FreeRTOS内存管理分析
目录
heap_1.c内存管理算法
heap_2.c内存管理算法
heap_3.c内存管理算法
heap_4.c内存管理算法
heap_5.c内存管理算法
内存管理对应用程序和操作系统来说非常重要,而内存对于嵌入式系统来说是寸土寸金的资源,FreeRTOS操作系统将内核与内存管理分开实现,操作系统内核仅规定了必要的内存管理函数原型,而不关心这些函数的具体实现。这样做大有好处,可以增加系统的灵活性,不同的应用场合可以使用不同的内存分配实现,选择对自己更有利的内存管理算法。比如对于安全型的嵌入式系统,通常不允许动态分配内存,那么可以采用非常简单的内存管理策略,一经申请的内存,甚至不允许被释放。
FreeRTOS内核规定的几个内存管理的函数原型为:
1. void *pvPortMalloc( size_t xSize ) :内存申请函数
2. void vPortFree( void *pv ) :内存释放函数
3. void vPortInitialiseBlocks( void ) :初始化内存堆函数
4. size_t xPortGetFreeHeapSize( void ) :获取当前未分配的内存堆大小
5. size_t xPortGetMinimumEverFreeHeapSize( void ):获取未分配的内存堆历史最小值
FreeRTOS中内存管理的接口函数为pvPortMalloc、vPortFree,对应于C库的malloc和free函数。
源码中对应的提供了5个文件,对应内存管理的5种方法。
| 文件 | 优点 | 缺点 |
| heap_1.c | 分配简单,时间确定 | 只分配,不回收 |
| heap_2.c | 动态分配,最佳匹配 | 碎片,时间不定 |
| heap_3.c | 调用标准库函数 | 速度慢,时间不定 |
| heap_4.c | 相邻空闲内存可以合并 | 可解决碎片问题,时间不定 |
| heap_5.c | 在heap_4.c基础上支持分隔的内存块 | 可解决碎片问题,时间不定 |
对于heap_1.c和heap_2.c和heap_4.c这三种内存管理算法,内存堆实际上是一个很大的静态数组,定义为:
static uint8_t ucHeap[ configTOTAL_HEAP_SIZE ];其中宏configTOTAL_HEAP_SIZE用来定义内存堆的大小,这个宏在FreeRTOSConfig.h中设置。
对于heap_3.c,这种策略只是简单的包装了标准库中的malloc()和free()函数,包装后的malloc()和free()函数具备线程保护。因此,内存堆需要通过编译器或者启动文件设置堆空间。
heap_5.c比较有趣,它允许程序设置多个非连续内存堆,比如需要快速访问的内存堆设置在片内RAM,稍微慢速访问的内存堆设置在外部RAM。每个内存堆的起始地址和大小由应用程序设计者定义。(需要手动自己定义一个数组,手动调用函数初始化内存)
heap_1.c内存管理算法
通过阅读heap_1.c的源码分析可以知道,它只实现了pvPortMalloc,没有实现vPortFree.
如果你的程序不需要删除内核对象,那么可以使用heap_1.c,它只分配不回收内存:
- 实现最简单
- 没有碎片问题
- 一些要求非常严格的系统里,不允许使用动态内存,就可以使用heap_1
对于这种内存分配,我们可以把内存看成一个一根完整的长面包,每次申请内存,就从一端切下适当长度的面包返回给申请者,知道面包被分配完毕,就这么简单。
它的实现原理很简单,首先定义一个大数组:
/* Allocate the memory for the heap. */
#if ( configAPPLICATION_ALLOCATED_HEAP == 1 )/* The application writer has already defined the array used for the RTOS
* heap - probably so it can be placed in a special segment or address. */extern uint8_t ucHeap[ configTOTAL_HEAP_SIZE ];
#elsestatic uint8_t ucHeap[ configTOTAL_HEAP_SIZE ];
#endif /* configAPPLICATION_ALLOCATED_HEAP */
然后对于 pvPortMalloc 调用时,从这个数组中分配空间。
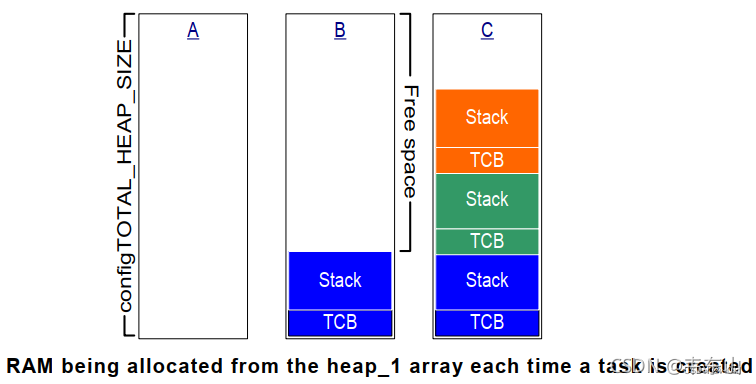
FreeRTOS在创建任务时,需要2个内核对象:task control block(TCB)、stack。
使用heap_1时,内存分配过程如下图所示:
- A:创建任务之前整个数组都是空闲的
