(二)Pytorch快速搭建神经网络模型实现气温预测回归(代码+详细注解)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、数据集
- 二、导入数据以及展示部分
- 1.导入数据集以及对数据集进行处理
- 2.展示数据(看看就好)
- 三(1)、搭建网络进行预测(理解版)
- 三(2)、搭建网络进行预测(应用版)
- 四、 对预测结果进行一个展示,蓝色真实值,红色预测值
- 总结
前言
深度学习pytorch系列第二篇,第一篇实现的是分类任务,这篇是回归任务,大差不差,重在理解,具体的理解内容我都以注释的形式放在了代码中,方便大家阅读
一、数据集
想要复现的可以下载
链接:网盘链接
提取码:k6a4
二、导入数据以及展示部分
1.导入数据集以及对数据集进行处理
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
# 过滤警告
import warnings
warnings.filterwarnings("ignore")
# 读取数据
features = pd.read_csv('data/temps.csv')
#
#看看数据长什么样子
# print(features.head())
# print('数据维度:', features.shape)
# 数据维度:(348, 9),348条数据,每条8个特征x,1个标签y
# 处理时间数据
import datetime
# 分别得到年,月,日
years = features['year']
months = features['month']
days = features['day']
#
# # datetime格式
dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates]
# 在打印的结果中,每个datetime.datetime对象的后面两个0表示小时和分钟,没有时默认为0
# print(dates[:5])
# 独热编码
# # 将字符串进行onehot
# # 周一 周二 周三 周四 周五 周六 周天
# # 如果是周一,编码就是
# # 1000000
# Pandas库中的get_dummies函数,是一种独热编码(One-Hot Encoding)的方法
features = pd.get_dummies(features)# print(features.head(5))
# print(features.shape)
# 此时的数据维度:(348, 15),多的7个是日期的七天
# 取标签
labels = np.array(features['actual'])
# 在特征中去掉标签,features.drop,去掉标签列
features= features.drop('actual', axis = 1)
# 名字单独保存一下,以备后患
feature_list = list(features.columns)
# 转换成合适的格式
features = np.array(features)
# print(features.shape)
# print(features)
"""
数据标准化
由于神经网络在训练的过程中具有倾向性,数值越大,认为越重要
# 但是在月份这种重要程度与数值无关的特征上,这种倾向性就会出错
# 因此进行标准化,使数据以零点为中心均匀分布
# (x-u)/σ
# x-u 去均值
# /σ 除以标准差:让离散数据更加收敛
标准化通常是针对特征而不是标签的。
标准化的目的是使特征具有相同的尺度,以便模型能够更好地学习权重并提高模型的性能。
标签(也称为目标变量)通常不需要标准化,因为它们是模型试图预测的值,而不是用于学习权重的输入。
"""
from sklearn import preprocessing
input_features = preprocessing.StandardScaler().fit_transform(features)
"""
[ 0. -1.5678393 -1.65682171 -1.48452388 -1.49443549 -1.3470703-1.98891668 2.44131112 -0.40482045 -0.40961596 -0.40482045 -0.40482045-0.41913682 -0.40482045]标准化处理后的数据以零点为中心,均匀分布
"""
上述代码中的初始数据集为:
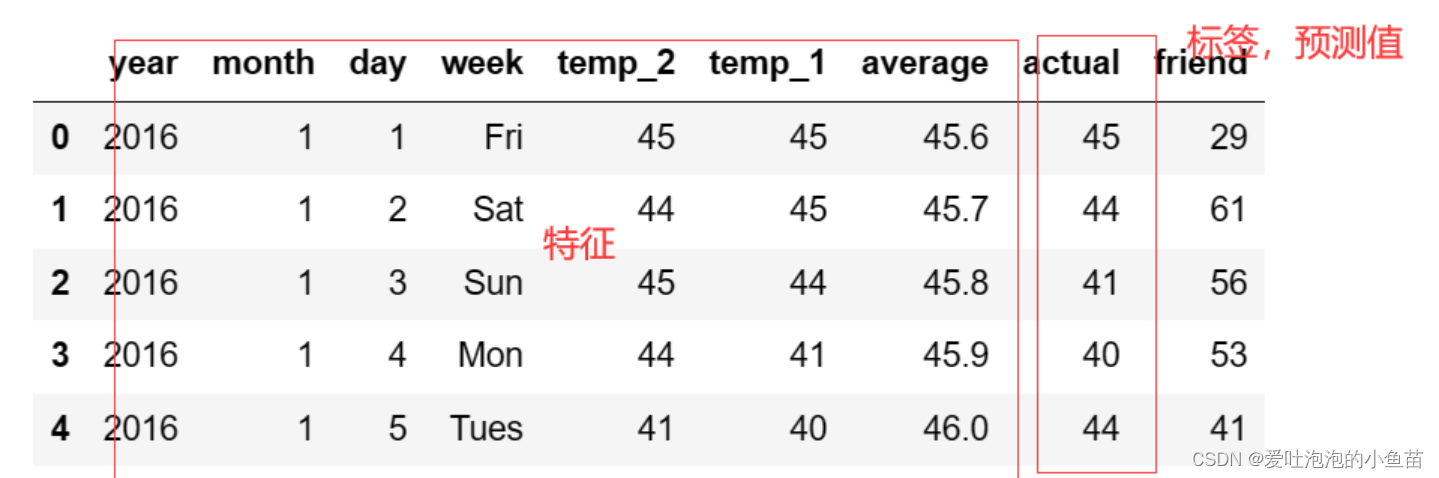
处理完成后的数据样貌:

