YOLOv8改进 | 如何在网络结构中添加注意力机制、C2f、卷积、Neck、检测头
一、本文介绍
本篇文章的内容是在大家得到一个改进版本的C2f一个新的注意力机制、或者一个新的卷积模块、或者是检测头的时候如何替换我们YOLOv8模型中的原有的模块,从而用你的模块去进行训练模型或者检测。因为最近开了一个专栏里面涉及到挺多改进的地方,不能每篇文章都去讲解一遍如何修改,就想着在这里单独出一期文章进行一个总结性教程,大家可以从我的其它文章中拿到修改后的代码,从这篇文章学会如何去添加到你的模型结构中去。
YOLOv8专栏:YOLOv8改进有效涨点专栏->持续复现各种最新机制
本文的讲解举例都以最新的YOLOv8的目录结构为例,老版本的其实方法都一样只是目录构造不一样找到同样的文件名即可。
适用对象->本文适合那些拿到源码却不知道如何添加到网络结构中的朋友
目录
一、本文介绍
二、导入修改内容
2.1创建新文件导入新模块
2.1.1情况一
2.1.2情况二
三、Conv模块
3.1修改一
3.2修改二
3.3修改三
四、C2f、Bottleneck模块
4.1修改一
4.2步骤二
4.3修改三
4.4修改四
4.5修改五
4.6修改六
4.7修改七
四、注意力机制
4.1修改一
4.2修改二
4.3修改三
4.2.1有参数的注意力机制修改
4.2.2无参数的注意力机制修改
4.4配置注意力机制
五、Neck部分
六、检测头
七、损失函数
7.1 修改一
7.2 修改二
7.3 修改三
二、导入修改内容
大家拿到任何一个代码,想要加入到模型的内部,我们都需要先将其导入到模型的内部,才可以将其添加到模型的结构中去,下面的代码是一个ODConv,和我创建的一个ODConv_yolo的类(官方的代码报错进行一定的处理想知道为啥可以看我单独讲解它的博客), 我们先拿其进行举例。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.autogradclass Attention(nn.Module):def __init__(self, in_planes, out_planes, kernel_size, groups=1, reduction=0.0625, kernel_num=4, min_channel=16):super(Attention, self).__init__()attention_channel = max(int(in_planes * reduction), min_channel)self.kernel_size = kernel_sizeself.kernel_num = kernel_numself.temperature = 1.0self.avgpool = nn.AdaptiveAvgPool2d(1)self.fc = nn.Conv2d(in_planes, attention_channel, 1, bias=False)self.bn = nn.BatchNorm2d(attention_channel)self.relu = nn.ReLU(inplace=True)self.channel_fc = nn.Conv2d(attention_channel, in_planes, 1, bias=True)self.func_channel = self.get_channel_attentionif in_planes == groups and in_planes == out_planes: # depth-wise convolutionself.func_filter = self.skipelse:self.filter_fc = nn.Conv2d(attention_channel, out_planes, 1, bias=True)self.func_filter = self.get_filter_attentionif kernel_size == 1: # point-wise convolutionself.func_spatial = self.skipelse:self.spatial_fc = nn.Conv2d(attention_channel, kernel_size * kernel_size, 1, bias=True)self.func_spatial = self.get_spatial_attentionif kernel_num == 1:self.func_kernel = self.skipelse:self.kernel_fc = nn.Conv2d(attention_channel, kernel_num, 1, bias=True)self.func_kernel = self.get_kernel_attentionself._initialize_weights()def _initialize_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)if isinstance(m, nn.BatchNorm2d):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)def update_temperature(self, temperature):self.temperature = temperature@staticmethoddef skip(_):return 1.0def get_channel_attention(self, x):channel_attention = torch.sigmoid(self.channel_fc(x).view(x.size(0), -1, 1, 1) / self.temperature)return channel_attentiondef get_filter_attention(self, x):filter_attention = torch.sigmoid(self.filter_fc(x).view(x.size(0), -1, 1, 1) / self.temperature)return filter_attentiondef get_spatial_attention(self, x):spatial_attention = self.spatial_fc(x).view(x.size(0), 1, 1, 1, self.kernel_size, self.kernel_size)spatial_attention = torch.sigmoid(spatial_attention / self.temperature)return spatial_attentiondef get_kernel_attention(self, x):kernel_attention = self.kernel_fc(x).view(x.size(0), -1, 1, 1, 1, 1)kernel_attention = F.softmax(kernel_attention / self.temperature, dim=1)return kernel_attentiondef forward(self, x):x = self.avgpool(x)x = self.fc(x)# x = self.bn(x) # 在外面我提供了一个bn这里会报错x = self.relu(x)return self.func_channel(x), self.func_filter(x), self.func_spatial(x), self.func_kernel(x)class ODConv2d(nn.Module):def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=1, dilation=1, groups=1,reduction=0.0625, kernel_num=4):super(ODConv2d, self).__init__()kernel_size = kernel_size[0]in_planes = in_planesself.in_planes = in_planesself.out_planes = out_planesself.kernel_size = kernel_sizeself.stride = strideself.padding = paddingself.dilation = dilationself.groups = groupsself.kernel_num = kernel_numself.attention = Attention(in_planes, out_planes, kernel_size, groups=groups,reduction=reduction, kernel_num=kernel_num)self.weight = nn.Parameter(torch.randn(kernel_num, out_planes, in_planes//groups, kernel_size, kernel_size),requires_grad=True)self._initialize_weights()if self.kernel_size == 1 and self.kernel_num == 1:self._forward_impl = self._forward_impl_pw1xelse:self._forward_impl = self._forward_impl_commondef _initialize_weights(self):for i in range(self.kernel_num):nn.init.kaiming_normal_(self.weight[i], mode='fan_out', nonlinearity='relu')def update_temperature(self, temperature):self.attention.update_temperature(temperature)def _forward_impl_common(self, x):# Multiplying channel attention (or filter attention) to weights and feature maps are equivalent,# while we observe that when using the latter method the models will run faster with less gpu memory cost.channel_attention, filter_attention, spatial_attention, kernel_attention = self.attention(x)batch_size, in_planes, height, width = x.size()x = x * channel_attentionx = x.reshape(1, -1, height, width)aggregate_weight = spatial_attention * kernel_attention * self.weight.unsqueeze(dim=0)aggregate_weight = torch.sum(aggregate_weight, dim=1).view([-1, self.in_planes // self.groups, self.kernel_size, self.kernel_size])output = F.conv2d(x, weight=aggregate_weight, bias=None, stride=self.stride, padding=self.padding,dilation=self.dilation, groups=self.groups * batch_size)output = output.view(batch_size, self.out_planes, output.size(-2), output.size(-1))output = output * filter_attentionreturn outputdef _forward_impl_pw1x(self, x):channel_attention, filter_attention, spatial_attention, kernel_attention = self.attention(x)x = x * channel_attentionoutput = F.conv2d(x, weight=self.weight.squeeze(dim=0), bias=None, stride=self.stride, padding=self.padding,dilation=self.dilation, groups=self.groups)output = output * filter_attentionreturn outputdef forward(self, x):return self._forward_impl(x)拿到这种代码之后,一般都很长,有一些博主推荐直接将其复制粘贴到YOLOv8的"ultralytics/nn/modules/conv.py"或者"ultralytics/nn/modules/block.py"目录下面,这种方法可不可以?答案是可以的,但是我建议大家最好新建一个文件在conv.py的同级目录下,为什么这么做,因为我们修改的模块越来越多,你往conv.py文件或则block.py文件里面加的代码越来越多很容易就把代码改崩溃了,最后就跌卸载进行重新下载包,我们通过建立文件导入其中类的形式,如果我们不用了,也不会对我们的代码做出任何影响,实在不行把新建立的文件删除了都可以,下面开始进行实际操作的讲解。
2.1创建新文件导入新模块
我们将我们得到的任何一个Conv或者想要修改的任何一个模块都可以像下面的图片一样直接建立一个文件复制粘贴进去即可。
建立好上面的文件之后,我们此时呢有两种情况,一周呢官方的代码可以直接使用,另一种呢需要进行一定的处理,我们下面分别进行讲解两种情况。
2.1.1情况一
这种情况是官方的代码可以直接使用,此时我们直接修改"ultralytics/nn/modules/__init__.py"文件就可以了,修改如下->
2.1.2情况二
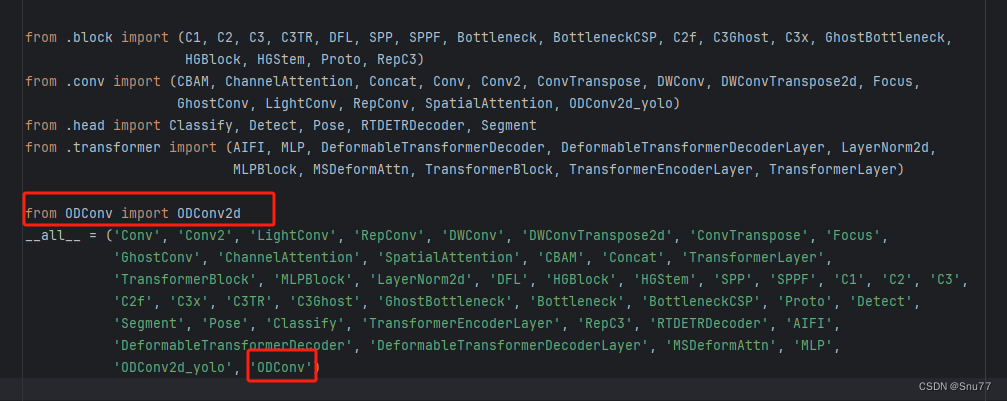
另一种情况(绝大多数):官方的代码不能直接使用我们本文的例子ODConv就是这种情况,所以我们需要对其进行一定的处理,我们找到如下的文件->"ultralytics/nn/modules/conv.py"对其进行修改如下->
修改一、导入模块

