AI机器学习 | 基于librosa库和使用scikit-learn库中的分类器进行语音识别
专栏集锦,大佬们可以收藏以备不时之需
Spring Cloud实战专栏:https://blog.csdn.net/superdangbo/category_9270827.html
Python 实战专栏:https://blog.csdn.net/superdangbo/category_9271194.html
Logback 详解专栏:https://blog.csdn.net/superdangbo/category_9271502.html
tensorflow专栏:https://blog.csdn.net/superdangbo/category_8691332.html
Redis专栏:https://blog.csdn.net/superdangbo/category_9950790.html
AI机器学习实战:
AI机器学习实战 | 使用 Python 和 scikit-learn 库进行情感分析
Python实战:
Python实战 | 使用 Python 和 TensorFlow 构建卷积神经网络(CNN)进行人脸识别
Spring Cloud实战:
Spring Cloud 实战 | 解密Feign底层原理,包含实战源码
Spring Cloud 实战 | 解密负载均衡Ribbon底层原理,包含实战源码
1024程序员节特辑文章:
1024程序员狂欢节特辑 | ELK+ 协同过滤算法构建个性化推荐引擎,智能实现“千人千面”
1024程序员节特辑 | 解密Spring Cloud Hystrix熔断提高系统的可用性和容错能力
1024程序员节特辑 | ELK+ 用户画像构建个性化推荐引擎,智能实现“千人千面”
1024程序员节特辑 | OKR VS KPI谁更合适?
1024程序员节特辑 | Spring Boot实战 之 MongoDB分片或复制集操作
Spring实战系列文章:
Spring实战 | Spring AOP核心秘笈之葵花宝典
Spring实战 | Spring IOC不能说的秘密?
国庆中秋特辑系列文章:
国庆中秋特辑(八)Spring Boot项目如何使用JPA
国庆中秋特辑(七)Java软件工程师常见20道编程面试题
国庆中秋特辑(六)大学生常见30道宝藏编程面试题
国庆中秋特辑(五)MySQL如何性能调优?下篇
国庆中秋特辑(四)MySQL如何性能调优?上篇
国庆中秋特辑(三)使用生成对抗网络(GAN)生成具有节日氛围的画作,深度学习框架 TensorFlow 和 Keras 来实现
国庆中秋特辑(二)浪漫祝福方式 使用生成对抗网络(GAN)生成具有节日氛围的画作
国庆中秋特辑(一)浪漫祝福方式 用循环神经网络(RNN)或长短时记忆网络(LSTM)生成祝福诗词

