R语言——taxize(第三部分)
taxize(第三部分)
- 3. taxize 文档中译
- 3.24. genbank2uid(从 GenBankID 获取 NCBI 分类 UID)
- 3.25. getkey(获取 API 密钥的函数)
- 3.26. get_boldid(获取搜索词的 BOLD(生命条形码)代码)
- 3.27. get_eolid(根据分类名称从《生命百科全书》中获取 EOL ID)
- 3.28. get_gbifid(从分类名称中获取 GBIF 主干分类群 ID)
- 3.29. get_ids(检索给定分类群名称的分类标识符)
- 3.30. get_id_details(关于 get_*() 函数的详细信息)
- 3.31. get_iucn(获取《世界自然保护联盟红色名录》分类群)
- 3.32. get_natservid(获取分类群名称的 NatureServe 分类标识)
- 3.33. get_nbnid(从分类名称中获取英国国家生物多样性网络 ID)
- 3.34. get_pow(获取邱园世界植物分类群代码)
- 3.35. get_tolid(获取搜索词的 OTT ID)
- 3.36. get_tpsid(从 Tropicos 获取分类名称的 NameID 代码)
- 3.37. get_tsn(获取搜索词的 TSN 代码)
- 3.38. get_uid(从 NCBI 获取分类名称的 UID 代码)
3. taxize 文档中译
3.24. genbank2uid(从 GenBankID 获取 NCBI 分类 UID)
用法:genbank2uid(id, batch_size = 100, key = NULL, ...)
参数:
- id:GenBank 编号字母数字字符串或 gi 数字字符串。
- batch_size:一次提交的查询次数。
- key:(字符型)NCBI Entrez API 密钥。可选。
- …:传递给crul::HttpClient的可选参数。
说明:关于为什么有两个标识符以及它们之间的区别,请参阅 https://www.ncbi.nlm.nih.gov/Sitemap/sequenceIDs.html。
返回值:一个或多个 NCBI 分类 ID。
NCBI请求限制:以防万一你触发了NCBI的请求速率限制导致出错,参考taxize_options(),你可以设置ncbi_sleep。
NCBI请求的HTTP版本:本方法硬编码了http_version=2L以便让HTTP请求使用HTTP/1.1访问Entrez API。详见curl::curl_symbols(“CURL_HTTP_VERSION”)。
示例1:使用许可编号
genbank2uid(id = 'AJ748748')
[[1]]
[1] "282199"
attr(,"class")
[1] "uid"
attr(,"match")
[1] "found"
attr(,"multiple_matches")
[1] FALSE
attr(,"pattern_match")
[1] FALSE
attr(,"uri")
[1] "https://www.ncbi.nlm.nih.gov/taxonomy/282199"
attr(,"name")
[1] "Nereida ignava 16S rRNA gene, type strain 2SM4T"
示例2:使用gi编号
genbank2uid(id = 62689767)
[[1]]
[1] "282199"
attr(,"class")
[1] "uid"
attr(,"match")
[1] "found"
attr(,"multiple_matches")
[1] FALSE
attr(,"pattern_match")
[1] FALSE
attr(,"uri")
[1] "https://www.ncbi.nlm.nih.gov/taxonomy/282199"
attr(,"name")
[1] "Nereida ignava 16S rRNA gene, type strain 2SM4T"
3.25. getkey(获取 API 密钥的函数)
描述:检查从 .Rprofile 或 .Renviron(或类似文件)中获取的密钥。
用法:getkey(x = NULL, service)
参数:
- x:(字符型)API 密钥,默认为NULL。
- service:(字符型)API 数据提供者,用于匹配默认访客密钥(用于 Tropicos;NCBI 或 IUCN 没有访客密钥,您必须自己获取)。
示例:
getkey(service="tropicos")
[1] "00ca3d6a-cbcc-4924-b882-c26b16d54446"
3.26. get_boldid(获取搜索词的 BOLD(生命条形码)代码)
用法:
get_boldid(sci, fuzzy=FALSE, dataTypes='basic', includeTree=FALSE, ask=TRUE, message=TRUE, rows=NA, rank=NULL, division=NULL, parent=NULL, searchterm=NULL, ...)as.boldid(x, check=TRUE)## S3 method for class 'boldid'
as.boldid(x, check=TRUE)## S3 method for class 'character'
as.boldid(x, check=TRUE)## S3 method for class 'list'
as.boldid(x, check=TRUE)## S3 method for class'numeric'
as.boldid(x, check=TRUE)## S3 method for class 'data.frame'
as.boldid(x, check=TRUE)## S3 method for class 'boldid'
as.data.frame(x, ...)get_boldid_(sci, message=TRUE, fuzzy=FALSE, dataTypes='basic', includeTree=FALSE, rows=NA, searchterm=NULL, ...)
参数:
- sci:(字符型)一个学名向量。或分类群状态对象。
- fuzzy:(逻辑型)是否使用模糊搜索(默认值:FALSE)。
- dataTypes:(字符型)指定将返回的数据类型。dataTypes参数的接受值*:
| 接受值 | 返回说明 |
|---|---|
| all | 所有数据 |
| basic | 基本的类群信息 |
| images | 标本图片。包含版权信息,图片链接,图片元数据 |
| stats | 标本和测序统计。包括公开物种数,公开BIN数,公开标记物数,公开记录数,标本数,测序物种数,条形码标本数,物种数,条形码物种数 |
| geo | 采集点信息。包括国家和采集点地图 |
| sequencinglabs | 测序实验室。包括实验室名称和记录数 |
| depository | 标本仓库。包括仓库名和记录数 |
| thirdparty | 第三方信息。包括维基百科总结,维基百科链接和GBIF地图 |
- includeTree:(逻辑型)如果为 TRUE(默认值:FALSE),则返回一个包含
父分类群和指定分类群的信息。 - ask:(逻辑型)是否应在交互模式下运行 get_tsn?如果为 “true”,并且为该物种找到了一个以上的 TSN,则会要求用户输入。如果为 FALSE,多个匹配结果将返回 NA。
- messages:(逻辑型)是否应该输出进展情况?
- rows:(数值型)从 1 到无穷大的任意数字。如果默认值为 NA,则会考虑所有行。需要注意的是,该函数仍然只能返回一个具有一到多个标识符的 boldid 类对象。请参阅 get_boldid_(),获取问询过程中显示的全部或部分原始数据。
- rank:(字符型)分类等级名称。可选项见 rank_ref。不过要注意的是,有些数据源使用非典型阶元,因此请检查数据本身的选项。可选。
- division:(字符型)门名称。可选。
- parent:(字符型)父类名称(即目标搜索分类群的父类)。可选。
- searchterm:已弃用,请使用sci。
- …:传递给crul::verb-GET的可选参数。
- x:传递给as.boldid()。
- check:(逻辑型)检查 ID 是否与数据库中的任何现有 ID 匹配,仅用于 as.boldid()。
返回值:作为 S3 类的分类标识符向量。如果未找到分类群,则给出 NA。如果找到一个以上的标识符,如果 ask = TRUE,函数会要求用户输入,否则返回 NA。如果 ask=FALSE 且行不等于 NA,则返回一个 data.frame,但不是 uid 类,不能像通常那样传递给其他函数。
筛选:division、parent和rank参数不用于搜索数据提供者,而是用于将数据筛选为更接近所需目标的子集。所有这些参数都可以使用 regex 字符串,因为我们内部使用 grep() 进行匹配。过滤将范围缩小到与您的查询相匹配的数据集,并删除其余数据。
示例1:简单传入分类名称。
get_boldid(sci = "Agapostemon")
[1] "1973"
attr(,"class")
[1] "boldid"
attr(,"match")
[1] "found"
attr(,"multiple_matches")
[1] FALSE
attr(,"pattern_match")
[1] FALSE
attr(,"uri")
[1] "http://boldsystems.org/index.php/Taxbrowser_Taxonpage?taxid=1973"
示例2:模糊匹配。
get_boldid(sci="Osmi", fuzzy=TRUE)
示例3:筛选子集。
get_boldid(sci="Osmi", fuzzy=TRUE, rows = 1)
[1] "4940"
attr(,"class")
[1] "boldid"
attr(,"match")
[1] "found"
attr(,"multiple_matches")
[1] TRUE
attr(,"pattern_match")
[1] TRUE
attr(,"uri")
[1] "http://boldsystems.org/index.php/Taxbrowser_Taxonpage?taxid=4940"
3.27. get_eolid(根据分类名称从《生命百科全书》中获取 EOL ID)
