Hive调优
1.参数配置优化
设定Hive参数有三种方式:
(1)配置Hive文件
当修改配置Hive文件的设定后,对本机启动的所有Hive进程都有效,因此配置是全局性的。
一般地,Hive的配置文件包括两部分:
a)用户自定义配置文件:$HIVE_CONF_DIR/hive-site.xml
b)默认配置文件:$HIVE_CONF_DIR/hive-default.xml.template
# 当用户自定义配置后,会覆盖默认配置。
实际上,因为Hive是作为Hadoop的客户端环境下启动,而Hive的配置会覆盖
Hadoop的配置,因此这类修改配置的方式不推荐使用。
(2)命令行参数配置
命令行参数配置就是:启动Hive(客户端或Server方式)时,可以在命令行添加-hiveconf param=value来设定参数。比如:
hive --service hiveserver2 --hiveconf
hive.root.logger=DEBUG,console
需要注意的是,只要通过Beeline连接的这个hiveserver2的客户端,都具备这个配置参数的方式。
但这种配置方式,有一个存在问题,那就是:命令行参数配置的作用域是所有请求的Sessions会话内有效,即仅在当前窗口下生效,一旦关闭窗口,则失效。
(3)设定参数声明
通常地,在Hive中,设定参数声明需要使用到set关键字,比如:
-- 查看
set mapreduce.job.reduces;
-- 设定reduce数量
set mapreduce.job.reduces = 3;
(1)参数设置优先级
参数声明 > 命令行参数 > 配置文件参数
(2)参数设置范围大小
配置文件参数 > 命令行参数 > 参数声明
一般情况下,会在执行程序前使用set关键字来设定参数配置。
1.1 设定Fetch抓取策略
我们知道,执行Hive时,查询缓慢的主要原因是:执行了MapReduce计算。因此,
若想提高执行效率,可以避免执行MapReduce程序。
简单地说,设定了Fetch抓取策略的某些参数后,Hive可以避免走MapReduce程序,有效提升了执行效率。比如:
-- 设置Fetch本地抓取策略
hive.fetch.task.conversion = more;
当Fetch的这个属性修改为more值后,在全局查找、字段查找、limit查找等都不执行MapReduce计算。
hive.fetch.task.conversion属性值有3个选项:
(1)hive.fetch.task.conversion = more; [默认值]
可以保证在执行全表扫描、查询某几个列、执行简单查询、where条件且包括
limit操作时,都不会走MR
(2)hive.fetch.task.conversion = minimal;
保证执行全表扫描以及查询某几个列以及limit操作可以不走MR, 其他操作都会执
行MR
(3)hive.fetch.task.conversion = none;
全部查询操作,都执行MR
强烈建议当调试程序结束后,继续设定[hive.fetch.task.conversion =more;]结果。
-- select * from tb_taobao_log;
-- select * from tb_taobao_log where result_value>0; -- 没有
走mr , 自动优化
-- set hive.fetch.task.conversion = minimal;
-- 4
-- select * from tb_taobao_log; -- minimal状态很简单就不走mr
-- select * from tb_taobao_log where result_value>0; -- 走mr,
没有优化
set hive.fetch.task.conversion = none; -- 什么都不优化-- 5
select * from tb_taobao_log;
select * from tb_taobao_log where result_value>0;
/*
more: 普通查询、全表扫描、简单条件都不走mr, 自动优化; --执行效率提升
[默认]
minimal: 全表扫描不走mr, 其他一般都走
none: 所有的查询操作都走mr程序 -->底层
*/
-- 恢复默认
set hive.fetch.task.conversion = more;
(2)Fetch抓取策略已默认设定为more,因此当调试完程序后,记得恢复默认值more。
1.2设定本地模式
在应用中,大多数的Hadoop Job是需要Hadoop提供的完整可扩展性来处理大数据
集(TB)。不过,有时Hive的输入数据量是非常小的。
在这种情况下,为查询触发执行任务时,消耗资源可能会比实际Job的执行时间要多的多。
对于大多数的这种情况,Hive可以通过本地模式在单台机器上处理所有的任务。而对于小数据集,执行时间可以明显被缩短。
用户可以通过设置hive.exec.mode.local.auto的值为true,来让Hive在适当的时候,自动启动这个优化。
比如,设定本地模式时,可以设定如下参数:
-- 开启本地local mr
set hive.exec.mode.local.auto=true;