2.展示数据(看看就好)
代码如下(示例):
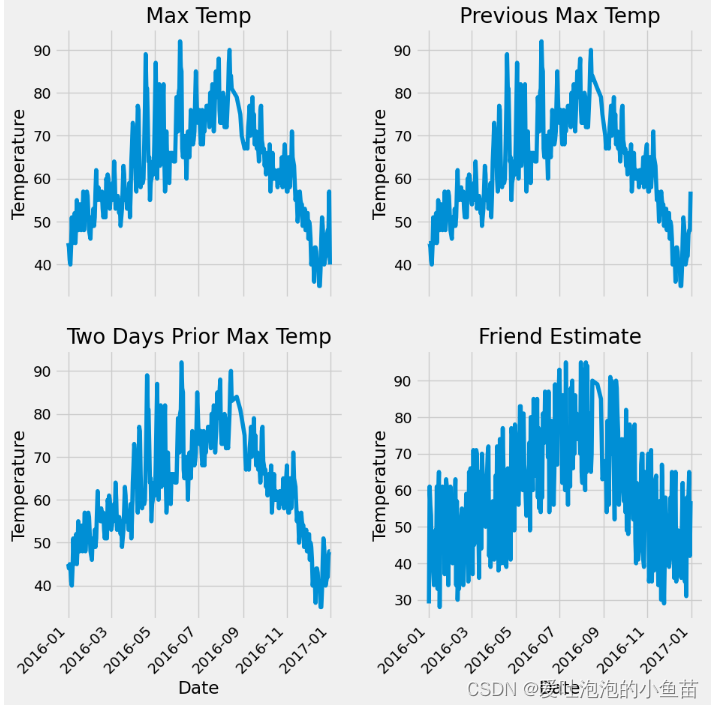
# 该段是展示一下数据的样貌
plt.style.use('fivethirtyeight')
# 设置布局
# 4个子图,两行两列
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2, figsize = (10,10))
# 坐标倾斜45度
fig.autofmt_xdate(rotation = 45)# 标签值
ax1.plot(dates, features['actual'])
ax1.set_xlabel(''); ax1.set_ylabel('Temperature'); ax1.set_title('Max Temp')
# 昨天
ax2.plot(dates, features['temp_1'])
ax2.set_xlabel(''); ax2.set_ylabel('Temperature'); ax2.set_title('Previous Max Temp')
#
# 前天
ax3.plot(dates, features['temp_2'])
ax3.set_xlabel('Date'); ax3.set_ylabel('Temperature'); ax3.set_title('Two Days Prior Max Temp')
#
# 朋友感觉的值
ax4.plot(dates, features['friend'])
ax4.set_xlabel('Date'); ax4.set_ylabel('Temperature'); ax4.set_title('Friend Estimate')
# 子图之间间隔多少
plt.tight_layout(pad=2)
plt.show()
展示图如下:
三(1)、搭建网络进行预测(理解版)
该过程是一步一步构建网络,促进理解,后边会附上更为简单的网络结构
x = torch.tensor(input_features, dtype=float)
y = torch.tensor(labels, dtype=float)
# # 权重参数初始化
# (14, 128),将14个特征转成128个神经元,可以理解为转成128个特征
# requires_grad = True,是否求导,也就是是否记录梯度
weights = torch.randn((14, 128), dtype=float, requires_grad=True)
biases = torch.randn(128, dtype=float, requires_grad=True)
weights2 = torch.randn((128, 1), dtype=float, requires_grad=True)
biases2 = torch.randn(1, dtype=float, requires_grad=True)
# 学习率 :决定梯度更新幅度的大小,计算出来的梯度只能确定方向
# 这个幅度不能太大
learning_rate = 0.001
losses = []
# 迭代次数,每次算梯度,然后更新
for i in range(1000):# 计算隐层hidden = x.mm(weights) + biases# 加入激活函数,非线性映射hidden = torch.relu(hidden)# 预测结果 :h1*w2+b2=预测值predictions = hidden.mm(weights2) + biases2# 通计算损失loss = torch.mean((predictions - y) ** 2)losses.append(loss.data.numpy())# 打印损失值if i % 100 == 0:print('loss:', loss)# 返向传播计算loss.backward()# 更新参数# grad.data 取梯度,然后乘以学习率,应该沿着梯度的反方向更新weights.data.add_(- learning_rate * weights.grad.data)biases.data.add_(- learning_rate * biases.grad.data)weights2.data.add_(- learning_rate * weights2.grad.data)biases2.data.add_(- learning_rate * biases2.grad.data)# 每次迭代都得记得清空# 每次迭代过程都是独立的,之前计算的梯度要清零# 在torch中,如果不清零,梯度就会累加weights.grad.data.zero_()biases.grad.data.zero_()weights2.grad.data.zero_()biases2.grad.data.zero_()
print(predictions.shape)
print(predictions)
三(2)、搭建网络进行预测(应用版)
实际应用中,往往会这样实现
# 更简单的构建网络模型
# 取特征个数
# 0是样本数;1是特征数
input_size = input_features.shape[1]
# print(input_size) 14 有14个特征
# 隐层个数
hidden_size = 128
output_size = 1
batch_size = 16
# Sequential序列模块,按顺序执行
my_nn = torch.nn.Sequential(# 计算隐层,相当于wx+b,参数是自动更新的torch.nn.Linear(input_size, hidden_size),
