Java 多线程进阶
1 方法执行与进程执行
@GetMapping("/demo1")public void demo1(){//方法调用new ThreadTest1("run1").run();//线程调用new ThreadTest1("run2").start();}下断点调试信息,可以看到run()方法当前线程是“main@1”

继续运行到run里面,当前线程仍然是“main@1”
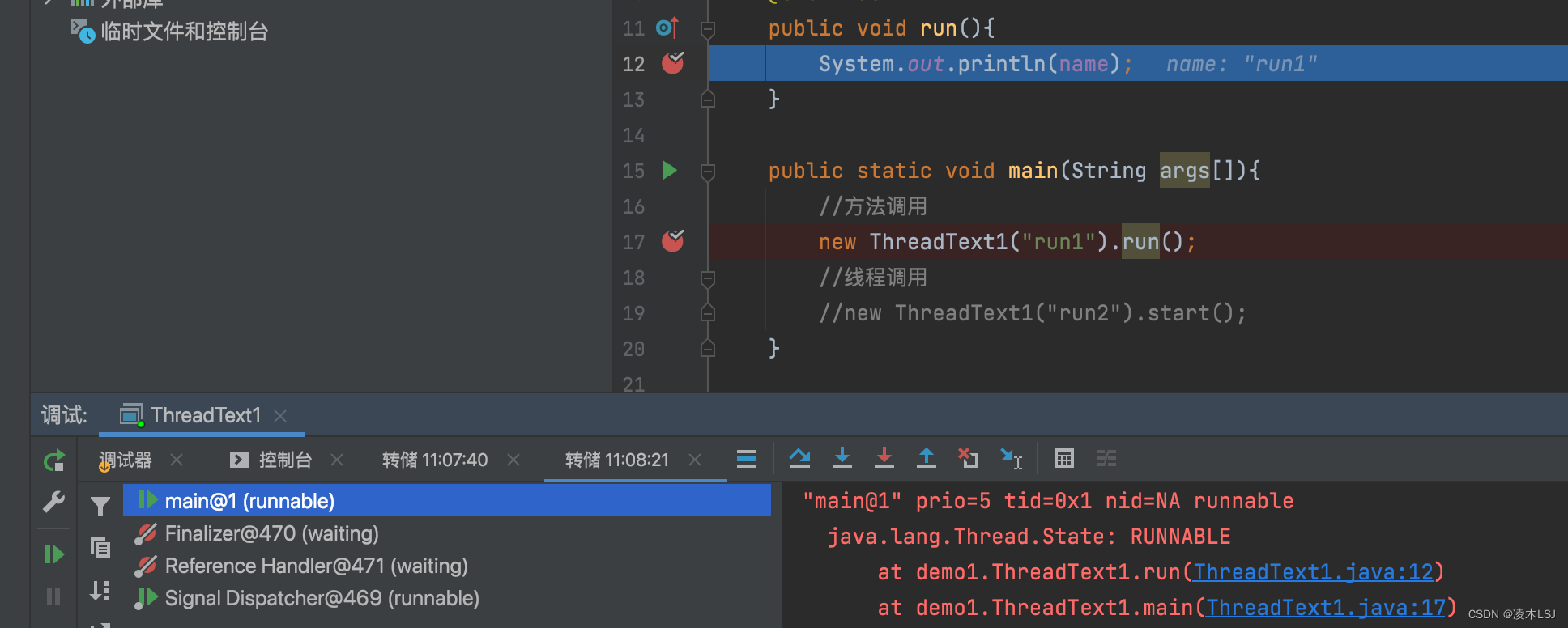
接下来看一下start()方法运行的线程结果,可以看到是两个线程



单线程的状态:
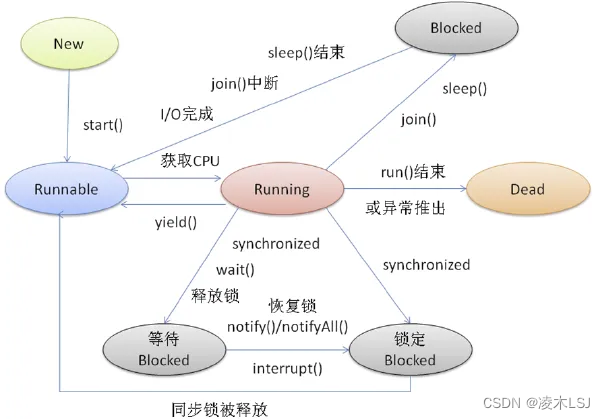
2 线程池
2.1 了解线程池
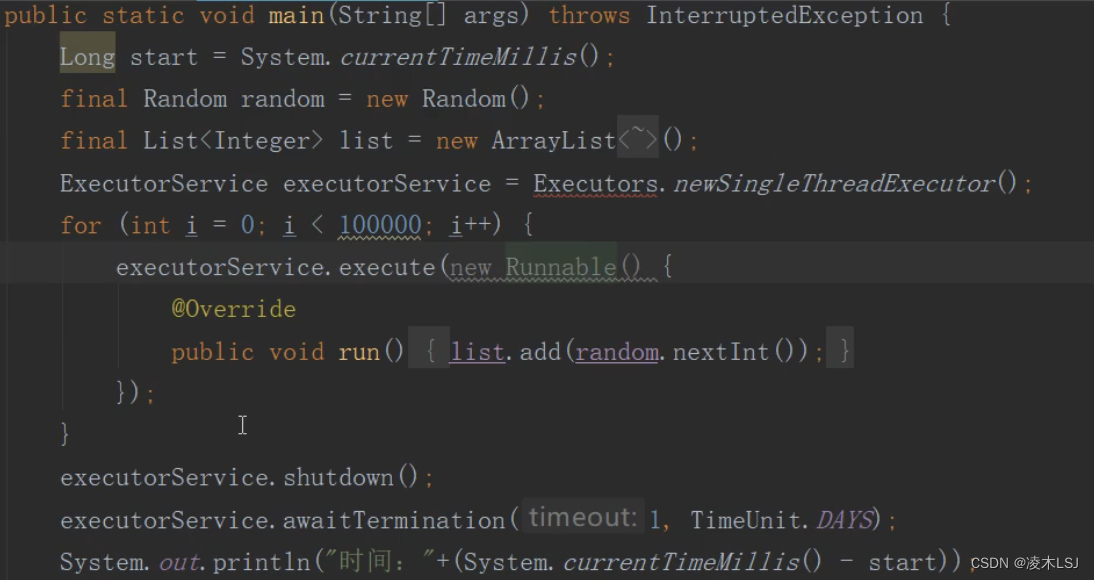
以线程的方式运行:

以线程池的方式运行,会发现线程池所需要的时间很短
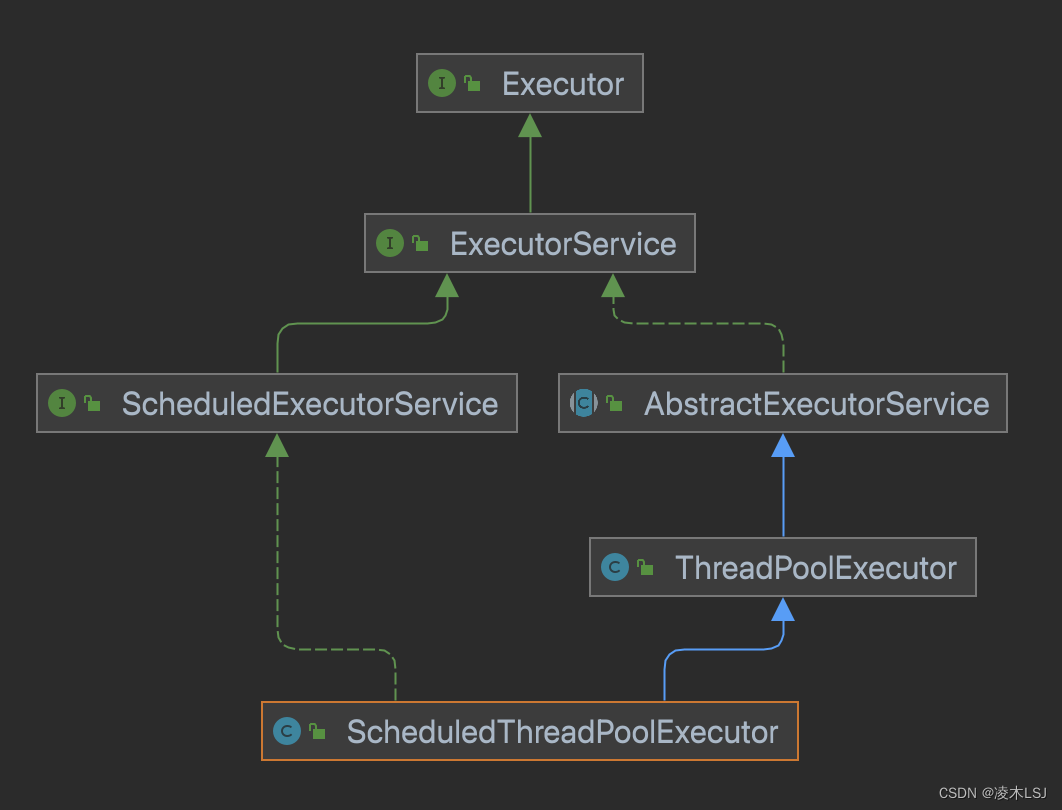
1)Executor框架
Executor框架是 Java5 之后引进的,在 Java 5 之后,通过 Executor 来启动线程比使用 Thread 的 start 方法更好。Executor 框架不仅包括了线程池的管理,还提供了线程工厂、队列以及拒绝策略等,Executor 框架让并发编程变得更加简单。
Executors如下:

Excuter主要有三大部分组成:
(1)任务:实现了Runnable接口或Callable接口的对象。Runnable任务不返回结果,而Callable任务可以返回结果。
(2)任务的执行(Excute,执行器):执行器是任务的执行引擎,它负责执行任务并管理任务的执行等。也就是把任务分派给多个线程的执行机制,包括Executor接口及继承自Executor接口的ExecutorService接口。
(3)异步计算的结果。包括Future接口及实现了Future接口的FutureTask类。
继续使用以下代码测试运行速度:
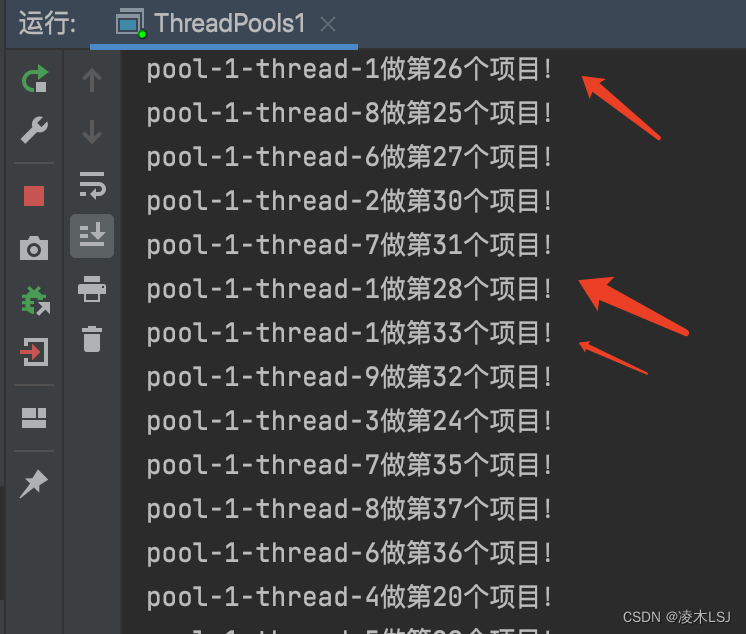
public class ThreadPools1 {public static void main(String args[]){ExecutorService executorService1 = Executors.newCachedThreadPool();ExecutorService executorService2 = Executors.newSingleThreadExecutor();ExecutorService executorService3 = Executors.newFixedThreadPool(10);for (int i=1; i <= 100; i++){executorService1.execute(new Mytask(i));}}
}class Mytask implements Runnable{int i = 0;public Mytask(int i){this.i = i;}@Overridepublic void run() {System.out.println(Thread.currentThread().getName() + "做第" + i + "个项目!");try{Thread.sleep(1000);}catch (Exception e){e.printStackTrace();}}
}Executors.newCachedThreadPool() 运行结果

去掉Thread.sleep(1000)后的运行结果:
1)newCachedThreadPool的底层主要是调用了ThreadPoolExecutor,传入的参数如下:

SynchronousQueue队列决定了每次只能一个进程完成任务后,在进行下一个
所以当执行任务时间很短时,会出现线程复用。
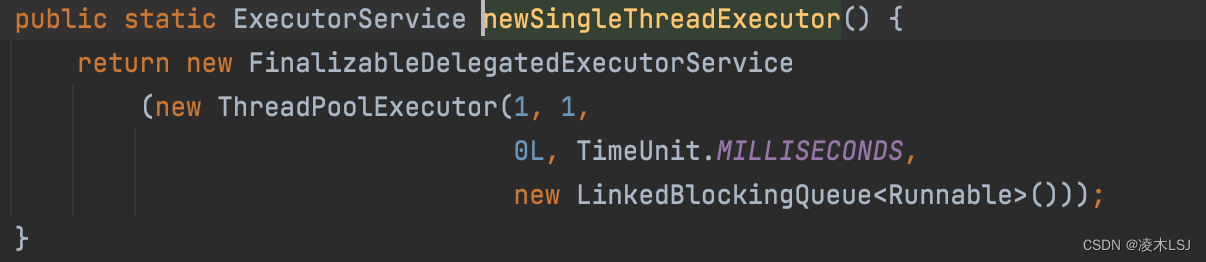
2)newSingleThreadExecutor传入的参数如下
3)newFixedThreadPool(10)传入的参数如下

底层都是ThreadPoolExecutor,所以接下来介绍一下ThreadPoolExecutor:
Java.util.concurrent.ThreadPoolExecutor 类就是 Java 对线程池的默认实现,开发中推荐使用ThreadPoolExecutor 而不是Excurors。
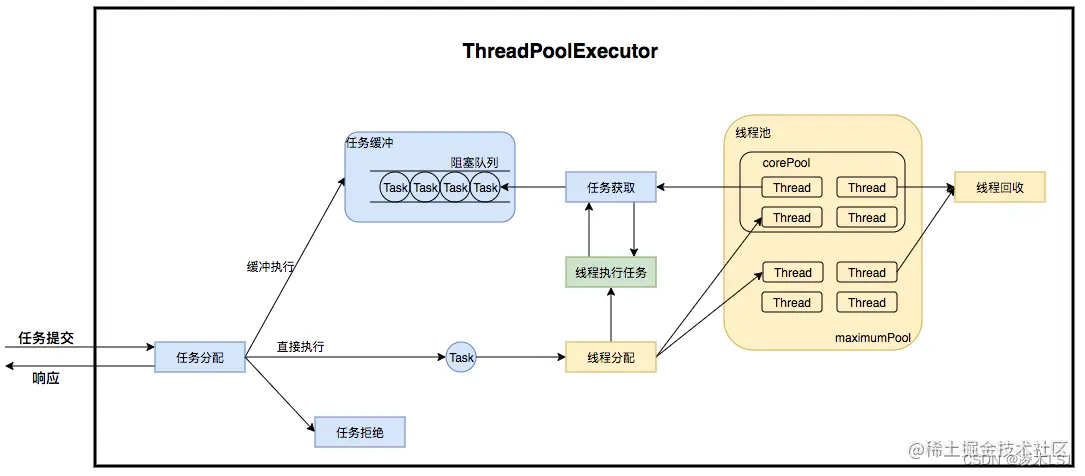
线程池的流程走向是受线程池的状态来决定的:
注意: ThreadPoolExecutor 就是通过将一个 32 位的 int 类型变量分割为两段,高 3 位用来表示线程池的当前生命周期状态,低 29 位就拿来表示线程池的当前线程数量,从而做到用一个变量值来维护两份数据,这个变量值就是 ctl。
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); //通过按位取反 + 按位与运算,将 c 的高3位保留,舍弃低29位,从而得到线程池状态private static int runStateOf(int c) { return c & ~CAPACITY; }//通过按位与运算,将 c 的高3位舍弃,保留低29位,从而得到工作线程数private static int workerCountOf(int c) { return c & CAPACITY; }
ThreadPoolExecutor的参数很多,
public ThreadPoolExecutor(
int corePoolSize, //线程池核心线程大小
int maximumPoolSize, //线程池最大线程数量
long keepAliveTime, //空闲线程存活时间
TimeUnit unit, //空间线程存活时间单位
BlockingQueue<Runnable> workQueue, //工作队列
ThreadFactory threadFactory, //线程工厂
RejectedExecutionHandler handler //拒绝工厂)
工作队列:
①ArrayBlockingQueue
基于数组的有界阻塞队列,按FIFO排序。当线程池中线程数量达到corePoolSize后,再有新任务进来,则会将任务放入该队列的队尾,等待被调度。如果队列已经是满的,则创建一个新线程,如果线程数量已经达到maxPoolSize,则会执行拒绝策略。
②LinkedBlockingQuene
基于链表的无界阻塞队列(其实最大容量为Interger.MAX),按照FIFO排序。、当线程池中线程数量达到corePoolSize后,再有新任务进来,会一直存入该队列,而不会去创建新线程直到maxPoolSize。
③SynchronousQuene
一个不缓存任务的阻塞队列,生产者放入一个任务必须等到消费者取出这个任务。也就是说新任务进来时,不会缓存,而是直接被调度执行该任务,如果没有可用线程,则创建新线程,如果线程数量达到maxPoolSize,则执行拒绝策略。
④PriorityBlockingQueue
具有优先级的无界阻塞队列,优先级通过参数Comparator实现。
2.2 推荐的使用方式
阿里不提倡使用Executors去创建线程池,推荐直接使用ThreadPoolExecutor去自定义线程,从而自动控制合理的参数。
1)执行优先级与提交执行优先级
执行优先级 : 核心线程>非核心线程>队列
提交优先级 : 核心线程>队列>非核心线程
- 核心线程:线程池中固定含有的线程数目。也就是ThreadPoolExecutor方法中corePoolSize参数设置的数值。
- 非核心线程:线程池中非固定含有的线程数目。如果ThreadPoolExecutor方法中maximumPoolSize参数的值大于corePoolSize则会有非核心线程出现,否则则没有。
- 工作队列:用来保存等待任务的队列。主要是通过ThreadPoolExecutor方法中workQueue参数来配置,workQueue有好几种队列模式,像是同步队列,非同步队列等等,这个是通过传参类型来判定。
2)执行方法execute