-- 设置local mr的最大输入数据量,当输入数据量小于这个值时采用local mr的
方式,默认为134217728,即128M
set hive.exec.mode.local.auto.inputbytes.max=134217728;
-- 设置local mr的最大输入文件个数,当输入文件个数小于这个值时采用local mr
的方式,默认为4
set hive.exec.mode.local.auto.input.files.max=4;
1.3数据压缩格式
为什么要对文件或目录进行压缩呢?
(1)便于集中处理;
(1)对于一个未执行任何压缩操作的1000MB文件, 当从路径A传输到路径B时,
假定网速100MB/s,
则传输总时长为10秒;
(2)对于一个未执行任何压缩操作的1000MB文件, 通过压缩后再传输操作完成: 从路
径A传输到路径B。
假定压缩效率330MB/s, 则1000MB压缩到100MB花费3秒,
到达指定路径后, 解压花费3秒,
则传输总时长为6秒。
(2)便于资料传输;
(3)便于阅读数据。
--开启hive支持中间结果的压缩方案
-- set hive.exec.compress.intermediate=true;
-- --开启hive支持最终结果压缩
-- set hive.exec.compress.output=true;
--
-- --开启MR的mapper端压缩操作
-- set mapreduce.map.output.compress=true;
-- --设置mapper端压缩的方案
-- set mapreduce.map.output.compress.codec=
org.apache.hadoop.io.compress.SnappyCodec;
-- -- 开启MR的reduce端的压缩方案
-- set mapreduce.output.fileoutputformat.compress=true;
--
-- -- 设置reduce端压缩的方案
-- set mapreduce.output.fileoutputformat.compress.codec =
org.apache.hadoop.io.compress.SnappyCodec;
-- --设置reduce的压缩类型
-- set mapreduce.output.fileoutputformat.compress.type=BLOCK;
一般地,设定数据文件的压缩格式时,仅需执行一些参数配置声明即可。
1.4数据存储格式
下行存储、列存储的一些特点:
(1)行式存储的特点:
查询满足条件的一整行数据时,行存储只需要找到其中一个值,其余的值都在相邻地方,
所以行存储查询和访问的效率更高;
(2)列式存储的特点:
因为每个字段的列数据都是聚集存储,当在查询仅需要少数几个字段时,能大大减少读取的数据量;
并且,每个字段的数据类型一定是相同的,
所以,列式存储可以针对性的设计出更好的存储格式、或设计压缩算法。
(1)行式存储格式
常用的行式存储格式为TEXTFILE
优点:相关的数据是保存在一起,比较符合面向对象的思维,因为一行数据就是一条记录。这种存储格式比较方便进行INSERT/UPDATE操作
缺点:如果查询只涉及某几个列,它会把整行数据都读取出来,不能跳过不必要的列读取。当然数据比较少,一般没啥问题,如果数据量比较大就比较影响性能。
(2)列式存储格式
常用的列式存储格式有ORC(Optimized Row Columnar)和PARQUET。一般地,ORC格式效果要比PARQUET压缩率更高!
优点:查询时,只有涉及到的列才会被查询,不会把所有列都查询出来,即可以跳过不必要的列查询。高效的压缩率,不仅节省储存空间也节省计算内存和CPU。
缺点:INSERT/UPDATE很麻烦或者不方便,不适合扫描小量的数据。
create [external] table 表名(
字段名 字段类型,
字段名 字段类型,
...
)
[row format delimited
fields terminated by '指定分隔符']
[stored as textfile] -- 行式存储格式 18.1M
[stored as parquet] -- 列式存储格式 13.1M
[stored as orc]; -- 列式存储格式 2.8M
-- 创建表
create table tb_textfile_mode(
log_date_time string,
visit_web string,
secret string,
web_engine string,
ip string,
buy_status string,
result_value int
) row format delimited
fields terminated by "\t"
stored as textfile ;
-- 导入数据
insert into table tb_textfile_mode select * from
tb_taobao_log;
-- 查看数据
select * from tb_textfile_mode;
-- 看文件大小
create table tb_parquet_mode(
log_date_time string,
visit_web string,
secret string,
web_engine string,
ip string,
