参数估计(一)(点估计)
文章目录
- 点估计和估计量的求法
- 点估计概念
- 矩估计法
- 极大似然估计法
- 参考文献
参数估计是数理统计中重要的基本问题之一。通常,称参数的可容许值的全体为参数空间,并记为 Θ \Theta Θ。所谓参数估计就是由样本对总体分布所含的未知参数做出估计。另外,在有些实际问题中,由于事先并不知道总体 X X X 的分布类型,而要对其某些数字特征,如均值、方差等做出估计,习惯上也把这些数字特征称为参数,对它们进行估计也属于参数估计范畴。
点估计和估计量的求法
点估计概念
设总体 X X X 的分布函数是 F ( x ; θ 1 , . . . , θ l ) F(x;\theta_1,...,\theta_l) F(x;θ1,...,θl),其中 θ 1 , . . . , θ l \theta_1,...,\theta_l θ1,...,θl 是未知参数, X 1 , . . . , X n X_1,...,X_n X1,...,Xn 是来自总体 X X X 的样本, x 1 , . . . , x n x_1,...,x_n x1,...,xn 是相应的样本值,参数点估计就是研究如何构造适当的统计量 θ ^ i ( X 1 , . . . , X n ) \hat{\theta}_i(X_1,...,X_n) θ^i(X1,...,Xn),并分别用观察值 θ ^ i ( x 1 , . . . , x n ) \hat{\theta}_i(x_1,...,x_n) θ^i(x1,...,xn) 作为未知参数 θ i \theta_i θi 的估计。
通常,称用作估计的统计量 θ ^ i ( X 1 , . . . , X n ) \hat{\theta}_i(X_1,...,X_n) θ^i(X1,...,Xn) 为估计量,称其观察值 θ ^ i ( x 1 , . . . , x n ) \hat{\theta}_i(x_1,...,x_n) θ^i(x1,...,xn) 为估计值。
由于对不同的样本值,得到的参数估计值往往不同,因此,点估计问题的关键在于构造估计量的方法。下面介绍求估计量的一些常用方法。
矩估计法
设总体 X X X 的分布中含有 l l l 个未知参数 θ 1 , . . . , θ l \theta_1,...,\theta_l θ1,...,θl,又设总体 X X X 的前 l l l 阶原点矩 α k = E ( X k ) ( k = 1 , . . . , l ) \alpha_k=E(X^k)(k=1,...,l) αk=E(Xk)(k=1,...,l) 存在,且是 θ 1 , . . . , θ l \theta_1,...,\theta_l θ1,...,θl 的函数,即 α k = α k ( θ 1 , . . . , θ l ) \alpha_k=\alpha_k(\theta_1,...,\theta_l) αk=αk(θ1,...,θl),令
α k ( θ ^ 1 , . . . , θ ^ l ) = A k , k = 1 , . . . , l \alpha_k(\hat{\theta}_1,...,\hat{\theta}_l)=A_k,\quad k=1,...,l αk(θ^1,...,θ^l)=Ak,k=1,...,l
解此方程组可得 θ ^ 1 , . . . , θ ^ l \hat{\theta}_1,...,\hat{\theta}_l θ^1,...,θ^l,并将它们分别作为 θ 1 , . . . , θ l \theta_1,...,\theta_l θ1,...,θl 的估计量。这种求估计量的方法称为矩估计法,用矩估计法求得的估计量称为矩估计量。
例:设总体 X X X 的二阶矩存在, X 1 , . . . , X n X_1,...,X_n X1,...,Xn 为总体 X X X 的样本,求总体均值 μ \mu μ 与总体方差 σ 2 \sigma^2 σ2 的矩估计。
解:因 α 1 = μ , α 2 = σ 2 + μ 2 \alpha_1=\mu, \alpha_2=\sigma^2+\mu^2 α1=μ,α2=σ2+μ2,令 { μ ^ = A 1 = X ˉ σ ^ 2 + μ ^ 2 = A 2 = 1 n ∑ i = 1 n X i 2 \begin{cases} \hat{\mu}=A_1=\bar{X} \\ \hat{\sigma}^2+\hat{\mu}^2=A_2=\frac{1}{n}\sum_{i=1}^n X_i^2 \end{cases} {μ^=A1=Xˉσ^2+μ^2=A2=n1∑i=1nXi2
解得 μ \mu μ 与 σ 2 \sigma^2 σ2 的矩估计分别为
