ClickHouse SQL 查询优化
1 单表查询
1.1 Prewhere替代where
Prewhere和where语句的作用相同,用来过滤数据。不同之处在于prewhere只支持 *MergeTree 族系列引擎的表,首先会读取指定的列数据,来判断数据过滤,等待数据过滤之后再读取select 声明的列字段来补全其余属性。
当查询列明显多于筛选列时使用Prewhere可十倍提升查询性能,Prewhere会自动优化执行过滤阶段的数据读取方式,降低io操作。
在某些场合下,prewhere语句比where语句处理的数据量更少性能更高。
#关闭where自动转prewhere(默认情况下, where条件会自动优化成prewhere)
set optimize_move_to_prewhere=0;
# 使用where
select WatchID,
JavaEnable,
Title,
GoodEvent,
EventTime,
EventDate,
CounterID,
ClientIP,
ClientIP6,
RegionID,
UserID,
CounterClass,
OS,
UserAgent,
URL,
Referer,
URLDomain,
RefererDomain,
Refresh,
IsRobot,
RefererCategories,
URLCategories,
URLRegions,
RefererRegions,
ResolutionWidth,
ResolutionHeight,
ResolutionDepth,
FlashMajor,
FlashMinor,
FlashMinor2
from datasets.hits_v1 where UserID='3198390223272470366';# 使用prewhere关键字
select WatchID,
JavaEnable,
Title,
GoodEvent,
EventTime,
EventDate,
CounterID,
ClientIP,
ClientIP6,
RegionID,
UserID,
CounterClass,
OS,
UserAgent,
URL,
Referer,
URLDomain,
RefererDomain,
Refresh,
IsRobot,
RefererCategories,
URLCategories,
URLRegions,
RefererRegions,
ResolutionWidth,
ResolutionHeight,
ResolutionDepth,
FlashMajor,
FlashMinor,
FlashMinor2
from datasets.hits_v1 prewhere UserID='3198390223272470366';
默认情况,我们肯定不会关闭where自动优化成prewhere,但是某些场景即使开启优化,也不会自动转换成prewhere,需要手动指定prewhere:
- 使用常量表达式
- 使用默认值为alias类型的字段
- 包含了arrayJOIN,globalIn,globalNotIn或者indexHint的查询
- select查询的列字段和where的谓词相同
- 使用了主键字段
1.2 数据采样
通过采样运算可极大提升数据分析的性能
SELECT Title,count(*) AS PageViews
FROM hits_v1
SAMPLE 0.1 #代表采样10%的数据,也可以是具体的条数
WHERE CounterID =57
GROUP BY Title
ORDER BY PageViews DESC LIMIT 1000
采样修饰符只有在MergeTree engine表中才有效,且在创建表时需要指定采样策略。
1.3 列裁剪与分区裁剪
数据量太大时应避免使用select * 操作,查询的性能会与查询的字段大小和数量成线性表换,字段越少,消耗的io资源越少,性能就会越高。
反例:
select * from datasets.hits_v1;
正例:
select WatchID,
JavaEnable, Title,
GoodEvent,
EventTime,
EventDate,
CounterID,
ClientIP,
ClientIP6,
RegionID,
UserID
from datasets.hits_v1;
分区裁剪就是只读取需要的分区,在过滤条件中指定。
select WatchID,
JavaEnable, Title,
GoodEvent,
EventTime,
EventDate,
CounterID,
ClientIP,
ClientIP6,
RegionID,
UserID
from datasets.hits_v1
where EventDate='2014-03-23';
1.4 orderby 结合 where、limit
千万以上数据集进行order by查询时需要搭配where条件和limit语句一起使用。
#正例:
SELECT UserID,Age
FROM hits_v1
WHERE CounterID=57
ORDER BY Age DESC LIMIT 1000#反例:
SELECT UserID,Age
FROM hits_v1
ORDER BY Age DESC
1.5 避免构建虚拟列
如非必须,不要在结果集上构建虚拟列,虚拟列非常消耗资源浪费性能,可以考虑在前端进行处理,或者在表中构造实际字段进行额外存储。
反例:
SELECT Income,Age,Income/Age as IncRate FROM datasets.hits_v1;
正例:拿到Income和Age后,考虑在前端进行处理,或者在表中构造实际字段进行额外存储
SELECT Income,Age FROM datasets.hits_v1;
1.6 uniqCombined替代distinct
性能可提升10倍以上,uniqCombined底层采用类似HyperLogLog算法实现,能接收2%左右的数据误差,可直接使用这种去重方式提升查询性能。Count(distinct )会使用uniqExact精确去重。
