Postgresql运维信息(一)
1. 运维系统视图
PostgreSQL 提供了一系列系统视图和函数,可以用于获取数据库的运维统计信息。这些信息对于监控和优化数据库性能非常有用。以下是一些常用的 PostgreSQL 运维统计信息:
1.1. pg_stat_activity
这个系统视图包含了当前数据库连接的活动信息,例如正在执行的查询、连接的用户、查询开始时间等。
SELECT * FROM pg_stat_activity;
pg_stat_activity 是一个系统视图,用于显示当前正在连接到 PostgreSQL 数据库的会话信息和活动查询的详细信息。这个视图提供了有关每个当前数据库连接的一些重要信息,方便进行监控和性能调优。
| 字段名 | 描述 | 详细描述 |
|---|---|---|
| datid | 数据库 OID | 当前数据库的对象标识符(OID)。 |
| datname | 数据库名 | 连接所在的数据库名称。 |
| pid | 进程 ID | 当前会话后端进程的标识符。 |
| usesysid | 用户 OID | 连接的用户的对象标识符(OID)。 |
| usename | 用户名 | 连接的用户名。 |
| application_name | 应用程序名 | 建立连接的应用程序的名称。 |
| client_addr | 客户端地址 | 连接到 PostgreSQL 的客户端的IP地址。 |
| client_hostname | 客户端主机名 | 连接到 PostgreSQL 的客户端的主机名。如果无法解析主机名,则显示IP地址。 |
| client_port | 客户端端口 | 客户端连接到 PostgreSQL 的端口号。 |
| backend_start | 后端启动时间 | 后端进程启动的时间戳。 |
| xact_start | 事务启动时间 | 最近一次事务开始执行的时间戳。 |
| query_start | 查询启动时间 | 最近一次查询开始执行的时间戳。 |
| state | 连接状态 | 连接的当前状态。可能的值包括 “活动”、“空闲”、“等待” 等。 |
| state_change | 状态变更时间 | 最近一次连接状态发生变化的时间戳。 |
| wait_event_type | 等待事件类型 | 如果连接处于等待状态,表示正在等待的事件的类型。可能的值包括 “IO”、“Lock” 等。 |
| wait_event | 等待事件名称 | 如果连接处于等待状态,表示正在等待的具体事件名称。 |
1.2. pg_stat_database
这个系统视图包含了有关每个数据库的统计信息,例如数据库的大小、连接数、提交和回滚次数等。
SELECT * FROM pg_stat_database;
pg_stat_database 是一个 PostgreSQL 的系统视图,提供了关于每个数据库的统计信息。以下是 pg_stat_database 视图中一些重要字段的含义:
| 字段名 | 描述 | 详细描述 |
|---|---|---|
| datid | 数据库 OID | 每个数据库的唯一标识符(OID)。 |
| datname | 数据库名称 | 连接所在的数据库名称。 |
| numbackends | 活动连接数 | 当前数据库的活动连接数。 |
| xact_commit | 提交事务数量 | 自数据库启动以来的提交事务数量。 |
| xact_rollback | 回滚事务数量 | 自数据库启动以来的回滚事务数量。 |
| blks_read | 从磁盘读取的块数 | 自数据库启动以来从磁盘读取的块数量(8KB 块)。 |
| blks_hit | 从缓存读取的块数 | 自数据库启动以来从缓存读取的块数量(8KB 块)。 |
| tup_returned | 检索的行数 | 自数据库启动以来检索的行数。 |
| tup_fetched | 获取的行数 | 自数据库启动以来获取的行数。 |
| tup_inserted | 插入的行数 | 自数据库启动以来插入的行数。 |
| tup_updated | 更新的行数 | 自数据库启动以来更新的行数。 |
| tup_deleted | 删除的行数 | 自数据库启动以来删除的行数。 |
| conflicts | 冲突数 | 自数据库启动以来发生的冲突数。 |
| temp_files | 创建的临时文件数 | 自数据库启动以来创建的临时文件数。 |
| temp_bytes | 使用的临时空间字节数 | 自数据库启动以来使用的临时空间的字节数。 |