μ ^ = X ˉ \hat{\mu}=\bar{X} μ^=Xˉ σ ^ 2 = A 2 − X ˉ 2 = S 2 \hat{\sigma}^2=A_2-\bar{X}^2=S^2 σ^2=A2−Xˉ2=S2
极大似然估计法
以下用 X = ( X 1 , . . . , X n ) T \boldsymbol{X}=(X_1,...,X_n)^T X=(X1,...,Xn)T 表示样本, x = ( x 1 , . . . , x n ) T \boldsymbol{x}=(x_1,...,x_n)^T x=(x1,...,xn)T 表示样本点, f ( x ; θ ) f(\boldsymbol{x};\theta) f(x;θ) 表示样本分布。
极大似然法的提出是基于如下的想法:
当给定 θ \theta θ 时, f ( x ; θ ) f(\boldsymbol{x};\theta) f(x;θ) 度量样本 X \boldsymbol{X} X 在 x \boldsymbol{x} x 点发生的可能性。对于样本空间中的两个不同样本点 x 1 , x 2 ∈ X \boldsymbol{x}_1, \boldsymbol{x}_2 \in \mathcal{X} x1,x2∈X,如果有 f ( x 1 ; θ ) > f ( x 2 ; θ ) f(\boldsymbol{x}_1;\theta) > f(\boldsymbol{x}_2;\theta) f(x1;θ)>f(x2;θ),自然会认为样本 X \boldsymbol{X} X 更可能在 x 1 \boldsymbol{x}_1 x1 点发生。
现在换个角度来看待 f ( x ; θ ) f(\boldsymbol{x};\theta) f(x;θ)。当给定样本点 x \boldsymbol{x} x 时,对参数空间中的两个不同参数 θ 1 , θ 2 ∈ Θ \theta_1,\theta_2 \in \Theta θ1,θ2∈Θ,如果有 f ( x ; θ 1 ) > f ( x ; θ 2 ) f(\boldsymbol{x};\theta_1) > f(\boldsymbol{x};\theta_2) f(x;θ1)>f(x;θ2),那么会认为样本点 x \boldsymbol{x} x 更像是来自总体 f ( X ; θ 1 ) f(\boldsymbol{X};\theta_1) f(X;θ1),所以,数 f ( x ; θ ) f(\boldsymbol{x};\theta) f(x;θ) 的大小可作为参数 θ \theta θ 对产生样本观察值 x \boldsymbol{x} x 有多大似然性的一种度量。
当给定样本点 x \boldsymbol{x} x 时,称 f ( x ; θ ) f(\boldsymbol{x};\theta) f(x;θ) 为 θ \theta θ 的似然函数,记为 L ( θ ; x ) L(\theta;\boldsymbol{x}) L(θ;x),即
L ( θ ; x ) = f ( x ; θ ) = { ∏ i = 1 n p ( x i ; θ ) , 总体 X 为离散型随机变量 ∏ i = 1 n f ( x i ; θ ) , 总体 X 为连续型随机变量 L(\theta;\boldsymbol{x})=f(\boldsymbol{x};\theta)=\begin{cases} \prod_{i=1}^np(x_i;\theta), & 总体 X 为离散型随机变量 \\ \prod_{i=1}^nf(x_i;\theta), & 总体 X 为连续型随机变量 \end{cases} L(θ;x)=f(x;θ)={∏i=1np(xi;θ),∏i=1nf(xi;θ),总体X为离散型随机变量总体X为连续型随机变量
而称 ln f ( x ; θ ) \ln f(\boldsymbol{x};\theta) lnf(x;θ) 为对数似然函数,记为 ln L ( θ ; x ) \ln L(\theta;\boldsymbol{x}) lnL(θ;x)。
若有统计量 θ ^ ≏ θ ^ ( X ) \hat{\theta}\bumpeq \hat{\theta}(\boldsymbol{X}) θ^≏θ^(X),使得
L ( θ ^ ( x ) ; x ) = sup θ ∈ Θ { L ( θ ; x ) } L(\hat{\theta}(\boldsymbol{x});\boldsymbol{x})=\sup_{\theta \in \Theta}\{L(\theta;\boldsymbol{x})\} L(θ^(x);x)=θ∈Θsup{L(θ;x)}
或等价的,使得