# 激活函数torch.nn.Sigmoid(),
# 预测结果 :h1*w2+b2=预测值torch.nn.Linear(hidden_size, output_size),
)
# 计算损失
# reduction='mean 平均损失
cost = torch.nn.MSELoss(reduction='mean')
# 优化器
# my_nn.parameters() 更新nn中所有参数
optimizer = torch.optim.Adam(my_nn.parameters(), lr = 0.001)
# ADM优化器,比SGD(梯度下降)效果好,效率高
# 训练网络
losses = []
# 迭代1000次
for i in range(1000):# 每次取一个batch的数据,每次只取一批数据batch_loss = []# MINI-Batch方法来进行训练# for start in range(0, len(input_features), batch_size):# 从0开始,到整个数据结束,取batch,间隔是一个batch_size大小for start in range(0, len(input_features), batch_size):end = start + batch_size if start + batch_size < len(input_features) else len(input_features) # 判断索引越界xx = torch.tensor(input_features[start:end], dtype=torch.float, requires_grad=True)yy = torch.tensor(labels[start:end], dtype=torch.float, requires_grad=True)prediction = my_nn(xx)loss = cost(prediction, yy)# 通过优化器进行梯度清零optimizer.zero_grad()# 反向传播loss.backward(retain_graph=True)# 更新参数optimizer.step()# 将每一个batch的损失相加batch_loss.append(loss.data.numpy())# 打印损失if i % 100 == 0:losses.append(np.mean(batch_loss))print(i, np.mean(batch_loss))
x = torch.tensor(input_features, dtype = torch.float)
# 所有的数据进行预测,得到结果,进行画图
predict = my_nn(x).data.numpy()
四、 对预测结果进行一个展示,蓝色真实值,红色预测值
# 转换日期格式
dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates]# 创建一个表格来存日期和其对应的标签数值
true_data = pd.DataFrame(data = {'date': dates, 'actual': labels})# 同理,再创建一个来存日期和其对应的模型预测值
months = features[:, feature_list.index('month')]
days = features[:, feature_list.index('day')]
years = features[:, feature_list.index('year')]test_dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]test_dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in test_dates]predictions_data = pd.DataFrame(data = {'date': test_dates, 'prediction': predict.reshape(-1)})
# 真实值
plt.plot(true_data['date'], true_data['actual'], 'b-', label = 'actual')# 预测值
plt.plot(predictions_data['date'], predictions_data['prediction'], 'ro', label = 'prediction')
plt.xticks(rotation = '60');
plt.legend()
plt.show()
# 图名
plt.xlabel('Date'); plt.ylabel('Maximum Temperature (F)'); plt.title('Actual and Predicted Values');
# 层数越来越对,就会过拟合
# 什么是过拟合?过拟合(Overfitting)是指机器学习模型在训练数据上表现得很好,但在未见过的新数据上表现较差的现象。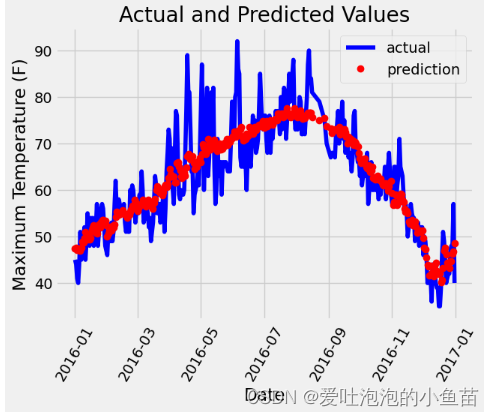
总结
pytorch学习的第二篇啦,慢慢更新ing
相关文章:
(二)Pytorch快速搭建神经网络模型实现气温预测回归(代码+详细注解)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、数据集二、导入数据以及展示部分1.导入数据集以及对数据集进行处理2.展示数据(看看就好) 三(1)、搭建网络进…...

