卷积神经网络(VGG-19)灵笼人物识别
文章目录
- 前期工作
- 1. 设置GPU(如果使用的是CPU可以忽略这步)
- 我的环境:
- 2. 导入数据
- 3. 查看数据
- 二、数据预处理
- 1. 加载数据
- 2. 可视化数据
- 3. 再次检查数据
- 4. 配置数据集
- 5. 归一化
- 三、构建VGG-19网络
- 1. 官方模型(已打包好)
- 2. 自建模型
- 3. 网络结构图
- 四、编译
- 五、训练模型
- 六、模型评估
- 七、保存and加载模型
- 八、预测
前期工作
1. 设置GPU(如果使用的是CPU可以忽略这步)
我的环境:
- 语言环境:Python3.6.5
- 编译器:jupyter notebook
- 深度学习环境:TensorFlow2.4.1
import tensorflow as tfgpus = tf.config.list_physical_devices("GPU")if gpus:tf.config.experimental.set_memory_growth(gpus[0], True) #设置GPU显存用量按需使用tf.config.set_visible_devices([gpus[0]],"GPU")
2. 导入数据
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号import os,PIL# 设置随机种子尽可能使结果可以重现
import numpy as np
np.random.seed(1)# 设置随机种子尽可能使结果可以重现
import tensorflow as tf
tf.random.set_seed(1)from tensorflow import keras
from tensorflow.keras import layers,modelsimport pathlib
data_dir = "weather_photos/"
data_dir = pathlib.Path(data_dir)
3. 查看数据
数据集中一共有白月魁、查尔斯、红蔻、马克、摩根、冉冰等6个人物角色。
| 文件夹 | 含义 | 数量 |
|---|---|---|
| baiyuekui | 白月魁 | 40 张 |
| chaersi | 查尔斯 | 76 张 |
| hongkou | 红蔻 | 36 张 |
| make | 马克 | 38张 |
| mogen | 摩根 | 30 张 |
| ranbing | 冉冰 | 60张 |
image_count = len(list(data_dir.glob('*/*')))print("图片总数为:",image_count)
二、数据预处理
1. 加载数据
使用image_dataset_from_directory方法将磁盘中的数据加载到tf.data.Dataset中
batch_size = 32
img_height = 224
img_width = 224
train_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.1,subset="training",seed=123,image_size=(img_height, img_width),batch_size=batch_size)
Found 280 files belonging to 6 classes.
Using 252 files for training.
val_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.1,subset="validation",seed=123,image_size=(img_height, img_width),batch_size=batch_size)
Found 280 files belonging to 6 classes.
Using 28 files for validation.
我们可以通过class_names输出数据集的标签。标签将按字母顺序对应于目录名称。
class_names = train_ds.class_names
print(class_names)
['baiyuekui', 'chaersi', 'hongkou', 'make', 'mogen', 'ranbing']
2. 可视化数据
plt.figure(figsize=(10, 5)) # 图形的宽为10高为5for images, labels in train_ds.take(1):for i in range(8):ax = plt.subplot(2, 4, i + 1) plt.imshow(images[i].numpy().astype("uint8"))plt.title(class_names[labels[i]])plt.axis("off")

plt.imshow(images[1].numpy().astype("uint8"))