描述:请注意,EOL 并没有提供直接查询 EOL 分类群 ID 的 API 端点,因此我们首先使用函数 eol_search()查找涉及相关物种的页面,然后使用 eol_pages()查找实际的分类群 ID。
用法:
get_eolid(sci_com, ask=TRUE, messages=TRUE, rows=NA, rank=NULL, data_source=NULL, sciname=NULL, ...)as.eolid(x, check=TRUE)## S3 method for class 'eolid'
as.eolid(x, check=TRUE)## S3 method for class 'character'
as.eolid(x, check=TRUE)## S3 method for class 'list'
as.eolid(x, check=TRUE)## S3 method for class 'numeric'
as.eolid(x, check=TRUE)## S3 method for class 'data.frame'
as.eolid(x, check=TRUE)## S3 method for class 'eolid'
as.data.frame(x, ...)get_eolid_(sci_com, messages=TRUE, rows=NA, sciname=NULL, ...)
参数:
- sci_com:(字符型)一个或多个学名或俗名。或taxon_state对象。
- ask:(逻辑型)get_eolid 是否应在交互模式下运行?如果 “true”(“正确”),且发现该物种有一个以上的 ID,则会要求用户输入。如果为 FALSE,多个匹配项将返回 NA。
- messages:(逻辑型)如果为 “true”,则在控制台中打印实际查询的分类群。
- rows:(数值型)从 1 到无穷大的任意数字。如果默认值为 NA,则考虑所有行。需要注意的是,该函数仍然只能返回一个包含一到多个标识符的 eolid 类对象。请参阅 get_eolid_(),获取问询过程中显示的全部或部分原始数据。
- rank:(字符型)分类等级名称。可选项见 rank_ref。不过要注意的是,有些数据源使用非典型阶元,因此请检查数据本身的选项。可选。请参阅下面的筛选。
- data_source:(字符型)EOL 中的数据源。这些名称较长,如 "Barcode of Life Data Systems(生命条形码数据系统)"或 “USDA PLANTS images(美国农业部植物图像)”。可选。请参阅下面的筛选。
- sciname:已弃用,请使用sci_com。
- …:传递给*eol_search()*的参数。
- x:传入as.eolid() 的参数。
- check:(逻辑型)检查 ID 是否与数据库中的任何现有 ID 匹配,仅用于 as.eolid()。
说明:EOL 有点奇怪,它们为每个分类群都设置了页面 ID,但在页面 ID 中,它们又为该页面中的不同分类群设置了分类群 ID(例如,GBIF 和 NCBI 在页面 [即分类群] 中都有一个分类群)。我们需要特定数据提供者(如 NCBI)提供的分类群 id 来做其他事情,比如获取更高级的分类树。然而,我们需要的是页面 id,而不是分类群 id。因此,该函数返回的 id 是分类群 id,而不是页面 id。你可以通过使用 eol_search() 和 'eol_pages() 获得分类群的页面 id,分类群属性中返回的 URI 将引导你进入分类群页面,URL 中的 ID 就是页面 id。
返回值:作为 S3 类的分类标识符向量。如果未找到分类群,则给出 NA。如果找到一个以上的标识符,如果 ask = TRUE,函数会要求用户输入,否则返回 NA。如果 ask=FALSE 且 rows 不等于 NA,则会返回一个 data.frame,但不是 uid 类,不能像通常那样传递给其他函数。有关属性和异常情况的详细信息,请参见 get_id_details。
筛选:rank 和 data_source 参数不用于搜索数据提供者,而是用于过滤数据,使其成为更接近所需目标的子集。所有这些参数都可以使用 regex 字符串,因为我们内部使用 grep() 进行匹配。筛选将范围缩小到与您的查询相匹配的数据集,并删除其余数据。
示例
get_eolid('Poa annua', rows=1)
[1] "11811642"
attr(,"class")
[1] "eolid"
attr(,"pageid")
[1] "1114594"
attr(,"provider")
[1] "Arctic Vascular Plants"
attr(,"match")
[1] "found"
attr(,"multiple_matches")
[1] TRUE
attr(,"pattern_match")
[1] TRUE
attr(,"uri")
[1] "https://eol.org/pages/1114594/"
3.28. get_gbifid(从分类名称中获取 GBIF 主干分类群 ID)
用法:
get_gbifid(sci, ask = TRUE, messages = TRUE, rows = NA, phylum = NULL, class = NULL, order = NULL, family = NULL, rank = NULL, method = "backbone", sciname = NULL, ...)as.gbifid(x, check = FALSE)
## S3 method for class 'gbifid'
as.gbifid(x, check = FALSE)
## S3 method for class 'character'
as.gbifid(x, check = TRUE)
## S3 method for class 'list'
as.gbifid(x, check = TRUE)
## S3 method for class 'numeric'
as.gbifid(x, check = TRUE)
## S3 method for class 'data.frame'
as.gbifid(x, check = TRUE)
## S3 method for class 'gbifid'
as.data.frame(x, ...)get_gbifid_(sci, messages = TRUE, rows = NA, method = "backbone", sciname = NULL)
参数:
- sci:(字符型)一个或多个学名或俗名。或taxon_state对象。
- ask:(逻辑型)get_eolid 是否应在交互模式下运行?如果 “true”(“正确”),且发现该物种有一个以上的 ID,则会要求用户输入。如果为 FALSE,多个匹配项将返回 NA。
- messages:(逻辑型)如果为 “true”,则在控制台中打印实际查询的分类群。
- rows:(数值型)从 1 到无穷大的任意数字。如果默认值为 NA,则考虑所有行。需要注意的是,该函数仍然只能返回一个包含一到多个标识符的 eolid 类对象。请参阅 get_gbifid_(),获取问询过程中显示的全部或部分原始数据。
- phylum:(字符型)门名称。可选。
- class:(字符型)纲名称。可选。
- order:(字符型)目名称。可选。
- family:(字符型)科名称。可选。
- rank:(字符型)分类等级名称。可选项见 rank_ref。不过要注意的是,有些数据源使用非典型阶元,因此请检查数据本身的选项。可选。请参阅下面的筛选。
- method:(字符型)backbone或lookup之一。
- sciname:已弃用,请使用sci。
- …:暂无用。
- x:传递给*as.gbifid()*的参数。
- check:(逻辑型)检查 ID 是否与数据库中的任何现有 ID 匹配,仅用于 as.gbifid()。
说明:在这个函数的内部,我们使用一个函数来搜索 GBIF 的分类标准,如果找到完全匹配的,我们会返回该匹配的 ID。如果没有完全匹配,我们将返回选项供您选择。
返回值:作为 S3 类的分类标识符向量。如果未找到分类群,则给出 NA。如果 如果 ask = TRUE,函数会要求用户输入,否则返回 NA。如果 ask=FALSE,且行不等于 NA,则返回一个 data.frame,但不是 uid 类、 这样就不能像通常那样将其传递给其他函数。有关属性和异常情况的详细信息,请参见 get_id_details。
method参数:"backbone "使用/species/match GBIF API途径,根据其主干分类法进行匹配。我们默认开启模糊匹配,因为不开启模糊匹配的骨干分类法搜索范围很窄。“查找”(lookup)使用/species/search GBIF API途径,对名称使用情况进行全文检索,包括科学命名和俗名、物种描述、分布和整个分类信息。
筛选:phylum, class, order, family, 和 rank参数并不用于搜索数据提供者,而是用于过滤数据,筛选出更接近所需目标的子集。所有这些参数都可以使用 regex 字符串,因为我们内部使用 grep() 进行匹配。过滤将范围缩小到与您的查询相匹配的数据集,并删除其余数据。
示例:get_gbifid(sci='Poa annua')
3.29. get_ids(检索给定分类群名称的分类标识符)
描述:这是一个方便的函数,用于获取所有数据源的标识符。您可以使用其他 get_* 函数来获取特定数据源中的标识符。
用法:
get_ids(sci_com, db = c("itis", "ncbi", "eol", "tropicos", "gbif", "nbn", "pow"), suppress = FALSE, names = NULL, ...)get_ids_(sci_com, db = get_ids_dbs, rows = NA, suppress = FALSE, names = NULL, ...)
参数:
- sci_com:(字符型)要查询的分类名称。
- db:(字符型)要查询的数据库。ncbi、itis、eol、tropicos、gbif、nbn或pow中的一个或多个。默认情况下,db 设置为搜索所有数据源。需要注意的是,每个分类数据源都有自己的标识符,因此如果为标识符提供了错误的 db 值,虽然可能会得到一个结果,但很可能是错误的(不是你所期望的)。如果使用 ncbi 和/或 tropicos,建议获取 API 密钥;请参阅 taxize-authentication。