目录
- 1、普通人在学习 AI 时结合以下10个方面开展
- 2、机器学习应用场景
- 3、机器学习面对的挑战
- 4、机器学习步骤
- 5、语音识别具体步骤
- 1. 环境准备
- 2. 数据准备
- 3. 特征提取
- 4. 模型训练
- 5. 模型评估
- 6、语音识别相关资料
- 1. 学习资料
- 2. 开源技术
- 3. 完整代码介绍
- 4. 调优
- 5. 案例分享
1、普通人在学习 AI 时结合以下10个方面开展
普通人在学习 AI 时可以采取以下具体措施和对应案例:
- 学习基础知识:
- 阅读书籍:《人工智能:一种现代的方法》(作者:Stuart Russell 和 Peter Norvig)
- 在线课程:斯坦福大学 CS224n(计算机视觉)和 CS221(机器学习)
- 学习编程语言:
- 选择 Python 作为入门编程语言,因为它易于学习且在 AI 领域广泛应用。
- 学习数学和统计学:
- 线性代数:学习矩阵运算、向量空间和线性变换等概念。
- 概率论与统计学:学习概率分布、假设检验和回归分析等概念。
- 学习 AI 相关库和框架:
- TensorFlow:一个广泛用于深度学习的开源库。
- PyTorch:另一个流行的深度学习框架。
- scikit-learn:一个用于机器学习的库,包含多种分类、回归和聚类算法。
- 动手实践:
- 项目案例:使用 TensorFlow 实现 MNIST 手写数字识别。
- 参考教程:https://www.tensorflow.org/tutorials/sequential/mnist
- 学习具体应用领域:
- 自然语言处理(NLP):使用 spaCy 库进行文本分类和情感分析。
- 计算机视觉(CV):使用 OpenCV 库实现图像处理和目标检测。
- 关注行业动态:
- 阅读 AI 领域的论文和研究:如《深度学习》(作者:Ian Goodfellow、Yoshua Bengio 和 Aaron Courville)
- 关注顶级会议:如 NeurIPS(神经信息处理系统会议)和 CVPR(计算机视觉和模式识别国际会议)
- 加入社群交流:
- 参与线上论坛:如 Reddit、知乎等,关注 AI 相关话题。
- 参加线下活动:如 AI 沙龙、技术讲座和研讨会。
- 结合实际工作或兴趣爱好:
- 工作案例:使用 AI 优化供应链管理或客户服务。
- 个人兴趣:利用 AI 制作音乐、游戏或艺术作品。
- 持续学习:
- 参加在线课程:如 Coursera、Udacity 等,不断提升自己的 AI 技能。
- 阅读博客和论文:了解最新的 AI 研究和应用。
通过以上具体措施和案例,普通人可以逐步掌握 AI 技术,并在实际应用中发挥重要作用。只要不断学习、实践和探索,普通人在 AI 领域也能取得很好的成果。
2、机器学习应用场景
AI 和机器学习技术在以下具体应用场景中发挥着重要作用,并且具有广阔的前景:
- 金融领域:AI 机器学习技术可以用于风险评估、投资决策、欺诈检测等,有助于金融机构提高效率和降低风险。
- 医疗健康:AI 机器学习技术在医疗影像分析、基因测序、疾病预测等方面具有巨大潜力,有助于提高诊断准确率和治疗效果。
- 自然语言处理:AI 机器学习技术在语音识别、文本分析、情感分析、机器翻译等领域具有广泛应用,为人类提供便捷的语言交互方式。
- 计算机视觉:AI 机器学习技术在图像识别、目标检测、人脸识别等方面有着广泛应用,助力智能监控、自动驾驶等场景。
- 零售业:通过分析消费者行为和购买偏好,AI 机器学习技术可以帮助零售商实现精准营销和库存管理。
- 制造业:AI 机器学习技术可以用于智能制造、机器人、自动化生产线等,提高生产效率和质量。
- 能源领域:AI 机器学习技术在智能电网、能源优化等方面具有潜力,有助于实现可持续能源发展和降低能源成本。
- 物流行业:AI 机器学习技术可以应用于路径规划、仓储管理、配送优化等,提高物流效率。
- 城市规划:AI 机器学习技术在交通优化、基础设施规划、城市安全等方面具有价值。
- 环境保护:AI 机器学习技术可以帮助实现更有效的环境监测、污染源识别和生态评估。
- 教育:AI 机器学习技术可以用于智能教育辅导、学习分析、教育内容推荐等,提高教学质量和个人学习能力。
- 医疗诊断:AI 机器学习技术可以辅助医生进行疾病诊断,提高诊断准确率和治疗效果。
- 网络安全:AI 机器学习技术在入侵检测、恶意代码分析、网络流量监控等方面具有重要意义。
- 艺术创作:AI 机器学习技术在生成艺术、音乐生成、绘画等方面具有潜力,为艺术家提供新的创作工具和思路。
- 农业领域:AI 机器学习技术在智能农业、作物病虫害预测、农业自动化等方面具有价值。
总之,AI 机器学习技术具有广泛的应用场景和前景,随着技术的不断发展,其在各个领域的应用将更加广泛,为人类带来更多便利和创新。
3、机器学习面对的挑战
挑战:
- 数据隐私和安全:在数据收集、存储和处理过程中,保护用户隐私和数据安全成为重要挑战。
- 模型可解释性:AI 和机器学习模型往往具有很高的复杂性,解释模型决策的过程和结果对于提高透明度和信任度至关重要。
- 算法偏见和歧视:由于数据来源和训练过程中的偏见,AI 和机器学习模型可能出现不公平和歧视现象。
- 技术成熟度:AI 和机器学习技术仍处于快速发展阶段,需要不断优化和完善,以满足实际应用的需求。
- 人才培养:AI 和机器学习领域的人才供应与需求之间存在较大差距,人才培养成为制约行业发展的重要因素。
- 社会伦理和法律问题:随着 AI 和机器学习技术在各个领域的应用,如何解决伦理和法律问题日益凸显。
综上所述,AI 和机器学习技术在众多应用场景中具有广阔的前景,但同时也面临着诸多挑战。为了实现可持续发展和广泛应用,行业需要不断探索创新,解决技术和社会问题。
4、机器学习步骤
机器学习代码的编写可以分为以下几个步骤:
- 数据预处理:在编写机器学习代码之前,首先需要对原始数据进行预处理。这包括数据清洗、特征提取和特征缩放等操作。以下是一个简单的数据预处理代码示例:
import pandas as pd
# 读取数据
data = pd.read_csv('data.csv')
# 数据清洗
data = data.drop_duplicates()
