实用篇-ES-DSL查询文档
数据的存储不是目的,我们希望从海量的酒店数据中检索出需要的信息,这就是ES的搜索功能
官方文档: https://elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html#query-dsl。DSL是用来查询文档的
Elasticsearch提供了基于JSON的DSL来定义查询,简单说就是用json来描述查询条件,然后发送给es服务,最后es服务基于查询条件,把结果返回给我们
常见的查询类型包括如下:
1、查询所有: 查询出所有数据,一般在测试的时候使用
match_all2、全文检索查询: 利用分词器对用户输入内容进行分词,然后去倒排索引库中匹配
match_querymulti_match_query3、精确查询: 根据精确的词条值去查找数据,一般是查找keyword、数值、日期、boolean等类型的字段。这些字段是不需要分词的,但是依旧会建立倒排索引,把字段的整体内容作为一个词条,并存入倒排索引。在查找的时候,也就不需要分词,直接把搜索的内容去跟倒排索引匹配即可
ids,表示根据id,进行精确匹配range,表示根据数值范围,进行精确匹配term,表示根据数据的值,进行精确匹配4、地理查询: 根据经纬度查询
geo_distancegeo_bounding_box5、复合查询: 复合查询可将上述各种查询条件组合一起,合并查询条件
bool,利用逻辑运算把其它查询条件组合起来function_score,用于控制相关度算分,算分会影响性能一、DSL查询语法

GET /hotel/_search
{"query": {"match_all": {}}
}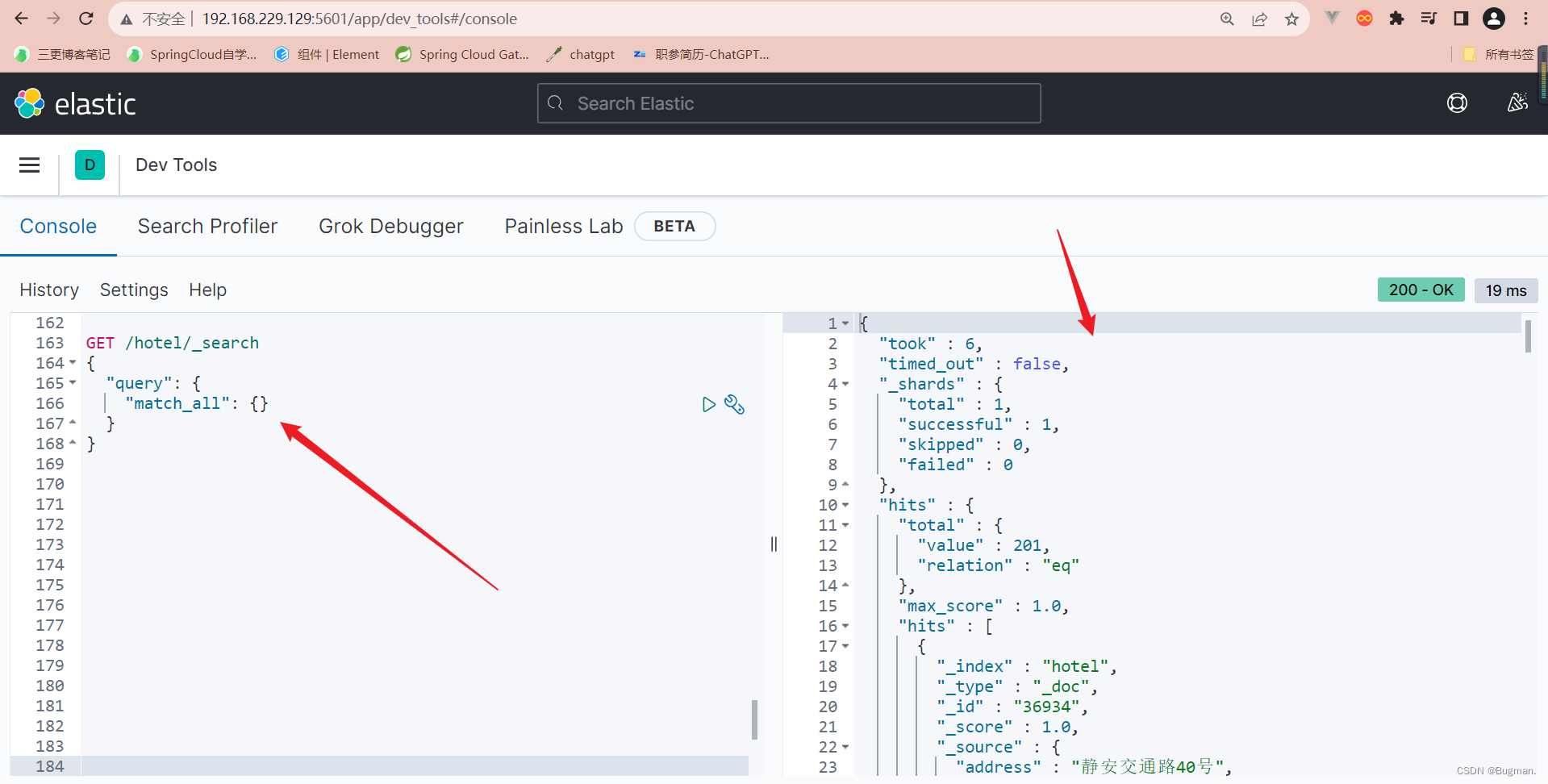
存在一个问题,我们明明查询的是所有文档,查询结果也显示查询出所有的文档了,为什么上图右侧,鼠标往下拉,最多才只有10条文档数据呢
原因: 受默认的分页条件限制,后面学习的时候,会进行解决
二、全文检索查询
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为hotel的索引库,导入了批量文档。然后开始下面的操作
全文检索查询,分为下面两种,会对用户输入内容进行分词之后,再进行匹配。也就是利用分词器对用户输入内容进行分词,然后去倒排索引库中匹配
match_querymulti_match_query【第一种全文检索查询】
match查询(也就是match_query查询): 全文检索查询的一种,会对用户输入的内容进行分词,然后去倒排索引库检索
GET /索引库名/_search
{"query": {"match": {"字段名": "TEXT"}}
}具体操作如下,为了让大家知道hotel索引库有哪些字段,我把当初建立gghotel索引库的类先放出来
package cn.itcast.hotel.constants;public class HotelConstants {public static final String MAPPING_TEMPLATE = "{\n" +" \"mappings\": {\n" +" \"properties\": {\n" +" \"id\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"name\":{\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"address\":{\n" +" \"type\": \"keyword\",\n" +" \"index\":false\n" +" },\n" +" \"price\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"score\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"brand\":{\n" +" \"type\": \"keyword\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"city\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"starName\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"business\":{\n" +" \"type\": \"keyword\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"location\":{\n" +" \"type\": \"geo_point\"\n" +" },\n" +" \"pic\":{\n" +" \"type\":\"keyword\",\n" +" \"index\": false\n" +" },\n" +" \"all\":{\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\"\n" +" }\n" +" }\n" +" }\n" +"}";
}
注意: 我要解释一下,上面有个字段叫all,那个字段是当时自定义的,不清楚的话可回去看 '实用篇-ES-RestClient操作' 的 'hotel数据结构分析'。
all的作用如下图,相当于一个大的字段,里面存放了几个小字段,优点是我们可以在这个大的字段里面搜索到多个小字段的信息
然后,我们就正式开始全文检索查询,输入如下。注意all换成其它字段也没事,例如换成name字段。正常来说,我们检索name字段,就只在name字段检索匹配的分词文档,但是在all字段里面检索时,也会检索到name、brand、business字段,原因如上面那个图的copy_to属性
GET /hotel/_search
{"query": {"match": {"all": "外滩"}}
}//或者如下
# 第一种全文检索查询 match。查询name字段中包含'酒店'的文档
GET /hotel/_search
{"query": {"match": {"name": "酒店"}}
}
【第二种全文检索查询】
multi_match(也就是multi_match_query查询): 与match查询类似,只不过允许同时查询多个字段
GET /索引库名/_search
{"query": {"multi_match": {"query": "TEXT","字段名": ["FIELD1", " FIELD12"]}}
}# 第二种全文检索查询 multi_match。查询business、brand、name字段中包含'如家'的文档,满足一个字段即可
GET /hotel/_search
{"query": {"multi_match": {"query": "如家","fields":["business","brand","name"]}}
}
三、精确查询

