(动手学习深度学习)第13章 实战kaggle竞赛:CIFAR-10
- 导入相关库
import collections
import math
import os
import shutil
import pandas as pd
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
- 下载数据集
d2l.DATA_HUB['cifar10_tiny'] = (d2l.DATA_URL + 'kaggle_cifar10_tiny.zip','2068874e4b9a9f0fb07ebe0ad2b29754449ccacd')# 如果使用完整的Kaggle竞赛的数据集,设置demo为False
demo = Trueif demo:data_dir = d2l.download_extract('cifar10_tiny')
else:data_dir = '../data/kaggle/cifar-10/'
- 整理数据集
# 查看数据集
def read_csv_labels(fname):"""读取‘fname’来给标签字典返回一个文件名"""with open(fname, 'r') as f:lines = f.readlines()[1:] # readlines(): 每次读文档的一行,以后还需要逐步循环tokens = [l.rstrip().split(',') for l in lines] # rstrip(): 删除字符串后面(右面)的空格或特殊字符, 还有lstrip(左面)、strip(两面)return dict((name, label) for name, label in tokens)labels = read_csv_labels(os.path.join(data_dir, 'trainLabels.csv'))
print('训练样本:', len(labels))
print('类别:', len(set(labels.values()))) # set(): 集合,里面不能包含重复的元素,接受一个list作为参数

