基础课6——开放领域对话系统架构
开放领域对话系统是指针对非特定领域或行业的对话系统,它可以与用户进行自由的对话,不受特定领域或行业的知识和规则的限制。开放领域对话系统需要具备更广泛的语言理解和生成能力,以便与用户进行自然、流畅的对话。
与垂直领域对话系统相比,开放领域对话系统的构建更具挑战性,因为它需要处理更广泛的语言现象和用户行为,同时还需要进行更复杂的自然语言理解和生成任务。
目前,开放领域对话系统还处于研究和开发阶段,尚未有成熟的商业应用。但是,随着技术的不断进步和应用的不断深化,开放领域对话系统有望在未来成为人工智能领域的重要发展方向,为人们提供更加智能、自然、便捷的交互体验。
1.系统组成
开放领域对话系统的架构通常包括以下模块:
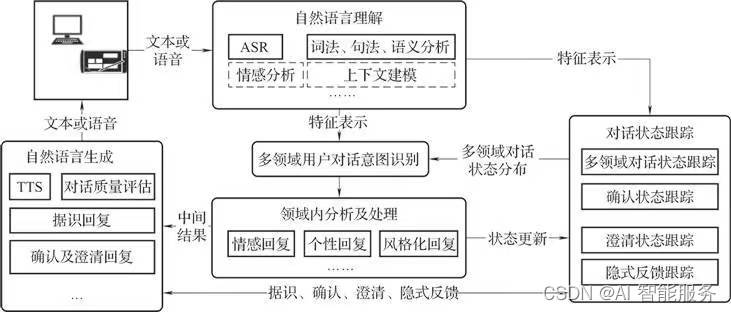
- 自然语言理解模块:负责对用户输入进行理解,包括句子的语义、情感、语言风格等信息。该模块将用户输入转化为计算机可理解的语言表示,为后续的处理提供基础。
- 对话管理模块:负责管理和维护对话状态,包括对话的上下文、历史记录、用户意图等信息。该模块通过不断更新对话状态,来维持与用户的对话,并保证对话的连贯性和流畅性。
- 自然语言生成模块:负责生成回复用户的信息,包括文本、语音、图像等形式。该模块将计算机理解的信息转化为用户易于理解的文本或语音,提高用户满意度和服务质量。
- 知识库和规则库模块:负责存储和管理领域知识和规则信息,包括事实、概念、关系等信息。该模块为对话系统提供基础的知识和规则支持,帮助系统更好地理解和回答用户问题。
- 机器学习模块:负责对系统进行训练和优化,包括模型训练、参数调整、性能评估等功能。该模块通过不断的学习和优化,来提高系统的性能和准确性。
在开放领域对话系统的架构中,各个模块之间相互协作,共同实现与用户的自由对话。同时,系统还需要具备高度的可扩展性和灵活性,以便能够适应不同领域和行业的需求。