修改二、将额外处理代码添加至conv模块
将如下代码添加至该文件中的末尾处->
class ODConv2d_yolo(nn.Module):def __init__(self, in_channels, out_channels, kernel_size=1, stride=1, groups=1, dilation=1):super().__init__()self.conv = Conv(in_channels, out_channels, k=1)self.dcnv3 = ODConv2d(out_channels,out_channels, kernel_size=kernel_size, stride=stride, groups=groups,dilation=dilation)self.bn = nn.BatchNorm2d(out_channels)self.gelu = nn.GELU()def forward(self, x):x = self.conv(x)x = self.dcnv3(x)x = self.gelu(self.bn(x))return x
修改三、配置头文件
修改如下->

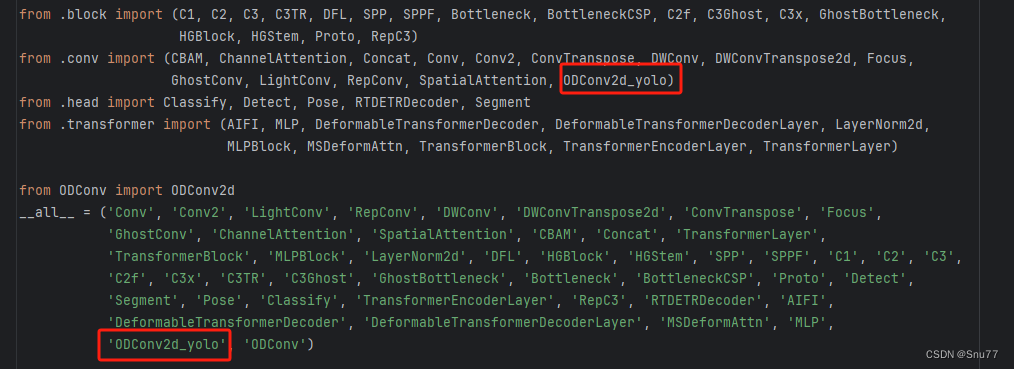
修改四 、重复情况一的步骤
修改"ultralytics/nn/modules/__init__.py"文件如下
总结:通过建立文件这种方法导入想要加入到模型中的模块(这里举例的是ODConv2d)其已经在我们新创建的.py文件中定义好了然后直接导过来就可以用了,从而不修改原有的conv.py文件就做到了,这样就算我们随时不用了,直接删除文件然后需要改的地方也很直观,否则时间久了代码早晚跌崩溃。
三、Conv模块
上面我们已经把定义好的卷积模块代码中了,此时我们还需要配置其位置,当然不同的模块导入的方式也有可能略有不同。
3.1修改一
我们找到如下的文件"ultralytics/nn/tasks.py",图片如下->
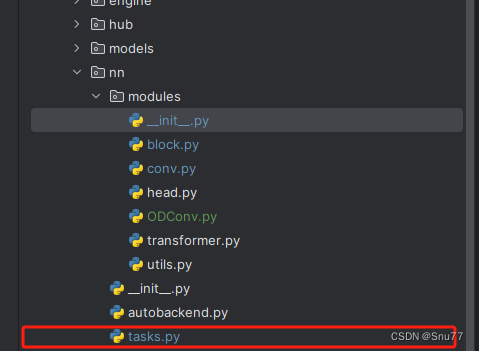
我们先把我们在上面"ultralytics/nn/modules/__init__.py" 文件的函数头中导入的类,在下面的地方导入进"ultralytics/nn/tasks.py"文件中,修改内容如下->

3.2修改二
我们在这个文件中找到一个方法(def定义的就叫方法),因为其代码很长,我们一行一行搜索很麻烦,我们适用文件搜索功能(快捷键Ctrl + F),弹出快捷栏如下->

我们搜索下面这个代码"parse_model" 然后进行翻滚很容易就找到了下面的部分,同时进行红框内部的修改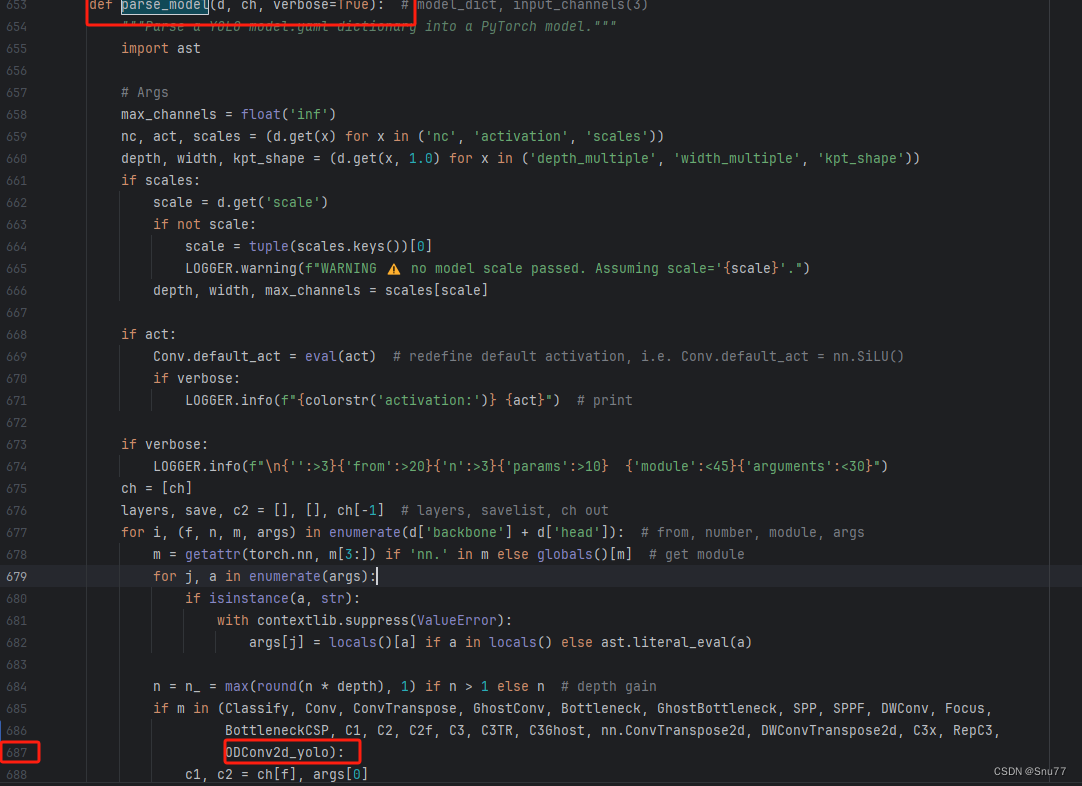
3.3修改三
到此我们就已经将我们定义的三个模块添加到我们的模型中了,已经可以修改yaml文件进行网络结构的配置了,我们找到该文件"ultralytics/cfg/models/v8/yolov8.yaml"进行配置。
我们可以在其中的任何一个位置进行替换,当然我们的替换要符合逻辑,类似于之前这个位置是Conv那么你可以将你修改的卷积替换上,之前这个位置是C2f那么你就将修改后的C2f替换上。
我们在yaml文件中进行了如下修改。
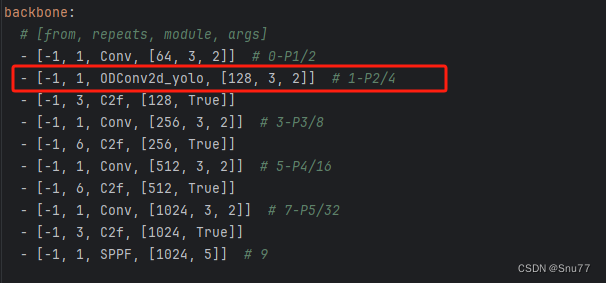
到此我们就配置完成了此时进行训练就可以开始训练了~

四、C2f、Bottleneck模块
下面我们拿修改后的C2f、和Bottleneck举例,这两个模块定义在该文件中"ultralytics/nn/modules/block.py",所以如果我们想添加修改后的C2f和Bottleneck(这俩一般配套使用),就需要在该文件中进行修改,修改步骤如下->
4.1修改一
找到该文件"ultralytics/nn/modules/block.py",进行如下修改->

4.2步骤二
添加修改后的C2f和Bottleneck模块,这里起名为C2f_ODConv和Bottleneck_ODConv,
class Bottleneck_ODConv(nn.Module):"""Standard bottleneck."""def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, andexpansion."""super().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, k[0], 1)self.cv2 = ODConv2d_yolo(c_, c2, k[1], 1, groups=g)self.add = shortcut and c1 == c2def forward(self, x):"""'forward()' applies the YOLO FPN to input data."""return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))class C2f_ODConv(nn.Module):"""Faster Implementation of CSP Bottleneck with 2 convolutions."""def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):"""Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups,expansion."""super().__init__()self.c = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, 2 * self.c, 1, 1)self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)self.m = nn.ModuleList(Bottleneck_ODConv(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))def forward(self, x):"""Forward pass through C2f layer."""y = list(self.cv1(x).chunk(2, 1))y.extend(m(y[-1]) for m in self.m)return self.cv2(torch.cat(y, 1))def forward_split(self, x):"""Forward pass using split() instead of chunk()."""y = list(self.cv1(x).split((self.c, self.c), 1))y.extend(m(y[-1]) for m in self.m)return self.cv2(torch.cat(y, 1))将以上代码复制到文件"ultralytics/nn/modules/block.py"的末尾,
4.3修改三
修改头文件如下->