- supress:(逻辑值)在查询数据库名称时抑制 cli 分隔符。默认为FALSE。
- names:已弃用,请使用sci_com。
- …:传递给 get_tsn()、get_uid()、get_eolid()、get_tpsid()、get_gbifid()、get_nbnid() 的其他参数。
- rows:(数值型)从 1 到无穷大的任意数字。如果默认为 NA,则返回所有行。当在 get_ids 中使用时,该函数仍然只返回一个带有一到多个标识符的 ids 类对象。请参阅 get_ids_,以获取问询过程中显示的全部或部分原始数据。
返回值:分类标识符向量,每个标识符都保留了各自的 S3 类别,这样每个元素都可以传递给另一个函数。
说明:向 NCBI 查询的间隔时间为 1/3 秒。
示例:get_ids("Poa annua", db="eol", rows=1)
3.30. get_id_details(关于 get_*() 函数的详细信息)
说明:
• get_boldid()
• get_eolid()
• get_gbifid()
• get_ids()
• get_iucn()
• get_natservid()
• get_nbnid()
• get_tolid()
• get_tpsid()
• get_tsn()
• get_ubioid()
• get_uid()
• get_wiki()
• get_wormsid()
属性:get_*() 函数的每个输出都具有以下属性:
- match:(字符型)NA 的原因,可以是 “not found”、“found”,或者如果 ask = FALSE,则 “NA 因为 ask=FALSE”)。
- multiple_matches:(字符型)数据源是否返回多个匹配项。即使只返回一个名字,这个属性也可能是 TRUE,因为我们会尝试对名字进行模式匹配,看是否有直接匹配的名字。因此,有时该属性为 TRUE,pattern_match 也为 TRUE,这样就会返回 1 个结果名称,而不会出现用户提示。
- pattern_match:(字符型)是否进行了模式匹配。如果为 TRUE,则 multiple_matches 必须为 TRUE,我们找到了与您姓名完全匹配的信息,忽略大小写。如果为 FALSE,则无法直接匹配,您可能需要从多个选项中进行选择,或者可以使用其他参数来限制结果。
- uri:(字符型)可以读取该分类群更多信息的 URI。
- 在 URL 的某处包含分类标识符。如果返回的值为 NA,则可能缺少该标识符。
抛出异常:以下是 get_*() 函数的各种行为方式:
- success:返回的值是字符串或数字。
- no matches found:您将收到 NA,请缩小搜索范围,或者您使用的数据库中可能不存在所搜索的分类群。
- 多个匹配且 ask = FALSE:如果有一个以上的匹配结果,而你又设置了 ask = FALSE,那么我们就无法确定要返回的单个匹配结果,所以我们会返回 NA。不过,在这种情况下,由于 ask=FALSE 和 > 1 个结果,我们确实会将匹配属性设置为 NA,因此发生了什么就一目了然了–你甚至还可以通过编程来检查这一点。
- 由于其他原因返回NA:有些 get_*()函数有用于过滤分类群的附加参数。即使有结果(即找到的结果为 TRUE),也有可能返回一个 NA。这很可能是参数在从数据提供者返回分类群后对其进行了过滤,而传递给参数的值导致没有匹配结果。
3.31. get_iucn(获取《世界自然保护联盟红色名录》分类群)
用法:
get_iucn(sci, messages = TRUE, key = NULL, x = NULL, ...)as.iucn(x, check = TRUE, key = NULL)## S3 method for class 'iucn'
as.iucn(x, check = TRUE, key = NULL)## S3 method for class 'character'
as.iucn(x, check = TRUE, key = NULL)## S3 method for class 'list'
as.iucn(x, check = TRUE, key = NULL)## S3 method for class 'numeric'
as.iucn(x, check = TRUE, key = NULL)## S3 method for class 'data.frame'
as.iucn(x, check = TRUE, key = NULL)## S3 method for class 'iucn'as.data.frame(x, ...)
参数:
- sci:(字符型)一个学名向量。。或taxon_state对象。
- messages:(逻辑型)是否应该输出进展情况?
- key:(字符型)必需的。您的世界自然保护同盟红名单 API 密钥。请参阅 rredlist::rredlist-package 以获取有关世界自然保护同盟红名单认证的帮助。
- x:用于 get_iucn(): 已弃用,请使用 sci。对于 as.iucn(),均可。
- …:请忽略。
- check:(逻辑型)检查 ID 是否与数据库中的任何现有 ID 匹配,仅用于 as.iucn()。
说明:没有下划线方法,是因为没有真正的 IUCN 搜索,即搜索一个字符串,然后通过模糊匹配得到一堆结果。如果将来出现这种情况,我们将在这里添加下划线方法。IUCN ID 仅适用于synonyms() 和 sci2comm() 方法。
返回值:作为 S3 类的分类标识符向量。具有以下属性:
-
match:(字符型)NA 的原因,可以是 “not found”、“found”,或者如果 ask = FALSE,则 “NA 因为 ask=FALSE”)。
-
name:(字符型)synonyms()和 sci2comm() 方法需要分类名称,因为它们内部使用的 rredlist 函数需要分类名称,而不是分类标识符。
-
ri(字符型)可以读取分类群更多信息的 URI - 包括 URL 中的分类标识符。
在这里,multiple_match 和 pattern_match 并不像其他 get_* 方法那样适用,因为没有 IUCN Redlist 搜索,所以要么匹配,要么不匹配。
示例:get_iucn("Branta canadensis")
3.32. get_natservid(获取分类群名称的 NatureServe 分类标识)
用法:
get_natservid(sci_com, searchtype = "scientific", ask = TRUE, messages = TRUE, rows = NA, query = NULL, ...)as.natservid(x, check = TRUE)## S3 method for class 'natservid'
as.natservid(x, check = TRUE)## S3 method for class 'character'
as.natservid(x, check = TRUE)## S3 method for class 'list'
as.natservid(x, check = TRUE)## S3 method for class 'numeric'
as.natservid(x, check = TRUE)## S3 method for class 'data.frame'
as.natservid(x, check = TRUE)## S3 method for class 'natservid'
as.data.frame(x, ...)get_natservid_(sci_com, searchtype = "scientific", messages = TRUE, rows = NA, query = NULL, ...)
参数:
- sci_com:(字符型)一个学名或俗名向量。或taxon_state对象。
- searchtype:(字符型)“scientific”(默认)或 "common"之一。这并不影响对 NatureServe 的查询,而是会影响在数据请求后的名称筛选中针对哪一列数据。
- ask:(逻辑型)是否应该在交互模式下运行 get_natservid?如果为 “true”,并且为该物种找到了一个以上的 wormsid,则会要求用户输入。默认值: TRUE。
- messages:(逻辑型)是否应打印进度? 默认值: TRUE。
- rows:(数值型)从 1 到无穷大的任意数字。如果默认值为 NaN,则考虑所有行。需要注意的是,这个函数仍然只能返回一个包含一到多个标识符的 natservid 类对象。请参阅 get_natservid_(),获取问询过程中显示的全部或部分原始数据。
- query:已弃用,请使用 sci_name。
- …:传递给crul::verb-POST的参数。
- x:传入as.natservid。
- check:(逻辑型)检查 ID 是否与数据库中的任何现有 ID 匹配,仅在 as.natservid() 中使用。
返回值:作为 S3 类的分类标识符向量。如果未找到分类群,则给出 NA。如果找到一个以上的标识符,如果 ask = TRUE,函数会要求用户输入,否则返回 NA。如果 ask=FALSE 且行不等于 NA,则返回一个 data.frame,但不是 uid 类,不能像通常那样传递给其他函数。有关属性和例外情况的更多详情,请参阅 get_id_details。
示例:get_natservid("Helianthus annuus", verbose = TRUE)
3.33. get_nbnid(从分类名称中获取英国国家生物多样性网络 ID)
用法:
get_nbnid(sci_com, ask = TRUE, messages = TRUE, rec_only = FALSE, rank = NULL, rows = NA, name = NULL, ...)as.nbnid(x, check = TRUE)## S3 method for class 'nbnid'
as.nbnid(x, check = TRUE)## S3 method for class 'character'
as.nbnid(x, check = TRUE)## S3 method for class 'list'
as.nbnid(x, check = TRUE)## S3 method for class 'data.frame'
as.nbnid(x, check = TRUE)## S3 method for class 'nbnid'