public void execute(Runnable command) {if (command == null)throw new NullPointerException();int c = ctl.get();if (workerCountOf(c) < corePoolSize) {if (addWorker(command, true))return;c = ctl.get();}if (isRunning(c) && workQueue.offer(command)) {int recheck = ctl.get();if (! isRunning(recheck) && remove(command))reject(command);else if (workerCountOf(recheck) == 0)addWorker(null, false);}else if (!addWorker(command, false))reject(command);}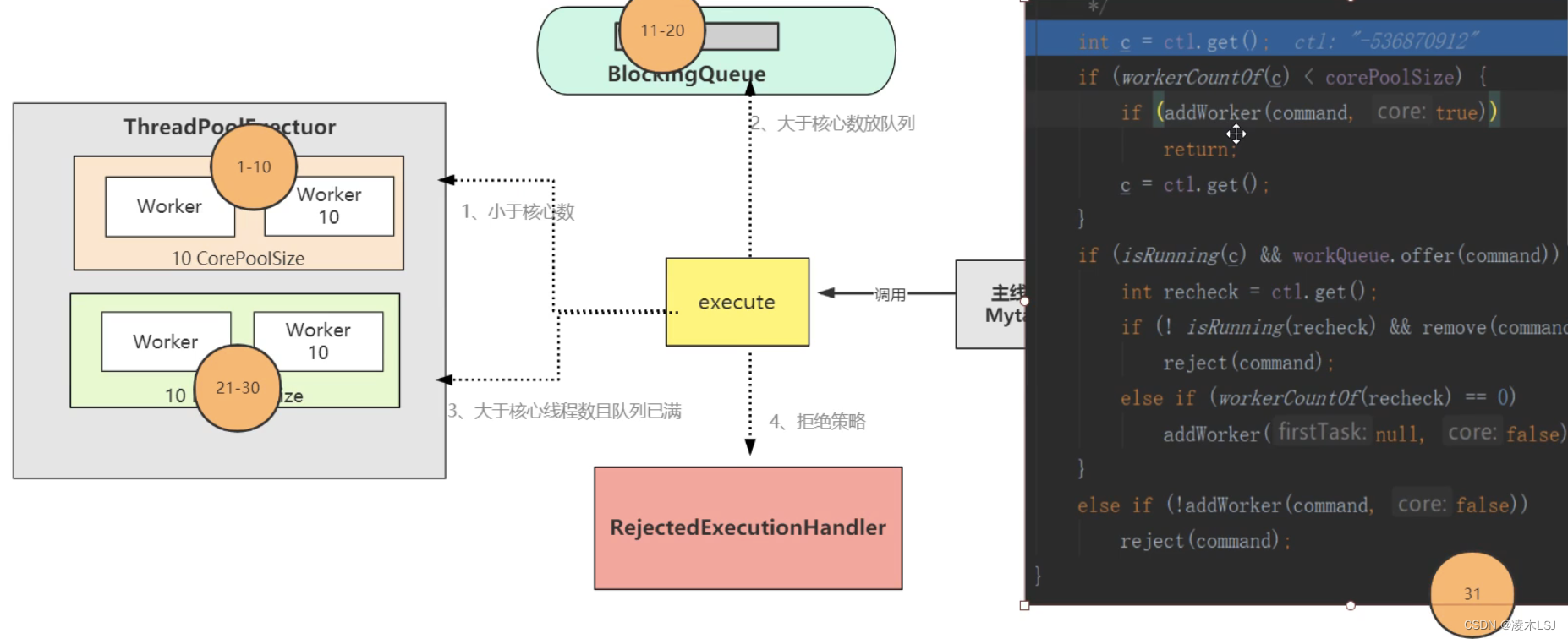
如果核心线程10个,最大线程数20,等待队列10,在执行30个线程的时候。
会先执行任务1-10,然后执行任务21-30,最后执行任务11-20.
首先任务1-10会直接给核心线程执行,核心线程满了之后,任务会被放到等待队列;等待队列满了(11-20);就会把任务放到非核心线程处并创建非核心线程(21-30),这样放到非核心线程处的任务反而先执行了。如果连非核心线程处也满了,就执行拒绝策略。
3)提交方法submit
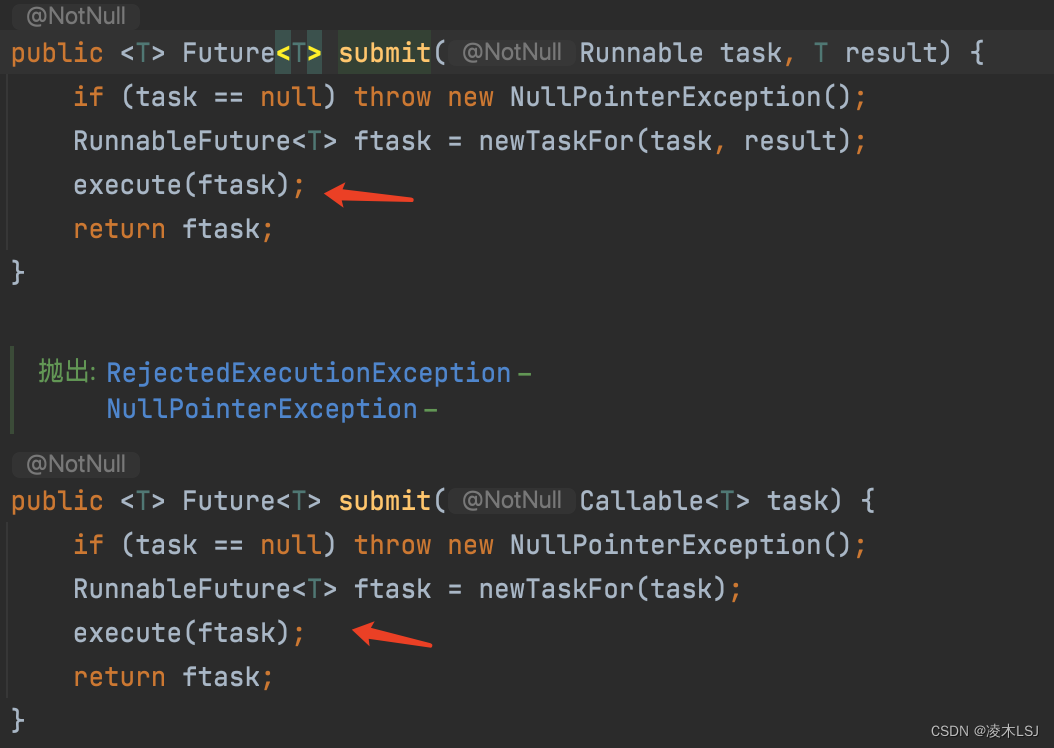

4)拒绝策略

| AbortPolicy | ThreadPoolExecutor 默认策略 直接抛出java.util.concurrent.RejectedExecutionException异常 |
| DiscardPolicy | 放弃当前任务,并且不会抛出任何异常 |
| DiscardOldestPolicy | 会将队列中最早添加的元素移除,再尝试添加,如果失败则按该策略不断重试 |
| CallerRunsPolicy | 由调用线程(提交任务的线程)处理该任务,如果调用线程是主线程,那么主线程会调用执行器中的execute方法来执行改任务 |
3 CPU多核并发
多核并发缓存架构

3.1 JMM内存模型
(JAVA多线程内存模型)

主内存
所有线程创建的实例对象都存放在内存中,不管该实例对象是成员变量,还是局部变量,类信息、常量、静态变量都是放在主内存中,属于所有线程共享区域,所以存在线程之间安全问题。
工作内存
主要是存储局部变量(存储着主内存中变量的副本),每个线程只能在自己的工作内存中操作变量副本,对其他线程是不可见的。就算两个线程同时执行同一段代码,也是都在自己的工作内存中对变量进行操作。由于线程的工作内存是私有,所以线程之间是不可见的,同时也是线程安全。
通过一个demo进行研究:

运行结果:

通过内存模型可以知道,线程1不一定知道initFlag的值已经改变。

3.2 volatile关键字
当然,如果想要可以打印success,需要使用volatile关键字:
![]()
volatile的实现原理:
1)MESI缓存一致性协议:多个cpu从主内存读取同一个数据到各自的高速缓存,当其中某个cpu修改了缓存里的数据,该数据会马上同步回主内存,其它cpu通过总线嗅探机制可以感知到数据的变化从而将自己缓存里的数据失效。
2)Volatile缓存可见性实现原理底层实现主要是通过汇编lock前缀指令,它会锁定这块内存区域的缓存并回写到主内存,此操作被称为“缓存锁定”,MESI缓存一致性协议机制会阻止同时修改被两个以上处理器缓存的内存区域数据。一个处理器的缓存值通过总线回写到内存会导致其他处理器相应的缓存失效。


3.3 原子操作
java内存模型定义了8种原子操作如下:
- read (读取) : 从主内存读取数据
- load(载入) :将主内存读取到的数据写入工作内存
- use(使用) : 从工作内存读取数据来计算
- assign (赋值) :将计算好的值重新赋值到工作内存中
- store (存储) : 将工作内存数据写入主内存
- write(写入) :将store过去的变量值赋值给主内存中的变量
- lock(锁定) :将主内存变量加锁,标识为线程独占状态
- unlock (解锁) :将主内存变量解锁,解锁后其他线程可以锁定该变量
并发编程三大特性:可见性,原子性,有序性。
Volatile保证可见性与有序性,但是不保证原子性;
synchronized 可以保证可见性,原子性,有序性。