| deadlocks | 死锁数 | 自数据库启动以来发生的死锁数。 |
1.3. pg_stat_user_tables 和 pg_stat_user_indexes
这两个系统视图分别提供了用户表和索引的统计信息,包括行数、更新次数、索引扫描次数等。
SELECT * FROM pg_stat_user_tables;
SELECT * FROM pg_stat_user_indexes;
1.3.1. pg_stat_user_tables
pg_stat_user_tables 视图是 PostgreSQL 提供的一个系统视图,用于提供关于用户表的统计信息。它包含了与用户表相关的各种统计数据,帮助用户监视和分析数据库中表的活动情况和性能指标。
以下是针对 pg_stat_user_tables 视图字段的详细描述
| 字段名 | 描述 | 详细描述 |
|---|---|---|
| relid | 表的 OID | 表示统计信息相关的表的对象标识符。 |
| schemaname | 模式名称 | 表所在模式的名称。 |
| relname | 表名称 | 表的名称。 |
| seq_scan | 顺序扫描的次数 | 自数据库重启以来执行顺序扫描的次数。 |
| seq_tup_read | 通过顺序扫描读取的行数 | 自数据库重启以来通过顺序扫描读取的行数。 |
| idx_scan | 索引扫描的次数 | 自数据库重启以来执行索引扫描的次数。 |
| idx_tup_fetch | 通过索引扫描获取的行数 | 自数据库重启以来通过索引扫描获取的行数。 |
| n_tup_ins | 插入的行数 | 自数据库重启以来插入的行数。 |
| n_tup_upd | 更新的行数 | 自数据库重启以来更新的行数。 |
| n_tup_del | 删除的行数 | 自数据库重启以来删除的行数。 |
| n_tup_hot_upd | 热更新的行数 | 自数据库重启以来进行热更新的行数。 |
| n_live_tup | 当前存活的行数 | 当前存在的未标记为删除的行数。 |
| n_dead_tup | 当前死亡的行数 | 当前被标记为删除但尚未被清理的行数。 |
| last_vacuum | 最后一次 VACUUM 执行的时间 | 表最后一次执行 VACUUM 操作的时间。 |
| last_autovacuum | 最后一次自动 VACUUM 执行的时间 | 表最后一次自动执行 VACUUM 操作的时间。 |
| last_analyze | 最后一次 ANALYZE 执行的时间 | 表最后一次执行 ANALYZE 操作的时间。 |
| last_autoanalyze | 最后一次自动 ANALYZE 执行的时间 | 表最后一次自动执行 ANALYZE 操作的时间。 |
| vacuum_count | VACUUM 操作的计数 | 自数据库重启以来执行 VACUUM 操作的次数。 |
| autovacuum_count | 自动 VACUUM 操作的计数 | 自数据库重启以来执行自动 VACUUM 操作的次数。 |
| analyze_count | ANALYZE 操作的计数 | 自数据库重启以来执行 ANALYZE 操作的次数。 |
| autoanalyze_count | 自动 ANALYZE 操作的计数 | 自数据库重启以来执行自动 ANALYZE 操作的次数。 |
1.3.2. pg_stat_user_indexes
pg_stat_user_indexes 视图提供了有关用户创建的索引的统计信息,用于监视和分析这些索引的活动情况和性能指标。
| 字段名 | 描述 | 详细描述 |
|---|---|---|
| relid | 索引所属表的 OID | 表示索引所属的表的对象标识符(OID)。 |
| indexrelname | 索引名称 | 索引的名称。 |
| schemaname | 模式名称 | 索引所在的模式的名称。 |
| idx_scan | 索引扫描的次数 | 自数据库启动以来执行索引扫描的次数。 |
| idx_tup_read | 通过索引扫描获取的行数 | 自数据库启动以来通过索引扫描读取的行数。 |
| idx_tup_fetch | 通过索引扫描获取的行数 | 自数据库启动以来通过索引扫描获取的行数(通常与 idx_tup_read 类似,但在某些情况下可能会有差异)。 |
1.4. pg_stat_bgwriter
SELECT * FROM pg_stat_bgwriter;