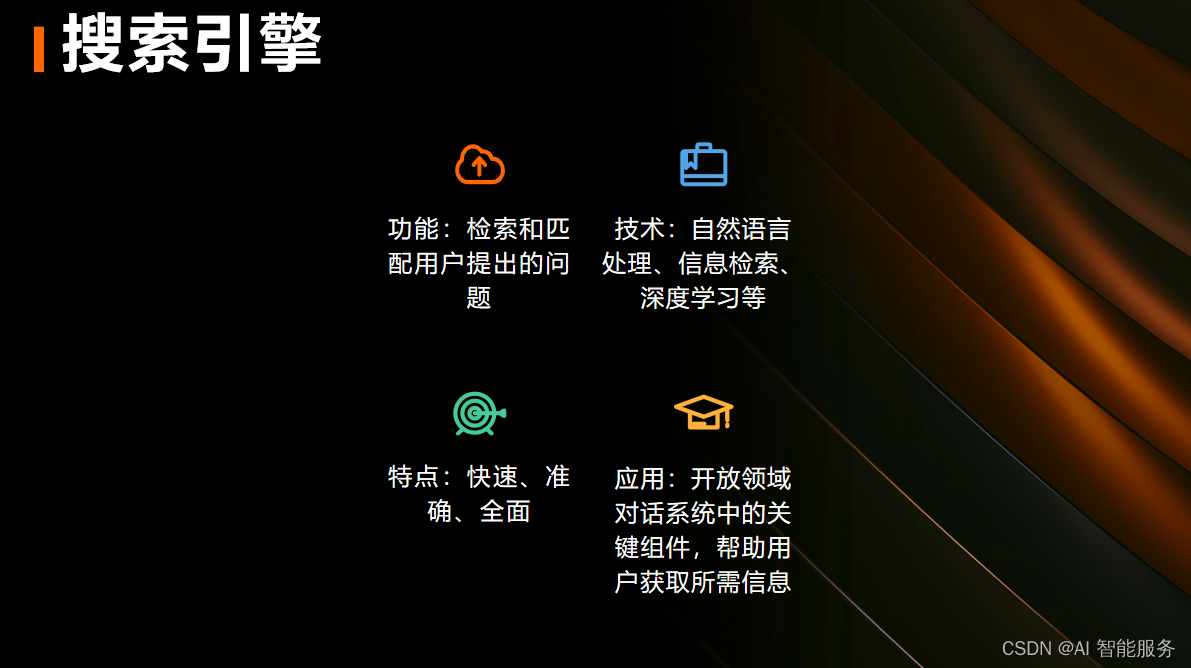
2.系统功能


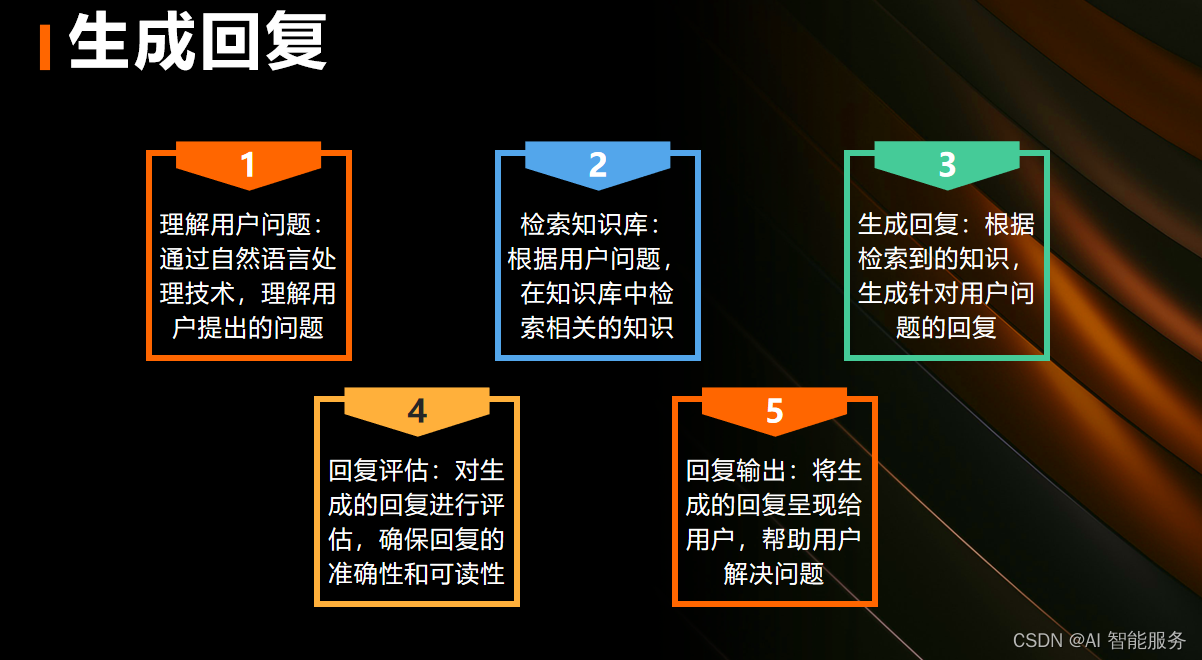
3.系统特点
开放领域对话系统具有以下特点:
- 自由对话:开放领域对话系统与用户之间可以进行任何话题的自由对话,不受特定主题或目标的限制。
- 丰富的知识库:开放领域对话系统需要具备丰富的知识库,以便能够回答用户提出的不同类型的问题。
- 多任务处理:开放领域对话系统可以完成多项任务,例如回答问题、提供建议、执行指令等。
- 社会性:开放领域对话系统需要具备一定的社会性,包括友好度、自觉性、幽默感等,以便能够与用户进行更为自然的交互。
- 上下文管理:开放领域对话系统需要对对话的上下文进行管理,以便能够理解用户的意图和维持对话的连贯性。
- 对话流程控制:开放领域对话系统需要对对话流程进行控制,包括引导对话、避免重复、确保信息准确等。
- 自然语言生成:开放领域对话系统需要具备自然语言生成的能力,以便能够生成自然、流畅的文本或语音回复用户。
- 高度可扩展性:开放领域对话系统需要具备高度可扩展性,以便能够适应不同领域和行业的需求。
开放领域对话系统是一种高度智能化、自然化、多功能的人工智能系统,能够与用户进行自由、自然的交互,并提供高质量的服务体验。