term: 根据词条的精确值查询,强调精确匹配
range: 根据值的范围查询,例如金额、时间
【第一种精确查询 term】
具体操作如下
查询city为杭州
GET /hotel/_search
{
"query":{"term":{"city":{"value":"杭州"}}}
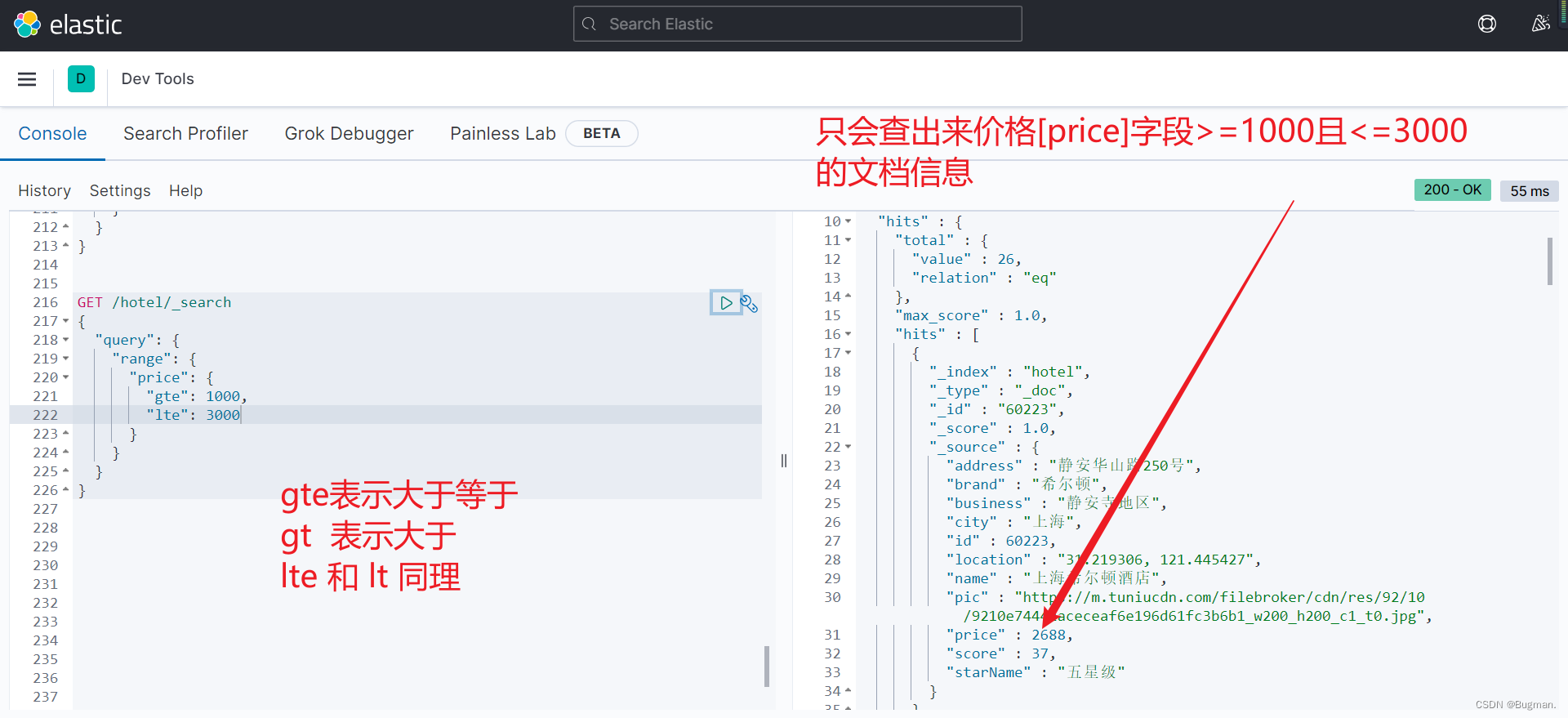
}【第二种精确查询 range】
GET /hotel/_search
{"query": {"range": {"price": {"gte": 10,"lte": 20}}}
}
四、地理查询
根据经纬度查询。常见的使用场景包括: 查询附近酒店、附近出租车、搜索附近的人。使用方式有很多种,介绍如下,这种最常用
geo_distance: 查询到指定中心点,以该点为圆心,distance为半径的圆,符合要求的所有文档
GET /索引库名/_search
{"query": {"geo_distance": {"distance": "15km","字段名": "31.21,121.5"}}
}
具体操作如下
输入如下DSL语句
GET /hotel/_search
{"query": {"geo_distance": {"distance": "15km","location": "31.21,121.5"}}
}五、相关性算分
上面学的全文检索查询、精确查询、地理查询,这三种查询在es当中都称为简单查询,下面我们将学习复合查询。复合查询可以其它简单查询组合起来,实现更复杂的搜索逻辑,其中就有 '算分函数查询' 如下
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为hotel的索引库,导入了批量文档。然后开始下面的操作
算分函数查询(function score): 可以控制文档相关性算分、控制文档排名。例如搜索'外滩' 和 '如家' 词条时,某个文档要是都能匹配这两个词条,那么在所有被搜索出来的文档当中,这个文档的位置就最靠前,简单说就是越匹配就排名越靠前