as.data.frame(x, ...)get_nbnid_(sci_com, messages = TRUE, rec_only = FALSE, rank = NULL, rows = NA, name = NULL, ...)
参数:
- sci_com:(字符型)一个学名或俗名向量。或taxon_state对象。
- ask:(逻辑型)是否应该在交互模式下运行 get_nbnid?如果为 “true”,并且为该物种找到了一个以上的 ID,则会要求用户输入。默认值: TRUE。
- messages:(逻辑型)是否应打印进度? 默认值: TRUE。
- rec_only:(逻辑型)如果为 TRUE,将返回推荐名称的 id(即删除同义词)。默认为 FALSE。请记住,同义词的 id 是具有 "推荐 "名称状态的分类群。
- rank:(字符型)如果给定,我们会尝试将结果限制在具有匹配等级的分类群中。
- rows:(数值型)从 1 到无穷大的任意数字。如果默认值为 NaN,则考虑所有行。需要注意的是,这个函数仍然只能返回一个包含一到多个标识符的 nbnid 类对象。请参阅 get_nbnid_(),获取问询过程中显示的全部或部分原始数据。
- name:已弃用,请使用 sci_name。
- …:传递给nbn_search的参数。
- x:传递给as.nbnid()的参数。
- check:(逻辑型)检查 ID 是否与数据库中的任何现有 ID 匹配,仅在 as.nbnid() 中使用。
返回值:作为 S3 类的分类标识符向量。如果未找到分类群,则给出 NA。如果找到一个以上的标识符,如果 ask = TRUE,函数会要求用户输入,否则返回 NA。如果 ask=FALSE 且 rows 不等于 NA,则会返回一个 data.frame,但不是 uid 类,不能像通常那样传递给其他函数。
请参阅 get_id_details,了解更多详细信息,包括属性和异常 nbnid 类对象,是对作为分类 ID 的字符串的轻量级封装–包括具有相关元数据的属性。
示例:get_nbnid(sci_com='Poa annua')
3.34. get_pow(获取邱园世界植物分类群代码)
用法:
get_pow(sci_com, accepted = FALSE, ask = TRUE, messages = TRUE, rows = NA,family_filter = NULL,rank_filter = NULL,x = NULL,...)as.pow(x, check = TRUE)## S3 method for class 'pow'
as.pow(x, check = TRUE)## S3 method for class 'character'
as.pow(x, check = TRUE)## S3 method for class 'list'
as.pow(x, check = TRUE)## S3 method for class 'data.frame'
as.pow(x, check = TRUE)## S3 method for class 'pow'
as.data.frame(x, ...)get_pow_(sci_com, messages = TRUE, rows = NA, x = NULL, ...)
参数:
- sci_com:(字符型)一个学名或俗名向量。或taxon_state对象。
- accepted:(逻辑型)如果设置为 TRUE,则删除 ITIS 不接受的有效名称。设为 FALSE(默认值),则同时返回已接受和未接受的名称。
- ask:(逻辑型)是否应该在交互模式下运行 get_pow?如果为 “true”,并且为该物种找到了一个以上的 ID,则会要求用户输入。默认值: TRUE。
- messages:(逻辑型)是否应打印进度? 默认值: TRUE。
- rows:(数值型)从 1 到无穷大的任意数字。如果默认值为 NaN,则考虑所有行。需要注意的是,这个函数仍然只能返回一个包含一到多个标识符的 nbnid 类对象。请参阅 get_pow_(),获取问询过程中显示的全部或部分原始数据。
- family_filter:(字符型)从 NCBI 获取的用于筛选门的部门(又称门类)名称。可选。
- rank_filter:(字符型)分类等级名称,用于过滤从 NCBI 检索到的数据。有关可能的选项,请参见 rank_ref。不过要注意的是,有些数据源使用非典型等级,因此请查看数据本身的选项。可选。
- x:对于get_pow(),已弃用,请使用sci_com。
- …:传递给crul::verb-POST的参数。
- check:(逻辑型)检查 ID 是否与数据库中的任何现有 ID 匹配,仅用于 as.pow()。
返回值:作为 S3 类的分类标识符向量。如果未找到分类群,则给出 NA。如果找到一个以上的标识符,如果 ask = TRUE,函数会要求用户输入,否则返回 NA。如果 ask=FALSE 且 rows 不等于 NA,则会返回一个 data.frame,但不是 uid 类,不能像通常那样传递给其他函数。请参阅 get_id_details,了解更多详细信息,包括属性和异常。
筛选:参数 family_filter 和 rank_filterer 不用于搜索数据提供者,而是用于过滤数据,使其成为更接近所需目标的子集。对于这两个参数,可以使用 regex 字符串,因为我们内部使用 grep() 进行匹配。过滤将范围缩小到与您的查询相匹配的数据集,并删除其余数据。
请求频率限制:截至 2019 年 2 月,KEW 限制为每秒 5 个请求。请注意,他们将来可能会更改这一数字。如果你收到包含 429 的错误,那就是达到了速率限制,你可以通过在请求之间使用 Sys.sleep 来解决这个问题。
示例:get_pow(sci_com="Helianthus")
3.35. get_tolid(获取搜索词的 OTT ID)
描述:从 OpenTreeOfLife 检索分类群的开放生命树分类法 (OTT) ID。
用法:
get_tolid(sci, ask = TRUE, messages = TRUE, rows = NA, sciname = NULL, ...)as.tolid(x, check = TRUE)## S3 method for class 'tolid'
as.tolid(x, check = TRUE)## S3 method for class 'character'
as.tolid(x, check = TRUE)## S3 method for class 'list'
as.tolid(x, check = TRUE)## S3 method for class 'numeric'
as.tolid(x, check = TRUE)## S3 method for class 'data.frame'
as.tolid(x, check = TRUE)## S3 method for class 'tolid'
as.data.frame(x, ...)get_tolid_(sci, messages = TRUE, rows = NA, sciname = NULL)
参数:
- sci:(字符型)一个学名或俗名向量。或taxon_state对象。
- ask:(逻辑型)是否应在交互模式下运行 get_tolid?如果为 “true”,并且为该物种找到了一个以上的 TOL,则会要求用户输入。如果为 FALSE,多个匹配结果将返回 NA。
- messages:(逻辑型)是否应打印进度? 默认值: TRUE。
- rows:(数值型)从 1 到无穷大的任意数字。如果默认值为 NA,则考虑所有行。需要注意的是,该函数仍然只能返回一个 tol 类对象,其中包含一到多个标识符。请参阅 get_tolid_(),获取问询过程中显示的全部或部分原始数据。
- sciname:已弃用,请使用sci。
- …:请忽略。
- x:传递给as.tolid()的参数。
- check:(逻辑型)检查 ID 是否与数据库中已有的 ID 匹配,仅用于 as.tolid()。
返回值:作为 S3 类的分类标识符向量。如果未找到分类群,则给出 NA。如果找到一个以上的标识符,如果 ask = TRUE,函数会要求用户输入,否则返回 NA。如果 ask=FALSE 且 rows 不等于 NA,则会返回一个 data.frame,但不是 uid 类,不能像通常那样传递给其他函数。请参阅 get_id_details,了解更多详细信息,包括属性和异常。
示例:get_tolid(sci = "Quercus douglasii")
3.36. get_tpsid(从 Tropicos 获取分类名称的 NameID 代码)
用法:
get_tpsid(sci, ask = TRUE, messages = TRUE, key = NULL, rows = NA, family = NULL, rank = NULL, sciname = NULL, ...)as.tpsid(x, check = TRUE)## S3 method for class 'tpsid'
as.tpsid(x, check = TRUE)## S3 method for class 'character'
as.tpsid(x, check = TRUE)## S3 method for class 'list'
as.tpsid(x, check = TRUE)## S3 method for class 'numeric'
as.tpsid(x, check = TRUE)## S3 method for class 'data.frame'
as.tpsid(x, check = TRUE)## S3 method for class 'tpsid'
as.data.frame(x, ...)get_tpsid_(sci, messages = TRUE, key = NULL, rows = NA, sciname = NULL, ...)
参数:
- sci:(字符型)一个学名或俗名向量。或taxon_state对象。
- ask:(逻辑型)是否应在交互模式下运行 get_tpsid?如果为 “true”,并且为该物种找到了一个以上的 TOL,则会要求用户输入。如果为 FALSE,多个匹配结果将返回 NA。
- messages:(逻辑型)是否应打印进度? 默认值: TRUE。
- key:你的API密钥,参考taxize-authentication。