4.4修改四
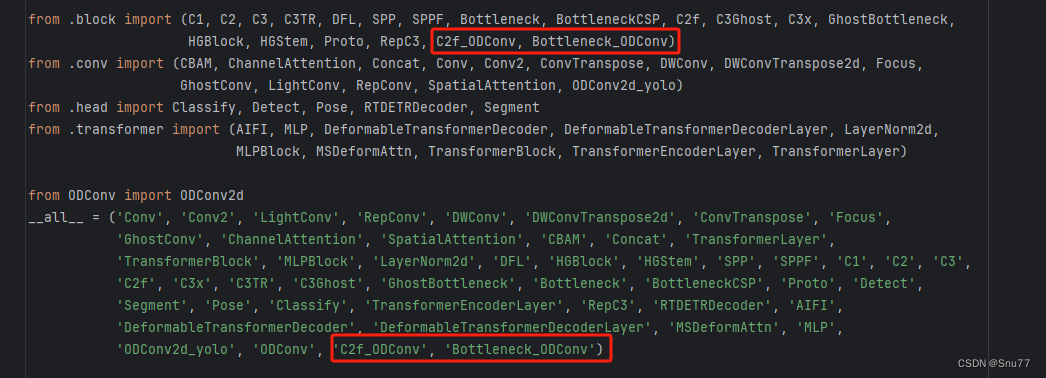
找到文件"ultralytics/nn/modules/__init__.py",修改如下->
4.5修改五
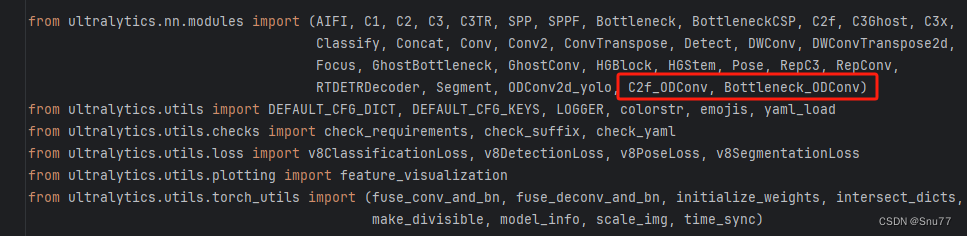
找到该文件我们找到如下的文件"ultralytics/nn/tasks.py"进行修改(其实和卷积模块的一模一样),
4.6修改六
我们在这个文件中找到一个方法(def定义的就叫方法),因为其代码很长,我们一行一行搜索很麻烦,我们适用文件搜索功能(快捷键Ctrl + F),弹出快捷栏如下->
我们搜索下面这个代码"parse_model" 然后进行翻滚很容易就找到了下面的部分,同时进行红框内部的修改
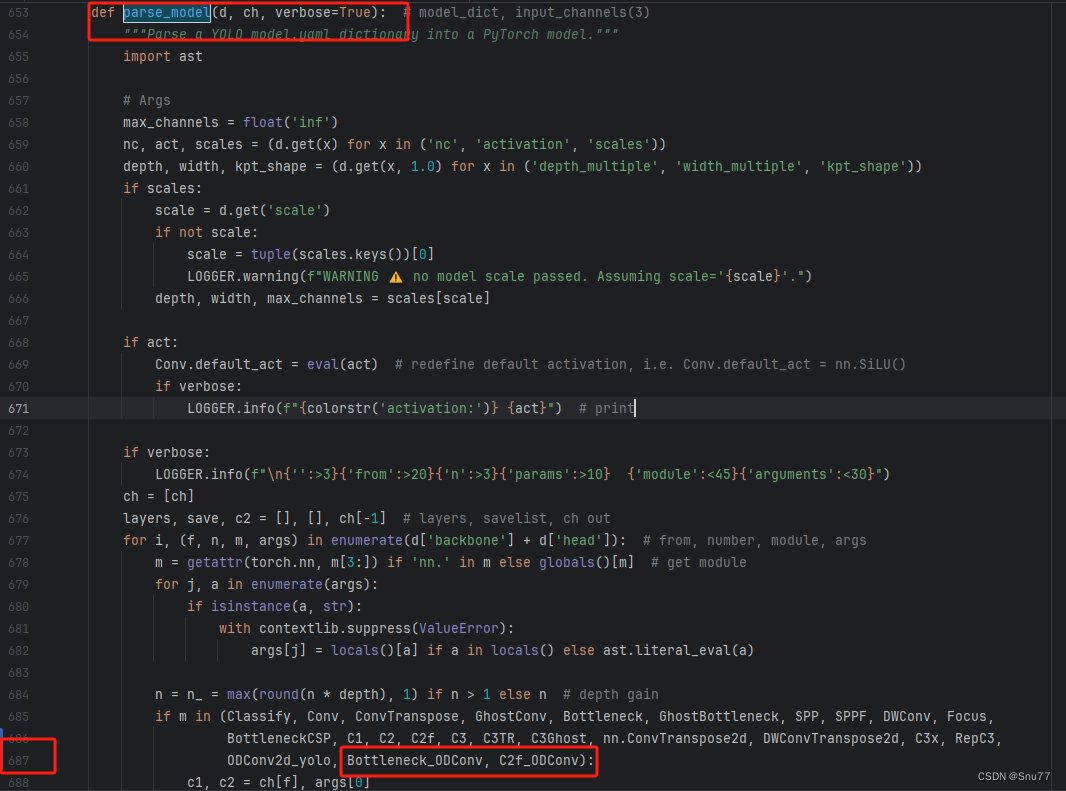
4.7修改七
到此我们就已经将我们定义的三个模块添加到我们的模型中了,已经可以修改yaml文件进行网络结构的配置了,我们找到该文件"ultralytics/cfg/models/v8/yolov8.yaml"进行配置。
我们可以在其中的任何一个位置进行替换,当然我们的替换要符合逻辑,类似于之前这个位置是Conv那么你可以将你修改的卷积替换上,之前这个位置是C2f那么你就将修改后的C2f替换上。
在yaml文件中进行了如下修改。
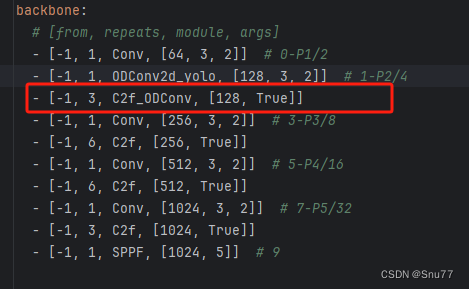
到此就完成了修改C2f和Bottleneck模块了,已经可以开始进行训练了~
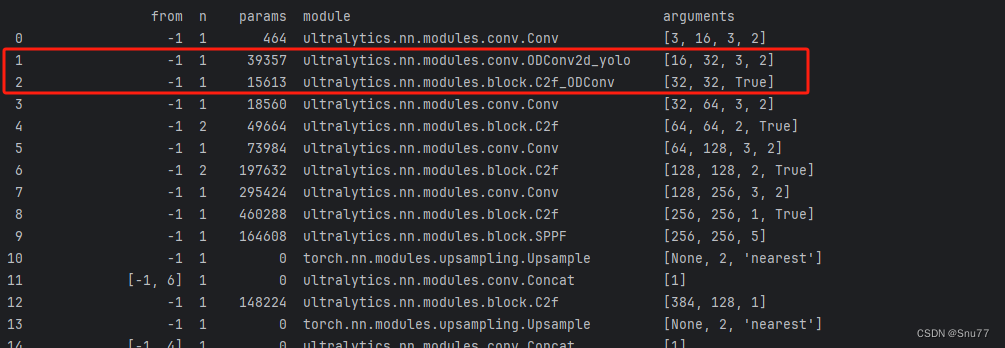
至于修改这个ODConv的 效果如何可以看我的其它博客里面有详细的讲解~
四、注意力机制
修改注意力机制的部分其实和上面都是类似只是在修改如下文件的时候有点不一样"ultralytics/nn/tasks.py",但是需要注意的是注意力机制分为两种,一种是有参数的注意力机制我们需要像其中传入参数,一种是无参数的注意力机制这两种机制的添加呢稍微有一些不同,我会在下面进行标注大家仔细看
4.1修改一
这里我们拿Biformer注意力机制为例(我们拿有参数的注意力机制为例),首先我们找到该目录'ultralytics/nn/modules'该目录的构造如下->
我们在其中创建一个名字为Biformer的py文件如图所示,我们在其中复制如下代码即可
"""
Bi-Level Routing Attention.
"""
from typing import Tuple, Optional
import torch
import torch.nn as nn
import torch.nn.functional as F
from einops import rearrange
from torch import Tensor, LongTensorclass TopkRouting(nn.Module):"""differentiable topk routing with scalingArgs:qk_dim: int, feature dimension of query and keytopk: int, the 'topk'qk_scale: int or None, temperature (multiply) of softmax activationwith_param: bool, wether inorporate learnable params in routing unitdiff_routing: bool, wether make routing differentiablesoft_routing: bool, wether make output value multiplied by routing weights"""def __init__(self, qk_dim, topk=4, qk_scale=None, param_routing=False, diff_routing=False):super().__init__()self.topk = topkself.qk_dim = qk_dimself.scale = qk_scale or qk_dim ** -0.5self.diff_routing = diff_routing# TODO: norm layer before/after linear?self.emb = nn.Linear(qk_dim, qk_dim) if param_routing else nn.Identity()# routing activationself.routing_act = nn.Softmax(dim=-1)def forward(self, query: Tensor, key: Tensor) -> Tuple[Tensor]:"""Args:q, k: (n, p^2, c) tensorReturn:r_weight, topk_index: (n, p^2, topk) tensor"""if not self.diff_routing:query, key = query.detach(), key.detach()query_hat, key_hat = self.emb(query), self.emb(key) # per-window pooling -> (n, p^2, c)attn_logit = (query_hat * self.scale) @ key_hat.transpose(-2, -1) # (n, p^2, p^2)topk_attn_logit, topk_index = torch.topk(attn_logit, k=self.topk, dim=-1) # (n, p^2, k), (n, p^2, k)r_weight = self.routing_act(topk_attn_logit) # (n, p^2, k)return r_weight, topk_indexclass KVGather(nn.Module):def __init__(self, mul_weight='none'):super().__init__()assert mul_weight in ['none', 'soft', 'hard']self.mul_weight = mul_weightdef forward(self, r_idx: Tensor, r_weight: Tensor, kv: Tensor):"""r_idx: (n, p^2, topk) tensorr_weight: (n, p^2, topk) tensorkv: (n, p^2, w^2, c_kq+c_v)Return:(n, p^2, topk, w^2, c_kq+c_v) tensor"""# select kv according to routing indexn, p2, w2, c_kv = kv.size()topk = r_idx.size(-1)# print(r_idx.size(), r_weight.size())# FIXME: gather consumes much memory (topk times redundancy), write cuda kernel?topk_kv = torch.gather(kv.view(n, 1, p2, w2, c_kv).expand(-1, p2, -1, -1, -1),# (n, p^2, p^2, w^2, c_kv) without mem cpydim=2,index=r_idx.view(n, p2, topk, 1, 1).expand(-1, -1, -1, w2, c_kv)# (n, p^2, k, w^2, c_kv))if self.mul_weight == 'soft':topk_kv = r_weight.view(n, p2, topk, 1, 1) * topk_kv # (n, p^2, k, w^2, c_kv)elif self.mul_weight == 'hard':raise NotImplementedError('differentiable hard routing TBA')# else: #'none'# topk_kv = topk_kv # do nothingreturn topk_kvclass QKVLinear(nn.Module):def __init__(self, dim, qk_dim, bias=True):super().__init__()self.dim = dimself.qk_dim = qk_dimself.qkv = nn.Linear(dim, qk_dim + qk_dim + dim, bias=bias)def forward(self, x):q, kv = self.qkv(x).split([self.qk_dim, self.qk_dim + self.dim], dim=-1)return q, kv# q, k, v = self.qkv(x).split([self.qk_dim, self.qk_dim, self.dim], dim=-1)# return q, k, vclass BiLevelRoutingAttention(nn.Module):"""n_win: number of windows in one side (so the actual number of windows is n_win*n_win)kv_per_win: for kv_downsample_mode='ada_xxxpool' only, number of key/values per window. Similar to n_win, the actual number is kv_per_win*kv_per_win.topk: topk for window filteringparam_attention: 'qkvo'-linear for q,k,v and o, 'none': param free attentionparam_routing: extra linear for routingdiff_routing: wether to set routing differentiablesoft_routing: wether to multiply soft routing weights"""def __init__(self, dim, n_win=7, num_heads=8, qk_dim=None, qk_scale=None,kv_per_win=4, kv_downsample_ratio=4, kv_downsample_kernel=None, kv_downsample_mode='identity',topk=4, param_attention="qkvo", param_routing=False, diff_routing=False, soft_routing=False,side_dwconv=3,auto_pad=True):super().__init__()# local attention settingself.dim = dimself.n_win = n_win # Wh, Wwself.num_heads = num_headsself.qk_dim = qk_dim or dimassert self.qk_dim % num_heads == 0 and self.dim % num_heads == 0, 'qk_dim and dim must be divisible by num_heads!'self.scale = qk_scale or self.qk_dim ** -0.5################side_dwconv (i.e. LCE in ShuntedTransformer)###########self.lepe = nn.Conv2d(dim, dim, kernel_size=side_dwconv, stride=1, padding=side_dwconv // 2,groups=dim) if side_dwconv > 0 else \lambda x: torch.zeros_like(x)################ global routing setting #################self.topk = topkself.param_routing = param_routingself.diff_routing = diff_routingself.soft_routing = soft_routing# routerassert not (self.param_routing and not self.diff_routing) # cannot be with_param=True and diff_routing=Falseself.router = TopkRouting(qk_dim=self.qk_dim,qk_scale=self.scale,topk=self.topk,diff_routing=self.diff_routing,param_routing=self.param_routing)if self.soft_routing: # soft routing, always diffrentiable (if no detach)mul_weight = 'soft'elif self.diff_routing: # hard differentiable routingmul_weight = 'hard'else: # hard non-differentiable routingmul_weight = 'none'self.kv_gather = KVGather(mul_weight=mul_weight)# qkv mapping (shared by both global routing and local attention)self.param_attention = param_attentionif self.param_attention == 'qkvo':self.qkv = QKVLinear(self.dim, self.qk_dim)self.wo = nn.Linear(dim, dim)elif self.param_attention == 'qkv':self.qkv = QKVLinear(self.dim, self.qk_dim)self.wo = nn.Identity()else:raise ValueError(f'param_attention mode {self.param_attention} is not surpported!')self.kv_downsample_mode = kv_downsample_modeself.kv_per_win = kv_per_winself.kv_downsample_ratio = kv_downsample_ratioself.kv_downsample_kenel = kv_downsample_kernelif self.kv_downsample_mode == 'ada_avgpool':assert self.kv_per_win is not Noneself.kv_down = nn.AdaptiveAvgPool2d(self.kv_per_win)elif self.kv_downsample_mode == 'ada_maxpool':assert self.kv_per_win is not Noneself.kv_down = nn.AdaptiveMaxPool2d(self.kv_per_win)elif self.kv_downsample_mode == 'maxpool':assert self.kv_downsample_ratio is not Noneself.kv_down = nn.MaxPool2d(self.kv_downsample_ratio) if self.kv_downsample_ratio > 1 else nn.Identity()elif self.kv_downsample_mode == 'avgpool':assert self.kv_downsample_ratio is not Noneself.kv_down = nn.AvgPool2d(self.kv_downsample_ratio) if self.kv_downsample_ratio > 1 else nn.Identity()elif self.kv_downsample_mode == 'identity': # no kv downsamplingself.kv_down = nn.Identity()elif self.kv_downsample_mode == 'fracpool':# assert self.kv_downsample_ratio is not None# assert self.kv_downsample_kenel is not None# TODO: fracpool# 1. kernel size should be input size dependent# 2. there is a random factor, need to avoid independent sampling for k and vraise NotImplementedError('fracpool policy is not implemented yet!')elif kv_downsample_mode == 'conv':# TODO: need to consider the case where k != v so that need two downsample modulesraise NotImplementedError('conv policy is not implemented yet!')else:raise ValueError(f'kv_down_sample_mode {self.kv_downsaple_mode} is not surpported!')# softmax for local attentionself.attn_act = nn.Softmax(dim=-1)self.auto_pad = auto_paddef forward(self, x, ret_attn_mask=False):"""x: NHWC tensorReturn:NHWC tensor"""x = rearrange(x, "n c h w -> n h w c")# NOTE: use padding for semantic segmentation###################################################if self.auto_pad:N, H_in, W_in, C = x.size()pad_l = pad_t = 0pad_r = (self.n_win - W_in % self.n_win) % self.n_winpad_b = (self.n_win - H_in % self.n_win) % self.n_winx = F.pad(x, (0, 0, # dim=-1pad_l, pad_r, # dim=-2pad_t, pad_b)) # dim=-3_, H, W, _ = x.size() # padded sizeelse:N, H, W, C = x.size()assert H % self.n_win == 0 and W % self.n_win == 0 ##################################################### patchify, (n, p^2, w, w, c), keep 2d window as we need 2d pooling to reduce kv sizex = rearrange(x, "n (j h) (i w) c -> n (j i) h w c", j=self.n_win, i=self.n_win)#################qkv projection#################### q: (n, p^2, w, w, c_qk)# kv: (n, p^2, w, w, c_qk+c_v)# NOTE: separte kv if there were memory leak issue caused by gatherq, kv = self.qkv(x)# pixel-wise qkv# q_pix: (n, p^2, w^2, c_qk)# kv_pix: (n, p^2, h_kv*w_kv, c_qk+c_v)q_pix = rearrange(q, 'n p2 h w c -> n p2 (h w) c')kv_pix = self.kv_down(rearrange(kv, 'n p2 h w c -> (n p2) c h w'))kv_pix = rearrange(kv_pix, '(n j i) c h w -> n (j i) (h w) c', j=self.n_win, i=self.n_win)q_win, k_win = q.mean([2, 3]), kv[..., 0:self.qk_dim].mean([2, 3]) # window-wise qk, (n, p^2, c_qk), (n, p^2, c_qk)##################side_dwconv(lepe)################### NOTE: call contiguous to avoid gradient warning when using ddplepe = self.lepe(rearrange(kv[..., self.qk_dim:], 'n (j i) h w c -> n c (j h) (i w)', j=self.n_win,i=self.n_win).contiguous())lepe = rearrange(lepe, 'n c (j h) (i w) -> n (j h) (i w) c', j=self.n_win, i=self.n_win)############ gather q dependent k/v #################r_weight, r_idx = self.router(q_win, k_win) # both are (n, p^2, topk) tensorskv_pix_sel = self.kv_gather(r_idx=r_idx, r_weight=r_weight, kv=kv_pix) # (n, p^2, topk, h_kv*w_kv, c_qk+c_v)k_pix_sel, v_pix_sel = kv_pix_sel.split([self.qk_dim, self.dim], dim=-1)# kv_pix_sel: (n, p^2, topk, h_kv*w_kv, c_qk)# v_pix_sel: (n, p^2, topk, h_kv*w_kv, c_v)######### do attention as normal ####################k_pix_sel = rearrange(k_pix_sel, 'n p2 k w2 (m c) -> (n p2) m c (k w2)',m=self.num_heads) # flatten to BMLC, (n*p^2, m, topk*h_kv*w_kv, c_kq//m) transpose here?v_pix_sel = rearrange(v_pix_sel, 'n p2 k w2 (m c) -> (n p2) m (k w2) c',m=self.num_heads) # flatten to BMLC, (n*p^2, m, topk*h_kv*w_kv, c_v//m)q_pix = rearrange(q_pix, 'n p2 w2 (m c) -> (n p2) m w2 c',m=self.num_heads) # to BMLC tensor (n*p^2, m, w^2, c_qk//m)# param-free multihead attentionattn_weight = (q_pix * self.scale) @ k_pix_sel # (n*p^2, m, w^2, c) @ (n*p^2, m, c, topk*h_kv*w_kv) -> (n*p^2, m, w^2, topk*h_kv*w_kv)attn_weight = self.attn_act(attn_weight)out = attn_weight @ v_pix_sel # (n*p^2, m, w^2, topk*h_kv*w_kv) @ (n*p^2, m, topk*h_kv*w_kv, c) -> (n*p^2, m, w^2, c)out = rearrange(out, '(n j i) m (h w) c -> n (j h) (i w) (m c)', j=self.n_win, i=self.n_win,h=H // self.n_win, w=W // self.n_win)out = out + lepe# output linearout = self.wo(out)# NOTE: use padding for semantic segmentation# crop padded regionif self.auto_pad and (pad_r > 0 or pad_b > 0):out = out[:, :H_in, :W_in, :].contiguous()if ret_attn_mask:return out, r_weight, r_idx, attn_weightelse:return rearrange(out, "n h w c -> n c h w")4.2修改二
我们找到该文件'ultralytics/nn/tasks.py'在其中添加如下一行代码
from ultralytics.nn.modules.Biformer import BiLevelRoutingAttention as Biformer添加完之后的效果如下图->
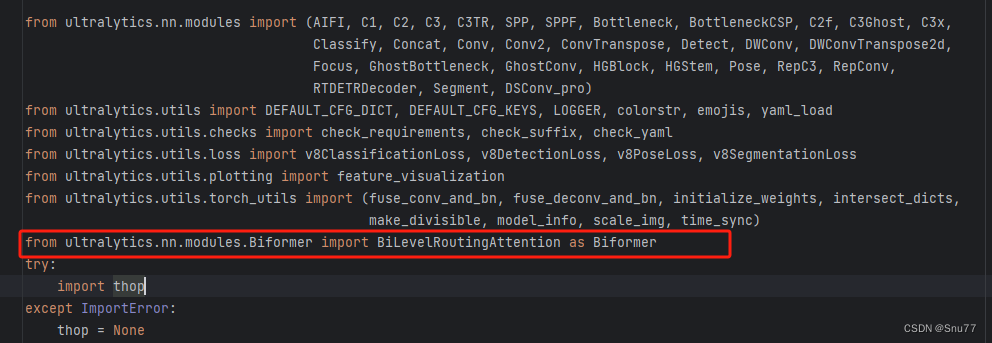
4.3修改三
这里需要注意体现出两种注意力机制的修改方式~
4.2.1有参数的注意力机制修改
现在我们已经将Biformer文件导入了模型中了,下一步我们就需要添加该机制到模型中让我们可以使用它,我们在步骤二的文件中''ultralytics/nn/tasks.py''按快捷键Ctrl+F可以进行文件搜索。

