基于Bagging集成学习方法的情绪分类预测模型研究(文末送书)

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
2.数据集介绍
3.技术工具
4.实验过程
4.1导入数据
4.2数据预处理
4.3分词处理
4.4词云可视化
4.5构建语料库
4.6词向量化
4.7构建模型
4.8模型评估
4.9模型测试
5.总结
文末推荐与福利
1.项目背景
随着社交媒体和在线平台的普及,大量用户生成的文本数据不断涌现,其中包含了丰富的情感信息。情感分类是自然语言处理(NLP)领域中的一个重要任务,它旨在自动识别和分析文本中蕴含的情感倾向,如积极、消极或中性等。情感分类在社交媒体舆情分析、产品评论分析、用户反馈分析等领域具有广泛的应用。
然而,由于文本数据的复杂性和多样性,单一的分类器可能无法充分捕捉数据的多样性和复杂性。为了提高情感分类的准确性和稳定性,集成学习成为一种常用的方法。Bagging(Bootstrap Aggregating)是集成学习的一种经典方法,它通过训练多个基分类器并对它们的输出进行组合,从而减少模型的过拟合风险,提高整体性能。
本研究旨在探讨基于Bagging集成学习方法的情感分类预测模型。通过结合多个基分类器的输出,我们可以期望获得更为鲁棒和泛化能力强的情感分类模型,从而更好地适应不同领域和文本类型的情感分析任务。此外,通过采用Bootstrap采样技术,Bagging还能够有效减少过拟合的风险,提高模型的稳定性。
在实验中,我们将选择合适的基分类器,并通过Bagging方法进行组合,比较其性能与单一分类器的差异。通过深入研究基于Bagging的情感分类模型,我们旨在为情感分析领域的研究和应用提供新的思路和方法,从而更好地应对大规模文本数据的情感分类问题。
2.数据集介绍
本数据集来源于Kaggle,原始数据集共有5937条,2个特征变量,一个是评论内容,一个是情绪标签。

3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.实验过程
4.1导入数据
首先导入常用的一些数据分析的第三方库并加载数据集
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')data=pd.read_csv("Emotion_classify_Data.csv")
data.head()
查看数据大小

