YOLOv8优化与量化(1000+ FPS性能)
YOLO家族又添新成员了!作为目标检测领域著名的模型家族,you only look once (YOLO) 推 出新模型的速度可谓是越来越快。就在刚刚过去的1月份,YOLO又推出了最新的YOLOv8模型,其模型结构和架构上的创新以及所提供的性能提升,使得它刚刚面世,就获得了广大开发者的关注。
YOLOv8的性能到底怎么样?如果说利用OpenVINO™的量化和加速,利用英特尔®CPU、集成显卡以及独立显卡与同一代码库无缝协作,可以获得1000+ FPS的性能,你相信吗?那不妨继续往下看,我们将手把手的教你在利用OpenVINO™在英特尔®处理器上实现这一性能。

好的,让我们开始吧。
注意:以下步骤中的所有代码来自OpenVINO Notebooks开源仓库中的230-yolov8-optimization notebook 代码示例,您可以点击以下链接直达源代码。openvino_notebooks/230-yolov8-optimization.ipynb at main · openvinotoolkit/openvino_notebooks · GitHub
第一步: 安装相应工具包及加载模型
本次代码示例我们使用的是Ultralytics YOLOv8模型,因此需要首先安装相应工具包。
!pip install "ultralytics==8.0.5"然后下载及加载相应的PyTorch模型。
1. from ultralytics import YOLO2.3. MODEL_NAME = "yolov8n"4. model = YOLO(f'{MODEL_NAME}.pt')5. label_map = model.model.names定义测试图片的地址,获得原始PyTorch模型的推理结果
1. IMAGE_PATH = "../data/image/coco_bike.jpg"2. results = model(IMAGE_PATH, return_outputs=True)其运行效果如下

为将目标检测的效果以可视化的形式呈现出来,需要定义相应的函数,最终运行效果如下图所示

第二步: 将模型转换为OpenVINO IR格式
为获得良好的模型推理加速,并更方便的部署在不同的硬件平台上,接下来我们首先将YOLO v8模型转换为OpenVINO IR模型格式。YOLOv8提供了用于将模型导出到不同格式(包括OpenVINO IR格式)的API。model.export负责模型转换。我们需要在这里指定格式,此外,我们还可以在模型中保留动态输入。
1. from pathlib import Path2.3. model_path = Path(f"{MODEL_NAME}_openvino_model/{MODEL_NAME}.xml")4. if not model_path.exists():5. model.export(format="openvino", dynamic=True, half=False)接下来我们来测试一下转换后模型的准确度如何。运行以下代码,并定义相应的前处理、后处理函数,
1. from openvino.runtime import Core, Model2.3. core = Core()4. ov_model = core.read_model(model_path)5. device = "CPU" # GPU6. if device != "CPU":7. ov_model.reshape({0: [1, 3, 640, 640]})8. compiled_model = core.compile_model(ov_model, device)在单张测试图片上进行推理,可以得到如下推理结果

第三步: 在数据集上验证模型准确度
YOLOv8是在COCO数据集上进行预训练的,因此为了评估模型的准确性,我们需要下载该数据集。根据YOLOv8 GitHub仓库中提供的说明,我们还需要下载模型作者使用的格式的标注,以便与原始模型评估功能一起使用。
1. import sys2. from zipfile import ZipFile3.4. sys.path.append("../utils")5. from notebook_utils import download_file6.7. DATA_URL = "http://images.cocodataset.org/zips/val2017.zip"8. LABELS_URL = "https://github.com/ultralytics/yolov5/releases/download/v1.0/coco2017labels-segments.zip"9.10. OUT_DIR = Path('./datasets')11.12. download_file(DATA_URL, directory=OUT_DIR, show_progress=True)13. download_file(LABELS_URL, directory=OUT_DIR, show_progress=True)14.15. if not (OUT_DIR / "coco/labels").exists():16. with ZipFile(OUT_DIR / 'coco2017labels-segments.zip' , "r") as zip_ref:17. zip_ref.extractall(OUT_DIR)18. with ZipFile(OUT_DIR / 'val2017.zip' , "r") as zip_ref:19. zip_ref.extractall(OUT_DIR / 'coco/images')接下来,我们配置DetectionValidator并创建DataLoader。原始模型存储库使用DetectionValidator包装器,它表示精度验证的过程。它创建DataLoader和评估标准,并更新DataLoader生成的每个数据批的度量标准。此外,它还负责数据预处理和结果后处理。对于类初始化,应提供配置。我们将使用默认设置,但可以用一些参数替代,以测试自定义数据,代码如下。
1. from ultralytics.yolo.utils import DEFAULT_CONFIG2. from ultralytics.yolo.configs import get_config3. args = get_config(config=DEFAULT_CONFIG)4. args.data = "coco.yml"5. validator = model.ValidatorClass(args)6. data_loader = validator.get_dataloader("datasets/coco", 1)Validator配置代码如下
1. from tqdm.notebook import tqdm2. from ultralytics.yolo.utils.metrics import ConfusionMatrix3.4. validator.is_coco = True5. validator.class_map = ops.coco80_to_coco91_class()6. validator.names = model.model.names7. validator.metrics.names = validator.names8. validator.nc = model.model.model[-1].nc定义验证函数,以及打印相应测试结果的函数,结果如下