3. 再次检查数据
for image_batch, labels_batch in train_ds:print(image_batch.shape)print(labels_batch.shape)break
(16, 224, 224, 3)
(16,)
Image_batch是形状的张量(16,180,180,3)。这是一批形状180x180x3的16张图片(最后一维指的是彩色通道RGB)。Label_batch是形状(16,)的张量,这些标签对应16张图片
4. 配置数据集
AUTOTUNE = tf.data.AUTOTUNEtrain_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
5. 归一化
normalization_layer = layers.experimental.preprocessing.Rescaling(1./255)
normalization_train_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
val_ds = val_ds.map(lambda x, y: (normalization_layer(x), y))
image_batch, labels_batch = next(iter(val_ds))
first_image = image_batch[0]
# 查看归一化后的数据
print(np.min(first_image), np.max(first_image))
0.0 0.9928046
三、构建VGG-19网络
VGG优缺点分析:
- VGG优点
VGG的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸(3x3)和最大池化尺寸(2x2)。
- VGG缺点
1)训练时间过长,调参难度大。2)需要的存储容量大,不利于部署。例如存储VGG-16权重值文件的大小为500多MB,不利于安装到嵌入式系统中。
1. 官方模型(已打包好)
官网模型调用这块我放到后面几篇文章中,下面主要讲一下VGG-19
# model = keras.applications.VGG19(weights='imagenet')
# model.summary()
2. 自建模型
from tensorflow.keras import layers, models, Input
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, Dropoutdef VGG19(nb_classes, input_shape):input_tensor = Input(shape=input_shape)# 1st blockx = Conv2D(64, (3,3), activation='relu', padding='same',name='block1_conv1')(input_tensor)x = Conv2D(64, (3,3), activation='relu', padding='same',name='block1_conv2')(x)x = MaxPooling2D((2,2), strides=(2,2), name = 'block1_pool')(x)# 2nd blockx = Conv2D(128, (3,3), activation='relu', padding='same',name='block2_conv1')(x)x = Conv2D(128, (3,3), activation='relu', padding='same',name='block2_conv2')(x)x = MaxPooling2D((2,2), strides=(2,2), name = 'block2_pool')(x)# 3rd blockx = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv1')(x)x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv2')(x)x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv3')(x)x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv4')(x)x = MaxPooling2D((2,2), strides=(2,2), name = 'block3_pool')(x)# 4th blockx = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv1')(x)x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv2')(x)x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv3')(x)x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv4')(x)x = MaxPooling2D((2,2), strides=(2,2), name = 'block4_pool')(x)# 5th blockx = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv1')(x)x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv2')(x)x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv3')(x)x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv4')(x)x = MaxPooling2D((2,2), strides=(2,2), name = 'block5_pool')(x)# full connectionx = Flatten()(x)x = Dense(4096, activation='relu', name='fc1')(x)x = Dense(4096, activation='relu', name='fc2')(x)output_tensor = Dense(nb_classes, activation='softmax', name='predictions')(x)model = Model(input_tensor, output_tensor)return modelmodel=VGG19(1000, (img_width, img_height, 3))
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 224, 224, 3)] 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_conv4 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_conv4 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv4 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 25088) 0