3.1优点
开放领域对话系统的优点主要包括:
- 广泛的适用性:开放领域对话系统可以应用于多个领域和行业,例如客户服务、虚拟助手、教育、智能家居等。这使得它可以满足不同用户的需求,并提高用户满意度。
- 自然语言交互:开放领域对话系统能够理解和生成自然语言,这使得用户可以以更自然、更直观的方式与系统进行交互,提高交互的效率和舒适度。
- 丰富的知识库:开放领域对话系统具备丰富的知识库,可以回答用户提出的不同类型的问题。这使得用户可以获得更全面、更准确的信息,并更好地了解相关领域的知识。
- 多任务处理能力:开放领域对话系统可以完成多项任务,例如回答问题、提供建议、执行指令等。这使得用户可以获得更全面、更个性化的服务体验。
- 社会性:开放领域对话系统具备一定的社会性,可以与用户进行更为自然的交互。这使得用户可以更好地感受到系统的友好度和亲切感,从而提高交互的舒适度。
- 高度可扩展性:开放领域对话系统需要具备高度可扩展性,以便能够适应不同领域和行业的需求。这使得系统可以随着技术的不断进步和应用的不断深化,不断进行优化和改进。
开放领域对话系统的优点在于它具有广泛的适用性、自然语言交互、丰富的知识库、多任务处理能力、社会性和高度可扩展性。这些优点使得开放领域对话系统成为一种高效、便捷、个性化的智能交互方式,可以满足不同用户的需求,提高用户满意度。
3.2缺点与困难