- B:创建第1个任务之后,蓝色区域被分配出去了
- C:创建3个任务之后的数组使用情况
内存申请:pvPortMalloc
/*-----------------------------------------------------------*/void *pvPortMalloc( size_t xWantedSize )
{
void *pvReturn = NULL;
static uint8_t *pucAlignedHeap = NULL;/* Ensure that blocks are always aligned to the required number of bytes. */#if( portBYTE_ALIGNMENT != 1 ){if( xWantedSize & portBYTE_ALIGNMENT_MASK ){/* Byte alignment required. */xWantedSize += ( portBYTE_ALIGNMENT - ( xWantedSize & portBYTE_ALIGNMENT_MASK ) );}}#endifvTaskSuspendAll();{if( pucAlignedHeap == NULL ){/* Ensure the heap starts on a correctly aligned boundary. */pucAlignedHeap = ( uint8_t * ) ( ( ( portPOINTER_SIZE_TYPE ) &ucHeap[ portBYTE_ALIGNMENT ] ) & ( ~( ( portPOINTER_SIZE_TYPE ) portBYTE_ALIGNMENT_MASK ) ) );}/* Check there is enough room left for the allocation. */if( ( ( xNextFreeByte + xWantedSize ) < configADJUSTED_HEAP_SIZE ) &&( ( xNextFreeByte + xWantedSize ) > xNextFreeByte ) )/* Check for overflow. */{/* Return the next free byte then increment the index past thisblock. */pvReturn = pucAlignedHeap + xNextFreeByte;xNextFreeByte += xWantedSize;}traceMALLOC( pvReturn, xWantedSize );}( void ) xTaskResumeAll();#if( configUSE_MALLOC_FAILED_HOOK == 1 ){if( pvReturn == NULL ){extern void vApplicationMallocFailedHook( void );vApplicationMallocFailedHook();}}#endifreturn pvReturn;
}
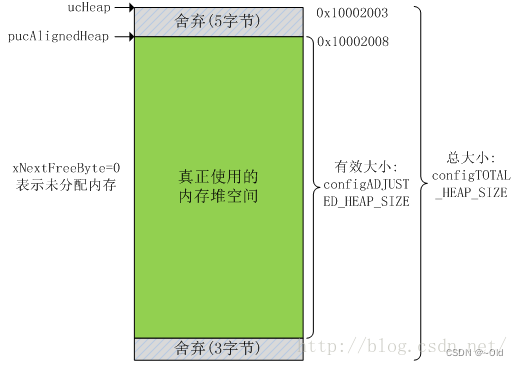
如果是第一次执行这个函数,需要将变量pucAlignedHeap指向内存堆区域第一个地址对齐处。我们上面说内存堆其实是一个大数组,编译器为这个数组分配的起始地址是随机的,可能不符合我们的对齐需要,这时候要进行调整。比如数组地址是0x20000001,这时候一些芯片是对齐才能工作,所以代码一开始设置的内存初始状态如下图所示:

在申请内存过程中同样会对要申请的内存大小做一个字节对齐的操作(向上对齐) ,比如对于8字节对齐的系统来说, 你申请11个字节大小的内存,这时候向上对齐就是16字节,接下来就是挂起调度器,防止多个任务同时申请内存,因为内存是不可重入的(使用了静态变量)。
分配内存的过程如下图:

下面是一个更加清晰的整体的一个分配内存的图:
内存分配完成后,不管有没有分配成功都恢复之前挂起的调度器。
如果内存分配不成功,这里最可能是内存堆空间不够用了,会调用一个钩子函数vApplicationMallocFailedHook()。这个钩子函数由应用程序提供,通常我们可以打印内存分配设备信息或者点亮也故障指示灯。
heap_2.c内存管理算法
Heap_2之所以还保留,只是为了兼容以前的代码。新设计中不再推荐使用Heap_2。建议使用Heap_4来替代Heap_2,更加高效。
Heap_2也是在数组上分配内存,跟Heap_1不一样的地方在于:
- Heap_2使用最佳匹配算法(best fit)来分配内存
- 它支持vPortFree
最佳匹配算法:
- 假设heap有3块空闲内存:5字节、25字节、100字节
- pvPortMalloc想申请20字节
- 找出最小的、能满足pvPortMalloc的内存:25字节
