大模型之十二十-中英双语开源大语言模型选型
从ChatGPT火爆出圈到现在纷纷开源的大语言模型,众多出入门的学习者以及跃跃欲试的公司不得不面临的是开源大语言模型的选型问题。
基于开源商业许可的开源大语言模型可以极大的节省成本和加速业务迭代。
当前(2023年11月17日)开源的大语言模型如下:
| 模型 | 所属公司 | 发布时间 | 开放模型 | 许可 | 词表大小 | 语料 | Huggingface下载量 | 模型结构 | 位置编码 | 激活函数 | 隐变量维度dimension | 自注意力头的个数n heads | 层数n layers | 输入序列长度sequence length | 训练时长 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LLaMA-2 | Meta | 2023年8月 | 7B 13B 70B | 允许商用,月活超7亿需向Meta申请许可 | 32000 | 2.0T | 70B-chat下载量1.69M,变种还有若干 | Casual decoder | RoPE | SwiGLU | Pre RMS Norm | 7B 4096, 13B 5120, 70B 8192 | 7B 32, 13B 40, 70B 64 | 7B 32, 13B 40, 70B 80 | 4096 | A100 7B 184320, 13B 368640, 70B 1720320 |
| baichuan-2 | 百川智能 | 2023年9月6日 | 7B 13B base/chat | 代码Apache 2.0,模型非商用 | 125696 | 2.6T | 1-7B 95.5k,2-13B 40.8k, 2-7B 20.5k | Prefix decoder | RoPE | GeGLU | Post Deep Norm | 7B 4096, 13B 5120 | 7B 32, 13B 40 | 7B 32, 13B 40 | 4096 | |
| ChatGLM3 | 智普 | 2023年10月 | 6B | 填问卷登记后允许免费商业使用 | 65024 | 1.5T左右中英 | 8k | Casual decoder | RoPE | SwiGLU | Post Deep Norm | 4096 | 32 | 28 | 8192 | |
| 千问 | 阿里 | 2023年8月 | 7B 14B | 允许商用,超过1亿用户机构需申请 | 151936 | 7B 2.4T,14B 3.0T | 25k | Casual decoder | RoPE | SwiGLU | Pre Layer Norm | 4096 | 32 | 32 | 8192 | |
| Bloom | BigScience | 2022年7月 | 560M 1.1B 1.7B 3B 7.1B | 允许商用 | 250880 | 366B | 125M | Casual decoder | ALiBi | GeLU | Pre Layer Norm | 4096 | 32 | 30 | 2048 |
- LLaMA-2的词表是32k,在中英文上的平均token数最多,对中英文分词比较碎,比较细粒度。尤其在中文上平均token数高达1.45,这意味着大概率会将中文字符切分为2个以上的token。
- ChatGLM3-6B是平衡中英文分词效果最好的tokenizer。由于词表比较大,中文处理时间也有增加。
- BLOOM虽然是词表最大的,但由于是多语种的,在中英文上分词效率与ChatGLM-6B基本相当。
还有很多其他的开源中英大语言模型,但基本都有Llama的影子,有些是直接扩充Lllama的词汇再用新的数据集重新训练,这些大语言模型包括Chinese-LLaMA-Alpaca-2、OpenChineseLLaMA、Panda、Robin (罗宾)、Fengshenbang-LM等,这里就不一一列出了。
和信息大爆炸一样,模型也是呈现大爆炸的态势,如何选择一个合适自己/公司业务场景的基座大模型就显得十分重要,模型选择的好,至于训练方法和一些训练技巧以及超参设置都不那么重要,相对而言数据工程确是相对重要的。一个模型的选择需要结合自身的目的和资源决定。
从模型到落地,涉及到方方面面的东西,相对而言模型公司也注意到了,所以开源模型也会附带一些Agent等支持。选择模型第一要考虑的是license问题,如果是学习目的,那么几乎所有开源的大语言模型都可以选择,结合算力和内存资源选择合适参数量的模型即可,如果是蹭免费GPU的,建议选择7B及以下的模型参数。
如果是商用目的的建议选择70B及以上的模型,个别很窄的垂直领域也可以考虑30B左右的,甚至是7B的参数,如果是端上智能,考虑7B参数量。
10B以内的中英模型,建议选择chatglm3-6B(生态工具支持也挺好,性能在10B里中英文很不错,上下文长度基座有8k,长上下文大32k)以及llama-2的变种(LlaMA-2生态很好,工具很多)模型。算力有限的学生建议选择Bloom 1.1B模型。
chatglm和LlaMA-2在模型有些差异,关于mask和norm的差异性区别如下。
transformer中的mask机制:
mask机制是用于Transformer模型self-attention机制中的技术,用以控制不同token之间的注意力交互。有两种类型的mask:padding mask和sequence mask。