data = data.drop_na()
# 特征提取
X = data.iloc[:, :-1].values
y = data.iloc[:, -1].values
# 特征缩放(标准化)
scaler = StandardScaler()
X = scaler.fit_transform(X)
- 模型选择与训练:根据任务需求选择合适的机器学习算法,然后使用训练数据对模型进行训练。以下是一个使用决策树算法(from sklearn.tree import DecisionTreeClassifier)进行训练的示例:
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建并训练决策树模型
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
# 使用训练好的模型进行预测
y_pred = clf.predict(X_test)
# 计算预测准确率
accuracy = accuracy_score(y_test, y_pred)
print("决策树模型预测准确率:", accuracy)
- 模型评估:使用测试数据评估模型的性能,如准确率、召回率、F1 分数等。以下是一个评估决策树模型准确率的示例:
from sklearn.metrics import accuracy_score
# 使用训练好的模型进行预测
y_pred = clf.predict(X_test)
# 计算预测准确率
accuracy = accuracy_score(y_test, y_pred)
print("决策树模型预测准确率:", accuracy)
- 模型优化:根据模型评估结果,对模型进行优化。这可能包括调整模型参数、使用更先进的算法或集成学习等。
- 实际应用:将训练好的模型应用于实际问题,如预测、分类、聚类等。以下是一个使用训练好的决策树模型进行预测的示例:
# 预测新数据
new_data = pd.DataFrame({'特征 1': [1, 2, 3], '特征 2': [4, 5, 6]})
new_data['预测结果'] = clf.predict(new_data.iloc[:, :-1].values)
print(new_data)
以上代码只是一个简单的机器学习项目示例,实际应用中可能需要根据具体任务和数据类型进行调整。此外,根据实际需求,您可能还需要学习更多的机器学习算法和高级技巧,如神经网络、深度学习、集成学习等。
5、语音识别具体步骤
语音识别是机器学习中的一个重要应用领域。下面是一个使用Python和简单方法的语音识别示例:
- 环境准备:
首先,确保安装了以下库:- numpy
- pandas
- matplotlib
- seaborn
- scikit-learn
- librosa
- 数据准备:
对于这个简单的示例,我们将使用一个预先准备好的数据集。这个数据集应该包含两个文件:一个包含语音特征的CSV文件和一个包含对应语音标签的CSV文件。 - 特征提取:
使用librosa库来提取语音特征。通常,我们会使用梅尔频谱系数(Mel-frequency cepstral coefficients (MFCCs))作为特征。 - 模型训练:
使用scikit-learn库中的分类器(如SVM、 Random Forest等)来训练模型。 - 模型评估:
使用测试集评估模型的性能。
现在,让我们开始实施这个示例:
1. 环境准备
首先,确保您已经安装了上述库。您可以使用以下命令来安装它们:
pip install numpy pandas matplotlib seaborn scikit-learn librosa
2. 数据准备
假设您已经有一个名为speech_data.csv的CSV文件,其中包含语音特征,以及一个名为speech_labels.csv的CSV文件,其中包含对应的语音标签。
3. 特征提取
我们可以使用librosa库来提取MFCC特征。以下是一个简单的特征提取脚本:
import librosa
import librosa.display
import numpy as np
def extract_mfcc(file_path, n_mfcc=13):# 加载音频文件y, sr = librosa.load(file_path, sr=None)# 计算MFCCmfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=n_mfcc)# 返回MFCC的平均值和标准差return mfccs.mean(axis=1), mfccs.std(axis=1)
# 加载数据
data = pd.read_csv('speech_data.csv')
labels = pd.read_csv('speech_labels.csv')
# 提取MFCC特征
mfcc_features = []
for i, row in data.iterrows():file_path = row['file_path']mfcc_mean, mfcc_std = extract_mfcc(file_path)mfcc_features.append(np.hstack([mfcc_mean, mfcc_std]))
# 转换为DataFrame
mfcc_features = pd.DataFrame(mfcc_features)
4. 模型训练
我们可以使用scikit-learn中的SVM分类器来训练模型。以下是训练模型的脚本:
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 准备数据
X = mfcc_features
y = labels['label']
# 分割训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练SVM分类器
clf = SVC(kernel='linear', C=1)
clf.fit(X_train, y_train)
# 预测
y_pred = clf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy * 100:.2f}%")
