使用大语言模型 LLM 做文本分析
本文主要分享
-
传统聚类算法
-
LLM与嵌入算法
-
嵌入算法聚类
-
LLM的其他用法
聚类是一种无监督机器学习技术,旨在根据相似的数据点的特征将其分组在一起。使用聚类成簇,有助于解决各种问题,例如客户细分、异常检测和文本分类等。尽管传统的聚类技术被广泛使用,但它仍然面临着挑战。今天代码很少,也没有实验数据, 主要是偏思路分享。
技术提升
论文探讨、算法交流、求职内推、干货分享、解惑答疑,与2000+来自港大、北大、腾讯、科大讯飞、阿里等开发者互动学习。
项目源码、数据、技术交流提升,均可加交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
方式①、添加微信号:mlc2060,备注:来自CSDN +研究方向
方式②、微信搜索公众号:机器学习社区,后台回复:加群

一、编码挑战
1.1 字段单位不统一
我想在本文中解决的主要挑战是选择如何编码或转换输入特征。一般来说,您需要将每个特征转换为相同的比例,否则,聚类模型将在特征之间分配不成比例的权重。例如, 假设数据中有重量 weight1 、 weight2 两个字段,weight1单位是市斤,而weight2单位是公斤。如果不首先对这些测量进行标准化,即使实际重量相同,我们的模型也会推断出以市斤为单位(对于类似重量的物体)测量的重量差异大于以公斤为单位的差异。
现实中,数据集中不会出现对一个信息使用两种单位进行度量。使用这个例子, 只为说明数据中不同字段分布不同,训练模型时不同字段承载的权重也不一样。为了减轻这个问题,一般是训练之前先将字段标准化。
1.2 字段之间存在相关性
让我们使用颜色组成的特征作为另一个示例。通常,许多人会选择将此特征 one-hot 编码到 n-1 个附加列中,其中 n 是唯一颜色的数量。虽然这有效,但它忽略了颜色之间的任何潜在关系。
为什么是这样?让我们考虑数据集中的一个特征具有以下颜色:红色、栗色、深红色、猩红色和绿色。如果我们要对该列进行 one-hot 编码,我们将得到一个如下所示的数据帧:

在 欧几里德距离空间 中,任意两个记录(行)之间的距离是相同的。
import numpy as npdef euclidean_distance(vec1, vec2):if len(vec1) != len(vec2):raise ValueError("vecs must have the same length.")squared_differences = [(a - b) ** 2 for a, b in zip(vec1, vec2)]distance = np.sqrt(sum(squared_differences))return distancered = np.array([0, 0, 0, 1, 0])
maroon = np.array([0, 0, 1, 0, 0])
green = np.array([0, 1, 0, 0, 0])print(euclidean_distance(red, maroon))
print(euclidean_distance(red, green))
Run
1.4142135623730951 1.4142135623730951
二、有更好的办法吗?
当然, 红色 和 栗色 是两种不同的颜色,但为了我们的聚类算法,我们其实不希望euclidean_distance(red, maroon) 与 euclidean_distance(red, green) 是相等的。
那么该如何解决这个缺点呢?
如果您阅读这篇文章的标题,我相信您可能已经get到本文的ieda……我们将结合 大语言模型 (Large language model, LLM), 将每条记录字段和数值整理成一个字符串, 并通过LLM获得每条记录对应的嵌入表示。
对于此示例,我将使用 Huggingface 中的句子转换器库以及我围绕工作申请综合创建的数据集。
让我们从句子转换器开始。该 LLM 的工作原理与 BERT 类似,只不过它经过专门训练以在句子级别而不是单词或标记级别输出嵌入。这些句子级嵌入可以更好地捕获含义,并且计算速度更快。
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim#使用hugginface,需要科学上网
model = SentenceTransformer(r"sentence-transformers/paraphrase-MiniLM-L6-v2")def prompt_text(x):#每条记录整合为一个字符串p_text = (f"Age: {x['Age']} Gender: {x['Gender'].lower()} Role: {x['Role']} "f"Hiring Department: {x['HiringDepartment']} "f"Travel Preference: {x['TravelPreference']} Extracurriculars: {x['ExtraCurriculars']} "f"Distance From Home: {x['DistanceFromHome']} "f"Internships: {x['Internships']} Education Level: {x['EducationLevel']} Education Field: {x['EducationField']} "f"Summary: {x['Summary']}" )return p_textdef output_embedding(text):#返回的嵌入表示的尺寸(记录数, 384)#sentence-transformers/paraphrase-MiniLM-L6-v2 模型的词向量维度是384embd = model.encode(text)return pd.DataFrame(embd.reshape(-1, 384))def preprocess_text(x):text = prompt_text(x)embd = output_embedding(text)return embddf['combined_text'] = df.apply(lambda x: preprocess_text(x), axis=1)
我们的数据集包括有关求职者的信息,例如招聘部门、职位、年龄和教育水平等特征。这是一个数据截图:

我们的目标是将所有求职者分为不同的簇(可以理解为群体)。
让我们看看如何将句子嵌入应用于每个求职者。第一步是通过将所有功能连接到一个字符串中来创建单个文本prompt。
Age: 28.
Gender: male.
Role: Research Scientist.
Hiring Department: Research & Development.
Travel Preference: Travel_Frequently.
Extracurriculars: nan.
Distance From Home: 4.
Internships: 9.
Education Level: 3.
Education Field: Engineering.
Summary: As you can see, I am very dedicated and I am ready to start at your firm immediately.
将原记录(行)转为如上图所示的文本,之后调用 SBERT LLM 检索文本对应的嵌入向量。为方便展示,这里使用 dataframe.style 功能来突出显示低值和大值,以使表格更容易扫描:

三、用嵌入编码有什么益处?
之前讲了传统聚类算法使用one-hot编码方式的不足,但没有解释用嵌入表示的益处。先不讲理论, 就像探索颜色编码,我们看一个例子。我想测量 Role (岗位角色) 的相似程度, 我更倾向于用余弦相似度,而不是欧几里德距离, 请问这其中的差异是?
-
欧几里得距离 是两点之间几何距离的度量,而 余弦相似度 度量向量的方向。
-
欧几里得距离对向量的大小敏感,而余弦相似度则不然。
-
欧氏距离的值范围从 0(相同向量)到无穷大,而 余弦相似度的范围从 -1(完全不相似)到 1(完全相似)
让我们选择两个岗位角色:销售代表(sales representative)和销售主管(sales executive)。
-
使用 one-hot 编码的 销售代表 和 销售主管 的余弦相似度为 0.5,这意味着他们有些相关。这是有道理的,因为他们都是销售角色。
-
使用嵌入编码的余弦相似度为 0.82。它们的相关性要高得多。这更有意义,因为销售代表和销售主管在实践中是极其相似的角色。
3.1 传统的聚类
传统聚类算法大致流程如下图所示,

原文作者实验使用K=3的聚类算法,但k如何设置不是最关键的点。我们的聚类模型中最重要的字段是求职者的个人总结(Summary),其次是 招聘部门(HiringDepartment)、是否喜欢旅行(TravelPreference)。

为了更好的理解3个簇, 我们输出了数据汇总,每个数值字段平均值 及 非数值字段的高频项。

按道理聚类算法的结果应该不同簇之间的差异尽可能的大。糟糕的是不同簇之间的, 年龄(Age)、实习次数(Internships) 差异很小,而更糟糕的是招聘部门(HiringDepartment) 和 岗位角色(Role) 完全相同。
3.2 嵌入的聚类
使用嵌入编码的聚类算法流程如下图所示。与传统 聚类方法相比,使用嵌入的流程只需处理数字特征, 因为由求职者提示信息(代码里的prompt_text)转化来的嵌入是严格数字化的。