当然如果你不想用快捷键也可以自己寻找大概在 650行左右,有一个方法的名字叫"parse_model"
我们找到该方法对其进行修改,添加如下图所示内容。
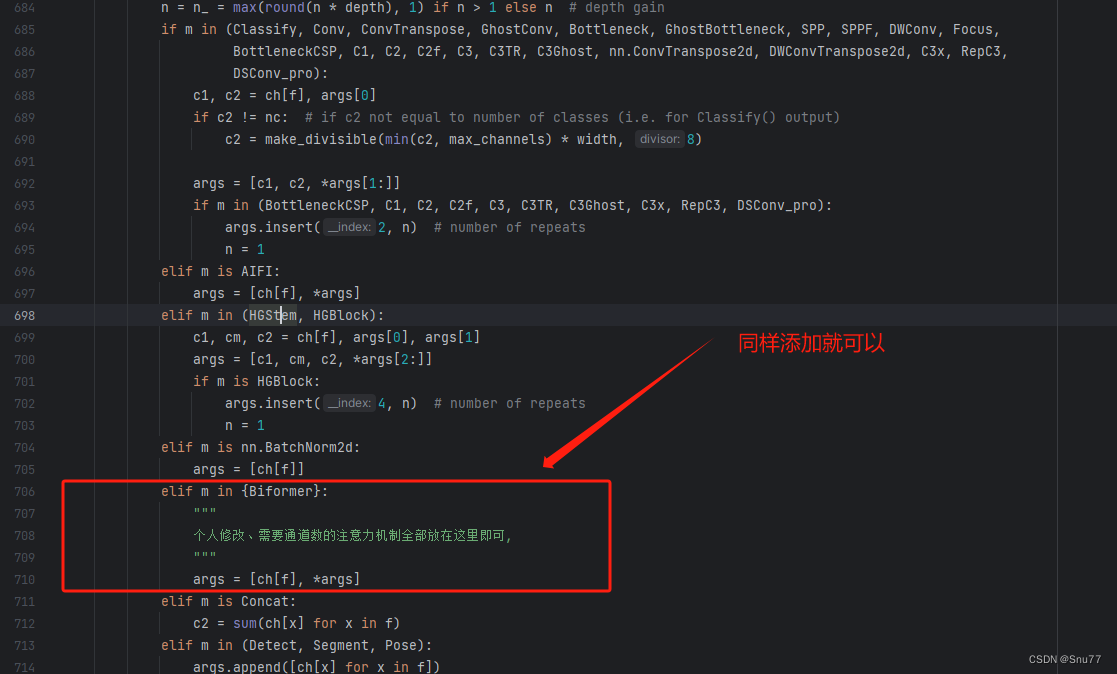
这里我们定义了一个字典,我们以后在想导入其它的注意力机制就可以重复步骤一和步骤二,然后在步骤三这里定义的字典中添加你导入的注意力机制名字即可。
4.2.2无参数的注意力机制修改
无参数的注意力机制直接修改完步骤二就可以,直接跳过本步骤的修改直接进行配置注意力机制即可,无参数的注意力机制的修改三不用进行任何修改~
4.4配置注意力机制
恭喜你,到这里我们就已经成功的导入了注意力机制,离修改模型只差最后一步,我们需要找到如下文件进行修改"ultralytics/cfg/models/v8/yolov8.yaml",找到这个文件之后初始如下所示,

