六大排序(插入排序、希尔排序、冒泡排序、选择排序、堆排序、快速排序)未完
文章目录
- 排序
- 一、 排序的概念
- 1.排序:
- 2.稳定性:
- 3.内部排序:
- 4.外部排序:
- 二、插入排序
- 1.直接插入排序
- 2.希尔排序
- 三、选择排序
- 1.直接选择排序
- 方法一
- 方法二
- 直接插入排序和直接排序的区别
- 2.堆排序
- 四、交换排序
- 1.冒泡排序
- 2.快速排序
- 1.挖坑法
- 2.Hoare法
- 3.前后指针法
- 4.快速排序的优化
- 方法一、三数取中法选基准值
- 方法二、递归到最小区间时、用插入排序
- 5.快速排序非递归实现
排序
一、 排序的概念
1.排序:
- 一组数据按递增/递减排序
2.稳定性:

- 待排序的序列中,存在多个相同的关键字,拍完序后,相对次序保持不变,就是稳定的
3.内部排序:
- 数据元素全部放在内存中的排序
4.外部排序:
- 数据元素太多不能同时放在内存中,根据排序过程的要求不能在内外存之间移动数据的排序
二、插入排序
1.直接插入排序

和整理扑克牌类似,将乱序的牌,按值的大小,插入整理好的顺序当中
从头开始,比最后一个小的话依次向前挪,直到大于之前牌时,进行插入

1.如果只有一个值,则这个值有序,所以插入排序, i 从下标1开始,把后面的无序值插入到前面的有序当中
2.j = i-1,是i的前一个数,先用tmp将 i位置的值(要插入的值)先存起来,比较tmp和j位置的值
3.如果tmp的值比 j位置的值小,说明要向前插入到有序的值中,把 j位置的值后移,移动到 j+1的位置,覆盖掉 i 的值
4.j 下标向前移动一位,再次和 tmp 比较
5.如果tmp的值比 j 位置的值大,说明找到了要插入的位置就在当前j位置之后,把tmp存的值,放到 j+1的位置
6.如果tmp中存的值比有序的值都小,j位置的值依次向后移动一位,j不停减1,直到排到第一位的数移动到第二位,j的下标从0移动到-1,循环结束,最后将tmp中存的值,存放到 j+1的位置,也就是0下标
public void insertSort(int[] array) {for (int i = 1; i < array.length; i++) {int tmp = array[i];//tmp存储i的值int j = i - 1;for (; j >= 0; j--) {if (tmp < array[j]) {array[j + 1] = array[j];} else {// array[j+1] = tmp;break;}}array[j + 1] = tmp;}}插入就是为了维护前面的有序
-
元素越接近有序,直接插入排序算法的时间效率越高
-
时间复杂度O( N 2 )
-
空间复杂度O ( 1 )
-
稳定性:稳定
如果一个排序是稳定的,可以改变实现为不稳定的
如果是不稳定的排序,则没有办法改变
2.希尔排序

希尔排序shellSort 叫缩小增量排序,是对直接插入排序的优化,先分组,对每组插入排序,让整体逐渐有序
利用了插入排序元素越有序越快的特点

- 先确定一个整数,把待排序数分成多个组,每个组中的数距离相同,
- 对每一组进行排序,然后再次分组排序,减少分组数,组数多,每组数据就少
- 找到分组数=1时,基本有序了,只需要再排一次插入排序即可
一开始组数多,每组数据少,可以保证效率
随着组数的减少,每组数据变多,数据越来越有序,同样保证了效率
到达1分组之前,前面的排序都是预排序
public static void shellSort2(int[] array) {int gap = array.length;while (gap > 1) { //gap>1时缩小增量gap /= 2;//直接在循环内进行最后一次排序shell(array, gap);}}/**** 希尔排序* 时间复杂度O(N^1.3---N^1.5)* @param array*/public static void shellSort1(int[] array) {int gap = array.length;while (gap > 1) { //gap>1时缩小增量shell(array, gap);gap /= 2;//gap==1时不进入循环,再循环为再次排序}shell(array, gap);//组数为1时,进行插入排序}public static void shell(int[] arr, int gap) {//本质上还是插入排序,但是i和j的位置相差为组间距for (int i = gap ; i < arr.length; i++) {int tmp = arr[i];int j = i-gap;for (; j >=0; j -= gap) {if (tmp<arr[j]){arr[j+gap] = arr[j];}else {break;}}arr[j+gap] = tmp;}}- 时间复杂度:O( N^1.3 ^) ---- O( N^1.5 ^)
- 空间复杂的:O(1)
- 稳定性:不稳定
三、选择排序