pg_stat_bgwriter 视图提供了有关后台写入进程(background writer)的统计信息。这个视图包含了后台写入进程的性能指标,帮助用户监视数据库的后台写入活动情况。
| 字段名 | 描述 |
|---|---|
| checkpoints_timed | 周期性检查点的触发次数(通过时间间隔触发) |
| checkpoints_req | 请求性检查点的触发次数(通过请求触发) |
| checkpoint_write_time | 检查点写入到磁盘的时间(以毫秒为单位) |
| checkpoint_sync_time | 检查点同步到磁盘的时间(以毫秒为单位) |
| buffers_checkpoint | 由检查点写入的缓冲区数量 |
| buffers_clean | 后台写入进程释放的脏数据缓冲区数量 |
| maxwritten_clean | 单个检查点中释放的最大脏数据缓冲区数量 |
| buffers_backend | 后台写入进程主动写入的缓冲区数量 |
| buffers_alloc | 分配的共享缓冲区数量 |
| stats_reset | 统计信息重置的时间戳 |
pg_stat_bgwriter 视图中的这些字段提供了关于后台写入进程活动的各种统计信息,例如检查点的触发次数、写入时间、缓冲区写入和释放情况等。这些信息对于监视数据库的后台写入活动并评估数据库性能非常有用。
1.5. pg_stat_replication
pg_stat_replication 是一个系统视图,用于在 PostgreSQL 中查看关于流复制(streaming replication)的统计信息。它提供了有关当前正在进行的流复制连接的统计数据,允许用户监视和管理 PostgreSQL 流复制的状态。
SELECT * FROM pg_stat_replication;
| 字段名 | 描述 |
|---|---|
| pid | 流复制进程的后端进程 ID |
| usesysid | 备库的系统标识符 |
| usename | 连接流复制的用户名 |
| application_name | 连接的应用程序名称 |
| client_addr | 连接的客户端地址 |
| client_hostname | 连接的客户端主机名 |
| client_port | 连接的客户端端口号 |
| backend_start | 流复制进程启动时间 |
| state | 流复制连接状态 |
| sent_location | 主服务器发送到流复制客户端的位置 |
| write_location | 流复制客户端已写入到磁盘的位置 |
| flush_location | 流复制客户端已确认已刷新到磁盘的位置 |
| replay_location | 流复制客户端正在回放的位置 |
| sync_priority | 流复制连接的同步优先级 |
| sync_state | 流复制连接的同步状态 |
1.6. pg_stat_progress_vacuum
pg_stat_progress_vacuum 是一个系统视图,用于在 PostgreSQL 中查看正在执行的 VACUUM 进程的进度信息。它提供了有关正在进行的 VACUUM 操作的统计数据,允许用户监视和了解 VACUUM 操作的进度和状态。
SELECT * FROM pg_stat_progress_vacuum;
| 字段名 | 描述 |
|---|---|
| pid | VACUUM 进程的后端进程 ID |
| datid | 正在执行 VACUUM 的数据库 OID |
| relid | 正在执行 VACUUM 的表的 OID |
| phase | VACUUM 操作的阶段 |
| heap_blks_total | 表的总块数(以块为单位) |
| heap_blks_scanned | 已扫描的块数 |
| heap_blks_vacuumed | 已清理的块数 |
| heap_blks_index_cleaned | 已清理的索引块数 |
在 PostgreSQL 中,VACUUM 是一种重要的数据库维护操作,用于管理数据库中的空间和性能。VACUUM 主要用于以下几个方面:
-
释放过期的行版本空间:PostgreSQL 使用多版本并发控制(MVCC)来管理事务。当一个行被更新或删除时,旧的行版本不会立即从磁盘中删除,而是被标记为可被清理。VACUUM 会释放这些被标记为可清理的行版本所占用的空间。
-
更新统计信息:VACUUM 运行时会更新数据库中的统计信息,这些信息是优化查询计划的基础。更新这些统计信息有助于 PostgreSQL 优化查询,提高查询性能。