将验证集从原始的训练集钟拆分出来
# 拆分数据集:训练集、验证集
def copyfile(filename, target_dir):"""将文件复制到目标目录"""os.makedirs(target_dir, exist_ok=True) # 创建多层目录,exist_ok为True:在目标目录已存在的情况下不会触发FileExistsError异常。shutil.copy(filename, target_dir) #拷贝文件,filename:要拷贝的文件;target_dir:目标文件夹def reorg_train_valid(data_dir, labels, valid_ratio):"""将验证集从原始训练集钟拆分出来"""# 训练数据集中样本数量最少的类别中的样本数# Counter: 计数器,返回一个字典,键为元素,值为元素个数;# .most_common(): 返回一个列表, 列表元素为(元素,出现次数),默认按出现频率排序# [-1]: 样本数量最少的类别(类别, 样本数),[-1][1]: 样本数数量最少的类别中的样本数n = collections.Counter(labels.values()).most_common()[-1][1]# 验证集中每个类别的样本数n_valid_per_label= max(1, math.floor((n * valid_ratio))) # math.floor(): 向下取整 math.ceil(): 向上取整label_count = {}# 遍历原始训练集中的每个样本for train_file in os.listdir(os.path.join(data_dir, 'train')):label = labels[train_file.split('.')[0]] # 从文件名中提取标签fname = os.path.join(data_dir, 'train', train_file)copyfile(fname, os.path.join(data_dir, 'train_valid_test', 'train_valid', label))# 如果该类别的样本数还未达到在验证集中的设定数量,则将样本复制到验证集中if label not in label_count or label_count[label] < n_valid_per_label:copyfile(fname, os.path.join(data_dir, 'train_valid_test', 'valid', label))label_count[label] = label_count.get(label, 0) + 1else:copyfile(fname, os.path.join(data_dir, 'train_valid_test', 'train', label))return n_valid_per_label# reorg_test函数用来在预测期间整理测试集,以方便读取
def reorg_test(data_dir):"""在预测期间整理测试集,以方便读取"""# 遍历测试集中的每个样本for test_file in os.listdir(os.path.join(data_dir, 'test')):# 将测试集中的样本复制到新的目录结构中的 'test' 子目录下,标签为 'unknown'copyfile(os.path.join(data_dir, 'test', test_file),os.path.join(data_dir, 'train_valid_test', 'test', 'unknown'))
# 整个处理数据集函数
def reorg_cifar10_data(data_dir, valid_ratio):labels = read_csv_labels(os.path.join(data_dir, 'trainLabels.csv'))reorg_train_valid(data_dir, labels, valid_ratio)reorg_test(data_dir)
- 这个小规模数据集的批量大小是32,在实际的cifar-10数据集中,可以设为128
- 将10%的训练样本作为调整超参数的验证集
batch_size = 32 if demo else 128
valid_ratio = 0.1
reorg_cifar10_data(data_dir, valid_ratio)
结果会生成一个train_valid_test的文件夹,里面有:
- test文件夹---unknow文件夹:5张没有标签的测试照片
- train_valid文件夹---10个类被的文件夹:每个文件夹包含所属类别的全部照片
- train文件夹--10个类别的文件夹:每个文件夹下包含90%的照片用于训练
- valid文件夹--10个类别的文件夹:每个文件夹下包含10%的照片用于验证
- 图像增广
transform_train = torchvision.transforms.Compose([# 原本图像是32*32,先放大成40*40, 在随机裁剪为32*32,实现训练数据的增强torchvision.transforms.Resize(40),torchvision.transforms.RandomResizedCrop(32, scale=(0.64, 1.0), ratio=(1.0, 1.0)),torchvision.transforms.RandomHorizontalFlip(),torchvision.transforms.ToTensor(),torchvision.transforms.Normalize([0.4914, 0.4822, 0.4465],[0.2023, 0.1994, 0.2010])