六、函数算分查询
上面只是简单演了相关性打分中的函数算分查询,文档与搜索关键字的相关度越高,打分就越高,排名就越靠前。不过,有的时候,我们希望人为地去控制控制文档的排名,例如某些文档我们就希望排名靠前一点,算分高一点,此时就需要使用函数算分查询,下面就来学习 '函数算分查询'
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,导入了批量文档。然后开始下面的操作
使用 ’函数算分查询(function score query)’,可以在原始的相关性算分的基础上加以修改,得到一个想要的算分,从而去影响文档的排名,语法如下
GET /索引库名/_search
{"query": {"function_score": {"query": { "match": {"字段": "词条"} },"functions": [{"filter": {"term": {"指定字段": "值"}},"算分函数": 函数结果}],"boost_mode": "加权模式"}}
}
function score需要考虑的三要素
1. 哪些文档需要算分加权
2. 算分函数是什么
3. 加权模式是什么
下面我们实现一个案例:给如家这个品牌的酒店排名靠前一些
考虑三要素
1. 哪些文档需要算分加权 brand为如家的酒店
2. 算分函数是什么 weigh
3. 加权模式是什么 相加/相乘都可
输入如下DSL语句,表示在 '如家' 这个品牌中,字段为'北京'的酒店排名靠前一些
GET /hotel/_search
{"query": {"function_score": {"query": {"match": {"brand": "如家"}},"functions": [{"filter": {"term": {"city": "北京"}},"weight": 2}],"boost_mode": "sum"}}
}七、布尔查询
这是第二种复合查询
布尔查询不会去修改算分,而是把多个查询语句组合成一起,形成新查询,这些被组合的查询语句,被称为子查询。子查询的组合方式有如下四种
1、must:必须匹配每个子查询,类似"与"
2、should:选择性匹配子查询,类似"或"
3、must_not:必须不匹配,不参与算分,类似"非"
4、filter:必须匹配,不参与算分
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,导入了批量文档。然后开始下面的操作
输入如下DSL语句,表示搜索名字包含'如家',价格不高于400,在坐标31.21,121.5周围10km范围内的文档
GET /hotel/_search
{"query": {"bool": {"must": [{"match": {"name": "如家"}}],"must_not": [{"range": {"price": {"gt": 400}}}],"filter": [{"geo_distance": {"distance": "10km","xxlocation": {"lat": 31.21,"lon": 121.5}}}]}}
}八、搜索结果处理
lasticsearch(称为es)支持对搜索的结果,进行排序,默认是根据 '相关度' 算分,也就是score值,根据score值进行排序。
可以排序的字段类型有: keyword类型、数值类型、地理坐标类型、日期类型
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,导入了批量文档。然后开始下面的操作
1. 排序
输入如下DSL语句,表示对所有的文档,根据评分(score)进行降序排序,如果评分相同就根据价格(price)升序排序
GET /hotel/_search
{"query": {"match_all": {}},"sort": [{"score": {"order": "desc"},"price": {"order": "asc"}}]
}
2. 分页
elasticsearch(称为es)默认情况下只返回前10 条数据。而如果要查询更多数据就需要修改分页参数,分页参数包括from和size,语法如下
GET /索引库名/_search
{"query": {"要查询的字段": {}},"from": 要查第几页, // 分页开始的位置,默认为0"size": 每页显示多少条文档, // 期望获取的文档总数"sort": [ //表示排序{"price": "排序方式"}]
}输入如下DSL语句,表示对所有的文档,根据价格(price)进行升序排序,每次分页显示20条数据,看的是第六页
size默认是10,表示一页显示多少条文档。from默认是0,表示你要看的是第一页
GET /hotel/_search
{"query": {"match_all": {}},"sort": [{"price": {"order": "asc"}}],"from": 5,"size": 20
}