- Padding mask(填充掩码):在自注意力机制中,句子中的所有单词都会参与计算。但是,在实际的句子中,往往会存在填充符,用来填充句子长度不够的情况。Padding mask就是将这些填充符对应的位置标记为0,以便在计算中将这些位置的单词忽略掉。
- Sequence mask(序列掩码):sequence mask用于在Decoder端的self-attention中,以保证在生成序列时不会将未来的信息泄露给当前位置的单词。
Norm层
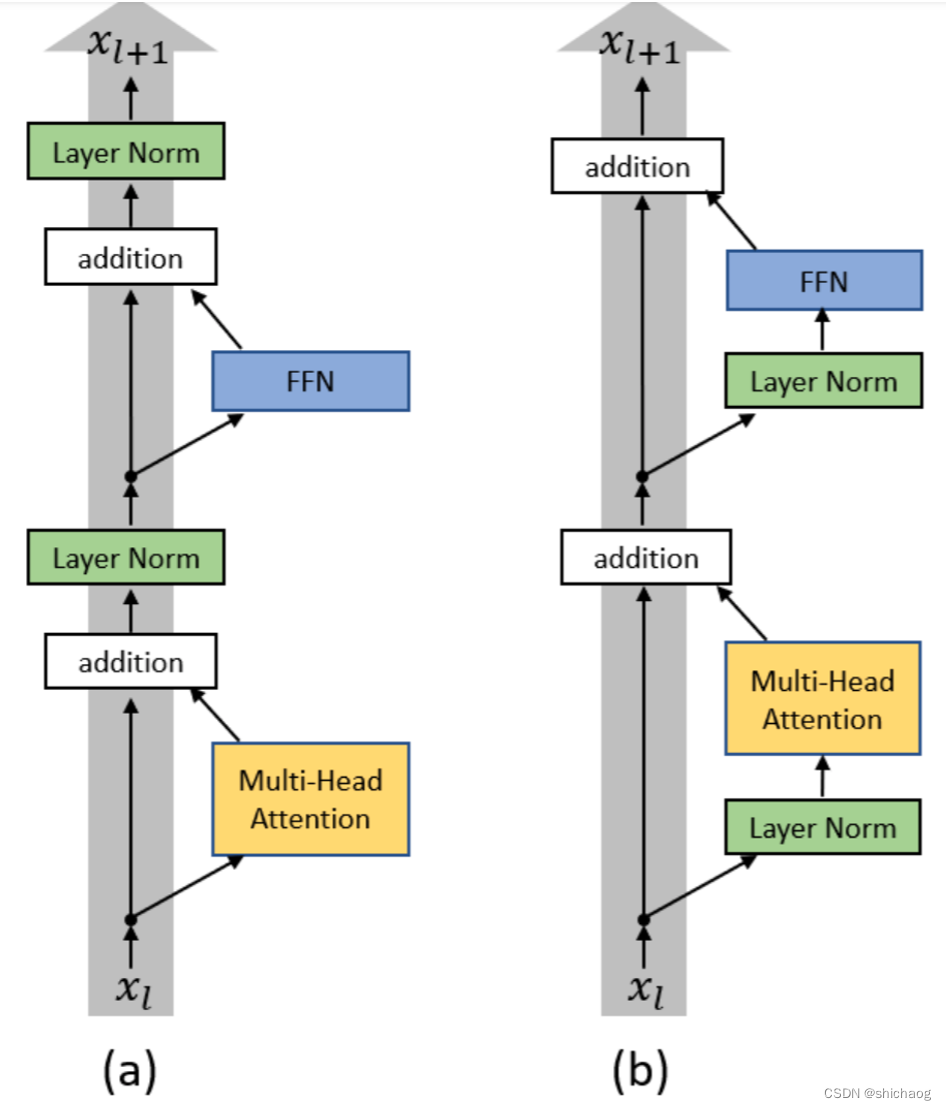
-
post layer norm。在原始的transformer中,layer normalization是放在残差连接之后的,称为post LN。使用Post LN的深层transformer模型容易出现训练不稳定的问题。post LN随着transformer层数的加深,梯度范数逐渐增大,导致了训练的不稳定性。
-
pre layer norm。将layer norm放在残差连接的过程中,self-attention或FFN块之前,称为“Pre LN”。Pre layer norm在每个transformer层的梯度范数近似相等,有利于提升训练稳定性,但缺点是pre LN可能会轻微影响transformer模型的性能,为了提升训练稳定性,GPT3、PaLM、BLOOM、OPT等大语言模型都采用了pre layer norm。
- LayerNorm:LayerNorm对每一层的所有激活函数进行标准化,使用它们的均值和方差来重新定位和调整激活函数。其公式如下:
x − μ σ ⋅ γ β , μ = 1 d ∑ i = 1 d x i , σ = 1 d ∑ i = 1 d ( x i − μ ) 2 \frac{\mathbf x -\mu}{\sqrt{\sigma}} \cdot \gamma \beta, \mu=\frac{1}{d} \sum_{i=1}^dx_i, \sigma=\sqrt{\frac{1}{d}\sum_{i=1}^{d}(x_i-\mu)^2} σx−μ⋅γβ,μ=d1i=1∑dxi,σ=d1i=1∑d(xi−μ)2 -
- RMSNorm:RMSNorm通过仅使用激活函数的均方根来重新调整激活,从而提高了训练速度。
x R M S ( x ) ⋅ γ , R M S ( x ) = 1 d ∑ i = 1 d x i 2 \frac{\mathbf x}{RMS(\mathbf x)} \cdot \gamma, RMS(\mathbf x)=\sqrt{\frac{1}{d}\sum_{i=1}^dx_i^2} RMS(x)x⋅γ,RMS(x)=d1i=1∑dxi2
- LayerNorm:LayerNorm对每一层的所有激活函数进行标准化,使用它们的均值和方差来重新定位和调整激活函数。其公式如下:
-
- DeepNorm:为了进一步稳定深度Transformer的训练,Microsoft推出了DeepNorm。这是一个创新的方法,它不仅用作标准化,还作为残差连接。有了DeepNorm的帮助,我们现在可以轻松训练高达1000层的Transformer模型,同时保持稳定性和高性能。其中,GLM-130B和ChatGLM就是采用了这种技术的代表。其公式如下:其中SublayerSublayer是FFN或Self-Attention模块。
L a y e r N o r m ( α ⋅ x + S u b l a y e r ( x ) ) LayerNorm(\alpha\cdot \mathbf x+Sublayer(\mathbf x)) LayerNorm(α⋅x+Sublayer(x))
- DeepNorm:为了进一步稳定深度Transformer的训练,Microsoft推出了DeepNorm。这是一个创新的方法,它不仅用作标准化,还作为残差连接。有了DeepNorm的帮助,我们现在可以轻松训练高达1000层的Transformer模型,同时保持稳定性和高性能。其中,GLM-130B和ChatGLM就是采用了这种技术的代表。其公式如下:其中SublayerSublayer是FFN或Self-Attention模块。
相关文章:
大模型之十二十-中英双语开源大语言模型选型
从ChatGPT火爆出圈到现在纷纷开源的大语言模型,众多出入门的学习者以及跃跃欲试的公司不得不面临的是开源大语言模型的选型问题。 基于开源商业许可的开源大语言模型可以极大的节省成本和加速业务迭代。 当前(2023年11月17日)开源的大语言模型如下&#…...
.Net6 部署到IIS示例
基于FastEndpoints.Net6 框架部署到IIS 环境下载与安装IIS启用与配置访问网站 环境下载与安装 首先下载环境安装程序,如下图所示,根据系统位数选择x86或者x64进行下载安装,网址:Download .NET 6.0。 IIS启用与配置 启用IIS服务 打开控制面板ÿ…...
轻松搭建短域名短链接服务系统,可选权限认证,并自动生成证书认证把nginx的http访问转换为https加密访问,完整步骤和代码
轻松搭建短域名短链接服务系统,可选权限认证,并自动生成证书认证把nginx的http访问转换为https加密访问,完整步骤和代码。 在互联网信息爆炸的时代,网址复杂而冗长,很难在口头告知他人,也难以分享到社交媒体…...

