake_quant:布尔值。如果为True,则使用fake量化模式。默认为True -
axis:None, int或整数的tuple,轴将利用自己的最大值以计算缩放因子,默认None。- 如果None(默认值),则使用
per tensor scale。
确保在范围[-rank(input_tensor),rank(输入_tensor))内。
例如,对于KCRS权重张量,quant_axis=(0)将产生per channel scaling。
- 如果None(默认值),则使用
-
amax:用户指定的绝对最大范围的float或list/ndarray。如果提供,忽略quant_axis并使用它进行量化。如果learn_amax为True,将用于初始化可学习的amax。默认None -
learn_amax:boolean,如果为True,学习amax。默认为False。 -
scale_amax:float,如果提供,将amax乘以scale_amax,默认无。 -
calib_method:string,[“max”,“histogram”]中的一个校准要使用的指标。除了
max calibration,其他都是基于hisogram的。默认值“max”。 -
unsigned:Boolean,如果为True,则使用无符号。默认为False。
Raises:
- TypeError:如果传入了不支持的类型。
Read-only properties:
fake_quant:name:learn_amax:scale_amax:axis:calib_method:num_bits:amax:unsigned:
QuantDescriptor定义了张量应该如何量化。预定义的QuantDescriptor张量描述符如下:
QuantDescriptor = ScaledQuantDescriptor# Predefined descriptors
QUANT_DESC_8BIT_PER_TENSOR = QuantDescriptor(num_bits=8)
QUANT_DESC_UNSIGNED_8BIT_PER_TENSOR = QuantDescriptor(num_bits=8, unsigned=True)
QUANT_DESC_8BIT_CONV1D_WEIGHT_PER_CHANNEL = QuantDescriptor(num_bits=8, axis=(0))
QUANT_DESC_8BIT_CONV2D_WEIGHT_PER_CHANNEL = QuantDescriptor(num_bits=8, axis=(0))
QUANT_DESC_8BIT_CONV3D_WEIGHT_PER_CHANNEL = QuantDescriptor(num_bits=8, axis=(0))
QUANT_DESC_8BIT_LINEAR_WEIGHT_PER_ROW = QuantDescriptor(num_bits=8, axis=(0))
QUANT_DESC_8BIT_CONVTRANSPOSE1D_WEIGHT_PER_CHANNEL = QuantDescriptor(num_bits=8, axis=(0))
QUANT_DESC_8BIT_CONVTRANSPOSE2D_WEIGHT_PER_CHANNEL = QuantDescriptor(num_bits=8, axis=(0))
QUANT_DESC_8BIT_CONVTRANSPOSE3D_WEIGHT_PER_CHANNEL = QuantDescriptor(num_bits=8, axis=(0))
如果在QuantDescriptor中给出最amax,TensorQuantizer将使用它进行量化。否则,TensorQuantizer将计算amax,然后进行量化。amax被计算通过指定的axis轴。注意QuantDescriptor将剩余轴指定与max()轴相反。
例子:
from pytorch_quantization.tensor_quant import QuantDescriptor
from pytorch_quantization.nn.modules.tensor_quantizer import TensorQuantizerquant_desc = QuantDescriptor(num_bits=4, fake_quant=False, axis=(0), unsigned=True)
接下来看量化函数:pytorch_quantization提供3个自定义的张量量化函数算子,继承torch.autograd.function,实现函数的前向传播、反向传播
TensorQuantFunction
- 通用的张量量化函数
TensorQuantFunction
class TensorQuantFunction(Function):"""一个输入张量,输出一个量化张量。`scale`的粒度可以从amax的形状来解释"""
forward
在前向过程中,对浮点权重和激活进行伪量化,并使用这些伪量化的权重和激活来执行层的操作
@staticmethoddef forward(ctx, inputs, amax, num_bits=8, unsigned=False, narrow_range=True):ctx.save_for_backward(inputs, amax)outputs, scale = _tensor_quant(inputs, amax, num_bits, unsigned, narrow_range)# Check if scale overflows FP16if outputs.dtype == torch.half and scale.max() > 65504:raise ValueError("scale is too large for FP16 with amax={}".format(amax))return outputs, scale.to(inputs.dtype)
output_dtype指示量化值是以整数还是浮点形式存储。希望将其存储在浮点中的原因是pytorch函数接受量化值,它可能不接受整数输入,例如Conv2D。
它使用2num_bits−12^{num\_bits-1}2num_bits−1值,例如,对于num_bits=8,使用[-127,127]
遵循tensorflow约定,传入最大值并用于确定比例,而不是直接输入比例。尽管直接输入比例可能更自然。
参数:
-
ctx:一个用于向后存储张量的Context对象。 -
inputs:float32型张量。 -
amax:float32型张量。输入将在[-amax,amax]范围内量化,amax将广播到inputs tensor。 -
num_bits:用于计算缩放因子的整数,scale=(2num_bits−1−1)/maxscale=(2^{num\_bits-1}-1)/maxscale=(2num_bits−1−1)/max。默认值8。 -
output_dtype:张量的一种类型。torch.int32或torch.float32。希望存储为float,pytorch函数接受float量化值,它可能不接受整数输入。
unsigned:boolean,使用无符号整数范围。例如,对于num_bits=8,[0,255]。默认为False。 -
narrow_range:布尔值。使用对称整数范围进行有符号量化
例如,对于num_bits=8,用[-127,127]代替[-128,127]。默认为True。
Returns:
-
outputs:output_dtype类型的张量。 -
scale:float32型张量。outputs / scale将对输出张量进行反量化。
Raises:
ValueError:
backward
通过clipping实现直通估计。对于-amax<=input<=amax,梯度直接通过,否则梯度为零。
参数:
ctx:一个上下文对象,其中保存了来自forward的张量。grad_outputs:outputs梯度张量。grad_scale:scale梯度张量。
Returns:
grad_inputs:梯度张量。
@staticmethoddef backward(ctx, grad_outputs, grad_scale):"""Implements straight through estimation with clipping. For -amax <= input <= amaxthe gradient passes straight through, otherwise the gradient is zero.Args:ctx: A Context object with saved tensors from forward.grad_outputs: A tensor of gradient of outputs.grad_scale: A tensor of gradient of scale.Returns:grad_inputs: A tensor of gradient."""inputs, amax = ctx.saved_tensorszero = grad_outputs.new_zeros(1) # create a zero tensor with the same type and devicegrad_inputs = torch.where(inputs.abs() <= amax, grad_outputs, zero)return grad_inputs, None, None, None, None