- 把它划分为20字节、5字节
- 返回这20字节的地址
- 剩下的5字节仍然是空闲状态,留给后续的pvPortMalloc使用
与Heap_4相比,Heap_2不会合并相邻的空闲内存,所以Heap_2会导致严重的"碎片化"问题。
但是,如果申请、分配内存时大小总是相同的,这类场景下Heap_2没有碎片化的问题。所以它适合这种场景:频繁地创建、删除任务,但是任务的栈大小都是相同的(创建任务时,需要分配TCB和栈,TCB总是一样的)。
虽然不再推荐使用heap_2,但是它的效率还是远高于malloc、free。
Tips: 其实heap_2.c算法就是在heap_1.c的基础上进行的改进,其中可以思考为什么heap_1.c没办法实现free函数吗,因为free函数释放内存只传入你要释放内存的地址,对于要释放多少呢,heap_1.c算法是没有记录的,我记得我在学习C语言的时候也想过这个问题,free函数只传入要释放内存的地址,它怎么知道要释放多大呢,在操作系统的学习中了解过这部分知识,其实申请的时候,会有一个头部在申请内存的前面,这个添加头部的方法其实很常见。

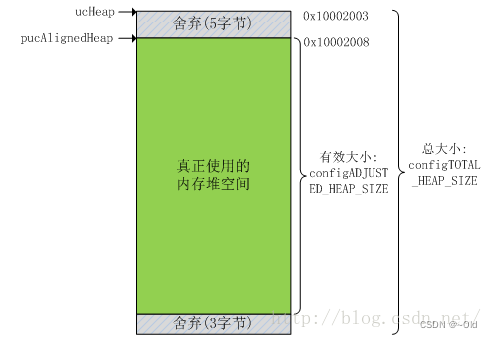
局部静态变量pucAlignedHeap指向对齐后的内存堆起始位置。地址对齐的原因在第一种内存管理策略中已经说明。假如内存堆数组ucHeap从RAM地址0x10002003处开始,系统按照8字节对齐,则对齐后的内存堆与第一个内存管理策略一样,如图所示:
与第一种内存管理策略不同,第二种内存管理策略使用一个链表结构来跟踪记录空闲内存块,将空闲块组成一个链表。头部结构体定义为:
typedef struct A_BLOCK_LINK
{struct A_BLOCK_LINK *pxNextFreeBlock; /*<< The next free block in the list. */size_t xBlockSize; /*<< The size of the free block. */
} BlockLink_t;static BlockLink_t xStart, xEnd;两个BlockLink_t类型的全局静态变量xStart和xEnd用来标识空闲内存块的起始和结束。刚开始时,整个内存堆有效空间就是一个空闲块:

当申请N字节内存时,实际上不仅需要分配N字节内存,还要分配一个BlockLink_t类型结构体空间,用于描述这个内存块,结构体空间位于空闲内存块的最开始处。当然,和第一种内存管理策略一样,申请的内存大小加上BlockLink_t类型结构体大小之后也要向上扩大到对齐字节数的整数倍 。
我们看一下内存申请过程:首先计算实际要分配的内存大小,判断申请的内存是否合法。如果合法则从链表头xStart开始查找,如果某个空闲块的xBlockSize字段大小能容得下要申请的内存,则从这块内存取出合适的部分返回给申请者,剩下的内存块组成一个新的空闲块,按照空闲块的大小顺序插入到空闲块链表中,小块在前大块在后。
/*-----------------------------------------------------------*/void *pvPortMalloc( size_t xWantedSize )
{
BlockLink_t *pxBlock, *pxPreviousBlock, *pxNewBlockLink;
static BaseType_t xHeapHasBeenInitialised = pdFALSE;
void *pvReturn = NULL;vTaskSuspendAll();{/* If this is the first call to malloc then the heap will requireinitialisation to setup the list of free blocks. */if( xHeapHasBeenInitialised == pdFALSE ){prvHeapInit();xHeapHasBeenInitialised = pdTRUE;}/* The wanted size is increased so it can contain a BlockLink_tstructure in addition to the requested amount of bytes. */if( xWantedSize > 0 ){xWantedSize += heapSTRUCT_SIZE;/* Ensure that blocks are always aligned to the required number of bytes. */if( ( xWantedSize & portBYTE_ALIGNMENT_MASK ) != 0 ){/* Byte alignment required. */xWantedSize += ( portBYTE_ALIGNMENT - ( xWantedSize & portBYTE_ALIGNMENT_MASK ) );}}if( ( xWantedSize > 0 ) && ( xWantedSize < configADJUSTED_HEAP_SIZE ) ){/* Blocks are stored in byte order - traverse the list from the start(smallest) block until one of adequate size is found. */pxPreviousBlock = &xStart;pxBlock = xStart.pxNextFreeBlock;while( ( pxBlock->xBlockSize < xWantedSize ) && ( pxBlock->pxNextFreeBlock != NULL ) ){pxPreviousBlock = pxBlock;pxBlock = pxBlock->pxNextFreeBlock;}/* If we found the end marker then a block of adequate size was not found. */if( pxBlock != &xEnd ){/* Return the memory space - jumping over the BlockLink_t structureat its start. */pvReturn = ( void * ) ( ( ( uint8_t * ) pxPreviousBlock->pxNextFreeBlock ) + heapSTRUCT_SIZE );/* This block is being returned for use so must be taken out of thelist of free blocks. */pxPreviousBlock->pxNextFreeBlock = pxBlock->pxNextFreeBlock;/* If the block is larger than required it can be split into two. */if( ( pxBlock->xBlockSize - xWantedSize ) > heapMINIMUM_BLOCK_SIZE ){/* This block is to be split into two. Create a new blockfollowing the number of bytes requested. The void cast isused to prevent byte alignment warnings from the compiler. */pxNewBlockLink = ( void * ) ( ( ( uint8_t * ) pxBlock ) + xWantedSize );/* Calculate the sizes of two blocks split from the singleblock. */pxNewBlockLink->xBlockSize = pxBlock->xBlockSize - xWantedSize;pxBlock->xBlockSize = xWantedSize;/* Insert the new block into the list of free blocks. */prvInsertBlockIntoFreeList( ( pxNewBlockLink ) );}xFreeBytesRemaining -= pxBlock->xBlockSize;}}traceMALLOC( pvReturn, xWantedSize );}( void ) xTaskResumeAll();#if( configUSE_MALLOC_FAILED_HOOK == 1 ){if( pvReturn == NULL ){extern void vApplicationMallocFailedHook( void );vApplicationMallocFailedHook();}}#endifreturn pvReturn;
}
阅读源码的个人理解:
第一次调用malloc申请内存时需要进行heap的初始化操作,而它的初始化操作就是将heap加上一个头部,以及初始化xStart和xEnd,heap_2.c的内存管理是通过块Block进行管理的。
- 在申请内存块的时候,使用的是最佳匹配算法,在空闲块的链表中找到一个刚好合适又最小的块,如果申请之后还剩下比较大的内存则会进行拆分,把剩余的内存块添加回空闲内存块管理的链表中,按照内存大小进行插入。
- 正是因为上面空闲内存的插入是按照大小进行插入这一个特点,注定了空闲内存块之间是不能进行合并的,所以会出现内存碎片的情况.