JS 日期格式化
日期格式化 parseTime: // 日期格式化 export function parseTime(time, pattern) {if (arguments.length 0 || !time) {return null}const format pattern || {y}-{m}-{d} {h}:{i}:{s}let dateif (typeof time object) {date time} else {if ((typeof time st…...
右键菜单和弹出菜单的区别
接触windows开发10年了,一直以为"右键菜单"和"弹出菜单"是不同的。 最近刚刚发现,这两种菜单在定义的时候和消息循环处理程序中并没有什么不同,区别只是在于windows底层显示方式。 如下是右键菜单的显示方式࿱…...
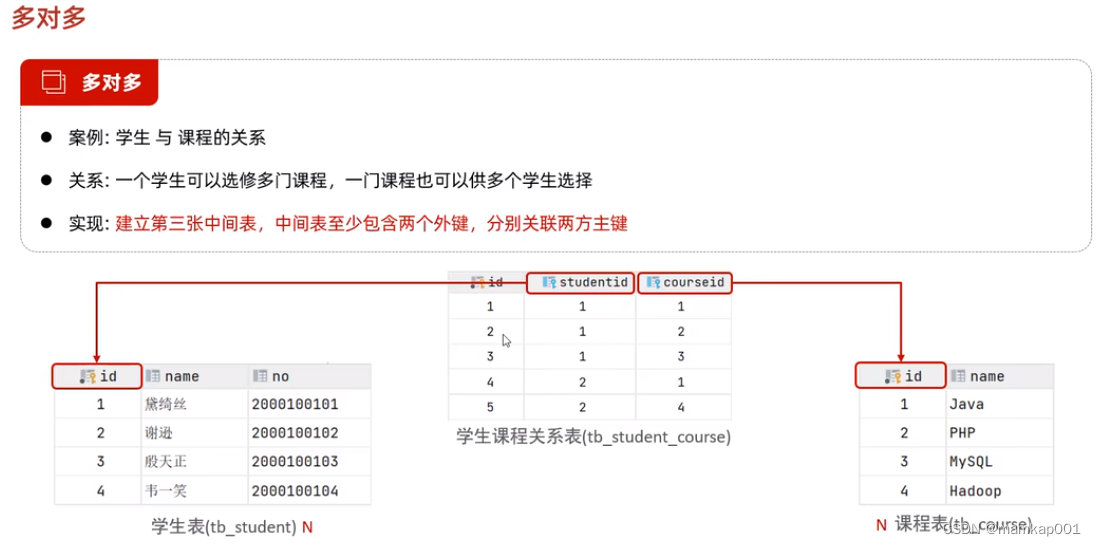
查询数据库DQL
DQL 查询基本语法 -- DQL :基本语法; -- 1查询指定的字段 name entrydate 并返回select name , entrydate from tb_emp;-- 2 查询 所有字段 并返回select id, username, password, name, gender, image, job, entrydate, create_time, update_time from tb_emp;-- 2 查询…...