buy_status string,
result_value int
) row format delimited
fields terminated by "\t"
stored as parquet ;
-- 导入数据
insert into table tb_parquet_mode select * from
tb_taobao_log;
-- 查看数据
select * from tb_parquet_mode;
create table tb_orc_mode(
log_date_time string,
visit_web string,
secret string,
web_engine string,
ip string,
buy_status string,
result_value int
) row format delimited
fields terminated by "\t"
stored as orc ;
-- 导入数据
insert into table tb_orc_mode select * from tb_taobao_log;
-- 查看数据
select * from tb_orc_mode;
当仅考虑数据文件的压缩比时,可以优先考虑使用列式存储的orc格式。
1.5join的优化操作
述join存在哪些问题?
- 导致reduce的压力剧增, 所有的数据全部都打向reduce中
- 当有了多个reduce后, 如果某个join字段的值出现大量的重复, 会导致大量key发往同一个reduce, 从而导致数据倾斜
通过 map 端 join实现
通过 map join 即可解决掉 reduce join所出现的所有的问题, 也可以这么mapjoin有解决数据倾斜的作用
存在什么弊端:
小表数据需要存储在内存中, 随着mapTask越多, 存储在内存的小表数据份数也会越多
当这个小表数据比较大的, 可能无法放置到内存中
所以说, mapJoin有一定使用范围: 仅适用于小表 和大表 进行join的情况
2.SQL优化
2.1列裁剪
Hive在读数据的时候,可以只读取查询中所需要用到的列,而忽略其他列
假设有一个表A: a b c 三个字段, 请查看以下SQL
select a,b from A where a=xxx;
在这条SQL, 发现没有使用c这个字段, 在from A表时候, 读取数据, 只需要将a列和 b列数据读取出来即可, 不需要读取c列字段, 这样可以减少读取的数据量, 从而提升效率
2.2分区裁剪
执行查询SQL的时候, 如果操作的表是一张分区表, 那么建议一定要带上分区字段, 以减少扫描的数据量, 从而提升效率, 能在join之前提前过滤的操作, 一定要提前过滤, 不要在join后进行过滤操作
select * from A join B where A.id=xxx;
优化后:
select * from (select * from A where id= xxx) A join B;
2.3 group by 操作
执行分组操作, 翻译后的MR, 分组的字段就是k2的字段, 按照k2进行分组操作, 将相同value合并在同一个集合中, 既然分组的字段就是MR的k2, 那么分区也会按照分组字段进行分区操作, 如果某个组下数据非常的多, 可能出现出现什么问题呢?
此时有可能发生数据倾斜, 因为相同key会发往同一个reduce中
所以说: 在hive中出现数据倾斜的主要体现在两个方面:
第一个:执行join操作(reduce join)
第二个:执行group by 操作
2.4count(distinct)
说明 : count(distinct) 在数据量比较大的情况下, 效率并不高
执行count操作的时候, hive翻译的MR, reduce数量是否可以有多
个? 必然不会有多个, 只能有一个, 因为全局求最终结果
此时如果执行统计的时候, 需要进行去重,那么去重工作是由reduce执行
去重操作, 由于reduce只有一个, 所有的数据都在一个reduce中, 此时reduce
的压力比较大
希望执行去重工作可能有多个reduce一起来执行操作, 此时可以将SQL优化:
原有:
select count(distinct ip) from ip_tab;
优化:
select
count(ip)
from
(select ip from ip_tab group by ip) tmp;
请注意: 这样的做法, 虽然会运行两个MR, 但是当数据量足够庞大的时
候, 此操作绝对是值得的, 如果数据量比较少, 此操作效率更低
2.5笛卡尔积
什么是笛卡尔积呢? 在进行join的时候, 两个表乘积之后结果就是笛卡尔积的结果
比如: 一个表有5条, 一个表有3条数据, 笛卡尔积结果就有15条数据 , 笛卡尔积中有大量数据都是无用数据
什么时候会产生笛卡尔积呢? 在多表join的时候, 关联条件缺少或者使用错误的关联条件以及将关联条件放置在where中都会导致笛卡尔积在实际使用中, 建议:
1) 避免join的时候不加on条件,或者无效的on条件
2) 关联条件不要放置在where语句, 因为底层, 先产生笛卡尔积 然后基于where进行过滤 , 建议放置on条件上
3) 如果实际开发中无法确定表与表关联条件 建议与数据管理者重新对接, 避免出现问题
3,动态分区