最后运行结果 num < 10000
某一个CPU改变num值后,只有继续写入缓存,主内存,才会被其他CPU嗅探到。当多个CPU同时改变num值后,同时准备往主内存写,必然会出现先来后到问题,此时会产生影响。先写入主内存的被其他CPU嗅探后,会将其他CPU的值失效掉,其他CPU重新去读取主内存的值时,已经不是最开始的值了,而是被改过之后的值,从而数据不再准确。
synchronized 底层实际上通过JVM来实现的,同一时间只能有一个线程去执行synchronized 中的代码块,从而解决原子性问题。
3.4有序性与指令重排序
JMM内存模型具有先天的有序性,每个线程都有自己的工作内存。
通过一个代码示例来认识有序性:
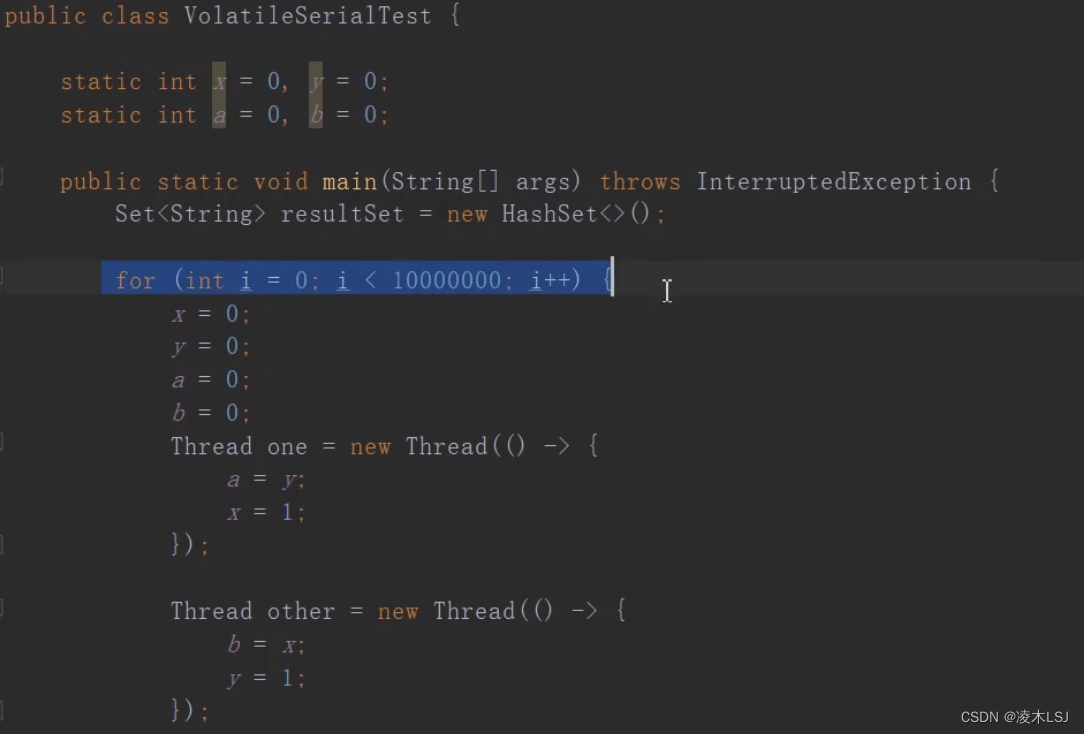

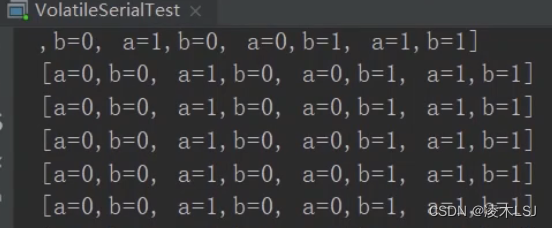
1)为什么a b同时为1了?(指令重排序)
指令重排序:在不影响单线程程序执行结果的前提下,计算机为了最大限度的发挥机器
性能,会对机器指令重排序优化。

第一阶段,编译器重排序,就是在编译过程中,编译器根据上下文分析对指令进行重排序,目的是减少CPU和内存的交互,重排序之后尽可能保证CPU从寄存器或缓存行中读取数据。
第二阶段,处理器重排序,处理器重排序分为两个部分。
- 并行指令集重排序,这是处理器优化的一种,处理器可以改变指令的执行顺序。
- 内存系统重排序,这是处理器引入Store Buffer缓冲区延时写入产生的指令执行顺序不一致的问题。
补充:
在处理器内核中一般会有多个执行单元,CPU在每个时钟周期内只能执行单条指令,也就是说只有一个执行单元在工作,其他执行单元处于空闲状态;在引入并行指令集之后,CPU在一个时钟周期内可以同时分配多条指令在不同的执行单元中执行。
通过提前执行其他可执行指令来填补CPU的时间空隙,然后在结束时重新排序运算结果,从而实现指令顺序执行的运行结果。
2)重排序遵循as-if-serial和happens-before原则
as-if-serial原则:
不管怎么重排序(编译器和处理器为了提高并行度), (单线程)程序的执行结果不能被改变[编译器、runtime和处理器都必须遵守as-if-serial语义。
为了遵守as-if-serial语义,编译器和处理器不会对存在数据依赖关系的操作做重排席,因为这种重排席会改变执行结果。但是,如果操作之间不存在数据依赖关系,这些操作就可能被编译器和处理器重排序。
happens-before原则:
1.程序顺序原则: 即在一个线程内必须保证语义串行性,也就是说按照代码顺序执行。
2.锁规则: 解锁(unlock)操作必然发生在后续的同一个锁的加锁(lok)之前,也就是说,如果对于一个锁解锁后,再加锁,那么加锁的动作必须在解锁动作之后(同一个锁)。
3.volatile规则: volatile变量的写,先发生于读,这保证了volatile变量的可见性,简单的理解就是,volatile变量在每次被线程访问时,都强迫从主内存中读该变量的值,而当该变量发生变化时,又会强迫将最新的值刷新到主内存,任何时刻,不同的线程总是能够看到该变量的最新值。
4.线程启动规则: 线程的stat()方法先于它的每一个动作,即如果线程A在执行线程B的start方法之前修改了共享变量的值,那么当线程B执行start方法时,线程A对共享变量的修改对线程B可见。
5.传递性: A先于B,B先于C 那么A必然先于C。
6,线程终止规则: 线程的所有操作先于线程的终结,Thread.oin()方法的作用是等待当前执行的线程终上。假设在线程B终止之前,修改了共享变量,线程A从线程B的ioin方法成功返回后,线程B对共享变量的修改将对线程A可见。
3.5 内存屏障
内存屏障就是Java语言与CPU的约定代码标志, 告诉CPU看到这种代码不要重排序,且此处代码前后需要严格的数据一致性。
JVM规范定义的内存屏障:

规定volatile需要添加内存屏障,看一下底层源码实现:



3.7 双重检测锁DLC
//单例模式 + private volatile static LazySingletonDCL lazySingleton = null;public static LazySingletonDCL getLazySingleton() {// 第⼀重检查是否为 nullif (lazySingleton == null) {// 使⽤ synchronized 加锁synchronized (LazySingletonDCL.class) {// 第二重检查是否为 nullif (lazySingleton == null) {lazySingleton = new LazySingletonDCL();}}}return lazySingleton;}两次⾮空判断,锁指的是 synchronized 加锁,为什么要进⾏双重判断,其实很简单,第⼀重判断,如果实例已经存在,那么就不再需要进⾏同步操作,⽽是直接返回这个实例,如果没有创建,才会进⼊同步块,同步块的⽬的与之前相同,⽬的是为了防⽌有多个线程同时调⽤时,导致⽣成多个实例,有了同步块,每次只能有⼀个线程调⽤访问同步块内容,当第⼀个抢到锁的调⽤获取了实例之后,这个实例就会被创建,之后的所有调⽤都不会进⼊同步块,直接在第⼀重判断就返回单例。
4 JAVA锁机制


4.1 synchronized 同步锁
1)对象锁
非静态方法使用 synchronized 修饰的写法,修饰实例方法时,锁定的是当前对象:
public synchronized void test(){// TODO}//等同于public void test(){synchronized (this) {// TODO}}某个线程得到了对象锁之后,该对象的其他同步方法是锁定的,其他线程是无法访问的。
2)类锁
类锁需要 synchronized 来修饰静态 static 方法:
public static synchronized void test(){// TODO}//等同于public static void test(){synchronized (TestSynchronized.class) {// TODO}}类锁和对象锁其实是一样的,由于静态方法是类所有对象共用的,所以进行同步后,该静态方法的锁也是所有对象唯一的。每次只能有一个线程来访问对象的该非静态同步方法。
4.2 CAS(比较并交换)
volatile值有可见性和禁止指令重拍(有序性),无法保证原子性。jdk1.5后产生了CAS利用CPU原语(不可分割,连续不中断)保证现场操作原子性。
Java 提供常用的原子操作类有:
- 基本类型:AtomicBoolean,AtomicInteger,AtomicLong;
- 引用类型:AtomicReference,AtomicMarkableReference,AtomicStampedReference;
- 数组类型:AtomicIntegerArray,AtomicLongArray,AtomicReferenceArray;
- 字段类型:AtomicReferenceFieldUpdater,AtomicIntegerFieldUpdater,AtomicLongFieldUpdater。

AtomicInteger.incrementAndGet()就是CAS机制的实现,比较并交换,实现逻辑如下:

CAS的原理:CAS算法有三个操作数,通过内存中的值(V)、预期原始值(A)、修改后的新值。
(1)如果内存中的值和预期原始值相等, 就将修改后的新值保存到内存中。
(2)如果内存中的值和预期原始值不相等,说明共享数据已经被修改,放弃已经所做的操作,然后重新执行刚才的操作,直到重试成功。



对比两个锁:
(1)synchronized(悲观锁,影响其他线程)

(2)cas(乐观锁,不阻塞其他线程)