我们可以在某一层中添加Biformer注意力机制,具体添加到哪里由你自己决定,我这里建议添加到 Neck层,也就是我们的特征融合层,添加之后的效果如下,这里我在三个地方添加了Biformer注意力机制。
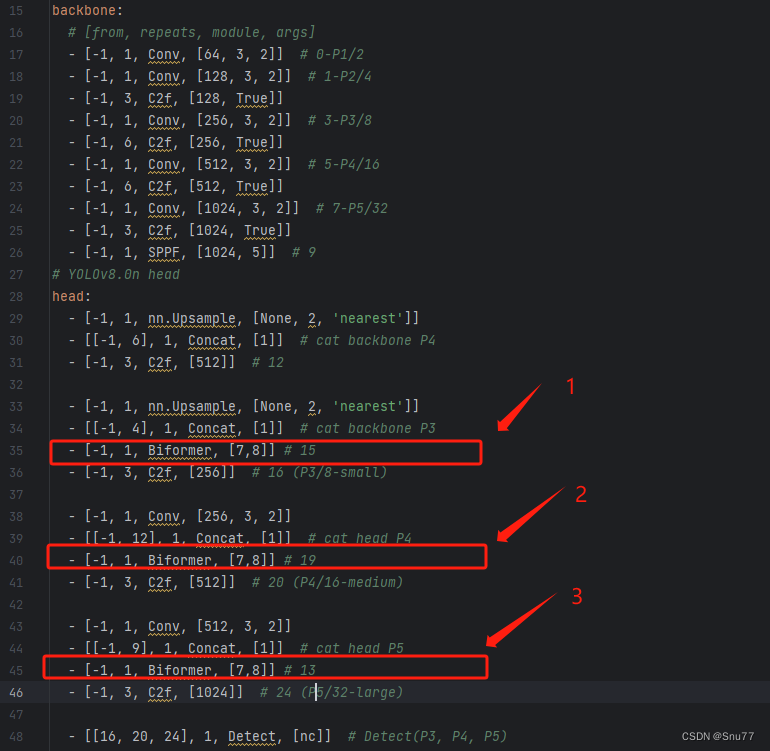
OK到此我们就添加了注意力机制到我们的模型里面了,下面我来讲一下添加的注意力机制中的参数是如何来的,
- 首先-1这里我们不用管, 它代表上一个层的输入输入-1就是让模型自动帮我们算输入的大小!
- 数字1代表这里我们的Biformer注意力机制执行一次
- Biformer代表我们的注意力机制名字,本来类的名字不是这个我在前面导入的时候给他另命名了前面有讲到
- [7,8]这里是根据Biformer定义的时候来的,你只需要输入前两个即可(需要注意的是无参数的注意力机制这里什么都不用填写可以看看你的无参数注意力机制需要什么那种超参数你给予赋值即可,不用从模型中获取任何的其它参数)。