4.2数据预处理
首先查看数据集是否存在缺失值和重复值

从结果可以发现,原始数据集中并不存在缺失数据和重复数据。
接着对情绪标签变量进行编码处理
# 使用LabelEncoder编码目标列
from sklearn.preprocessing import LabelEncoder
encoder=LabelEncoder()
data["Emotion"]=encoder.fit_transform(data["Emotion"])
data.head()
类以这种形式编码:-如果Emotion=0表示“愤怒”,如果Emotion=1表示“恐惧”,如果Emotion=2表示“快乐”。
pie_labels=data["Emotion"].value_counts().index
pie_values=data["Emotion"].value_counts().values
plt.pie(pie_values,labels=pie_labels,autopct="%1.1f%%")
plt.show()
可以发现数据是平衡的
4.3分词处理
Punkt句子分词器
Punkt tokenizer通过使用无监督算法为缩写词、搭配和句子开头词构建模型,将文本划分为句子列表。
import nltk
nltk.download("punkt")
加载停用词
nltk.download("stopwords")
from nltk.corpus import stopwords
stopwords.words("english")
词干提取
# 测试词干提取
from nltk.stem.porter import PorterStemmer
stemmer=PorterStemmer()
stemmer.stem("playing") # 测试它是否有效![]()
# 预处理数据的函数
def transformed_text(Comment):# 将文本转换为小写Comment = Comment.lower()# 标记文本words = nltk.word_tokenize(Comment)# 初始化Porter Stemmerstemmer = PorterStemmer()# 删除英语停词并应用词干提取,同时忽略特殊符号filtered_words = [stemmer.stem(word) for word in words if word not in stopwords.words('english') and word.isalnum()]# 将过滤后的单词连接回单个字符串transformed_text = ' '.join(filtered_words)return transformed_textdata["final_data"]=data["Comment"].apply(transformed_text)
data.head()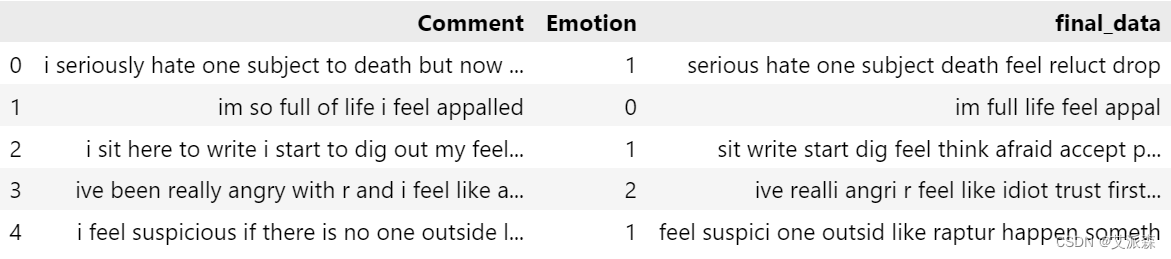
4.4词云可视化
愤怒情绪的词云
from wordcloud import WordCloud
wc=WordCloud(width=500,height=500,min_font_size=10,background_color="white")
# 愤怒情绪的词云
anger_wc=wc.generate(data[data["Emotion"]==0]["final_data"].str.cat(sep=" "))
plt.imshow(anger_wc)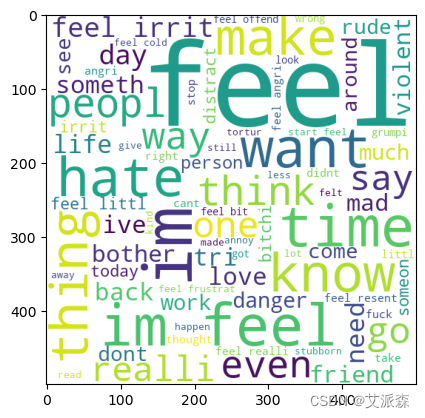
恐惧情绪的词云
# 恐惧情绪的词云
fear_wc=wc.generate(data[data["Emotion"]==1]["final_data"].str.cat(sep=" "))
plt.imshow(fear_wc)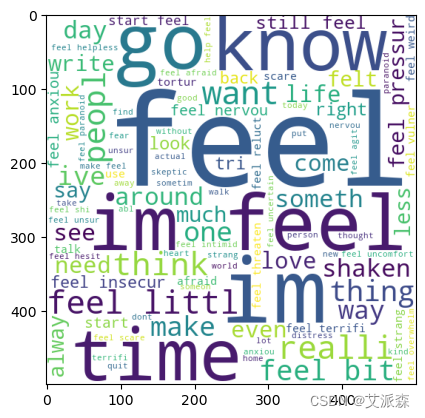
喜悦情绪的词云
# 喜悦情绪的词云
joy_wc=wc.generate(data[data["Emotion"]==2]["final_data"].str.cat(sep=" "))
plt.imshow(joy_wc)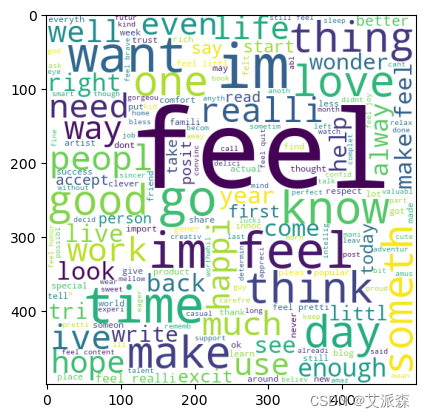
4.5构建语料库
构建愤怒用语的语料库
# 愤怒用语语料库
anger_corpus=[]
for msg in data[data["Emotion"]==0]["final_data"].tolist():for word in msg.split():anger_corpus.append(word)from collections import Counter
pd.DataFrame(Counter(anger_corpus).most_common(50))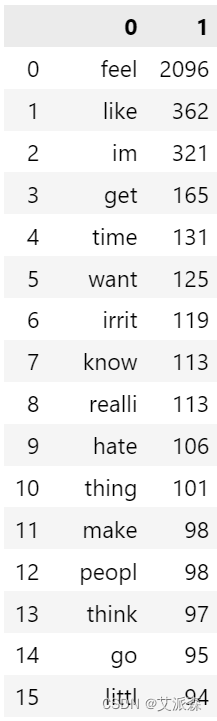
构建恐惧用语的语料库
# 恐惧用语语料库
fear_corpus=[]
for msg in data[data["Emotion"]==1]["final_data"].tolist():for word in msg.split():fear_corpus.append(word)
pd.DataFrame(Counter(fear_corpus).most_common(50))
构建喜悦用语的语料库
# 喜悦用语语料库
joy_corpus=[]
for msg in data[data["Emotion"]==2]["final_data"].tolist():for word in msg.split():joy_corpus.append(word)
pd.DataFrame(Counter(joy_corpus).most_common(50))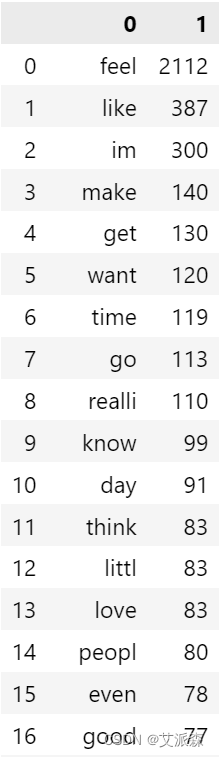
4.6词向量化
from sklearn.feature_extraction.text import CountVectorizer
cvector=CountVectorizer()
x=cvector.fit_transform(data["final_data"]).toarray() # 对数据进行向量化
x
y=data["Emotion"].values
y
4.7构建模型
在构建模型先拆分原始数据集为训练集和测试集
# 分离训练和测试数据
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=3) # 20%的数据将用于测试导入模型的第三方库
# 导入模型
from sklearn.metrics import accuracy_score,precision_score
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.naive_bayes import MultinomialNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import BaggingClassifier
from sklearn.ensemble import GradientBoostingClassifier
from xgboost import XGBClassifier 逻辑回归模型
# Logistic regression逻辑回归模型
log_reg=LogisticRegression()
log_reg.fit(x_train,y_train)
y_log_pred=log_reg.predict(x_test)
yt_log_pred=log_reg.predict(x_train)
log_reg_acc=accuracy_score(y_test,y_log_pred)
log_reg_prec=precision_score(y_test,y_log_pred,average='macro')
tr_log_reg_acc=accuracy_score(y_train,yt_log_pred)
tr_log_reg_prec=precision_score(y_train,yt_log_pred,average='macro')
print("accuracy score on train data is ",tr_log_reg_acc)
print("precision score on train data is ",tr_log_reg_prec)