markdown 公式编辑
参考:https://blog.csdn.net/qq_36584673/article/details/117167861...
20231117在ubuntu20.04下使用ZIP命令压缩文件夹
20231117在ubuntu20.04下使用ZIP命令压缩文件夹 2023/11/17 17:01 百度搜索:Ubuntu zip 压缩 https://blog.51cto.com/u_64214/7641253 Ubuntu压缩文件夹zip命令 原创 chenglei1208 2023-09-28 17:21:58博主文章分类:LINUX 小工具 文章标签命令行压缩包U…...

IPKISS Tutorials 1------导入 pdk
IPKISS Tutorials 1------导入 pdk 方法1方法2今天给大家介绍一下如何在 IPKISS 中导入想要使用的 pdk 文件。 方法1 # 导入IPKISS 自带 si_fab PDK from si_fab import all as pdk # 导入amf PDK from amfsip import all as pdk方法2 # 导入IPKISS 自带 si_fab PDK import …...

使用ChatGPT进行数据分析案例——贷款数据分析
目录 数据数据 每一行是一个记录,代表着一笔贷款,每一列是一个特征,一共1万多条数据,最后一列非常重要save_loans是否成功收回...

【数字图像处理】Gamma 变换
在数字图像处理中,Gamma 变换是一种重要的灰度变换方法,可以用于图像增强与 Gamma 校正。本文主要介绍数字图像 Gamma 变换的基本原理,并记录在紫光同创 PGL22G FPGA 平台的布署与实现过程。 目录 1. Gamma 变换原理 2. FPGA 布署与实现 2…...

ChatGPT + DALL·E 3
参考链接: https://chat.xutongbao.top/...