第四步: 利用NNCF POT 量化 API进行模型优化
Neural network compression framework (NNCF) 为OpenVINO中的神经网络推理优化提供了一套先进的算法,精度下降最小。我们将在后训练(Post-training)模式中使用8位量化(无需微调)来优化YOLOv8。
优化过程包括以下三个步骤:
- 建立量化数据集Dataset;
- 运行nncf.quantize来得到优化模型
- 使用串行化函数openvino.runtime.serialize来得到OpenVINO IR模型。
建立量化数据集代码如下
1. import nncf # noqa: F8112. from typing import Dict3.4.5. def transform_fn(data_item:Dict):6. """7. Quantization transform function. Extracts and preprocess input data from dataloader item for quantization.8. Parameters:9. data_item: Dict with data item produced by DataLoader during iteration10. Returns:11. input_tensor: Input data for quantization12. """13. input_tensor = validator.preprocess(data_item)['img'].numpy()14. return input_tensor15.16.17. quantization_dataset = nncf.Dataset(data_loader, transform_fn)运行nncf.quantize代码如下
1. quantized_model = nncf.quantize(2. ov_model,3. quantization_dataset,4. preset=nncf.QuantizationPreset.MIXED,5. ignored_scope=nncf.IgnoredScope(6. types=["Multiply", "Subtract", "Sigmoid"], # ignore operations7. names=["/model.22/dfl/conv/Conv", # in the post-processing subgraph8. "/model.22/Add",9. "/model.22/Add_1",10. "/model.22/Add_2",11. "/model.22/Add_3",12. "/model.22/Add_4",13. "/model.22/Add_5",14. "/model.22/Add_6",15. "/model.22/Add_7",16. "/model.22/Add_8",17. "/model.22/Add_9",18. "/model.22/Add_10"]19. ))最终串行化函数代码如下
1. from openvino.runtime import serialize2. int8_model_path = Path(f'{MODEL_NAME}_openvino_int8_model/{MODEL_NAME}.xml')3. print(f"Quantized model will be saved to {int8_model_path}")4. serialize(quantized_model, str(int8_model_path))运行后得到的优化的YOLOv8模型保存在以下路径
yolov8n_openvino_int8_model/yolov8n.xml
接下来,运行以下代码在单张测试图片上验证优化模型的推理结果
1. if device != "CPU":2. quantized_model.reshape({0, [1, 3, 640, 640]})3. quantized_compiled_model = core.compile_model(quantized_model, device)4. input_image = np.array(Image.open(IMAGE_PATH))5. detections = detect(input_image, quantized_compiled_model)[0]6. image_with_boxes = draw_boxes(detections, input_image)7.8. Image.fromarray(image_with_boxes)运行结果如下

验证下优化后模型的精度,运行如下代码:
1. print("FP32 model accuracy")2. print_stats(fp_stats, validator.seen, validator.nt_per_class.sum())3.4. print("INT8 model accuracy")5. print_stats(int8_stats, validator.seen, validator.nt_per_class.sum())得到结果如下:

可以看到模型精度相较于优化前,并没有明显的下降。
第五步: 比较优化前后模型的性能
接着,我们利用OpenVINO 基线测试工具Benchmark Python Tool — OpenVINO™ documentation 来比较优化前(FP32)和优化后(INT8)模型的性能。在这里,我们分别在英特尔®至强®第三代处理器(Xeon Ice Lake Gold Intel 6348 2.6 GHz 42 MB 235W 28 cores)上运行CPU端的性能比较。针对优化前模型的测试代码和运行结果如下
1. # Inference FP32 model (OpenVINO IR)2. !benchmark_app -m $model_path -d CPU -api async -shape "[1,3,640,640]"FP32模型性能:
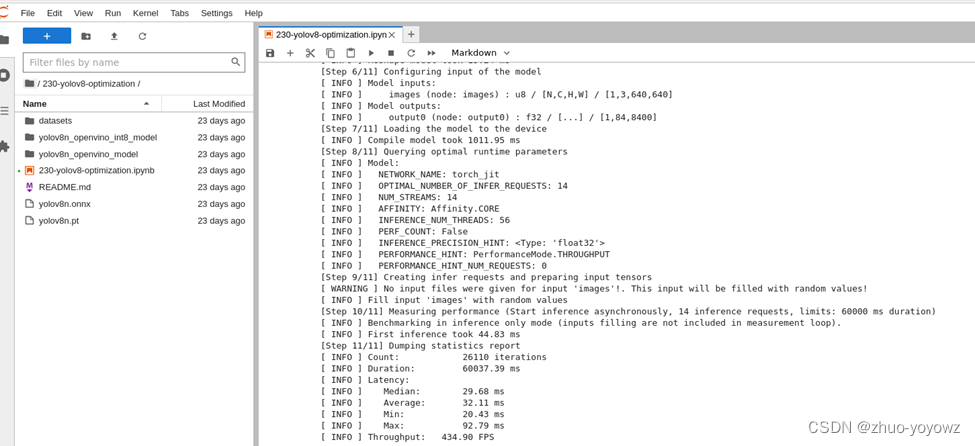
INT8模型性能:
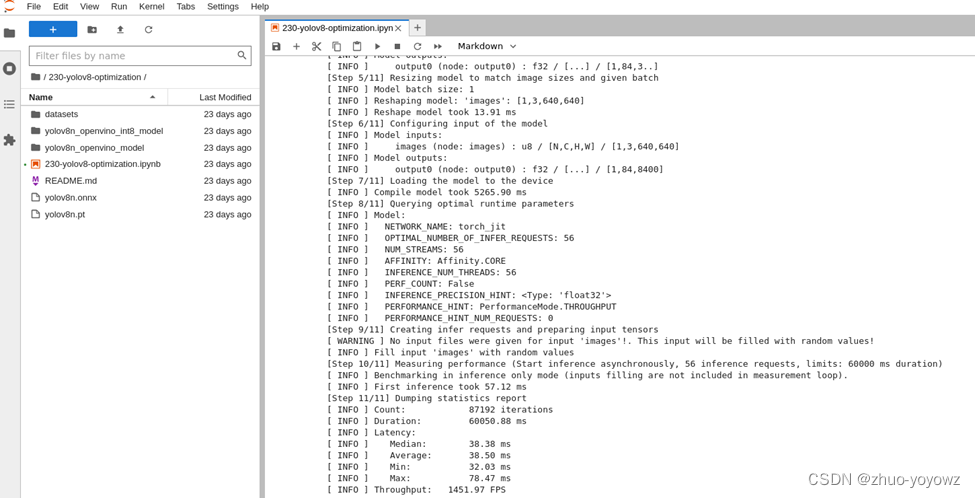
已经达到了1400+ FPS!
在英特尔®独立显卡上的性能又如何呢?我们在Arc™ A770m上测试效果如下:
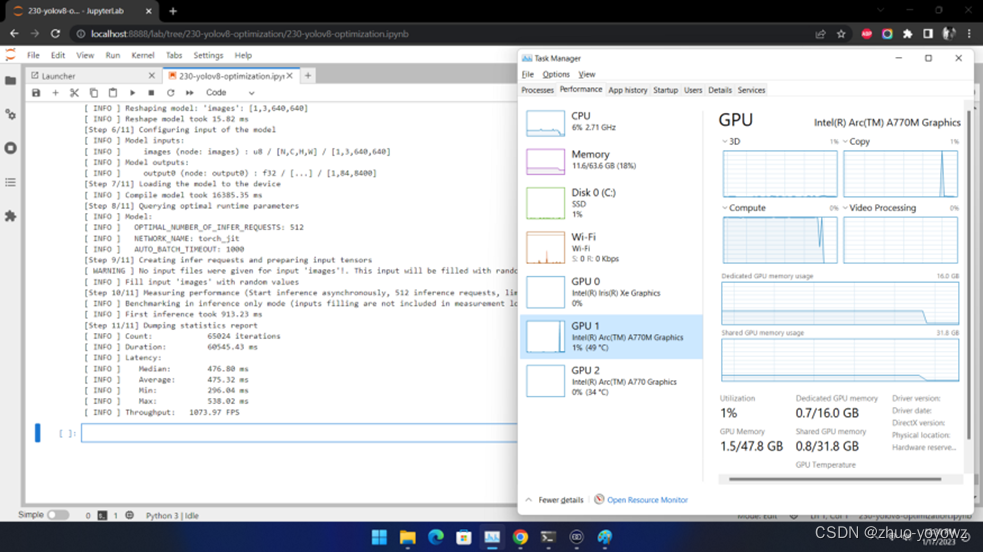
也超过了1000 FPS!
需要注意的是要想获得如此的高性能,需要将推理运行在吞吐量模式下,并使用多流和多个推理请求(即并行运行多个)。同样,仍然需要确保对预处理和后处理管道进行微调,以确保没有性能瓶颈。
第六步: 利用网络摄像头运行实时测试
除了基线测试工具外,如果你想利用自己的网络摄像头,体验一下实时推理的效果,可以运行我们提供的实时运行目标检测函数
1. run_object_detection(source=0, flip=True, use_popup=False, model=ov_model, device="AUTO")第七步: 进一步提升性能的小技巧
- 非同步推理流水线 :在进行目标检测的推理时,推理性能常常会因为数据输入量的限制而受到影响。此时,采用异步推理的模型,可以进一步提升推理的性能。异步API的主要优点是,当设备忙于推理时,应用程序可以并行执行其他任务(例如填充输入或调度其他请求),而不是等待当前推理首先完成。要了解如何使用openvino执行异步推理,请参阅AsyncAPI教程https://github.com/openvinotoolkit/openvino_notebooks/blob/97f25b16970b6fe2287ca47bba64f31cff98e795/notebooks/115-async-api/115-async-api.ipynb
- 使用预处理API: 预处理API允许将预处理作为模型的一部分,从而减少应用程序代码和对其他图像处理库的依赖。预处理API的主要优点是将预处理步骤集成到执行图中,并将在选定的设备(CPU/GPU/VPU/等)上执行,而不是作为应用程序的一部分始终在CPU上执行。这将提高所选设备的利用率。更详细的预处理API信息,请参阅预处理教程 Optimize Preprocessing — OpenVINO™ documentation 。
对于本次YOLOv8示例来说,预处理API的使用包含以下几个步骤:
- 初始化PrePostProcessing对象
1. from openvino.preprocess import PrePostProcessor2.3. ppp = PrePostProcessor(quantized_model)2. 定义输入数据格式
1. from openvino.runtime import Type, Layout2.3. ppp.input(0).tensor().set_shape([1, 640, 640, 3]).set_element_type(Type.u8).set_layout(Layout('NHWC'))4. pass3. 描述预处理步骤
预处理步骤主要包括以下三步:
- 将数据类型从U8转换为FP32
- 将数据布局从NHWC转换为NCHW格式
- 通过按比例因子255进行除法来归一化每个像素
代码如下:
1. ppp.input(0).preprocess().convert_element_type(Type.f32).convert_layout(Layout('NCHW')).scale([255., 255., 255.])2.3. print(ppp)4. 将步骤集成到模型中