])
transform_test = torchvision.transforms.Compose([torchvision.transforms.ToTensor(),# 标准化图像的每个通道 : 消除评估结果中的随机性torchvision.transforms.Normalize([0.4914, 0.4822, 0.4465],[0.2023, 0.1994, 0.2010])
])
- 加载数据集
train_ds, train_valid_ds = [torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train_valid_test', folder),transform=transform_train) for folder in ['train', 'train_valid']
]
valid_ds, test_ds = [torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train_valid_test', folder), transform=transform_test) for folder in ['valid', 'test']
]
- 定义迭代器,方便快速迭代数据
train_iter, train_valid_iter = [torch.utils.data.DataLoader(dataset, batch_size, shuffle=True, drop_last=True) for dataset in (train_ds, train_valid_ds)
]
valid_iter = torch.utils.data.DataLoader(valid_ds, batch_size, shuffle=False, drop_last=True
)
test_iter = torch.utils.data.DataLoader(test_ds, batch_size, shuffle=False, drop_last=False
)
- 定义模型与损失函数
# 对resnet18做微调,输入通道数为3, 输出类别数为10
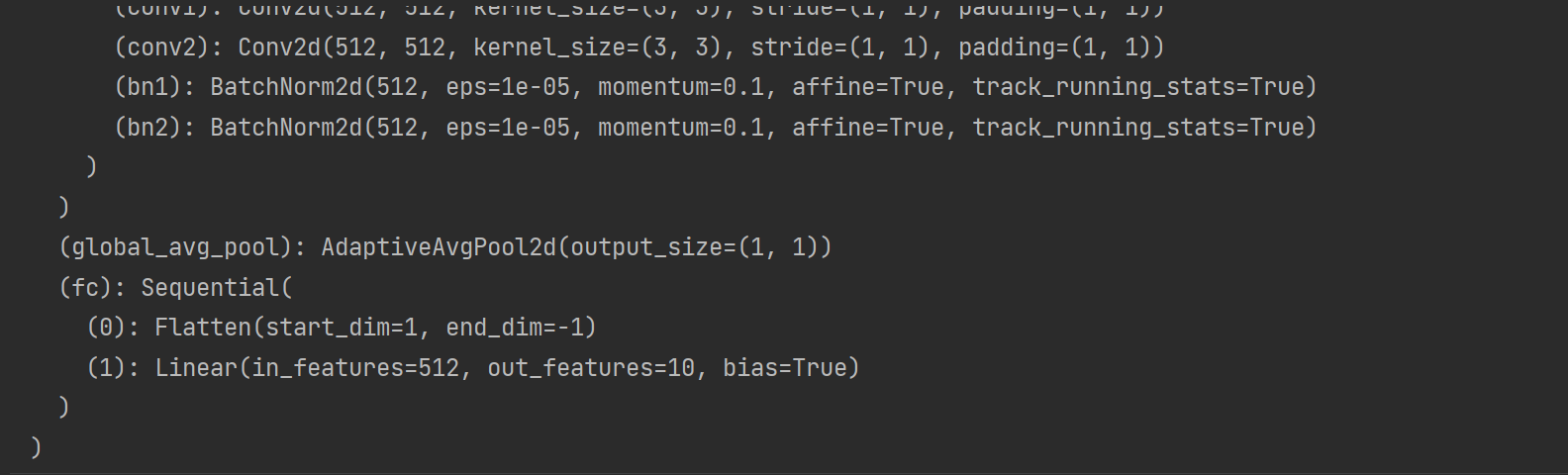
def get_net():num_classes = 10net = d2l.resnet18(num_classes, in_channels=3)return net
# 查看网络模型
get_net()
# 使用交叉熵损失函数作为损失函数: 直接返回n分样本的loss
loss = nn.CrossEntropyLoss(reduction='none')
- 定义训练函数
# 定义训练函数
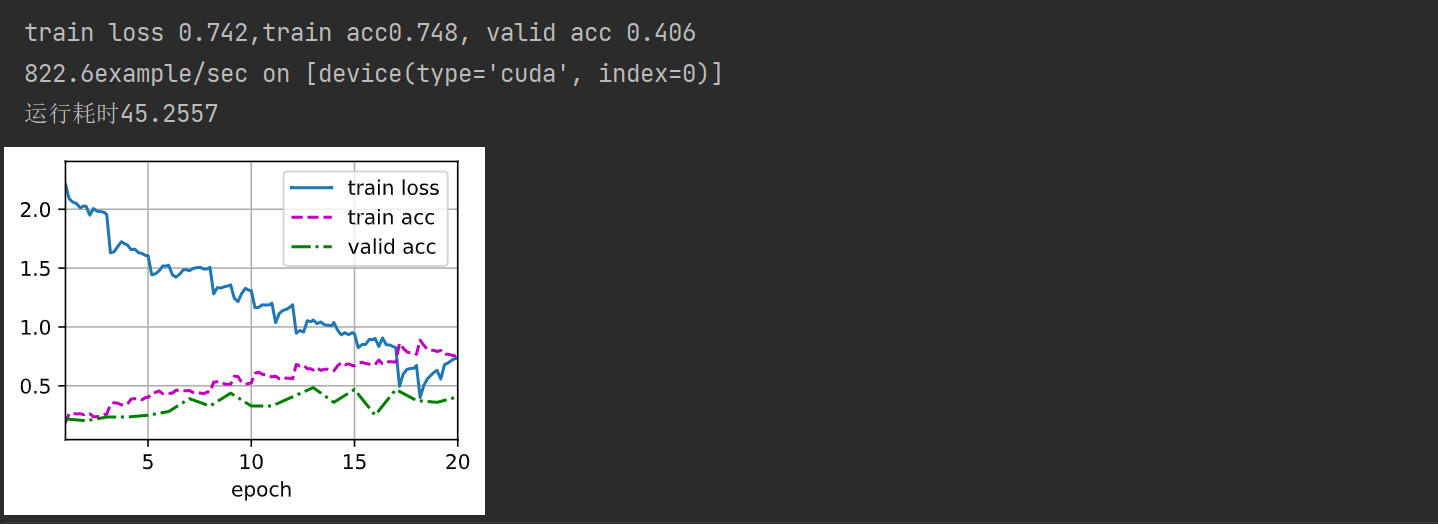
def train(net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period, lr_decay):trainer = torch.optim.SGD(net.parameters(), lr=lr, momentum=0.9, weight_decay=wd)scheduler = torch.optim.lr_scheduler.StepLR(trainer, lr_period, lr_decay)num_batches, timer = len(train_iter), d2l.Timer()legend = ['train loss', 'train acc']if valid_iter is not None:legend.append('valid acc')animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], legend=legend)net = nn.DataParallel(net, device_ids=devices).to(devices[0])for epoch in range(num_epochs):net.train()metric = d2l.Accumulator(3)for i, (features, labels) in enumerate(train_iter):timer.start()l, acc = d2l.train_batch_ch13(net, features, labels, loss, trainer, devices)metric.add(l, acc, labels.shape[0])timer.stop()if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:animator.add(epoch + (i + 1) / num_batches,(metric[0]/ metric[2], metric[1] / metric[2], None))if valid_iter is not None:valid_acc = d2l.evaluate_accuracy_gpu(net, valid_iter)animator.add(epoch+1, (None, None, valid_acc))scheduler.step()measures = (f'train loss {metric[0] / metric[2]:.3f},'f'train acc{metric[1] / metric[2]:.3f}')if valid_iter is not None:measures += f', valid acc {valid_acc:.3f}'print(measures + f'\n{metric[2] * num_epochs /timer.sum():.1f}'f'example/sec on {str(devices)}')