【AI视野·今日Robot 机器人论文速览 第六十三期】Thu, 26 Oct 2023
AI视野今日CS.Robotics 机器人学论文速览 Fri, 27 Oct 2023 Totally 27 papers 👉上期速览✈更多精彩请移步主页 Daily Robotics Papers 6-DoF Stability Field via Diffusion Models Authors Takuma Yoneda, Tianchong Jiang, Gregory Shakhnarovich, Matthew R. …...

测试Bard和ChatGPT关于双休的法规和推理
Bard是试验品,chatgpt是3.5版的。 首先带着问题,借助网络搜索,从政府官方网站等权威网站进行确认,已知正确答案的情况下,再来印证两个大语言模型的优劣。 想要了解的问题是,在中国,跟法定工作…...

py查询第三方库的路径
在Python中,你可以使用pkg_resources模块来查询第三方库的路径。这个模块提供了许多有用的函数来处理Python包和资源。 以下是一个简单的示例,展示如何查询第三方库的路径: import pkg_resources# 指定要查询的包名 package_name "第…...
LeetCode(16)接雨水【数组/字符串】【困难】
目录 1.题目2.答案3.提交结果截图 链接: 42. 接雨水 1.题目 给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。 示例 1: 输入:height [0,1,0,2,1,0,1,3,2,1,2,1] 输出&…...
Kotlin 知识体系
Kotlin 知识体系 1、Kotlin 文档2、Kotlin 基础3、桌面应用程序4、Android 与 iOS 应用程序 1、Kotlin 文档 Kotlin 是一门现代但已成熟的编程语言,旨在让开发人员更幸福快乐。 它简洁、安全、可与 Java 及其他语言互操作,并提供了多种方式在多个平台间复…...
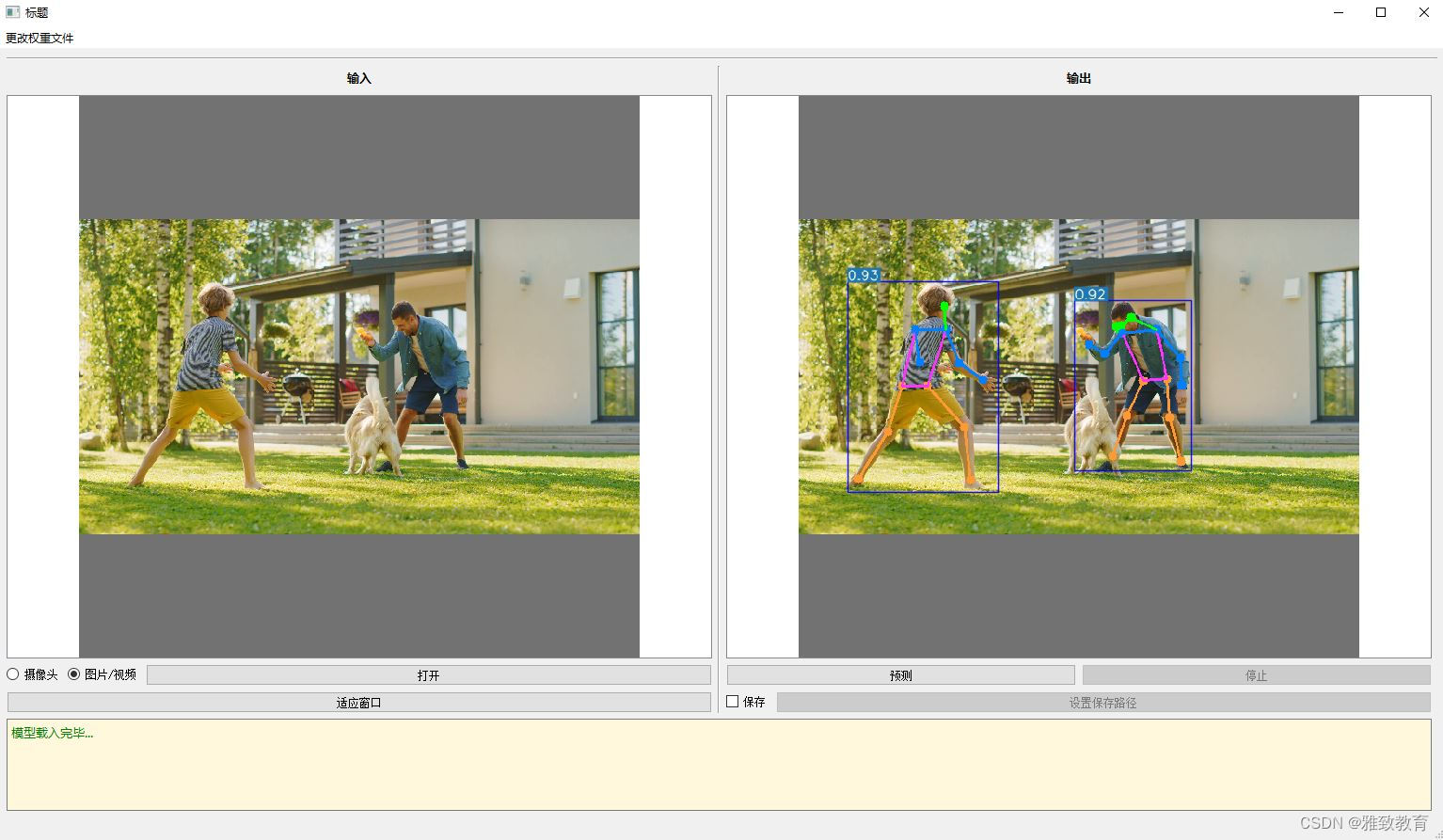
深度学习之基于YoloV5-Pose的人体姿态检测可视化系统
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。 文章目录 一项目简介 深度学习之基于 YOLOv5-Pose 的人体姿态检测可视化系统介绍YOLOv5-Pose 简介系统特点系统架构使用方法 二、功能三、系统四. 总结 一项目简介 深度学习之基…...