需求: 请将下面的一个分区表数据, 拷贝到另一个分区表, 保证对应区数据放置到另一个表的对应区下
作用: 帮助一次性灌入多个分区的数据
参数:
set hive.exec.dynamic.partition.mode=nonstrict; -- 开启非严格模式 默认为 strict(严格模式)
set hive.exec.dynamic.partition=true; -- 开启动态分区支持, 默认就是true
可选的参数:
set hive.exec.max.dynamic.partitions=1000; -- 在所有执行MR的
节点上,最大一共可以创建多少个动态分区。
set hive.exec.max.dynamic.partitions.pernode=100; -- 每个执
行MR的节点上,最大可以创建多少个动态分区
set hive.exec.max.created.files=100000; -- 整个MR Job中,最大可以创建多少个HDFS文件
-- 分区列本质就是在原表基础上生成了一个虚拟列
create table dynamic_stu1(
id int,
name string,
age int
)partitioned by (month string)
row format delimited
fields terminated by ','
stored as textfile;
-- 上传文件后查询
select * from dynamic_stu1; -- 查不到
-- 注意: 分区表上传文件是没有效果,需要将此文件数据放到分区目录中
-- 手动/自动创建分区目录
-- 静态分区
load data inpath
'/user/hive/warehouse/day09.db/dynamic_stu1/dynamic_stu.txt'
into table dynamic_stu1 partition (month='202302');
-- 自动生成分区后查询
select * from dynamic_stu1;
-- 如果要是手动创建了分区目录,需要msck repair修复 metastorecheck
msck repair table dynamic_stu1;
-- 修复完后再查询
select * from dynamic_stu1;
-- 需求: 把dynamic_stu1表结构数据都复制到dynamic_stu2分区表
create table dynamic_stu2(
id int,
name string,
age int
)partitioned by (month string)
row format delimited
fields terminated by ','
stored as textfile;
-- 开启动态分区支持, 默认就是true,无需操作
set hive.exec.dynamic.partition=true;
-- 动态分区方式1
insert into dynamic_stu2 select * from dynamic_stu1;
-- 查看分区
show partitions dynamic_stu2;
-- 想要演示动态分区方式2,需要删除刚才的分区
alter table dynamic_stu2 drop partition (month='202302');
alter table dynamic_stu2 drop partition (month='202303');
-- 动态分区方式2
insert into dynamic_stu2 partition (month) select * from
dynamic_stu1; -- 报错
set hive.exec.dynamic.partition.mode=nonstrict; -- 开启非严格模
式 默认为 strict(严格模式)
insert into dynamic_stu2 partition (month) select * from
dynamic_stu1; -- 成功
-- 再次查看分区
show partitions dynamic_stu2;
3.1 如何调整map和reduce的数量
1>是不是map数越多越好? 答案是否定的。如果一个任务有很多小文件(远远小于块大小128m),则每个小文件也会被当做一个块,用一个map任务来完
成,而一个map任务启动和初始化的时间远远大于逻辑处理的时间,就会造成很大的资源浪费。而且,同时可执行的map数是受限的。
2>是不是保证每个map处理接近128m的文件块,就高枕无忧了? 答案也是不一定。比如有一个127m的文件,正常会用一个map去完成,但这个文件只有一个或者两个小字段,却有几千万的记录,如果map处理的逻辑比较复杂,用一个map任务去做,肯定也比较耗时。
3>是不是reduce数越多越好? 答案是否定的。如果reduce设置的过大,对整个作业会产生一定的影响。 ①过多的启动和初始化reduce也会消耗时间和资源;
②另外,有多少个reduce,就会有多少个输出文件,如果生成了很多个小文件,那么如果这些小文件作为下一个任务的输入,则也会出现小文件过多的问题;
如何调整mapTask数量:
小文件场景
当input的文件都很小,把小文件进行合并归档,减少map数, 设置map数量:
– 每个Map最大输入大小(这个值决定了合并后文件的数量)
set mapred.max.split.size=112345600;
– 一个节点上split的至少的大小(这个值决定了多个DataNode上的文件是否需要合并)
set mapred.min.split.size.per.node=112345600;
– 一个交换机下split的至少的大小(这个值决定了多个交换机上的文件是否需要合并)
set mapred.min.split.size.per.rack=112345600;
– 执行Map前进行小文件合并
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHive InputFormat;
大文件场景
当input的文件都很大,任务逻辑复杂,map执行非常慢的时候,可以考虑增加Map数,来使得每个map处理的数据量减少,从而提高任务的执行效率。
举例:如果表a只有一个文件,大小为120M,但包含几千万的记录,如果用1个map去完成这个任务,肯定是比较耗时的,这种情况下,我们要考虑将这一个文件合理的拆分成多个,这样就可以用多个map任务去完成。set mapred.reduce.tasks=10;
create table a_1 as select * from tab_info distribute
by rand(123);
这样会将a表的记录,随机的分散到包含10个文件的a_1表中,再用a_1代替上面sql中的a表,则会用10个map任务去完成。
如何reduce的数量:
总共受3个参数控制:
(1)每个Reduce处理的数据量默认是256MB
hive.exec.reducers.bytes.per.reducer=256123456
(2)每个任务最大的reduce数,默认为999
hive.exec.reducers.max=999
(3)mapreduce.job.reduces
该值默认为-1,由hive自己根据任务情况进行判断。因此,可以手动设置每个job的Reduce个数
set mapreduce.job.reduces = 8;
在什么情况下, 只能有一个reduce呢?
以下几种, 不管如何设置, 最终翻译后reduce只能有一个
1) 执行order by操作
2) 执行不需要group by直接聚合的操作
3) 执行笛卡尔积
4.并行执行
在执行一个SQL语句的时候, SQL会被翻译为MR, 一个SQL有可能被翻译成多个MR,那么在多个MR之间, 有些MR之间可能不存在任何的关联, 此时可以设置让这些没有关联的MR 并行执行, 从而提升效率 , 默认是 一个一个来
set hive.exec.parallel=true; --打开任务并行执行,默认关闭
set hive.exec.parallel.thread.number=16; --同一个sql允许最大并行度,默认为8。
前提:
服务器必须有资源, 如果没有 即使支持并行, 也没有任何作用
select * from A ....
union all
select * from B ...;
例如:
select from (select * from A group by ...) tmp1 join
(select * from B group by xxx) on ...
5,严格模式
屏蔽一下操作:
1) 执行order by 不加 limit
2) 出现笛卡尔积的现象SQL
3) 查询分区表, 不带分区字段
前提: 数据量足够大, 如果数据量比较少, 严格模式对此三项内容不生效
set hive.mapred.mode = strict; --开启严格模式
set hive.mapred.mode = nostrict; --开启非严格模式
6.推测执行
Hadoop采用了推测执行(Speculative Execution)机制,它根据一定的法则推测出“拖后腿”的任务,并为这样的任务启动一个备份任务,让该任务与原始任务同时处理同一份数据,并最终选用最先成功运行完成任务的计算结果作为最终结果。hadoop中默认两个阶段都开启了推测执行机制。
hive本身也提供了配置项来控制reduce-side的推测执行:
set hive.mapred.reduce.tasks.speculative.execution=true;
关于调优推测执行机制,还很难给一个具体的建议。如果用户对于运行时的偏差非常敏感的话,那么可以将这些功能关闭掉。如果用户因为输入数据量很大而需要执行长时间的
map或者Reduce task的话,那么启动推测执行造成的浪费是非常巨大。
7,执行计划explain
使用EXPLAIN关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的。帮助我们了解底层原理,hive调优,排查数据倾斜等有很有帮助
使用示例:explain [...] sql查询语句;
explain sql语句: 查看执行计划的基本信息
(1)stage dependencies:各个stage之间的依赖性
包含两部分:Stage-1和Stage-0,Stage-1 是根stage,Stage-0 依赖 Stage-1,
(2)stage plan:各个stage的执行计划
包含两部分: map端执行计划树和reduce端执行计划树