- 在待排序序列中,找到最小值(大)的下标,和排好序的末尾交换,放到待排序列的开头,直到全部待排序元素排完
1.直接选择排序

方法一
/*** 选择排序** @param array*/public static void selectSort(int[] array) {for (int i = 0; i < array.length; i++) {int minIndex = i;for (int j = i + 1; j < array.length; j++) {//找最小值if (array[j] < array[minIndex]) {minIndex = j;//只要比minIndex小,放进去}}//循环走完后,minIndex存的就是当前未排序的最小值//将当前i的值和找到的最小值进行交换swap(array,i,minIndex);}}public static void swap(int[] array, int i, int j) {int tmp = array[i];array[i] = array[j];array[j] = tmp;}
1.遍历数组长度,i从0开始
2.每次循环,都由minIndex = i 来记录最小值的下标
3.j 从i+1开始遍历,只要比记录的最小值小,就让minIndex记录。找到未排序中的最小值,进行交换
4.如果遍历完后,未排序中没有比minIndex存的值小,i的值就是最小值,i++;
- 效率低, 如果较为有序的序列,在交换时会破坏有序性
- 时间复杂度:O ( N2 )
- 空间复杂的:O ( 1 )
- 稳定性:不稳定
方法二
-
上面的方法,只是先选出最小的值,然后和i的位置交换,
-
进行优化:在遍历时选出最大值和最小值,和收尾进行交换

/*** 选择排序---选最大值和最小值** @param array*/public static void selectSort2(int[] array) {int left = 0;int right = array.length - 1;while (left < right) {int minIndex = left;int maxIndex = left;//选出最大值和最小值for (int i = left + 1; i <= right; i++) {if (array[i] > array[maxIndex]) {maxIndex = i;}if (array[i] < array[minIndex]) {minIndex = i;}}//用最大值和最小值交换首位swap(array, left, minIndex);//把left和最小值交换//如果left恰好就是最大值,就有可能把最大值换到minIndex的位置if(left == maxIndex){maxIndex = minIndex;//最大值位置不是left了,而是换到了minIndex}swap(array, right, maxIndex);left++;right--;}}
1.在遍历的过程中,选出最大值的下标和最小值的下标
2.将left和最小值进行交换
3.如果left恰好为最大值,left和最小值交换完成后,最大值就在原来最小值的位置上,
4.maxIndex = minIndex,修正最大值的位置
4.将right和最大值进行交换
直接插入排序和直接排序的区别
- 和插入排序不同的是,插入排序会持续对已排序的数进行比较,把合适的数放在合适的位置
- 直接选择排序就是不断找到最小的值,依次放在排好序的末尾,不干预排好的序列
2.堆排序
- 时间复杂度: O( N * log N)
- 空间复杂的:O (1)
-
升序:建大堆
-
降序:建小堆
-

将一组数据从小到大排序 ——> 建立大根堆
为什么不用小根堆:小根堆只能保证,根比左右小,不能保证左右孩子的大小顺序,并且要求对数组本身进行排序
- 大根堆,保证堆顶元素是最大值,最大值跟最后一个元素交换,将最大的放在最后,usedSize–;
- 向下调整:调整0下标的树,维护大根堆,最大值继续交换到最后一个有效元素的位置
- 从后往前,从大到小依次排列,保证在原来数组本身进行排序
/*** 堆排序* 时间复杂度: N*logN* 空间复杂的:o(1)** @param array*/public static void heapSort(int[] array) {createBigHeap(array);//创建大根堆int end = array.length-1;while (end>0){swap(array,0,end);//堆顶元素和末尾互换shiftDown(array,0,end);//维护大根堆end--;}}/*** 创建大根堆** @param array*/public static void createBigHeap(int[] array) {//最后一个结点的下标 = array.length - 1//它的父亲结点的下标就为array.length - 1 - 1) / 2for (int parent = (array.length - 1 - 1) / 2; parent >= 0; parent--) {shiftDown(array, parent, array.length);}}/*** 向下调整** @param array* @param parent* @param len*///向下调整,每棵树从父结点向下走public static void shiftDown(int[] array, int parent, int len) {int child = parent * 2 + 1;while (child < len) {//child < len:最起码要有一个左孩子if (child + 1 < len && array[child] < array[child + 1]) {child++;}//child + 1<len:保证一定有右孩子的情况下,和右孩子比较//拿到子节点的最大值if (array[child] > array[parent]) {swap(array, child, parent);parent = child;//交换完成后,让parent结点等于等于当前child结点child = 2 * parent + 1;//重新求子节点的位置,再次进入循环交换} else {break;//比父结点小,结束循环}}}
- 时间复杂度: O( N * log 2N)
- 空间复杂的:O (1)
- 稳定性:不稳定
四、交换排序
- 根据序列中两个记录键值的比较结果来对换这两个记录在序列中的位置
- 将键值较大的记录向序列的尾部移动,键值较小的记录向序列的前部移动。
1.冒泡排序