1. quantized_model_with_preprocess = ppp.build()2. serialize(quantized_model_with_preprocess, str(int8_model_path.with_name(f"{MODEL_NAME}_with_preprocess.xml")))具有集成预处理的模型已准备好加载到设备。现在,我们可以跳过检测函数中的这些预处理步骤,直接运行如下推理
1. def detect_without_preprocess(image:np.ndarray, model:Model):2. """3. OpenVINO YOLOv8 model with integrated preprocessing inference function. Preprocess image, runs model inference and postprocess results using NMS.4. Parameters:5. image (np.ndarray): input image.6. model (Model): OpenVINO compiled model.7. Returns:8. detections (np.ndarray): detected boxes in format [x1, y1, x2, y2, score, label]9. """10. output_layer = model.output(0)11. img = letterbox(image)[0]12. input_tensor = np.expand_dims(img, 0)13. input_hw = img.shape[:2]14. result = model(input_tensor)[output_layer]15. detections = postprocess(result, input_hw, image)16. return detections17.18.19. compiled_model = core.compile_model(quantized_model_with_preprocess, device)20. input_image = np.array(Image.open(IMAGE_PATH))21. detections = detect_without_preprocess(input_image, compiled_model)[0]22. image_with_boxes = draw_boxes(detections, input_image)23.24. Image.fromarray(img_with_boxes)由此推理速度又能进一步得到提升啦。
总结:
整个的步骤就是这样!现在就开始跟着我们提供的代码和步骤,动手试试用Open VINO™ 优化和加速YOLOv8吧。
优化和加速YOLOv8吧。
关于英特尔OpenVINOTM开源工具套件的详细资料,包括其中我们提供的三百多个经验证并优化的预训练模型的详细资料,请您点击https://www.intel.com/content/www/us/en/developer/tools/openvino-toolkit/overview.html
除此之外,为了方便大家了解并快速掌握OpenVINOTM的使用,我们还提供了一系列开源的Jupyter notebook demo。运行这些notebook,就能快速了解在不同场景下如何利用OpenVINOTM实现一系列、包括计算机视觉、语音及自然语言处理任务。OpenVINOTM notebooks的资源可以在Github这里下载安装:https://github.com/openvinotoolkit/openvino_notebooks 。
相关文章:
YOLOv8优化与量化(1000+ FPS性能)
YOLO家族又添新成员了!作为目标检测领域著名的模型家族,you only look once (YOLO) 推 出新模型的速度可谓是越来越快。就在刚刚过去的1月份,YOLO又推出了最新的YOLOv8模型,其模型结构和架构上的创新以及所提供的性能提升…...