当然这两个参数你可以换,调成其它的试试效果。
五、Neck部分
持续更新~
六、检测头
持续更新~
七、损失函数
当我们想要在YOLOv8中添加算是函数时候我们需要进行以下的操作,同时我我们引入Focus的思想时候需要进行如何的操作,大家可以按照如下的步骤进行操作即可。
我们提供的代码是最新的Inner实现的各种损失的思想,给大家进行尝试。
大家可以用下面的代码块一和代码块二进行操作。
代码块一
class Inner_WIoU_Scale:''' monotonous: {None: origin v1True: monotonic FM v2False: non-monotonic FM v3}momentum: The momentum of running mean'''iou_mean = 1.monotonous = False_momentum = 1 - 0.5 ** (1 / 7000)_is_train = Truedef __init__(self, iou):self.iou = iouself._update(self)@classmethoddef _update(cls, self):if cls._is_train: cls.iou_mean = (1 - cls._momentum) * cls.iou_mean + \cls._momentum * self.iou.detach().mean().item()@classmethoddef _scaled_loss(cls, self, gamma=1.9, delta=3):if isinstance(self.monotonous, bool):if self.monotonous:return (self.iou.detach() / self.iou_mean).sqrt()else:beta = self.iou.detach() / self.iou_meanalpha = delta * torch.pow(gamma, beta - delta)return beta / alphareturn 1def bbox_iou(box1, box2, x1y1x2y2=True, ratio=1, inner_GIoU=False, inner_DIoU=False, inner_CIoU=False, inner_SIoU=False,inner_EIoU=False, inner_WIoU=False, Focal=False, alpha=1, gamma=0.5, scale=False, eps=1e-7):(x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, -1), box2.chunk(4, -1)w1_, h1_, w2_, h2_ = w1 / 2, h1 / 2, w2 / 2, h2 / 2b1_x1, b1_x2, b1_y1, b1_y2 = x1 - w1_, x1 + w1_, y1 - h1_, y1 + h1_b2_x1, b2_x2, b2_y1, b2_y2 = x2 - w2_, x2 + w2_, y2 - h2_, y2 + h2_# IoU #IoU #IoU #IoU #IoU #IoU #IoU #IoU #IoU #IoU #IoUinter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \(torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)union = w1 * h1 + w2 * h2 - inter + eps# Inner-IoU #Inner-IoU #Inner-IoU #Inner-IoU #Inner-IoU #Inner-IoU #Inner-IoUinner_b1_x1, inner_b1_x2, inner_b1_y1, inner_b1_y2 = x1 - w1_ * ratio, x1 + w1_ * ratio, \y1 - h1_ * ratio, y1 + h1_ * ratioinner_b2_x1, inner_b2_x2, inner_b2_y1, inner_b2_y2 = x2 - w2_ * ratio, x2 + w2_ * ratio, \y2 - h2_ * ratio, y2 + h2_ * ratioinner_inter = (torch.min(inner_b1_x2, inner_b2_x2) - torch.max(inner_b1_x1, inner_b2_x1)).clamp(0) * \(torch.min(inner_b1_y2, inner_b2_y2) - torch.max(inner_b1_y1, inner_b2_y1)).clamp(0)inner_union = w1 * ratio * h1 * ratio + w2 * ratio * h2 * ratio - inner_inter + epsinner_iou = inner_inter / inner_union # inner_iouif scale:self = Inner_WIoU_Scale(1 - (inner_inter / inner_union))if inner_CIoU or inner_DIoU or inner_GIoU or inner_EIoU or inner_SIoU or inner_WIoU:cw = inner_b1_x2.maximum(inner_b2_x2) - inner_b1_x1.minimum(inner_b2_x1) # convex (smallest enclosing box) widthch = inner_b1_y2.maximum(inner_b2_y2) - inner_b1_y1.minimum(inner_b2_y1) # convex heightif inner_CIoU or inner_DIoU or inner_EIoU or inner_SIoU or inner_WIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1c2 = (cw ** 2 + ch ** 2) ** alpha + eps # convex diagonal squaredrho2 = (((inner_b2_x1 + inner_b2_x2 - inner_b1_x1 - inner_b1_x2) ** 2 + (inner_b2_y1 + inner_b2_y2 - inner_b1_y1 - inner_b1_y2) ** 2) / 4) ** alpha # center dist ** 2if inner_CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47v = (4 / math.pi ** 2) * (torch.atan(w2 / h2) - torch.atan(w1 / h1)).pow(2)with torch.no_grad():alpha_ciou = v / (v - inner_iou + (1 + eps))if Focal:return inner_iou - (rho2 / c2 + torch.pow(v * alpha_ciou + eps, alpha)), torch.pow(inner_inter / (inner_union + eps),gamma) # Focal_CIoUelse:return inner_iou - (rho2 / c2 + torch.pow(v * alpha_ciou + eps, alpha)) # CIoUelif inner_EIoU:rho_w2 = ((inner_b2_x2 - inner_b2_x1) - (inner_b1_x2 - inner_b1_x1)) ** 2rho_h2 = ((inner_b2_y2 - inner_b2_y1) - (inner_b1_y2 - inner_b1_y1)) ** 2cw2 = torch.pow(cw ** 2 + eps, alpha)ch2 = torch.pow(ch ** 2 + eps, alpha)if Focal:return inner_iou - (rho2 / c2 + rho_w2 / cw2 + rho_h2 / ch2), torch.pow(inner_inter / (inner_union + eps),gamma) # Focal_EIouelse:return inner_iou - (rho2 / c2 + rho_w2 / cw2 + rho_h2 / ch2) # EIouelif inner_SIoU:# SIoU Loss https://arxiv.org/pdf/2205.12740.pdfs_cw = (inner_b2_x1 + inner_b2_x2 - inner_b1_x1 - inner_b1_x2) * 0.5 + epss_ch = (inner_b2_y1 + inner_b2_y2 - inner_b1_y1 - inner_b1_y2) * 0.5 + epssigma = torch.pow(s_cw ** 2 + s_ch ** 2, 0.5)sin_alpha_1 = torch.abs(s_cw) / sigmasin_alpha_2 = torch.abs(s_ch) / sigmathreshold = pow(2, 0.5) / 2sin_alpha = torch.where(sin_alpha_1 > threshold, sin_alpha_2, sin_alpha_1)angle_cost = torch.cos(torch.arcsin(sin_alpha) * 2 - math.pi / 2)rho_x = (s_cw / cw) ** 2rho_y = (s_ch / ch) ** 2gamma = angle_cost - 2distance_cost = 2 - torch.exp(gamma * rho_x) - torch.exp(gamma * rho_y)omiga_w = torch.abs(w1 - w2) / torch.max(w1, w2)omiga_h = torch.abs(h1 - h2) / torch.max(h1, h2)shape_cost = torch.pow(1 - torch.exp(-1 * omiga_w), 4) + torch.pow(1 - torch.exp(-1 * omiga_h), 4)if Focal:return inner_iou - torch.pow(0.5 * (distance_cost + shape_cost) + eps, alpha), torch.pow(inner_inter / (inner_union + eps), gamma) # Focal_SIouelse:return inner_iou - torch.pow(0.5 * (distance_cost + shape_cost) + eps, alpha) # SIouelif inner_WIoU:if Focal:raise RuntimeError("WIoU do not support Focal.")elif scale:return getattr(Inner_WIoU_Scale, '_scaled_loss')(self), (1 - inner_iou) * torch.exp((rho2 / c2)), inner_iou # WIoU https://arxiv.org/abs/2301.10051else:return inner_iou, torch.exp((rho2 / c2)) # WIoU v1if Focal:return inner_iou - rho2 / c2, torch.pow(inner_inter / (inner_union + eps), gamma) # Focal_DIoUelse:return inner_iou - rho2 / c2 # DIoUc_area = cw * ch + eps # convex areaif Focal:return inner_iou - torch.pow((c_area - inner_union) / c_area + eps, alpha), torch.pow(inner_inter / (inner_union + eps),gamma) # Focal_GIoU https://arxiv.org/pdf/1902.09630.pdfelse:return inner_iou - torch.pow((c_area - inner_union) / c_area + eps,alpha) # GIoU https://arxiv.org/pdf/1902.09630.pdfif Focal:return inner_iou, torch.pow(inner_inter / (inner_union + eps), gamma) # Focal_IoUelse:return inner_iou # IoU代码块二
if type(iou) is tuple:if len(iou) == 2:# Focus Loss 时返回的是元组类型,进行额外处理loss_iou = ((1.0 - iou[0]) * iou[1].detach() * weight).sum() / target_scores_sumelse:loss_iou = (iou[0] * iou[1] * weight).sum() / target_scores_sumelse:# 正常的损失函数loss_iou = ((1.0 - iou) * weight).sum() / target_scores_sum7.1 修改一
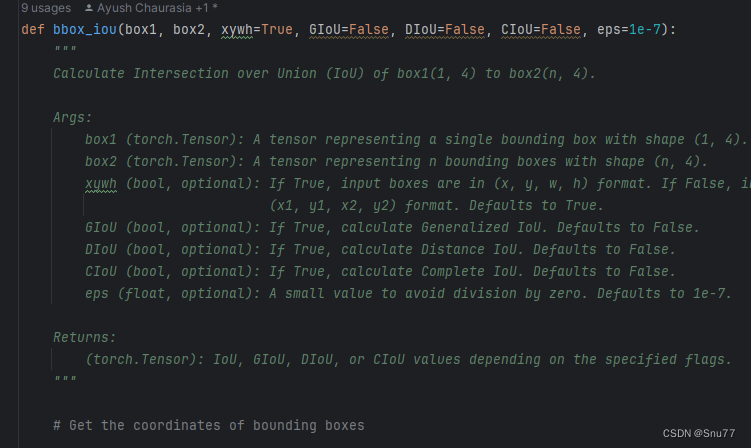
第一步我们需要找到如下的文件ultralytics/utils/metrics.py,找到如下的代码,下面的图片是原先的代码部分截图的正常样子,然后我们将整个代码块一将下面的整个方法(这里这是部分截图)内容全部替换
7.2 修改二
第二步我们找到另一个文件如下->"ultralytics/utils/loss.py",我们找到如下的代码块,将代码块二替换其中的第74行,
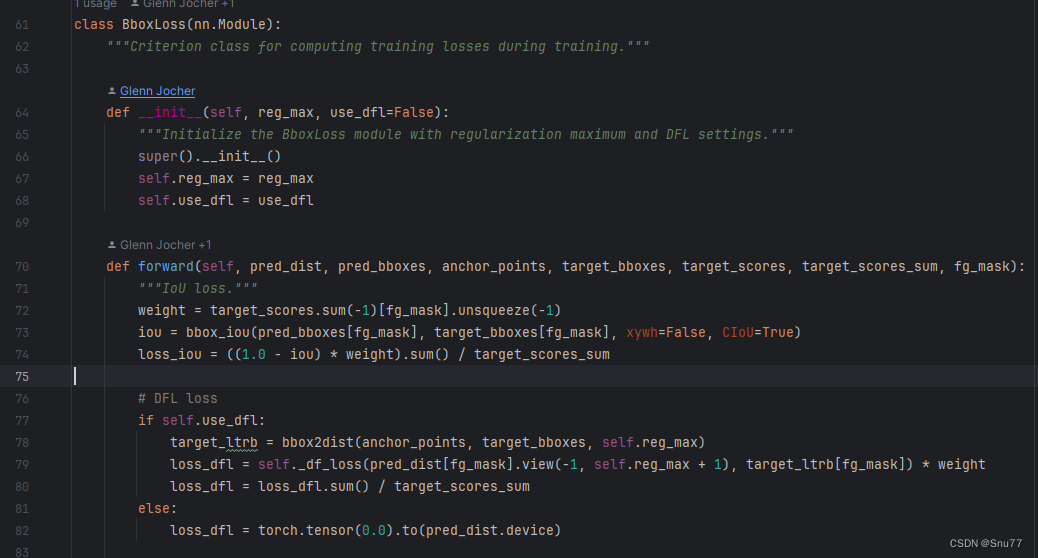
同时在上面的第73行(我说的我图片这里的不一定代表你那里,替换成如下的形式,因为我们这里用的Inner的思想的IoU所以我们的红框内和原先的也是不一样需要修改的,大家可以看到这里用到的是Inner_CIoU如果你想使用其它的IoU可以直接将Innner_CIoU更改其他的如果都是False则默认适用Inner_IoU即普通版本。(这里可以使用Focus的思想如果你想使用则在下面的红框内添加Foucs=True即可,Focus一般情况下精度会更高,但也有个别的例外)
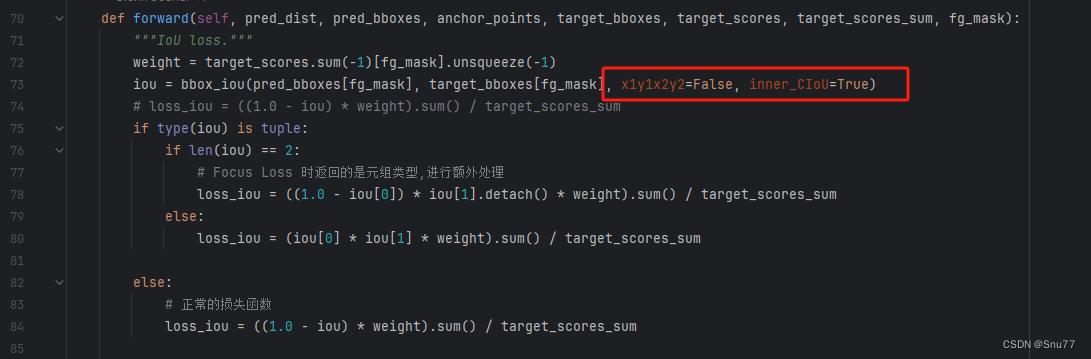
7.3 修改三
修改完上面的第二步,我们需要找到如下文件"ultralytics/utils/tal.py",在这个文件中我们找到如下的代码块,我这里已经修改完了(这里不要开启Focus的如果步骤二开启这里也不要开启,只要保持使用的损失函数一致即可)
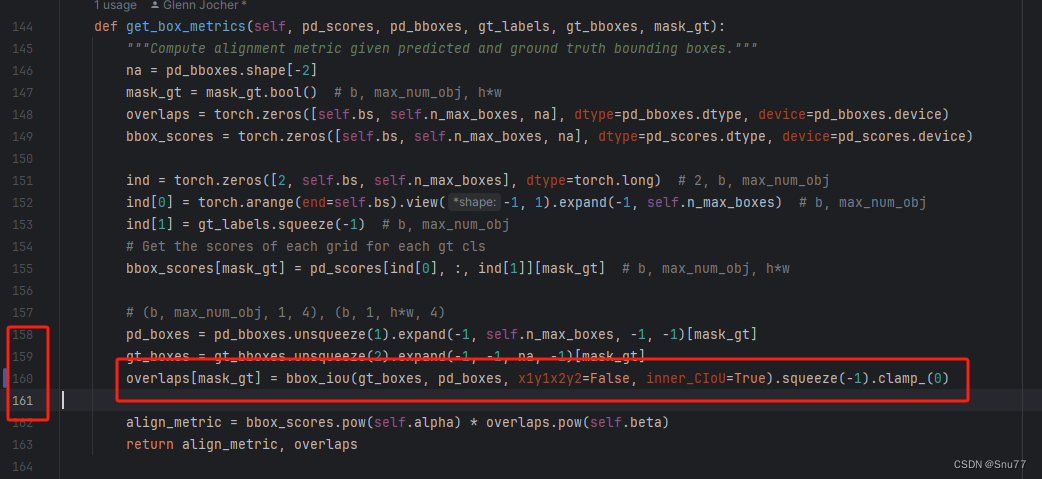