-
避免表空间膨胀:长时间运行的数据库操作会产生大量不再使用的空间(如删除、更新等操作会造成存储空间碎片化)。VACUUM 可以帮助回收这些空间,减少表的膨胀,使得表的存储更加紧凑。
-
减少事务ID的消耗:每个活动的事务都会消耗事务ID。通过清理旧的行版本和过期事务的元数据,VACUUM 可以减少事务ID的消耗。
VACUUM 是 PostgreSQL 数据库维护的一个关键操作,对于保持数据库性能和空间管理至关重要。通常,定期运行 VACUUM 是一个良好的实践,特别是在高写入负载的数据库中。
1.6.1. 如何清理 VACUUM
在 PostgreSQL 中执行 VACUUM 可以通过以下几种方式进行:
1. 手动执行 VACUUM
-
VACUUM 整个数据库:运行以下命令可以对整个数据库执行 VACUUM 操作:
VACUUM; -
VACUUM 单个表:指定表名执行 VACUUM 操作:
VACUUM tablename;
2. 自动化执行 VACUUM
- 自动化 VACUUM:可以设置自动执行 VACUUM 的策略。例如,使用 autovacuum 功能,通过配置参数
autovacuum和autovacuum_vacuum_scale_factor等来启用自动 VACUUM。
3. 在命令行执行 VACUUM
- 通过命令行工具执行:使用命令行工具
psql或pg_ctl来执行 VACUUM 操作。
注意事项
- 执行 VACUUM 通常会锁定被清理的对象(表),因此在高负载的生产环境中要谨慎执行,避免对正常业务产生影响。
- 在执行 VACUUM 的同时,建议先备份数据库以防意外情况发生。
- 避免频繁地手动执行 VACUUM,尤其是对于活跃更新频繁的数据库,可以考虑使用自动化的 VACUUM 策略。
总的来说,VACUUM 是一个维护性的操作,可以通过命令行工具、SQL 命令或设置自动执行来管理数据库中的空间和性能。
1.7. pg_stat_progress_analyze
pg_stat_progress_analyze 是 PostgreSQL 中的一个系统视图,用于查看正在进行的 ANALYZE 操作的进度信息。它提供了关于当前 ANALYZE 操作的统计数据,允许用户监视和了解 ANALYZE 操作的执行情况。
SELECT * FROM pg_stat_progress_analyze;
| 字段名 | 描述 |
|---|---|
| pid | ANALYZE 进程的后端进程 ID |
| datid | 正在执行 ANALYZE 的数据库 OID |
| relid | 正在执行 ANALYZE 的表的 OID |
| phase | ANALYZE 操作的阶段 |
| heap_blks_total | 表的总块数(以块为单位) |
| heap_blks_scanned | 已扫描的块数 |
| heap_blks_vacuumed | 已清理的块数 |
| num_index_scans | 已扫描的索引数 |
| max_tid | 最大的可见行版本号 |
相关文章:
)
Postgresql运维信息(一)
1. 运维系统视图 PostgreSQL 提供了一系列系统视图和函数,可以用于获取数据库的运维统计信息。这些信息对于监控和优化数据库性能非常有用。以下是一些常用的 PostgreSQL 运维统计信息: 1.1. pg_stat_activity 这个系统视图包含了当前数据库连接的活动…...
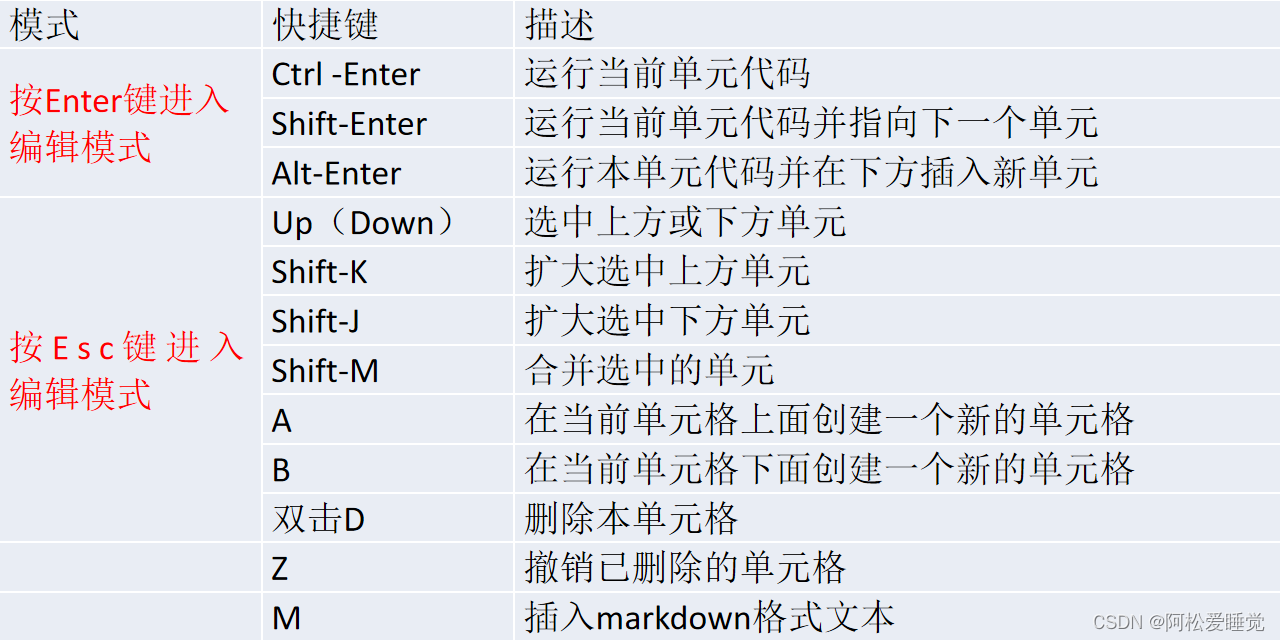
Jupyter Notebook的下载安装与使用教程_Python数据分析与可视化
Jupyter Notebook的下载安装与使用 Jupyter简介下载与安装启动与创建NotebookJupyter基本操作 在计算机编程领域,有一个很强大的工具叫做Jupyter。它不仅是一个集成的开发环境,还是一个交互式文档平台。对于初学者来说,Jupyter提供了友好的界…...
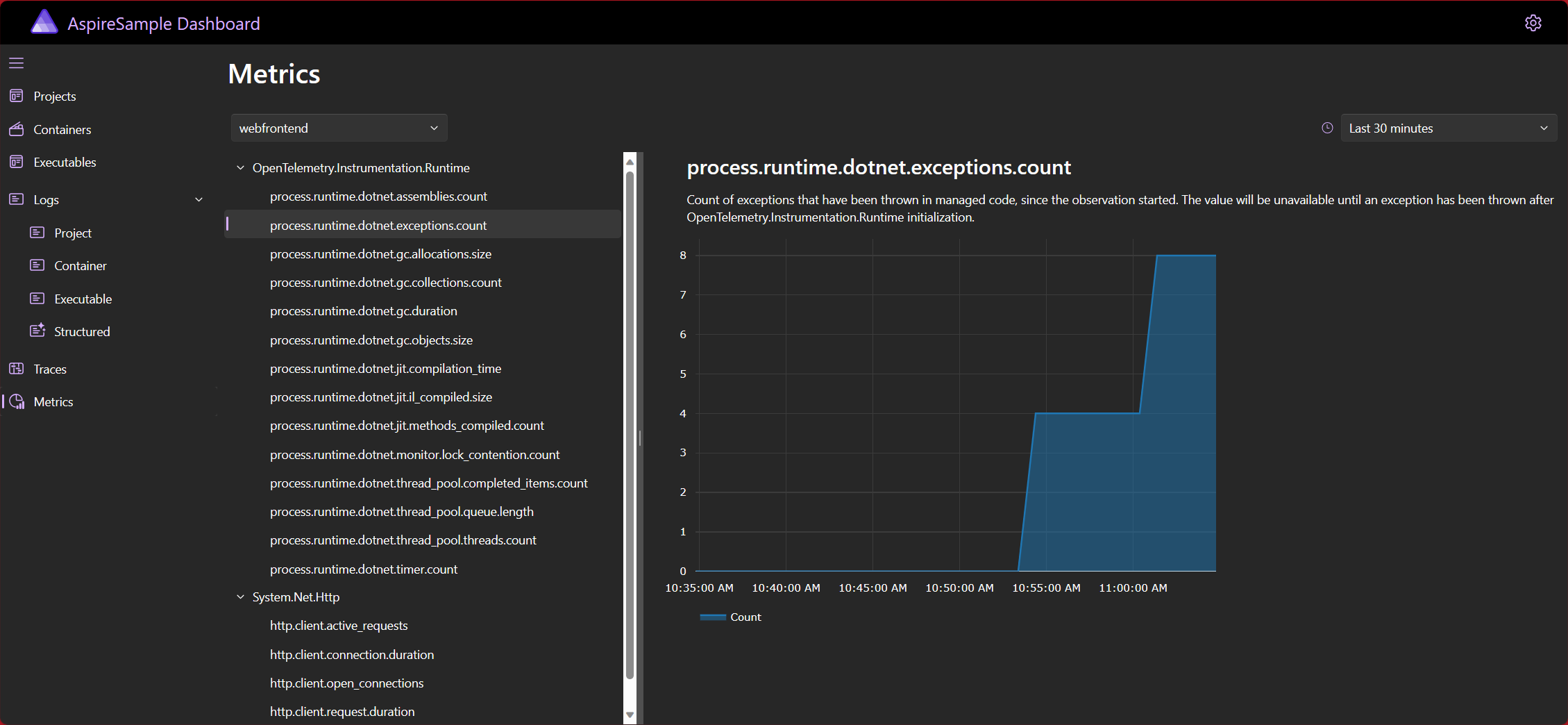
快速入门:构建您的第一个 .NET Aspire 应用程序
##前言 云原生应用程序通常需要连接到各种服务,例如数据库、存储和缓存解决方案、消息传递提供商或其他 Web 服务。.NET Aspire 旨在简化这些类型服务之间的连接和配置。在本快速入门中,您将了解如何创建 .NET Aspire Starter 应用程序模板解决方案。 …...