ABA问题就是进程1将A值改成B值,然后在进行比较并交换之前,进程2将A值改成C值又改回A值,那么进程1进行比较并交换是可以成功的,最终结果是正常的,但其实进程2也做操作了。
可以使用Version思维进行解决,每一次获取原来的值都附一个版本号进行标识。从Java1.5开始JDK的atomic包里提供了一个类AtomicStampedReference来解决ABA问题。这个类的compareAndSet方法作用是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如 全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
三个引用类型:
- AtomicReference 不保证 ABA 问题;
- AtomicMarkableReference 可以解决 ABA 问题,它会记录原数据是否被更新过;
- AtomicStampedReference 也可以解决 ABA 问题,它不仅会记录原数据是否被更新过,还能记录被更新过多少次。
注意:CAS使用的时机
线程数较少、等待时间短可以采用自旋锁进行CAS尝试拿锁,较于synchronized高效。
4.3 偏向锁
在Java SE 1.6中,锁一共有4种状态,级别从低到高依次是:无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态。
核心原理
- 如果不存在线程竞争的一个线程获得了锁,那么锁就进入偏向状态, 此时 Mark Word 的结构变为偏向锁结构:锁对象的锁标志位(lock)被改为 01,偏向标志位 (biased_lock)被改为 1,然后线程的 ID 记录在锁对象的 Mark Word 中(使用 CAS 操作完成)。
- 以后该线程获取锁的时,判断一下线程 ID 和标志位,就可以直接进入同步块,连 CAS 操作都不需要,这样就省去了大量有关锁申请的操作,从而也就提供程序的性能。
补充:
HotSpot中,Java的对象内存模型分为三部分,分别为对象头、实例数据和对齐填充。而对象头中分为两部分,一部分是“Mark Word”(存储对象自身的运行时数据,32bit或64bit,可复用);另一部分是指向它的类的元数据指针。
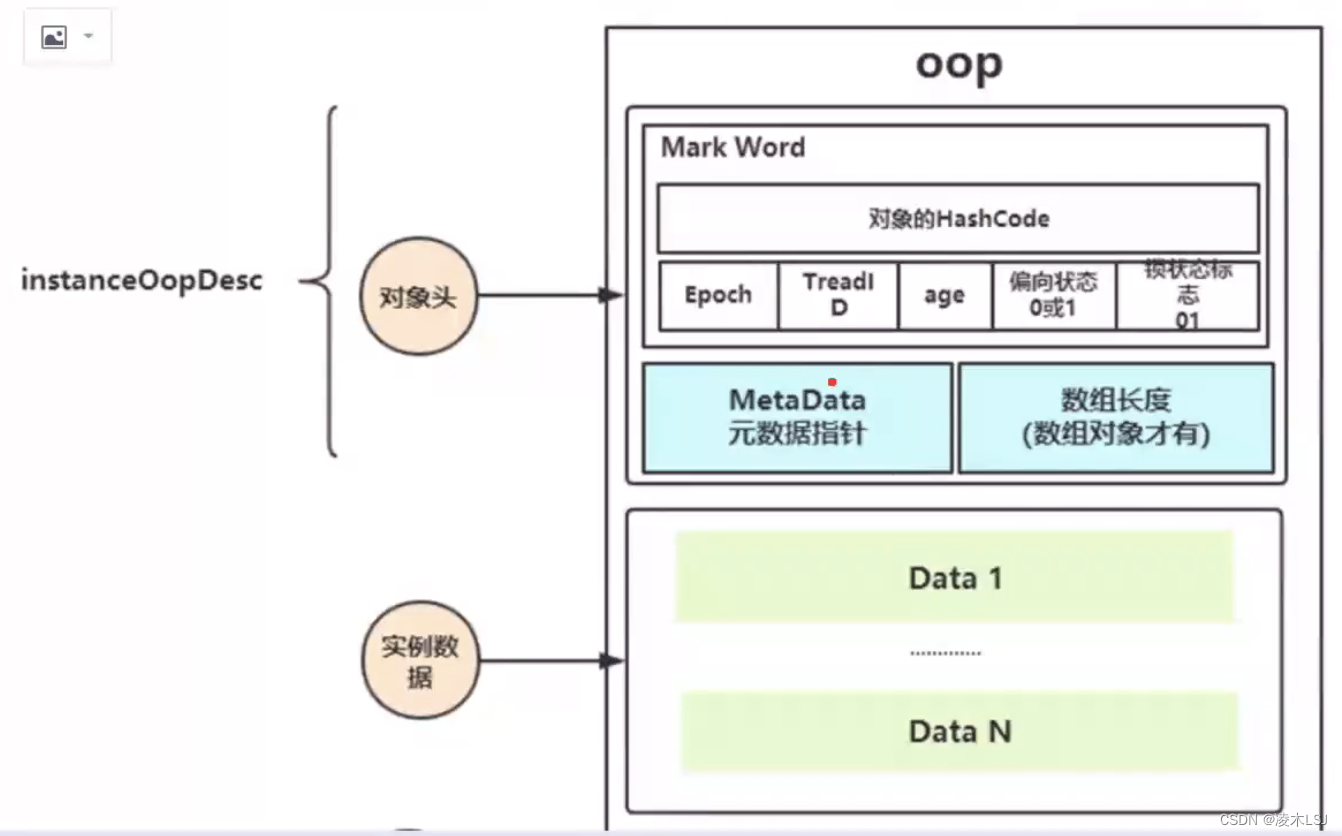
因为synchronized是Java对象的内置锁,所以其优化策略(即偏向锁等)的信息都包含在Mark Word中:


偏向锁膨胀:




看一下打印结果:
1)偏向锁

2)释放偏向锁
Mark Word头中标记不变,(偏向这个线程)如果同线程再来启用这部分代码块,只需判断线程ID是否是同一个,然后进行偏向。

3)轻量级锁

4)重量级锁

过程总结:
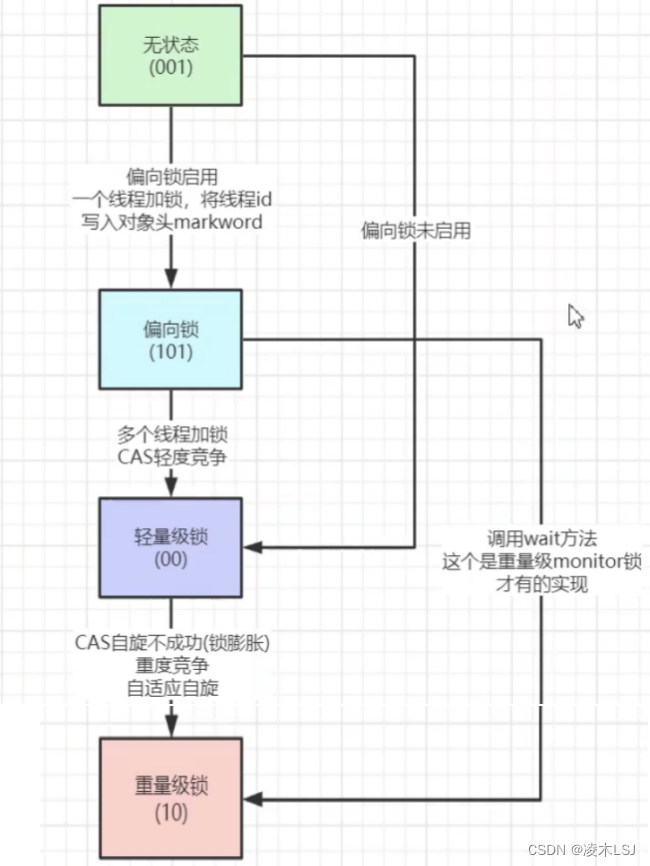
轻量级锁:
线程在执行同步块之前,JVM会先在当前线程的栈桢中创建用于存储锁记录的空间,并将对象头中的Mark Word复制到锁记录中。然后线程尝试使用CAS将对象头中的Mark Word替换为指向锁记录的指针。如果成功,当前线程获得锁,如果失败,表示其他线程竞争锁,当前线程便尝试使用自旋来获取锁。
重量级锁:
重量级锁是依赖对象内部的monitor锁来实现。当系统检查到锁是重量级锁之后,会把等待想要获得锁的线程进行阻塞,被阻塞的线程不会消耗cup。但是阻塞或者唤醒一个线程时,都需要操作系统来帮忙,需要从用户态转换到内核态,而转换状态是需要消耗很多时间。

4.4 AQS机制
场景:有四个线程由于业务需求需要同时占用某资源,但该资源在同一个时刻只能被其中唯一线程所独占。那么此时应该如何标识该资源已经被独占,同时剩余无法获取该资源的线程又该何去何从呢?
AQS (AbstractQueuedSynchronizer)是一个集同步状态管理、线程阻塞、线程释放及队列管理功能与一身的同步框架。其核心思想是当多个线程竞争资源时会将未成功竞争到资源的线程构造为 Node 节点放置到一个双向 FIFO 队列中。被放入到该队列中的线程会保持阻塞直至被前驱节点唤醒。
1)同步状态
private volatile int state;
查看AQS源码可以知道,当 state 值为 1 的时候表示当前锁已经被某线程占用,除非等占用的锁的线程释放锁后将 state 置为 0,否则其它线程无法获取该锁。这里的 state 变量用 volatile 关键字保证其在多线程之间的可见性。
2)队列