python urllib open 头部信息错误
header 有些字符在 lighttpd server 中无法正常解析,需要转换 quteo 可以转换 就跨平台而言,Rust 和 python 一样优秀,看了在stm32 上使用 Rust 进行编程,从一定程度上,而言,稳定和安全性要比C 开发的好的多,说出来可能不信,在单片机上是可以对空指针进行…...
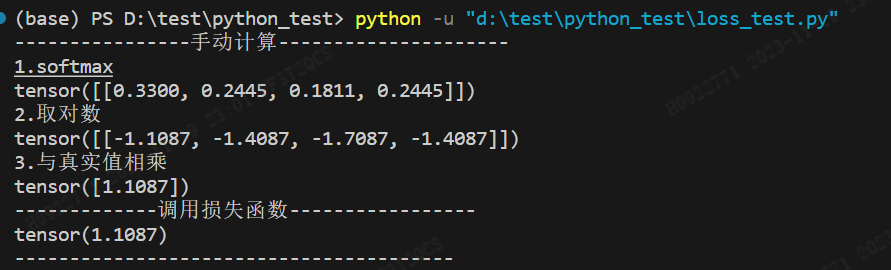
nn.KLDivLoss,nn.CrossEntropyLoss,nn.MSELoss,Focal_Loss
KL loss:https://blog.csdn.net/qq_50001789/article/details/128974654 https://pytorch.org/docs/stable/nn.html 1. nn.L1Loss 1.1 公式 L1Loss: 计算预测 x和 目标y之间的平均绝对值误差MAE, 即L1损失: l o s s 1 n ∑ i 1 , . . . n ∣ x i…...
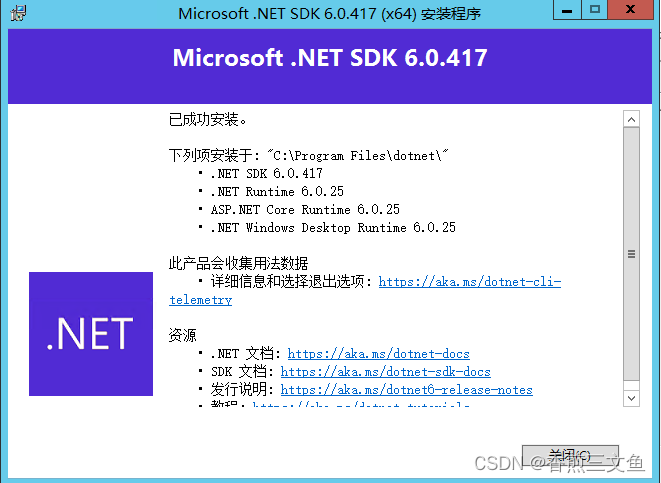
HTTP Error 500.31 - Failed to load ASP.NET Core runtime
在winserver服务器上部署net6应用后,访问接口得到以下提示: 原因是因为没有安装net6的运行时和环境,我们可以在windows自带的 “事件查看器” 查看原因。 可以直接根据给出的地址去官网下载sdk环境,安装即可 下载对应的net版本…...
2023.11.17 关于 Spring Boot 日志文件
目录 日志文件作用 常见的日志框架说明 门面模式 日志的使用 日志的级别 六种级别 日志级别的设置 日志的持久化 使用 Lombok 输出日志 实现原理 普通打印和日志的区别 日志文件作用 记录 错误日志 和 警告日志(发现和定位问题)记录 用户登录…...