_________________________________________________________________
fc1 (Dense) (None, 4096) 102764544
_________________________________________________________________
fc2 (Dense) (None, 4096) 16781312
_________________________________________________________________
predictions (Dense) (None, 1000) 4097000
=================================================================
Total params: 143,667,240
Trainable params: 143,667,240
Non-trainable params: 0
_________________________________________________________________
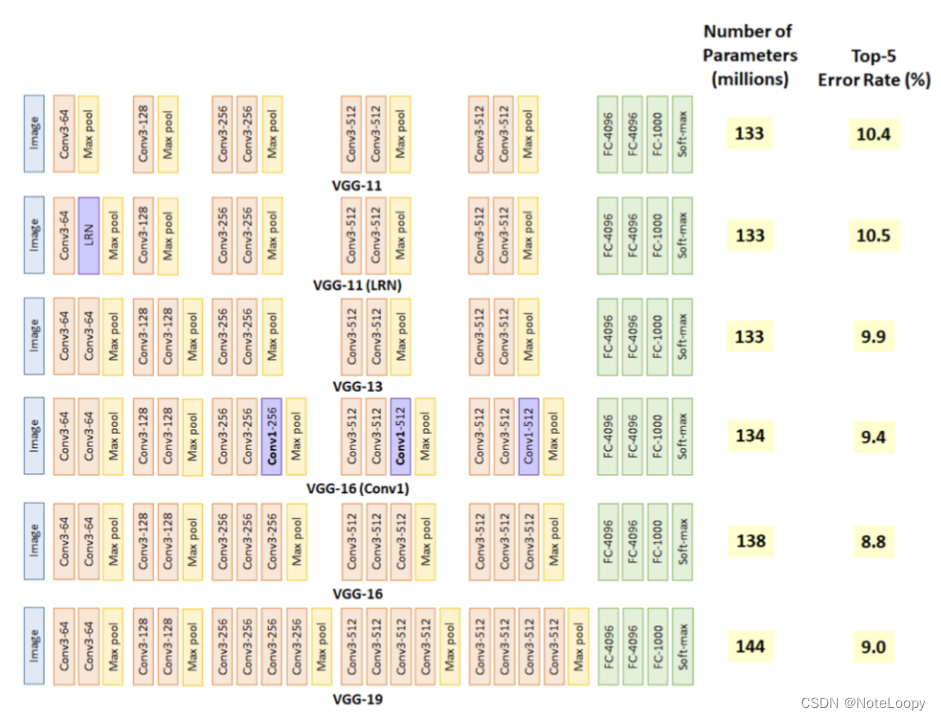
3. 网络结构图
结构说明:
- 16个卷积层(Convolutional Layer),分别用
blockX_convX表示 - 3个全连接层(Fully connected Layer),分别用
fcX与predictions表示 - 5个池化层(Pool layer),分别用
blockX_pool表示
VGG-19包含了19个隐藏层(16个卷积层和3个全连接层),故称为VGG-19
**
**
四、编译
在准备对模型进行训练之前,还需要再对其进行一些设置。以下内容是在模型的编译步骤中添加的:
- 损失函数(loss):用于衡量模型在训练期间的准确率。
- 优化器(optimizer):决定模型如何根据其看到的数据和自身的损失函数进行更新。
- 指标(metrics):用于监控训练和测试步骤。以下示例使用了准确率,即被正确分类的图像的比率。
# 设置优化器
opt = tf.keras.optimizers.Adam(learning_rate=1e-4)model.compile(optimizer=opt,loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])
五、训练模型
epochs = 10history = model.fit(train_ds,validation_data=val_ds,epochs=epochs
)
Epoch 1/10
16/16 [==============================] - 21s 274ms/step - loss: 5.4494 - accuracy: 0.1508 - val_loss: 6.8600 - val_accuracy: 0.0714
Epoch 2/10
16/16 [==============================] - 2s 130ms/step - loss: 1.7976 - accuracy: 0.3174 - val_loss: 6.8402 - val_accuracy: 0.3929
Epoch 3/10
16/16 [==============================] - 2s 139ms/step - loss: 1.4882 - accuracy: 0.4201 - val_loss: 6.8453 - val_accuracy: 0.5357
Epoch 4/10
16/16 [==============================] - 2s 135ms/step - loss: 1.1548 - accuracy: 0.5917 - val_loss: 6.8551 - val_accuracy: 0.3571
Epoch 5/10
16/16 [==============================] - 2s 139ms/step - loss: 1.0376 - accuracy: 0.6267 - val_loss: 6.8421 - val_accuracy: 0.4286
Epoch 6/10
16/16 [==============================] - 2s 136ms/step - loss: 1.0189 - accuracy: 0.5942 - val_loss: 6.8277 - val_accuracy: 0.5714
Epoch 7/10
16/16 [==============================] - 2s 133ms/step - loss: 0.6873 - accuracy: 0.7761 - val_loss: 6.8382 - val_accuracy: 0.6429
Epoch 8/10
16/16 [==============================] - 2s 128ms/step - loss: 0.3739 - accuracy: 0.9019 - val_loss: 6.8109 - val_accuracy: 0.5357
Epoch 9/10
16/16 [==============================] - 2s 128ms/step - loss: 0.3761 - accuracy: 0.8547 - val_loss: 6.8101 - val_accuracy: 0.6429
Epoch 10/10
16/16 [==============================] - 2s 129ms/step - loss: 0.1258 - accuracy: 0.9713 - val_loss: 6.7796 - val_accuracy: 0.8929
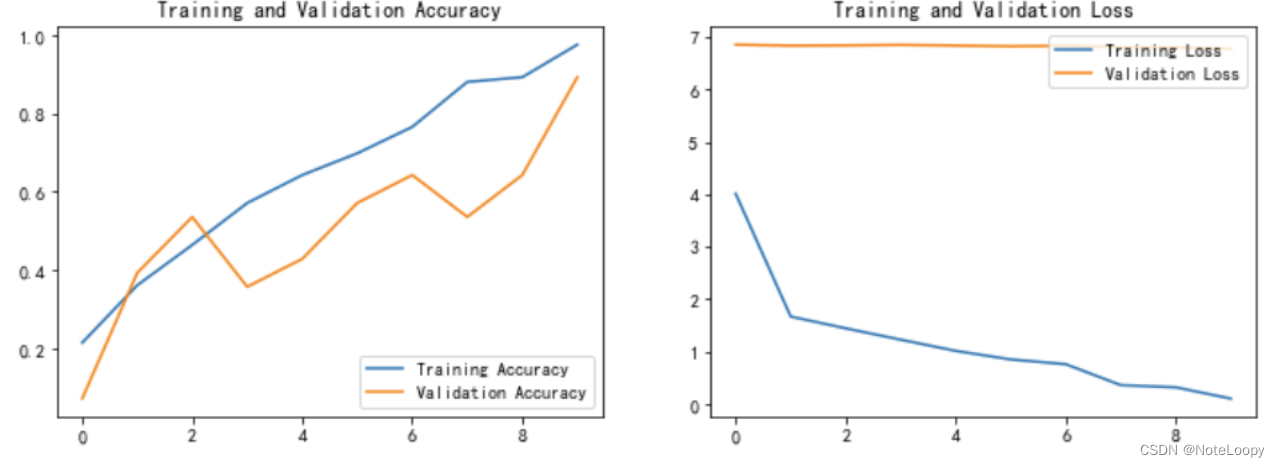
六、模型评估
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']loss = history.history['loss']
val_loss = history.history['val_loss']epochs_range = range(epochs)plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
七、保存and加载模型
# 保存模型
model.save('model/my_model.h5')
# 加载模型
new_model = keras.models.load_model('model/my_model.h5')
八、预测
# 采用加载的模型(new_model)来看预测结果plt.figure(figsize=(10, 5)) # 图形的宽为10高为5for images, labels in val_ds.take(1):for i in range(8):ax = plt.subplot(2, 4, i + 1) # 显示图片plt.imshow(images[i])# 需要给图片增加一个维度img_array = tf.expand_dims(images[i], 0) # 使用模型预测图片中的人物predictions = new_model.predict(img_array)plt.title(class_names[np.argmax(predictions)])plt.axis("off")