相关文章:
YOLOv8改进 | 如何在网络结构中添加注意力机制、C2f、卷积、Neck、检测头
一、本文介绍 本篇文章的内容是在大家得到一个改进版本的C2f一个新的注意力机制、或者一个新的卷积模块、或者是检测头的时候如何替换我们YOLOv8模型中的原有的模块,从而用你的模块去进行训练模型或者检测。因为最近开了一个专栏里面涉及到挺多改进的地方ÿ…...

记录一个困难
Mysql加插件 create table tb_xuesheng1 as select * from tb_xuesheng; 会报如下错误 SQL 错误 [3185] [HY000]: Cant find master key from keyring, please check in the server log if a keyring is loaded and initialized successfully.当我去搜寻答案网上都说缺少插件…...

Linux 进程管理 实时调度类及SMP和NUMA
文章目录 一、 实时调度类分析1.1 实时调度实体sched_rt_entity数据结构1.2 实时调度类rt_sched_class数据结构1.3 实时调度类功能函数 二、SMP和NUMA2.1 SMP(多对称处理器结构,UMA)2.2 NUMA(非一致内存访问结构)2.3 C…...
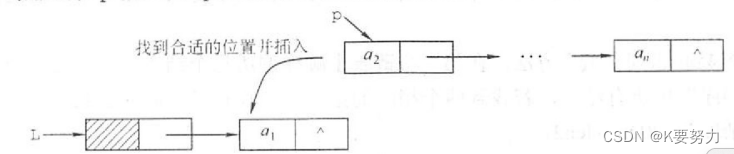
线性表--链表-1
文章目录 主要内容一.链表练习题1.设计一个递归算法,删除不带头结点的单链表 L 中所有值为 X 的结点代码如下(示例): 2.设 L为带头结点的单链表,编写算法实现从尾到头反向输出每个结点的值代码如下(示例): …...

WPF小知识
在编写WPF程序遇到一些小问题,所以记录起来,查其他方便。 Label自动换行 网上搜的都不能自动换行,发现使用Run 就可以。在脚本中直接调用labTip.Text进行赋值就可以了。 <Label Foreground"#FF9E9E9E" FontSize"16"…...

坐标系下的运动旋量转换
坐标系下的运动旋量转换 文章目录 坐标系下的运动旋量转换前言一、运动旋量物体运动旋量空间运动旋量 二、伴随变换矩阵三、坐标系下运动旋量的转换四、力旋量五、总结参考资料 前言 对于刚体而言,其角速度可以写为 ω ^ θ ˙ \hat {\omega} \dot \theta ω^θ˙&…...

Android Termux安装MySQL,通过内网穿透实现公网远程访问
🔥博客主页: 小羊失眠啦. 🔖系列专栏: C语言、Linux、Cpolar ❤️感谢大家点赞👍收藏⭐评论✍️ 文章目录 前言1.安装MariaDB2.安装cpolar内网穿透工具3. 创建安全隧道映射mysql4. 公网远程连接5. 固定远程连接地址 前…...

Python in Visual Studio Code 2023年11月发布
排版:Alan Wang 我们很高兴地宣布 Visual Studio Code 的 Python 和 Jupyter 扩展将于 2023 年 11 月发布! 此版本包括以下公告: 改进了使用 Shift Enter 在终端中运行当前行弃用内置 linting 和格式设置功能对 Python linting 扩展的改进重…...
算法通关村——数字中的统计、溢出、进制转换处理模板
数字与数学基础问题 1、数字统计 1.1、符号统计 LeetCode1822. 给定一个数组,求所有元素的乘积的符号,如果最终答案是负的返回-1,如果最终答案是正的返回1,如果答案是0返回0. 这题其实只用看数组中0和负数的个数就好了&#x…...

ESP01S通过心知天气获取天气和时间信息
ESP01S通过心知天气获取天气和时间信息 设置STA模式 ATCWMODE1 连接wifi ATCWJAP"wifi名称","wifi密码"3.设置时间地域 ATCIPSNTPCFG1,8获取时间 ATCIPSNTPTIME?返回: CIPSNTPTIME:Fri Nov 17 17:09:22 2023 OK连接心知服务器 ATCIPSTAR…...

docker容器内core dumped却找不到core文件
1. 检查ulimit, 使用命令: ulimit -a rootb7c19f6da1e3:/usr# ulimit -a core file size (blocks, -c) unlimited data seg size (kbytes, -d) unlimited scheduling priority (-e) 0 file size (blocks…...
ubuntu提高 github下载速度
Github一般用于Git的远程仓库,由于服务器位于国外,国内访问速度比较慢,为了提高访问速度,决定绕过DNS域名解析。 获取Github的IP地址 按下ctrl+alt+T打开命令终端,输入: nslookup gi…...

Node.js之path路径模块
让我为大家介绍一下path路径模块吧! 什么是path路径模块? path 模块是 Node.s 官方提供的、用来处理路径的模块。它提供了一系列的方法和属性,用来满足用户对路径的处理需求。 介绍三个关于path模块的方法: path.join() 方法&…...