- 训练模型
- (数据集太小,导致精度不高)
import time# 在开头设置开始时间
start = time.perf_counter() # start = time.clock() python3.8之前可以# 训练和验证模型
devices, num_epochs, lr, wd = d2l.try_all_gpus(), 20, 2e-4, 5e-4
lr_period, lr_decay, net = 4, 0.9, get_net()
train(net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period, lr_decay)# 在程序运行结束的位置添加结束时间
end = time.perf_counter() # end = time.clock() python3.8之前可以# 再将其进行打印,即可显示出程序完成的运行耗时
print(f'运行耗时{(end-start):.4f}')
10. 对测试集进行分类并提交结果
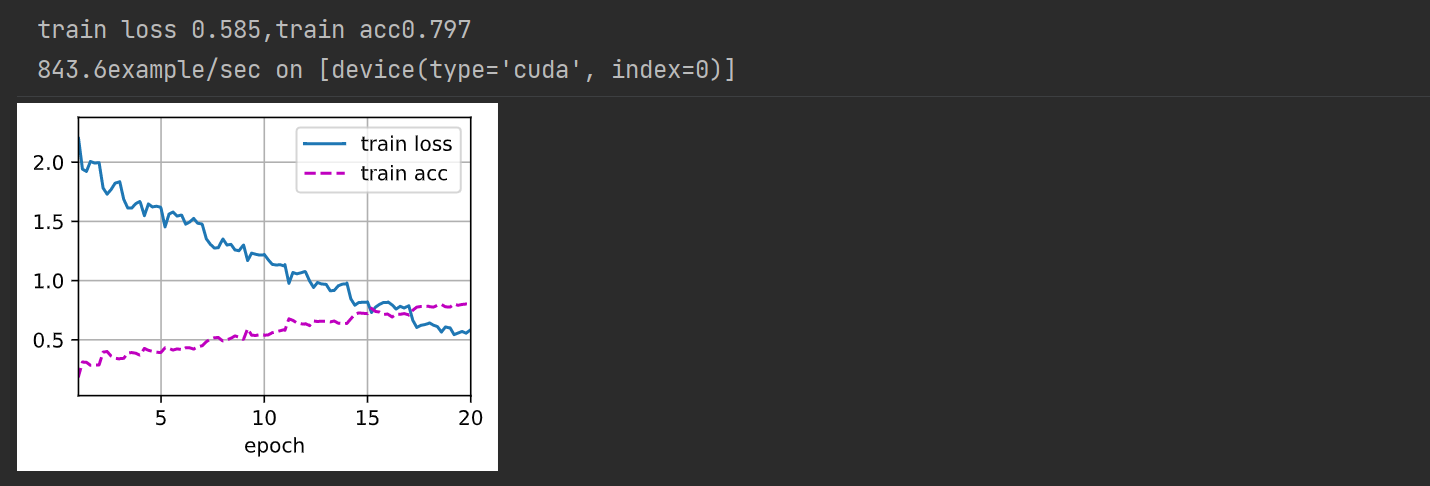
net, preds = get_net(), []
train(net ,train_valid_iter, None, num_epochs, lr, wd, devices, lr_period, lr_decay)
for X, _ in test_iter:y_hat = net(X.to(devices[0]))preds.extend(y_hat.argmax(dim=1).type(torch.int32).cpu().numpy())
sorted_ids = list(range(1, len(test_ds) + 1))
sorted_ids.sort(key=lambda x: str(x))
df = pd.DataFrame({'id' : sorted_ids, 'label': preds})
df['label'] = df['label'].apply(lambda x: train_valid_ds.classes[x])
df.to_csv('submission.csv', index=False)
相关文章:
(动手学习深度学习)第13章 实战kaggle竞赛:CIFAR-10
导入相关库 import collections import math import os import shutil import pandas as pd import torch import torchvision from torch import nn from d2l import torch as d2l下载数据集 d2l.DATA_HUB[cifar10_tiny] (d2l.DATA_URL kaggle_cifar10_tiny.zip,2068874e4…...
Go 语言中的map和内存泄漏
map在内存中总是会增长;它不会收缩。因此,如果map导致了一些内存问题,你可以尝试不同的选项,比如强制 Go 重新创建map或使用指针。 在 Go 中使用map时,我们需要了解map增长和收缩的一些重要特性。让我们深入探讨这一点…...
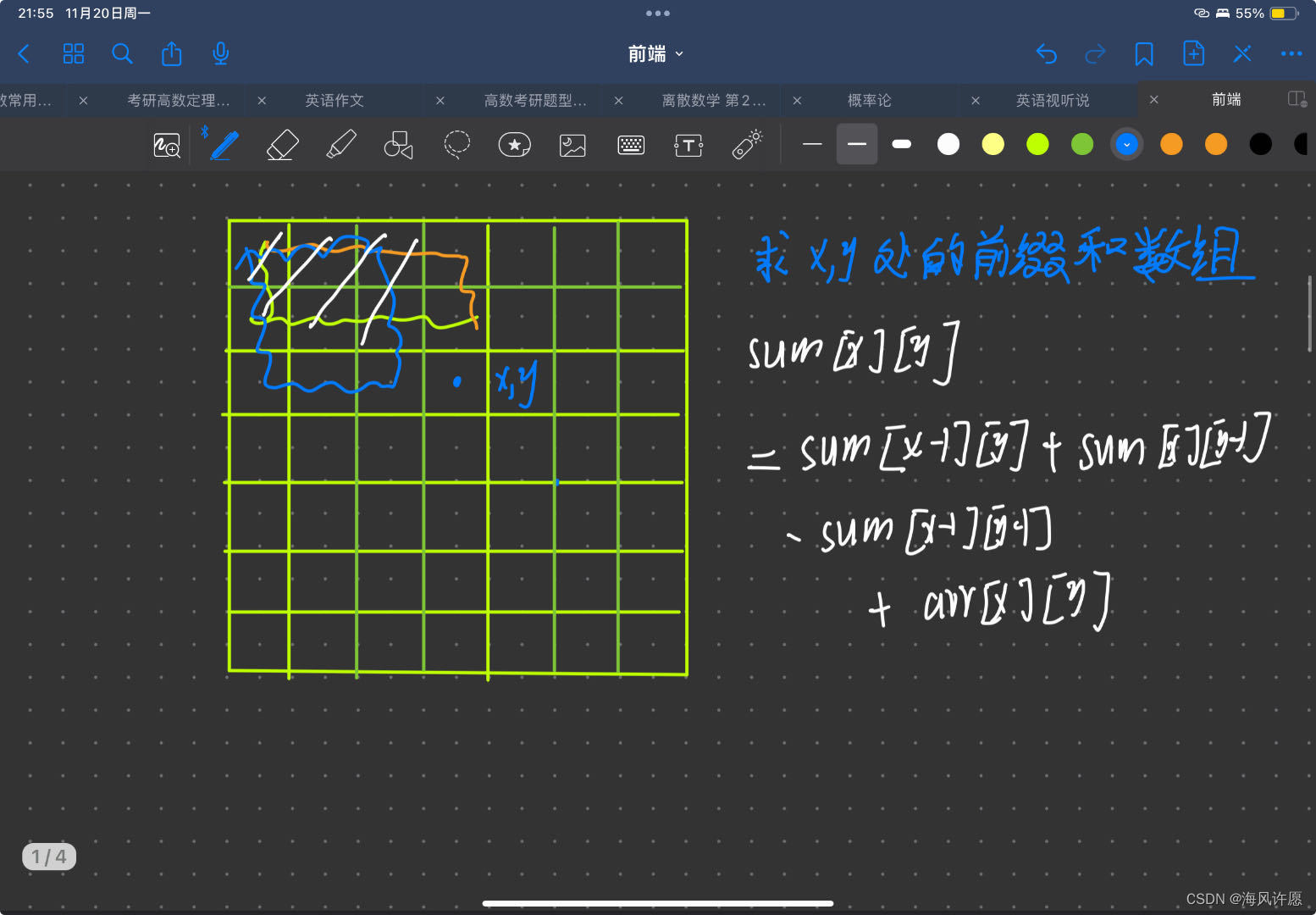
前缀和(c++,超详细,含二维)
前缀和与差分 当给定一段整数序列a1,a2,a3,a4,a5…an; 每次让我们求一段区间的和,正常做法是for循环遍历区间起始点到结束点,进行求和计算,但是当询问次数很多并且区间很长的时候 比如,10^5 个询问和10^6区间长度,相…...
)
详解FreeRTOS:二值信号量和计数信号量(高级篇—2)
目录 1、二值信号量 1.1、二值信号量运行机制 1.2、创建二值信号量 1...
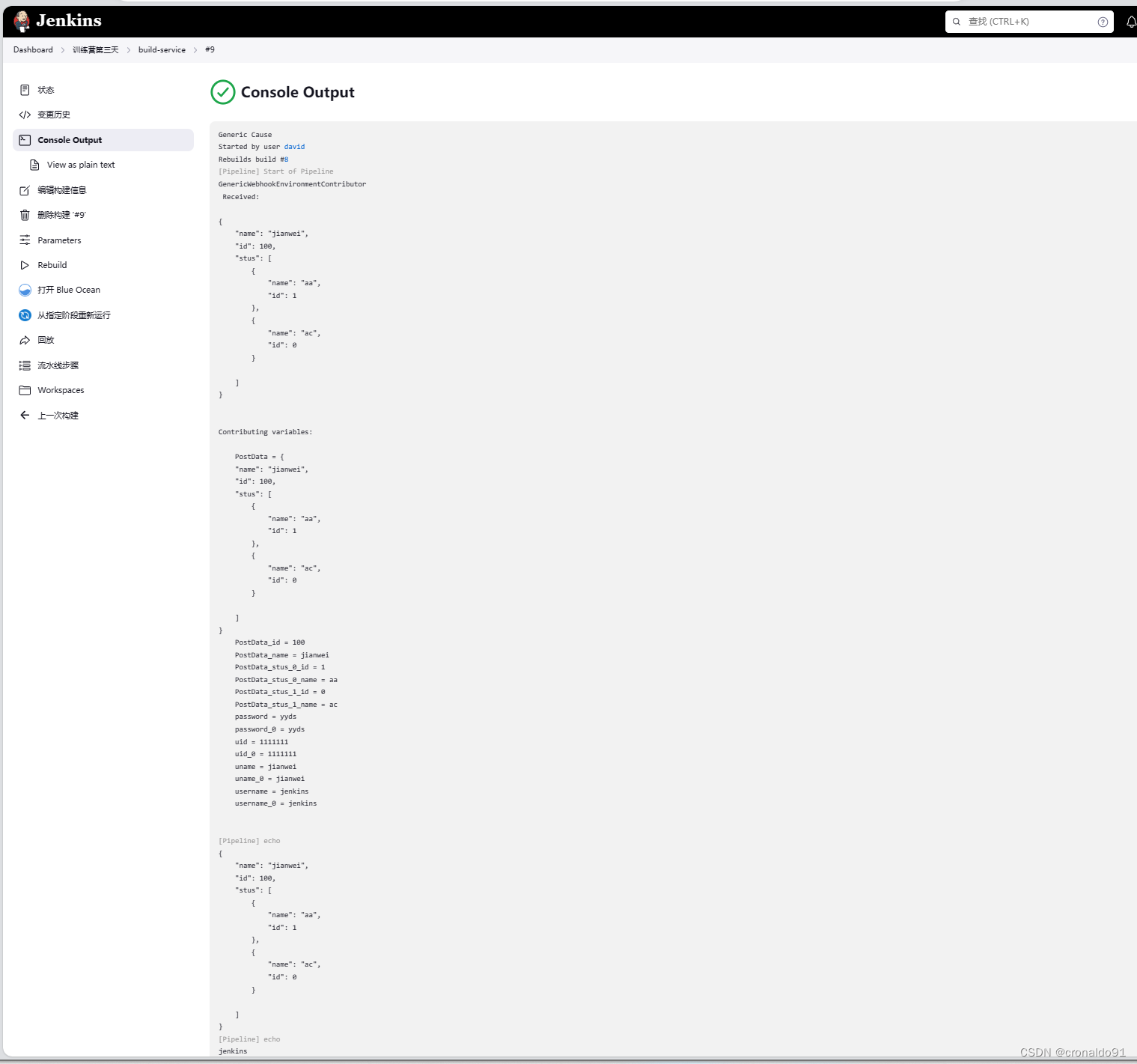
持续集成交付CICD:Jenkins通过API触发流水线
目录 一、理论 1.HTTP请求 2.调用接口的方法 3.HTTP常见错误码 二、实验 1.Jenkins通过API触发流水线 三、问题 1.如何拿到上一次jenkinsfile文件进行自动触发流水线 一、理论 1.HTTP请求 (1)概念 HTTP超文本传输协议,是确保服务器…...
【Python】12 GPflow安装
概述 GPflow 是一个基于TensorFlow 在 Python 中构建高斯过程模型的包。高斯过程是一种监督学习模型。 高斯过程的一些优点是: 不确定性是高斯过程的固有部分。高斯过程可以在不知道答案时告诉您。适用于小型数据集。如果您的数据有限,高斯过程可以从…...

