从一到无穷大 #19 TagTree,倒排索引入手是否是优化时序数据库查询的通用方案?
 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
- 文章主旨
- 时序数据库查询的一般流程
- 扫描
- 维度聚合
- 时间聚合
- 管控语句
- TagTree
- 整体结构
- 索引结构
- 可能的问题
- 测试
文章主旨
文章针对的问题点在于现有的倒排索引实现在高基数的情况下性能较差,现有方法问题如下:
- 使用外部数据库管理tag信息时,时间序列数据库需要为每次用户查询向外部数据库发送请求,从而大大增加了tag查询延迟。
- 将tag索引与时间序列数据一起存储在多个时间分段文件中,每个数据段包含一个时间窗口中的所有时间序列数据以及将时间序列映射到数据的倒排索引,此时跨越多个时间窗口的时间序列元数据将存储在多个时间段中,从而导致元数据重复。这种重复的元数据会带来巨大的内存消耗和 I/O 开销以及多个分段的额外搜索开销。
文章的主要思想是设计一个全局共享的倒排索引,与时间分区方法相比,内存消耗和存储空间占用可以大大减少,此外倒排索引在内部进行了时间分区。对于每个tag,seriesId被分为多个分区,每个分区对应一个时间段,时间段本身也被编码在key中,这意味着对于多个时间段的查询可以很好的利用B+树的有序特性,元数据的扫描只需要一次;对于单次的查询也可以根据查询时间范围快速定位所需的分区,避免稀疏数据带来的额外扫描数据的开销(不做时间分区可能存在大量时间线指定时间区间内无数据)。
时序数据库查询的一般流程
以influxdb引擎举例子,引擎侧查询侧涉及TSI(基于Predicate筛选SeriesID),SeriesFile(基于SeriesID获取原始SerieKey)和TSM(基于SeriesID扫描压缩后的数据)三个结构。而不同的sql涉及的瓶颈则各不相同,举几个例子:
扫描
select field1,field2 from car where “taga” = ‘lizhaolong’
select aggregate(field1) from car where “taga” = ‘lizhaolong’
select selector(field1) from car where “taga” = ‘lizhaolong’
此时查询的开销基本集中在TSI和TSM,且大概率集中在TSM,但是也于数据本身的稀疏程度,基数有关
维度聚合
select field1,field2 from car where “taga” = ‘lizhaolong’ group by tagb
select aggregate(field1) from car where “taga” = ‘lizhaolong’ group by tagb
select selector(field1) from car where “taga” = 'lizhaolong group by tagb
通过TSI获取此次查询涉及到的SeriesIDSets后,需要基于SeriesID反查SeriesFile获取实际的tag组合,最后扫描数据
数据的稀疏程度,基数,写入流程中涉及到的时间线分布(影响反查SeriesFile)
时间聚合
select field1,field2 from car where “taga” = ‘lizhaolong’ group by tagb, time(12m)
select aggregate(field1) from car where “taga” = ‘lizhaolong’ group by tagb, time(12m)
select selector(field1) from car where “taga” = 'lizhaolong group by tagb, time(12m)
在之前的基础上,此时CPU的计算可能成为瓶颈,因为涉及到大量数据的聚合计算
管控语句
show tag values
show series cardinality
此时瓶颈基本存在在TSI查询和SeriesIDs的合并流程(虽然基于RoaringBitmap的合并很快,但是有时仍旧会成为瓶颈)
TagTree
从上一节可以看到,工程上的查询优化的流程并不是简单的替换某个结构就可以完成的,因为基于不同的条件,查询的瓶颈并不相同,所以对于结构的修改一般非常谨慎,我们需要衡量其优势和劣势,并针对于业务的场景做决策。
回到论文本身,TagTree的思路其实非常简洁,即通过合并多个时间分片中的倒排索引结构,并实现高效的B+树,和定期与磁盘结构合并的内存索引,以做到:
- 去除磁盘上重复的元数据存储
- 去除查询多个时间分片中倒排索引带来的内存消耗, I/O 开销以及额外搜索开销
- 写入性能不受影响
整体结构
优点看完了,我们来过一遍TagTree的设计,思考这样做可能存在的问题:

整体的设计有三个地方比较重要:
- symbol table is a list of all strings that appear in the tags to reduce space overhead for duplicate strings.
- The memory index and the index tree implement the inverted index which finds series IDs by tag sets.
- The series manager contains a list of series entries that hold the metadata for each time series.
基于这里可以看出设计tagTree的团队至少已经意识到了tagkey/tagvalue本身带来的磁盘空间占用问题,所以引入symbol table,这里我认为可以理解为字典化减少存储开销
其次可以看到Index Tree和Series Manager的实现是基于Page cache的,而不是基于mmap,这样的好处我已经不想说了,influxdb使用mmap的行为目前来看实在是架构上最为错误的决定,带来了性能上的致命缺陷,而自己管理page cache和淘汰才是最优方案。

文中把倒排索引看作一个键值存储,那键的编码自然非常重要,文中认为每个唯一键都可以代表一个这个tag组合的SeriesSets的一个分段。
键本身分为四个部分:
- tagkey的哈希值
- tagvalue的哈希值
- 分区的起始时间戳
- segment selector
key编码中加入时间最大的优势是查询中的Predicate在KeyNameSpace中被编码为一个区间,这个区间包含某个Predicate涉及的所有时间区间可以被一次B+树的查询找到起始点,随后利用B+树的有序优势,迅速索引到剩下的时间区间。
segment selector的概念其实是因为tagTree希望利用到seriesID到有序特性,SeriesSets在磁盘中采用bitmap存储,这样一个4kb的页可以存储32k个seriesID,但是因为seriesID本身是有序的,而tagTree全局唯一后SeriesID的分配也必将全局唯一,这样就导致伴随着时间的移动,可能存在一大片区间bitmap中永远为0,所以可以把SeriesSet的存储划分为N段,分段 1 涵盖 ID 为 0 至 32k 的时间序列,分段 2 涵盖 32k 至 64k 的时间序列,tagTree使用最低两个字节来指代SeriesSet的特定段,这意味着tagTree最多可以支持2^16*32k=2147450880的时间线上限,基本已经足够,但是我想说这样的做法不一定更节省存储(极端情况需要用4kb代表一个时间序列),而且以时序数据库的磁盘利用率来看这里也并不是瓶颈。
当然SeriesSets的页面还存储了这个tagkey对应在符号表中的引用,为了正则操作可以正确的进行。
从架构来看,Series Manager也是TagTree很重要的模块,功能可以类比influxdb中的SeriesFile,但是文中只是提了寥寥几笔,可以理解为这里的实现没有什么创新点,但是也同时可以看到series-cache的概念已经被用于非常多的时序数据库(Lindorm)。
The series manager contains a list of series entries and each entry is a tuple of the series ID of a time series and its tag set. The series entries are stored on the disk and the series manager maintains a series-cache in the memory to accelerate the access to the most recent time series. The series manager also handles loading series entries from the disk.
索引结构
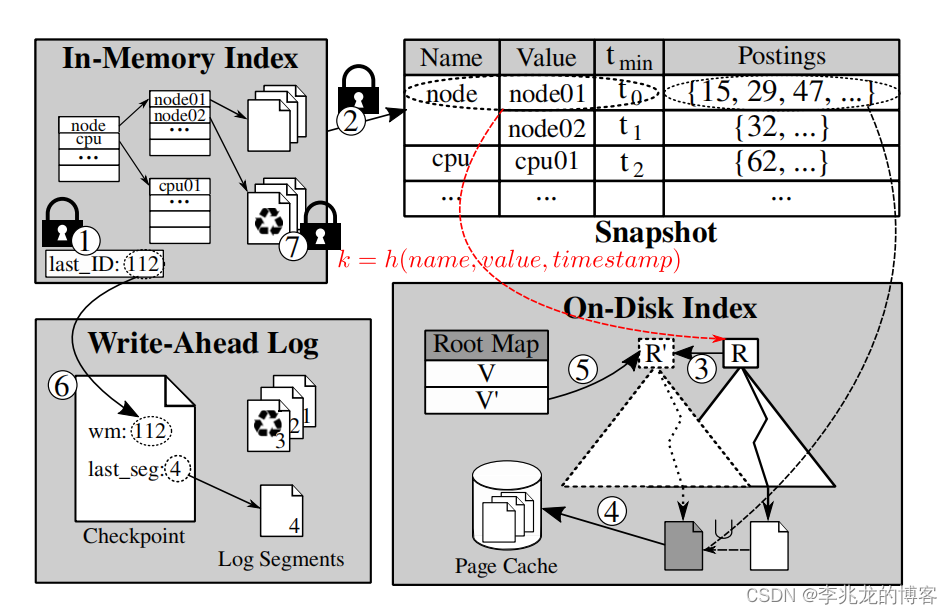
索引本身的实现的高效依赖于copy-on-write B±tree,它以一种存储效率高的格式存储索引数据,但只支持通过内存组件进行分批插入。
内存中的结构不必多说,tagkey->tagvalue->SeriesSets,这里需要的是一个内存友好的倒排索引,在内存到达阈值后触发异步索引合并流程