SpringBoot中文乱码问题解决方案
在Spring Boot中,确实没有像传统Web应用程序中需要使用web.xml配置文件。对于中文乱码问题,你可以采取以下几种方式来解决: 在application.properties文件中添加以下配置: spring.http.encoding.charsetUTF-8 spring.http.encod…...
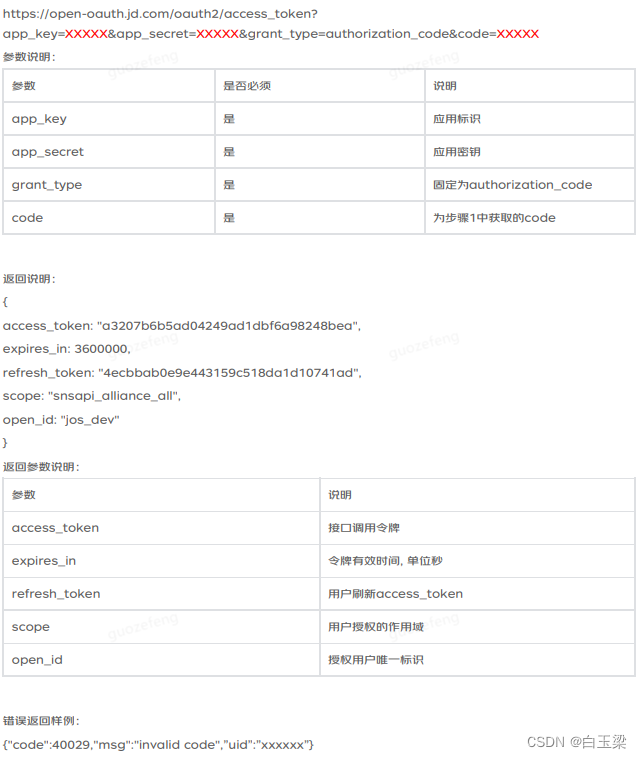
京东联盟flutter插件使用方法
目录 1.京东联盟官网注册申请步骤略~2.安卓端插件配置:3.IOS端插件配置4.其它配置5.京东OAuth授权 文档地址:https://baiyuliang.blog.csdn.net/article/details/134444104 京东联盟flutter插件地址:https://pub.dev/packages/jdkit 1.京东联…...