ln L ( θ ^ ( x ) ; x ) = sup θ ∈ Θ { ln L ( θ ; x ) } \ln L(\hat{\theta}(\boldsymbol{x});\boldsymbol{x})=\sup_{\theta \in \Theta}\{\ln L(\theta;\boldsymbol{x})\} lnL(θ^(x);x)=θ∈Θsup{lnL(θ;x)}
则称 θ ^ ( X ) \hat{\theta}(\boldsymbol{X}) θ^(X) 为参数 θ \theta θ 的极大似然估计量(Maximum Likelihood Estimators, MLE)。
例:设总体 X ∼ P ( λ ) , λ > 0 X \sim P(\lambda),\lambda>0 X∼P(λ),λ>0,试求参数 λ \lambda λ 的极大似然估计量。
解: X X X 的概率函数为
P { X = x } = λ x x ! e − λ , x = 0 , 1 , 2 , . . . P\{X=x\}=\frac{\lambda^x}{x!}e^{-\lambda},\quad x=0,1,2,... P{X=x}=x!λxe−λ,x=0,1,2,...
故 λ \lambda λ 的似然函数为
L ( λ ) = ∏ i = 1 n ( λ x i x i ! e − λ ) = e − n λ λ ∑ i = 1 n x i ∏ i = 1 n ( x i ! ) L(\lambda)=\prod_{i=1}^n (\frac{\lambda^{x_i}}{x_i!}e^{-\lambda})=e^{-n\lambda}\frac{\lambda^{\sum_{i=1}^nx_i}}{\prod_{i=1}^n(x_i!)} L(λ)=i=1∏n(xi!λxie−λ)=e−nλ∏i=1n(xi!)λ∑i=1nxi
对数似然函数为
ln L ( λ ) = − n λ + ln λ ∑ i = 1 n x i − ∑ i = 1 n ln ( x i ! ) \ln L(\lambda)=-n\lambda+\ln \lambda \sum_{i=1}^nx_i-\sum_{i=1}^n \ln(x_i!) lnL(λ)=−nλ+lnλi=1∑nxi−i=1∑nln(xi!)
令
∂ ln L ( λ ) ∂ λ = − n + 1 λ ∑ i = 1 n x i = 0 \frac{\partial \ln L(\lambda)}{\partial \lambda}=-n+\frac{1}{\lambda}\sum_{i=1}^nx_i=0 ∂λ∂lnL(λ)=−n+λ1i=1∑nxi=0
该似然方程有唯一解 λ ^ = 1 n ∑ i = 1 n x i = x ˉ \hat{\lambda}=\frac{1}{n}\sum_{i=1}^nx_i=\bar{x} λ^=n1∑i=1nxi=xˉ,又因
∂ 2 ln L ( λ ) ∂ λ 2 ∣ λ = x ˉ < 0 \frac{\partial^2 \ln L(\lambda)}{\partial \lambda^2}|_{\lambda=\bar{x}}<0 ∂λ2∂2lnL(λ)∣λ=xˉ<0
故 λ \lambda λ 的极大似然估计量为 λ ^ = X ˉ \hat{\lambda}=\bar{X} λ^=Xˉ。
参考文献
[1] 《应用数理统计》,施雨,西安交通大学出版社。
相关文章:
(点估计))
参数估计(一)(点估计)
文章目录 点估计和估计量的求法点估计概念矩估计法极大似然估计法 参考文献 参数估计是数理统计中重要的基本问题之一。通常,称参数的可容许值的全体为参数空间,并记为 Θ \Theta Θ。所谓参数估计就是由样本对总体分布所含的未知参数做出估计。另外&am…...
kubenetes-服务发现和负载均衡
一、服务发布 kubenetes把服务发布至集群内部或者外部,服务的三种不同类型: ClusterlPNodePortLoadBalancer ClusterIP是发布至集群内部的一个虚拟IP,通过负载均衡技术转发到不同的pod中。 NodePort解决的是集群外部访问的问题,用户可能不…...
docker的基本使用以及使用Docker 运行D435i
1.一些基本的指令 1.1 容器 要查看正在运行的容器: sudo docker ps 查看所有的容器(包括停止状态的容器) sudo docker ps -a 重新命名容器 sudo docker rename <old_name> <new_name> <old_name> 替换为你的容器名称…...
如何看待人工智能行业发展
随着人工智能技术的飞速发展,这个领域的就业前景也日益广阔。人工智能在各行各业都有广泛的应用,包括医疗、金融、制造业、教育等。因此,对于想要追求高薪、高技能职业的人来说,学习人工智能是一个非常有前景的选择。 首先&#x…...