开放领域对话系统存在以下缺点和困难:
- 上下文理解和对话管理困难:开放领域对话系统需要理解和跟踪对话的上下文,以确保对话的连贯性和准确性。然而,由于开放领域对话系统的自由度和不确定性,理解和跟踪对话的上下文变得更加困难。此外,开放领域对话系统还需要进行多轮对话管理,以确保对话的流畅性和完整性。这需要系统具备较高的对话管理能力,包括对对话流程的掌控、对话内容的理解、用户意图的判断等。
- 语言处理和理解的复杂性:开放领域对话系统需要处理自然语言,这需要解决很多语言处理和理解的问题。例如,歧义性、一词多义、语法错误、语义理解等。这些问题的解决需要大量的数据和复杂的算法支持,增加了开放领域对话系统的复杂性和开发难度。
- 信息筛选和过滤困难:由于开放领域对话系统的自由度和不确定性,用户可能会输入大量不相关的信息,甚至是一些无意义的内容。因此,开放领域对话系统需要具备信息筛选和过滤的能力,以识别和筛选出有用的信息。这需要系统具备较高的自然语言处理和信息检索能力,增加了系统的复杂性和开发难度。
- 隐私和安全问题:开放领域对话系统需要处理用户的输入和输出信息,这涉及到用户的隐私和安全问题。因此,开放领域对话系统需要采取有效的隐私保护和安全措施,以确保用户数据的安全性和保密性。这需要系统具备较高的安全性能和隐私保护能力,增加了系统的开发难度和成本。
- 训练数据获取和标注困难:开放领域对话系统需要大量的训练数据来支持模型的训练和学习。然而,获取和标注大量高质量的训练数据是一项既耗时又耗力的任务,增加了系统的开发难度和成本。此外,由于语言的多样性和复杂性,训练数据的获取和标注也面临着很多挑战和困难。
开放领域对话系统存在上下文理解、语言处理和理解、信息筛选和过滤、隐私和安全问题以及训练数据获取和标注等方面的缺点和困难。这些问题的解决需要大量的技术投入和研发工作,增加了系统的开发难度和成本。
3.3用python搭建一个开放域智能客服
要使用Python搭建一个开放域智能客服,需要以下几个步骤:
1.数据收集和预处理
首先需要收集大量的文本数据,包括问题和答案。可以使用爬虫技术从互联网上抓取数据,或者从公开的数据集下载。收集到数据后,需要进行预处理,例如去除噪音、标准化文本等。
2.模型选择
在数据预处理之后,需要选择一个合适的模型来进行训练。可以选择的模型有很多种,例如基于规则的模型、基于统计的模型、深度学习模型等。在这里我们选择深度学习模型,因为它们可以自动从数据中学习规则和模式,并且具有很好的泛化性能。
3.模型训练
选择模型后,需要使用大量的数据来进行训练。可以使用Python中的机器学习库来进行训练,例如TensorFlow或PyTorch。在训练模型时,需要调整模型的参数,例如学习率、批次大小、隐藏层大小等,以便得到最好的性能。
4.模型评估和调整
训练模型后,需要评估模型的性能,以便了解模型是否能够正确地回答问题。可以使用测试集来进行评估,比较模型预测的答案和真实答案的匹配度。如果模型的性能不够好,需要对模型进行调整和优化,例如改变隐藏层大小、增加数据量等。
5.部署上线
完成模型训练和评估后,可以将模型部署到线上,以便用户访问。可以使用Python中的Web框架来进行部署,例如Flask或Django。在部署时,需要考虑如何处理用户输入和输出,以便得到最好的用户体验。
以上是搭建开放域智能客服的基本步骤。当然在实际操作中还需要考虑很多细节问题,例如如何保证数据的安全性和隐私性、如何处理用户反馈和投诉等。
代码展示
当然,下面是一个简单的示例代码,演示如何使用Python和TensorFlow搭建一个简单的开放域智能客服:python
import tensorflow as tf
import numpy as np
import re # 数据预处理
def preprocess_data(text): text = re.sub(r'\W+', ' ', text) # 将非字母数字字符替换为空格 text = text.lower() # 将文本转换为小写 text = text.split() # 将文本拆分为单词 return text # 构建词汇表
def build_vocab(text): word2idx = {} idx2word = {} words = set(text) for i, word in enumerate(words): word2idx[word] = i idx2word[i] = word return word2idx, idx2word # 构建模型
def build_model(vocab_size, embedding_dim, hidden_dim, output_dim): input_layer = tf.keras.Input(shape=(None,), dtype='int32') embedding_layer = tf.keras.layers.Embedding(vocab_size, embedding_dim)(input_layer) lstm_layer = tf.keras.layers.LSTM(hidden_dim)(embedding_layer) output_layer = tf.keras.layers.Dense(output_dim, activation='softmax')(lstm_layer) model = tf.keras.Model(inputs=input_layer, outputs=output_layer) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) return model # 训练模型
def train_model(model, data, labels, epochs): model.fit(data, labels, epochs=epochs, batch_size=32) # 评估模型
def evaluate_model(model, data, labels): loss, accuracy = model.evaluate(data, labels) return loss, accuracy
4.大模型涌现
2022年以来,大模型在开放域对话上表现出色。
ChatGPT是一种由OpenAI开发的大型语言模型,采用无监督学习方法,以Transformer为基础架构,能够通过使用大量的语料库进行训练来模拟人类的语言行为。它可以用来生成各种类型的文本,例如文章、新闻报道、产品描述、对话等。ChatGPT的目标是回答用户提出的问题或执行用户提供的指令,同时尽可能地使对话流畅自然。ChatGPT拥有大量的语料库和训练数据,这使得它能够生成高质量的文本内容,并且可以处理各种语言和主题。
ChatGPT的应用非常广泛,例如在聊天机器人、智能客服、自动翻译、自然语言处理等领域中都有应用。它也可以用于辅助写作和编辑,帮助人们快速生成高质量的文本内容。此外,ChatGPT还可以用于生成个性化的回复和答案,例如在社交媒体平台上自动回复用户的问题和评论。
【基础课5——垂直领域对话系统架构 - CSDN App】http://t.csdnimg.cn/5BUpt
相关文章:
基础课6——开放领域对话系统架构
开放领域对话系统是指针对非特定领域或行业的对话系统,它可以与用户进行自由的对话,不受特定领域或行业的知识和规则的限制。开放领域对话系统需要具备更广泛的语言理解和生成能力,以便与用户进行自然、流畅的对话。 与垂直领域对话系统相比…...
)
Hive常见的面试题(十二道)
Hive 1. Hive SQL 的执行流程 ⾸先客户端通过shell或者Beeline等⽅式向Hive提交SQL语句,之后sql在driver中经过 解析器(SQL Parser):将 SQL 字符串转换成抽象语法树 AST,这一步一般都用第三方工具库完成,比如 ANTLR&…...