相关文章:
Hive调优
1.参数配置优化 设定Hive参数有三种方式: (1)配置Hive文件 当修改配置Hive文件的设定后,对本机启动的所有Hive进程都有效,因此配置是全局性的。 一般地,Hive的配置文件包括两部分: aÿ…...

基于R语言平台Biomod2模型的物种分布建模与可视化分析
!](https://img-blog.csdnimg.cn/84e1cc8c7f9b4b6ab60903ffa17d82f0.jpeg#pic_center)...

Docker 安装一个本地的画图软件 —— 筑梦之路
画图是必不可少的,比如流程图、架构图等等,网上有很多画图软件是要收费的,使用起来很不方便,因此在内网部署一个免费开源的画图软件是有必要的。 如何部署 docker run -it --rm --name"drawio" -p 8080:8080 -p 8443:…...

【python】Conda强大的包/环境管理工具
Conda强大的包/环境管理工具 1. 简介2. 安装3. 指令 1. 简介 Conda是Anaconda中一个强大的包和环境管理工具,可以在Windows的Anaconda Prompt命令行使用,也可以在macOS或者Linux系统的终端窗口(terminal window)的命令行使用。2. 安装 [Linux平台安装教…...

常见面试题-Netty线程模型以及TCP粘包拆包
介绍一下 Netty 使用的线程模型? 答: Netty 主要基于主从 Reactor 多线程模型,其中主从 Reactor 多线程模型将 Reactor 分为两部分: mainReactor:监听 Server Socket,用来处理网络 IO 连接建立操作&…...
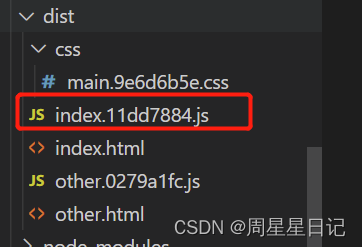
03.webpack中hash,chunkhash和contenthash 的区别
hash、contenthash 和 chunkhash 是通过散列函数处理之后,生成的一串字符,可用于区分文件。 作用:善用文件的哈希值,解决浏览器缓存导致的资源未及时更新的问题 1.文件名不带哈希值 const path require(path) const HtmlWebpac…...
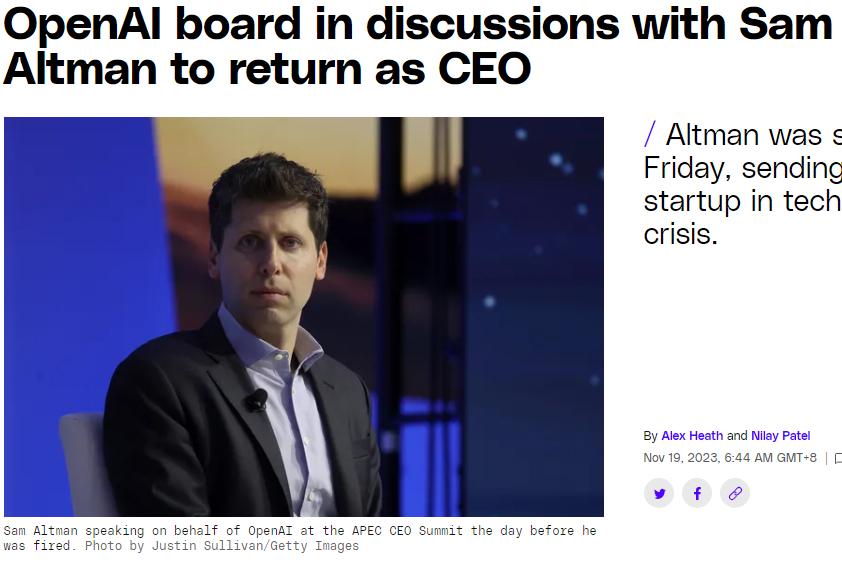
OpenAI前CEO萨姆·阿尔特曼可能重返CEO职位;用LoRA微调LLM的实用技巧
🦉 AI新闻 🚀 OpenAI前CEO萨姆阿尔特曼可能重返CEO职位 摘要:据报道,OpenAI前CEO萨姆阿尔特曼有望重新担任CEO职位,并对公司董事会进行重大改变。微软等投资人正努力恢复阿尔特曼的职位,尽管董事会仍然是…...

修改docker默认数据目录
前言: docker默认数据目录是/var/lib/docker,根目录的存储空间有限,我们往往不能使用默认配置,需要创建空间相对较大的数据data目录 停止docker服务 systemctl stop docker 编辑配置文件 vi /etc/docker/daemon.json 增加选项 “graph”…...
wpf devexpress post 更改数据库
这个教程示范如何使用GridControl编辑数据,和保存更改到数据库。这个教程基于前一个篇。 Items Source Wizard 当 CRUD (Create, Read, Update, Delete) 启动选项时添加Post data功能 Items Source Wizard 生成如下代码: 1、设置 TableView.ShowUpdat…...

Ubuntu 18.04/20.04 LTS 操作系统设置静态DNS
1、nano /etc/systemd/resolved.conf 2、修改配置 使用DNS服务器:223.5.5.5 223.6.6.6 [Resolve] DNS223.5.5.5 223.6.6.6 3、重启服务 systemctl restart systemd-resolved.service 4、查看解析文件 cat /run/systemd/resolve/resolv.conf # This file is man…...

VSCode使用MinGW中的go并支持CGO
在Windows中,如果想使用Linux下的一些命令或者开发工具,可以安装Cygwin或者MinGW,MinGW相比Cygwin要轻量得多,笔者就安装的MinGW,但是安装MinGW后,如果把它加到Windows系统的PATH环境变量中,则可…...

tensor张量 ------ python特殊的数据结构
点赞收藏关注! 如需转载请注明出处! 张量与数组和矩阵非常相似。 在PyTorch中,使用张量来编码模型的输入和输出,以及模型的参数。 张量可以在GPU或其他硬件加速器上运行。 张量和NumPy数组通常可以共享相同的底层内存,…...

openai/chatgpt的api接口,各个模型的最大输入token一览表
chatgpt的各个3.5api模型接口的最大输入量一览表: MODELDESCRIPTIONCONTEXT WINDOWTRAINING DATAgpt-3.5-turbo-1106Updated GPT 3.5 Turbo New The latest GPT-3.5 Turbo model with improved instruction following, JSON mode, reproducible outputs, parallel…...