为什么Go是后端开发的未来
近年来,Go 编程语言的流行度迅速增加。Go 最初由 Google 开发,迅速成为后端开发中最受欢迎的语言之一,特别是在分布式系统和微服务的开发中。本文将讨论为什么 Go 是后端开发的未来。 Go 简介 Go,又称为 Golang,是由…...

Linux输入设备应用编程(键盘,按键,触摸屏,鼠标)
目录 一 输入设备编程介绍 1.1 什么是输入设备呢? 1.2 什么是输入设备的应用编程? 1.3 input子系统 1.4 数据读取流程 1.5 应用程序如何解析数据 1.5.1 按键类事件: 1.5.2 相对位移事件 1.5.3 绝对位移事件 二 读取 struct input_e…...

【Axure教程】滑动内容选择器
滑动内容选择器通常是一种用户界面组件,允许用户通过滑动手势在一组内容之间进行选择。这种组件可以在移动应用程序或网页中使用,以提供直观的图片选择体验。 那今天就教大家如何用中继器制作一个滑动内容选择器,我们会以滑动选择电影为案例…...

vite+vue3使用@路径,报错处理
报错原因:未配置 符号为指定路径别名,直接使用导致 处理方法: 安装path模块: npm install --save-dev types/node修改vite.config.ts import { defineConfig } from vite import vue from vitejs/plugin-vue import path from…...
[开源]基于 AI 大语言模型 API 实现的 AI 助手全套开源解决方案
原文:[开源]基于 AI 大语言模型 API 实现的 AI 助手全套开源解决方案 一飞开源,介绍创意、新奇、有趣、实用的开源应用、系统、软件、硬件及技术,一个探索、发现、分享、使用与互动交流的开源技术社区平台。致力于打造活力开源社区࿰…...
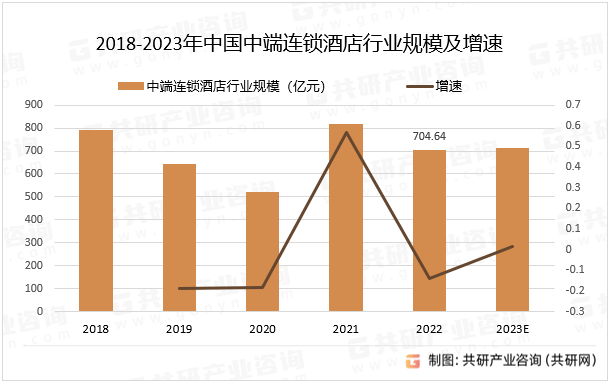
2023年中国中端连锁酒店分类、市场规模及主要企业市占率[图]
中端连锁酒店行业是指定位于中档酒店市场、具有全国统一的品牌形象识别系统、全国统一的运营体系、会员体系和营销体系的酒店。中端酒店通常提供舒适、标准化的房间设施和服务,价格较为合理,符合广大消费者的需求。其价格略高于经济型酒店,但…...
mac下vue-cli从2.9.6升级到最新版本
由于mac之前安装了 vue 2.9.6 的版本,现在想升级到最新版本,用官方给的命令: npm uninstall vue-cli -g 发现不行。 1、究其原因:从vue-cli 3.0版本开始原来的npm install -g vue-cli 安装的都是旧版,最高到2.9.6。安…...