TCP与UDP协议
TCP与UDP协议 1、TCP协议: 1、TCP特性: TCP 提供一种面向连接的、可靠的字节流服务。在一个 TCP 连接中,仅有两方进行彼此通信。广播和多播不能用于 TCP。TCP 使用校验和,确认和重传机制来保证可靠传输。TCP 给数据分节进行排序…...
$/i ”这个正则表达式的理解)
“ /^A-Z:\\{1,2}^/:\*\?<>\|+\.(jpg|gif|png|bmp)$/i ”这个正则表达式的理解
这个正则表达式可以分解为以下几个部分: ^:这是一个开始符号,表示匹配必须从字符串的开始部分开始。/:这是一个斜杠符号,通常在正则表达式中用来表示特殊字符的转义。A-Z::这部分表示匹配一个大写字母后跟…...

批量下载Sentinel数据脚本2023
批量下载Sentinel数据脚本2023 那些最好的程序员不是为了得到更高的薪水或者得到公众的仰慕而编程,他们只是觉得这是一件有趣的事情! 批量下载Sentinel数据脚本2023 批量下载Sentinel数据脚本2023🌿前言🌿脚本地址📧Su…...
lv11 嵌入式开发 ARM指令集中(伪操作与混合编程) 7
目录 1 伪指令 2 伪操作 3 C和汇编的混合编程 4 ATPCS协议 1 伪指令 本身不是指令,编译器可以将其替换成若干条等效指令 空指令NOP 指令LDR R1, [R2] 将R2指向的内存空间中的数据读取到R1寄存器 伪指令LDR R1, 0x12345678 R1 0x12345678 LDR伪指令可以将任…...

北邮22级信通院数电:Verilog-FPGA(10)第十周实验 实现移位寄存器74LS595
北邮22信通一枚~ 跟随课程进度更新北邮信通院数字系统设计的笔记、代码和文章 持续关注作者 迎接数电实验学习~ 获取更多文章,请访问专栏: 北邮22级信通院数电实验_青山如墨雨如画的博客-CSDN博客 目录 一.代码部分 二.管脚分配 三.实现过程讲解及效…...
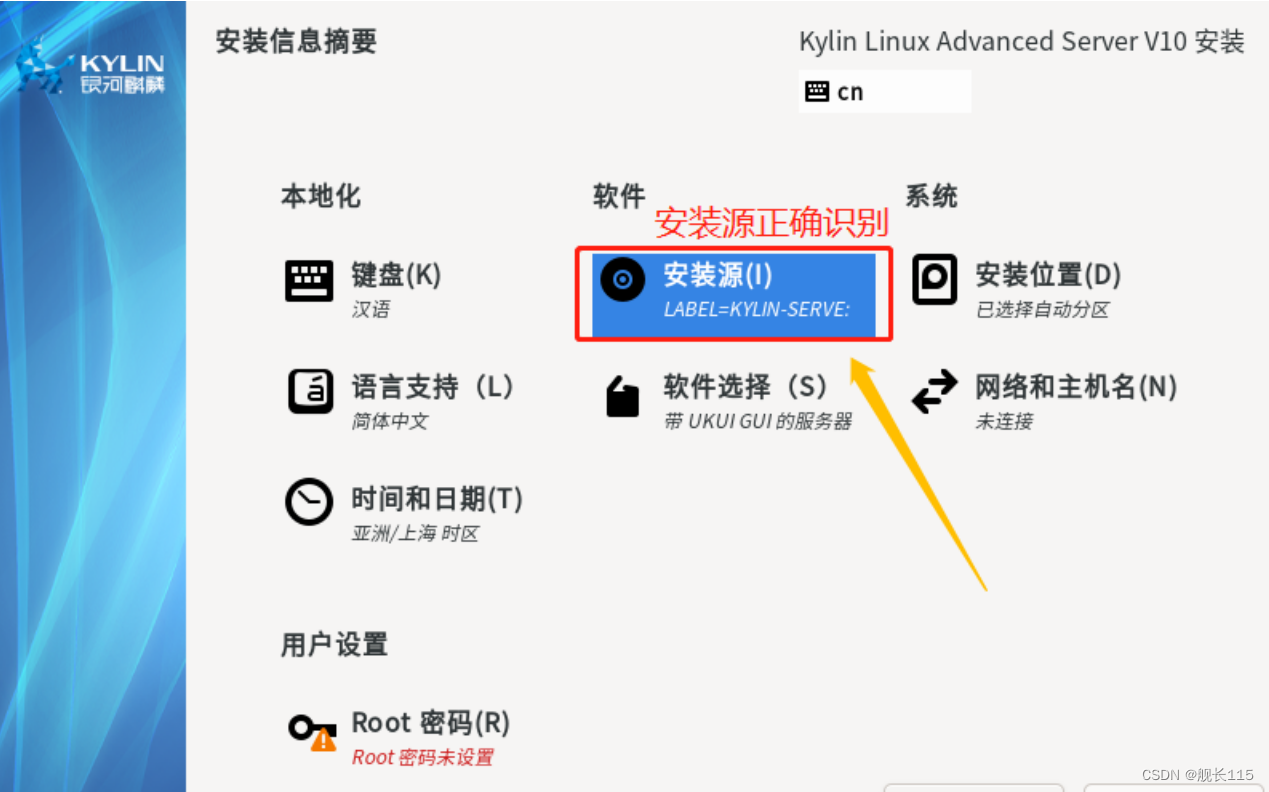
麒麟系统安装找不到安装源!!!!设置基础软件仓库时出错
记录--华为RH2288 V3服务器安装麒麟系统遇到的问题 1.遇到的问题--“设置基础软件仓库时出错”报错导致无法继续安装 没办法下一步 先说结论:系统bug 该问题在CentOS、Rocky Linux最新版中均存在 解决: (一)、如果是外网直接配…...
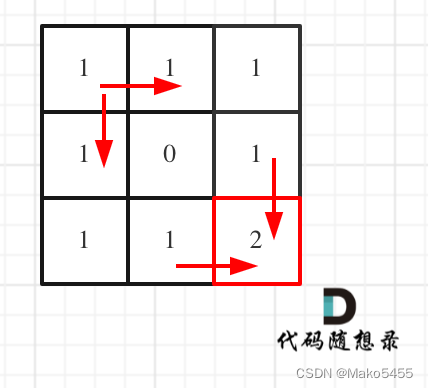
代码随想录算法训练营第三十九天【动态规划part02】 | 62.不同路径、63. 不同路径 II
62.不同路径 题目链接: 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 求解思路: 动规五部曲 确定dp数组及其下标含义:dp[i][j] 表示从(0,0)出发,到(i,j&#x…...

利用 Taotoken 为不同业务场景动态选择最合适的大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用 Taotoken 为不同业务场景动态选择最合适的大模型 在构建一个集成了大模型能力的应用时,一个常见的挑战是如何为不…...

Wireshark实战识别与防御ARP欺骗攻击
1. 为什么ARP欺骗不是“黑客电影”里的特效,而是你每天都在裸奔的真实风险 很多人第一次听说ARP欺骗,是在某部电影里看到主角敲几行命令,对面电脑就突然断网、弹出奇怪窗口、甚至开始自动转账——然后心里一紧:“这玩意儿真能这么…...

【2026必藏】6款智能降AI率软件全揭秘,一键把AI检测率精准控到安全区!
步入 2026 年,学术界的风向早已悄然转变。曾经只需担心查重率的焦虑,如今已经被更严苛的 AI 检测标准彻底覆盖。各大高校的审核系统不断迭代升级,AI 痕迹的识别能力越来越强,连最细微的语言风格都逃不过算法的审视。单靠改写句子、…...

火狐浏览器配置Burp Suite抓包完全指南
1. 为什么火狐浏览器在Burp Suite里“抓不到包”?——不是工具不行,是链路断了很多人第一次用Burp Suite配火狐时,点开Proxy → Intercept is on,浏览器照常访问网站,但Burp的HTTP History里空空如也。刷新十次、重启三…...

MPC-BE播放器完全手册:打造极致影音体验的终极解决方案
MPC-BE播放器完全手册:打造极致影音体验的终极解决方案 【免费下载链接】MPC-BE MPC-BE – универсальный проигрыватель аудио и видеофайлов для операционной системы Windows. 项目地址: h…...

Python HTTPS请求SSL证书验证失败排查指南
1. 这不是requests的bug,是TLS握手失败在敲门你刚写完一行requests.get("https://api.example.com"),回车一按,终端却甩出一长串红色报错:HTTPSConnectionPool(hostapi.example.com, port443): Max retries exceeded wi…...

公平AI研究的组织协调困境:从技术理想走向工程实践
1. 公平AI研究的十字路口:当技术理想遭遇组织现实如果你最近几年关注过人工智能的新闻,大概率会看到这样的标题:“某招聘算法被曝歧视女性”、“某医疗AI系统对少数族裔诊断准确率显著偏低”。这些并非科幻小说的情节,而是算法偏见…...

破解行业共性管控难题,推动矿山安全体系迭代升级 ——基于视频孪生无感定位的矿山安全体系革新技术方案
破解行业共性管控难题,推动矿山安全体系迭代升级——基于视频孪生无感定位的矿山安全体系革新技术方案一、方案引言国内煤炭矿山长期在人员监管、灾害应急、隐患溯源、空间管控层面沉淀诸多共性难题,佩戴管控流于形式、监测数据失真失实、灾变监测体系快…...

体验Taotoken聚合端点带来的高稳定性与低延迟模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 体验Taotoken聚合端点带来的高稳定性与低延迟模型调用 作为一名需要频繁调用大模型API的开发者,我曾管理着多个项目&am…...

基于特征图的机器学习模型选择:从静态规则到动态适应
1. 项目概述:从“凭感觉”到“有章法”的模型选择在机器学习项目的实战中,最让人头疼的环节之一,往往不是调参,而是最初那个看似简单的问题:我该用哪个模型?面对Scikit-Learn库里琳琅满目的算法,…...