tensor_quant = TensorQuantFunction.apply
给TensorQuantFunction.apply赋予一个别名tensor_quant,这样可以直接调用tensor_quant进行量化,例如:
from pytorch_quantization import tensor_quant# Generate random input. With fixed seed 12345, x should be
# tensor([0.9817, 0.8796, 0.9921, 0.4611, 0.0832, 0.1784, 0.3674, 0.5676, 0.3376, 0.2119])
torch.manual_seed(12345)
x = torch.rand(10)# quantize tensor x. quant_x will be
# tensor([126., 113., 127., 59., 11., 23., 47., 73., 43., 27.])
# with scale=128.0057
quant_x, scale = tensor_quant.tensor_quant(x, x.abs().max())
FakeTensorQuantFunction
class FakeTensorQuantFunction(Function):"""Fake version of TensorQuantFunctionSee comments of TensorQuantFunction, arguments are the same."""@staticmethoddef forward(ctx, inputs, amax, num_bits=8, unsigned=False, narrow_range=True):ctx.save_for_backward(inputs, amax)outputs, scale = _tensor_quant(inputs, amax, num_bits, unsigned, narrow_range)return outputs / scale.to(inputs.dtype)@staticmethoddef backward(ctx, grad_outputs):inputs, amax = ctx.saved_tensorszero = grad_outputs.new_zeros(1)grad_inputs = torch.where(inputs.abs() <= amax, grad_outputs, zero)return grad_inputs, None, None, None, None
在向后过程中,使用权重的渐变来更新浮点权重。为了处理量化梯度,除了未定义的点之外,几乎所有地方都是零,可以使用 直通估计器 ( STE ),它通过伪量化操作符传递梯度。
fake_tensor_quant = FakeTensorQuantFunction.apply
给TensorQuantFunction.apply赋予一个别名fake_tensor_quant,这样可以直接调用fake_tensor_quant进行量化,例如:
from pytorch_quantization import tensor_quant# Generate random input. With fixed seed 12345, x should be
# tensor([0.9817, 0.8796, 0.9921, 0.4611, 0.0832, 0.1784, 0.3674, 0.5676, 0.3376, 0.2119])
torch.manual_seed(12345)
x = torch.rand(10)# fake quantize tensor x. fake_quant_x will be
# tensor([0.9843, 0.8828, 0.9921, 0.4609, 0.0859, 0.1797, 0.3672, 0.5703, 0.3359, 0.2109])
fake_quant_x = tensor_quant.fake_tensor_quant(x, x.abs().max())
_tensor_quant
def _tensor_quant(inputs, amax, num_bits=8, unsigned=False, narrow_range=True):"""Shared function body between TensorQuantFunction and FakeTensorQuantFunction"""# Fine scale, per channel scale will be handled by broadcasting, which could be tricky. Pop a warning.if isinstance(amax, torch.Tensor) and inputs.dim() != amax.dim():logging.debug("amax %s has different shape than inputs %s. Make sure broadcast works as expected!",amax.size(), inputs.size())logging.debug("{} bits quantization on shape {} tensor.".format(num_bits, inputs.size()))if unsigned:if inputs.min() < 0.:raise TypeError("Negative values encountered in unsigned quantization.")# Computation must be in FP32 to prevent potential over flow.input_dtype = inputs.dtypeif inputs.dtype == torch.half:inputs = inputs.float()if amax.dtype == torch.half:amax = amax.float()min_amax = amax.min()if min_amax < 0:raise ValueError("Negative values in amax")max_bound = torch.tensor((2.0**(num_bits - 1 + int(unsigned))) - 1.0, device=amax.device)if unsigned:min_bound = 0elif narrow_range:min_bound = -max_boundelse:min_bound = -max_bound - 1scale = max_bound / amaxepsilon = 1. / (1<<24)if min_amax <= epsilon: # Treat amax smaller than minimum representable of fp16 0zero_amax_mask = (amax <= epsilon)scale[zero_amax_mask] = 0 # Value quantized with amax=0 should all be 0outputs = torch.clamp((inputs * scale).round_(), min_bound, max_bound)if min_amax <= epsilon:scale[zero_amax_mask] = 1. # Return 1 makes more sense for values quantized to 0 with amax=0if input_dtype == torch.half:outputs = outputs.half()return outputs, scale待梳理!!!
相关文章:
)
TensorRT量化工具pytorch_quantization代码解析(二)
有些地方看的不是透彻,后续继续补充! 继续看张量量化函数,代码位于:tools\pytorch-quantization\pytorch_quantization\tensor_quant.py ScaledQuantDescriptor 量化的支持描述符:描述张量应该如何量化。QuantDescriptor和张量…...