Ubuntu源码编译gdal3.6.2
在华为云申请了一台Ubuntu v18的机器,乱七八糟的不要装。 apt install build-essential pkg-config -y cmake-3.21.1 apt-get install openssl libssl-dev 过程参考:Yukon for PostgreSQL_格來羙、日出的博客-CSDN博客 zlib-1.2.9(不需要) 如果用系统的后面gd…...

【LeetCode】160. 相交链表
160. 相交链表 难度:简单 题目 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。 图示两个链表在节点 c1 开始相交: 题目数据 保证 整个链式结构中…...

数据集笔记:NGSIM (next generation simulation)
1 数据集介绍 数据介绍s Next Generation Simulation (NGSIM) Open Data (transportation.gov) 数据地址:Next Generation Simulation (NGSIM) Vehicle Trajectories and Supporting Data | Department of Transportation - Data Portal 时间2005年到2006年间地…...
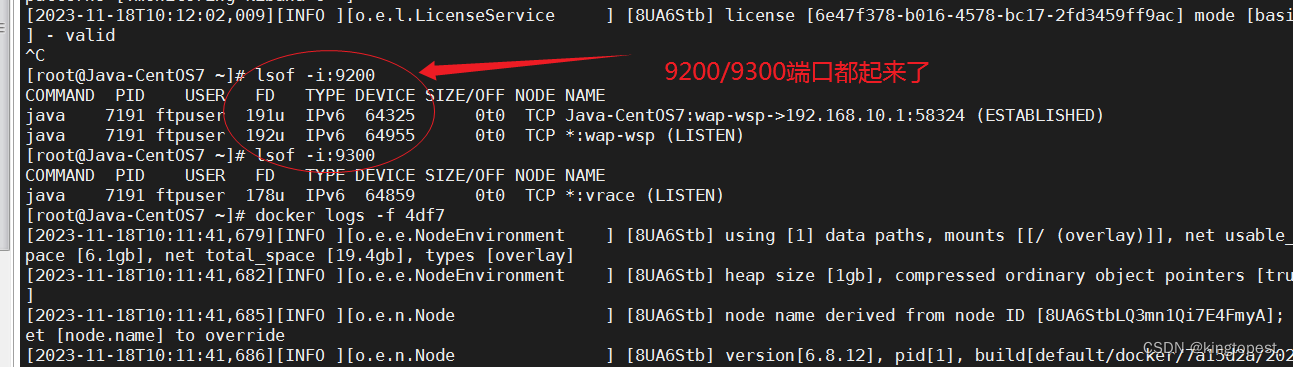
解决docker运行elastic服务端启动不成功
现象: 然后查看docker日志,发现有vm.max_map_count报错 ERROR: [1] bootstrap checks failed [1]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144] 解决办法: 1. 宿主机(运行doc…...