linux中实现自己的bash
🐶博主主页:ᰔᩚ. 一怀明月ꦿ ❤️🔥专栏系列:线性代数,C初学者入门训练,题解C,C的使用文章,「初学」C 🔥座右铭:“不要等到什么都没有了,才下…...

14 Go的类型转换
概述 在上一节的内容中,我们介绍了Go的错误处理,包括:errors包、返回错误、抛出异常、捕获异常等。在本节中,我们将介绍Go的类型转换。在Go语言中,类型转换是一种将一个值从一种类型转换为另一种类型的过程。类型转换主…...
多线程概述
文章目录 线程是什么线程有什么作用线程和进程的区别多线程相较于进程优势 在Java这个圈子中,多进程用的并不多,因为进程是一个重量级操作,进程是资源分配的基本单位,申请资源是一个比较消耗时间的操作. 线程是什么 线程是一个独立的执行流,可以被独立调度到CPU上执行 线程是…...

AR贴纸特效SDK,无缝贴合的虚拟体验
增强现实(AR)技术已经成为了企业和个人开发者的新宠。它通过将虚拟元素与现实世界相结合,为用户提供了一种全新的交互体验。然而,如何将AR贴纸完美贴合在人脸的面部,同时支持多张人脸的检测和标点及特效添加࿰…...

Leetcode hot 100
双指针 283.移动零 class Solution { public:void moveZeroes(vector<int>& nums) {int cnt 0;for(vector<int>::iterator it nums.begin(); it ! nums.end(); ){if(*it 0) it nums.erase(it),cnt;else it;}while(cnt--){nums.push_back(0);}} }; 11.盛…...