/*** 冒泡排序* 时间复杂度 n^2* 空间复杂度 1* @param array*/public static void bubbleSort(int[]array){for (int i = 0; i < array.length-1; i++) {//趟数boolean flg =false;for (int j = 0; j < array.length-1-i; j++) {if (array[j]>array[j+1]){swap(array,j,j+1);flg = true;}}if (flg == false){return;}}}1.遍历 i 代表交换的趟数,遍历 j 进行两两交换
2.j < array.length-1-i 是对于趟数的优化,每走一趟,交换就少一次
3.boolean flg =false;当两两交换时,flg变为true
4.进一步优化:如果遍历完,没发生交换,flg还是false,直接返回,排序结束
- 时间复杂度:O ( N2 )
- 空间复杂度:O ( 1 )
- 稳定性:稳定
2.快速排序
-
时间复杂度:
最好情况:O (N*log2N) :树的高度为log2N,每一层都是N
最坏情况:O (N2):有序、逆序的情况下,没有左树,只有右树,单分支树,树的高度是N,每一层都是N
-
空间复杂的:
最好情况:O (log2N):满二叉树(均匀分割待排序的序列,效率最高)树高为 log2N
最坏情况:O(N):单分支树,树高为N
-
稳定性:不稳定
-
二叉树结构的交换排序方法
-
任取一个待排序元素作为基准值,把序列一分为二,左子序都比基准值小,右子序都比基准值大,左右两边再重复进行

- 左边找比基准值大的,右边找比基准值小的
1.挖坑法

- 基准值位置挖一个坑,后面找一个比基准值小的把坑埋上
- 前面找一个比基准值大的,埋后面的坑
- 当l==r时,把基准值填入剩下的坑中

- 左右两边重复进行上述步骤,直到排完为止
- 左右两边都以同样的方法进行划分,运用递归来实现
/*** 快速排序* 时间复杂度:N*log~2~N* 空间复杂度* * @param array*/public static void quickSort(int[] array) {quick(array, 0, array.length - 1);}private static void quick(int[] array, int start, int end) {if (start >= end) {return;//结束条件// start == end,说明只剩一个了,是有序的,返回//start > end ,说明此时的基准值在开头或者末尾//在开头:start不变,end=pivot-1,start > end ,end=-1 没有左树//在结尾:end不变,start = pivot+1,start > end,超出索引,没有右树}//不断递归quickint pivot = partition(array, start, end);// 进行排序,划分找到pivot//然后递归划分法左边,递归划分的右边quick(array, start, pivot - 1);quick(array, pivot + 1, end);}// ---挖坑法 划分,返回基准值private static int partition(int[] array, int left, int right) {int tmp = array[left];//挖一个坑,取left位置为基准值while (left < right) {//在右边找一个比基准值小的把坑填上while (left < right && array[right] >= tmp) {//防止越界right--;}array[left] = array[right];//找到比tmp小的数,填坑,//在左边找一个比tmp大的值,填到右边的坑while (left < right && array[left] <= tmp) {//防止越界left++;}array[right] = array[left];}//如果相遇了,退出循环array[left] = tmp;//填坑return left;}-
先划分序列,递归左边,然后再递归右边
-
递归结束条件:
start == end时,说明只剩一个了,是有序的,返回
start > end 时 ,说明此时的基准值在开头或者末尾如果基准值在开头:start不变,end=pivot-1,start > end ,end=-1 没有左树
如果基准值在结尾:end不变,start = pivot+1,start > end,超出索引,没有右树
2.Hoare法