在这里,我们不能像上次那样直接计算字段重要性。我们有数百个难以理解的特征,它们的重要性各不相同,我们无法理解。那么我们该怎么办?让我们训练另一个模型(这次是有监督的三类分类模型),使用原始特征集来预测嵌入模型生成的类标签。这样就可以以同类的方式重现字段重要性。结果如下

我们找到一种新的嵌入表示来编码求职者信息, 并运算出了聚类结果。

从统计信息(上图)中可以看出,不同簇之间的差异变的更加清晰。使用嵌入编码, 让更多申请销售岗位的的销售主管划分到cluster2, 让更多申请研发岗位的的科学家划分到cluster1 和 cluster3.
四、启发
读完以上内容,大邓想到一个问题, 假设 没有简历系统,没有大数据,求职者与面试官坐在现场, 数据就是面试过程中的交流, 而交流必然通过话语这一媒介。例如求职者的个人信息
“大家好,我叫张三, 今年24岁,哈尔滨人。本科毕业于哈尔滨工业大学,市场营销专业。 我是一个很外向的人,对销售很感兴趣,在大学期间摆了很多地摊。很希望获得贵公司的机会,让我在营销岗位上大发异彩。”
面试期间,记录人员将该哈尔滨张三的个人信息被整理为
name: 张三
age: 24
city: 哈尔滨
edu: 哈尔滨工业大学
major: 市场营销
experience: 摆摊
summary: 我是外向的人,对销售很感兴趣。
求职者的信息汇总成xlsx, 每个人的信息都或多或少的被压缩了。这种表示方式, 在小规模时, 求职者的总结summary还是有很大信息量的,能够让面试者回忆起当时的场景和情景。但是当求职者的规模上升到几千上万, 备注note信息这种很重要的信息反而无法利用。
使用大语言模型LLM,将文本提示转化为嵌入表示。我们可以将LLM看成是一个察言观色,见微知著,明察秋毫的智者。 这个智者可以
-
分类
-
提取信息
-
补全
-
相似性
-
…
以往缺失数据, 用插值或者其他技巧, 现在我们可以借助LLM, 只有有其他字段残存的微弱线索, LLM就能帮我们补全缺失值。
4.1 分类
如图所示, 对于很多短文本, 我们可以推断话题,也可以推断情绪。
https://huggingface.co/morit/chinese_xlm_xnli


4.2 提取信息
假设有一些信息存储在文本中, 可以用正则表达式提取, 下面的例子用正则会很难设计, 但用LLM很简单。
https://huggingface.co/luhua/chinese_pretrain_mrc_roberta_wwm_ext_large

4.3 补全
填充缺失值信息

4.4 相似性

当然LLM功能还有很多,大家可以自己探索探索。
相关文章:
使用大语言模型 LLM 做文本分析
本文主要分享 传统聚类算法 LLM与嵌入算法 嵌入算法聚类 LLM的其他用法 聚类是一种无监督机器学习技术,旨在根据相似的数据点的特征将其分组在一起。使用聚类成簇,有助于解决各种问题,例如客户细分、异常检测和文本分类等。尽管传统的聚…...

Windows本地搭建rtmp推流服务
前言 开发时偶尔需要使用rtmp直播流做视频流测试,苦于网上开源的rtmp视频流都已经失效,无奈只好尝试在本地自己搭建一个rtmp的推流服务,方便测试使用。 一、工具准备 Nginx:使用nginx-rtmp-win64推流工具FFmpeg:官方…...