异步索引合并对张贴列表页和树节点页都采用了写时复制的方法。
对于每个tag组合都需要顾及seriesSet的大小(前文提到是用segment selector+bitmap实现的),其次确定最小时间戳,与现有B+数中的分段执行合并后写入 shadow pages,随后从根节点开始修改PageID指向,创建新版本的copy-on-write tree。
新的时间序列已经被保留在磁盘,就可以截断WAL,丢弃内存数据,从而将内存索引的大小保持在阈值以下。
可能的问题
事实上优化思路是没错的,工程不是学术,对于一个新结构我们最关心的是这个特性的普适程度以及各种负载下的稳定性,目前看到的问题有这些:
- 现有的云数据库全面拥抱Parquet(IotDB tsfile)不是没道理的,分离索引设计带来的性能/存储开销一般来看不是性能瓶颈,反而带来了允许批量导入的极大优势,合并倒排索引后基本上断了批量导入就只能慢慢悠悠的写数据了,就连打包迁移都不好做。
- Copy-on-write B+树本身的问题,
a. 数据一致性: 在高并发环境中,读取操作可能会遇到数据一致性问题。虽然COW策略可以减少锁的使用,但在写操作发生时,读操作可能会读到旧的数据,因为它可能在新数据被完全写入之前就已经开始了。
b. 内存使用: 由于COW需要在写操作时复制节点,这可能会导致内存使用的短暂增加,尤其是在大量写操作发生时。
c. 稳定的实现需要时间 - 优化的仅仅是TSI的查询部分,大多数查询语句瓶颈不在这里
测试
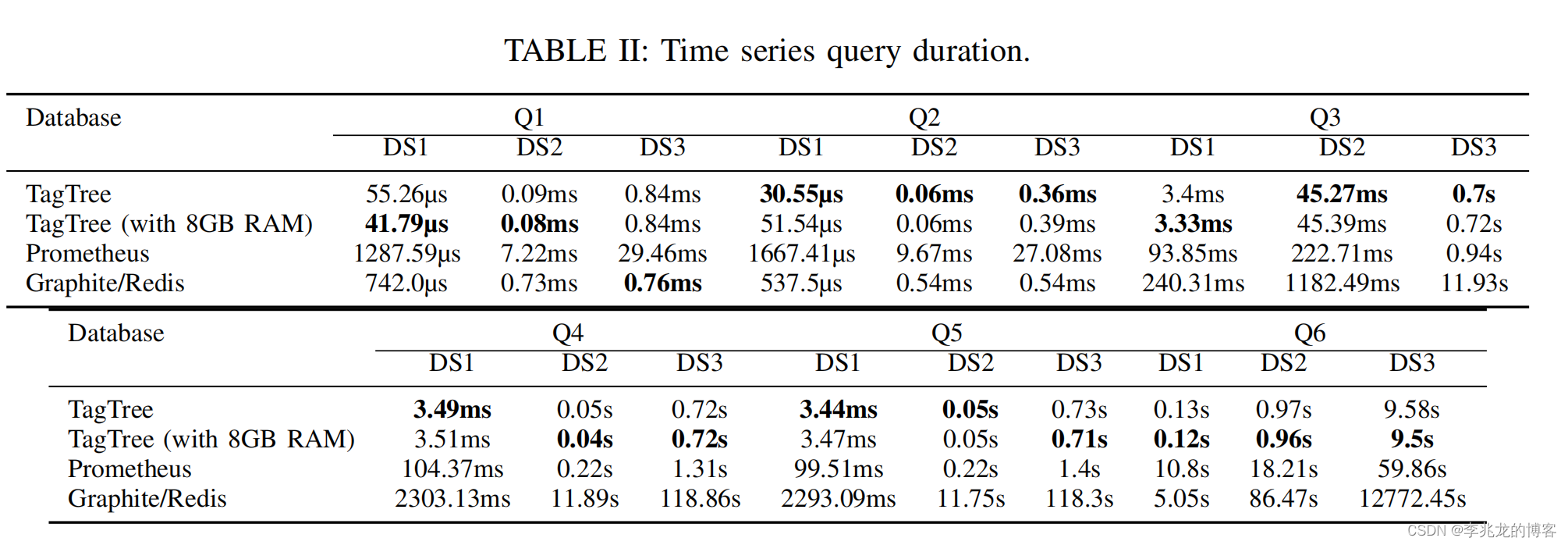
- Q1 (single-groupby-1-1-1): Select one metric for one host (point query).
- Q2 (cpu-max-all-1): Find all metrics for one host.
- Q3 (single-groupby-1-8-1): Find one metric for each of 8 hosts.
- Q4 (cpu-max-all-8): Find all metrics for 8 hosts.
- Q5 (single-groupby-5-8-1): Find 5 metrics for each of the 8 hosts.
- Q6: cpu{ metric !=“usage user”} This query selects time series for all CPU usages except usage user for all hosts. This query selects 90% of all time series in the database. This query is to test the performance of range queries with a large result set.
tagTree在时间跨度较长,Predicate涵盖范围较多,数据量较少,数据集不稀疏,计算较少,性能相对于一般倒排索引结构会有显著提升,显然测试中的case就是这样。
参考:
- Reducing the storage overhead of main-memory oltp databases with hybrid indexes sigmod 2016
- Db2 Event Store,A Purpose-Built IoT Database Engine
- ByteSeries: an in-memory time series database for large-scale monitoring systems
- TagTree: Global Tagging Index with Efficient Querying for Time Series Databases
相关文章:
从一到无穷大 #19 TagTree,倒排索引入手是否是优化时序数据库查询的通用方案?
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。 本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。 文章目录 文章主旨时序数据库查询的一般流程扫描维度聚合时间聚合管控语句 TagTree整体结构索引…...
程序员带你入门人工智能
随着人工智能技术的飞速发展,越来越多的程序员开始关注并学习人工智能。作为程序员,我们可能会对如何开始了解人工智能感到困惑。今天,我将向大家介绍一些如何通过自学了解人工智能的经验和方法,帮助大家更好地入门这个充满挑战和…...