相关文章:
卷积神经网络(VGG-19)灵笼人物识别
文章目录 前期工作1. 设置GPU(如果使用的是CPU可以忽略这步)我的环境: 2. 导入数据3. 查看数据 二、数据预处理1. 加载数据2. 可视化数据3. 再次检查数据4. 配置数据集5. 归一化 三、构建VGG-19网络1. 官方模型(已打包好ÿ…...

MQTT协议详解
前言 MQTT是一个即时通讯协议,它工作在TCP/IP协议族上,是为硬件性能低下的远程设备以及网络状况糟糕的情况下而设计的发布/订阅型消息协议。它使用发布/订阅消息模式,提供一对多的消息发布,解除应用程序耦合。MQTT是轻量、简单、…...
WordPress画廊插件Envira Gallery v1.9.7河蟹版下载
Envira Gallery是一款功能强大的WordPress画廊插件。通过使用这个插件,你可以在WordPress的前台页面上创建出令人赏心悦目的图片画廊展示形式。 拖放生成器:轻松创建精美照片和视频画廊 自定义主题,打造独特外观 使用预设模板,为…...

认识前端包常用包管理工具(npm、cnpm、pnpm、nvm、yarn)
随着前端的快速发展,前端的框架越来越趋向于工程化,所以对于包的使用也越来越多,为了优化性能和后期的维护更新,对于前端包的管理也尤为重要,本文主要阐述对node中包管理工具的理解和简单的使用方法。也欢迎各位大佬和同行们多多指教。😁😁😁 👉1. npm 安装npm 通…...
使用树莓派学习Linux系统编程的 --- 库编程(面试重点)
在之前的Linux系统编程中,学习了文件的打开;关闭;读写;进程;线程等概念.... 本节补充“Linux库概念 & 相关编程”,这是一个面试的重点! 分文件编程 在之前的学习中,面对较大的…...
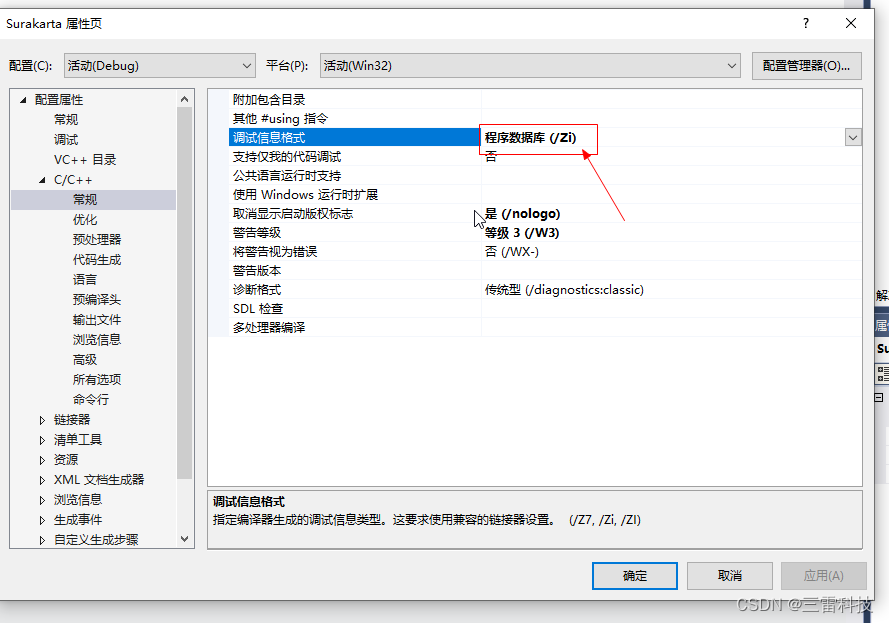
vs2017打开工程提示若要解决此问题,请使用以下选择启动 Visual Studio 安装程序: 用于 x86 和 x64 的 Visual C++ MFC
下载安装文件。 下载之后点击C项目,他会提示需要安装编译依赖。这个时候需要选择 用于 x86 和 x64 的 Visual C MFCWindows SDK 版本8.1 点击右下角的安装等待即可 error MSB8036: 找不到 Windows SDK 版本8.1。请安装所需的版本的 Windows SDK 或者在项目属性页…...

Redis学习笔记17:基于spring data redis及lua脚本批处理scan指令查询永久有效的key
Redis的KEYS和SCAN指令都可以用于在数据库中搜索匹配指定模式的键。然而,它们之间有一些关键的区别; KEYS指令会在整个数据库中阻塞地执行匹配操作,并返回匹配的键列表。如果数据库很大,或者匹配的键很多,将会对性能产…...