print("accuracy score on test data is ",log_reg_acc)
print("precision score on test data is ",log_reg_prec)
支持向量机模型
# Support vector classifier 支持向量机模型
sv=SVC()
sv.fit(x_train,y_train)
sv_pred=sv.predict(x_test)
svt_pred=sv.predict(x_train)
sv_acc=accuracy_score(y_test,sv_pred)
sv_prec=precision_score(y_test,sv_pred,average='macro')
svt_acc=accuracy_score(y_train,svt_pred)
svt_prec=precision_score(y_train,svt_pred,average='macro')
print("accuracy score on train datais ",svt_acc)
print("precision score on train data is ",svt_prec)
print("accuracy score on test data is ",sv_acc)
print("precision score on test data is ",sv_prec)
决策树模型
# Decision tree Classifier决策树模型
dec_tree=DecisionTreeClassifier()
dec_tree.fit(x_train,y_train)
dec_tree_pred=dec_tree.predict(x_test)
dec_tree_tr_pred=dec_tree.predict(x_train)
dec_tree_acc=accuracy_score(y_test,dec_tree_pred)
dec_tree_prec=precision_score(y_test,dec_tree_pred,average='macro')
dec_tree_tr_acc=accuracy_score(y_train,dec_tree_tr_pred)
dec_tree_tr_prec=precision_score(y_train,dec_tree_tr_pred,average='macro')
print("accuracy score on train data is ",dec_tree_tr_acc)
print("precision score on train data is ",dec_tree_tr_prec)
print("accuracy score on test data is ",dec_tree_acc)
print("precision score on test data is ",dec_tree_prec)
随机森林模型
# Random forest classifier 随机森林模型
rfcl_model=RandomForestClassifier()
rfcl_model.fit(x_train,y_train)
rfcl_pred_model=rfcl_model.predict(x_test)
rfcl_tr_pred_model=rfcl_model.predict(x_train)
rfcl_acc_model=accuracy_score(y_test,rfcl_pred_model)
rfcl_prec_model=precision_score(y_test,rfcl_pred_model,average='macro')
rfcl_tr_acc_model=accuracy_score(y_train,rfcl_tr_pred_model)
rfcl_tr_prec_model=precision_score(y_train,rfcl_tr_pred_model,average='macro')
print("accuracy score on train data is ",rfcl_tr_acc_model)
print("precision score on train data is ",rfcl_tr_prec_model)
print("accuracy score on test data is ",rfcl_acc_model)
print("precision score on test data is ",rfcl_prec_model)
朴素贝叶斯模型
# Naive Bayes classifier 朴素贝叶斯模型
mnb=MultinomialNB()
mnb.fit(x_train,y_train)
mnb_pred=mnb.predict(x_test)
mnb_tr_pred=mnb.predict(x_train)
mnb_acc=accuracy_score(y_test,mnb_pred)
mnb_prec=precision_score(y_test,mnb_pred,average='macro')
mnb_tr_acc=accuracy_score(y_train,mnb_tr_pred)
mnb_tr_prec=precision_score(y_train,mnb_tr_pred,average='macro')
print("accuracy score on train data is ",mnb_tr_acc)
print("precision score on train data is ",mnb_tr_prec)
print("accuracy score on test data is ",mnb_acc)
print("precision score on test data is ",mnb_prec)
XGBoost模型
# XGboost classifier XGB模型
xgb=XGBClassifier()
xgb.fit(x_train,y_train)
xgb_pred=xgb.predict(x_test)
xgb_tr_pred=xgb.predict(x_train)
xgb_acc=accuracy_score(y_test,xgb_pred)
xgb_prec=precision_score(y_test,xgb_pred,average='macro')
xgb_tr_acc=accuracy_score(y_train,xgb_tr_pred)
xgb_tr_prec=precision_score(y_train,xgb_tr_pred,average='macro')
print("accuracy score on train data is ",xgb_tr_acc)
print("precision score on train data is ",xgb_tr_prec)
print("accuracy score on test data is ",xgb_acc)
print("precision score on test data is ",xgb_prec)
Adaboost模型
# Adaboost模型
adb=AdaBoostClassifier()
adb.fit(x_train,y_train)
adb_pred=adb.predict(x_test)
adb_tr_pred=adb.predict(x_train)
adb_acc=accuracy_score(y_test,adb_pred)
adb_prec=precision_score(y_test,adb_pred,average='macro')
adb_tr_acc=accuracy_score(y_train,adb_tr_pred)
adb_tr_prec=precision_score(y_train,adb_tr_pred,average='macro')
print("accuracy score on train data is ",adb_tr_acc)
print("precision score on train data is ",adb_tr_prec)
print("accuracy score on test data is ",adb_acc)
print("precision score on test data is ",adb_prec)
GBDT模型
# Gradient Boost 模型
gbc=GradientBoostingClassifier()