mysql数据库中mysql database 数据被破坏产生的一系列问题
在执行sql脚本时,没有注意到sql脚本文件包含了对mysql 原始数据库的操作,执行了脚本。 脚本执行成功之后,登录或链接数据库查看数据时报错: The user specified as a definer (‘mysql.infoschema’‘localhost’) does not exis…...
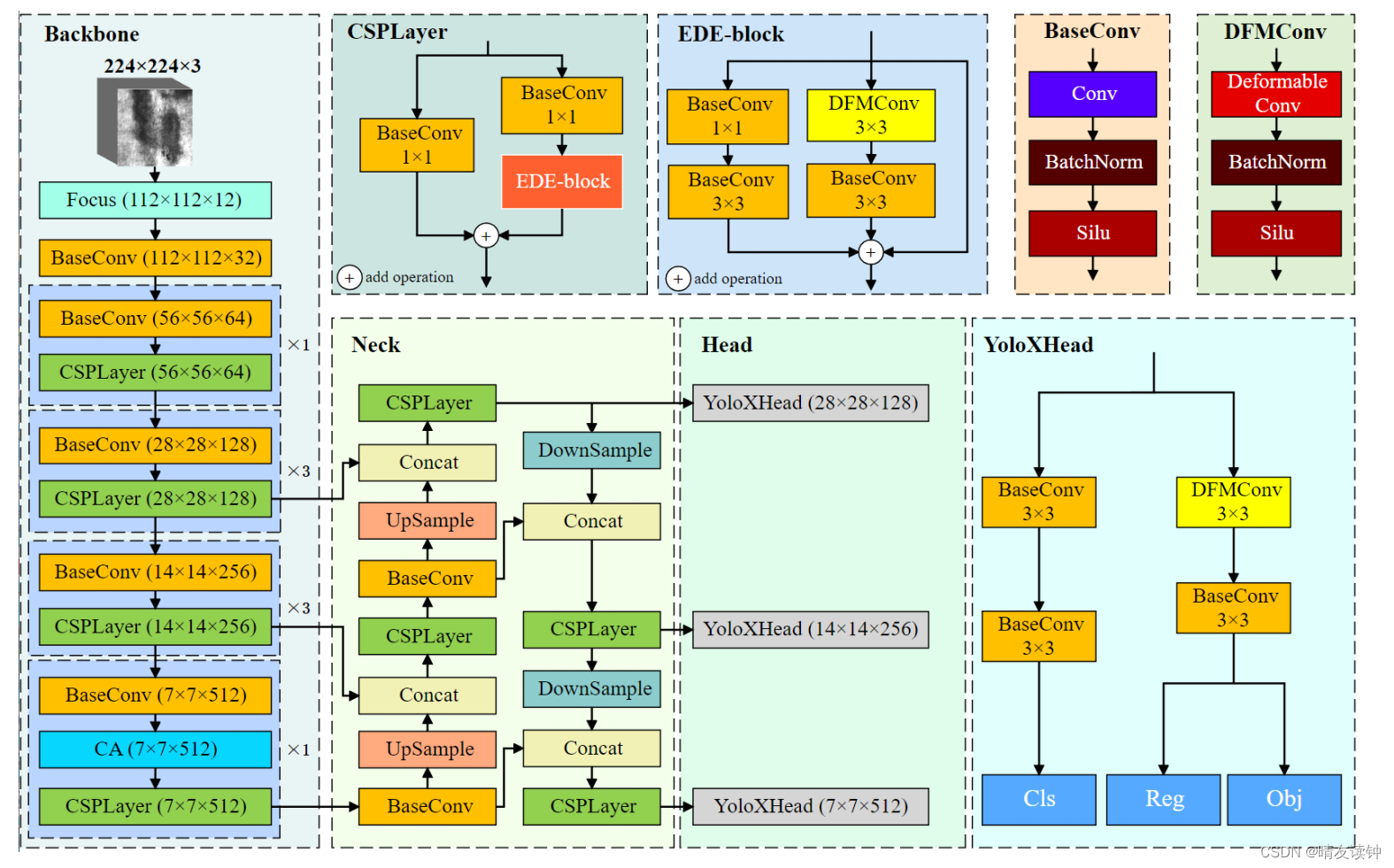
基于变形卷积和注意机制的带钢表面缺陷快速检测网络DCAM-Net(论文阅读笔记)
原论文链接->DCAM-Net: A Rapid Detection Network for Strip Steel Surface Defects Based on Deformable Convolution and Attention Mechanism | IEEE Journals & Magazine | IEEE Xplore DCAM-Net: A Rapid Detection Network for Strip Steel Surface Defects Base…...