Python之enc-dotenv包语法、参数和实际应用案例
Python enc-dotenv 包完整详解 enc-dotenv 是加密版 python-dotenv 核心增强包,专门解决明文存储环境变量(密钥、密码、Token) 的安全风险。它能将 .env 文件加密存储,运行时自动解密加载,彻底避免敏感配置明文泄露。 …...

AI医疗落地实操指南:临床决策支持与人机协同诊疗
1. 这不是科幻片,是每天在三甲医院晨交班时发生的事 “AI把医生取代了?”——这是我过去三年被问得最多的问题,通常来自刚轮转到信息科的住院医,或是陪孩子看病时刷到短视频的家长。但真实情况比这复杂得多:上周五我蹲…...

用AI写论文,重复率和AIGC疑似率能同时控制在20%以内吗?实测几款主流软件的结果
2026年的毕业季,学术审核的天,彻底变了。两个月前,我的一位研究生朋友提交了初稿,查重率12%,自己还挺满意。结果导师一句话让他当场emo:“你这AIGC检测率42%,是不是AI代写的?”他愣住…...

5分钟掌握跨平台资源下载:res-downloader新手完整指南
5分钟掌握跨平台资源下载:res-downloader新手完整指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 你是否经常…...

AI 教研科研一体化平台,以智能技术打通高校教研发展新路径
当前高校教学与科研工作普遍存在脱节割裂的问题,教学、教研、科研各成体系,资源分散、流程独立、数据不通。传统模式下,教师备课教学、课题研究、成果沉淀依靠人工完成,存在资源复用率低、科研选题盲目、教研过程无溯源、成果转化…...

为小型创业团队搭建经济可控的大模型应用开发平台
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为小型创业团队搭建经济可控的大模型应用开发平台 对于资源有限的创业团队而言,在拥抱大模型技术的同时,必…...

Open Generative AI Workflow Studio深度解析:可视化AI工作流构建教程
Open Generative AI Workflow Studio深度解析:可视化AI工作流构建教程 【免费下载链接】Open-Generative-AI Open-source alternative to AI video platforms — Free AI image & video generation studio with 200 models (Flux, Midjourney, Kling, Sora, Veo…...

Unity热更新本质与分层设计原理
1. 热更新不是“打补丁”,而是游戏生命周期的呼吸系统很多人第一次听说“Unity热更新”,脑子里立刻蹦出一个画面:玩家正在打Boss,突然弹出“检测到新版本,正在后台下载……3秒后重启生效”。然后下意识觉得——这不就是…...

ABAP中OAuth 2.0最小权限落地:从Authorization Code到AUTHORITY-CHECK
1. 这不是“配个Token就完事”的集成——为什么ABAP系统里OAuth 2.0落地总卡在“权限收不紧、业务接不住”上你有没有遇到过这样的场景:前端调用SAP Fiori应用时,后端ABAP系统明明配置了OAuth 2.0授权服务器,但一到实际业务环节就出问题——用…...

WarcraftHelper:如何快速解决魔兽争霸3在现代电脑上的三大兼容问题?
WarcraftHelper:如何快速解决魔兽争霸3在现代电脑上的三大兼容问题? 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为经典…...