buu [BJDCTF2020]easyrsa 1
题目描述 : from Crypto.Util.number import getPrime,bytes_to_long from sympy import Derivative from fractions import Fraction from secret import flagpgetPrime(1024) qgetPrime(1024) e65537 np*q zFraction(1,Derivative(arctan(p),p))-Fraction(1,Deri…...

taobao.user.openuid.getbyorder( 根据订单获取买家openuid )
¥免费不需用户授权 根据订单获取买家openuid,最大查询30个 公共参数 请求地址: HTTP地址 http://gw.api.taobao.com/router/rest 公共请求参数: 请求示例 TaobaoClient client new DefaultTaobaoClient(url, appkey, secret); UserOpenuidGetbyorderR…...
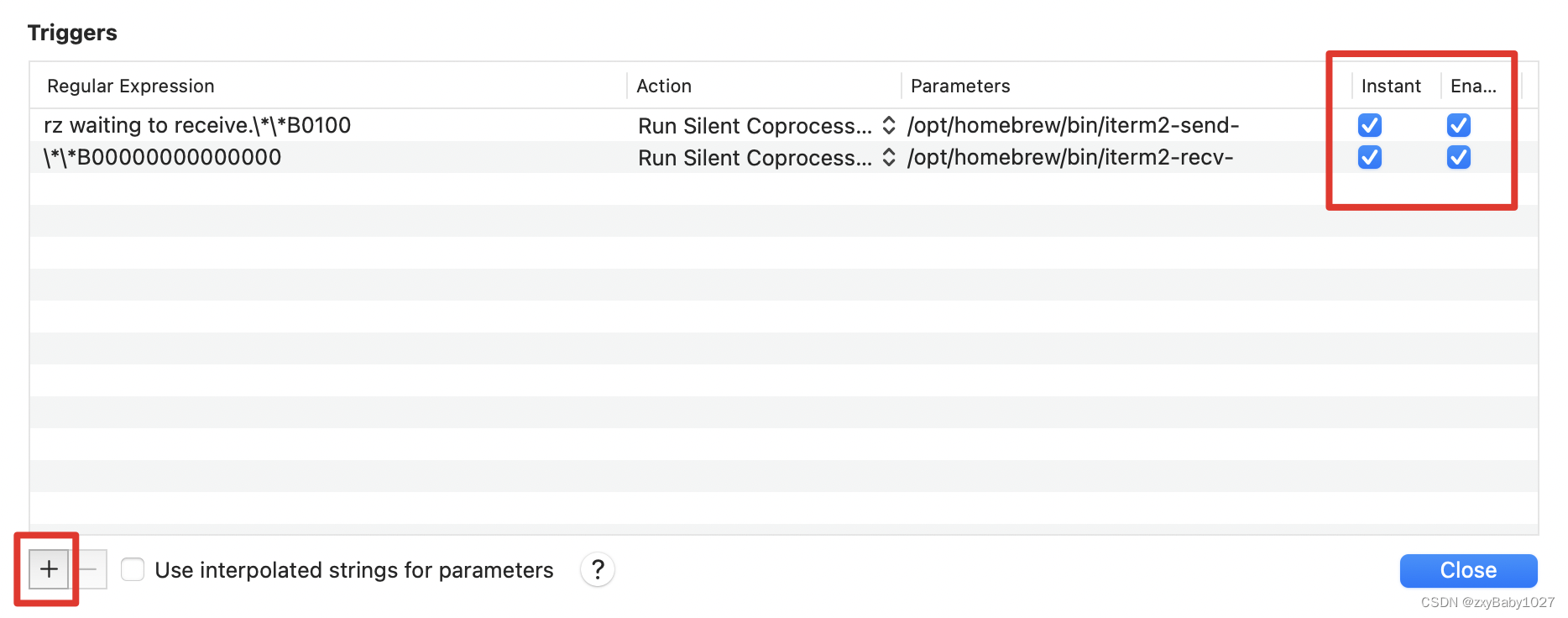
Mac iTerm2 rz sz
1、安装brew(找了很多🔗,就这个博主的好用) Mac如何安装brew?_行走的码农00的博客-CSDN博客_mac brew 2、安装lrzsz brew install lrzsz 检查是否安装成功 brew list 定位lrzsz的安装目录 brew list lrzsz 执…...
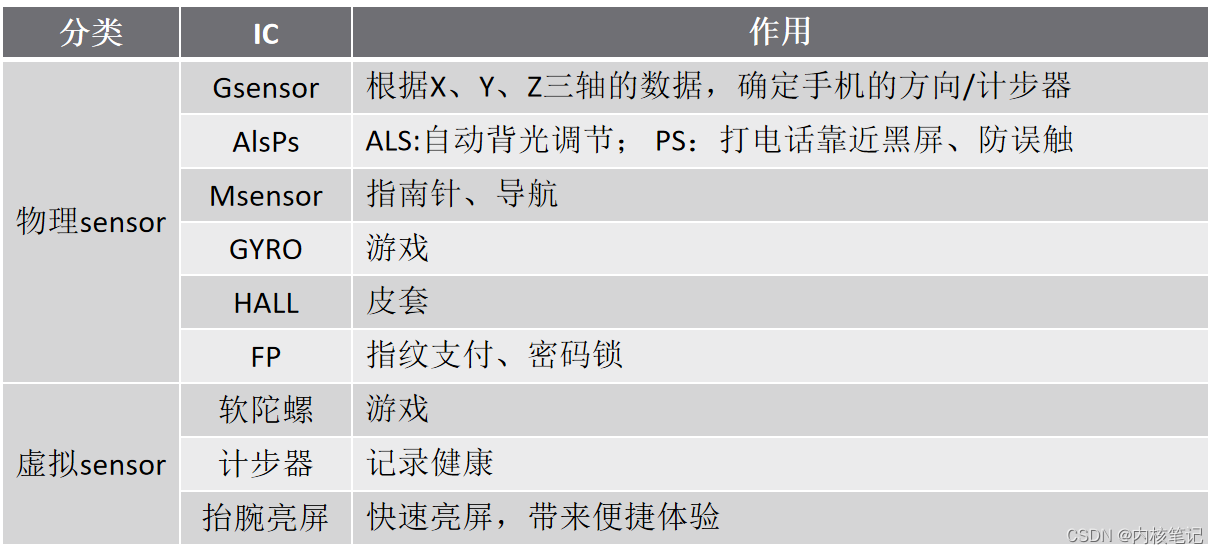
高通平台开发系列讲解(Sensor篇)Gsensor基础知识
文章目录 一、什么是SENSOR?二、Sensor的分类及作用三、Gsensor的工作原理及介绍3.1、常见Gsensor3.2、Gsensor的特性沉淀、分享、成长,让自己和他人都能有所收获!😄 📢本篇文章将介绍 Sensor 基础 一、什么是SENSOR? 传感器(英文名称:sensor )是一种检测装置,能感…...