- 不同的方法,找出基准值,排的序列是不一样的

- i记录基准值一开始在left位置的下标
- r找到比基准值小的停下来,l找到比基准值大的停下来,互相交换
- l和r相遇的时候,把i 记录基准值的初始下标和相遇位置交换
以左边为基准,先找右边再找左边,相遇的位置就是以右边为基准的值,要比基准小,才能交换
/*** Hoare法 划分排序找基准值* @param array* @param left* @param right* @return*/private static int partition2(int[] array, int left, int right) {int tmp = array[left];int i = left;//记录基准值一开始在left位置的下标while (left < right) {while (left < right && array[right] >= tmp) {right--;}while (left < right && array[left] <= tmp) {left++;}swap(array,left,right);}swap(array,i,left);return left;}
3.前后指针法


- prev记录了比key小的最后一个位置
- cur去找比key值小的,找到后,放到prev的下一个位置
- 最后找到基准值,并且基准值的左边都比它小,右边都比他大
/*** 前后指针法,划分排序找基准值** @param array* @param left* @param right* @return*/private static int partition3(int[] array, int left, int right) {int prev = left; //prev从left位置开始,left为当前的基准值int cur = left + 1;//cur在prev的后一个while (cur <= right) {//遍历完当前数组段if (array[cur] < array[left] && array[++prev] != array[cur]) {//只要cur指向的值小于left位置的基准值//并且prev++后不等于cur的值swap(array, cur, prev);//将cur和prev位置的值交换//cur++;}//如果cur的值大于基准值,或者prev下一位的值等于cur,cur后移cur++;}//cur越界,循环结束,最后,交换基准值和prev位置的值//prev记录的就是比基准值小的最后一个数swap(array, prev, left);return prev;//prev为基准值}4.快速排序的优化
-
时间复杂度:
最好情况:O (N*log2N) :树的高度为log2N,每一层都是N
最坏情况:O (N2):有序、逆序的情况下,没有左树,只有右树,单分支树,树的高度是N,每一层都是N
-
空间复杂的:
最好情况:O (log2N):满二叉树(均匀分割待排序的序列,效率最高)树高为 log2N
最坏情况:O(N):单分支树,树高为N
-
稳定性:不稳定
-
快速排序有可能发生栈溢出异常,需要进行优化
-
所以要能均匀分割待排序的序列
递归的次数多了,会导致栈溢出,所以优化的方向就是减少递归的次数
方法一、三数取中法选基准值
方法二、递归到最小区间时、用插入排序
5.快速排序非递归实现
的值等于cur,cur后移
cur++;
}
//cur越界,循环结束,最后,交换基准值和prev位置的值
//prev记录的就是比基准值小的最后一个数
swap(array, prev, left);
return prev;//prev为基准值
}
##### 4.快速排序的优化- 时间复杂度:> 最好情况:O (N*log~2~N) :树的高度为log~2~N,每一层都是N>> 最坏情况:O (N^2^):有序、逆序的情况下,没有左树,只有右树,单分支树,树的高度是N,每一层都是N >> - 空间复杂的:> 最好情况:O (log~2~N):满二叉树(均匀分割待排序的序列,效率最高)树高为 log~2~N>> 最坏情况:O(N):单分支树,树高为N- 稳定性:不稳定- 快速排序有可能发生栈溢出异常,需要进行优化
- 所以要能均匀分割待排序的序列递归的次数多了,会导致栈溢出,所以优化的方向就是减少递归的次数###### 方法一、三数取中法选基准值###### 方法二、递归到最小区间时、用插入排序##### 5.快速排序非递归实现## 五、归并排序
相关文章:
六大排序(插入排序、希尔排序、冒泡排序、选择排序、堆排序、快速排序)未完
文章目录 排序一、 排序的概念1.排序:2.稳定性:3.内部排序:4.外部排序: 二、插入排序1.直接插入排序2.希尔排序 三、选择排序1.直接选择排序方法一方法二直接插入排序和直接排序的区别 2.堆排序 四、交换排序1.冒泡排序2.快速排序…...
JVM垃圾回收相关概念
目录 一、System.gc()的理解 二、内存溢出与内存泄露 (一)OOM (二)内存泄露 三、StopTheWorld 四、垃圾回收的并行与并发 五、安全点与安全区域 (一)安全点 (二)安全区域 …...
C++各种字符转换
C各种字符转换 一.如何将char数组转化为string类型二. string转char数组:参考 一.如何将char数组转化为string类型 在C中,可以使用string的构造函数或者赋值操作符来将char数组转换为string类型。 方法1:使用string的构造函数 const char* c…...