机器学习笔记 - 了解常见开源文本识别数据集以及了解如何创建用于文本识别的合成数据
一、部分开源数据集 以下是一些英文可用的开源文本识别数据集。 ICDAR 数据集:ICDAR 代表国际文档分析和识别会议。该活动每两年举行一次。他们带来了一系列塑造了研究社区的场景文本数据集。例如, ICDAR-2013和ICDAR-2015数据集。 MJSynth 数据集:该合成词数据集由牛津大…...

openssl开发详解
文章目录 一、openssl 开发环境二、openssl随机数生成三、openssl对称加密3.1 SM43.2 AES3.3 DES3.4 3DES 四、openssl非对称加密4.1 SM24.2 RSA4.3 ECC 五、openssl的hash5.1 SM35.2 md55.3 sha256 五、证书5.1 证书格式 六、openssl网络编程七、openssl调试FIDO流程 一、open…...

conda虚拟环境中安装的cuda和服务器上安装的cuda的异同
服务器上已安装Nvidia提供的cuda,nvcc -V时会出现已安装的CUDA版本。如下图所示,服务器上已安装好的cuda版本为10.1。 但是当我们在Anaconda虚拟环境下安装pytorch或者paddlepaddle等深度学习框架的GPU版本时,通常会选择较高版本的cuda&…...

股东入股可用的出资形式主要有哪些
股东入股,可用的出资形式主要包括货币以及实物、知识产权、土地使用权等可以用货币估价并可以依法转让的非货币财产。 第一,货币。设立公司必然需要一定数量的流动资金。以支付创建公司时的开支和启动公司运营。因此,股东可以用货币出资。 第…...

react中设置activeClassName的笔记
React是一种流行的JavaScript库,用于构建动态用户界面。它具有许多有用的组件,其中之一是NavLink组件。NavLink组件用于在React应用程序中创建链接,并且它具有许多有用的属性,例如选中的样式设置。 react-router-dom": “^6…...