今天遇到Windows 10里安装的Ubuntu(WSL)的缺点
随着技术的发展,越来越多开发者转向使用 Windows Subsystem for Linux(WSL)在 Windows 10 上进行开发,也就是说不用虚拟机,不用准备多一台电脑,只需要在Windows 10/11 里安装 WSL 就能体验 Linux 系统。因此…...

hive sql多表练习
hive sql多表练习 准备原始数据集 学生表 student.csv 讲师表 teacher.csv 课程表 course.csv 分数表 score.csv 学生表 student.csv 001,彭于晏,1995-05-16,男 002,胡歌,1994-03-20,男 003,周杰伦,1995-04-30,男 004,刘德华,1998-08-28,男 005,唐国强,1993-09-10,男 006,陈道…...

论文速览 Arxiv 2023 | DMV3D: 单阶段3D生成方法
注1:本文系“最新论文速览”系列之一,致力于简洁清晰地介绍、解读最新的顶会/顶刊论文 论文速览 Arxiv 2023 | DMV3D: DENOISING MULTI-VIEW DIFFUSION USING 3D LARGE RECONSTRUCTION MODEL 使用3D大重建模型来去噪多视图扩散 论文原文:https://arxiv.org/pdf/2311.09217.pdf…...

访问限制符说明面向对象的封装性
1 问题 Java中4种“访问控制符”分别为private、default、protected、public,它们说明了面向对象的封装性,所以我们要利用它们尽可能的让访问权限降到最低,从而提高安全性。 private表示私有,只有自己类能访问,属性可以…...