python电影数据可视化分析系统的设计与实现【附源码】
电影数据可视化分析系统的设计与实现 (一)开题报告,就是确定设计(论文)选题之后,学生在调查研究的基础上撰写的研究计划,主要说明设计(论文)研究目的和意义、研究的条件以及如何开展研究等问题,也可以说是对设计(论文)的论证和设…...
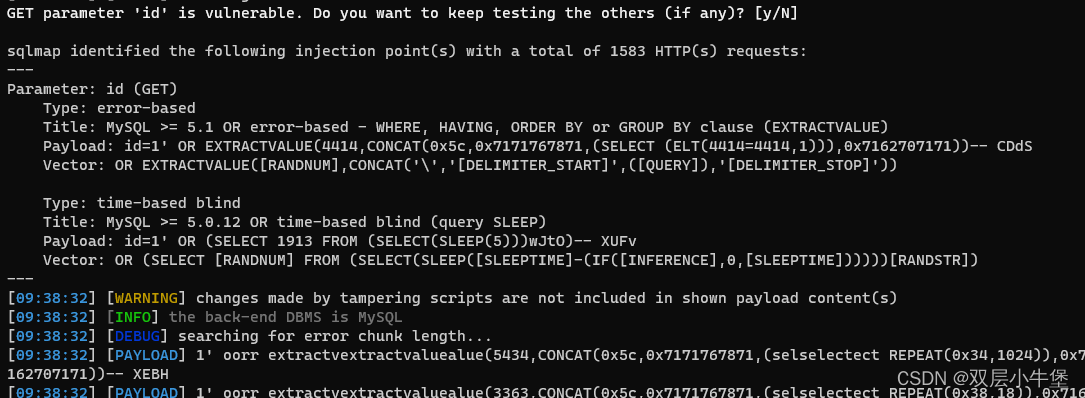
SQLMAP --TAMPER的编写
跟着师傅的文章进行学习 sqlmap之tamper脚本编写_sqlmap tamper编写-CSDN博客 这里学习一下tamper的编写 这里的tamper 其实就是多个绕过waf的插件 通过编写tamper 我们可以学会 在不同过滤下 执行sql注入 我们首先了解一下 tamper的结构 这里我们首先看一个最简单的例子…...
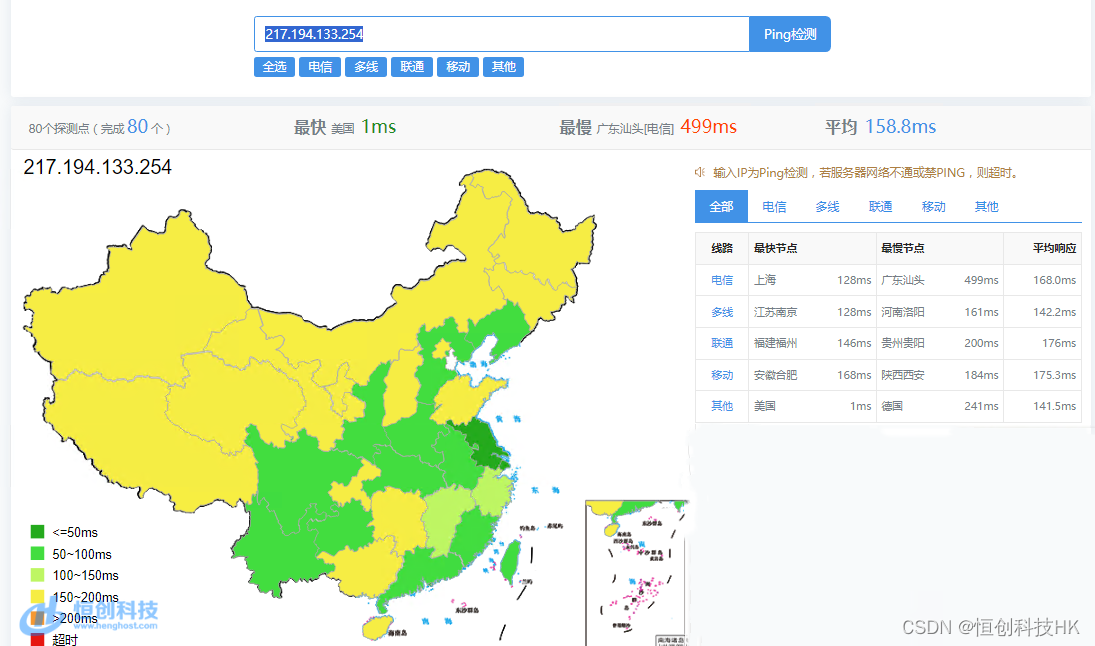
美国服务器:全面剖析其主要优点与潜在缺点
服务器是网站搭建的灵魂。信息化的今天,我们仍需要它来为网站和应用程序提供稳定的运行环境。而美国作为全球信息技术靠前的国家之一,其服务器市场备受关注。那么,美国服务器究竟有哪些主要优点和潜在缺点呢? 优点 数据中心基础设施&a…...
验证二叉搜索树