5. 模型评估
您可以使用测试集评估模型的性能。您可以根据需要调整模型参数或尝试其他分类器来优化性能。
这只是一个简单的示例,实际应用中的语音识别系统可能更复杂。实际应用中,您可能需要使用深度学习模型(如卷积神经网络)和更大的数据集来获得更好的性能。
6、语音识别相关资料
语音识别是人工智能领域的一个关键方向,涉及到大量的机器学习和深度学习技术。下面提供一个关于语音识别的概述,包括学习资料、开源技术和完整代码介绍,以及如何进行调优和案例分享。
1. 学习资料
- 书籍:
- 《Speech Recognition: A Machine Learning Approach》 - Michael A. Riley
- 《Speech Processing: A Practical Guide to信号 Processing in Speech Recognition》 - Tomoki Hayashi
- 在线课程:
- Coursera上的"Deep Learning for Natural Language Processing"
- edX上的"Introduction to Deep Learning"
- 研究论文:
- “Deep Learning for Speech Recognition: A Review” - Yoshua Bengio et al. (2017)
- “End-to-End Speech Recognition in TensorFlow” - TensorFlow.org
2. 开源技术
- TensorFlow: 谷歌的TensorFlow框架是一个流行的深度学习库,支持语音识别任务。
- Keras: Keras是一个高级神经网络API,可以在TensorFlow或其他后端上运行。
- PyTorch: PyTorch是另一个流行的深度学习框架,也可以用于语音识别。
- ESPNet: ESPNet是一个基于PyTorch的语音处理库,包括语音识别功能。
3. 完整代码介绍
- TensorFlow Example:
import tensorflow as tf# Load your dataset dataset = ...# Build your model model = tf.keras.Sequential([tf.keras.layers.Dense(64, activation='relu', input_shape=(40, 1)),tf.keras.layers.Dense(64, activation='relu'),tf.keras.layers.Dense(len(dataset.class_names)) ])# Compile the model model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])# Train the model model.fit(dataset) - PyTorch Example:
import torch import torch.nn as nn import torch.optim as optim# Load your dataset dataset = ...# Define your model class SpeechRecognitionModel(nn.Module):def __init__(self):super(SpeechRecognitionModel, self).__init__()self.fc1 = nn.Linear(40, 64)self.fc2 = nn.Linear(64, 64)self.fc3 = nn.Linear(64, len(dataset.class_names))def forward(self, x):x = torch.relu(self.fc1(x))x = torch.relu(self.fc2(x))x = self.fc3(x)return x# Initialize the model, loss function, and optimizer model = SpeechRecognitionModel() criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters())# Train the model for epoch in range(num_epochs):for inputs, labels in dataset:optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()
4. 调优
- 数据增强: 对数据进行预处理,如添加噪声、时间反转、平滑处理等,可以增加训练样本数量。
- 模型结构调优: 尝试不同的网络结构,如卷积神经网络、递归神经网络等。
- 超参数调优: 使用超参数搜索算法,如GridSearch或RandomSearch,找到最优的超参数组合。
5. 案例分享
- 语音命令识别: 使用语音识别技术实现对用户命令的识别,如智能家居控制。
- 实时语音翻译: 将一种语言的语音翻译成另一种语言的文本。
- 会议记录: 将会议内容实时转录成文本。
以上就是关于语音识别的概述,希望能对您有所帮助!
相关文章:
AI机器学习 | 基于librosa库和使用scikit-learn库中的分类器进行语音识别
专栏集锦,大佬们可以收藏以备不时之需 Spring Cloud实战专栏:https://blog.csdn.net/superdangbo/category_9270827.html Python 实战专栏:https://blog.csdn.net/superdangbo/category_9271194.html Logback 详解专栏:https:/…...
Asp.net MVC Api项目搭建
整个解决方案按照分层思想来划分不同功能模块,以提供User服务的Api为需求,各个层次的具体实现如下所示: 1、新建数据库User表 数据库使用SQLExpress版本,表的定义如下所示: CREATE TABLE [dbo].[User] ([Id] …...