MSSQL-逻辑级常用命令
--SQL Server 查询表的记录数 --one: 使用系统表. SELECT object_name (i.id) TableName, rows as RowCnt FROM sysindexes i INNER JOIN sysObjects o ON (o.id i.id AND o.xType U ) WHERE indid < 2 ORDER BY rows desc ————————————…...

【如何学习Python自动化测试】—— 时间等待
3 、 时间等待 在做自动化测试时,难免会碰到一些问题,比如你在脚本中操作某个对象时, 页面还没有加载出来,你的操作语句已经被执行,从而导致脚本执行失败,针对这样的问题 webdriver 提供了等待操作…...

《数字图像处理-OpenCV/Python》连载(44)图像的投影变换
《数字图像处理-OpenCV/Python》连载(44)图像的投影变换 本书京东优惠购书链接:https://item.jd.com/14098452.html 本书CSDN独家连载专栏:https://blog.csdn.net/youcans/category_12418787.html 第 6 章 图像的几何变换 几何变…...

AI机器学习 | 基于librosa库和使用scikit-learn库中的分类器进行语音识别
专栏集锦,大佬们可以收藏以备不时之需 Spring Cloud实战专栏:https://blog.csdn.net/superdangbo/category_9270827.html Python 实战专栏:https://blog.csdn.net/superdangbo/category_9271194.html Logback 详解专栏:https:/…...
Asp.net MVC Api项目搭建
整个解决方案按照分层思想来划分不同功能模块,以提供User服务的Api为需求,各个层次的具体实现如下所示: 1、新建数据库User表 数据库使用SQLExpress版本,表的定义如下所示: CREATE TABLE [dbo].[User] ([Id] …...

C语言中文网 - Shell脚本 - 8
第1章 Shell基础(开胃菜) 8. Linux Shell命令提示符 启动 Linux 桌面环境自带的终端模拟包,或者从 Linux 控制台登录后,便可以看到 Shell 命令提示符。看见命令提示符就意味着可以输入命令了。命令提示符不是命令的一部分&#x…...

性能测试学习——项目环境搭建和Jmete学习二
项目环境搭建、Jmeter学习二 环境的部署虚拟机的安装虚拟机中添加项目操作步骤 使用环境的注意事项Jmeter的安装和简单使用Jemter的使用的进阶Jemter元件 Jmeter属性执行顺序和作用域作用域以自定义用户变量和用户参数(前置处理器)为例如何解决用户变量和线程组同级时ÿ…...
-map介绍)
C++标准模板库(STL)-map介绍
C标准库中的map是一种关联容器,它提供了键值对的映射关系。每个键值对中的键都是唯一的,通过键可以访问对应的值。 map基本操作 插入元素: 使用insert函数插入元素,该函数有两种形式: // 插入一个pair<const Ke…...
使用docker部署ELK日志框架-Elasticsearch
一、ELK知识了解 1-ELK组件 工作原理: (1)在所有需要收集日志的服务器上部署Logstash;或者先将日志进行集中化管理在日志服务器上,在日志服务器上部署 Logstash。 (2)Logstash 收集日志&#…...

第7章 模式匹配与正则表达式
目录 1. 不用正则表达式来查找文本模式2. 用正则表达式来查找文本模式2.1 创建正则表达式(Regex)对象2.2 匹配Regex对象 3. 用正则表达式匹配更多模式3.1 利用括号分组3.2 用管道匹配多个分组3.3 用问号实现可选匹配3.4 用星号匹配零次或多次3.5 用加号匹…...
JPA 的测试)
单元测试实战(三)JPA 的测试
为鼓励单元测试,特分门别类示例各种组件的测试代码并进行解说,供开发人员参考。 本文中的测试均基于JUnit5。 单元测试实战(一)Controller 的测试 单元测试实战(二)Service 的测试 单元测试实战&am…...