- rows:(数值型)从 1 到无穷大的任意数字。如果默认值为 NA,则考虑所有行。需要注意的是,该函数仍然只能返回一个 tps 类对象,其中包含一到多个标识符。请参阅 get_tpsid_(),获取问询过程中显示的全部或部分原始数据。
- family:(字符型)科名。可选。详见筛选。
- rank:(字符型)分类阶元名称。详见rank_ref。不过要注意的是,有些数据源使用的是非典型等级,因此请检查数据本身以获取选项。可选。详见筛选。
- sciname:已弃用,请使用sci。
- …:传递给tp_search()的参数。
- x:传递给as.tpsid()的参数。
- check:(逻辑型)检查 ID 是否与数据库中已有的 ID 匹配,仅用于 as.tpsid()。
返回值:作为 S3 类的分类标识符向量。如果未找到分类群,则给出 NA。如果找到一个以上的标识符,如果 ask = TRUE,函数会要求用户输入,否则返回 NA。如果 ask=FALSE 且 rows 不等于 NA,则会返回一个 data.frame,但不是 uid 类,不能像通常那样传递给其他函数。请参阅 get_id_details,了解更多详细信息,包括属性和异常。
筛选:参数 family 和 rank 不用于搜索数据提供者,而是用于过滤数据,使其成为更接近所需目标的子集。对于这两个参数,可以使用 regex 字符串,因为我们内部使用 grep() 进行匹配。过滤将范围缩小到与您的查询相匹配的数据集,并删除其余数据。
示例:get_tpsid(sci='Poa annua')
3.37. get_tsn(获取搜索词的 TSN 代码)
用法:
get_tsn(sci_com, searchtype = "scientific", accepted = FALSE, ask = TRUE, messages = TRUE, rows = NA, searchterm = NULL, ...)as.tsn(x, check = TRUE)## S3 method for class 'tsn'
as.tsn(x, check = TRUE)## S3 method for class 'character'
as.tsn(x, check = TRUE)## S3 method for class 'list'
as.tsn(x, check = TRUE)## S3 method for class 'numeric'
as.tsn(x, check = TRUE)## S3 method for class 'data.frame'
as.tsn(x, check = TRUE)## S3 method for class 'tsn'
as.data.frame(x, ...)get_tsn_(sci_com, messages = TRUE, searchtype = "scientific", accepted = TRUE, rows = NA, searchterm = NULL, ...)
参数:
- sci_com:(字符型)一个学名或俗名向量。或taxon_state对象。
- searchtype:(字符型)“scientific”(默认)或 "common"或任意标准的缩写。
- accepted:(逻辑型)如果设置为 TRUE,则删除TSN不接受的有效名称。设为 FALSE(默认值),则同时返回已接受和未接受的名称。
- ask:(逻辑型)是否应在交互模式下运行 get_tsn?如果为 “true”,并且为该物种找到了一个以上的 TSN,则会要求用户输入。如果为 FALSE,多个匹配结果将返回 NA。
- messages:(逻辑型)是否应打印进度? 默认值: TRUE。
- rows:(数值型)从 1 到无穷大的任意数字。如果默认值为 NA,则考虑所有行。需要注意的是,该函数仍然只能返回一个 tsn 类对象,其中包含一到多个标识符。请参阅 get_tsn_(),获取问询过程中显示的全部或部分原始数据。
- searchterm:已弃用,请使用sci_com。
- …:请忽略。
- x:传递给as.tsn的参数。
- check:(逻辑型)检查 ID 是否与数据库中已有的 ID 匹配,仅用于 as.tsn()。
返回值:作为 S3 类的分类标识符向量。如果未找到分类群,则给出 NA。如果找到一个以上的标识符,如果 ask = TRUE,函数会要求用户输入,否则返回 NA。如果 ask=FALSE 且 rows 不等于 NA,则会返回一个 data.frame,但不是 uid 类,不能像通常那样传递给其他函数。请参阅 get_id_details,了解更多详细信息,包括属性和异常。
示例:get_tsn("Quercus douglasii")
3.38. get_uid(从 NCBI 获取分类名称的 UID 代码)
用法:
get_uid(sci_com, ask = TRUE, messages = TRUE, rows = NA, modifier = NULL, rank_query = NULL, division_filter = NULL, rank_filter = NULL, key = NULL, sciname = NULL, ...)as.uid(x, check = TRUE)## S3 method for class 'uid'
as.uid(x, check = TRUE)## S3 method for class 'character'
as.uid(x, check = TRUE)## S3 method for class 'list'
as.uid(x, check = TRUE)## S3 method for class 'numeric'
as.uid(x, check = TRUE)## S3 method for class 'data.frame'
as.uid(x, check = TRUE)## S3 method for class 'uid'
as.data.frame(x, ...)get_uid_(sci_com, messages = TRUE, rows = NA, key = NULL, sciname = NULL, ...)
参数:
- sci_com:(字符型)一个学名或俗名向量。或taxon_state对象。
- ask:(逻辑型)是否应在交互模式下运行 get_uid?如果为 “true”,并且为该物种找到了一个以上的 TSN,则会要求用户输入。如果为 FALSE,多个匹配结果将返回 NA。
- messages:(逻辑型)是否应打印进度? 默认值: TRUE。
- rows:(数值型)从 1 到无穷大的任意数字。如果默认值为 NA,则考虑所有行。需要注意的是,该函数仍然只能返回一个 uid 类对象,其中包含一到多个标识符。请参阅 get_uid_(),获取问询过程中显示的全部或部分原始数据。
- modifer:(字符型)给定的 sci_com 的修改器。选项包括 选项包括:Organism, Scientific Name, Common Name, All Names, Division, Filter, Lineage,GC、MGC、 Name Tokens、Next Level、PGC、Properties、Rank、Subtree、Synonym、Text Word。这些内容不会被检查,因此请确保输入正确无误。
- rank_query:(字符型)分类等级名称,用于修改发送给 NCBI 的查询。有关可能的选项,请参见 rank_ref。但要注意的是,有些数据源使用非典型等级,因此请检查数据本身以获取选项。可选。参见下面的查询。
- division_filter:(字符型)从 NCBI 获取的用于筛选数据的门类名称。可选。请参阅下面的筛选。
- rank_filter:(字符型)分类等级名称,用于过滤从 NCBI 检索到的数据。有关可能的选项,请参见 rank_ref。不过要注意的是,有些数据源使用非典型等级,因此请查看数据本身的选项。可选。
- key:(字符型)NCBI Entrez API 密钥。可选。
- sciname:已弃用,请使用sci_com。
- …:请忽略。
- x:传递给as.uid()的参数。
- check:(逻辑型)检查 ID 是否与数据库中已有的 ID 匹配,仅用于 as.uid()。
返回值:作为 S3 类的分类标识符向量。如果未找到分类群,则给出 NA。如果找到一个以上的标识符,如果 ask = TRUE,函数会要求用户输入,否则返回 NA。如果 ask=FALSE 且 rows 不等于 NA,则会返回一个 data.frame,但不是 uid 类,不能像通常那样传递给其他函数。请参阅 get_id_details,了解更多详细信息,包括属性和异常。
请求速率限制:如果因超出速率限制而出错,请参阅 taxize_options(),您可以在其中设置 ncbi_sleep。
查询:参数 rank_query 用于向 NCBI 发送搜索结果,而 rank_filter 则用于过滤返回的数据。参数 modifier 在名称中添加修饰符。例如,modifier=“Organism” 会在名称中添加修饰词,例如,Helianthus[Organism]。
筛选:参数 division_filter 和 rank_filter 并不用于搜索数据提供者,而是用于将数据筛选为更接近所需目标的子集。所有这些参数都可以使用 regex 字符串,因为我们内部使用 grep() 进行匹配。过滤将范围缩小到与您的查询相匹配的数据集,并删除其余数据。
注意:NCBI 有时会做一些有趣的事情。例如,如果你搜索羊肚菌(Fringella morel),属名拼写稍有错误,外标又不存在,NCBI 就会给出一个羊肚菌真菌物种。此外,NCBI 并不擅长模糊搜索,因此如果您的名称中存在轻微的拼写错误,您很可能得不到您所期望的结果。教训是:在使用该功能之前,请先清理名称。其他数据源在模糊匹配方面做得更好。
NCBI请求的HTTP版本:本方法硬编码了http_version=2L以便让HTTP请求使用HTTP/1.1访问Entrez API。详见curl::curl_symbols(“CURL_HTTP_VERSION”)。
示例:get_uid(c("Chironomus riparius", "Chaetopteryx"))
相关文章:
)
R语言——taxize(第三部分)
taxize(第三部分) 3. taxize 文档中译3.24. genbank2uid(从 GenBankID 获取 NCBI 分类 UID)3.25. getkey(获取 API 密钥的函数)3.26. get_boldid(获取搜索词的 BOLD(生命条形码&…...