gbc.fit(x_train,y_train)
gbc_pred=gbc.predict(x_test)
gbc_tr_pred=gbc.predict(x_train)
gbc_acc=accuracy_score(y_test,gbc_pred)
gbc_prec=precision_score(y_test,gbc_pred,average='macro')
gbc_tr_acc=accuracy_score(y_train,gbc_tr_pred)
gbc_tr_prec=precision_score(y_train,gbc_tr_pred,average='macro')
print("accuracy score on train data is ",gbc_tr_acc)
print("precision score on train data is ",gbc_tr_prec)
print("accuracy score on test data is ",gbc_acc)
print("precision score on test data is ",gbc_prec)
Bagging Classifer模型
# Bagging Classifer模型
bagc=BaggingClassifier()
bagc.fit(x_train,y_train)
bagc_pred=bagc.predict(x_test)
bagc_tr_pred=bagc.predict(x_train)
bagc_acc=accuracy_score(y_test,bagc_pred)
bagc_prec=precision_score(y_test,bagc_pred,average='macro')
bagc_tr_acc=accuracy_score(y_train,bagc_tr_pred)
bagc_tr_prec=precision_score(y_train,bagc_tr_pred,average='macro')
print("accuracy score on train data is ",bagc_tr_acc)
print("precision score on train data is ",bagc_tr_prec)
print("accuracy score on test data is ",bagc_acc)
print("precision score on test data is ",bagc_prec)
KNN模型
# KNN classifier模型
knn=KNeighborsClassifier(n_neighbors=5)
knn.fit(x_train,y_train)
knn_pred=knn.predict(x_test)
knn_tr_pred=knn.predict(x_train)
knn_acc=accuracy_score(y_test,knn_pred)
knn_prec=precision_score(y_test,knn_pred,average='macro')
knn_tr_acc=accuracy_score(y_train,knn_tr_pred)
knn_tr_prec=precision_score(y_train,knn_tr_pred,average='macro')
print("accuracy score on train data is ",knn_tr_acc)
print("precision score on train data is ",knn_tr_prec)
print("accuracy score on test data is ",knn_acc)
print("precision score on test data is ",knn_prec)
4.8模型评估
前面我们使用了10个机器学习中的分类模型进行了拟合,现在综合评估各模型的指标情况,选择最佳模型
# 显示各模型性能指标
pd.DataFrame({"model_name":["logistic_regression","support_vector_classifier","decision_tree","random_forest","multinomial_NB","xgboost","adaboost","gradientboost","bagging","knn"],"train_precision_score":[tr_log_reg_prec,svt_prec,dec_tree_tr_prec,rfcl_tr_prec_model,mnb_tr_prec,xgb_tr_prec,adb_tr_prec,gbc_tr_prec,bagc_tr_prec,knn_tr_prec],"test_precision_score":[log_reg_prec,sv_prec,dec_tree_prec,rfcl_prec_model,mnb_prec,xgb_prec,adb_prec,gbc_prec,bagc_prec,knn_prec],"train_accuracy_score":[tr_log_reg_acc,svt_acc,dec_tree_tr_acc,rfcl_tr_acc_model,mnb_tr_acc,xgb_tr_acc,adb_tr_acc,gbc_tr_acc,bagc_tr_acc,knn_tr_acc],"test_accuracy_score":[log_reg_acc,sv_acc,dec_tree_acc,rfcl_acc_model,mnb_acc,xgb_acc,adb_acc,gbc_acc,bagc_acc,knn_acc]})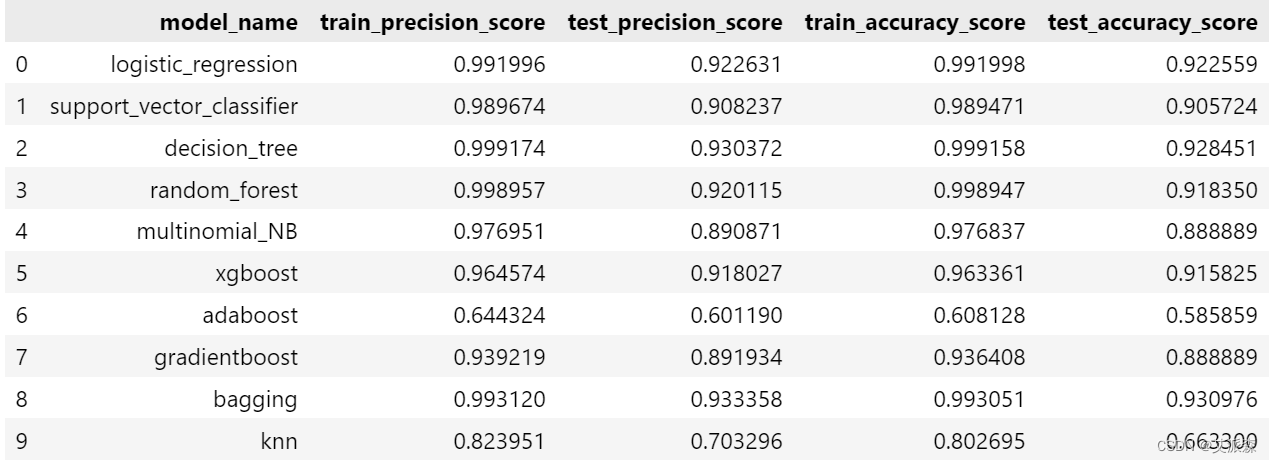
可以发现,决策树模型表现良好,但它可能导致数据过拟合,我们可以考虑Bagging和随机森林分类器,因为它们给出了最好的结果,精度和准确性得分很好地平衡。
4.9模型测试
使用Bagging模型进行测试新数据
# 测试新数据
user_text = "i hope that the next quote will be able to let my special someone knows what im feeling insecure about and understand that no matter how much i trust"
# 转换给定的文本
transformed_user_data = transformed_text(user_text)
# 向量化转换后的文本
text_vectorized = cvector.transform([transformed_user_data]).toarray()
# 使用模型进行预测
prediction = bagc.predict(text_vectorized)
# 打印预测结果
if prediction==0:print("emotion is anger")
elif prediction==1:print("emotion is fear")
else:print("emotion is joy")
可以发现模型分类正确!
5.总结
本实验旨在通过对英文文本中的愤怒、恐惧和喜悦等情感进行分类,利用10个常用的机器学习分类模型进行实验比较,最终选择Bagging模型进行拟合。实验结果显示,在测试集上,该Bagging模型取得了显著的准确率,达到了93%。
首先,通过对数据进行仔细的预处理和清洗,以及有效的特征提取,我们确保了输入模型的文本数据质量。选择10个常用的分类模型,包括决策树、支持向量机、逻辑回归等,为实验提供了广泛的比较基准,有助于找到最适合任务的模型。
然后,通过在这些模型中进行比较,我们发现Bagging模型在多方面指标上表现最为理想,具有较好的性能和稳定性。Bagging的优势在于能够通过组合多个基分类器的输出,降低过拟合的风险,并提高整体性能。最终的93%的准确率反映了该Bagging模型在情感分类任务中的出色表现。这意味着模型对于英文文本中的情感极性有着较强的识别和泛化能力。
综合来看,本实验通过充分比较不同分类模型,选择了Bagging模型作为最终的情感分类器,为处理英文情感文本提供了一个有效的解决方案。未来的研究可以进一步深入探讨模型的可解释性、对不平衡数据的适应性等方面,以进一步提升情感分类任务的性能。
文末推荐与福利
《AI智能化办公》与《巧用ChatGPT高效搞定Excel数据分析》二选一免费包邮送出3本!