不建议在千万级不同数据上执行distinct去重查询,改为近似去重uniqCombined
反例:
select count(distinct rand()) from hits_v1;
正例:
SELECT uniqCombined(rand()) from datasets.hits_v1
1.7 使用物化视图
参考第6章。
1.8 其他注意事项
(1)查询熔断
为了避免因个别慢查询引起的服务雪崩的问题,除了可以为单个查询设置超时以外,还可以配置周期熔断,在一个查询周期内,如果用户频繁进行慢查询操作超出规定阈值后将无法继续进行查询操作。
(2)关闭虚拟内存
物理内存和虚拟内存的数据交换,会导致查询变慢,资源允许的情况下关闭虚拟内存。
(3)配置join_use_nulls
为每一个账户添加 join_use_nulls 配置,左表中的一条记录在右表中不存在,右表的相应字段会返回该字段相应数据类型的默认值,而不是标准SQL中的Null值。
(4)批量写入时先排序
批量写入数据时,必须控制每个批次的数据中涉及到的分区的数量,在写入之前最好对需要导入的数据进行排序。无序的数据或者涉及的分区太多,会导致ClickHouse无法及时对新导入的数据进行合并,从而影响查询性能。
(5)关注CPU
cpu一般在50%左右会出现查询波动,达到70%会出现大范围的查询超时,cpu是最关键的指标,要非常关注。
2 多表关联
2.1 准备表和数据
#创建小表
CREATE TABLE visits_v2
ENGINE = CollapsingMergeTree(Sign)
PARTITION BY toYYYYMM(StartDate)
ORDER BY (CounterID, StartDate, intHash32(UserID), VisitID)
SAMPLE BY intHash32(UserID)
SETTINGS index_granularity = 8192
as select * from visits_v1 limit 10000;#创建join结果表:避免控制台疯狂打印数据
CREATE TABLE hits_v2
ENGINE = MergeTree()
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))
SAMPLE BY intHash32(UserID)
SETTINGS index_granularity = 8192
as select * from hits_v1 where 1=0;
2.2 用 IN 代替 JOIN
当多表联查时,查询的数据仅从其中一张表出时,可考虑用 IN 操作而不是JOIN
insert into hits_v2
select a.* from hits_v1 a where a. CounterID in (select CounterID from visits_v1);#反例:使用join
insert into table hits_v2
select a.* from hits_v1 a left join visits_v1 b on a. CounterID=b. CounterID;
2.3 大小表JOIN
多表join时要满足小表在右的原则,右表关联时被加载到内存中与左表进行比较,ClickHouse中无论是Left join 、Right join 还是 Inner join 永远都是拿着右表中的每一条记录到左表中查找该记录是否存在,所以右表必须是小表。
(1)小表在右
insert into table hits_v2
select a.* from hits_v1 a left join visits_v2 b on a. CounterID=b. CounterID;
(2)大表在右
insert into table hits_v2
select a.* from visits_v2 b left join hits_v1 a on a. CounterID=b. CounterID;
2.4 注意谓词下推(版本差异)
ClickHouse在join查询时不会主动发起谓词下推的操作,需要每个子查询提前完成过滤操作,需要注意的是,是否执行谓词下推,对性能影响差别很大(新版本中已经不存在此问题,但是需要注意谓词的位置的不同依然有性能的差异)
Explain syntax
select a.* from hits_v1 a left join visits_v2 b on a. CounterID=b. CounterID
having a.EventDate = '2014-03-17';Explain syntax
select a.* from hits_v1 a left join visits_v2 b on a. CounterID=b. CounterID
having b.StartDate = '2014-03-17';insert into hits_v2
select a.* from hits_v1 a left join visits_v2 b on a. CounterID=b. CounterID
where a.EventDate = '2014-03-17';insert into hits_v2
select a.* from (select * from
hits_v1 where EventDate = '2014-03-17'
) a left join visits_v2 b on a. CounterID=b. CounterID;
2.5 分布式表使用GLOBAL
两张分布式表上的IN和JOIN之前必须加上GLOBAL关键字,右表只会在接收查询请求的那个节点查询一次,并将其分发到其他节点上。如果不加GLOBAL关键字的话,每个节点都会单独发起一次对右表的查询,而右表又是分布式表,就导致右表一共会被查询N²次(N是该分布式表的分片数量),这就是查询放大,会带来很大开销。
2.6 使用字典表
将一些需要关联分析的业务创建成字典表进行join操作,前提是字典表不宜太大,因为字典表会常驻内存
2.7 提前过滤
通过增加逻辑过滤可以减少数据扫描,达到提高执行速度及降低内存消耗的目的
相关文章:

ClickHouse SQL 查询优化
1 单表查询 1.1 Prewhere替代where Prewhere和where语句的作用相同,用来过滤数据。不同之处在于prewhere只支持 *MergeTree 族系列引擎的表,首先会读取指定的列数据,来判断数据过滤,等待数据过滤之后再读取select 声明的列字段来补…...
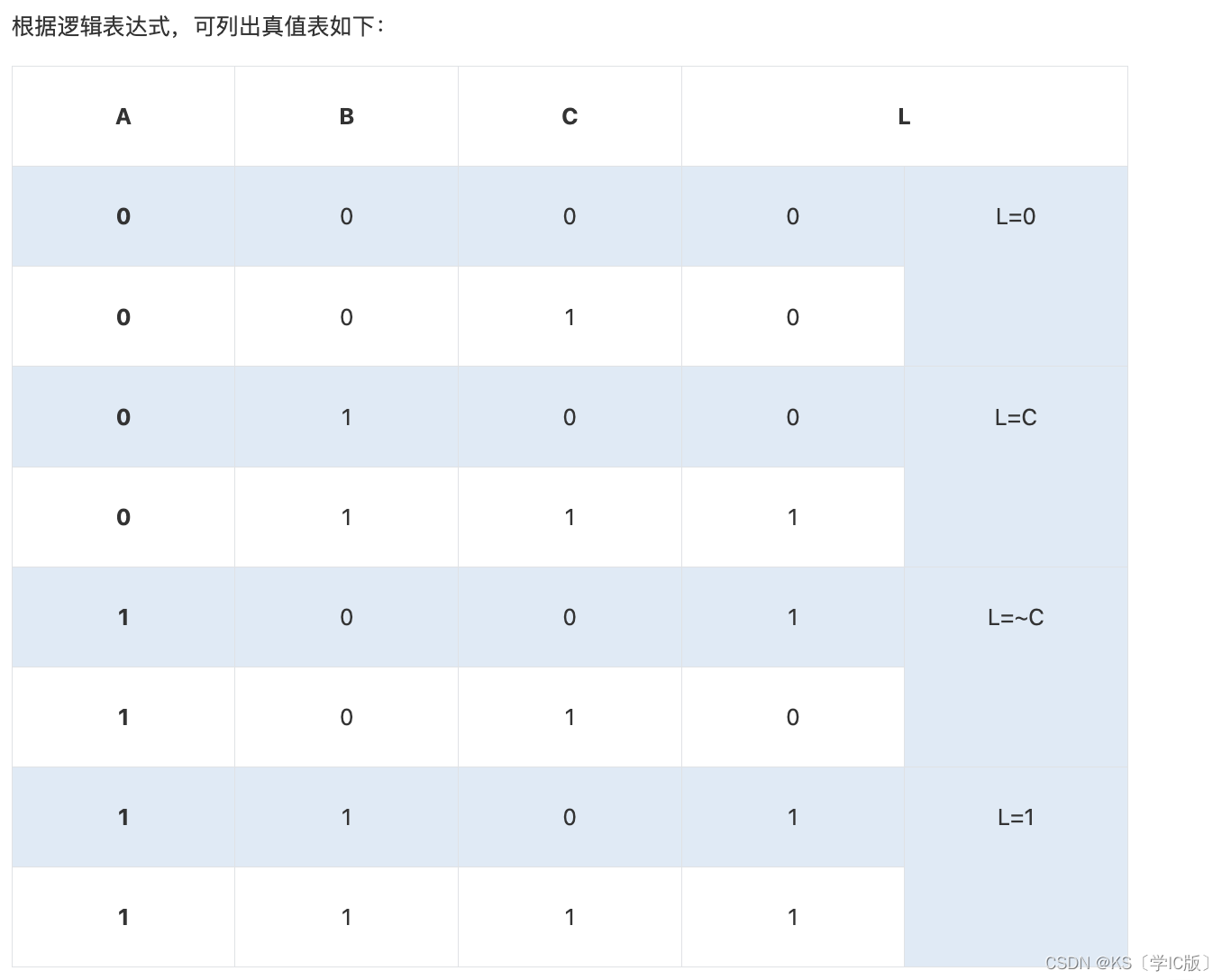
「Verilog学习笔记」数据选择器实现逻辑电路
专栏前言 本专栏的内容主要是记录本人学习Verilog过程中的一些知识点,刷题网站用的是牛客网 分析 将变量A、B接入4选1数据选择器选择输入端S0 S1。将变量C分配在数据输入端。从表中可以看出输出L与变量C的关系。 当AB00时选通D0而此时L0,所以数据端D0接0…...
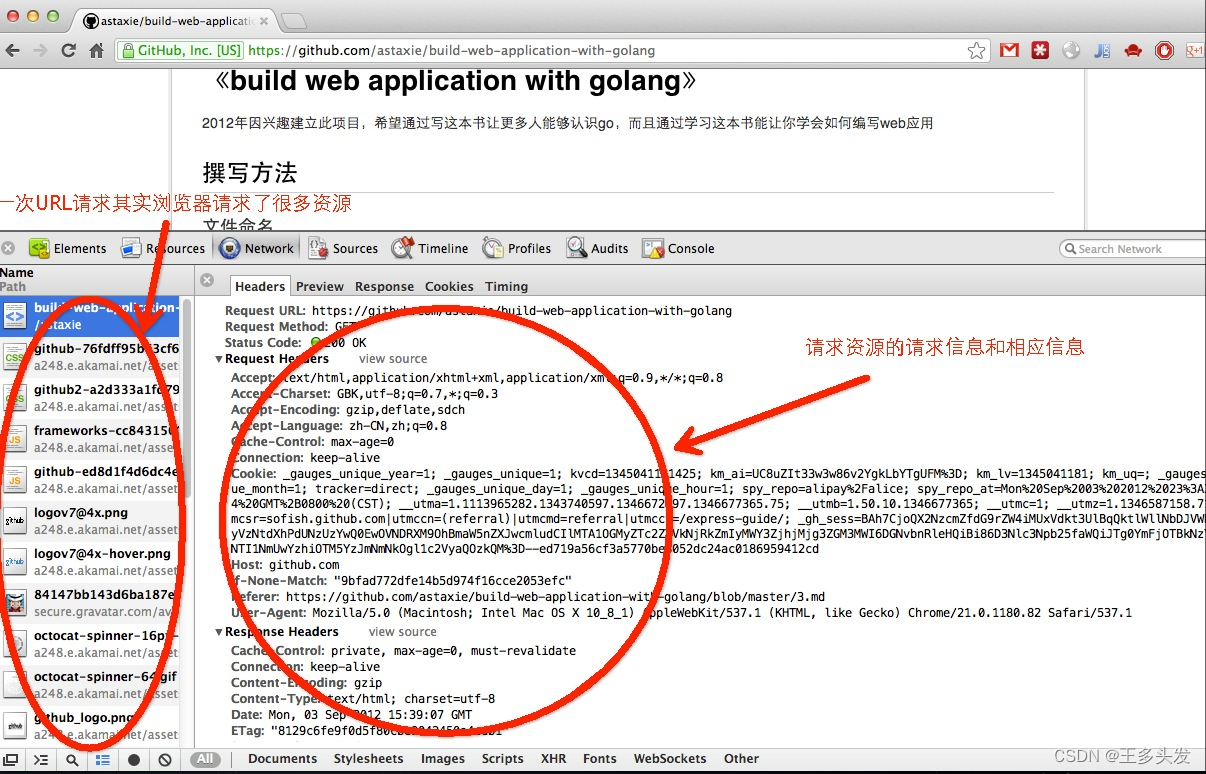
【Go入门】Web工作方式