Spark作业串行与并行提交job
在Scala中,您可以以串行和并行的方式提交Spark作业。看看如何使用for和par.foreach构造对应的例子。 串行Spark作业(使用for) // 串行Spark作业设置 for (tag <- tags) {spark.sparkContext.setJobGroup(tag.toString, s"Tag: $tag…...
HTTP HTTPS 独特的魅力
目录 HTTP协议 HTTP协议的工作过程 首行 请求头(header) HOST Content-Length编辑 User-Agent(简称UA) Referer Cookie 空行 正文(body) HTTP响应详解 状态码 报文格式 HTTP响应格式 如何…...
人名分类器实战项目(对比RNN、LSTM、GRU模型)工程管理方式)
【nlp】2.5(gpu version)人名分类器实战项目(对比RNN、LSTM、GRU模型)工程管理方式
人名分类器实战项目 0 说明1 工程项目设计2 数据预处理data_processing3 创建模型model4 模型测试test5 训练配置config6 模型训练train7 模型对比绘图plotfigure8 模型预测predict9 代码测试demo0 说明 本项目对前一个博客内容2.5(cpu version) 人名分类器实战项目(对比RNN、…...
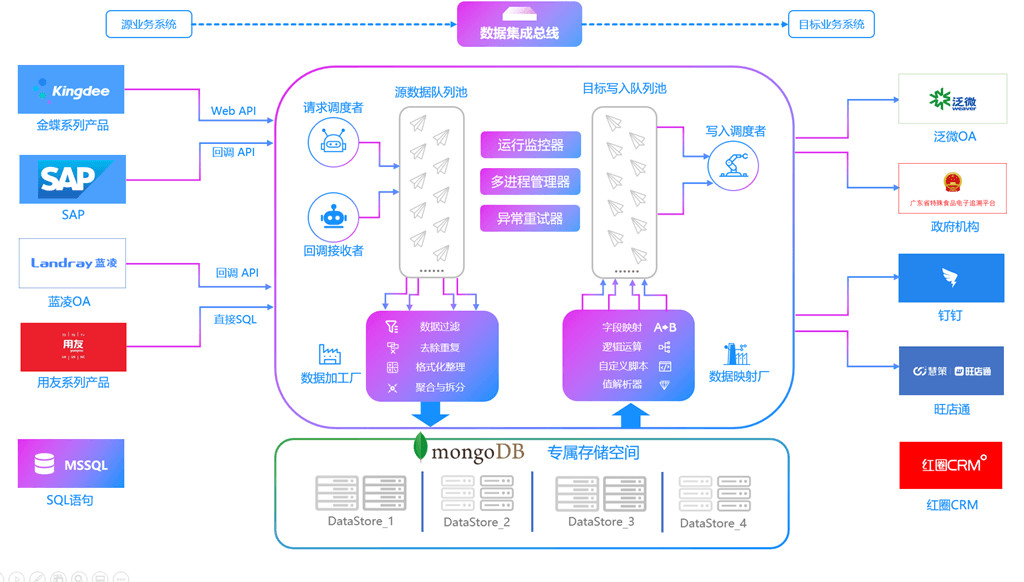
金蝶云星空对接打通旺店通·旗舰奇门采购退料单查询接口与创建货品档案接口
金蝶云星空对接打通旺店通旗舰奇门采购退料单查询接口与创建货品档案接口 来源系统:金蝶云星空 金蝶K/3Cloud在总结百万家客户管理最佳实践的基础上,提供了标准的管理模式;通过标准的业务架构:多会计准则、多币别、多地点、多组织、多税制应用…...
在线识别二维码工具
具体请前往:在线二维码识别解码工具--在线识别并解码二维码网址等内容...
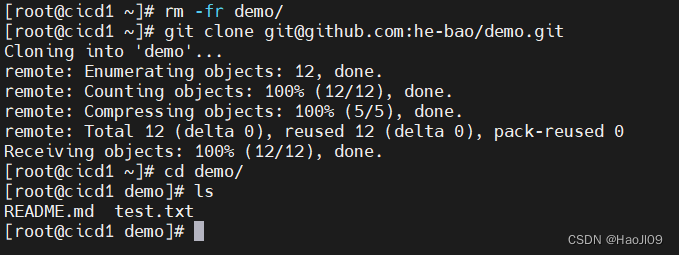
CICD 持续集成与持续交付——git
git使用 [rootcicd1 ~]# yum install -y git[rootcicd1 ~]# mkdir demo[rootcicd1 ~]# cd demo/ 初始化版本库 [rootcicd1 demo]# git init 查看状态 [rootcicd1 demo]# git status[rootcicd1 demo]# git status -s #简化输出 [rootcicd1 demo]# echo test > README.md[roo…...