JS原型对象prototype
让我简单的为大家介绍一下原型对象prototype吧! 使用原型实现方法共享 1.构造函数通过原型分配的函数是所有对象所 共享的。 2.JavaScript 规定,每一个构造函数都有一个 prototype 属性,指向另一个对象,所以我们也称为原型对象…...
nodejs+vue实验室上机管理系统的设计与实现-微信小程序-安卓-python-PHP-计算机毕业设计
用户:管理员、教师、学生 基础功能:管理课表、管理机房情况、预约机房预约;权限不同,预约类型不同,教师可选课堂预约和个人;课堂预约。 在实验室上机前,实验室管理员需要对教务处发来的上机课表…...

SpringBoot 注解开发
利用自定义注解,解决问题 例1 自定义注解限制请求 场景:前端发起的频繁的请求,导致服务器压力过大。需要对后端接口进行限流处理,每个接口都需要做限流处理的话就会导致代码冗余,此时就可以利用注解进行解决 非注解形…...
使用持久卷部署 WordPress 和 MySQL
🗓️实验环境 OS名称Microsoft Windows 11 家庭中文版系统类型x64-based PCDocker版本Docker version 24.0.6, build ed223bcminikube版本v1.32.0 🖇️创建 kustomization.yaml 你可以通过 kustomization.yaml 中的生成器创建一个 Secret存储密码或密…...

2024年csdn最新最全的Postman接口测试: postman实现参数化
什么时候会用到参数化 比如:一个模块要用多组不同数据进行测试 验证业务的正确性 Login模块:正确的用户名,密码 成功;错误的用户名,正确的密码 失败 postman实现参数化 在实际的接口测试中,部分参数…...
开发知识点-uniapp微信小程序-开发指南
uniapp Vue的原型链生命周期函数onLoaduni.chooseLocationgetCurrentPages美团外卖微信小程序开发uniapp-美团外卖微信小程序开发P1 成果展示P2外卖小程序后端,学习给小程序写http接口P3 主界面配置P4 首页组件拆分P13 外卖列表布局筛选组件商家 布局测试数据创建样…...

Vue3+Vite实现工程化,事件绑定以及修饰符
我们可以使用v-on来监听DOM事件,并在事件触发时执行对应的Vue的Javascript代码。 用法:v-on:click "handler" 或简写为 click "handler"vue中的事件名原生事件名去掉 on 前缀 如:onClick --> clickhandler的值可以是方法事件…...

20、动态路由_下滑线为前缀的目录
创建文件 pages_question\index.vue pages_question\detail.vue 生成的对应路由: const _6bf6ece8 () > interopDefault(import(..\\pages\\_question\\index.vue /* webpackChunkName: "pages/_question/index" */)) const _a98c80aa () > in…...
中间件安全: Apache 远程代码执行 (CVE-2021-42013)
中间件安全: Apache 远程代码执行 (CVE-2021-42013) Apache HTTP Server是美国阿帕奇(Apache)基金会的一款开源网页服务器。该服务器具有快速、可靠且可通过简单的API进行扩充的特点,发现 Apache HTTP Ser…...
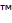
YOLOv8优化与量化(1000+ FPS性能)
YOLO家族又添新成员了!作为目标检测领域著名的模型家族,you only look once (YOLO) 推 出新模型的速度可谓是越来越快。就在刚刚过去的1月份,YOLO又推出了最新的YOLOv8模型,其模型结构和架构上的创新以及所提供的性能提升…...

python urllib open 头部信息错误
header 有些字符在 lighttpd server 中无法正常解析,需要转换 quteo 可以转换 就跨平台而言,Rust 和 python 一样优秀,看了在stm32 上使用 Rust 进行编程,从一定程度上,而言,稳定和安全性要比C 开发的好的多,说出来可能不信,在单片机上是可以对空指针进行…...
nn.KLDivLoss,nn.CrossEntropyLoss,nn.MSELoss,Focal_Loss
KL loss:https://blog.csdn.net/qq_50001789/article/details/128974654 https://pytorch.org/docs/stable/nn.html 1. nn.L1Loss 1.1 公式 L1Loss: 计算预测 x和 目标y之间的平均绝对值误差MAE, 即L1损失: l o s s 1 n ∑ i 1 , . . . n ∣ x i…...
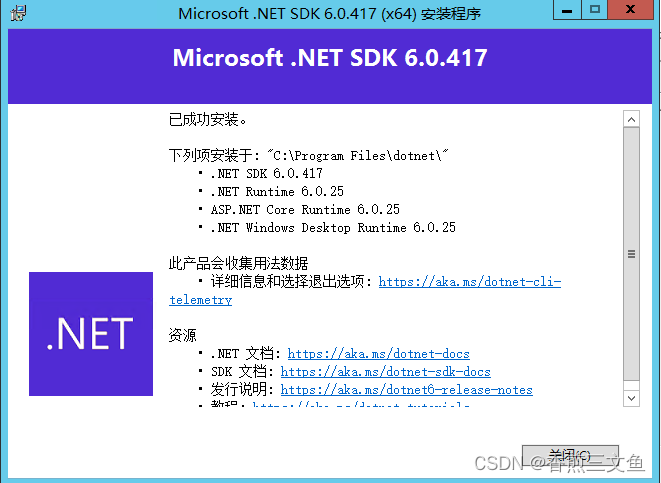
HTTP Error 500.31 - Failed to load ASP.NET Core runtime
在winserver服务器上部署net6应用后,访问接口得到以下提示: 原因是因为没有安装net6的运行时和环境,我们可以在windows自带的 “事件查看器” 查看原因。 可以直接根据给出的地址去官网下载sdk环境,安装即可 下载对应的net版本…...