所以我们可以知道heap_2.c适合对于那些频繁申请释放固定大小内存的场合,这样不会造成内存碎片。
/*-----------------------------------------------------------*/void vPortFree( void *pv )
{
uint8_t *puc = ( uint8_t * ) pv;
BlockLink_t *pxLink;if( pv != NULL ){/* The memory being freed will have an BlockLink_t structure immediatelybefore it. */puc -= heapSTRUCT_SIZE;/* This unexpected casting is to keep some compilers from issuingbyte alignment warnings. */pxLink = ( void * ) puc;vTaskSuspendAll();{/* Add this block to the list of free blocks. */prvInsertBlockIntoFreeList( ( ( BlockLink_t * ) pxLink ) );xFreeBytesRemaining += pxLink->xBlockSize;traceFREE( pv, pxLink->xBlockSize );}( void ) xTaskResumeAll();}
}
阅读代码释放内存的原理也很简单,无非就是通过要释放内存的地址往前推得到内存块结构体,就可以知道要释放的内存大小了。
heap_3.c内存管理算法
第三种内存管理策略简单的封装了标准库中的malloc()和free()函数,采用的封装方式是操作内存前挂起调度器、完成后再恢复调度器。封装后的malloc()和free()函数具备线程保护。
第一种和第二种内存管理策略都是通过定义一个大数组作为内存堆,数组的大小由宏configTOTAL_HEAP_SIZE指定。第三种内存管理策略与前两种不同,它不再需要通过数组定义内存堆,而是需要使用编译器设置内存堆空间,一般在启动代码中设置。因此宏configTOTAL_HEAP_SIZE对这种内存管理策略是无效的。
heap_4.c内存管理算法
跟Heap_1、Heap_2一样,Heap_4也是使用大数组来分配内存。
Heap_4使用首次适应算法(first fit)来分配内存。它还会把相邻的空闲内存合并为一个更大的空闲内存,这有助于较少内存的碎片问题。
首次适应算法:
- 假设堆中有3块空闲内存:5字节、200字节、100字节
- pvPortMalloc想申请20字节
- 找出第1个能满足pvPortMalloc的内存:200字节
- 把它划分为20字节、180字节
- 返回这20字节的地址
- 剩下的180字节仍然是空闲状态,留给后续的pvPortMalloc使用
Heap_4会把相邻空闲内存合并为一个大的空闲内存,可以较少内存的碎片化问题。适用于这种场景:频繁地分配、释放不同大小的内存。
Tips:其实个人感觉第四种内存管理算法就是在第二种内存管理算法heap_2.c的基础上再次进行改进而已, 由于heap_2.c算法存在内存碎片的问题,所以heap_4.c可以将相邻的内存块进行合并,这就意味着空闲内存块之间是按照地址进行存放的,不是像heap_2.c一样按照大小进行排序管理的。
和第二种内存管理策略一样,它也使用一个链表结构来跟踪记录空闲内存块。头部结构体定义是一样的。
与第二种内存管理策略一样,空闲内存块也是以单链表的形式组织起来的,BlockLink_t类型的全局静态变量xStart表示链表头,但第四种内存管理策略的链表尾保存在内存堆空间最后位置,并使用BlockLink_t指针类型局部静态变量pxEnd指向这个区域(第二种内存管理策略使用静态变量xEnd表示链表尾)(这里我想吐槽一下,感觉完全没必要啊,完全可以使用和heap_2.c一样的管理,可能这里是为了节省内存,能省就省就和迷你列表项一样🤣)
重点:第四种内存管理算法和第二种内存管理算法之间最大的不同就是,第四种内存管理算法的空闲内存块链表不是以内存块大小为存储顺序,而是以内存块起始地址大小为存储顺序的,地址小的在前,地址大的在后,其实这好像是必须的,因为你要合并相邻的内存块肯定地址要按顺序来才能合并嘛🤣,这是为了适应合并算法而作的改变。
/*-----------------------------------------------------------*/void *pvPortMalloc( size_t xWantedSize )
{
BlockLink_t *pxBlock, *pxPreviousBlock, *pxNewBlockLink;
void *pvReturn = NULL;vTaskSuspendAll();{/* If this is the first call to malloc then the heap will requireinitialisation to setup the list of free blocks. */if( pxEnd == NULL ){prvHeapInit();}else{mtCOVERAGE_TEST_MARKER();}/* Check the requested block size is not so large that the top bit isset. The top bit of the block size member of the BlockLink_t structureis used to determine who owns the block - the application or thekernel, so it must be free. */if( ( xWantedSize & xBlockAllocatedBit ) == 0 ){/* The wanted size is increased so it can contain a BlockLink_tstructure in addition to the requested amount of bytes. */if( xWantedSize > 0 ){xWantedSize += xHeapStructSize;/* Ensure that blocks are always aligned to the required numberof bytes. */if( ( xWantedSize & portBYTE_ALIGNMENT_MASK ) != 0x00 ){/* Byte alignment required. */xWantedSize += ( portBYTE_ALIGNMENT - ( xWantedSize & portBYTE_ALIGNMENT_MASK ) );configASSERT( ( xWantedSize & portBYTE_ALIGNMENT_MASK ) == 0 );}else{mtCOVERAGE_TEST_MARKER();}}else{mtCOVERAGE_TEST_MARKER();}if( ( xWantedSize > 0 ) && ( xWantedSize <= xFreeBytesRemaining ) ){/* Traverse the list from the start (lowest address) block untilone of adequate size is found. */pxPreviousBlock = &xStart;pxBlock = xStart.pxNextFreeBlock;while( ( pxBlock->xBlockSize < xWantedSize ) && ( pxBlock->pxNextFreeBlock != NULL ) ){pxPreviousBlock = pxBlock;pxBlock = pxBlock->pxNextFreeBlock;}/* If the end marker was reached then a block of adequate sizewas not found. */if( pxBlock != pxEnd ){/* Return the memory space pointed to - jumping over theBlockLink_t structure at its start. */pvReturn = ( void * ) ( ( ( uint8_t * ) pxPreviousBlock->pxNextFreeBlock ) + xHeapStructSize );/* This block is being returned for use so must be taken outof the list of free blocks. */pxPreviousBlock->pxNextFreeBlock = pxBlock->pxNextFreeBlock;/* If the block is larger than required it can be split intotwo. */if( ( pxBlock->xBlockSize - xWantedSize ) > heapMINIMUM_BLOCK_SIZE ){/* This block is to be split into two. Create a newblock following the number of bytes requested. The voidcast is used to prevent byte alignment warnings from thecompiler. */pxNewBlockLink = ( void * ) ( ( ( uint8_t * ) pxBlock ) + xWantedSize );configASSERT( ( ( ( size_t ) pxNewBlockLink ) & portBYTE_ALIGNMENT_MASK ) == 0 );/* Calculate the sizes of two blocks split from thesingle block. */pxNewBlockLink->xBlockSize = pxBlock->xBlockSize - xWantedSize;pxBlock->xBlockSize = xWantedSize;/* Insert the new block into the list of free blocks. */prvInsertBlockIntoFreeList( pxNewBlockLink );}else{mtCOVERAGE_TEST_MARKER();}xFreeBytesRemaining -= pxBlock->xBlockSize;if( xFreeBytesRemaining < xMinimumEverFreeBytesRemaining ){xMinimumEverFreeBytesRemaining = xFreeBytesRemaining;}else{mtCOVERAGE_TEST_MARKER();}/* The block is being returned - it is allocated and ownedby the application and has no "next" block. */pxBlock->xBlockSize |= xBlockAllocatedBit;pxBlock->pxNextFreeBlock = NULL;xNumberOfSuccessfulAllocations++;}else{mtCOVERAGE_TEST_MARKER();}}else{mtCOVERAGE_TEST_MARKER();}}else{mtCOVERAGE_TEST_MARKER();}traceMALLOC( pvReturn, xWantedSize );}( void ) xTaskResumeAll();#if( configUSE_MALLOC_FAILED_HOOK == 1 ){if( pvReturn == NULL ){extern void vApplicationMallocFailedHook( void );vApplicationMallocFailedHook();}else{mtCOVERAGE_TEST_MARKER();}}#endifconfigASSERT( ( ( ( size_t ) pvReturn ) & ( size_t ) portBYTE_ALIGNMENT_MASK ) == 0 );return pvReturn;
}
申请内存的代码和heap_2.c相比无非就是heap的初始化对于xEnd有点不一样,一个是指针一个是变量,然后就是空闲内存块的插入算法是不一样,一个按照地址来一个按照大小插入。
/*-----------------------------------------------------------*/static void prvInsertBlockIntoFreeList( BlockLink_t *pxBlockToInsert )
{
BlockLink_t *pxIterator;