内容简介:
《AI智能化办公》:
本书以人工智能领域最新翘楚“ChatGPT”为例,全面系统地讲解了ChatGPT的相关操作与热门领域的实战应用。
全书共10章,第1章介绍了ChatGPT是什么;第2章介绍了ChatGPT的注册与登录;第3章介绍了ChatGPT的基本操作与提问技巧;第4章介绍了用ChatGPT生成文章;第5章介绍了用ChatGPT生成图片;第6章介绍了用ChatGPT生成视频;第7章介绍了用ChatGPT编写程序;第8章介绍了ChatGPT的办公应用;第9章介绍了ChatGPT的设计应用;第10章介绍了ChatGPT的更多场景应用。
本书面向没有计算机专业背景又希望迅速上手ChatGPT操作应用的用户,也适合有一定的人工智能知识基础且希望快速掌握ChatGPT落地实操应用的读者学习。本书内容系统,案例丰富,浅显易懂,既适合ChatGPT入门的读者学习,也适合作为广大中职、高职、本科院校等相关专业的教材参考用书。
购买链接:
当当链接:http://product.dangdang.com/29646620.html
京东链接:https://item.jd.com/14256742.html
《巧用ChatGPT高效搞定Excel数据分析》:
本书以Excel 2021办公软件为操作平台,创新地借助当下最热门的AI工具——ChatGPT,来学习Excel数据处理与数据分析的相关方法、技巧及实战应用,同时也向读者分享在ChatGPT的帮助下进行数据分析的思路和经验。
全书共10章,分别介绍了在ChatGPT的帮助下,使用Excel在数据分析中的应用、建立数据库、数据清洗与加工、计算数据、简单分析数据、图表分析、数据透视表分析、数据工具分析、数据结果展示,最后通过行业案例,将之前学习的数据分析知识融会贯通,应用于实际工作中,帮助读者迅速掌握多项数据分析的实战技能。
本书内容循序渐进,章节内容安排合理,案例丰富翔实,适合零基础想快速掌握数据分析技能的读者学习,可以作为期望提高数据分析操作技能水平、积累和丰富实操经验的商务人员的案头参考书,也可以作为各大、中专职业院校,以及计算机培训班的相关专业的教学参考用书。
购买链接:
京东购买链接:https://item.jd.com/14256748.html
当当网购买链接:http://product.dangdang.com/29646616.html
- 抽奖方式:评论区随机抽取3位小伙伴免费送出!
- 参与方式:关注博主、点赞、收藏、评论区评论“人生苦短,拒绝内卷!”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
- 活动截止时间:2023-11-24 20:00:00
名单公布时间:2023-11-24 21:00:00
免费资料获取,更多粉丝福利,关注下方公众号获取