【Go入门】 Web工作方式 我们平时浏览网页的时候,会打开浏览器,输入网址后按下回车键,然后就会显示出你想要浏览的内容。在这个看似简单的用户行为背后,到底隐藏了些什么呢? 对于普通的上网过程,系统其实是这样做的&…...
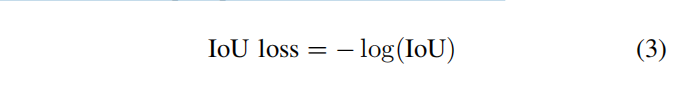
综述:目标检测二十年(机翻版)(未完
原文地址 20年来的目标检测:一项调查 摘要关键词一 介绍二 目标检测二十年A.一个目标检测的路线图1)里程碑:传统探测器Viola Jones探测器HOG检测器基于可变形零件的模型(DPM) 2)里程碑:基于CNN的两阶段探测器RCNNSPPN…...
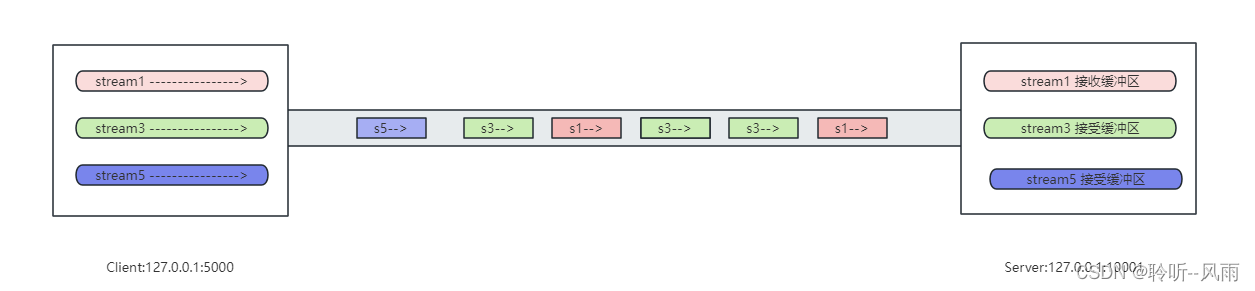
quinn源码解析:QUIC数据包是如何发送的
quinn源码解析:QUIC数据包是如何发送的 简介QUIC协议中的概念endpoint(端点)connection(连接)Stream(流)Frame (帧) 发包过程解析SendStream::write_allConnectionDriverEndpointDriver 简介 q…...