主流开源大语言模型的微调方法
文章目录 模型ChatGLM2网址原生支持微调方式 ChatGLM3网址原生支持微调方式 Baichuan 2网址原生支持微调方式 Qwen网址原生支持微调方式 框架FireflyEfficient-Tuning-LLMsSuperAdapters 模型 ChatGLM2 网址 https://github.com/thudm/chatglm2-6b 原生支持微调方式 https…...

Django DRF权限组件
在Django的drf框架内的权限组件,如果遇到多个权限认证类,是需要所有的权限类都要通过验证,才能访问视图。 一、简单示例 1、per.py 自定义权限类 from rest_framework.permissions import BasePermission import randomclass MyPerssion(B…...

leetcode每日一题31
搜索旋转排序数组 那……二分法呗 数组中的数可以相同 比 33. 搜索旋转排序数组 多了一个「有重复元素」,导致无法根据 num > nums[0] 来判断 num 在哪一半,比如 [1,1,1,1,1,2,1,1,1] 旋转数组两头相等,元素 1 可能在左半边可能在右半边 …...
)
使用Pytorch测试cuda设备的性能(单卡或多卡并行)
以下CUDA设备泛指NVIDIA显卡 或 启用ROCm的AMD显卡 测试环境: Distributor ID: UbuntuDescription: Ubuntu 22.04.3 LTSRelease: 22.04Codename: jammy 1.首先,简单使用torch.ones测试CUDA设备 import torch import timedef cuda_benchmark(device_id…...