C语言中文网 - Shell脚本 - 8
第1章 Shell基础(开胃菜) 8. Linux Shell命令提示符 启动 Linux 桌面环境自带的终端模拟包,或者从 Linux 控制台登录后,便可以看到 Shell 命令提示符。看见命令提示符就意味着可以输入命令了。命令提示符不是命令的一部分&#x…...

性能测试学习——项目环境搭建和Jmete学习二
项目环境搭建、Jmeter学习二 环境的部署虚拟机的安装虚拟机中添加项目操作步骤 使用环境的注意事项Jmeter的安装和简单使用Jemter的使用的进阶Jemter元件 Jmeter属性执行顺序和作用域作用域以自定义用户变量和用户参数(前置处理器)为例如何解决用户变量和线程组同级时ÿ…...
-map介绍)
C++标准模板库(STL)-map介绍
C标准库中的map是一种关联容器,它提供了键值对的映射关系。每个键值对中的键都是唯一的,通过键可以访问对应的值。 map基本操作 插入元素: 使用insert函数插入元素,该函数有两种形式: // 插入一个pair<const Ke…...
使用docker部署ELK日志框架-Elasticsearch
一、ELK知识了解 1-ELK组件 工作原理: (1)在所有需要收集日志的服务器上部署Logstash;或者先将日志进行集中化管理在日志服务器上,在日志服务器上部署 Logstash。 (2)Logstash 收集日志&#…...