scss的高级用法——循环
周末愉快呀!一起来学一点简单但非常有用的css小知识。 最近在一个项目中看到以下css class写法: 了解过tailwind css或者unocss的都知道,从命名就可以看出有以下样式: font-size: 30pxmargin-left: 5px;margin-top: 10px; 于是…...

Linux安装Chrome浏览器 -linux安装choeme
Linux 操作系统一般自带的浏览器是 FireFox,不过有些用户可能更喜欢 Google 出品的 Chrome 浏览器。本教程将介绍如何在 Linux 系统上安装 Chrome 浏览器,以及可能会遇到的一些问题解决方案。 下载 Chrome 安装包 需要下载 Chrome 的安装包。可以在 Go…...

六大排序(插入排序、希尔排序、冒泡排序、选择排序、堆排序、快速排序)未完
文章目录 排序一、 排序的概念1.排序:2.稳定性:3.内部排序:4.外部排序: 二、插入排序1.直接插入排序2.希尔排序 三、选择排序1.直接选择排序方法一方法二直接插入排序和直接排序的区别 2.堆排序 四、交换排序1.冒泡排序2.快速排序…...
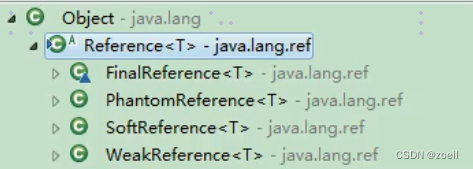
JVM垃圾回收相关概念
目录 一、System.gc()的理解 二、内存溢出与内存泄露 (一)OOM (二)内存泄露 三、StopTheWorld 四、垃圾回收的并行与并发 五、安全点与安全区域 (一)安全点 (二)安全区域 …...
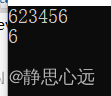
C++各种字符转换
C各种字符转换 一.如何将char数组转化为string类型二. string转char数组:参考 一.如何将char数组转化为string类型 在C中,可以使用string的构造函数或者赋值操作符来将char数组转换为string类型。 方法1:使用string的构造函数 const char* c…...

MSSQL-逻辑级常用命令
--SQL Server 查询表的记录数 --one: 使用系统表. SELECT object_name (i.id) TableName, rows as RowCnt FROM sysindexes i INNER JOIN sysObjects o ON (o.id i.id AND o.xType U ) WHERE indid < 2 ORDER BY rows desc ————————————…...