分类预测 | Matlab实现基于SDAE堆叠去噪自编码器的数据分类预测
分类预测 | Matlab实现基于SDAE堆叠去噪自编码器的数据分类预测 目录 分类预测 | Matlab实现基于SDAE堆叠去噪自编码器的数据分类预测分类效果基本描述程序设计参考资料 分类效果 基本描述 1.Matlab实现基于SDAE堆叠去噪自编码器的数据分类预测(完整源码和数据) 2.多…...
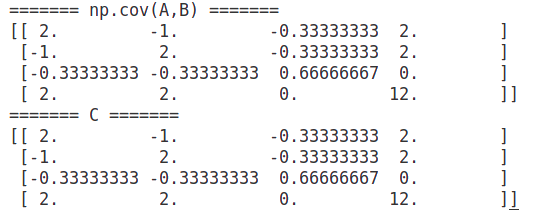
矩阵运算_矩阵的协方差矩阵/两个矩阵的协方差矩阵_求解详细步骤示例
1. 协方差矩阵定义 在统计学中,方差是用来度量单个随机变量的离散程度,而协方差则一般用来刻画两个随机变量的相似程度。 参考: 带你了解什么是Covariance Matrix协方差矩阵 - 知乎 2. 协方差矩阵计算过程 将输入数据A进行中心化处理得到A…...
——第108天:Pyecharts绘制多种炫酷词云图参数说明+代码实战)
100天精通Python(可视化篇)——第108天:Pyecharts绘制多种炫酷词云图参数说明+代码实战
文章目录 专栏导读一、词云图介绍1. 词云图是什么?2. 词云图应用场景?二、参数说明1. 导包2. add函数三、词云库实战1. 基础词云图2. 矩形词云图3. 三角形词云图4. 菱形词云图5. 自定义图片词云图书籍推荐专栏导读 🔥🔥本文已收录于《100天精通Python从入门到就业》:本…...
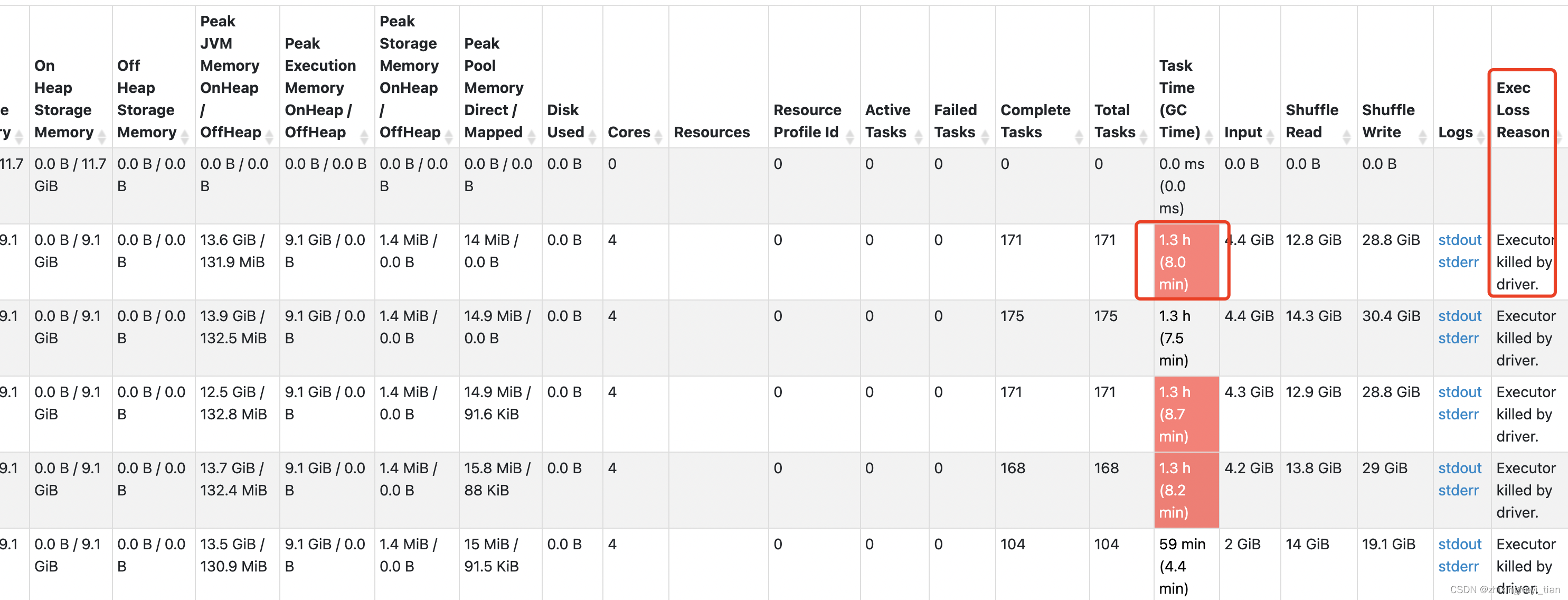
Spark 平障录
Profile Profile 是最重要的第一环。 利用好 spark UI 和 yarn container log分析业务代码,对其计算代价进行预判建设基准,进行对比,比如application id 进行对比,精确到 job DAG 环节 充分利用 UI Stage 页面 页头 summary&…...

基于一致性算法的微电网分布式控制MATLAB仿真模型
微❤关注“电气仔推送”获得资料(专享优惠) 本模型主要是基于一致性理论的自适应虚拟阻抗、二次电压补偿以及二次频率补偿,实现功率均分,保证电压以及频率稳定性。 一致性算法 分布式一致性控制主要分为两类:协调同…...