SpringBoot-AOP-基础到进阶
SpringBoot-AOP AOP基础 学习完spring的事务管理之后,接下来我们进入到AOP的学习。 AOP也是spring框架的第二大核心,我们先来学习AOP的基础。 在AOP基础这个阶段,我们首先介绍一下什么是AOP,再通过一个快速入门程序,…...

Midjourney绘画提示词Prompt参考学习教程
一、工具 SparkAi: SparkAi创作系统是基于OpenAI很火的ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软…...

美国费米实验室SQMS启动“量子车库”计划!30+顶尖机构积极参与
11月6日,美国能源部费米国家加速器实验室(SQMS)正式启动了名为“量子车库”的全新旗舰量子研究设施。这个6,000平方英尺的实验室是由超导量子材料与系统中心负责设计和建造,旨在联合国内外的科学界、工业领域和初创企业,共同推动量子信息科…...
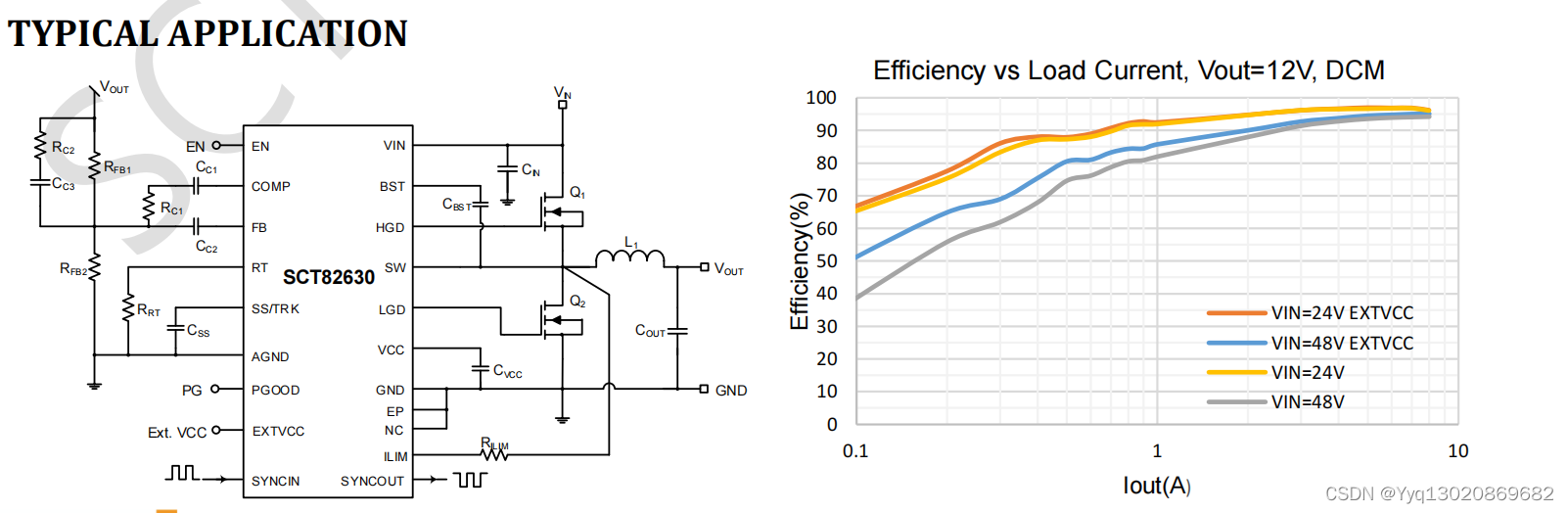
DCDC同步降压控制器SCT82A30\SCT82630
SCT82A30是一款100V电压模式控制同步降压控制器,具有线路前馈。40ns受控高压侧MOSFET的最小导通时间支持高转换比,实现从48V输入到低压轨的直接降压转换,降低了系统复杂性和解决方案成本。如果需要,在低至6V的输入电压下降期间&am…...
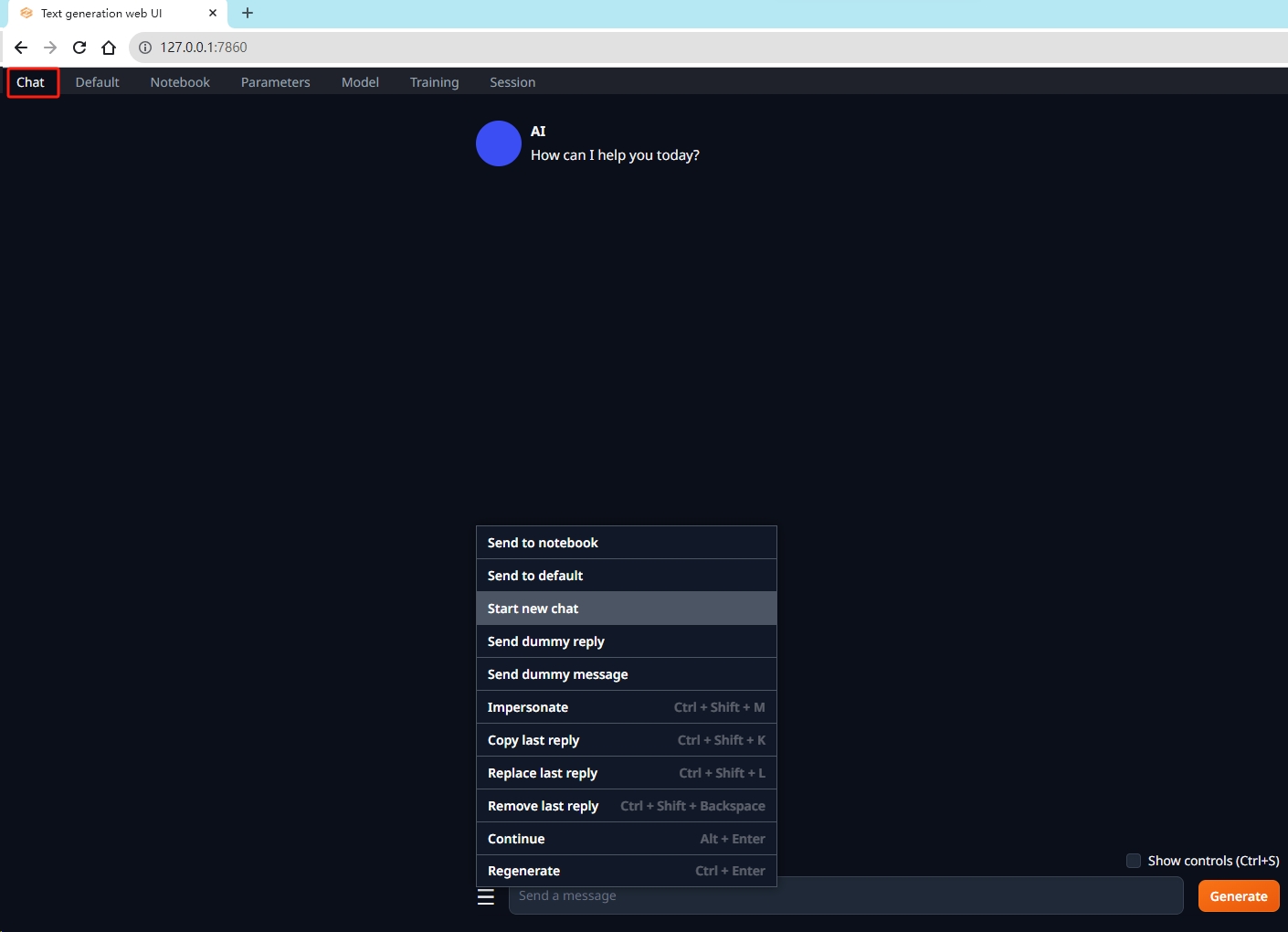
本地/笔记本/纯 cpu 部署、使用类 gpt 大模型
文章目录 1. 安装 web UI1.1. 下载代码库1.2. 创建 conda 环境1.3. 安装 pytorch1.4. 安装 pip 库 2. 下载大模型3. 使用 web UI3.1. 运行 UI 界面3.2. 加载模型3.3. 进行对话 使用 web UI 大模型文件,即可在笔记本上部署、使用类 gpt 大模型。 1. 安装 web UI 1…...