python趣味编程-5分钟实现一个贪吃蛇游戏(含源码、步骤讲解)
Python 贪吃蛇游戏代码是用 Python 语言编写的。在这个贪吃蛇游戏中,Python 代码是增强您在创建和设计如何使用 Python 创建贪吃蛇游戏方面的技能和才能的方法。 Python Tkinter中的贪吃蛇游戏是一个简单干净的 GUI,可轻松玩游戏。游戏设计非常简单,用户不会觉得使用和理解…...
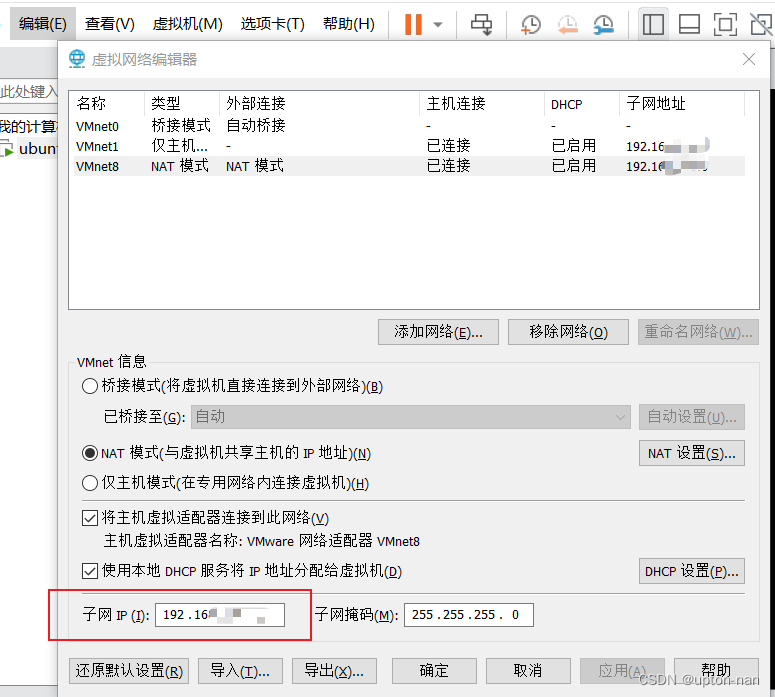
如何在虚拟机的Ubuntu22.04中设置静态IP地址
为了让Linux系统的IP地址在重新启动电脑之后IP地址不进行变更,所以将其IP地址设置为静态IP地址。 查看虚拟机中虚拟网络编辑器获取当前的子网IP端 修改文件/etc/netplan/00-installer-config.yaml文件,打开你会看到以下内容 # This is the network conf…...
代码随想录算法训练营第二十九天| 491 递增子序列 46 全排列
目录 491 递增子序列 46 全排列 491 递增子序列 在dfs中进行判断,如果path的长度大于1,则将其添加到res中。 本题nums中的元素的值处于-100与100之间,可以将元素映射0到199之间并且通过布尔数组st来记录此层中元素是否被使用过,…...
(动手学习深度学习)第13章 实战kaggle竞赛:CIFAR-10
导入相关库 import collections import math import os import shutil import pandas as pd import torch import torchvision from torch import nn from d2l import torch as d2l下载数据集 d2l.DATA_HUB[cifar10_tiny] (d2l.DATA_URL kaggle_cifar10_tiny.zip,2068874e4…...