初刷leetcode题目(3)——数据结构与算法
😶🌫️😶🌫️😶🌫️😶🌫️Take your time ! 😶🌫️😶🌫️😶🌫️😶🌫️…...
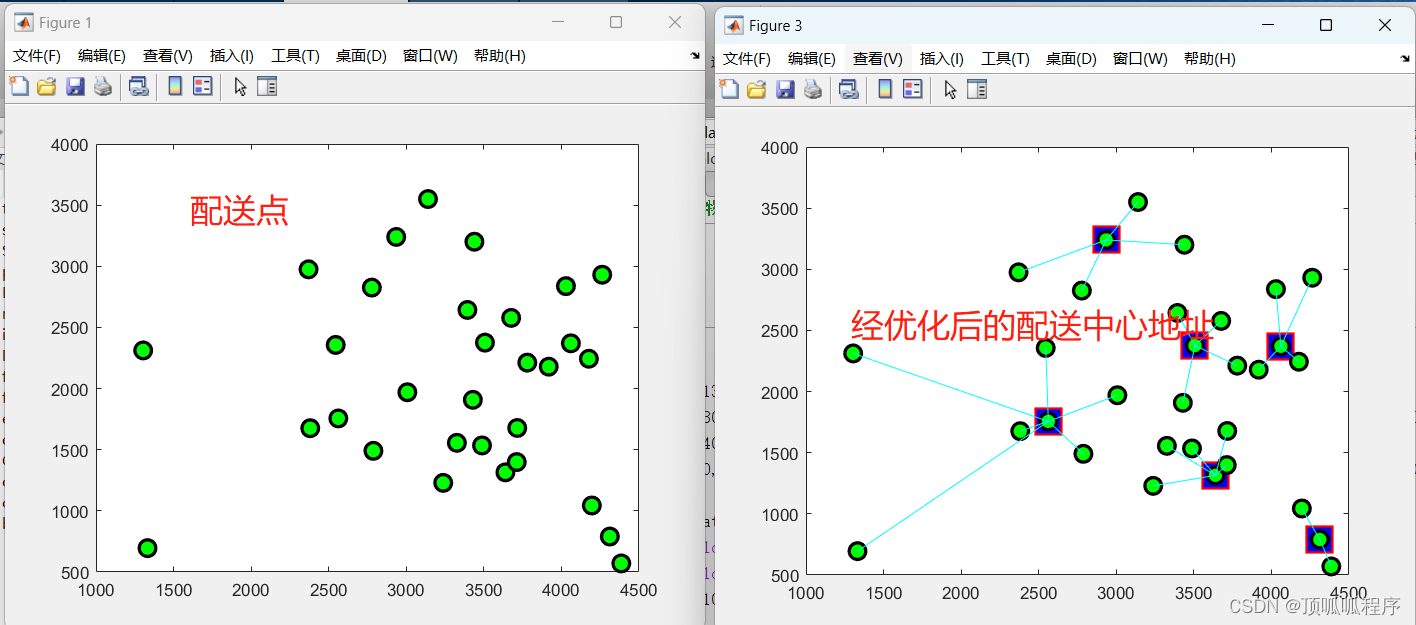
76基于matlab的免疫算法求解配送中心选址问题,根据配送地址确定最佳配送中心地址位置。
基于matlab的免疫算法求解配送中心选址问题,根据配送地址确定最佳配送中心地址位置。数据可更换自己的,程序已调通,可直接运行。 76matlab免疫算法配送中心选址 (xiaohongshu.com)...

C++二分查找算法:找到 Alice 和 Bob 可以相遇的建筑
本文涉及的基础知识点 二分查找算法合集 离线查询 题目 给你一个下标从 0 开始的正整数数组 heights ,其中 heights[i] 表示第 i 栋建筑的高度。 如果一个人在建筑 i ,且存在 i < j 的建筑 j 满足 heights[i] < heights[j] ,那么这个…...