Android 10.0 系统修改usb连接电脑mtp和PTP的显示名称
1.前言 在10.0的产品定制化开发中,在usb模块otg连接电脑,调整为mtp文件传输模式的时候,这时可以在电脑看到手机的内部存储 显示在电脑的盘符中,会有一个mtp名称做盘符,所以为了统一这个名称,就需要修改这个名称,接下来分析下处理的 方法来解决这个问题 2.系统修改usb连…...
飞鼠异地组网工具实战之访问k8s集群内部服务
飞鼠异地组网工具实战之访问k8s集群内部服务 一、飞鼠异地组网工具介绍1.1 飞鼠工具简介1.2 飞鼠工具官网 二、本次实践介绍2.1 本次实践场景描述2.2 本次实践前提2.3 本次实践环境规划 三、检查本地k8s集群环境3.1 检查k8s各节点状态3.2 检查k8s版本3.3 检查k8s系统pod状态 四…...
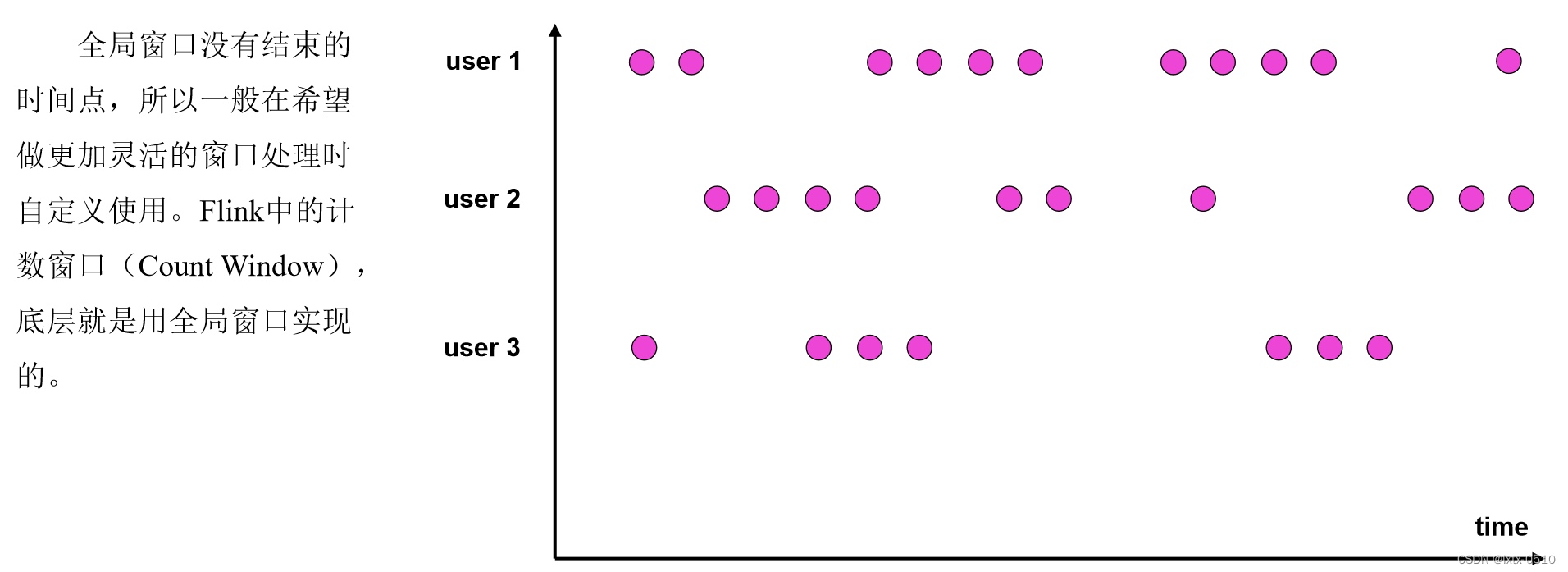
【Flink】窗口(Window)
窗口理解 窗口(Window)是处理无界流的关键所在。窗口可以将数据流装入大小有限的“桶”中,再对每个“桶”加以处理。 本文的重心将放在 Flink 如何进行窗口操作以及开发者如何尽可能地利用 Flink 所提供的功能。 对窗口的正确理解ÿ…...
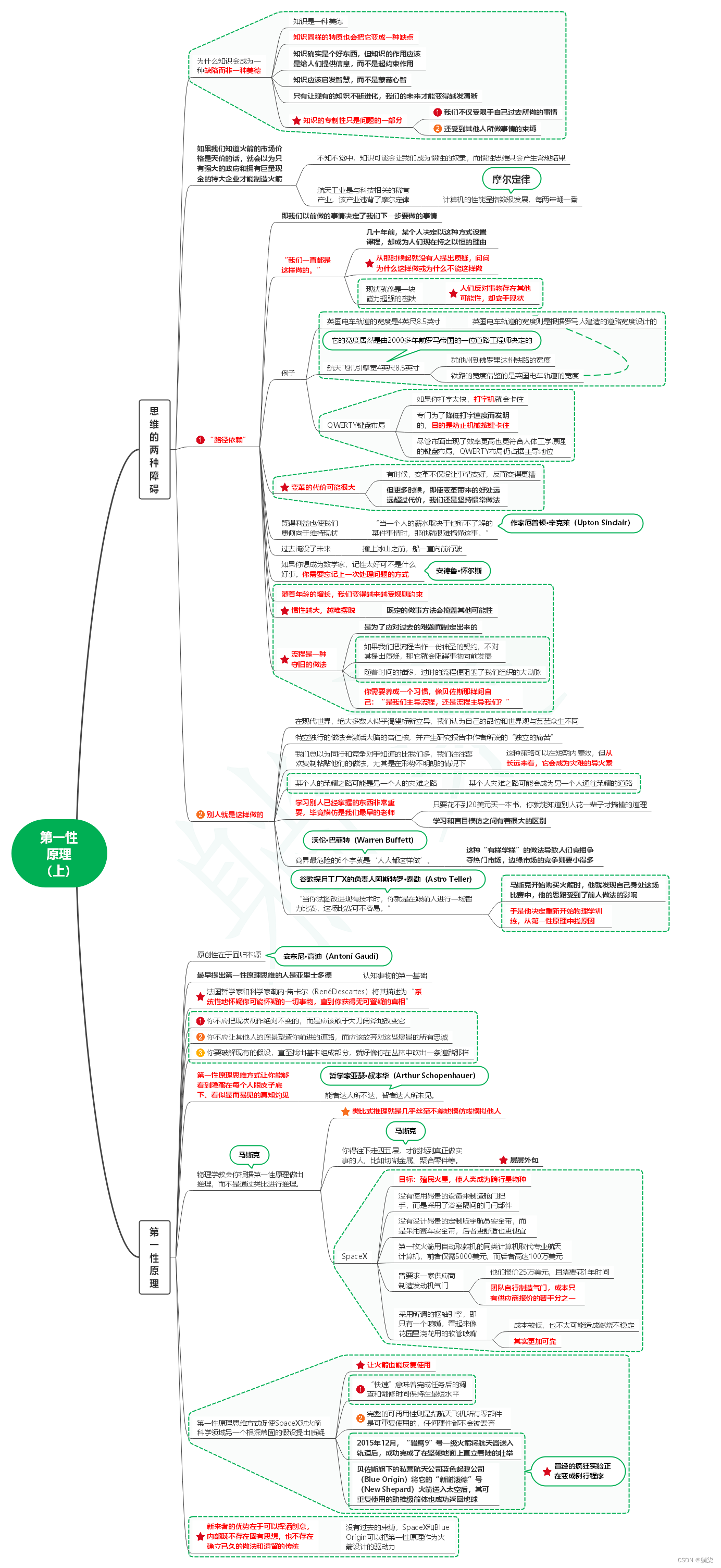
读像火箭科学家一样思考笔记03_第一性原理(上)
1. 思维的两种障碍 1.1. 为什么知识会成为一种缺陷而非一种美德 1.1.1. 知识是一种美德 1.1.2. 知识同样的特质也会把它变成一种缺点 1.1.3. 知识确实是个好东西,但知识的作用应该是给人们提供信息,而不是起约束作用 1.1.4. 知识应该启发智慧&#…...