1688商品详情API跨境专用接口php java
一、引言 随着全球电子商务的快速发展,跨境电子商务已经成为一种重要的国际贸易形式。1688作为全球最大的B2B电子商务平台之一,不仅拥有大量的商品资源,还为商家提供了丰富的API接口,以实现更高效、更便捷的电子商务活动。其中&a…...

h264流播放
参考文章: Android MediaCodec硬解码H264文件-CSDN博客...

02-1解析xpath
我是在edge浏览器中安装的xpath,需要安装的朋友可以参考下面这篇博客最新版edge浏览器中安装xpath插件 一、xpathd的使用 安装lxml pip install lxml ‐i https://pypi.douban.com/simple导入lxml.etree from lxml import etreeetree.parse() 解析本地文件 htm…...

Python算法——树的镜像
Python中的树的镜像算法详解 树的镜像是指将树的每个节点的左右子树交换,得到一棵新的树。在本文中,我们将深入讨论如何实现树的镜像算法,提供Python代码实现,并详细说明算法的原理和步骤。 树的镜像算法 树的镜像可以通过递归…...
ModStartCMS v7.6.0 CMS备份恢复优化,主题开发文档更新
ModStart 是一个基于 Laravel 模块化极速开发框架。模块市场拥有丰富的功能应用,支持后台一键快速安装,让开发者能快的实现业务功能开发。 系统完全开源,基于 Apache 2.0 开源协议,免费且不限制商业使用。 功能特性 丰富的模块市…...

vscode 推送本地新项目到gitee
一、gitee新建仓库 1、填好相关信息后点击创建 2、创建完成后复制 https,稍后要将本地项目与此关联 3、选择添加远程存储库 4、输入仓库地址,选择从URL添加远程存储仓库 5、输入仓库名称,确保仓库名一致...