Node类:

waitStatus:当前节点状态,该字段共有5种取值:
CANCELLED = 1。节点引用线程由于等待超时或被打断时的状态。SIGNAL = -1。后继节点线程需要被唤醒时的当前节点状态。当队列中加入后继节点被挂起(block)时,其前驱节点会被设置为SIGNAL状态,表示该节点需要被唤醒。CONDITION = -2。当节点线程进入condition队列时的状态。(见ConditionObject)PROPAGATE = -3。仅在释放共享锁releaseShared时对头节点使用。(见共享锁分析)0。节点初始化时的状态。
3)资源竞争策略
public final void acquire(int arg) {if (!tryAcquire(arg) &&acquireQueued(addWaiter(Node.EXCLUSIVE), arg))selfInterrupt();
}acquire核心为tryAcquire、addWaiter和acquireQueued三个函数,其中tryAcquire需具体类实现。 每当线程调用acquire时都首先会调用tryAcquire,失败后才会挂载到队列,因此acquire实现默认为非公平锁。
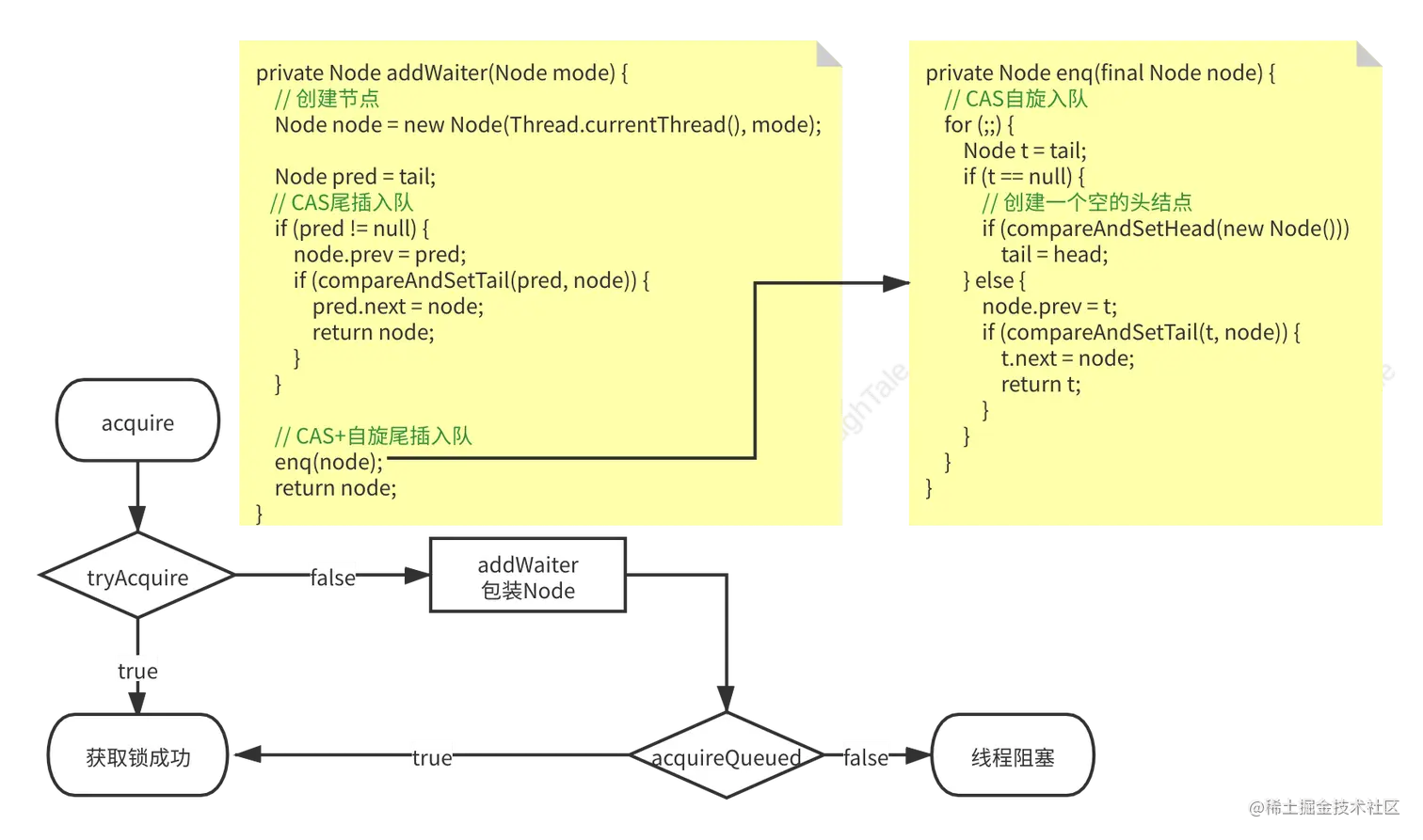
- addWaiter将线程包装为独占节点,尾插式加入到队列中,如队列为空,则会添加一个空的头节点。值得注意的是addWaiter中的enq方法,通过CAS+自旋的方式处理尾节点添加冲突。
- acquireQueue在线程节点加入队列后判断是否可再次尝试获取资源,如不能获取则将其前驱节点标志为SIGNAL状态(表示其需要被unpark唤醒)后,则通过park进入阻塞状态。
4)资源释放
release流程较为简单,尝试释放成功后,即从头结点开始唤醒其后继节点,如后继节点被取消,则转为从尾部开始找阻塞的节点将其唤醒。阻塞节点被唤醒后,即进入acquireQueued中的for(;;)循环开始新一轮的资源竞争。

相关文章:
Java 多线程进阶
1 方法执行与进程执行 GetMapping("/demo1")public void demo1(){//方法调用new ThreadTest1("run1").run();//线程调用new ThreadTest1("run2").start();} 下断点调试信息,可以看到run()方法当前线程是“main1” 继续运行到run里面&…...