企企通亮相广东智能装备产业发展大会:以数字化采购促进智能装备产业集群高质量发展
制造业是立国之本,是国民经济的主要支柱、是推动工业技术创新的重要来源。 广东作为我国制造业大省,装备制造业规模增长快速,技术水平居于全国前列。为全面贯彻学习党的二十大精神,进一步推动机械装备可靠性设计,促进新…...

pycharm安装教程
PyCharm的安装步骤如下: 找到下载PyCharm的路径,双击.exe文件进行安装。点击Next后,选择安装路径页面(尽量不要选择带中文和空格的目录),选择好路径后,点击Next进行下一步。进入Installation O…...

LeetCode【76】最小覆盖子串
题目: 思路: https://segmentfault.com/a/1190000021815411 代码: public String minWindow(String s, String t) { Map<Character, Integer> map new HashMap<>();//遍历字符串 t,初始化每个字母的次数for (int…...
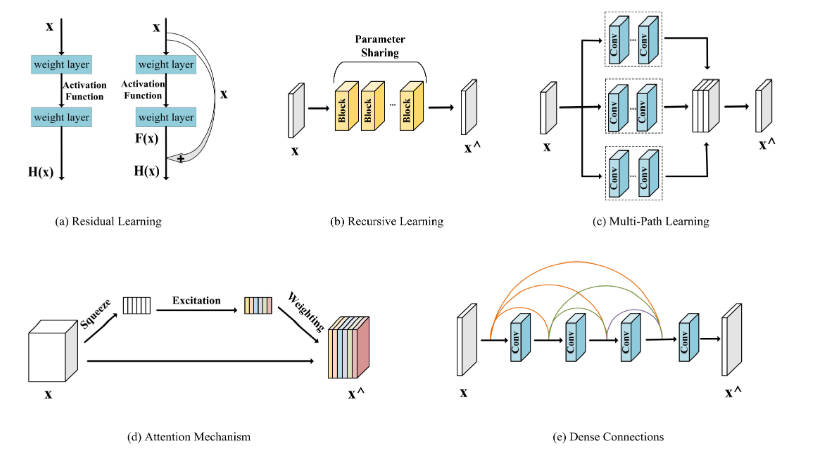
光谱图像超分辨率综述
光谱图像超分辨率综述 简介 论文链接:A Review of Hyperspectral Image Super-Resolution Based on Deep Learning UpSample网络框架 1.Front-end Upsampling 在Front-end上采样中,是首先扩大LR图像,然后通过卷积网络对放大图像进行…...

Ubuntu apt-get换源
一、参考资料 ubuntu16.04更换镜像源为阿里云镜像源 二、相关介绍 1. apt常用命令 sudo apt-get clean sudo apt-get update2. APT加速工具 轻量小巧的零配置 APT 加速工具:APT Proxy GitHub项目地址:apt-proxy 三、换源关键步骤 1. 更新阿里源 …...
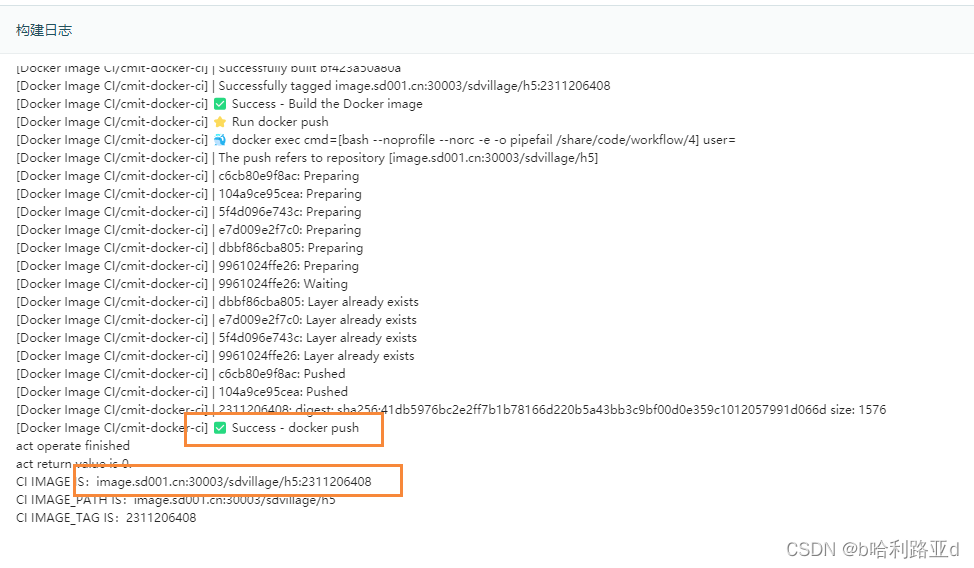
磐舟CI-Web前端项目
整体介绍 磐舟作为一个devops产品,它具备基础的CI流水线功能。同时磐舟的流水线是完全基于云原生架构设计的,在使用时会有一些注意事项。这里首先我们要了解磐舟整体的流水线打包逻辑。 文档结构说明 一般来说,磐舟推荐单个业务的标准git库…...