C++函数指针变量
#include <iostream> using namespace std;void MyFun(int x){cout << x << endl; }//函数指针的声明 void (*FunP) (int);/*** MyFun的函数名与FunP函数指针都是一样的,即都是函数指针* MyFun函数名是一个“函数指针常量”* FunP是一个“函数指针…...
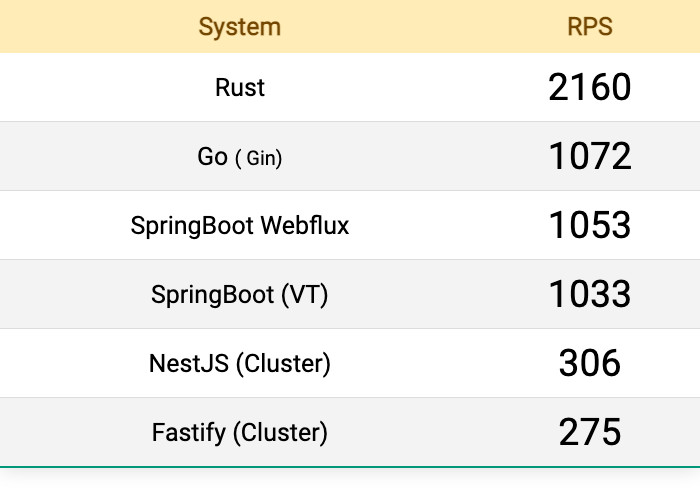
各类语言真实性能比较列表
这篇文章是我所做或将要做的所有真实世界性能比较的索引。如果你对想要看到的其他真实世界案例有建议,请在评论中添加。 用例 1 — JWT 验证 & MySQL 查询 该用例包括: 从授权头部获取 JWT验证 JWT 并从声明中获取电子邮件使用电子邮件执行 MySQL…...
华为笔记本MateBook D 14 2021款锐龙版R7集显非触屏(NbM-WFP9)原装出厂Windows10-20H2系统
链接:https://pan.baidu.com/s/13Kyy95GME-asli4woNN_ww?pwdbqa8 提取码:bqa8 HUAWEI华为MateBookD14原厂Win10系统自带所有驱动、出厂主题壁纸、系统属性专属LOGO标志、Office办公软件、华为电脑管家等预装程序...
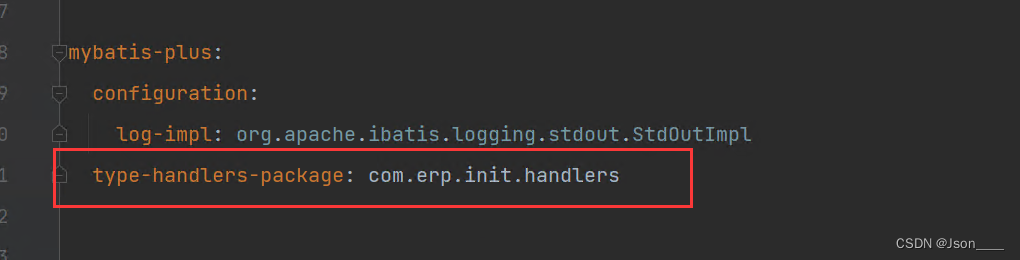
Springboot 对于数据库字段加密方案(此方案是对字符串处理的方案)
背景:在erp开发中,有些用户比较敏感数据库里的数据比较敏感,系统给用户部署后,公司也不想让任何人看到数据,所以就有了数据库字段加密方案。 技术 spring boot mybatisplus 3.3.1 mybatisplus 实际提供了 字段加密方案 第一 他…...

[C++]:8.C++ STL引入+string(介绍)
C STL引入string(介绍) 一.STL引入:1.什么是STL2.什么是STL的版本:2-1:原始版本:2-2:P. J 版本:2-3:RW 版本:2-4:SGL版本: 3.STL 的六大组件&…...
C++基础从0到1入门编程(三)
系统学习C 方便自己日后复习,错误的地方希望积极指正 往期文章: C基础从0到1入门编程(一) C基础从0到1入门编程(二) 参考视频: 1.黑马程序员匠心之作|C教程从0到1入门编程,学习编程不再难 2.系统…...

[Jenkins] 物理机 安装 Jenkins
这里介绍Linux CentOS系统直接Yum 安装 Jenkins,不同系统之间类似,操作命令差异,如:Ubuntu用apt; 0、安装 Jenkins Jenkins是一个基于Java语言开发的持续构建工具平台,主要用于持续、自动的构建/测试你的软…...
)
设计模式 -- 适配器模式(Adapter Pattern)
适配器模式:属于结构型模式,结合了两个独立接口的功能,作为 两个不兼容的接口之间的桥梁 。 介绍 意图:将一个类的接口转换成客户希望的另外一个接口。适配器模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。主要…...

Axios传值的几种方式
<body><script src"https://unpkg.com/axios/dist/axios.min.js"></script></body> axios基本使用 默认是get请求 注意:get请求无请求体,可以有body,但是不建议带 使用get方式进行无参请求 <script>axios(…...
git pull 报错 error object file is empty , The remote end hung up unexpectedly
报错原因分析:git pull的时候服务器在重启,导致git文件损坏 方法来源: 解决git错误: error object file is empty , The remote end hung up unexpectedly-CSDN博客 亲测有效 find .git/objects/ -type f -empty | xargs rm git fetch -p…...
手机数码类展示预约小程序效果如何
对于一家手机数码/电脑品牌来说,研发产品或衍生产品不少,通常会通过线上商城进行售卖。十年以来,流量成本逐渐增加,获客不易也难以寻找到合适的渠道,即使通过广告形式也因缺乏创意而耗时耗力,效果不佳。 同…...
图神经网络:消息传递算法
一、说明 图网络-GNN(Graph Neural Networks)是近几年研究的主题之一,虽不及深度神经网络那么火爆,但在一些领域,如分子化学方面是不得不依赖的理论。本文就一些典型意义的图神经网络消息传递展开阐述。 二、图网络简述…...