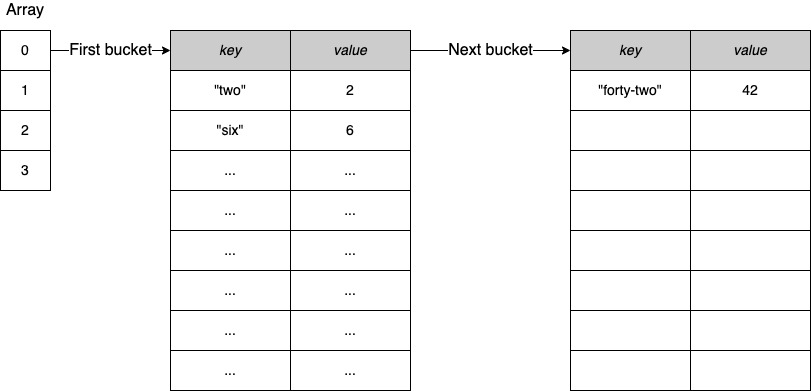
Go 语言中的map和内存泄漏
map在内存中总是会增长;它不会收缩。因此,如果map导致了一些内存问题,你可以尝试不同的选项,比如强制 Go 重新创建map或使用指针。 在 Go 中使用map时,我们需要了解map增长和收缩的一些重要特性。让我们深入探讨这一点…...
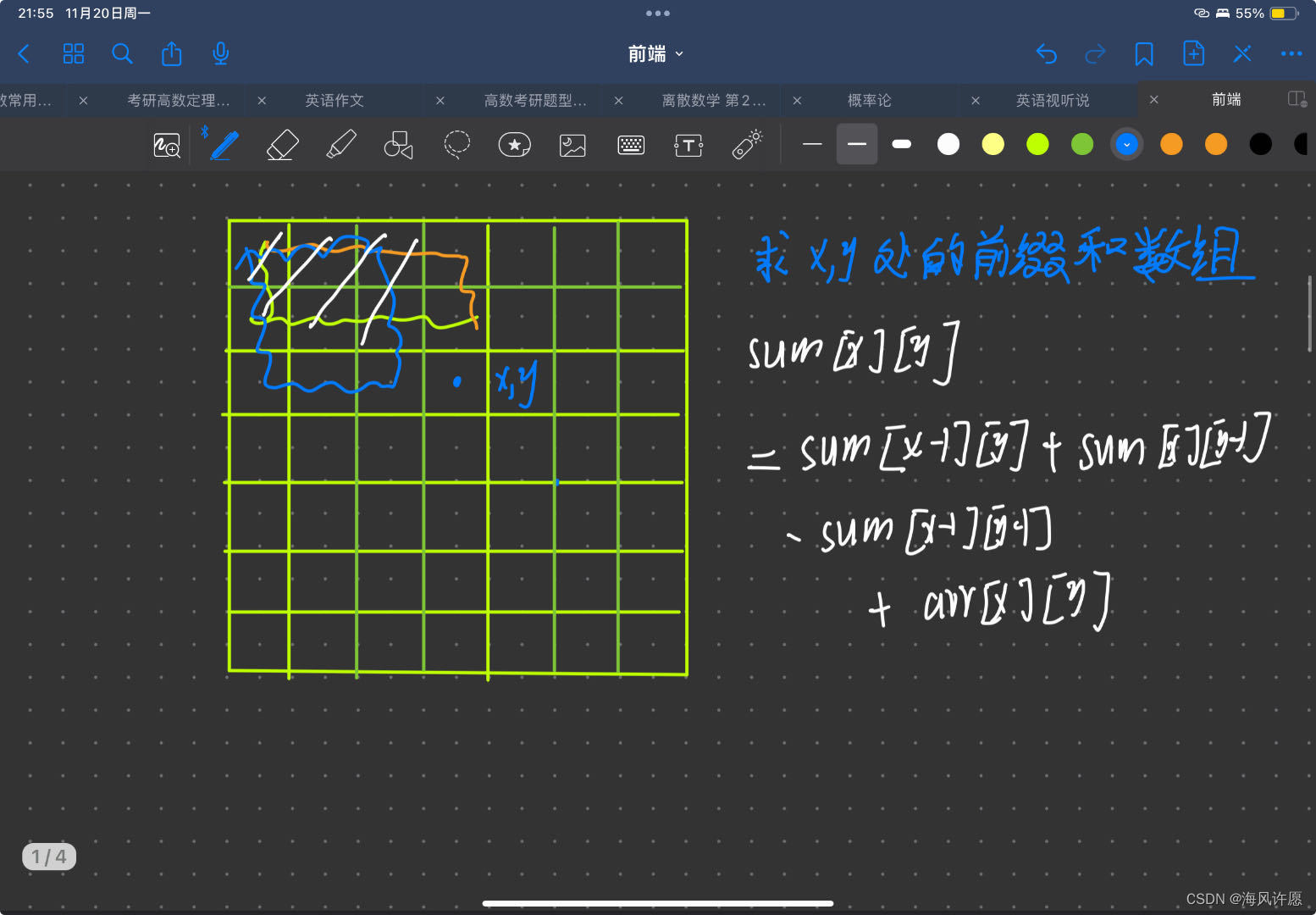
前缀和(c++,超详细,含二维)
前缀和与差分 当给定一段整数序列a1,a2,a3,a4,a5…an; 每次让我们求一段区间的和,正常做法是for循环遍历区间起始点到结束点,进行求和计算,但是当询问次数很多并且区间很长的时候 比如,10^5 个询问和10^6区间长度,相…...
)
详解FreeRTOS:二值信号量和计数信号量(高级篇—2)
目录 1、二值信号量 1.1、二值信号量运行机制 1.2、创建二值信号量 1...
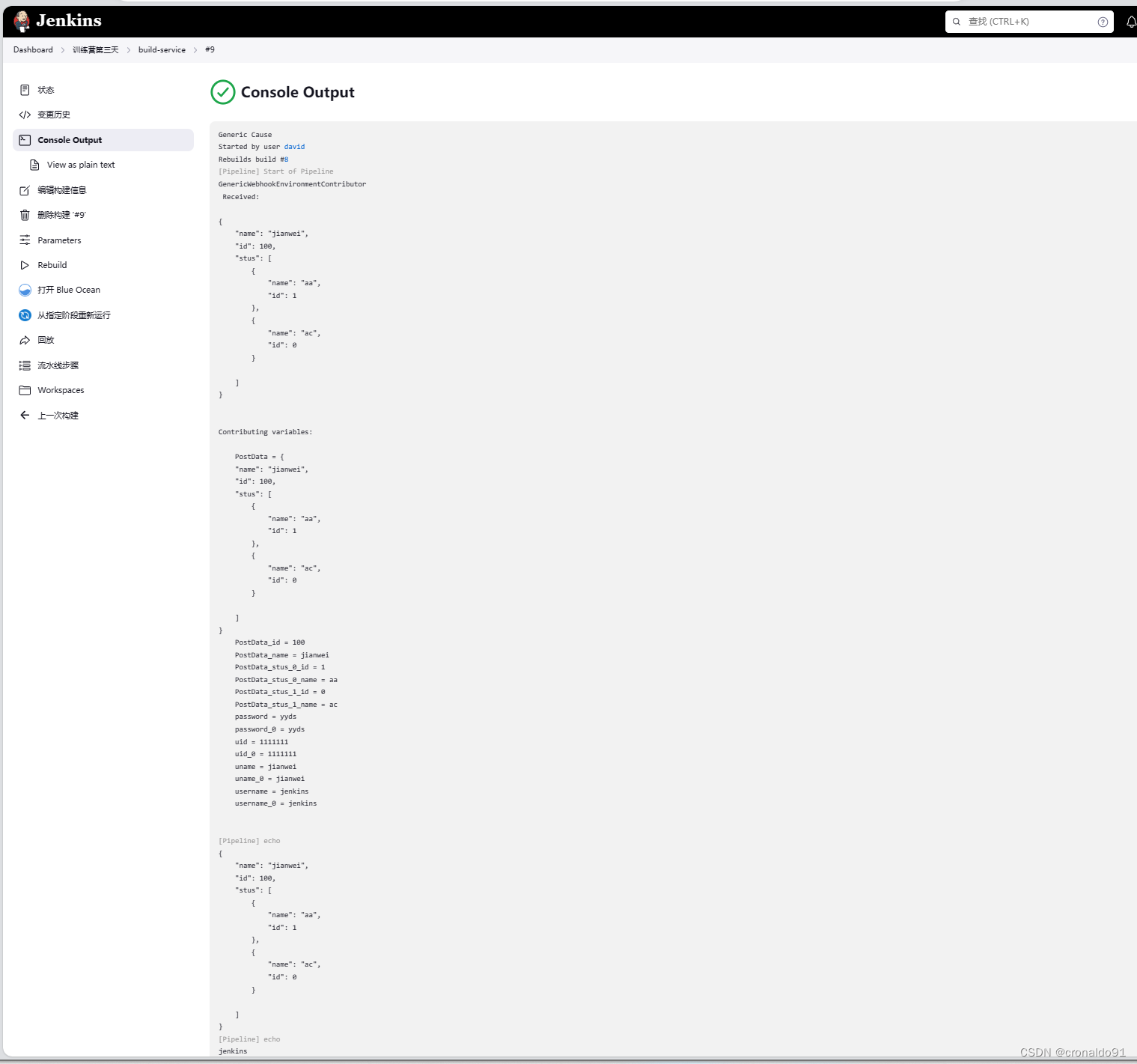
持续集成交付CICD:Jenkins通过API触发流水线
目录 一、理论 1.HTTP请求 2.调用接口的方法 3.HTTP常见错误码 二、实验 1.Jenkins通过API触发流水线 三、问题 1.如何拿到上一次jenkinsfile文件进行自动触发流水线 一、理论 1.HTTP请求 (1)概念 HTTP超文本传输协议,是确保服务器…...
【Python】12 GPflow安装
概述 GPflow 是一个基于TensorFlow 在 Python 中构建高斯过程模型的包。高斯过程是一种监督学习模型。 高斯过程的一些优点是: 不确定性是高斯过程的固有部分。高斯过程可以在不知道答案时告诉您。适用于小型数据集。如果您的数据有限,高斯过程可以从…...