【如何学习Python自动化测试】—— 时间等待
3 、 时间等待 在做自动化测试时,难免会碰到一些问题,比如你在脚本中操作某个对象时, 页面还没有加载出来,你的操作语句已经被执行,从而导致脚本执行失败,针对这样的问题 webdriver 提供了等待操作…...

《数字图像处理-OpenCV/Python》连载(44)图像的投影变换
《数字图像处理-OpenCV/Python》连载(44)图像的投影变换 本书京东优惠购书链接:https://item.jd.com/14098452.html 本书CSDN独家连载专栏:https://blog.csdn.net/youcans/category_12418787.html 第 6 章 图像的几何变换 几何变…...

AI机器学习 | 基于librosa库和使用scikit-learn库中的分类器进行语音识别
专栏集锦,大佬们可以收藏以备不时之需 Spring Cloud实战专栏:https://blog.csdn.net/superdangbo/category_9270827.html Python 实战专栏:https://blog.csdn.net/superdangbo/category_9271194.html Logback 详解专栏:https:/…...
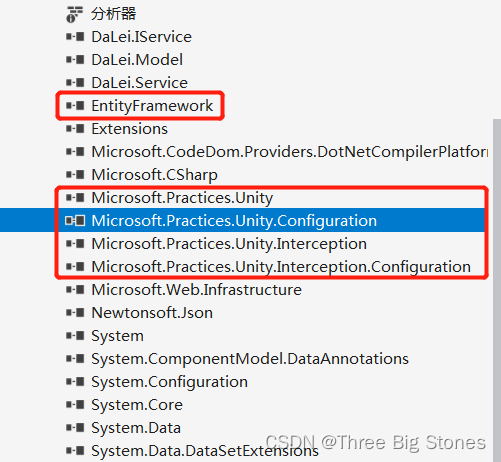
Asp.net MVC Api项目搭建
整个解决方案按照分层思想来划分不同功能模块,以提供User服务的Api为需求,各个层次的具体实现如下所示: 1、新建数据库User表 数据库使用SQLExpress版本,表的定义如下所示: CREATE TABLE [dbo].[User] ([Id] …...

C语言中文网 - Shell脚本 - 8
第1章 Shell基础(开胃菜) 8. Linux Shell命令提示符 启动 Linux 桌面环境自带的终端模拟包,或者从 Linux 控制台登录后,便可以看到 Shell 命令提示符。看见命令提示符就意味着可以输入命令了。命令提示符不是命令的一部分&#x…...

性能测试学习——项目环境搭建和Jmete学习二
项目环境搭建、Jmeter学习二 环境的部署虚拟机的安装虚拟机中添加项目操作步骤 使用环境的注意事项Jmeter的安装和简单使用Jemter的使用的进阶Jemter元件 Jmeter属性执行顺序和作用域作用域以自定义用户变量和用户参数(前置处理器)为例如何解决用户变量和线程组同级时ÿ…...
-map介绍)
C++标准模板库(STL)-map介绍
C标准库中的map是一种关联容器,它提供了键值对的映射关系。每个键值对中的键都是唯一的,通过键可以访问对应的值。 map基本操作 插入元素: 使用insert函数插入元素,该函数有两种形式: // 插入一个pair<const Ke…...
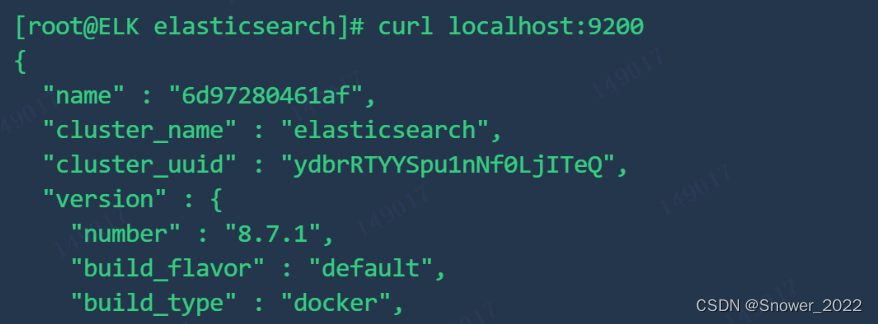
使用docker部署ELK日志框架-Elasticsearch
一、ELK知识了解 1-ELK组件 工作原理: (1)在所有需要收集日志的服务器上部署Logstash;或者先将日志进行集中化管理在日志服务器上,在日志服务器上部署 Logstash。 (2)Logstash 收集日志&#…...