相关文章:
基于Bagging集成学习方法的情绪分类预测模型研究(文末送书)
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...
手写String集合元素去重的两种实现方式 正序 逆序 删除集合中符合条件的字符串)
Java算法(八)手写String集合元素去重的两种实现方式 正序 逆序 删除集合中符合条件的字符串
Java算法(八): 实现集合去重 需求:创建一个存储String的集合,内部存储(test, 张三, test,test, 李四)字符串 删除所有的test字符串,删除后&#…...

Linux的简单使用
Linux命令使用技巧 Tab键自动补全连续两次Tab键,给出操作提示使用上下箭头快速调出曾经使用过的命令使用clear命令或者Ctrll快捷键实现清屏Linux的常用命令 命令作用详细说明ls [-al] [dir]显示指定目录下的内容 -a 显示所有文件及目录 (. 开头的隐藏文件也会列出) …...

OpenCV技术应用(4)— 如何改变图像的透明度
前言:Hello大家好,我是小哥谈。本节课就手把手教你如何改变图像的透明度,希望大家学习之后能够有所收获~!🌈 目录 🚀1.技术介绍 🚀2.实现代码 🚀1.技术介绍 改变图像透明度的实…...

SpringCloud之Feign
文章目录 前言一、Feign的介绍二、定义和使用Feign客户端1、导入依赖2、添加EnableFeignClients注解3、编写FeignClient接口4、用Feign客户端代替RestTemplate 三、自定义Feign的配置1、配置文件方式全局生效局部生效 2、java代码方式 四、Feign的性能优化连接池配置 五、Feign…...
股票池(三)
3-股票池 文章目录 3-股票池一. 查询股票池支持的类型二. 查询目前股票池对应的股票信息三 查询股票池内距离今天类型最少/最多的股票数据四. 查询股票的池统计信息 一. 查询股票池支持的类型 接口描述: 接口地址:/StockApi/stockPool/listPoolType 请求方式:GET…...