手把手教你为RV1126调试Sony IMX585:从设备树到驱动移植的完整避坑指南
RV1126平台Sony IMX585传感器移植实战:从设备树到图像调优的全流程解析 当拿到一块搭载RV1126芯片的开发板和Sony IMX585传感器模组时,如何快速完成从硬件对接到图像输出的完整流程?本文将深入剖析每个关键环节的技术细节与实战经验…...

鸣潮自动化终极指南:解放双手,轻松享受游戏乐趣的完整解决方案
鸣潮自动化终极指南:解放双手,轻松享受游戏乐趣的完整解决方案 【免费下载链接】ok-wuthering-waves 鸣潮 后台自动战斗 自动刷声骸 一键日常 Automation for Wuthering Waves 项目地址: https://gitcode.com/GitHub_Trending/ok/ok-wuthering-waves …...

3大远程管理痛点解决方案:MobaXterm中文版实现一站式终端效率革命
3大远程管理痛点解决方案:MobaXterm中文版实现一站式终端效率革命 【免费下载链接】Mobaxterm-Chinese Mobaxterm simplified Chinese version. Mobaxterm 的简体中文版. 项目地址: https://gitcode.com/gh_mirrors/mo/Mobaxterm-Chinese 远程服务器管理面临…...

5分钟搞定TikTok数据采集:DouK-Downloader终极批量下载神器
5分钟搞定TikTok数据采集:DouK-Downloader终极批量下载神器 【免费下载链接】TikTokDownloader TikTok 发布/喜欢/合辑/直播/视频/图集/音乐;抖音发布/喜欢/收藏/收藏夹/视频/图集/实况/直播/音乐/合集/评论/账号/搜索/热榜数据采集工具/下载工具 项目…...

差点把用户数据泄漏给Claude Code后,我写了个 Rust 工具
两周前,我把公司的数据库接进了Claude Code,效率确实起飞了,直到我翻了一下会话记录。 两周前 公司的 PostgreSQL 数据库接进了Claude Code以后,AI 确实能干——帮我写迁移、联表、生成报表,效率直接起飞。 直到我随…...

朱雀广告平台:技术架构深度解析与高性能广告解决方案构建
朱雀广告平台:技术架构深度解析与高性能广告解决方案构建 【免费下载链接】zhuque 开放源码的一站式广告平台,包含ssp/adx/dsp/dmp模块 项目地址: https://gitcode.com/gh_mirrors/zhu/zhuque 在数字广告技术快速演进的今天,广告平台面…...

Keil编译器数据类型详解与嵌入式开发实践
1. 变量范围查询指南:Keil编译器数据类型详解 作为一名嵌入式开发老手,我深知在Keil环境下编程时,准确掌握各种数据类型的取值范围是多么重要。今天就来系统梳理C51/C166/C251编译器中的数据类型范围问题,这些经验都是我在实际项目…...

5个实战技巧:Unlock-Music浏览器端音乐解密技术深度解析
5个实战技巧:Unlock-Music浏览器端音乐解密技术深度解析 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: htt…...

企业内训系统集成Taotoken实现多模型AI助教与可控的交互成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内训系统集成Taotoken实现多模型AI助教与可控的交互成本 对于现代企业而言,构建一个高效、智能的内训系统是提升员…...

ZeRO显存优化原理:从Adam状态切分到三阶段实战配置
1. 项目概述:当大模型训练卡在显存上,ZeRO 是怎么“拆墙”又“省电”的?你有没有试过在单张 A100 上跑一个 7B 参数的 LLaMA 模型微调?刚把模型 load 进去,torch.cuda.memory_allocated()就飙到 98%,OOM报错…...