图像处理实战--Opencv实现人像迁移
前言: Hello大家好,我是Dream。 今天来学习一下如何使用Opencv实现人像迁移,欢迎大家一起参与探讨交流~ 本文目录:一、实验要求二、实验环境三、实验原理及操作1.照片准备2.图像增强3.实现美颜功能4.背景虚化5.图像二值化处理6.人…...
OnlyOffice验证(二)在Centos7上部署OnlyOffice编译结果
在Centos7上部署OnlyOffice编译结果 此处将尝试将OnlyOffice验证(一)DocumentServer编译验证的结果部署到Centos7上。并且使用其它服务器现有的RabbitMq和Mysql。 安装Nginx 先安装Nginx需要的依赖环境: yum install openssl* -y yum insta…...

6.补充和总结【Java面试第三季】
6.补充和总结【Java面试第三季】前言推荐6.补充和总结69_总结闲聊回顾和总结继续学习最后前言 2023-2-4 19:08:01 以下内容源自 【尚硅谷Java大厂面试题第3季,跳槽必刷题目必扫技术盲点(周阳主讲)-哔哩哔哩】 仅供学习交流使用 推荐 Jav…...

基于ssm框架大学生社团管理系统(源码+数据库+文档)
一、项目简介 本项目是一套基于ssm框架大学生社团管理系统,主要针对计算机相关专业的正在做bishe的学生和需要项目实战练习的Java学习者。 包含:项目源码、数据库脚本等,该项目可以直接作为bishe使用。 项目都经过严格调试,确保可…...
vulnhub靶场NAPPING: 1.0.1教程
靶场搭建靶机下载地址:Napping: 1.0.1 ~ VulnHub直接解压双击ova文件即可使用软件:靶机VirtualBox,攻击机VMware攻击机:kali信息收集arp-scan -l上帝之眼直接来看看网站可以注册账号,那就先试试。注册完后登入哦。要输…...

Docker基本介绍
最近需要将项目做成一个web应用并部署到多台服务器上,于是就简单学习了一下docker,做一下小小的记录。 1、简单介绍一下docker 我们经常遇到这样一个问题,自己写的代码在自己的电脑上运行的很流畅,在其他人电脑上就各种bug&…...
可用于标记蛋白质216699-36-4,6-ROX,SE,6-羧基-X-罗丹明琥珀酰亚胺酯
一.6-ROX,SE产品描述:6-羧基-X-罗丹明琥珀酰亚胺酯(6-ROX,SE)是一种用于寡核苷酸标记和自动DNA测序的荧光染料,可用于标记蛋白质,寡核苷酸和其他含胺分子的伯胺(-NH2)。西…...

高数:极限的定义
目录 极限的定义: 数列极限的几何意义: 由极限的定义得出的极限的两个结论: 编辑 极限的第三个结论: 例题 方法1: 编辑 方法2: 编辑 方法3: 编辑 极限的定义: 如何理…...
大数据技术之Hadoop
第1章 Hadoop概述1.1 Hadoop是什么1.2 Hadoop发展历史(了解)1.3 Hadoop三大发行版本(了解)Hadoop三大发行版本:Apache、Cloudera、Hortonworks。Apache版本最原始(最基础)的版本,对于…...