第7章 模式匹配与正则表达式
目录 1. 不用正则表达式来查找文本模式2. 用正则表达式来查找文本模式2.1 创建正则表达式(Regex)对象2.2 匹配Regex对象 3. 用正则表达式匹配更多模式3.1 利用括号分组3.2 用管道匹配多个分组3.3 用问号实现可选匹配3.4 用星号匹配零次或多次3.5 用加号匹…...
JPA 的测试)
单元测试实战(三)JPA 的测试
为鼓励单元测试,特分门别类示例各种组件的测试代码并进行解说,供开发人员参考。 本文中的测试均基于JUnit5。 单元测试实战(一)Controller 的测试 单元测试实战(二)Service 的测试 单元测试实战&am…...

初刷leetcode题目(3)——数据结构与算法
😶🌫️😶🌫️😶🌫️😶🌫️Take your time ! 😶🌫️😶🌫️😶🌫️😶🌫️…...
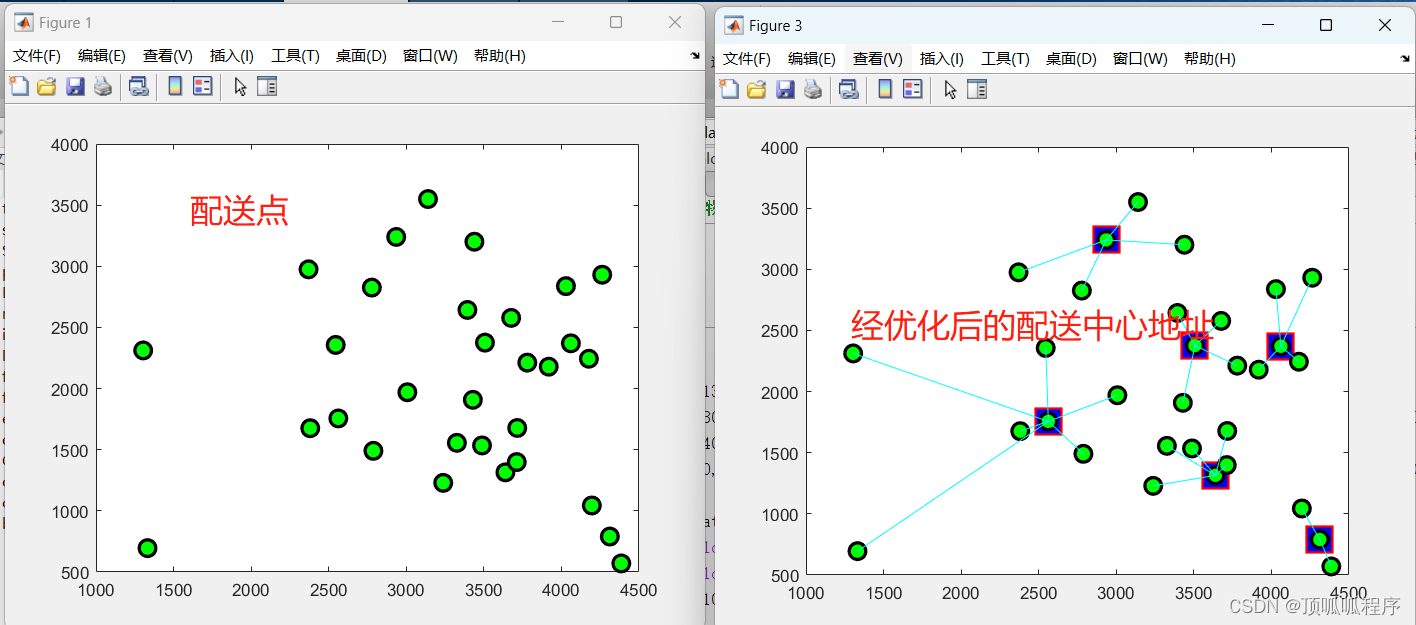
76基于matlab的免疫算法求解配送中心选址问题,根据配送地址确定最佳配送中心地址位置。
基于matlab的免疫算法求解配送中心选址问题,根据配送地址确定最佳配送中心地址位置。数据可更换自己的,程序已调通,可直接运行。 76matlab免疫算法配送中心选址 (xiaohongshu.com)...

C++二分查找算法:找到 Alice 和 Bob 可以相遇的建筑
本文涉及的基础知识点 二分查找算法合集 离线查询 题目 给你一个下标从 0 开始的正整数数组 heights ,其中 heights[i] 表示第 i 栋建筑的高度。 如果一个人在建筑 i ,且存在 i < j 的建筑 j 满足 heights[i] < heights[j] ,那么这个…...

建立跨层全栈的区块链安全保障系统-应用层,系统层,设施层
目录 建立跨层全栈的区块链安全保障系统 应用层 系统层 设施层...
程序员告诉你:人工智能是什么?
随着科技的快速发展,人工智能这个词汇已经逐渐融入了我们的日常生活。然而,对于大多数人来说,人工智能仍然是一个相对模糊的概念。 首先,让我们从人工智能的定义开始。人工智能是一种模拟人类智能的技术,它涵盖了多个领…...
飞书开发学习笔记(七)-添加机器人及发送webhook消息
飞书开发学习笔记(七)-添加机器人及发送webhook消息 一.添加飞书机器人 1.1 添加飞书机器人过程 在群的右上角点击折叠按键…选择 设置 群机器人中选择 添加机器人 选择自定义机器人,通过webhook发送消息 弹出的信息中有webhook地址,选择复制。 安…...