【框架整合】Redis限流方案
1、Redis实现限流方案的核心原理: redis实现限流的核心原理在于redis 的key 过期时间,当我们设置一个key到redis中时,会将key设置上过期时间,这里的实现是采用lua脚本来实现原子性的。2、准备 引入相关依赖 <dependency>…...
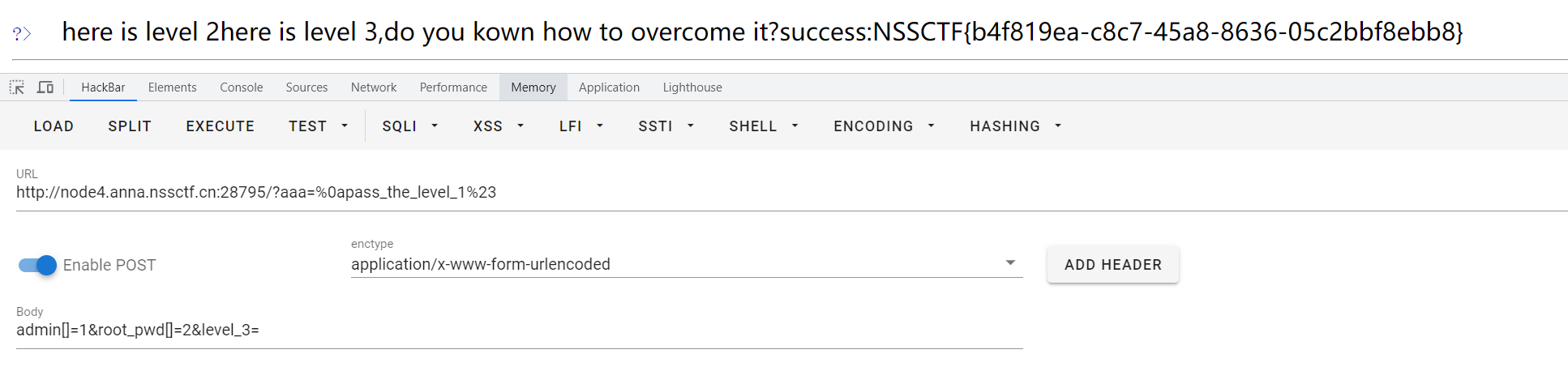
NSS [鹤城杯 2021]Middle magic
NSS [鹤城杯 2021]Middle magic 源码直接给了。 粗略一看,一共三个关卡 先看第一关: if(isset($_GET[aaa]) && strlen($_GET[aaa]) < 20){$aaa preg_replace(/^(.*)level(.*)$/, ${1}<!-- filtered -->${2}, $_GET[aaa]);if(preg_m…...
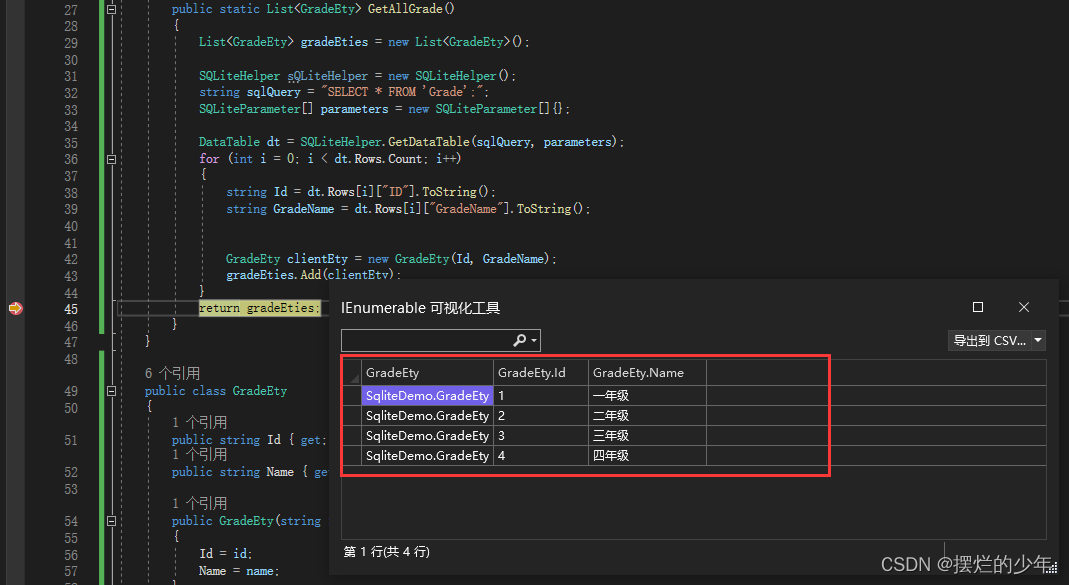
Sqlite安装配置及使用
一、下载SQLite Sqlite官网 我下载的是3370000版本:sqlite-dll-win64-x64-3370000.zip 和 sqlite-tools-win32-x86-3370000.zip 二、解压下载的两个压缩包 三、配置环境 四、检查是否安装配置成功 winR:输入cmd调出命令窗口,输入sqlite3后回车查看s…...
(点估计))
参数估计(一)(点估计)
文章目录 点估计和估计量的求法点估计概念矩估计法极大似然估计法 参考文献 参数估计是数理统计中重要的基本问题之一。通常,称参数的可容许值的全体为参数空间,并记为 Θ \Theta Θ。所谓参数估计就是由样本对总体分布所含的未知参数做出估计。另外&am…...
kubenetes-服务发现和负载均衡
一、服务发布 kubenetes把服务发布至集群内部或者外部,服务的三种不同类型: ClusterlPNodePortLoadBalancer ClusterIP是发布至集群内部的一个虚拟IP,通过负载均衡技术转发到不同的pod中。 NodePort解决的是集群外部访问的问题,用户可能不…...
docker的基本使用以及使用Docker 运行D435i
1.一些基本的指令 1.1 容器 要查看正在运行的容器: sudo docker ps 查看所有的容器(包括停止状态的容器) sudo docker ps -a 重新命名容器 sudo docker rename <old_name> <new_name> <old_name> 替换为你的容器名称…...
如何看待人工智能行业发展
随着人工智能技术的飞速发展,这个领域的就业前景也日益广阔。人工智能在各行各业都有广泛的应用,包括医疗、金融、制造业、教育等。因此,对于想要追求高薪、高技能职业的人来说,学习人工智能是一个非常有前景的选择。 首先&#x…...