3. 搜索结果处理-高亮
高亮: 就是在搜索结果中把搜索关键字突出显示。高亮显示的原理如下
1、将搜索结果中的关键字用标签标记出来
2、在页面中给标签添加css样式
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,导入了批量文档。然后开始下面的操作
语法
GET /索引库名/_search
{"query": {"match": { //match表示带关键字的查询"字段": "TEXT"}},"highlight": {"fields": {"字段名": {"require_field_match": "false",//默认是true,表示 '字段' 要和 '字段名' 要一致。如果我们写的是不一致的话,就需要修改为false"pre_tags": "<em>", // 用来标记高亮字段的前置标签,es会帮我们把标签加在关键字上。默认是<em>"post_tags": "</em>" // 用来标记高亮字段的后置标签,es会帮我们把标签加在关键字上。默认是</em>}}}
}
总结
GET /索引库名/_search
{"query": {"match": {"字段名": "如家"}},"from": 0, // 分页开始的位置"size": 20, // 期望获取的文档总数"sort": [ { "price": "asc" }, // 普通排序{"_geo_distance" : { // 距离排序"location" : "31.040699,121.618075", "order" : "asc","unit" : "km"}}],"highlight": {"fields": { // 高亮字段"字段名": {"pre_tags": "<em>", // 用来标记高亮字段的前置标签"post_tags": "</em>" // 用来标记高亮字段的后置标签}}}
}相关文章:
实用篇-ES-DSL查询文档
数据的存储不是目的,我们希望从海量的酒店数据中检索出需要的信息,这就是ES的搜索功能 官方文档: https://elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html#query-dsl。DSL是用来查询文档的 Elasticsearch提供了基于JSON的DSL来定…...
Nacos配置管理
将配置交给Nacos管理的步骤 1、在Nacos中添加配置文件 2、在微服务中引入nacos的config依赖 3、在微服务中添加bootstrap.yml,配置nacos地址、当前环境、服务名称、文件后缀名。这些决定了程序启动时去nacos读取哪个文件 Nacos配置更改后,微服务可以实…...
【前端学java】Java中的异常处理(15)完结
往期回顾: 【前端学java】JAVA开发的依赖安装与环境配置 (0)【前端学java】java的基础语法(1)【前端学java】JAVA中的packge与import(2)【前端学java】面向对象编程基础-类的使用 (…...

深入理解MySQL存储引擎、InnoDB与MyISAM的比较以及事务处理机制
介绍 MySQL是一款强大而灵活的关系型数据库管理系统,它支持多种存储引擎,每个引擎都有其独特的特点和适用场景。在本篇博客中,我们将深入探讨MySQL存储引擎的种类、InnoDB与MyISAM的区别,以及事务的概念及其在MySQL中的实现方式。…...

webpack 中,filename 和 chunkFilename 的区别
filename filename 是一个很常见的配置,就是对应于 entry 里面的输入文件,经过webpack打包后输出文件的文件名。比如说经过下面的配置,生成出来的文件名为 index.min.js。 chunkFilename chunkFilename 指未被列在 entry 中,却…...
gitlab 实战
一.安装依赖 yum install -y curl policycoreutils-python openssh-server perl 二.安装gitlab yum install gitlab-jh-16.0.3-jh.0.el7.x86_64.rpm 三.修改下面的 vim /etc/gitlab/gitlab.rbexternal_url http://192.168.249.156 四.初始化 gitlab-ctl reconfigure 五.查看状…...

openGauss学习笔记-128 openGauss 数据库管理-设置透明数据加密(TDE)
文章目录 openGauss学习笔记-128 openGauss 数据库管理-设置透明数据加密(TDE)128.1 概述128.2 前提条件128.3 背景信息128.4 密钥管理机制128.5 表级加密方案128.6 创建加密表128.7 切换加密表加密开关128.8 对加密表进行密钥轮转 openGauss学习笔记-12…...