05-Spring Boot工程中简化开发的方式Lombok和dev-tools
简化开发的方式Lombok和dev-tools Lombok常用注解 Lombok用标签方式代替构造器、getter/setter、toString()等重复代码, 在程序编译的时候自动生成这些代码 注解名功能NoArgsConstructor生成无参构造方法AllArgsConstructor生产含所有属性的有参构造方法,如果不希望含所有属…...

AIGC 技术在淘淘秀场景的探索与实践
本文介绍了AIGC相关领域的爆发式增长,并探讨了淘宝秀秀(AI买家秀)的设计思路和技术方案。文章涵盖了图像生成、仿真形象生成和换背景方案,以及模型流程串联等关键技术。 文章还介绍了淘淘秀的使用流程和遇到的问题及处理方法。最后,文章展望…...

ANSYS网格无关性检查
网格精度对应力结果存在很大的影响,有时候可以发现,随着网格精度逐渐提高,所求得的最大应力值逐渐趋于收敛。 默认网格: 从默认网格下计算出的应力云图可以发现,出现了的三处应力奇异点,此时算出的应力值是…...
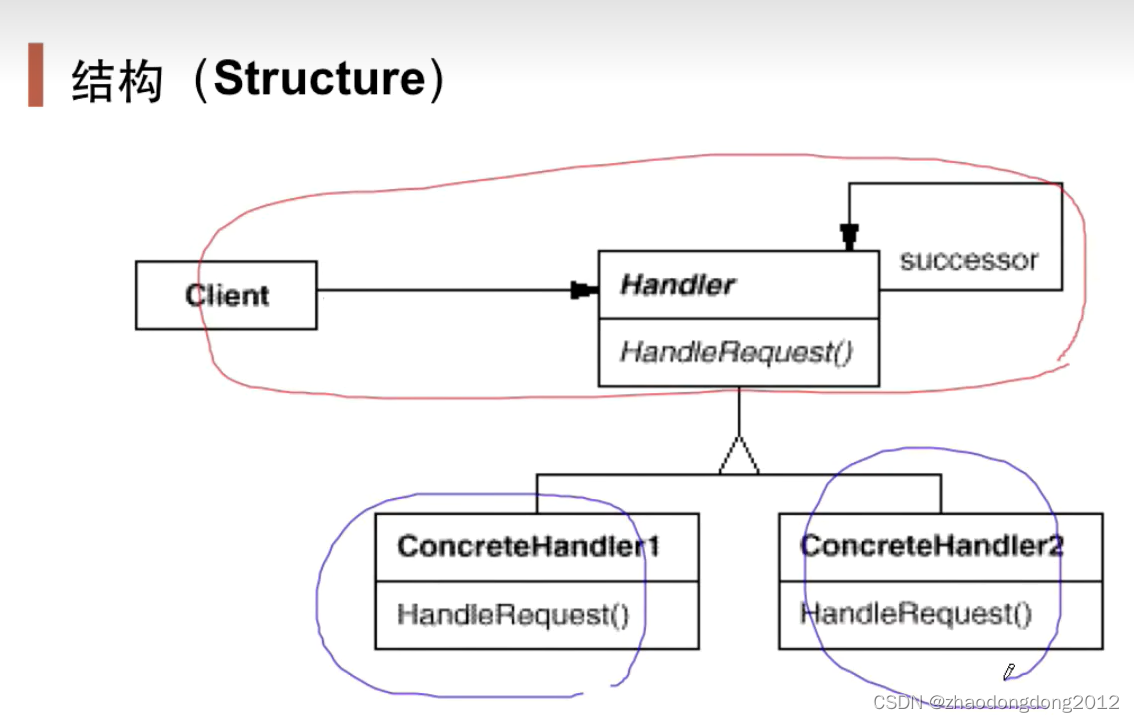
设计模式-责任链-笔记
动机(Motivation) 在软件构建过程中,一个请求可能被多个对象处理,但是每个请求在运行时只能有个接受者,如果显示指定,将必不可少地带来请求者与接受者的紧耦合。 如何使请求的发送者不需要指定具体的接受…...