CentOS上搭建SVN并自动同步至web目录
一、搭建svn环境并创建仓库: 1、安装Subversion: yum install svn2、创建版本库: //先建目录 cd /www mkdir wwwsvn cd wwwsvn //创建版本库 svnadmin create xiangmumingcheng二、创建用户组及用户: 1、 进入版本库中的配…...
.Net中Redis的基本使用
前言 Redis可以用来存储、缓存和消息传递。它具有高性能、持久化、高可用性、扩展性和灵活性等特点,尤其适用于处理高并发业务和大量数据量的系统,它支持多种数据结构,如字符串、哈希表、列表、集合、有序集合等。 Redis的使用 安装包Ser…...
使用cli批量下载GitHub仓库中所有的release
文章目录 1\. 引言2\. 工具官网3\. 官方教程4\. 测试用的网址5\. 安装5.1. 使用winget安装5.2. 查看gh是否安装成功了 6\. 使用6.1. 进行GitHub授权6.1.1. 授权6.1.2. 授权成功6.2 查看指定仓库中的所有版本的release6.2.1. 默认的30个版本6.2.2. 自定义的100个版本6.3 下载特定…...
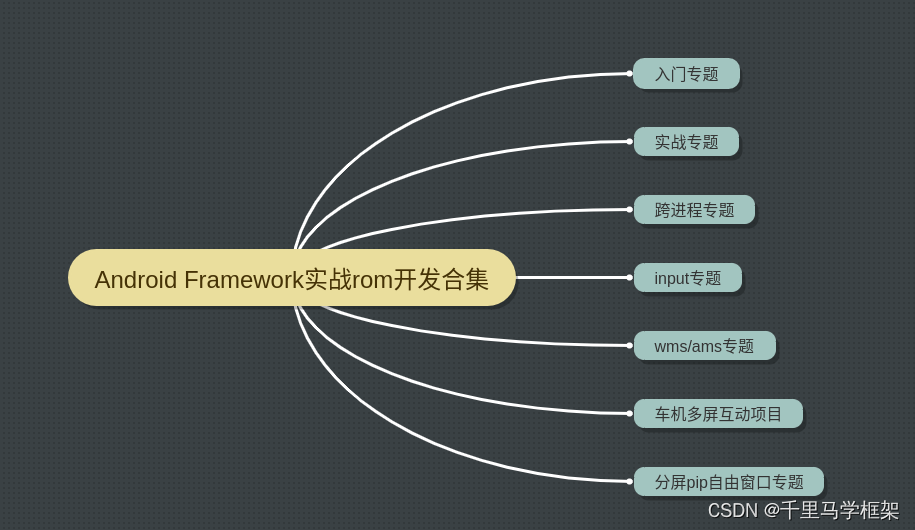
深入分析TaskView源码之触摸相关
问题背景 hi,粉丝朋友们: 大家好!android 10以后TaskView作为替代ActivityView的容器,在课程的分屏pip自由窗口专题也进行了相关的详细介绍分析。 这里再补充一下相关的TaskView和桌面内嵌情况下的触摸分析 主要问题点ÿ…...
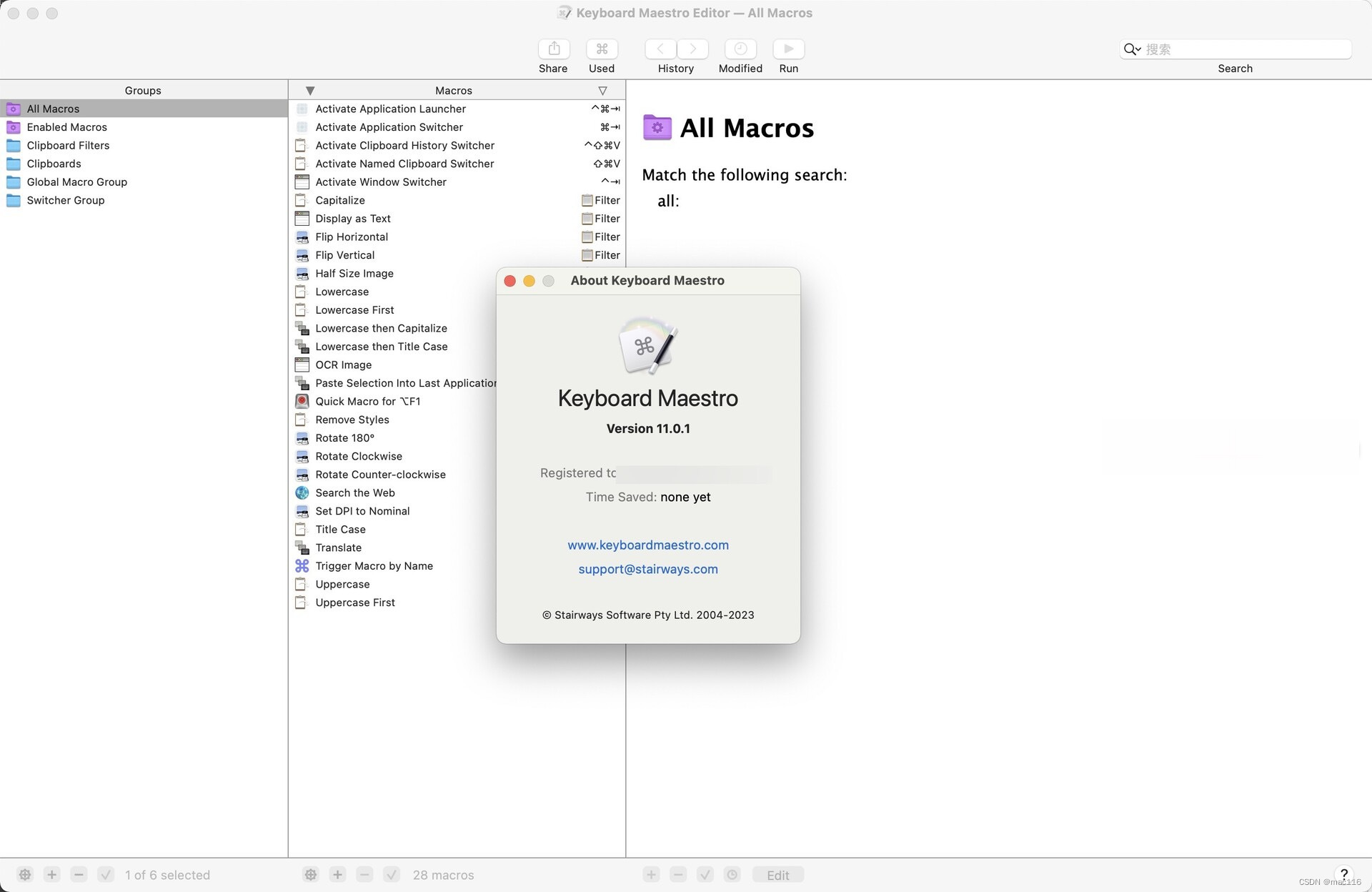
键盘快捷键工具Keyboard Maestro mac中文版介绍
Keyboard Maestro mac是一款键盘快捷键工具,它可以帮助用户通过自定义快捷键来快速完成各种操作,提高工作效率。Keyboard Maestro支持多种快捷键组合,包括单键、双键、三键、四键组合等,用户可以根据自己的习惯进行设置。此外&…...
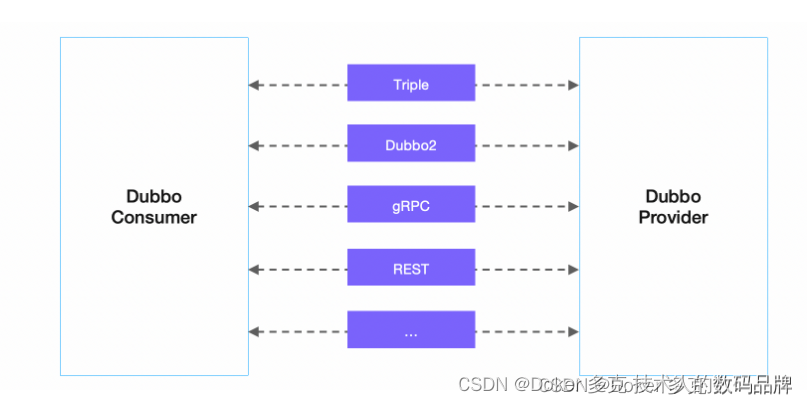
Dubbo开发系列
一、概述 以上是 Dubbo 的工作原理图,从抽象架构上分为两层:服务治理抽象控制面 和 Dubbo 数据面 。 服务治理控制面。服务治理控制面不是特指如注册中心类的单个具体组件,而是对 Dubbo 治理体系的抽象表达。控制面包含协调服务发现的注册中…...
)
周赛372(正难则反、枚举+贪心、异或位运算、离线+单调栈)
文章目录 周赛372[2937. 使三个字符串相等](https://leetcode.cn/problems/make-three-strings-equal/)模拟(正难则反) [2938. 区分黑球与白球](https://leetcode.cn/problems/separate-black-and-white-balls/)枚举 贪心 [2939. 最大异或乘积](https:/…...
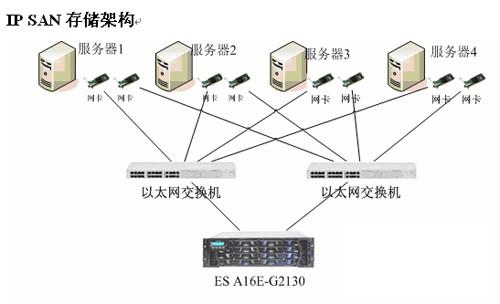
存储区域网络(SAN)之FC-SAN和IP-SAN的比较
存储区域网络(Storage Area Network,SAN)用于将多个系统连接到存储设备和子系统。 早期FC-SAN: 采用光纤通道(Fibre Channel,FC)技术,通过光纤通道交换机连接存储阵列和服务器主机,建立专用于数据存储的区域网络。 传…...

Leetcode_45:跳跃游戏 II
题目描述: 给定一个长度为 n 的 0 索引整数数组 nums。初始位置为 nums[0]。 每个元素 nums[i] 表示从索引 i 向前跳转的最大长度。换句话说,如果你在 nums[i] 处,你可以跳转到任意 nums[i j] 处: 0 < j < nums[i] i j < n 返…...

给新手教师的成长建议
随着教育的不断发展和进步,越来越多的新人加入到教师这个行列中来。从学生到教师,这是一个华丽的转身,需要我们不断地学习和成长。作为一名新手老师,如何才能快速成长呢?以下是一名老师教师给的几点建议: 一…...

新手教师如何迅速成长
对于许多新手教师来说,迈出教学的第一步可能会感到非常困难。不过,通过一些关键的策略和技巧,还是可以快速提升教学能力的,我将为大家提供一些实用的建议,帮助各位在教育领域迅速成长。 深入了解学科知识 作为一名老师…...
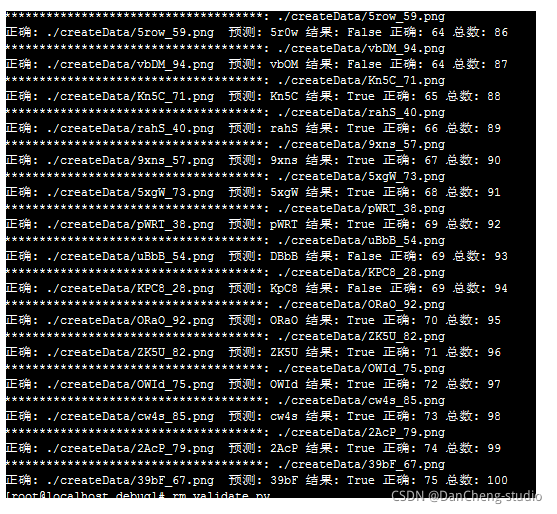
竞赛选题 深度学习验证码识别 - 机器视觉 python opencv
文章目录 0 前言1 项目简介2 验证码识别步骤2.1 灰度处理&二值化2.2 去除边框2.3 图像降噪2.4 字符切割2.5 识别 3 基于tensorflow的验证码识别3.1 数据集3.2 基于tf的神经网络训练代码 4 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 &#x…...
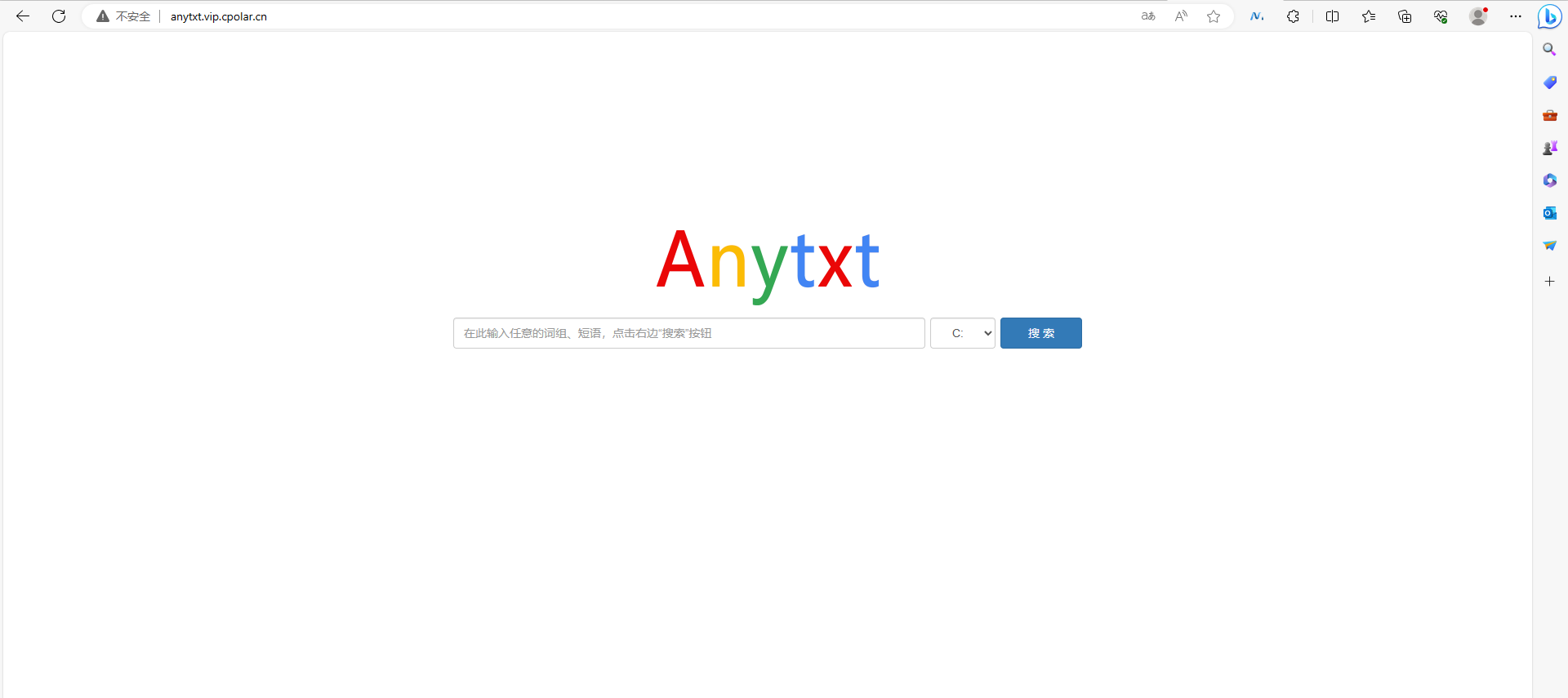
提升工作效率,使用AnyTXT Searcher实现远程办公速查公司电脑文件——“cpolar内网穿透”
文章目录 前言1. AnyTXT Searcher1.1 下载安装AnyTXT Searcher 2. 下载安装注册cpolar3. AnyTXT Searcher设置和操作3.1 AnyTXT结合cpolar—公网访问搜索神器3.2 公网访问测试 4. 固定连接公网地址 前言 你是否遇到过这种情况,异地办公或者不在公司,想找…...