用于神经网络的FLOP和Params计算工具
用于神经网络的FLOP和Params计算工具 1. FlopCountAnalysis pip install fvcoreimport torch from torchvision.models import resnet152, resnet18 from fvcore.nn import FlopCountAnalysis, parameter_count_tablemodel resnet152(num_classes1000)tensor (torch.rand(1…...

CUDA核函数,如何设置grid和block即不超过大小又能够遍历整个volume
此问题答案来自于openAI 1、Grid 大小: Grid 的大小由 dim3 grid 定义,其三个分量分别表示在 x、y、z 方向上的 Grid 数量。Grid 的大小不应该超过 GPU 的最大 Grid 大小。cudaDeviceGetAttribute获取限制。 int maxGridSizeX, maxGridSizeY, maxGridS…...

【Linux】软连接和硬链接:创建、管理和解除链接的操作
文章目录 1. 软链接和硬链接简介2. Linux软链接使用方法3. Linux硬链接使用方法4. 总结 1. 软链接和硬链接简介 什么是软链接 软链接(Symbolic Link),也称为符号链接,是包含了源文件位置信息的特殊文件。它的作用是间接指向一个文件或目录。如果软链接的源文件被删除或移动了,软…...

Matlab群体智能优化算法之海象优化算法(WO)
文章目录 一、灵感来源二、算法的初始化三、GTO的数学模型Phase1:危险信号和安全信号Phase2:迁移(探索)Phase3:繁殖(开发) 四、流程图五、伪代码六、算法复杂度七、WO搜索示意图八、实验分析和结…...