Redis从入门到精通(三)-高阶篇
文章目录 0. 前言[【高阶篇】3.1 Redis协议(RESP )详解](https://blog.csdn.net/wangshuai6707/article/details/132742584)[【高阶篇】3.3 Redis之底层数据结构简单动态字符串(SDS)详解](https://blog.csdn.net/wangshuai6707/article/details/131101404)[【高阶篇】3.4 Redis…...

线性表--队列-1
文章目录 主要内容一.队列基础练习题1.用链式存储方式的队列进行删除操作时需要 ( D ).代码如下(示例): 2.若以1,2,3,4作为双端队列的输入序列,则既不能由输入受限的双端队列得到,又不能由输出受限的双端队列得到的输出序列是( C …...

【开题报告】基于uni-app的汽车租赁app的设计与实现
1.项目背景及意义 项目背景: 随着人们生活水平的提高,汽车租赁服务在城市中变得越来越普及。传统的租车方式存在一些问题,比如租车流程繁琐、费用不透明、选择有限等。因此,开发一款基于uni-app的汽车租赁app成为了满足用户需求…...

Java实现围棋算法
围棋是一种源自中国的棋类游戏,也是世界上最古老、最复杂的棋类游戏之一。该游戏由黑白两方交替放置棋子在棋盘上进行,目的是将自己的棋子占据更多的空间,并将对手的棋子围死或吃掉,最终获得胜利。围棋不仅是一种游戏,…...
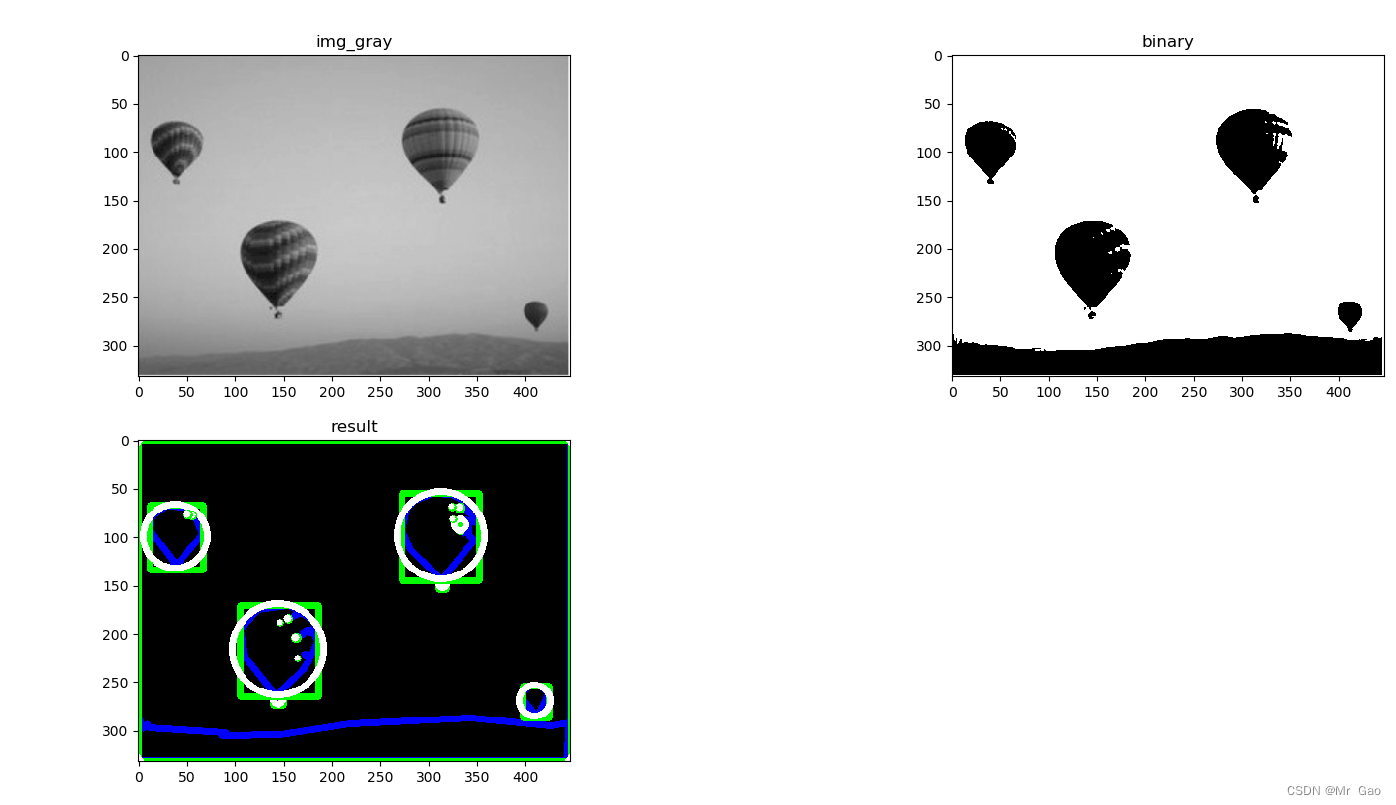
python -opencv 边缘检测
python -opencv 边缘检测 边缘检测步骤: 第一步:读取图像为灰度图 第二步:进行二值化处理 第三步:使用cv2.findContours对二值化图像提取轮廓 第三步:将轮廓绘制到图中 代码如下: from ctypes.wintypes import SIZ…...
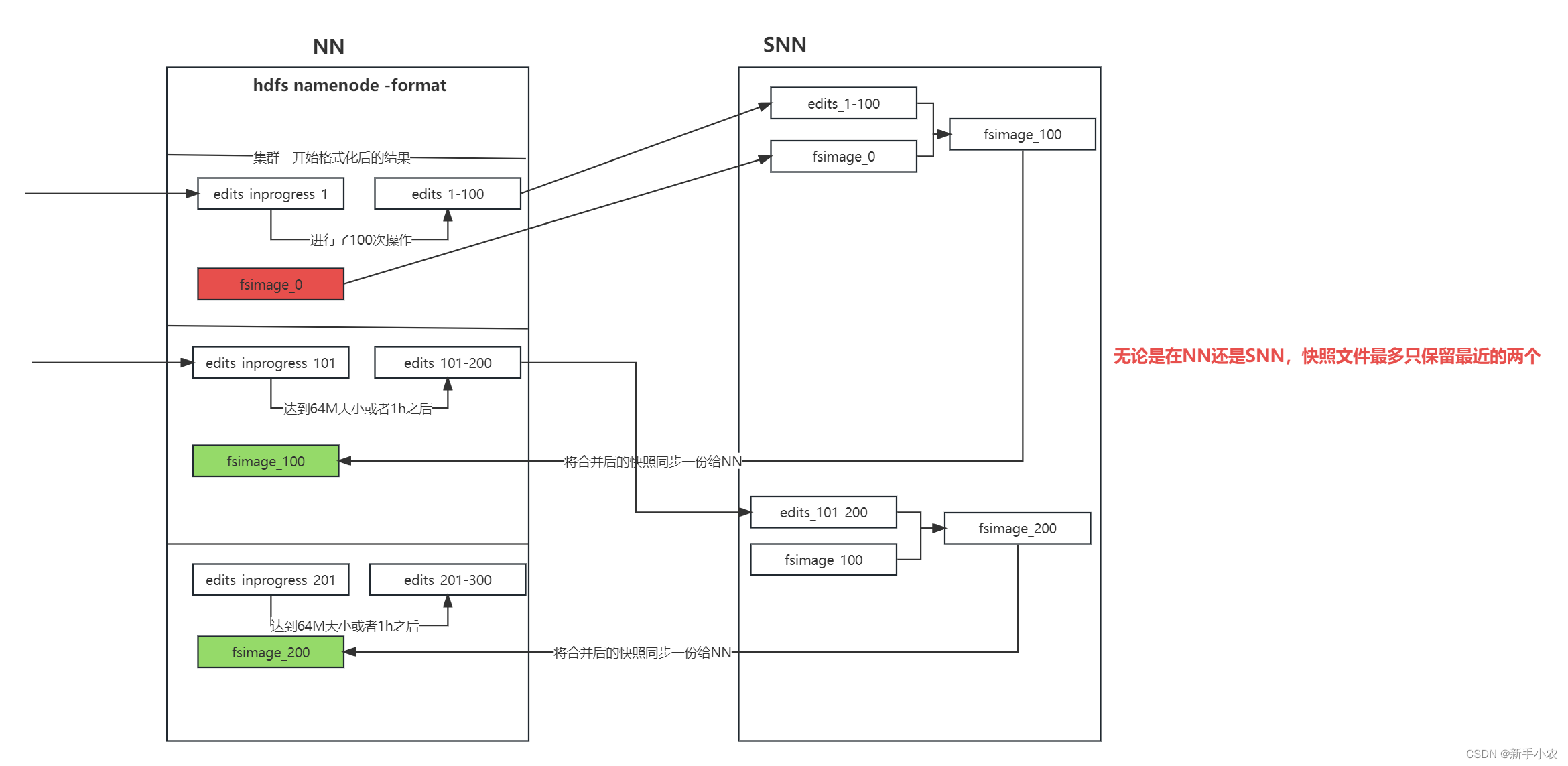
Hadoop-- hdfs
1、HDFS中的三个进程:NameNode(NN)、DataNode(DN)、SecondNameNode(SNN) 2、NameNode(NN) 1、作用: 1、接收客户端的一个读、写的服务,在namenode上存储了数据文件和datanode的映射的关系。 …...