linux中实现自己的bash
🐶博主主页:ᰔᩚ. 一怀明月ꦿ ❤️🔥专栏系列:线性代数,C初学者入门训练,题解C,C的使用文章,「初学」C 🔥座右铭:“不要等到什么都没有了,才下…...

14 Go的类型转换
概述 在上一节的内容中,我们介绍了Go的错误处理,包括:errors包、返回错误、抛出异常、捕获异常等。在本节中,我们将介绍Go的类型转换。在Go语言中,类型转换是一种将一个值从一种类型转换为另一种类型的过程。类型转换主…...
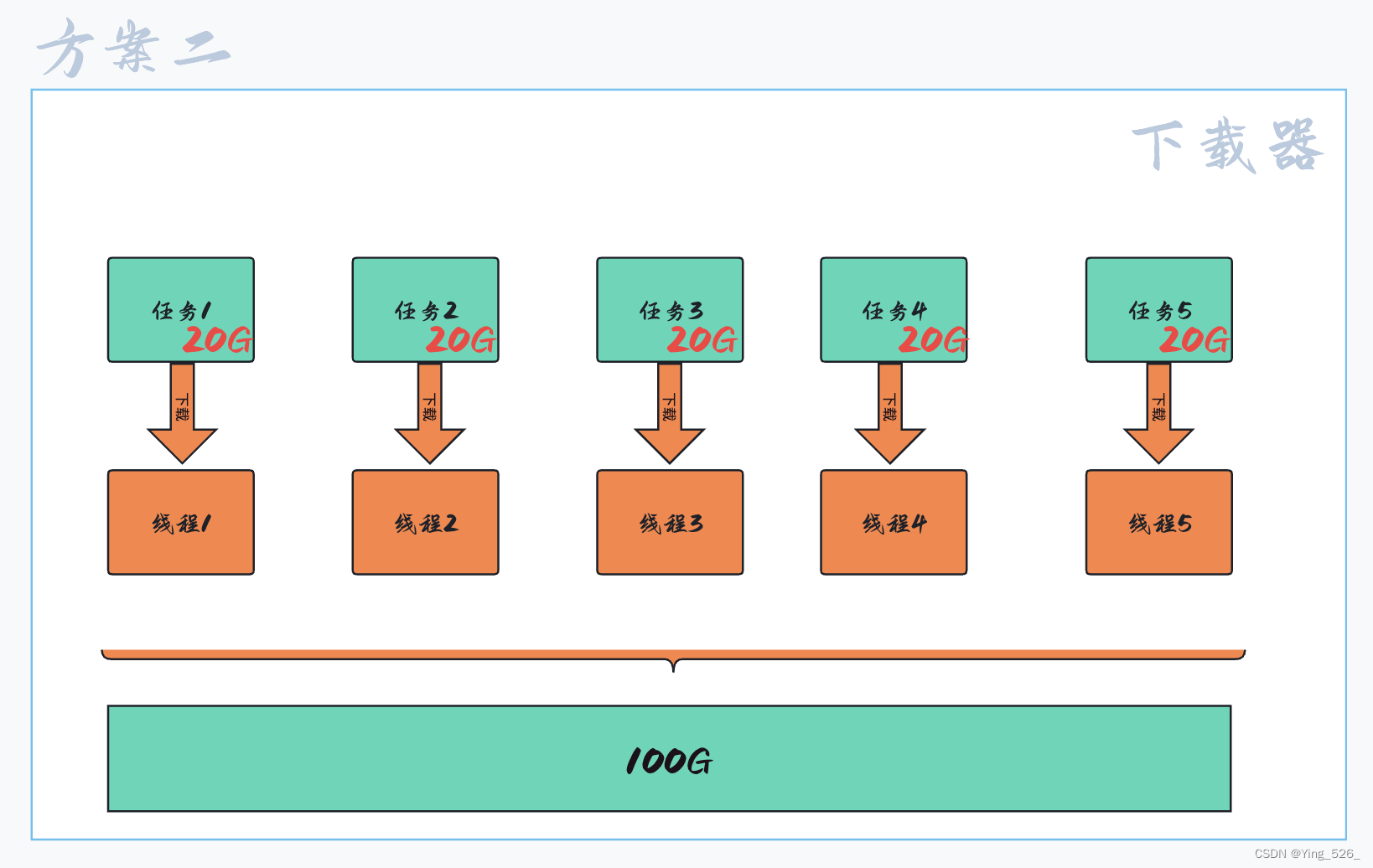
多线程概述
文章目录 线程是什么线程有什么作用线程和进程的区别多线程相较于进程优势 在Java这个圈子中,多进程用的并不多,因为进程是一个重量级操作,进程是资源分配的基本单位,申请资源是一个比较消耗时间的操作. 线程是什么 线程是一个独立的执行流,可以被独立调度到CPU上执行 线程是…...

AR贴纸特效SDK,无缝贴合的虚拟体验
增强现实(AR)技术已经成为了企业和个人开发者的新宠。它通过将虚拟元素与现实世界相结合,为用户提供了一种全新的交互体验。然而,如何将AR贴纸完美贴合在人脸的面部,同时支持多张人脸的检测和标点及特效添加࿰…...

Leetcode hot 100
双指针 283.移动零 class Solution { public:void moveZeroes(vector<int>& nums) {int cnt 0;for(vector<int>::iterator it nums.begin(); it ! nums.end(); ){if(*it 0) it nums.erase(it),cnt;else it;}while(cnt--){nums.push_back(0);}} }; 11.盛…...