uint8_t *puc;/* Iterate through the list until a block is found that has a higher addressthan the block being inserted. */for( pxIterator = &xStart; pxIterator->pxNextFreeBlock < pxBlockToInsert; pxIterator = pxIterator->pxNextFreeBlock ){/* Nothing to do here, just iterate to the right position. */}/* Do the block being inserted, and the block it is being inserted aftermake a contiguous block of memory? */puc = ( uint8_t * ) pxIterator;if( ( puc + pxIterator->xBlockSize ) == ( uint8_t * ) pxBlockToInsert ){pxIterator->xBlockSize += pxBlockToInsert->xBlockSize;pxBlockToInsert = pxIterator;}else{mtCOVERAGE_TEST_MARKER();}/* Do the block being inserted, and the block it is being inserted beforemake a contiguous block of memory? */puc = ( uint8_t * ) pxBlockToInsert;if( ( puc + pxBlockToInsert->xBlockSize ) == ( uint8_t * ) pxIterator->pxNextFreeBlock ){if( pxIterator->pxNextFreeBlock != pxEnd ){/* Form one big block from the two blocks. */pxBlockToInsert->xBlockSize += pxIterator->pxNextFreeBlock->xBlockSize;pxBlockToInsert->pxNextFreeBlock = pxIterator->pxNextFreeBlock->pxNextFreeBlock;}else{pxBlockToInsert->pxNextFreeBlock = pxEnd;}}else{pxBlockToInsert->pxNextFreeBlock = pxIterator->pxNextFreeBlock;}/* If the block being inserted plugged a gab, so was merged with the blockbefore and the block after, then it's pxNextFreeBlock pointer will havealready been set, and should not be set here as that would make it pointto itself. */if( pxIterator != pxBlockToInsert ){pxIterator->pxNextFreeBlock = pxBlockToInsert;}else{mtCOVERAGE_TEST_MARKER();}
}
这个链表插入函数,在内存释放函数中也会进行调用,它也是内存释放的关键代码, 它里面最关键的就是要进行前后相邻内存块是否能进行合并的判断和合并操作,先和前面的内存块判断是否进行合并,然后再和后面的内存块进行同样的操作。总的来说其实不是特别难,而且heap_4.c是一种比较均衡的内存管理算法,克服了前面heap_1.c和heap_2.c的问题,所以大多数还是采用这个内存管理算法的(以前不懂得时候,就感觉它是万能的,选这个准没错😂)。
heap_5.c内存管理算法
Heap_5分配内存、释放内存的算法跟Heap_4是一样的。
相比于Heap_4,Heap_5并不局限于管理一个大数组:它可以管理多块、分隔开的内存。
在嵌入式系统中,内存的地址可能并不连续,我们heap_4.c是一块连续的内存(声明的一个大数组嘛),而有些时候有的系统中内存地址可能不连续,这种场景下可以使用Heap_5。
既然内存是分隔开的,那么就需要进行初始化:确定这些内存块在哪、多大:
在使用pvPortMalloc之前,必须先指定内存块的信息(需要用户自己指定)
使用vPortDefineHeapRegions来指定这些信息
怎么指定一块内存?使用如下结构体:
typedef struct HeapRegion
{uint8_t * pucStartAddress; // 起始地址size_t xSizeInBytes; // 大小
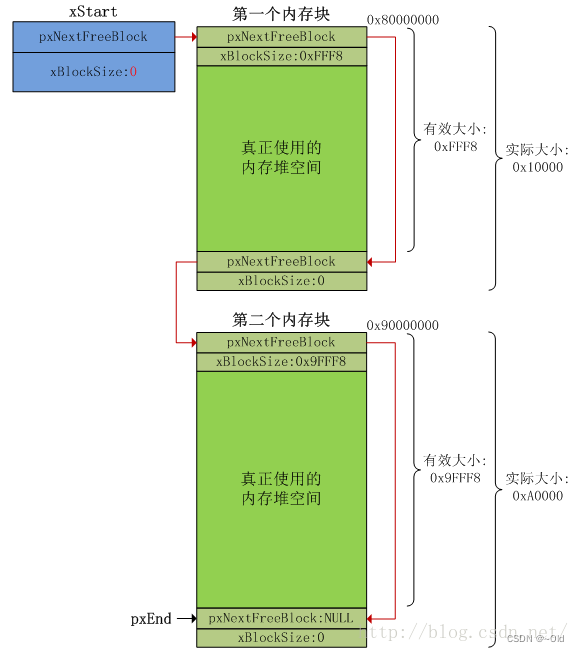
} HeapRegion_t;怎么指定多块内存?使用一个HeapRegion_t数组,在这个数组中,低地址在前、高地址在后(必须这样做)。
比如:
HeapRegion_t xHeapRegions[] =
{{ ( uint8_t * ) 0x80000000UL, 0x10000 }, // 起始地址0x80000000,大小0x10000{ ( uint8_t * ) 0x90000000UL, 0xa0000 }, // 起始地址0x90000000,大小0xa0000{ NULL, 0 } // 表示数组结束};因为heap_5.c的malloc函数没有像前面几种内存管理算法一样,第一次调用的时候进行了内存heap的初始化,所以在使用任何内存分配和释放操作前调用vPortDefineHeapRegions()函数初始化这些内存堆(用户自己手动调用)。
第一、第二和第四种内存管理策略都是利用一个大数组作为内存堆使用,并且只需要应用程序指定数组的大小(通过宏configTOTAL_HEAP_SIZE定义),数组定义由内存管理策略实现。第五种内存管理策略有些不同,首先它允许跨内存区定义多个内存堆,比如在片内RAM中定义一个内存堆,还可以在片外RAM再定义内存堆;其次,用户需要指定每个内存堆区域的起始地址和内存堆大小、将它们放在一个HeapRegion_t结构体类型数组中,并需要在使用任何内存分配和释放操作前调用vPortDefineHeapRegions()函数初始化这些内存堆。
/*-----------------------------------------------------------*/void vPortDefineHeapRegions( const HeapRegion_t * const pxHeapRegions )