《论文阅读》CAB:认知、情感和行为的共情对话生成 DASFAA 2023
《论文阅读》CAB:认知、情感和行为的共情对话生成 前言摘要相关知识CVAE 条件变分自编码器最大最小归一化模型架构1.获取 Representation2.Prior Network and Recognition Network (Affection)3.Knowledge Acquisition and Fusion (Cognition)4.Dialogue Act Predictor and Re…...
审计dvwa高难度命令执行漏洞的代码,编写实例说明如下函数的用法
审计dvwa高难度命令执行漏洞的代码 ,编写实例说明如下函数的用法 代码: <?phpif( isset( $_POST[ Submit ] ) ) {// Get input$target trim($_REQUEST[ ip ]);// Set blacklist$substitutions array(& > ,; > ,| > ,- > ,$ …...

国科大数据挖掘期末复习——聚类分析
聚类分析 将物理或抽象对象的集合分组成为由类似的对象组成的多个类的过程被称为聚类。由聚类所生 成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异。 聚类属于无监督学习(unsupervised learning&…...

【经验之谈·高频PCB电路设计常见的66个问题】
文章目录 1、如何选择PCB 板材?2、如何避免高频干扰?3、在高速设计中,如何解决信号的完整性问题?4、差分布线方式是如何实现的?5、对于只有一个输出端的时钟信号线,如何实现差分布线?6、接收端差…...
科大讯飞 vue.js 语音听写流式实现 全网首发
组件下载 还是最近的需求,页面表单输入元素过多,需要实现语音识别来由用户通过朗读的方式向表单中填写数据,尽量快的、高效的完成表单数据采集及输入。 国内科大讯飞在语音识别方面的建树还是有目共睹,于是还是选择了科大讯飞的平…...
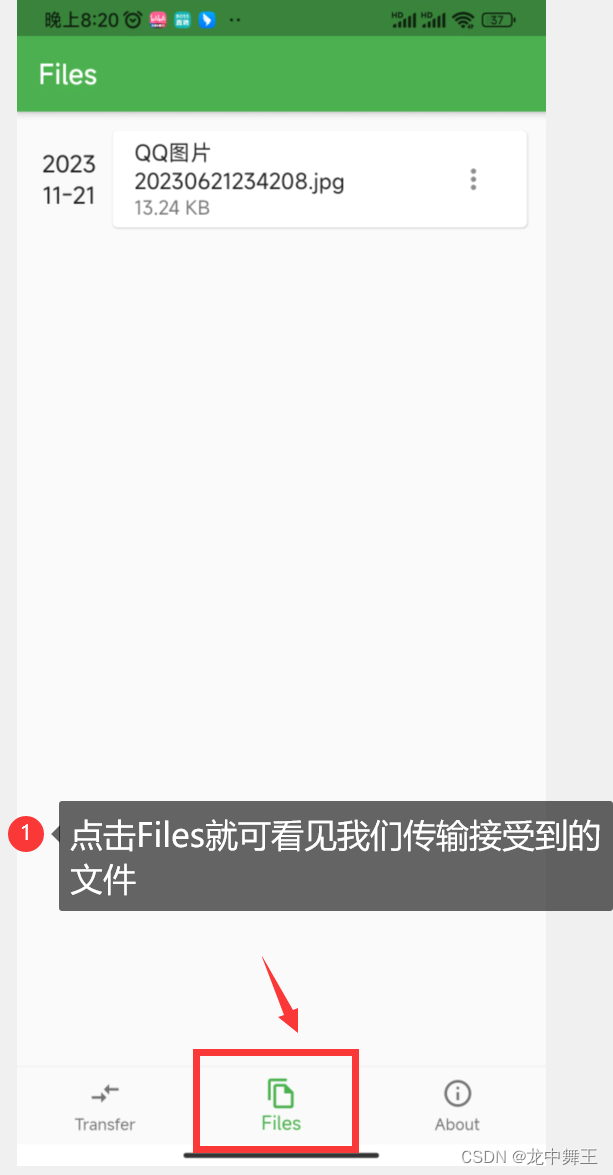
局域网文件共享神器:Landrop
文章目录 前言解决方案Landrop软件界面手机打开效果 软件操作 前言 平常为了方便传文件,我们都是使用微信或者QQ等聊天软件,互传文件。这样传输有两个问题: 必须登录微信或者QQ聊天软件。手机传电脑还有网页版微信,电脑传手机比…...
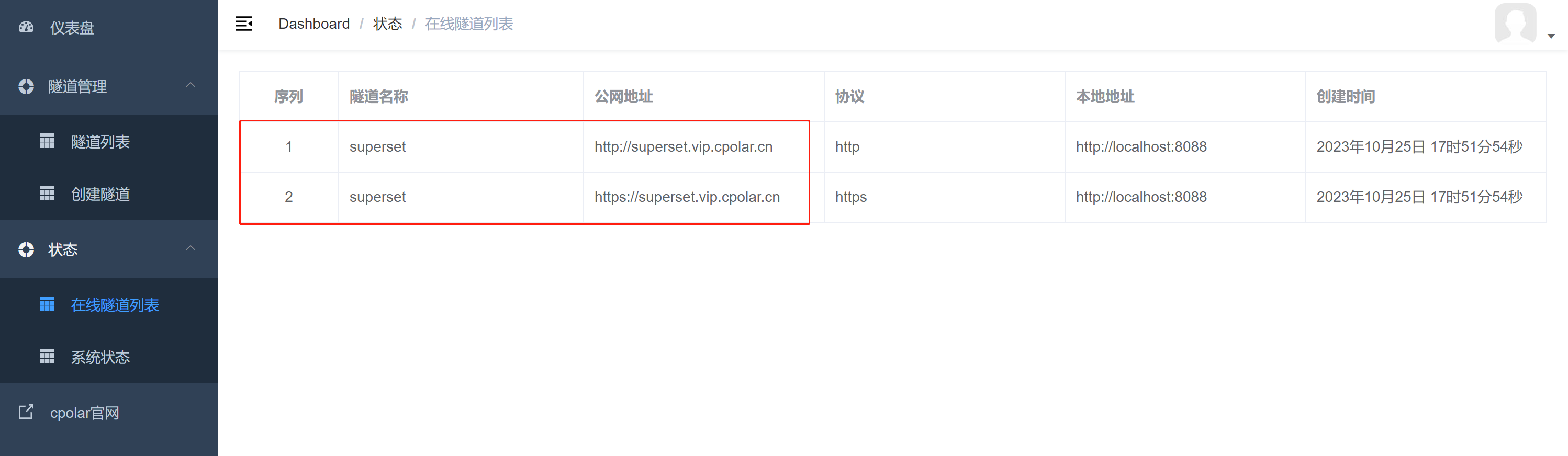
如何使用Docker部署Apache+Superset数据平台并远程访问?
大数据可视化BI分析工具Apache Superset实现公网远程访问 文章目录 大数据可视化BI分析工具Apache Superset实现公网远程访问前言1. 使用Docker部署Apache Superset1.1 第一步安装docker 、docker compose1.2 克隆superset代码到本地并使用docker compose启动 2. 安装cpolar内网…...