一文带你搞懂Go语言函数选项模式,Go函数一等公民。
前言 通过这篇文章《为什么说Go的函数是”一等公民“》,我们了解到了什么是“一等公民”,以及都具备哪些特性,同时对函数的基本使用也更加深入。 本文重点介绍下Go设计模式之函数选项模式,它得益于Go的函数是“一等公民”&#…...
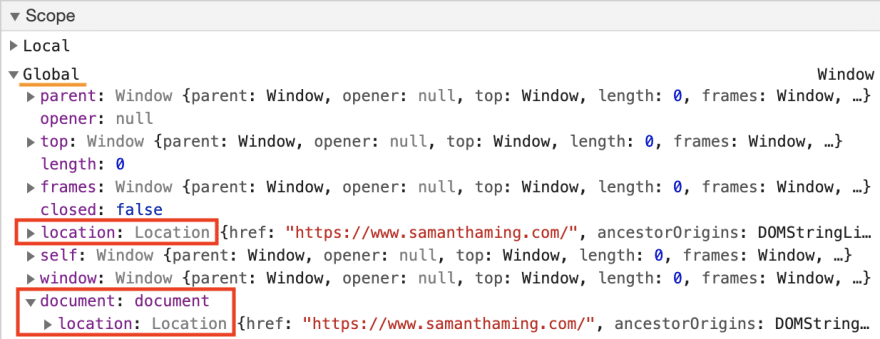
Window.location 详细介绍
如果你需要获取网站的 URL 信息,那么 window.location 对象就是为你准备的。使用它提供的属性来获取当前页面地址的信息,或使用其方法进行某些页面的重定向或刷新。 https://www.samanthaming.com/tidbits/?filterJS#2 window.location.origin → htt…...
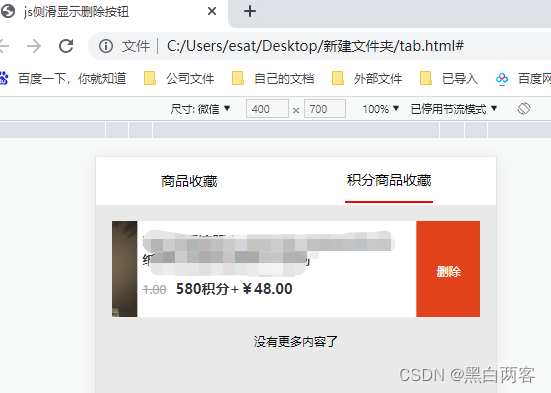
js侧滑显示删除按钮
效果图: <!DOCTYPE html> <html><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0, maximum-scale1.0, user-scalableno"><title>js侧滑显示删…...

Python - DIY - 使用dump取json某些键值对合成新的json文件
Python - Json处理前言:应用场景:基本工具:文件操作:打开文件:写文件:读文件:关闭文件并刷新缓冲区:Json字符串和字典转换:json.loads():json.dumps():Json文…...

深度剖析指针(中)——“C”
各位CSDN的uu们你们好呀,今天小雅兰的内容仍旧是深度剖析指针噢,在上一篇博客中,我已经写过了字符指针、数组指针、指针数组、数组传参和指针传参的知识点,那么这篇博客小雅兰会讲解一下函数指针、函数指针数组 、指向函数指针数组…...
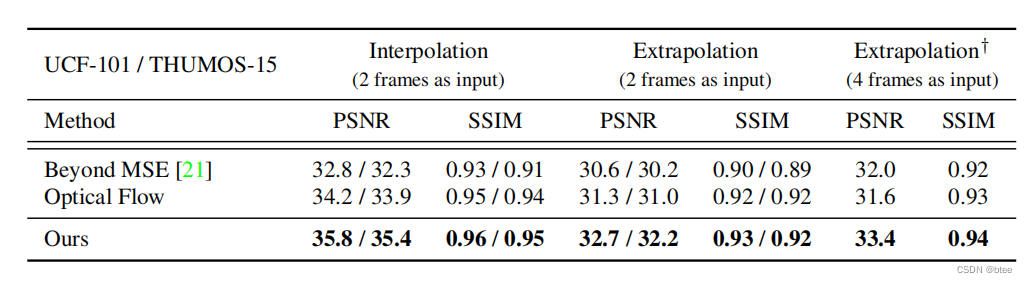
论文阅读 | Video Frame Synthesis using Deep Voxel Flow
前言: 视频帧生成方法(视频插帧/视频预测)ICCV2017 oral Video Frame Synthesis using Deep Voxel Flow 引言 当下进行视频帧合成的方法分为两种,第一种是光流法,光流准确的话效果好,光流不准确的话则生…...