npm私有云
安装node时npm会自动安装,npm也可以单独安装。 package.json 在使用npm时,package.json文件是非常重要的,因为它包含了关于项目的必要信息,比如名称、版本、依赖项等。在初始化新项目时,通常会使用npm init命令生成一…...

莹莹API管理系统源码附带两套模板
这是一个API后台管理系统的源码,可以自定义添加接口,并自带两个模板。 环境要求 PHP版本要求高于5.6且低于8.0,已测试通过的版本为7.4。 需要安装PHPSG11加密扩展。 已测试:宝塔/主机亲测成功搭建! 安装说明 &am…...

创业团队如何利用Token Plan套餐优化AI应用开发成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 创业团队如何利用Token Plan套餐优化AI应用开发成本 对于小型创业团队而言,在开发AI应用时,模型API的调用成…...

终极STL到STEP转换指南:从3D扫描到CAD设计的完整解决方案
终极STL到STEP转换指南:从3D扫描到CAD设计的完整解决方案 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 前言:跨越3D格式鸿沟的桥梁 在现代制造业和工程设计领域&…...

FanControl终极指南:5分钟实现Windows风扇智能控制,告别散热噪音烦恼
FanControl终极指南:5分钟实现Windows风扇智能控制,告别散热噪音烦恼 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitco…...

Java 零基础全套教程,File 类与 IO 流,笔记 175-176
Java 零基础全套教程,File 类与 IO 流,笔记 175-182 一、参考资料 【Java视频教程,java入门神器(附300道Java面试题剖析)】 https://www.bilibili.com/video/BV1PY411e7J6/?p175&share_sourcecopy_web&vd_sou…...

打造你的专属Minecraft体验:NightX Client深度解析与实用指南
打造你的专属Minecraft体验:NightX Client深度解析与实用指南 【免费下载链接】NightX-Client Minecraft Forge 1.8.9 hacked client, Based on LiquidBounce 项目地址: https://gitcode.com/gh_mirrors/ni/NightX-Client 你是否曾想过在Minecraft中拥有超越…...
)
别再乱装WinPcap了!手把手教你为华为eNSP Cloud正确配置虚拟网卡(Win7/Win10兼容方案)
华为eNSP Cloud虚拟网卡配置全指南:从原理到避坑实践 当你第一次打开华为eNSP Cloud功能时,是否也遇到过网卡显示不全的困扰?这个问题困扰过无数网络学习者和备考者,而90%的根源都指向同一个错误——WinPcap的安装方式。本文将彻底…...

MeritOpt:动态权重聚合算法在低资源NLP任务中的应用与实现
1. 项目概述与核心挑战在自然语言处理领域,低资源语言任务一直是个棘手的问题。想象一下,你手头只有几千条某个小语种的翻译对,却要训练一个能流畅翻译的模型,这就像试图用几块砖头盖起一栋大楼。传统的做法要么是“闭门造车”&am…...

PvZ Toolkit终极指南:解锁植物大战僵尸无限可能的开源修改器
PvZ Toolkit终极指南:解锁植物大战僵尸无限可能的开源修改器 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit PvZ Toolkit是一款专为《植物大战僵尸》PC版设计的开源游戏修改工具&#x…...

Windows Cleaner:4步高效解决C盘空间不足的开源终极方案
Windows Cleaner:4步高效解决C盘空间不足的开源终极方案 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner Windows Cleaner是一款完全免费开源的Windows…...

Camoufox反检测浏览器:深度伪造Canvas/WebGL/Audio指纹
1. 这不是浏览器,而是一套“数字伪装系统”:Camoufox的本质定位很多人第一次看到“Camoufox反检测浏览器”时,下意识会把它当成一个“长得像Firefox的爬虫工具”,甚至有人直接把它和普通无头浏览器、SeleniumUser-Agent轮换方案划…...