建立跨层全栈的区块链安全保障系统-应用层,系统层,设施层
目录 建立跨层全栈的区块链安全保障系统 应用层 系统层 设施层...
程序员告诉你:人工智能是什么?
随着科技的快速发展,人工智能这个词汇已经逐渐融入了我们的日常生活。然而,对于大多数人来说,人工智能仍然是一个相对模糊的概念。 首先,让我们从人工智能的定义开始。人工智能是一种模拟人类智能的技术,它涵盖了多个领…...
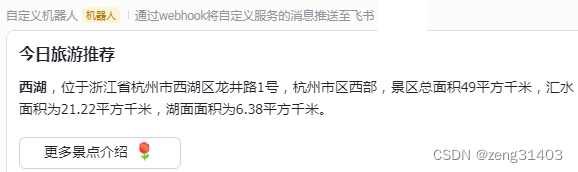
飞书开发学习笔记(七)-添加机器人及发送webhook消息
飞书开发学习笔记(七)-添加机器人及发送webhook消息 一.添加飞书机器人 1.1 添加飞书机器人过程 在群的右上角点击折叠按键…选择 设置 群机器人中选择 添加机器人 选择自定义机器人,通过webhook发送消息 弹出的信息中有webhook地址,选择复制。 安…...

D2DX技术深度解析:让经典《暗黑破坏神2》在现代PC上重获新生的渲染中间层方案
D2DX技术深度解析:让经典《暗黑破坏神2》在现代PC上重获新生的渲染中间层方案 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/…...

无敏感信息下的机器学习公平性:两大前沿框架与工程实践
1. 机器学习公平性:从理论到无人口统计信息的实战在算法决策日益渗透到信贷审批、司法风险评估、招聘筛选等关键社会领域的今天,一个尖锐的问题浮出水面:我们如何确保这些“智能”系统不成为偏见与歧视的放大器?机器学习公平性&am…...

机器学习项目开发模式解析:从提交历史看规模、协作与演化规律
1. 项目概述:从代码提交中解码机器学习项目的真实工作流在机器学习项目的日常开发中,我们每天都在与Git打交道,提交代码、更新模型、调整参数。但你是否想过,这些看似随意的提交背后,是否隐藏着某种规律?一…...

熬夜赶论文效率低到哭?学长安利这几个AI论文写作软件
熬夜赶论文效率低到哭?选题没思路、大纲难搭建、初稿写不顺、文献找不全、润色没方向、降重费时间、格式不规范——这些论文写作的痛点,其实都可以通过用对AI工具、走对流程来解决。资深教授普遍推荐:千笔AI(中文全流程首选&#…...

量子机器学习可解释性:从经典XAI到XQML的挑战与创新方法
1. 项目概述:当量子机器学习遇上“黑盒”挑战作为一名长期关注前沿技术交叉领域的从业者,我最近花了大量时间研究一个既烧脑又极具潜力的方向:如何让量子机器学习(QML)模型变得“透明”。我们都知道,经典深…...

DS4Windows实战指南:在Windows上完美使用PS4手柄的终极解决方案
DS4Windows实战指南:在Windows上完美使用PS4手柄的终极解决方案 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 在Windows系统上使用PS4手柄玩游戏时,你是否遇到过…...

JMeter压测5大底层优化:线程模型、HTTP连接、Groovy脚本、JVM参数与分布式协同
1. 为什么90%的JMeter脚本在压测中“假成功”——从一个被忽略的线程组配置说起你有没有遇到过这样的情况:脚本在JMeter GUI里跑得飞快,聚合报告里TPS稳稳上200,响应时间平均80ms,看起来一切完美;可一上生产环境做真实…...

LabVIEW采光节能控制系统
以自然光采集与室内智能调光工程为载体,基于 LabVIEW 图形化编程平台搭建完整测控系统,整合图像采集、照度标定、无线通信、PID 调节、嵌入式部署等技术。依托 LabVIEW 快速开发、多硬件兼容、算法集成、数据可视化等原生能力,完成室内自然…...

BetterGI原神自动化工具:5大核心功能让你每天节省2小时游戏时间
BetterGI原神自动化工具:5大核心功能让你每天节省2小时游戏时间 【免费下载链接】better-genshin-impact 📦BetterGI 更好的原神 - 自动拾取 | 自动剧情 | 全自动钓鱼(AI) | 全自动七圣召唤 | 自动伐木 | 自动刷本 | 自动采集/挖矿/锄地 | 一条龙 | 全连…...

别急着重启!深入理解Ubuntu 22.04的needrestart:守护进程、库文件与系统更新背后的原理
别急着重启!深入理解Ubuntu 22.04的needrestart:守护进程、库文件与系统更新背后的原理在Ubuntu 22.04 LTS的系统维护中,许多管理员都曾遇到过这样的场景:执行apt upgrade后,终端突然弹出"Daemons using outdated…...