C/C++统计数 2021年12月电子学会青少年软件编程(C/C++)等级考试一级真题答案解析
目录 C/C统计数 一、题目要求 1、编程实现 2、输入输出 二、算法分析 三、程序编写 四、程序说明 五、运行结果 六、考点分析 C/C统计数 2021年12月 C/C编程等级考试一级编程题 一、题目要求 1、编程实现 给定一个数的序列S,以及一个区间[L, R], 求序列…...
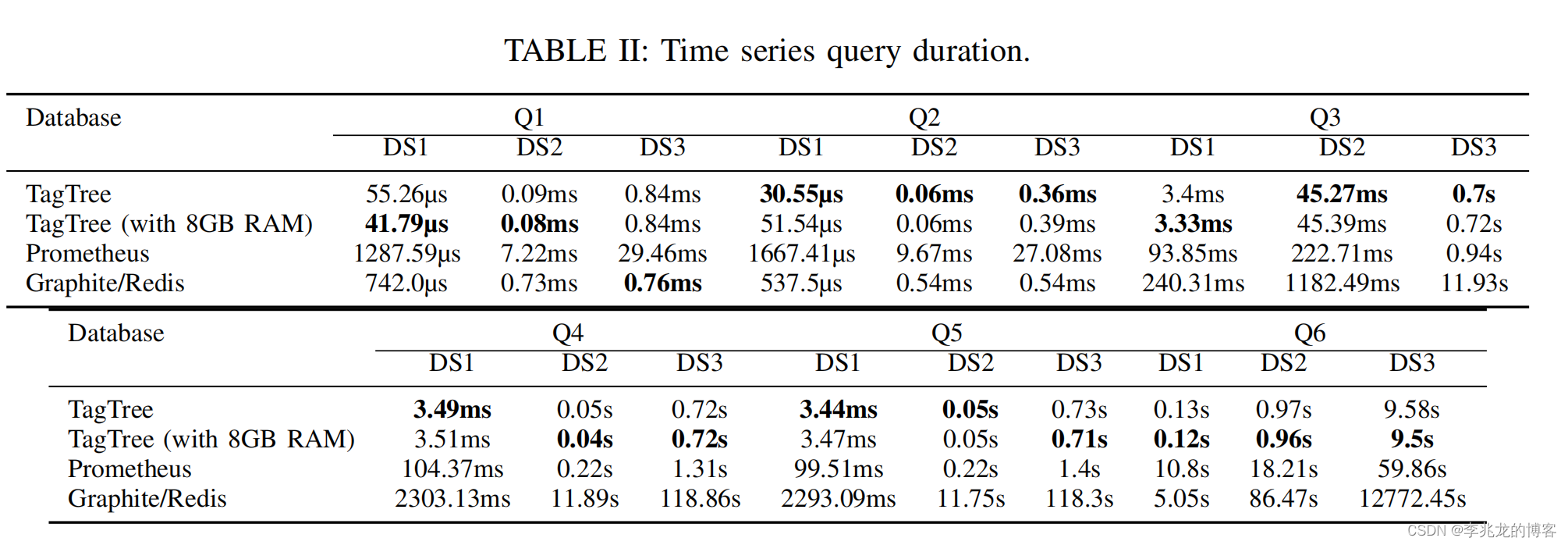
从一到无穷大 #19 TagTree,倒排索引入手是否是优化时序数据库查询的通用方案?
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。 本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。 文章目录 文章主旨时序数据库查询的一般流程扫描维度聚合时间聚合管控语句 TagTree整体结构索引…...
程序员带你入门人工智能
随着人工智能技术的飞速发展,越来越多的程序员开始关注并学习人工智能。作为程序员,我们可能会对如何开始了解人工智能感到困惑。今天,我将向大家介绍一些如何通过自学了解人工智能的经验和方法,帮助大家更好地入门这个充满挑战和…...

机器学习笔记 - 了解常见开源文本识别数据集以及了解如何创建用于文本识别的合成数据
一、部分开源数据集 以下是一些英文可用的开源文本识别数据集。 ICDAR 数据集:ICDAR 代表国际文档分析和识别会议。该活动每两年举行一次。他们带来了一系列塑造了研究社区的场景文本数据集。例如, ICDAR-2013和ICDAR-2015数据集。 MJSynth 数据集:该合成词数据集由牛津大…...