二叉搜索树 二叉查找树(Binary Search Tree),(又:二叉搜索树,二叉排序树)它或者是一棵空树,或者是具有下列性质的二叉树: 若它的左子树不空,则左子树上所有结…...
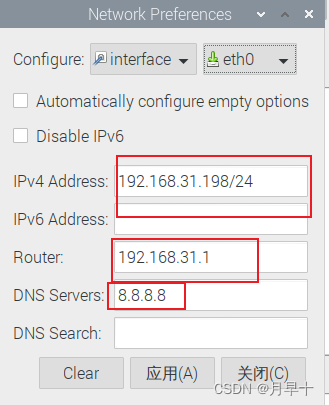
Ubuntu 18.04无网络连接的n种可能办法
文章目录 网络图标消失,Ubuntu无网络连接VMware上Ubuntu18.04,桥接了多个网卡,其中一个用来上网,均设置为静态ip网络桥接链路没有接对路由不对 树莓派同时使用无线网卡和有线网卡,且一个连接内部局域网,一个…...
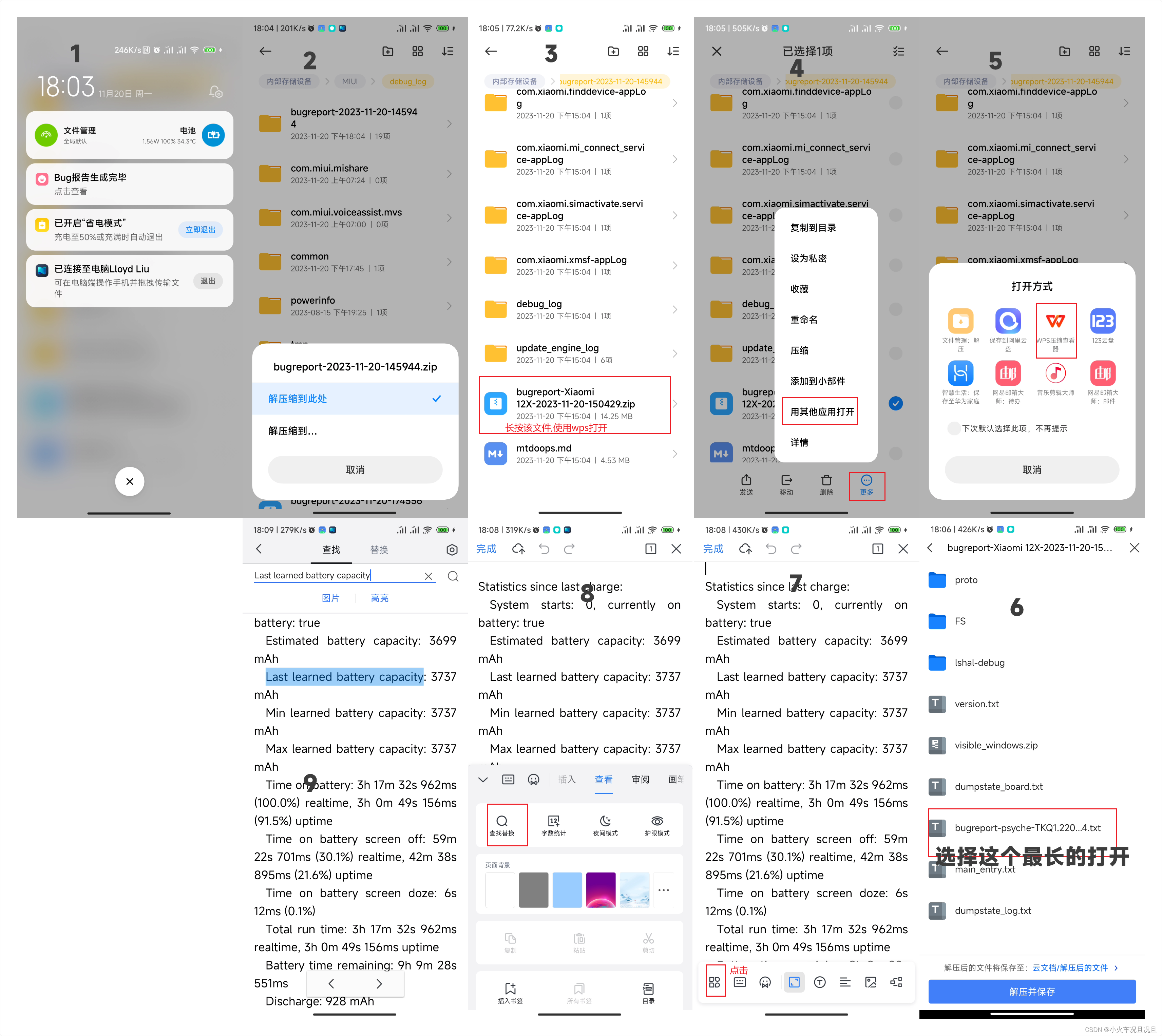
MIUI查看当前手机电池容量
MIUI查看当前手机电池容量 1. 按如下步骤操作生成bug报告 2. 按如下操作解压bug报告 Last learned battery capacity...
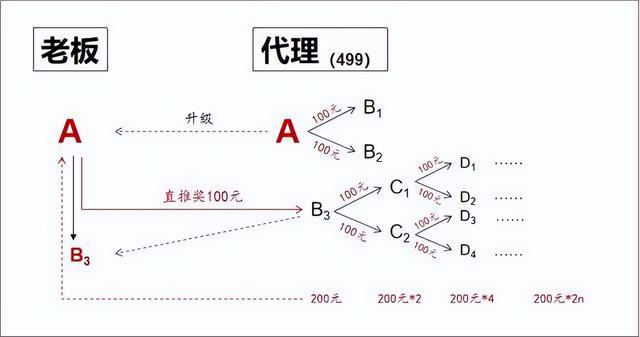
链动2+1模式:创新营销引领白酒产业新潮流
在当今高度竞争的市场环境中,创新营销模式对于企业的发展至关重要。链动21模式作为一种独特的营销策略,将白酒产品与该模式相结合,充分发挥其优势,通过独特的身份晋升和奖励机制,快速建立销售渠道,提高用户…...