第7章 模式匹配与正则表达式
目录 1. 不用正则表达式来查找文本模式2. 用正则表达式来查找文本模式2.1 创建正则表达式(Regex)对象2.2 匹配Regex对象 3. 用正则表达式匹配更多模式3.1 利用括号分组3.2 用管道匹配多个分组3.3 用问号实现可选匹配3.4 用星号匹配零次或多次3.5 用加号匹…...

范畴论与拓扑数据分析:统一聚类算法与捕捉数据形状的新范式
1. 项目概述:当聚类算法遇见范畴论与拓扑如果你在数据科学或机器学习领域摸爬滚打了一段时间,大概率对K-Means、DBSCAN、层次聚类这些名字已经烂熟于心。我们习惯于将它们视为一系列精妙的“算法黑箱”:输入数据点,调整几个超参数…...

基于多保真度机器学习与飞秒激光的光子表面逆向设计实践
1. 项目概述与核心价值在光子学和先进制造领域,我们常常面临一个核心挑战:如何根据一个理想的光学性能目标,比如特定的光谱吸收或发射曲线,反向找到能够实现这一目标的精确物理结构或制造工艺参数。这就是逆向设计的魅力所在。传统…...

Frida Hook Java层还原Android客户端签名算法
1. 这不是“调用API”,而是拆解签名生成的完整逻辑链 你有没有遇到过这种情况:App每次请求都带一个叫 api-sign 的字段,值像一串随机字符串,长度固定、格式规整,但无论你怎么翻网络请求日志、抓包重放、甚至改参数重…...

Wand-Enhancer终极指南:3分钟解锁WeMod完整专业功能
Wand-Enhancer终极指南:3分钟解锁WeMod完整专业功能 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer Wand-Enhancer是一款革命性的开源工具&a…...

统信UOS 1070系统克隆实战:用自带工具给电脑做个‘替身’,换机迁移不求人
统信UOS 1070系统克隆实战:用自带工具给电脑做个‘替身’,换机迁移不求人当企业批量采购新设备或个人用户升级电脑时,如何快速将原有系统环境完整迁移到新硬件?传统方案往往依赖第三方工具,而统信UOS 1070内置的备份还…...
)
客户旅程重构实战:用AI Agent打通投保、核保、续期、理赔全链路(含可落地的RPA+LLM融合架构图)
更多请点击: https://codechina.net 第一章:客户旅程重构实战:用AI Agent打通投保、核保、续期、理赔全链路(含可落地的RPALLM融合架构图) 传统保险业务流程中,投保表单录入、核保规则校验、续期提醒触发与…...

机器学习与模拟退火算法优化TPMS结构材料力学性能
1. 项目概述与核心价值在材料科学与先进制造领域,三周期极小曲面(Triply Periodic Minimal Surfaces, TPMS)结构正掀起一场设计革命。这类结构以其在三维空间内周期性重复、且具有极小表面积的特点,展现出传统实体材料难以企及的优…...

保险智能体部署失败率高达73%?揭秘头部险企AI Agent上线前必须完成的3个合规校验步骤
更多请点击: https://codechina.net 第一章:保险智能体部署失败率高达73%?揭秘头部险企AI Agent上线前必须完成的3个合规校验步骤 近期多家头部保险机构联合发布的《2024保险AI落地白皮书》指出,AI Agent在核心承保、核保与理赔场…...

强化学习实战:用Python手搓Sarsa和Q-Learning,在悬崖漫步里看谁更“怂”
强化学习实战:Python实现Sarsa与Q-Learning在悬崖漫步中的策略差异从游戏视角理解强化学习核心算法想象你正站在一个412的网格世界起点,目标是到达右下角的终点。但中间有一片"悬崖"——任何踏入都会让你回到起点并承受巨大惩罚。每走一步都会…...

Evident方法论:用观察、假设、测试构建可复现的数据科学工作流
1. 项目概述:为什么我们需要一种新的数据科学方法论?干了十多年数据科学和机器学习项目,从初创公司到大型企业都待过,我越来越觉得,我们这行当的“工作方式”有点不对劲。项目周期总是难以预估,代码和数据像…...