光纤的跳线和尾纤
光纤跳线和光纤尾纤在结构上、连接方式、应用场景等方面存在明显的区别。 光纤跳线有0.9、2.0、3.0,通常是区分光缆外径的。0.9光缆外径0.9mm的,2.0光缆外径2mm,3.0光缆外径3mm。 同时分单模光纤跳线和多模光纤跳线。单模一般是黄色ÿ…...

别再只懂ls -l了!手把手教你用getfattr/setfattr玩转Linux文件隐藏属性
别再只懂ls -l了!手把手教你用getfattr/setfattr玩转Linux文件隐藏属性 在Linux系统中,文件权限和属性管理是每个开发者和管理员的必修课。大多数人熟悉 ls -l 展示的基础权限,但很少有人深入探索文件系统中那些不为人知的"隐藏技能&q…...
)
AI Agent如何重构数据分析工作流:从数据清洗到洞察生成的7步自动化闭环(附企业级架构图)
更多请点击: https://intelliparadigm.com 第一章:AI Agent如何重构数据分析工作流:从数据清洗到洞察生成的7步自动化闭环(附企业级架构图) 传统数据分析依赖人工串联多个工具与脚本,耗时长、容错低、知识…...

Python爬虫实战:爬取论文期刊 文献整理+管理表生成
写论文的时候最烦什么?不是写内容,是找文献和整理文献。相信每个研究生都有过这样的经历:打开十几个浏览器标签页,一篇一篇复制论文标题、作者、期刊、发表时间、摘要,然后粘贴到Excel里,一不小心还会复制错…...

KNN工程落地:从距离度量到FAISS索引的生产级实践
1. 这不是“调个sklearn参数”就能糊弄过去的事:KNN背后被严重低估的工程现实“K近邻算法(K-nearest Neighbors)”,四个字,教科书里三行公式就讲完,面试官常问“它是不是懒惰学习?有没有训练过程…...

【AI面试八股文 Vol.3.5:推理幻觉规模定律】CoT、幻觉与 Scaling Law:为什么模型会推理,也会一本正经胡说
摘要:这篇会把 CoT、幻觉和 Scaling Law 放到同一条工程主线上:CoT 不是教模型思考,而是触发模型把隐式路径显式写出来;幻觉不是单一 bug,而是训练知识边界、解码策略和指令跟随压力叠加后的结果;Scaling L…...

2026年B2B制造业GEO优化服务商推荐:工业品牌AI搜索可见度提升实战指南
摘要:B2B制造业的品牌营销与消费品逻辑完全不同——技术参数、行业资质、项目案例才是AI推荐的核心素材。本文从B2B行业理解深度、结构化内容能力、合规安全保障三个维度,对比泓动数据、百分点科技、赛诺贝斯、大树科技、Laver AI五家服务商在工业制造业…...

当IP矩阵遇上GEO,中小企业如何实现“双轮驱动”?
流量入口正在从搜索框向对话栏迁徙,你的品牌是“被看见”还是“被信任”?一、一个正在发生的营销范式革命2026年的一个真实场景:当潜在客户向豆包或千问提问“哪家公司的XX服务比较好”时,AI给出的推荐列表里,你的品牌…...

Linux服务器TCP连接数远超65535:从协议原理到高并发调优
1. 项目概述:一个流传甚广的“常识”误区“Linux服务器的TCP连接数上限是65535。” 这句话,我相信很多运维工程师、后端开发,甚至是一些面试官都曾说过或听过。它像一条技术领域的“都市传说”,在无数技术讨论、博客文章甚至面试题…...
)
AI Agent社交交互延迟超800ms?——用eBPF+LLM Token流控双引擎压测实录(性能提升4.8倍原始基线)
更多请点击: https://intelliparadigm.com 第一章:AI Agent社交交互延迟超800ms?——用eBPFLLM Token流控双引擎压测实录(性能提升4.8倍原始基线) 当AI Agent在高并发社交场景中响应延迟突破800ms,用户会感…...

终极3D转2D视频转换器:让VR内容在普通设备上“活“起来
终极3D转2D视频转换器:让VR内容在普通设备上"活"起来 【免费下载链接】VR-reversal VR-Reversal - Player for conversion of 3D video to 2D with optional saving of head tracking data and rendering out of 2D copies. 项目地址: https://gitcode.…...