mybatis使用foreach标签实现union集合操作
最近遇到一个场景就是Java开发中,需要循环多个表名,然后用同样的查询操作分别查表,最终得到N个表中查询的结果集合。在查询内容不一致时Java中跨表查询常用的是遍历表名集合循环查库,比较耗费资源,效率较低。在查询内容…...

请问DasViewer是否支持与业务系统集成,将业务的动态的数据实时的展示到三维模型上?
答:一般这种是以平台的方式来展示,云端地球实景三维建模云平台是专门做这一块的,可前往云端地球官网免费使用。 DasViewer是由大势智慧自主研发的免费的实景三维模型浏览器,采用多细节层次模型逐步自适应加载技术,让用户在极低的电脑配置下,…...

[ruby on rails]rack-cors, rack-attack
gem rack-attack gem rack-cors1. rack-attack 可以根据ip、域名等设置黑名单、设置访问频率 设置黑名单 # 新增 config/initializers/rack_attack.rb # 请求referer如果匹配不上设置的allowed_origins,返回403 forbidden Rack::Attack.blocklist(block bad domai…...
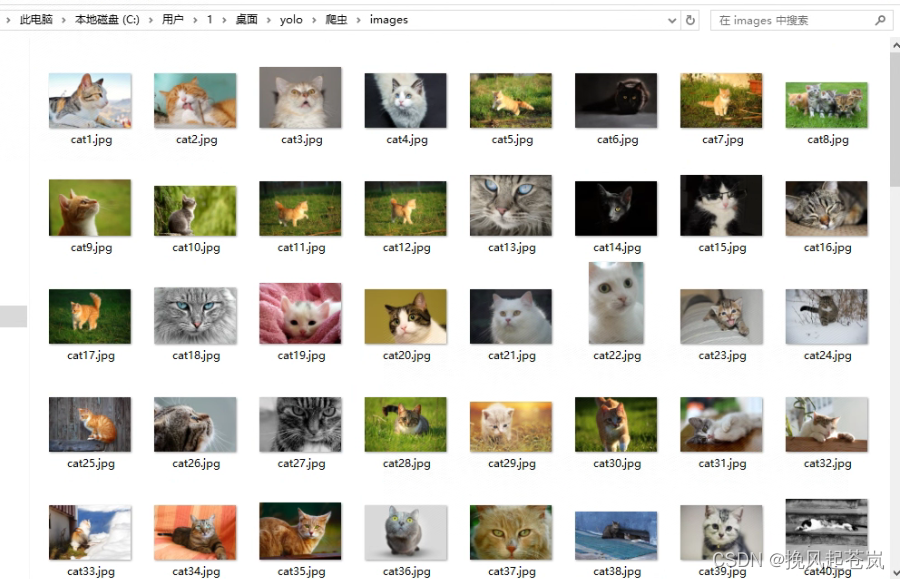
猫12分类:使用多线程爬取图片的Python程序
本文目标 对于猫12目标检测部分的数据集,采用网络爬虫来制作数据集。 在网络爬虫中,经常需要下载大量的图片。为了提高下载效率,可以使用多线程来并发地下载图片。本文将介绍如何使用Python编写一个多线程爬虫程序,用于爬取图片…...

《深度学习500问》外链笔记
1.这个是什么意思...

机器学习技术栈—— 概率学基础
机器学习技术栈—— 概率学基础 先验概率、后验概率、似然概率总体标准差和样本标准差 先验概率、后验概率、似然概率 首先 p ( w ∣ X ) p ( X ∣ w ) ∗ p ( w ) p ( X ) p(w|X) \frac{ p(X|w)*p(w)}{p(X)} p(w∣X)p(X)p(X∣w)∗p(w) 也就有 p ( w ∣ X ) ∝ p ( X ∣ …...
)
【仅限首批2000名开发者】:获取奇点大会AI原生CR沙箱环境访问权+5套企业级审查策略模板(含金融/车规/医疗三类合规预置包)
更多请点击: https://intelliparadigm.com 第一章:AI原生代码审查:2026奇点智能技术大会Code Review新范式 在2026奇点智能技术大会上,AI原生代码审查(AI-Native Code Review)正式取代传统人工规则引擎混合…...

想找升降货梯维修厂家电话?泰州群利起重设备有限公司告诉你!
在工业生产和物流运输中,升降货梯是不可或缺的设备。然而,长期使用后,升降货梯难免会出现各种故障,这时候就需要专业的维修厂家来解决问题。那么,如何找到靠谱的升降货梯维修厂家呢?泰州群利起重设备有限公…...

为LLM注入联网能力:SuGPT-kexue项目的架构设计与工程实践
1. 项目概述与核心价值最近在开源社区里,一个名为“SuGPT-kexue”的项目引起了不少开发者和AI爱好者的注意。这个项目名本身就挺有意思,它指向了一个非常具体且实用的场景:如何让一个大型语言模型(LLM)具备科学上网的能…...

FortiWeb VM 6.3.4初体验:除了当防火墙,还能怎么玩?
FortiWeb VM 6.3.4进阶玩法:解锁WAF的隐藏技能树 当大多数人还在把Web应用防火墙(WAF)当作简单的流量过滤工具时,你已经可以把它变成安全实验室的瑞士军刀。FortiWeb VM 6.3.4这个220MB的虚拟机镜像里,藏着比基础防护更有趣的可能性——从自动…...

Go+Lua构建可编程代理服务器hplan:从原理到实战应用
1. 项目概述与核心价值 最近在折腾个人服务器和家庭网络时,我一直在寻找一个能帮我高效管理、监控和自动化处理网络请求的工具。市面上成熟的方案很多,但要么太重,要么不够灵活,要么就是配置起来让人头大。直到我遇到了 Noirewi…...

AI编程助手变身色彩专家:meodai/skill.color-expert技能库深度解析
1. 项目概述:一个为AI编程助手打造的“色彩科学专家”技能库如果你和我一样,经常在开发与色彩相关的工具、设计系统,或者向团队解释复杂的色彩理论时,需要反复查阅资料,那你一定会理解那种“知识碎片化”的痛苦。你可能…...

Docker工具箱镜像构建:Alpine集成开发调试工具链实战
1. 项目概述:一个为开发者定制的“瑞士军刀”式Docker镜像在开发与运维的日常工作中,我们常常会遇到一些高频但琐碎的任务:需要快速验证一个API接口、临时搭建一个测试环境、或者只是想在一个干净的环境里跑一段脚本。每次都要从零开始安装依…...

AI Workspace:统一管理团队AI编程工具配置与技能的工程实践
1. 项目概述:AI Workspace 是什么,以及它解决了什么问题如果你和你的团队已经开始在日常开发中大量使用 Cursor、Claude Code、GitHub Copilot 这类 AI 编程工具,那你一定遇到过下面这些让人头疼的场景:你在一个前端项目里&#x…...

5分钟彻底告别乱码!GBKtoUTF-8编码转换终极指南
5分钟彻底告别乱码!GBKtoUTF-8编码转换终极指南 【免费下载链接】GBKtoUTF-8 To transcode text files from GBK to UTF-8 项目地址: https://gitcode.com/gh_mirrors/gb/GBKtoUTF-8 还在为Windows和Mac之间文件传输乱码而烦恼吗?GBKtoUTF-8编码转…...

跨平台文件共享实战:从中标麒麟OS无缝访问Win10 SMB共享
1. 为什么需要跨平台文件共享? 在日常办公环境中,经常会遇到不同操作系统之间需要共享文件的情况。比如财务部门使用中标麒麟OS处理敏感数据,而市场部同事用的却是Windows 10系统。这时候如果要用U盘来回拷贝文件,不仅效率低下&am…...