go语言学习-结构体
1、简介 Go语言中的结构体是一种自定义数据类型,可以将不同类型的数据字符组合在一起形成一个单独的实体。结构体可以用于存储和操作复杂的数据结构,以及创建自定义数据类型。通过自定义结构体创建的变量,可以存储不同类型的数据字段。在实际开发中,结构体的用途非常广泛,…...

Stable Diffusion进阶玩法说明
之前章节介绍了Stable Diffusion的入门,介绍了文生图的魅力,可以生成很多漂亮的照片,非常棒 传送门: Stable Diffusion新手村-我们一起完成AI绘画-CSDN博客 那我们今天就进一步讲讲这个Stable Diffusion还能做些什么, …...
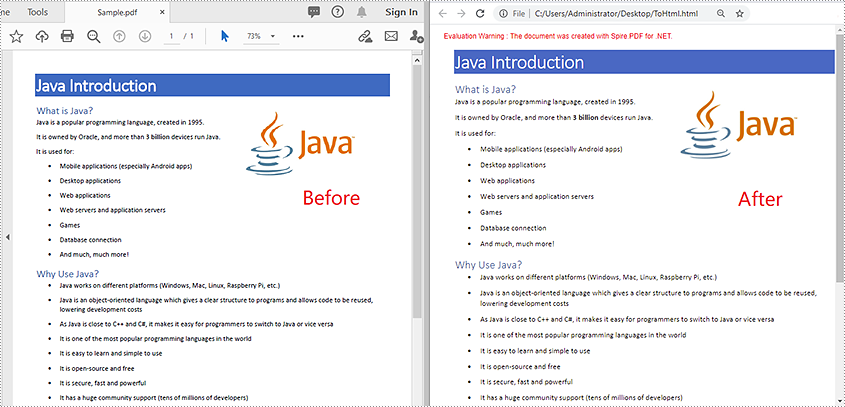
PDF控件Spire.PDF for .NET【转换】演示:将PDF 转换为 HTML
由于各种原因,您可能想要将 PDF 转换为 HTML。例如,您需要在社交媒体上共享 PDF 文档或在网络上发布 PDF 内容。在本文中,您将了解如何使用Spire.PDF for .NET在 C# 和 VB.NET 中将 PDF 转换为 HTML。 Spire.Doc 是一款专门对 Word 文档进行…...
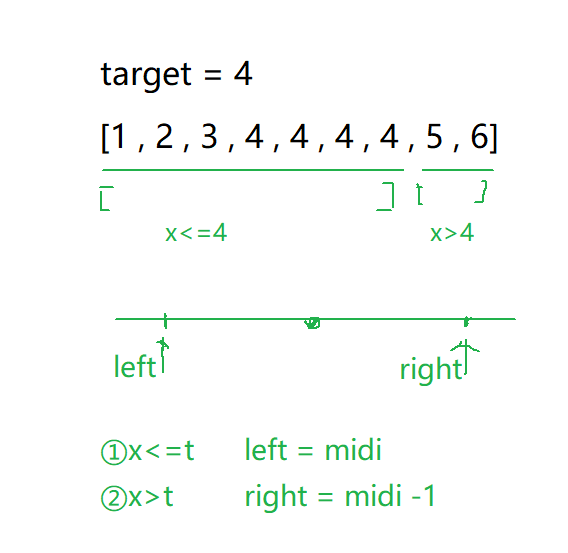
二分查找——34. 在排序数组中查找元素的第一个和最后一个位置
文章目录 1. 题目2. 算法原理2.1 暴力解法2.2 二分查找左端点查找右端点查找 3. 代码实现4. 二分模板 1. 题目 题目链接:34. 在排序数组中查找元素的第一个和最后一个位置 - 力扣(LeetCode) 给你一个按照非递减顺序排列的整数数组 nums&#…...

MFC中的主窗口以及如何通过代码找到主窗口
MFC程序中的主窗口 在MFC程序中,可以设置主窗口,主窗口在应用程序类中设置,即设置应用程序类(通常以App结尾,通常包括InitInstance方法的类)的m_pMainWnd属性,将其设置为主窗口的指针。 一般在…...
图文详解)
Typora下载安装 (Mac和Windows)图文详解
目录 Windows版本 一、下载 二、安装 Mac版本 一、下载 二、安装...
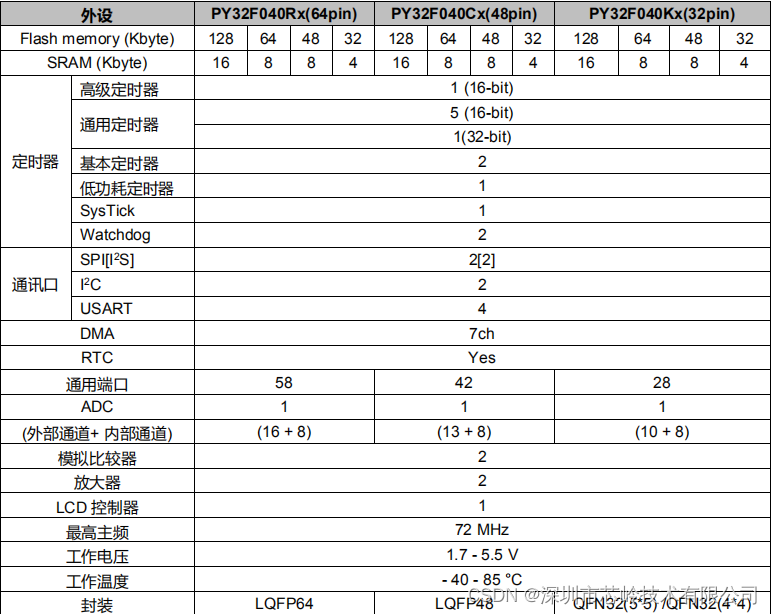
32位单片机PY32F040,主频72M,外设丰富,支持断码LCD
PY32F040 系列微控制器采用高性能的 32 位 ARM Cortex-M0 内核,宽电压工作范围的 MCU。嵌入高达 128 Kbytes flash 和 16 Kbytes SRAM 存储器,最高工作频率 72 MHz。LQFP64封装两块出头就可以拿到,我们还有开发板和开发资料帮助客户更好的开发。 PY32F040 系列微控…...
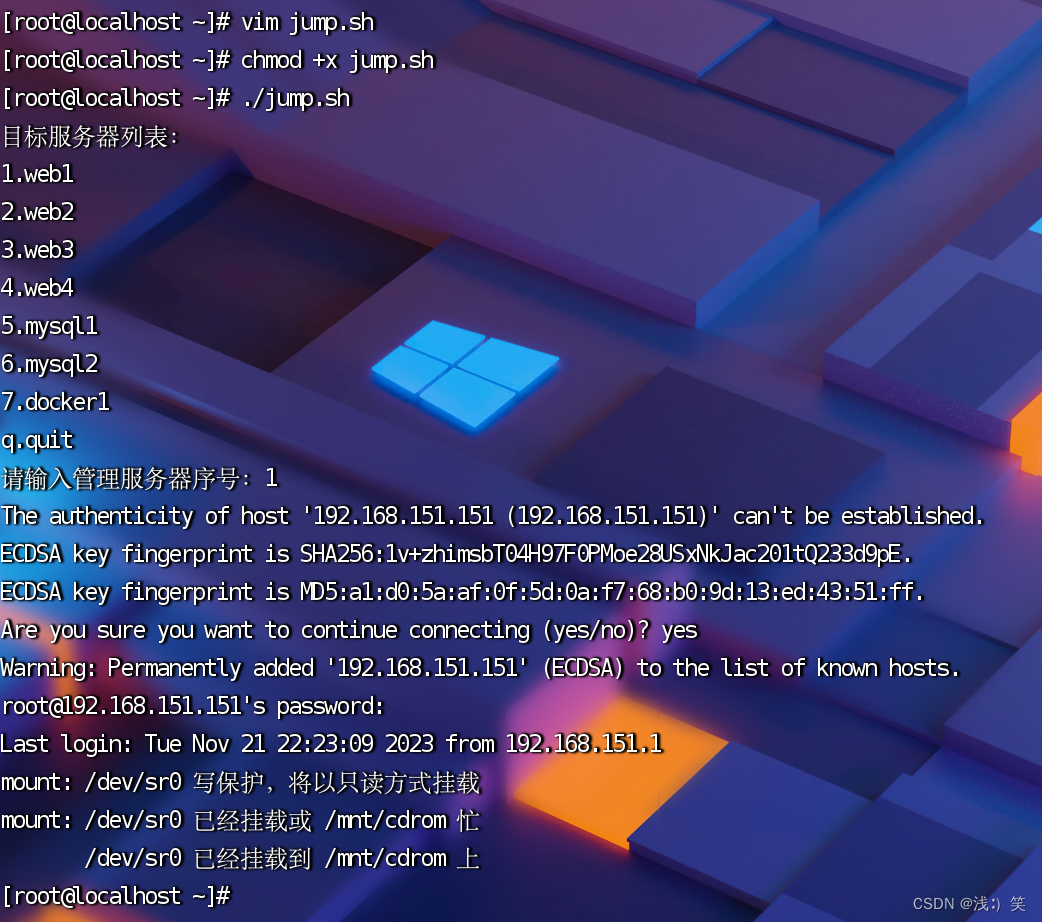
Shell判断:模式匹配:case(二)
简单的JumpServer 1、需求:工作中,我们需要管理N多个服务器。那么访问服务器就是一件繁琐的事情。通过shell编程,编写跳板程序。当我们需要访问服务器时,看一眼服务器列表名,按一下数字,就登录成功了。 2、…...
从android.graphics.Path中取出Point点,Kotlin
从android.graphics.Path中取出Point点,Kotlin /*** 从一条Path中获取多少个Point点*/private fun getPoints(path: Path, pointCount: Int): Array<FloatPoint?> {val points arrayOfNulls<FloatPoint>(pointCount)val pm PathMeasure(path, false)…...