机器学习二元分类 二元交叉熵 二元分类例子
二元交叉熵损失函数 深度学习中的二元分类损失函数通常采用二元交叉熵(Binary Cross-Entropy)作为损失函数。 二元交叉熵损失函数的基本公式是: L(y, y_pred) -y * log(y_pred) - (1 - y) * log(1 - y_pred)其中,y是真实标签&…...
)
Postgresql运维信息(一)
1. 运维系统视图 PostgreSQL 提供了一系列系统视图和函数,可以用于获取数据库的运维统计信息。这些信息对于监控和优化数据库性能非常有用。以下是一些常用的 PostgreSQL 运维统计信息: 1.1. pg_stat_activity 这个系统视图包含了当前数据库连接的活动…...
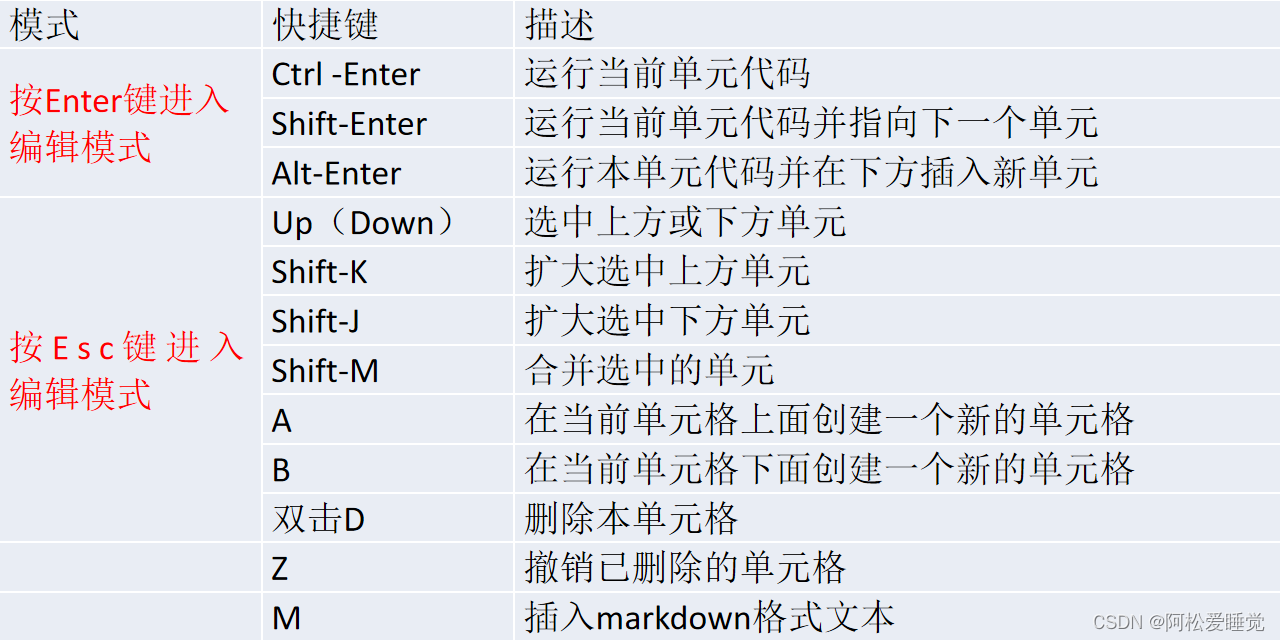
Jupyter Notebook的下载安装与使用教程_Python数据分析与可视化
Jupyter Notebook的下载安装与使用 Jupyter简介下载与安装启动与创建NotebookJupyter基本操作 在计算机编程领域,有一个很强大的工具叫做Jupyter。它不仅是一个集成的开发环境,还是一个交互式文档平台。对于初学者来说,Jupyter提供了友好的界…...
快速入门:构建您的第一个 .NET Aspire 应用程序
##前言 云原生应用程序通常需要连接到各种服务,例如数据库、存储和缓存解决方案、消息传递提供商或其他 Web 服务。.NET Aspire 旨在简化这些类型服务之间的连接和配置。在本快速入门中,您将了解如何创建 .NET Aspire Starter 应用程序模板解决方案。 …...

主流开源大语言模型的微调方法
文章目录 模型ChatGLM2网址原生支持微调方式 ChatGLM3网址原生支持微调方式 Baichuan 2网址原生支持微调方式 Qwen网址原生支持微调方式 框架FireflyEfficient-Tuning-LLMsSuperAdapters 模型 ChatGLM2 网址 https://github.com/thudm/chatglm2-6b 原生支持微调方式 https…...