分类预测 | Matlab实现基于SDAE堆叠去噪自编码器的数据分类预测
分类预测 | Matlab实现基于SDAE堆叠去噪自编码器的数据分类预测 目录 分类预测 | Matlab实现基于SDAE堆叠去噪自编码器的数据分类预测分类效果基本描述程序设计参考资料 分类效果 基本描述 1.Matlab实现基于SDAE堆叠去噪自编码器的数据分类预测(完整源码和数据) 2.多…...
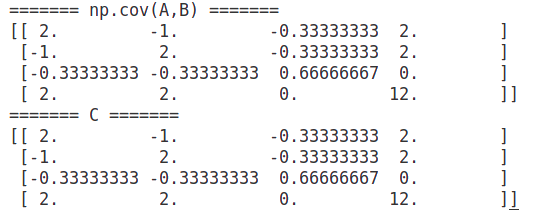
矩阵运算_矩阵的协方差矩阵/两个矩阵的协方差矩阵_求解详细步骤示例
1. 协方差矩阵定义 在统计学中,方差是用来度量单个随机变量的离散程度,而协方差则一般用来刻画两个随机变量的相似程度。 参考: 带你了解什么是Covariance Matrix协方差矩阵 - 知乎 2. 协方差矩阵计算过程 将输入数据A进行中心化处理得到A…...
——第108天:Pyecharts绘制多种炫酷词云图参数说明+代码实战)
100天精通Python(可视化篇)——第108天:Pyecharts绘制多种炫酷词云图参数说明+代码实战
文章目录 专栏导读一、词云图介绍1. 词云图是什么?2. 词云图应用场景?二、参数说明1. 导包2. add函数三、词云库实战1. 基础词云图2. 矩形词云图3. 三角形词云图4. 菱形词云图5. 自定义图片词云图书籍推荐专栏导读 🔥🔥本文已收录于《100天精通Python从入门到就业》:本…...

终极指南:Windows上无需模拟器安装APK文件的完整教程
终极指南:Windows上无需模拟器安装APK文件的完整教程 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为在Windows电脑上安装安卓应用而烦恼吗ÿ…...

告别手动字幕!3步用VideoSrt实现视频自动字幕生成
告别手动字幕!3步用VideoSrt实现视频自动字幕生成 【免费下载链接】video-srt-windows 这是一个可以识别视频语音自动生成字幕SRT文件的开源 Windows-GUI 软件工具。 项目地址: https://gitcode.com/gh_mirrors/vi/video-srt-windows 还在为视频字幕制作而烦…...

RDP Wrapper:免费解锁Windows家庭版多用户远程桌面功能
RDP Wrapper:免费解锁Windows家庭版多用户远程桌面功能 【免费下载链接】rdpwrap RDP Wrapper Library 项目地址: https://gitcode.com/gh_mirrors/rd/rdpwrap RDP Wrapper Library是一个创新的开源项目,专为Windows家庭版和基础版用户提供完整的…...

终极解决方案:3步恢复Calibre-Web豆瓣元数据获取功能
终极解决方案:3步恢复Calibre-Web豆瓣元数据获取功能 【免费下载链接】calibre-web-douban-api 新版calibre-web已经移除douban-api了,添加一个豆瓣api实现 项目地址: https://gitcode.com/gh_mirrors/ca/calibre-web-douban-api 还在为Calibre-W…...

Poppins字体终极指南:免费获取9种字重+天城文支持的多语言解决方案
Poppins字体终极指南:免费获取9种字重天城文支持的多语言解决方案 【免费下载链接】Poppins Poppins, a Devanagari Latin family for Google Fonts. 项目地址: https://gitcode.com/gh_mirrors/po/Poppins 还在为多语言项目寻找完美的字体吗?Po…...

Armv8-M安全系统中中断优先级分配策略
1. Armv8-M处理器中安全操作系统为何需要保留最低两个中断优先级 在基于Armv8-M架构的嵌入式系统开发中,中断优先级分配是一个需要精心设计的环节。特别是当系统采用TrustZone技术划分安全域(Secure Domain)和非安全域(Non-secure…...

大语言模型提示工程优化:精准解决机器翻译中的零代词恢复难题
1. 项目概述:当大语言模型遇上机器翻译的“隐形主语”在机器翻译的日常工程实践中,我们常常会遇到一个看似微小却影响深远的“幽灵”问题:零代词。尤其是在处理像中文到英文这类语言差异巨大的翻译任务时,这个问题尤为突出。中文讲…...

Frida Hook Java层还原Android客户端签名算法
1. 这不是“调用API”,而是拆解签名生成的完整逻辑链 你有没有遇到过这种情况:App每次请求都带一个叫 api-sign 的字段,值像一串随机字符串,长度固定、格式规整,但无论你怎么翻网络请求日志、抓包重放、甚至改参数重…...

iKuai系统安装踩坑实录:从‘找不到启动项’到成功引导,我的EFI/U盘避坑全记录
iKuai系统安装避坑指南:从EFI配置到BIOS设置的深度解析第一次尝试在x86设备上安装iKuai软路由系统时,我遇到了一个令人抓狂的问题——制作好的U盘启动盘竟然无法被电脑识别。屏幕上冷冰冰的"No bootable device found"提示,让原本简…...

不确定性量化神经网络:从海平面预测到状态依赖可预测性物理机制挖掘
1. 项目概述:用不确定性量化神经网络“透视”海平面预测的奥秘在气候与海洋研究的前沿,预测未来几天到几个月内的海平面变化,一直是个让人又爱又恨的难题。爱的是,准确的预测能直接服务于沿海城市的防洪预警、港口运营和生态保护&…...