力扣C++学习笔记——C++ 给vector去重
要使用std::set对std::vector进行去重操作,您可以将向量中的元素插入到集合中,因为std::set会自动去除重复元素。然后,您可以将集合中的元素重新存回向量中。以下是一个示例代码,演示如何使用std::set对std::vector进行去重&#…...

Flutter笔记:使用相机
Flutter笔记 使用相机 作者:李俊才 (jcLee95):https://blog.csdn.net/qq_28550263 邮箱 :291148484163.com 本文地址:https://blog.csdn.net/qq_28550263/article/details/134493373 【简介】本文介绍在 Fl…...

包装类型的缓存机制
Java 基本数据类型的包装类型的大部分都用到了缓存机制来提升性能。 Byte,Short,Integer,Long 这 4 种包装类默认创建了数值 [-128,127] 的相应类型的缓存数据,Character 创建了数值在 [0,127] 范围的缓存数据,Boolean 直接返回 True or Fal…...

【BUG】第一次创建vue3+vite项目启动报错Error: Cannot find module ‘worker_threads‘
问题描述 第一次创建vue3vite项目启动报错如下: Error: Cannot find module worker_threadsat Function.Module._resolveFilename (internal/modules/cjs/loader.js:636:15)at Function.Module._load (internal/modules/cjs/loader.js:562:25)at Module.require (…...
多目标应用:基于非支配排序的鲸鱼优化算法NSWOA求解微电网多目标优化调度(MATLAB代码)
一、微网系统运行优化模型 微电网优化模型介绍: 微电网多目标优化调度模型简介_IT猿手的博客-CSDN博客 二、基于非支配排序的鲸鱼优化算法NSWOA 基于非支配排序的鲸鱼优化算法NSWOA简介: 三、基于非支配排序的鲸鱼优化算法NSWOA求解微电网多目标优化…...
的几种方法)
网络爬虫|Selenium——find_element_by_xpath()的几种方法
Xpath (XML Path Language),是W3C定义的用来在XML文档中选择节点的语言 一、从根目录/开始 有点像Linux的文件查看,/代表根目录,一级一级的查找,直接子节点,相当于css_selector中的>号 /html/body/div/p 二、根据…...

保姆级教程:手把手教你用UDS 0x31服务搞定车窗防夹标定与胎压学习
实战指南:UDS 0x31服务在车窗防夹与胎压学习中的深度应用 当车辆仪表盘突然亮起胎压报警灯,或是车窗升降时反复触发防夹功能,背后往往隐藏着需要专业诊断工具介入的标定问题。UDS诊断协议中的0x31服务(RoutineControl)…...

为AI智能体构建实战技能包:自我修复、发布检查与经验萃取
1. 项目概述:为AI智能体构建一套实战技能包最近在折腾AI智能体(AI Agent)的落地应用,发现一个挺普遍的问题:很多智能体在演示时表现惊艳,但一到真实、复杂的项目环境里,就很容易“翻车”。要么是…...

别再只会用默认参数了!用R包pheatmap绘制高颜值热图的10个实用技巧
别再只会用默认参数了!用R包pheatmap绘制高颜值热图的10个实用技巧 在科研论文、数据分析报告或教学演示中,一张精心设计的热图往往能直观呈现复杂数据背后的规律。pheatmap作为R语言中最受欢迎的热图绘制工具之一,其默认参数虽能快速生成基础…...

代码生成图像技术:原理、应用与优化策略
1. 技术背景与核心价值在数字内容创作领域,代码生成图像技术正在颠覆传统设计流程。这项技术允许开发者通过编写结构化代码描述来生成精确的视觉内容,其核心价值体现在三个维度:首先,它实现了设计意图的精确传递。与人工绘制可能产…...

动态智能体集群编排器:AI团队协同与成本优化实战
1. 项目概述:动态智能体集群编排器最近在折腾一个挺有意思的开源项目,叫“动态智能体集群编排器”。简单来说,这玩意儿能帮你管理一大群AI智能体,让它们像一支训练有素的军队一样协同工作,去完成一个复杂的任务。传统的…...

Oatmeal:基于DSL的轻量级HTTP接口自动化测试与CI/CD集成实践
1. 项目概述:一个轻量级的HTTP请求模拟与测试工具 如果你是一名后端开发者,或者经常需要与各种API接口打交道,那么你一定对“如何高效、便捷地测试HTTP接口”这个问题深有感触。无论是开发初期验证接口逻辑,还是集成测试时模拟上…...

AI Agent思考过程可视化直播:streamYourClaw架构与部署实战
1. 项目概述:一个让AI思考过程“直播”出来的开源系统最近在捣鼓AI Agent,发现一个挺有意思的事儿:我们能看到Agent的最终输出,但它内部的“思考”过程——比如它怎么拆解任务、如何决策、遇到了什么问题——对用户来说基本是个黑…...

Vidura开源框架:模块化AI对话编排与自动化评估实战指南
1. 项目概述:一个开源的AI对话编排与评估框架最近在折腾AI应用开发,特别是涉及到多模型对话、复杂工作流编排和效果评估时,总感觉市面上现成的工具要么太重,要么太零散。直到我发现了Vidura这个项目,它像是一套为AI对话…...

用Zig重写LLM推理引擎:性能提升20%的底层优化实践
1. 项目概述:为什么用Zig重写一个LLM推理引擎? 如果你关注过小型语言模型(LLM)的部署和推理,大概率听说过 Andrej Karpathy 的 llama2.c 。这个项目用纯C语言实现了Meta的Llama 2模型推理,以其极致的简洁…...
)
jieba-analysis(Java 版结巴分词)
jieba-analysis(Java 版结巴分词)虽然只有 9 个核心类,但它完整复现了 Python jieba 的三大分词模式,并高效实现了中文分词的核心流程。下面我用技术拆解 代码逻辑映射的方式,告诉你它到底做了哪些事:✅ 一…...