openssl开发详解
文章目录 一、openssl 开发环境二、openssl随机数生成三、openssl对称加密3.1 SM43.2 AES3.3 DES3.4 3DES 四、openssl非对称加密4.1 SM24.2 RSA4.3 ECC 五、openssl的hash5.1 SM35.2 md55.3 sha256 五、证书5.1 证书格式 六、openssl网络编程七、openssl调试FIDO流程 一、open…...

conda虚拟环境中安装的cuda和服务器上安装的cuda的异同
服务器上已安装Nvidia提供的cuda,nvcc -V时会出现已安装的CUDA版本。如下图所示,服务器上已安装好的cuda版本为10.1。 但是当我们在Anaconda虚拟环境下安装pytorch或者paddlepaddle等深度学习框架的GPU版本时,通常会选择较高版本的cuda&…...

在Node.js后端服务中集成Taotoken调用多种大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js后端服务中集成Taotoken调用多种大模型 对于Node.js后端开发者而言,将大模型能力集成到Express、Koa或Fastif…...

DS4Windows终极方案:DualShock 4在PC平台的完全指南
DS4Windows终极方案:DualShock 4在PC平台的完全指南 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 在当今多平台游戏生态中,手柄兼容性已成为玩家体验的关键瓶颈。…...

刚刚,马斯克第三代星舰首飞成功!
克雷西 发自 凹非寺量子位 | 公众号 QbitAI刚刚,马斯克的第十二次星舰试验,也是第三代星舰的首次飞行,顺利完成!当地时间昨天下午5点30分(北京时间今早6点30分),33台猛禽3发动机同时点火&#x…...

UABEA深度指南:Unity AssetBundle资源提取与序列化层逆向分析
1. 为什么Unity开发者总在“找资源”上浪费半天——UABEA不是万能钥匙,但它是你最该先摸清的那把 Unity项目交付后,美术资源、音频片段、UI图集、甚至脚本逻辑,常常被打包进AssetBundle(.unity3d)、Resources文件夹或更…...

从文本到流程:NLP与LLM驱动的业务流程模型自动提取技术
1. 项目概述与核心价值在业务流程管理(BPM)的日常工作中,我们经常遇到一个经典难题:业务部门或客户给出一大段文字描述,比如一份操作手册、一封需求邮件或一次会议纪要,我们需要从中梳理出清晰、可执行的业…...

B物理反常的全局拟合:有效场论与机器学习解析新物理信号
1. 项目概述:当B介子衰变“不听话”时,我们如何用数学语言寻找新物理?在粒子物理的精密前沿,标准模型(Standard Model, SM)一直是我们理解微观世界最成功的理论框架。然而,物理学家们从未停止过…...

统信UOS/麒麟KOS截图快捷键失灵?别慌,试试这个后台进程清理大法
统信UOS/麒麟KOS截图快捷键失灵?三步精准定位僵尸进程早上9点,你正急着截取屏幕上的报错信息发给技术同事,却发现按下CtrlAltA后毫无反应——这不是个例。国内主流操作系统如统信UOS、麒麟KOS的用户常会遇到这类"幽灵故障"…...

VR交互框架VRF:输入抽象、物理建模与多端同步工程实践
1. 这不是又一个“VR按钮点击Demo”,而是一套能直接进产线的交互骨架我第一次在客户现场看到用Unity裸写VR交互逻辑的项目,是在2021年冬天。那是个工业培训场景,需要让学员用手柄抓取虚拟阀门、旋转、再插入对应接口——听起来简单࿰…...

Ubuntu 22.04双网卡配置踩坑记:netplan apply报错‘默认路由冲突’的三种解法
Ubuntu 22.04双网卡路由冲突实战指南:从紧急修复到高阶策略当你为Ubuntu服务器配置双网卡时,netplan apply命令突然抛出"Conflicting default route declarations for IPv4"错误,这种场景对运维工程师来说再熟悉不过。本文将带你深…...

从线性智能到多维能力光谱:重新理解AI的“陌生性”与工程实践
1. 项目概述:重新审视智能的“陌生性”在人工智能领域,我们似乎总在追逐一个幽灵般的“通用智能”(AGI)——一个能在所有认知任务上媲美甚至超越人类的系统。这种想象往往基于一个根深蒂固的线性模型:智能是一个单一的…...