openGauss学习笔记-126 openGauss 数据库管理-设置账本数据库-归档账本数据库
文章目录 openGauss学习笔记-126 openGauss 数据库管理-设置账本数据库-归档账本数据库126.1 前提条件126.2 背景信息126.3 操作步骤 openGauss学习笔记-126 openGauss 数据库管理-设置账本数据库-归档账本数据库 126.1 前提条件 系统中需要有审计管理员或者具有审计管理员权…...
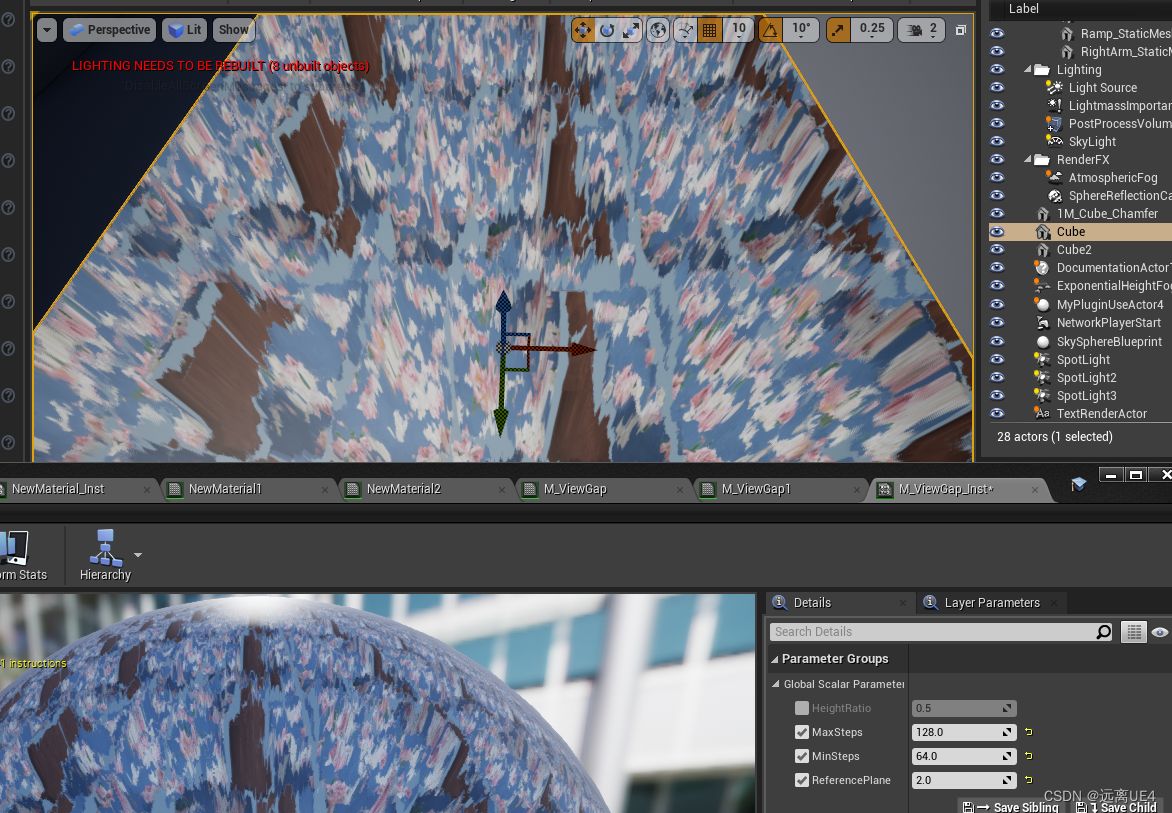
UE 视差材质 学习笔记
视差材质节点: 第一个是高度图, Heightmap Channel就是高度图的灰色通道,在RGBA哪个上面,例如在R上就连接(1,0,0,0),G上就连接(0,1,0,0)逐次类推 去看看对比效果: 这个是有视差效果…...