Django DRF权限组件
在Django的drf框架内的权限组件,如果遇到多个权限认证类,是需要所有的权限类都要通过验证,才能访问视图。 一、简单示例 1、per.py 自定义权限类 from rest_framework.permissions import BasePermission import randomclass MyPerssion(B…...

leetcode每日一题31
搜索旋转排序数组 那……二分法呗 数组中的数可以相同 比 33. 搜索旋转排序数组 多了一个「有重复元素」,导致无法根据 num > nums[0] 来判断 num 在哪一半,比如 [1,1,1,1,1,2,1,1,1] 旋转数组两头相等,元素 1 可能在左半边可能在右半边 …...
)
使用Pytorch测试cuda设备的性能(单卡或多卡并行)
以下CUDA设备泛指NVIDIA显卡 或 启用ROCm的AMD显卡 测试环境: Distributor ID: UbuntuDescription: Ubuntu 22.04.3 LTSRelease: 22.04Codename: jammy 1.首先,简单使用torch.ones测试CUDA设备 import torch import timedef cuda_benchmark(device_id…...

SpringBoot-AOP-基础到进阶
SpringBoot-AOP AOP基础 学习完spring的事务管理之后,接下来我们进入到AOP的学习。 AOP也是spring框架的第二大核心,我们先来学习AOP的基础。 在AOP基础这个阶段,我们首先介绍一下什么是AOP,再通过一个快速入门程序,…...

Midjourney绘画提示词Prompt参考学习教程
一、工具 SparkAi: SparkAi创作系统是基于OpenAI很火的ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软…...

美国费米实验室SQMS启动“量子车库”计划!30+顶尖机构积极参与
11月6日,美国能源部费米国家加速器实验室(SQMS)正式启动了名为“量子车库”的全新旗舰量子研究设施。这个6,000平方英尺的实验室是由超导量子材料与系统中心负责设计和建造,旨在联合国内外的科学界、工业领域和初创企业,共同推动量子信息科…...
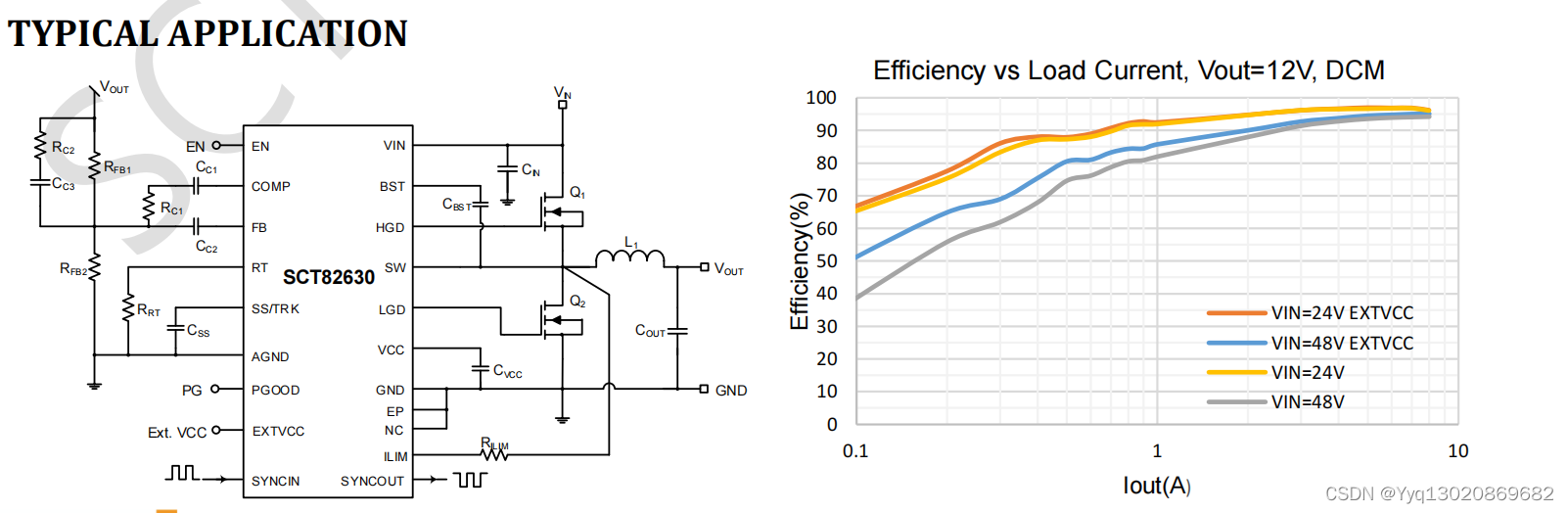
DCDC同步降压控制器SCT82A30\SCT82630
SCT82A30是一款100V电压模式控制同步降压控制器,具有线路前馈。40ns受控高压侧MOSFET的最小导通时间支持高转换比,实现从48V输入到低压轨的直接降压转换,降低了系统复杂性和解决方案成本。如果需要,在低至6V的输入电压下降期间&am…...
本地/笔记本/纯 cpu 部署、使用类 gpt 大模型
文章目录 1. 安装 web UI1.1. 下载代码库1.2. 创建 conda 环境1.3. 安装 pytorch1.4. 安装 pip 库 2. 下载大模型3. 使用 web UI3.1. 运行 UI 界面3.2. 加载模型3.3. 进行对话 使用 web UI 大模型文件,即可在笔记本上部署、使用类 gpt 大模型。 1. 安装 web UI 1…...