CANN/cann-recipes-infer:在昇腾Atlas A2/A3环境上适配SANA-Video模型的推理
在昇腾Atlas A2/A3环境上适配SANA-Video模型的推理 【免费下载链接】cann-recipes-infer 本项目针对LLM与多模态模型推理业务中的典型模型、加速算法,提供基于CANN平台的优化样例 项目地址: https://gitcode.com/cann/cann-recipes-infer SANA-Video模型是一…...

Zotero中文文献识别难题终结者:Jasminum插件深度解析
Zotero中文文献识别难题终结者:Jasminum插件深度解析 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 告别乱码与信息缺…...

终极视频加速工具:5大技巧让你每天多出2小时的高效观看体验
终极视频加速工具:5大技巧让你每天多出2小时的高效观看体验 【免费下载链接】videospeed HTML5 video speed controller (for Google Chrome) 项目地址: https://gitcode.com/gh_mirrors/vi/videospeed 你是否经常觉得视频内容太慢,但又不想错过关…...

3秒解锁百度网盘资源:baidupankey智能提取码获取终极指南
3秒解锁百度网盘资源:baidupankey智能提取码获取终极指南 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 还在为百度网盘分享链接的提取码而烦恼吗?每次遇到需要密码的资源,你是否也在各大论…...

4I-SIM超分辨显微技术:原理、实现与生物应用
1. 4I-SIM技术原理深度解析 超分辨显微技术领域近年来最引人注目的突破之一,就是结构光照明显微镜(SIM)的迭代升级。作为一名长期从事生物医学成像的研究者,我亲眼见证了传统宽场显微镜如何被SIM技术颠覆,而4I-SIM又将…...

sd-webui-oldsix-prompt核心功能解析:权重调整、位置调整、Alt+Q快捷键的终极使用指南
sd-webui-oldsix-prompt核心功能解析:权重调整、位置调整、AltQ快捷键的终极使用指南 【免费下载链接】sd-webui-oldsix-prompt sd-webui中文提示词插件、老手新手炼丹必备 项目地址: https://gitcode.com/gh_mirrors/sd/sd-webui-oldsix-prompt sd-webui-ol…...

Automagik Forge:从氛围编程到结构化AI协作的工程化实践
1. 项目概述:从“氛围编程”到“结构化执行”的进化如果你和我一样,在过去一年里深度体验过各种AI编程助手,从GitHub Copilot到Cursor,再到Claude Code,那你一定对那种“氛围感”又爱又恨。爱的是,你只需要…...

本地AI桌面助手Joanium:项目感知与自动化工作流实战
1. 项目概述:一个真正运行在你电脑里的AI桌面助手 如果你和我一样,每天的工作流里充斥着各种重复性的任务:打开GitHub看issue、检查邮件、整理项目文档、或者为某个代码片段写注释。这些事说大不大,但累积起来,就是巨…...

GPU加速优化框架cuGenOpt的设计与性能优化
1. GPU加速优化框架cuGenOpt的核心设计理念 在计算密集型优化领域,GPU加速已成为突破传统计算瓶颈的关键技术。cuGenOpt框架的独特之处在于其"三重自适应"架构设计,这使其在通用性和性能之间取得了显著平衡。 1.1 内存层次感知的并行计算模型…...

使用Taotoken CLI工具一键配置多开发环境下的AI助手接入
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键配置多开发环境下的AI助手接入 对于需要在不同项目、不同机器上工作的开发者而言,为每个AI助…...