终极Markdown Viewer浏览器扩展完整指南:打造高效文档阅读环境
终极Markdown Viewer浏览器扩展完整指南:打造高效文档阅读环境 【免费下载链接】markdown-viewer Markdown Viewer / Browser Extension 项目地址: https://gitcode.com/gh_mirrors/ma/markdown-viewer Markdown Viewer是一款功能强大的浏览器扩展࿰…...

从零到一:手把手教你完成Matlab R2020a的下载、安装与激活【避坑指南】
1. 准备工作:下载与系统检查 第一次安装Matlab的朋友们可能会被复杂的流程吓到,但别担心,跟着我的步骤走绝对没问题。我去年给实验室十几台电脑装过R2020a版本,踩过的坑比你们见过的都多。首先咱们得准备好安装包,这里…...

如何高效清理游戏平台残留文件:SteamCleaner一站式解决方案指南
如何高效清理游戏平台残留文件:SteamCleaner一站式解决方案指南 【免费下载链接】SteamCleaner :us: A PC utility for restoring disk space from various game clients like Origin, Steam, Uplay, Battle.net, GoG and Nexon :us: 项目地址: https://gitcode.c…...

你的桌面需要一个会思考的伙伴吗?DyberPet让虚拟宠物拥有情感与智慧
你的桌面需要一个会思考的伙伴吗?DyberPet让虚拟宠物拥有情感与智慧 【免费下载链接】DyberPet Desktop Cyber Pet Framework based on PySide6 项目地址: https://gitcode.com/GitHub_Trending/dy/DyberPet 每天面对冰冷的屏幕,你是否曾幻想过有…...

5G上行免调度传输:开启无线通信新篇章
5G上行免调度传输:开启无线通信新篇章 在无线通信技术不断演进的浪潮中,5G以其高速率、低时延和大连接等特性,成为推动社会数字化转型的关键力量。其中,上行免调度传输作为5G技术体系中的一个重要环节,正逐步展现出其独…...

全中文编程:豆包 AI居然会写单片机程序
AI时代,我写了一段全中文的程序:请写一个STC8H8K单片机的程序,要求连接在P0端口的八个LED灯左边四个与右边四个交替闪烁然后豆包AI 给了我下面的结果。我想问大家三个问题:(1)上面那段话算不算是一个全中文…...

终极指南:Awoo Installer - Nintendo Switch游戏安装的免费开源解决方案
终极指南:Awoo Installer - Nintendo Switch游戏安装的免费开源解决方案 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer 还在为Switch游…...

保险科技前端开源方案Insura:动态表单与保费试算核心实现
1. 项目概述:一个面向保险行业的开源前端解决方案最近在梳理一些开源项目时,发现了一个挺有意思的仓库:Rashed-ux920/insura。从名字上拆解,“insura”显然是“Insurance”(保险)的缩写,而作者“…...

LLM应用可观测性实战:基于OpenTelemetry与OpenLLMetry的监控方案
1. 项目概述:当LLM应用遇见可观测性如果你正在开发或维护一个基于大语言模型的应用,那么下面这个场景你一定不陌生:用户反馈说“AI助手刚才的回答很奇怪”,或者“昨天还能正常调用的功能今天突然报错了”。你打开日志,…...

12,Springboot3+vue3实现系统公告功能
做一个新的公告模块步骤如下 一, 后端 1, 创建系统公告表 CREATE TABLE `notice` (`id` int NOT NULL AUTO_INCREMENT COMMENT 主键ID,`title` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT 公告标题,`content` varchar(255) COLLATE utf8mb4_unicode_ci …...