Logo设计全流程指南:从品牌定位到视觉落地的核心逻辑
初创企业团队常面临标志图形难以传递核心业务的现实困境。脱离市场认知的视觉符号会导致后续传播成本成倍增加。本文系统拆解标志构建的标准作业路径,提供可量化验证的参数指标与执行清单。读者可依据本框架完成从抽象概念到商用矢量文件的完整转化。有效规避重复试…...

从硬盘拷贝文件到内存,CPU真的在摸鱼吗?深入聊聊DMA背后的性能优化哲学
从硬盘拷贝文件到内存,CPU真的在摸鱼吗?深入聊聊DMA背后的性能优化哲学 当你从硬盘拷贝一个10GB的电影文件到内存时,系统监控显示CPU占用率几乎没变化——这似乎违背直觉。难道CPU真的在"摸鱼"?实际上,这背后…...

DC/DC转换器混合输出电容设计原理与工程实践
1. DC/DC转换器中混合输出电容的设计优势解析在电源设计领域,输出电容的选择往往让工程师陷入两难境地。作为一名长期从事电源系统设计的工程师,我深刻理解这种选择的痛苦——电解电容价格亲民但性能受限,陶瓷电容性能卓越却成本高昂。直到混…...

博物馆科技馆迎来数字员工,AI数字人公司厂商助力展馆智慧升级
走进博物馆,你期待怎样的体验?是隔着玻璃看展品,还是听一段千篇一律的录音导览?如今,越来越多的场馆正在给出新的答案:一个能走、能说、能聊天的AI数字人,正悄然改变着“看展”这件事。过去几年…...

开源智能家居中枢搭建:从架构解析到自动化场景实践
1. 项目概述与核心价值最近在折腾智能家居中枢时,发现了一个挺有意思的开源项目,叫contextzero/nest_hub。乍一看名字,很容易让人联想到谷歌的 Nest Hub 智能显示屏,但深入探究后,你会发现它其实是一个旨在“模拟”或“…...

Nrfr终极指南:5步轻松修改SIM卡国家码,免Root突破区域限制
Nrfr终极指南:5步轻松修改SIM卡国家码,免Root突破区域限制 【免费下载链接】Nrfr 🌍 免 Root 的 SIM 卡国家码修改工具 | 解决国际漫游时的兼容性问题,帮助使用海外 SIM 卡获得更好的本地化体验,解锁运营商限制&#x…...

Simulink-采样时间实战:从模型配置到模块级联的精准控制
1. Simulink采样时间基础概念 第一次接触Simulink建模时,很多人会被"采样时间"这个概念搞得一头雾水。我刚开始用Simulink做电机控制系统仿真时,就因为这个参数设置不当,导致仿真结果完全失真。简单来说,采样时间决定了…...

别再只盯着YOLO了!用DeepSORT+SORT搞定视频多目标跟踪,保姆级代码解读与避坑指南
从零构建视频多目标跟踪系统:DeepSORT与SORT核心代码拆解与工业级优化策略 当监控摄像头中的人群如潮水般流动,当自动驾驶系统需要实时追踪数十个移动物体,多目标跟踪(MOT)技术便成为计算机视觉领域最具挑战性的任务之…...

动态寄存器分配优化技术及其在Racetrack内存中的应用
1. 动态寄存器分配优化技术概述寄存器分配优化是计算机体系结构设计中的核心问题之一,它直接影响着处理器的执行效率和能耗表现。传统静态寄存器分配方法在编译时确定寄存器使用方案,虽然实现简单,但无法适应程序运行时的动态行为特征。特别是…...

3分钟掌握WechatDecrypt:微信聊天记录解密的终极解决方案
3分钟掌握WechatDecrypt:微信聊天记录解密的终极解决方案 【免费下载链接】WechatDecrypt 微信消息解密工具 项目地址: https://gitcode.com/gh_mirrors/we/WechatDecrypt 你是否曾因更换手机而丢失珍贵的微信聊天记录?或者不小心删除了重要的商务…...