Flink 运行架构和核心概念
Flink 运行架构和核心概念 几个角色的作用: 客户端:提交作业JobManager进程 任务管理调度 JobMaster线程 一个job对应一个JobMaster 负责处理单个作业ResourceManager 资源的分配和管理,资源就是任务槽分发器 提交应用,为每一个…...
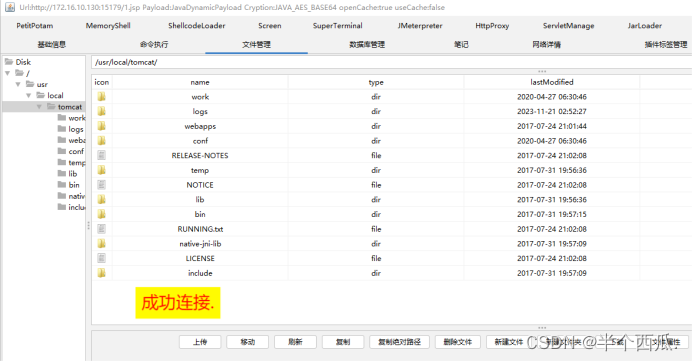
中间件安全:Apache Tomcat 文件上传.(CVE-2017-12615)
中间件安全:Apache Tomcat 文件上传. 当存在漏洞的 Tomcat 运行在 Windows / Linux 主机上,且启用了 HTTP PUT 请求方法(例如,将 readonly 初始化参数由默认值设置为ialse) , 攻击者将有可能可通过精心构造的攻击请求数据包向服务…...
)
大模型多维度评估体系构建指南:从SITS大会带回的4层漏斗式评估矩阵(含Prompt一致性校准模块)
更多请点击: https://intelliparadigm.com 第一章:大模型A/B测试方法:SITS大会 在2024年SITS(Scalable Intelligence Testing Summit)大会上,工业界首次系统性地提出了面向大语言模型的A/B测试新范式——*…...

SingleFile终极指南:如何一键保存完整网页到单个HTML文件
SingleFile终极指南:如何一键保存完整网页到单个HTML文件 【免费下载链接】SingleFile Web Extension for saving a faithful copy of a complete web page in a single HTML file 项目地址: https://gitcode.com/gh_mirrors/si/SingleFile SingleFile是一款…...

X-Mouse Controls:5个专业技巧解锁Windows鼠标终极效率
X-Mouse Controls:5个专业技巧解锁Windows鼠标终极效率 【免费下载链接】xmouse-controls Microsoft Windows utility to manage the active window tracking/raising settings. This is known as x-mouse behavior or focus follows mouse on Unix and Linux syste…...

AssetStudio:解锁Unity游戏资源宝库的专业工具
AssetStudio:解锁Unity游戏资源宝库的专业工具 【免费下载链接】AssetStudio AssetStudio - Based on the archived Perfares AssetStudio, I continue Perfares work to keep AssetStudio up-to-date, with support for new Unity versions and additional improve…...

HDLbits实战解析:Verification模块的Simulation测试技巧
1. 从零开始理解Verification模块的仿真测试 刚开始接触数字电路设计时,很多人会陷入一个误区——认为只要把模块代码写出来就万事大吉了。直到我第一次在HDLbits上遇到Verification模块的题目,才真正明白仿真测试的重要性。仿真就像给电路设计装上"…...

SKILL.md:用Markdown文件让AI助手直接调用Twitter API
1. 项目概述:让AI助手直接操作Twitter/X的“技能文件” 如果你正在捣鼓AI助手,想让它帮你自动刷推、搜索信息、管理社群,甚至自动回复私信,那么你很可能已经遇到了一个巨大的障碍:Twitter(现在叫X…...

从‘特征图侦探’视角看MaxPool2D:你的CNN到底通过池化‘忘记’了什么?
从‘特征图侦探’视角看MaxPool2D:你的CNN到底通过池化‘忘记’了什么? 在计算机视觉领域,卷积神经网络(CNN)的成功很大程度上依赖于其层次化特征提取能力。而在这个特征提取的流水线上,池化层扮演着至关重要的角色——它像一位严…...

无代码AI平台实战:从业务需求到模型部署的完整指南
1. 项目概述:当AI不再是程序员的专属玩具 “AI民主化”这个词最近听得耳朵都快起茧了,但真正落到实处的体验是什么?作为一个在技术和业务之间反复横跳了十多年的老手,我亲眼见证了从“只有博士才能玩转的算法黑箱”到“业务经理自…...

基于大语言模型的自动化知识图谱模式生成:原理、实践与应用
1. 项目概述:当大模型学会“画图”,知识图谱构建进入自动化时代如果你也和我一样,曾经被构建知识图谱(Knowledge Graph, KG)那繁琐、耗时且高度依赖人工标注的流程折磨过,那么看到“AutoSchemaKG”这个名字…...

Maestro工作流引擎:声明式编排与复杂自动化流程实践
1. 项目概述:一个面向开发者的全能型工作流编排引擎最近在梳理团队内部持续集成和自动化测试的流程,发现随着项目复杂度的提升,传统的脚本串联方式越来越力不从心。脚本分散、依赖管理混乱、错误处理不统一,每次流程调整都像在拆解…...