如何搭建测试环境?一文解决你所有疑惑!
什么是测试环境 测试环境,指为了完成软件测试工作所必需的计算机硬件、软件、网络设备、历史数据的总称,简而言之,测试环境硬件软件网络数据准备测试工具。 硬件:指测试必需的服务器、客户端、网络连接等辅助设备。 软件&#…...

【JVM】JVM异常不打印堆栈信息 [ -XX:-OmitStackTraceInFastThrow ]
文章目录 一、背景二、原因三、 代码验证 一、背景 生产环境日志突然膨胀到100G, 为了定位问题,所以截取了部分报错日志, 问题是 堆栈信息呢? 哪里报的NPE在哪??? 信息如下: [ERROR] 2020-12-09 09:41:50.053 - [taskAppIdTASK-1919-33805-97659]:[156] - wait task qu…...

第十一章 目标检测中的NMS
精度提升 众所周知,非极大值抑制NMS是目标检测常用的后处理算法,用于剔除冗余检测框,本文将对可以提升精度的各种NMS方法及其变体进行阶段性总结。 总体概要: 对NMS进行分类,大致可分为以下六种,这里是依…...
vue项目中使用vant轮播图组件(桌面端)
一. 内容简介 vue使用vant轮播图组件(桌面端) 二. 软件环境 2.1 Visual Studio Code 1.75.0 2.2 chrome浏览器 2.3 node v18.14.0 三.主要流程 3.1 安装环境 3.2 添加代码 3.3 结果展示 四.具体步骤 4.1 安装环境 先安装包 # Vue 3 项目,安装最新版 Va…...

如何做好性能压测 —— 压测环境设计和搭建!
简介:一般来说,保证执行性能压测的环境和生产环境高度一致是执行一次有效性能压测的首要原则。有时候,即便是压测环境和生产环境有很细微的差别,都有可能导致整个压测活动评测出来的结果不准确。 1. 性能环境要考虑的要素 1.1 系…...

手机弱网测试工具:Charles
我们在测试app的时候,需要测试弱网情况下的一些场景,那么使用Charles如何设置弱网呢,请看以下步骤: 前提条件: 手机和电脑要在同一局域网内 Charles连接手机抓包 一、打开Charles,点击代理,…...

Axios七大特性
Axios是一个基于Promise的HTTP客户端,用于浏览器和Node.js环境中发起HTTP请求。它有许多强大的特性,下面将介绍Axios的七大特性。 1. 支持浏览器和Node.js Axios既可以在浏览器中使用,也可以在Node.js环境中使用,提供了统一的AP…...

【机器学习基础】K-Means聚类算法
🚀个人主页:为梦而生~ 关注我一起学习吧! 💡专栏:机器学习 欢迎订阅!相对完整的机器学习基础教学! ⭐特别提醒:针对机器学习,特别开始专栏:机器学习python实战…...
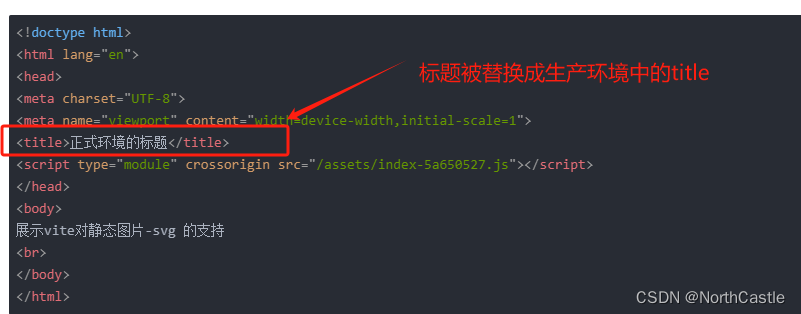
Vite - 配置 - 自动修改 index.html 中的title
需求描述 在Vue3项目的开发过程中,我们为了能区分正式环境和测试环境, 通常会进行环境配置文件的区分, 例如,开发环境一个配置文件、生产环境一个配置文件。因此,我们就希望 在项目的index.html 的 title 标签中&…...
基于安卓android微信小程序美容理发店预约系统app
项目介绍 为美容院设计一个系统以减少员工的工作量就成为了想法的初始状态。紧接着对美容院进行进一步的调查发现我的想法已然落后。基本上每个美容院都以有了自己的信息系统,并且做的已经较完善了。 在这时我突然想到,现在关注美容养生的人越来越多&am…...