企企通亮相广东智能装备产业发展大会:以数字化采购促进智能装备产业集群高质量发展
制造业是立国之本,是国民经济的主要支柱、是推动工业技术创新的重要来源。 广东作为我国制造业大省,装备制造业规模增长快速,技术水平居于全国前列。为全面贯彻学习党的二十大精神,进一步推动机械装备可靠性设计,促进新…...

pycharm安装教程
PyCharm的安装步骤如下: 找到下载PyCharm的路径,双击.exe文件进行安装。点击Next后,选择安装路径页面(尽量不要选择带中文和空格的目录),选择好路径后,点击Next进行下一步。进入Installation O…...

LeetCode【76】最小覆盖子串
题目: 思路: https://segmentfault.com/a/1190000021815411 代码: public String minWindow(String s, String t) { Map<Character, Integer> map new HashMap<>();//遍历字符串 t,初始化每个字母的次数for (int…...
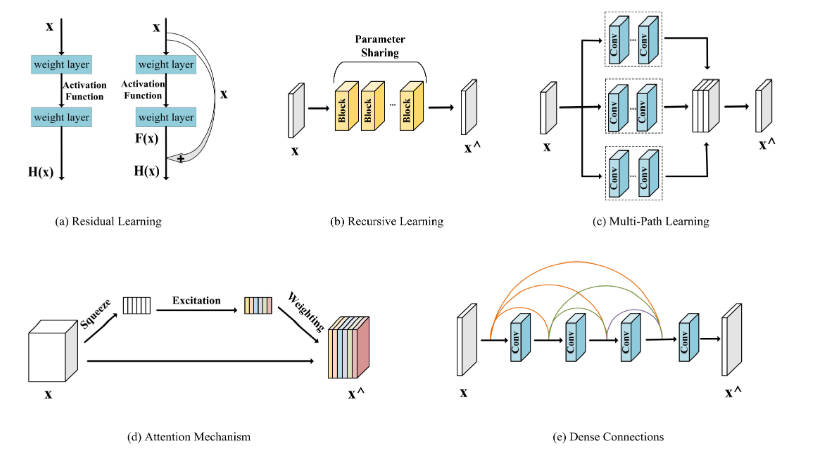
光谱图像超分辨率综述
光谱图像超分辨率综述 简介 论文链接:A Review of Hyperspectral Image Super-Resolution Based on Deep Learning UpSample网络框架 1.Front-end Upsampling 在Front-end上采样中,是首先扩大LR图像,然后通过卷积网络对放大图像进行…...