SpringMvc请求原理流程
springmvc是用户和服务沟通的桥梁,官网提供了springmvc的全面使用和解释:DispatcherServlet :: Spring Framework 流程 1.Tomcat启动 2.解析web.xml文件,根据servlet-class找到DispatcherServlet,根据init-param来获取spring的…...

【开源】基于Vue.js的音乐偏好度推荐系统的设计和实现
项目编号: S 012 ,文末获取源码。 \color{red}{项目编号:S012,文末获取源码。} 项目编号:S012,文末获取源码。 目录 一、摘要1.1 项目介绍1.2 项目录屏 二、系统设计2.1 功能模块设计2.1.1 音乐档案模块2.1…...
采集1688整店商品(店铺所有商品、店铺列表api)
返回数据: 请求链接 {"user": [],"items": {"item": [{"num_iid": "738354436678","title": "国产正品i13 promax全网通5G安卓智能手机源头厂家批发手机","pic_url": "http…...
IObit Unlocker丨解除占用程序软件
更多内容请收藏:https://rwx.tza-3.xyz 官网:IObit Unlocker “永远不用担心电脑上无法删除的文件。” 界面简单,支持简体中文,一看就会,只需要把无法删除/移动的文件或整个U盘拖到框里就行。 解锁率很高,…...

Qwen2.5-VL图文助手体验:RTX 4090极速推理,支持对话历史和一键清空
Qwen2.5-VL图文助手体验:RTX 4090极速推理,支持对话历史和一键清空 如果你手头有一张RTX 4090显卡,想找一个能看懂图片、能聊天、还能帮你处理各种视觉任务的本地AI助手,那么今天要聊的这个工具,你可能会很感兴趣。 …...

Phi-3-mini-4k-instruct-gguf一文详解:GGUF模型加载机制与内存映射优化原理
Phi-3-mini-4k-instruct-gguf一文详解:GGUF模型加载机制与内存映射优化原理 1. GGUF模型格式概述 GGUF(GPT-Generated Unified Format)是llama.cpp团队设计的新一代模型文件格式,专门为大型语言模型优化。相比之前的GGML格式&am…...

Qt跨平台即时通讯实战:从界面设计到TCP通信的完整实现
1. Qt跨平台即时通讯开发概述 用Qt框架开发即时通讯软件最大的优势就是"一次编写,到处运行"。我去年接手过一个项目,需要在Windows和Linux双平台上部署聊天工具,当时尝试过多种技术方案,最终Qt以绝对优势胜出。想象一下…...

pdfsizeopt如何实现PDF文件无损压缩?3大行业案例与高级技巧全解析
pdfsizeopt如何实现PDF文件无损压缩?3大行业案例与高级技巧全解析 【免费下载链接】pdfsizeopt PDF file size optimizer 项目地址: https://gitcode.com/gh_mirrors/pd/pdfsizeopt 在数字化办公环境中,PDF文件已成为信息传递的标准格式ÿ…...
)
别再手动查ID了!用R包一键搞定单细胞Marker基因ID转换(附org.Hs.eg.db实战)
单细胞Marker基因ID转换实战:用org.Hs.eg.db实现高效精准映射 刚完成单细胞聚类分析的研究者,常常会面临一个看似简单却极其耗时的任务——将Marker基因的Symbol标识转换为标准的Entrez ID。这个步骤虽然基础,却直接影响后续GO富集分析的可靠…...

ArduinoLog:面向MCU的零开销C++嵌入式日志框架
1. ArduinoLog 项目概述ArduinoLog 是一款专为 Arduino 及兼容嵌入式平台(包括 AVR、SAM、ESP8266 等)设计的轻量级 C 日志框架。其核心设计哲学是“零运行时开销、零动态内存分配、全编译期可控”,在资源极度受限的微控制器环境中࿰…...

ZGC停顿时间为何突然飙升?3个被90%团队忽略的配置雷区曝光
第一章:ZGC停顿时间为何突然飙升?3个被90%团队忽略的配置雷区曝光 ZGC(Z Garbage Collector)以亚毫秒级停顿著称,但生产环境中频繁出现 10–50ms 甚至更高停顿,往往并非内存压力所致,而是源于几…...

Phi-4-mini-reasoning部署教程:Nginx反向代理+Basic Auth安全加固
Phi-4-mini-reasoning部署教程:Nginx反向代理Basic Auth安全加固 1. 项目介绍 Phi-4-mini-reasoning是一款由微软开源的轻量级AI模型,专注于数学推理、逻辑推导和多步解题等强逻辑任务。这个3.8B参数的模型虽然体积小巧,但在推理能力上表现…...

【ZGC性能黄金阈值手册】:基于127个线上集群实测数据,定义堆大小/线程数/触发频率最优配比
第一章:ZGC性能黄金阈值的定义与行业意义ZGC(Z Garbage Collector)作为JDK 11引入的低延迟垃圾收集器,其核心设计目标是将GC暂停时间稳定控制在10毫秒以内,且不随堆大小线性增长。而“ZGC性能黄金阈值”并非官方术语&a…...

事件驱动视觉革命:EVS技术如何重塑机器感知的未来格局
1. EVS技术:重新定义机器视觉的游戏规则 想象一下你正坐在高速行驶的列车上,窗外风景飞速掠过。传统相机就像每隔几秒才按下一次快门的游客,拍到的全是模糊不清的照片;而EVS(事件驱动视觉传感器)则像专业摄…...