openfeign整合sentinel出现异常
版本兼容的解决办法:在为userClient注入feign的接口类型时,添加Lazy注解。 Lazy注解是Spring Framework中的一个注解,它通常用于标记Bean的延迟初始化。当一个Bean被标记为Lazy时,Spring容器在启动时不会立即初始化这个Bean&…...

Java的继承
继承(Inheritance) 【1】类是对对象的抽象: 举例: 荣耀20 ,小米 红米3,华为 p40 pro ---> 类:手机类 【2】继承是对类的抽象: 举例: 学生类:Student: 属性&…...

十二、Docker的简介
目录 一、介绍 Docker 主要由以下三个部分组成: Docker 有许多优点,包括: 二、Docker和虚拟机的差异 三、镜像和容器 四、Docker Hub 五、Docker架构 六、总结 一、介绍 Docker 是一种开源的应用容器平台,可以在容器内部…...

G-Helper终极指南:告别Armoury Crate臃肿体验的3步高效方案
G-Helper终极指南:告别Armoury Crate臃肿体验的3步高效方案 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenboo…...

Play Integrity API Checker:三步快速检测你的Android设备安全完整指南 [特殊字符]
Play Integrity API Checker:三步快速检测你的Android设备安全完整指南 🔐 【免费下载链接】play-integrity-checker-app Get info about your Device Integrity through the Play Intergrity API 项目地址: https://gitcode.com/gh_mirrors/pl/play-i…...

Debian服务器网络配置二选一:告别network与NetworkManager冲突,保姆级教程教你选对工具
Debian服务器网络配置终极指南:network与NetworkManager深度解析与实战选择 在Linux系统中,网络配置是系统管理员和开发者必须掌握的核心技能之一。Debian作为最流行的Linux发行版之一,提供了两种主要的网络管理工具:传统的ifupdo…...

2026电动车趋势:智驾与电池深度融合
2026年电动汽车(EV)发展趋势全景分析 2026年的全球电动汽车产业将迈入一个技术加速融合、市场竞争白热化与商业模式深度创新的关键阶段。其发展趋势可解构为核心技术突破、市场格局演变、供应链重塑及政策生态协同四个维度。以下结合具体数据、案例和技…...

皮线、裸纤总是分不清?试试这个算法一键校准技巧
不知道你有没有经历过这种工地上的"崩溃瞬间":大热天蹲在居民楼昏暗的楼道里,蚊子在耳边嗡嗡叫,你手里正拉着一根刚从住户门缝里拽出来的皮线光缆,准备跟分纤箱引出来的单模裸纤做熔接。结果放进机器,合上盖…...
)
别再怪PoE不稳定了!手把手教你排查网线、供电、配置三大坑(附真实监控项目踩坑实录)
PoE稳定性实战指南:从网线到供电的深度排查手册 凌晨三点,监控室突然响起警报——某重要区域的摄像头集体离线。值班工程师的第一反应往往是"设备又坏了",但真实情况可能藏在那些容易被忽略的细节里:一根劣质网线在低温…...

APT32F110 RISC-V开发板printf重定向与串口花式表白项目实战
1. 项目概述:从“Hello World”到“花式表白”的嵌入式浪漫作为一名在嵌入式领域摸爬滚打了十多年的老工程师,我调试过无数块开发板,写过数不清的“Hello World”。但当我拿到爱普特APT32F110这块基于国产RISC-V内核的开发板时,我…...

AI Agent Harness Engineering 反思机制3大实现路径:日志回溯 vs 强化学习 vs 人工反馈
AI Agent Harness Engineering 反思机制3大实现路径:日志回溯 vs 强化学习 vs 人工反馈 引言 痛点引入 想象一下:你花了整整两周,用 LangChain、AutoGPT 或者 LlamaIndex 搭了一个帮你写产品PRD草稿的AI Agent。你给它输入了竞品分析报告、用户访谈纪要、项目进度表,满心…...

2026年腾讯云OpenClaw/Hermes Agent配置Token Plan安装超全攻略
2026年腾讯云OpenClaw/Hermes Agent配置Token Plan安装超全攻略。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token Plan兼容主流 AI 工具&…...

企业微信桌面端深度集成:DLL注入与协议逆向实战
1. 这不是“黑产教程”,而是企业级办公系统集成的现实路径“微信逆向与DLL注入”这八个字,一出来就容易让人联想到灰色地带、安全攻防、甚至违规外挂。但今天我要说的,是另一条路——一条我带团队在三年内落地了7个大型政企客户微信生态集成项…...