*** stack smashing detected ***: terminated
有一个函数返回值是bool类型,但忘了return了,编译可以通过,但是运行的时候报这个错误。...
鸿蒙系统扫盲(二):再谈鸿蒙是不是安卓套壳?
最近小米发布了澎湃OS,vivo发布了蓝OS,好像自从华为回归后,大伙都开始写自己的OS了,小米官方承认是套壳安卓,然后被大家喷了,于是鸿蒙是不是安卓套壳的话题又回到了大众的视野,今天在讨论下这个…...
PG数据中DBeaver上传csv文件作为数据表
DBeaver 是一个开源的数据库工具,还是蛮好用的,有时候需要我们上传数据做表,数据为CSV格式的,DBeaver本身自带有功能实现的。 可打开连着的数据库,找到模式,点到下面的表里,选择一个表直接导入…...

第十七篇-Awesome ChatGPT Prompts-备份-百度翻译
Awesome ChatGPT Prompts——一个致力于提供挖掘ChatGPT能力的Prompt收集网站 https://prompts.chat/ 第十六篇-Awesome ChatGPT Prompts-备份【英文】 第十七篇-Awesome ChatGPT Prompts-备份-百度翻译 【中文】 高效提示词请参考,各种场景,2023-11-16内容如下(百…...

Phi-4-mini-reasoning 3.8B 网络协议分析助手:智能化解读与故障模拟
Phi-4-mini-reasoning 3.8B 网络协议分析助手:智能化解读与故障模拟 1. 网络协议分析的智能革命 网络工程师的日常工作总是伴随着海量的数据包和复杂的协议分析。传统工具虽然功能强大,但学习曲线陡峭,新手往往需要花费数月时间才能熟练使用…...

Shell脚本AI助手:终端集成Ollama与OpenAI的智能运维实践
1. 项目概述:一个纯粹的Shell脚本智能终端助手 在终端里直接和AI对话,让它帮你写命令、分析日志、解答技术问题,甚至管理本地的大语言模型——听起来是不是很酷?这就是 shell-pilot 带给我的核心体验。作为一个常年泡在终端里的…...

量化开发资源库:从Python数据处理到回测框架的完整指南
1. 项目概述:量化开发者资源库的诞生与价值 在金融科技领域,量化开发是一个门槛极高、信息又极度分散的领域。新手入门时,常常会陷入一种困境:知道需要学习Python、统计学、金融知识,但面对浩如烟海的库、框架、论文和…...

Kubernetes Job与CronJob深度解析与实践
Kubernetes Job与CronJob深度解析与实践 Job与CronJob概述 在Kubernetes中,Job用于运行一次性任务,而CronJob则用于运行定时任务。本文将深入探讨Job和CronJob的核心概念、配置方法和最佳实践。 Job核心概念 1. 基本Job配置 apiVersion: batch/v1 kind: …...

第五篇:锻造大脑——为什么算法公开,你却造不出 GPT?
书接上文。同学问:“既然 CNN、Transformer 的论文和代码都是开源的,我能不能在寝室里手搓一个 DeepSeek 或者 GPT-4?” 这就像虽然米其林餐厅的菜谱(算法)是公开的,但要把菜做成艺术品,你还需要…...

范式革新:时序媒体智能解析引擎与结构化知识蒸馏技术
范式革新:时序媒体智能解析引擎与结构化知识蒸馏技术 【免费下载链接】extract-video-ppt extract the ppt in the video 项目地址: https://gitcode.com/gh_mirrors/ex/extract-video-ppt 在数字内容爆炸式增长的今天,视频已成为知识传递的主要载…...

长期使用Taotoken服务在API延迟与稳定性方面的实际感受分享
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken服务在API延迟与稳定性方面的实际感受分享 在持续数月的项目开发中,我们团队将多个AI应用的后端服务统…...
)
安防/车载项目实战:用RK3588+NVP6188搞定AHD摄像头接入(附完整DTS配置与避坑点)
RK3588NVP6188工业级AHD摄像头接入实战:从硬件设计到多路预览的完整指南 在智能安防和车载电子领域,高清视频采集系统的稳定性直接决定了整个项目的成败。传统MIPI摄像头虽然画质出色,但传输距离的限制让它在停车场监控、行车记录仪等需要长距…...

nli-MiniLM2-L6-H768实际作品:短视频标题+封面OCR文本联合分类效果对比
nli-MiniLM2-L6-H768实际作品:短视频标题封面OCR文本联合分类效果对比 1. 项目背景与模型介绍 在短视频内容爆炸式增长的今天,如何快速准确地对海量视频内容进行分类成为一大挑战。传统方法通常需要单独处理视频标题和封面文字,不仅效率低下…...

RS信号发生器仿真模式应用与兼容性解决方案
1. R&S信号发生器远程仿真模式应用指南作为一名从事射频测试系统集成多年的工程师,我经常遇到老旧测试设备替换的挑战。最近在升级某卫星通信测试系统时,就遇到了Agilent 8648B信号发生器停产的问题。幸运的是,R&S的SMB100A通过其HP8…...