Ubuntu apt-get换源
一、参考资料 ubuntu16.04更换镜像源为阿里云镜像源 二、相关介绍 1. apt常用命令 sudo apt-get clean sudo apt-get update2. APT加速工具 轻量小巧的零配置 APT 加速工具:APT Proxy GitHub项目地址:apt-proxy 三、换源关键步骤 1. 更新阿里源 …...

桌面图标太多找不到文件?NoFences让你5分钟拥有整洁高效的工作空间
桌面图标太多找不到文件?NoFences让你5分钟拥有整洁高效的工作空间 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 你是否经历过这样的场景:电脑桌面堆…...

基于明朝内阁制的AI多智能体协作系统:从原理到部署实战
1. 项目概述:当皇上,一个基于明朝内阁制的AI多智能体协作系统 如果你曾经幻想过像皇帝一样,只需动动嘴皮子,就有一群“大臣”为你分忧解难,处理从写代码到查账单的各种琐事,那么“当皇上”这个项目&#x…...

告别键盘连击烦恼:开源工具KeyboardChatterBlocker完全指南
告别键盘连击烦恼:开源工具KeyboardChatterBlocker完全指南 【免费下载链接】KeyboardChatterBlocker A handy quick tool for blocking mechanical keyboard chatter. 项目地址: https://gitcode.com/gh_mirrors/ke/KeyboardChatterBlocker 还在为机械键盘的…...

2025届毕业生推荐的十大AI辅助论文神器横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 做为新一代大语言模型的DeepSeek,为学术论文写作供给了智能化辅助,研…...

开发工具分发遇阻,苹果开发者计划收费高、验证难,代码签名领域价格离谱!
苹果让开发者压力倍增2026年5月9日,开发者正在开发一款简单的开发者工具,旨在让管理Claude Code配置文件变得更轻松。该工具首个版本已发布,可在ccode.kronis.dev查看,或访问Itch.io页面下载或购买预编译的二进制文件,…...

IWR1642与mmWave Studio实战:从参数配置到数据解析的完整指南
1. IWR1642与mmWave Studio初探:为什么参数配置如此重要 第一次接触TI的IWR1642评估板和mmWave Studio软件时,很多人会被各种参数搞得晕头转向。我刚开始用的时候也是这样,看着界面上密密麻麻的选项,完全不知道从哪下手。后来才发…...

英雄联盟智能助手Seraphine:如何用5分钟提升你的游戏体验?
英雄联盟智能助手Seraphine:如何用5分钟提升你的游戏体验? 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 还在为BP阶段手忙脚乱而烦恼吗?还在手动查询队友对手战绩浪费宝贵…...

多模型AI代码助手:Claude、Codex、Gemini集成框架的设计与实践
1. 项目概述:一个面向开发者的多模型代码生成与智能助手最近在GitHub上看到一个挺有意思的项目,叫“Suga13/Claudecode-Codex-Gemini”。光看这个名字,就能嗅到一股浓浓的“缝合怪”味道,但别急着划走,这恰恰是它最有趣…...

writ工具:提升AI编程指令质量与智能体协作的工程实践
1. 项目概述:为AI编码智能体构建质量与沟通层如果你和我一样,每天都在和Cursor、Claude Code这类AI编码助手打交道,那你肯定遇到过这样的场景:你精心写了一大段指令,告诉AI“重构这个函数,让它更高效”&…...

从信托义务到AI对齐:构建可信人工智能的技术与治理框架
1. 项目概述:当法律遇上代码最近和几位做AI产品落地的朋友聊天,大家不约而同地提到了同一个词:“对齐”。但聊着聊着,话题就从技术上的“奖励模型”和“人类反馈强化学习”,滑向了更让人头疼的领域——合规、责任和信任…...