Axure RP中文语言包终极配置指南:5分钟实现界面完全本地化
Axure RP中文语言包终极配置指南:5分钟实现界面完全本地化 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包。支持 Axure 11、10、9。不定期更新。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn 还在为Axu…...

ShopXO任意文件读取漏洞CNVD-2021-15822深度解析
1. 这不是“读文件”,而是绕过权限边界的系统级失守 ShopXO 是国内中小电商项目中出镜率极高的开源系统,轻量、模板丰富、部署快,很多本地生活类小程序后台、县域特产商城、校园二手平台都用它打底。但就在2021年CNVD公布的编号 CNVD-2021-15…...

预测增强蒙特卡洛:用机器学习加速高成本仿真
1. 项目概述:当蒙特卡洛遇上机器学习在金融工程、量化风控乃至医疗资源模拟这些对精度和可靠性要求极高的领域,蒙特卡洛(Monte Carlo, MC)仿真是我们绕不开的基石工具。它的魅力在于“简单粗暴”的有效性:通过生成大量…...

WebPlotDigitizer完整指南:如何从图表图像中快速提取精准数据
WebPlotDigitizer完整指南:如何从图表图像中快速提取精准数据 【免费下载链接】WebPlotDigitizer Computer vision assisted tool to extract numerical data from plot images. 项目地址: https://gitcode.com/gh_mirrors/we/WebPlotDigitizer 你是否曾经面…...

SPT-AKI存档编辑器终极指南:掌握《逃离塔科夫》单机版修改技巧
SPT-AKI存档编辑器终极指南:掌握《逃离塔科夫》单机版修改技巧 【免费下载链接】SPT-AKI-Profile-Editor Программа для редактирования профиля игрока на сервере SPT-AKI 项目地址: https://gitcode.com/gh_m…...

如果你要设计一个“个人助理“Agent,记忆系统应该如何分层?
这个问题挺有意思的,个人助理 Agent 的记忆系统,核心是分层设计——不是所有记忆都放一个地方,得按时效性、访问频率、重要性分层。 我之前做过一个个人助理项目,一开始就把所有记忆都扔向量库里,结果检索慢、成本高、还容易检索到过时信息。后来重构成分层架构,效果好很多。 …...

基于开源大模型的自动化定性分析:GATOS工作流实践指南
1. 项目概述:当定性研究遇上开源大模型如果你做过定性研究,比如分析访谈记录、开放式问卷反馈或者社交媒体评论,你肯定对“主题分析”和“编码”这两个词又爱又恨。爱的是,它能让你从海量文本中提炼出深刻的、人性化的洞察&#x…...

Sunshine虚拟手柄终极指南:解决游戏串流控制难题
Sunshine虚拟手柄终极指南:解决游戏串流控制难题 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 在游戏串流体验中,最令人沮丧的莫过于手柄连接失败、按键映…...

视频硬字幕提取工具:如何用5分钟搞定87种语言的字幕提取?
视频硬字幕提取工具:如何用5分钟搞定87种语言的字幕提取? 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包含字幕区域…...

弦图与范畴论:统一混合量子-经典机器学习的形式化框架
1. 项目概述与核心价值如果你正在关注量子计算与机器学习的交叉领域,尤其是那些被称为“混合量子-经典”的算法,你可能会发现一个有趣的现象:相关的论文和代码库常常在两种截然不同的“语言”之间切换。一边是描述量子线路的狄拉克符号、酉矩…...