{
BlockLink_t *pxFirstFreeBlockInRegion = NULL, *pxPreviousFreeBlock;
size_t xAlignedHeap;
size_t xTotalRegionSize, xTotalHeapSize = 0;
BaseType_t xDefinedRegions = 0;
size_t xAddress;
const HeapRegion_t *pxHeapRegion;/* Can only call once! */configASSERT( pxEnd == NULL );pxHeapRegion = &( pxHeapRegions[ xDefinedRegions ] );while( pxHeapRegion->xSizeInBytes > 0 ){xTotalRegionSize = pxHeapRegion->xSizeInBytes;/* Ensure the heap region starts on a correctly aligned boundary. */xAddress = ( size_t ) pxHeapRegion->pucStartAddress;if( ( xAddress & portBYTE_ALIGNMENT_MASK ) != 0 ){xAddress += ( portBYTE_ALIGNMENT - 1 );xAddress &= ~portBYTE_ALIGNMENT_MASK;/* Adjust the size for the bytes lost to alignment. */xTotalRegionSize -= xAddress - ( size_t ) pxHeapRegion->pucStartAddress;}xAlignedHeap = xAddress;/* Set xStart if it has not already been set. */if( xDefinedRegions == 0 ){/* xStart is used to hold a pointer to the first item in the list offree blocks. The void cast is used to prevent compiler warnings. */xStart.pxNextFreeBlock = ( BlockLink_t * ) xAlignedHeap;xStart.xBlockSize = ( size_t ) 0;}else{/* Should only get here if one region has already been added to theheap. */configASSERT( pxEnd != NULL );/* Check blocks are passed in with increasing start addresses. */configASSERT( xAddress > ( size_t ) pxEnd );}/* Remember the location of the end marker in the previous region, ifany. */pxPreviousFreeBlock = pxEnd;/* pxEnd is used to mark the end of the list of free blocks and isinserted at the end of the region space. */xAddress = xAlignedHeap + xTotalRegionSize;xAddress -= xHeapStructSize;xAddress &= ~portBYTE_ALIGNMENT_MASK;pxEnd = ( BlockLink_t * ) xAddress;pxEnd->xBlockSize = 0;pxEnd->pxNextFreeBlock = NULL;/* To start with there is a single free block in this region that issized to take up the entire heap region minus the space taken by thefree block structure. */pxFirstFreeBlockInRegion = ( BlockLink_t * ) xAlignedHeap;pxFirstFreeBlockInRegion->xBlockSize = xAddress - ( size_t ) pxFirstFreeBlockInRegion;pxFirstFreeBlockInRegion->pxNextFreeBlock = pxEnd;/* If this is not the first region that makes up the entire heap spacethen link the previous region to this region. */if( pxPreviousFreeBlock != NULL ){pxPreviousFreeBlock->pxNextFreeBlock = pxFirstFreeBlockInRegion;}xTotalHeapSize += pxFirstFreeBlockInRegion->xBlockSize;/* Move onto the next HeapRegion_t structure. */xDefinedRegions++;pxHeapRegion = &( pxHeapRegions[ xDefinedRegions ] );}xMinimumEverFreeBytesRemaining = xTotalHeapSize;xFreeBytesRemaining = xTotalHeapSize;/* Check something was actually defined before it is accessed. */configASSERT( xTotalHeapSize );/* Work out the position of the top bit in a size_t variable. */xBlockAllocatedBit = ( ( size_t ) 1 ) << ( ( sizeof( size_t ) * heapBITS_PER_BYTE ) - 1 );
}
这个函数可以看到,代码量还是很大的🤣,但其实原理就是以链表的形式管理这些分隔的内存块。

一旦内存堆初始化之后,内存申请和释放都和第四种内存管理策略相同,不再单独分析。
第五种内存管理策略允许内存堆跨越多个非连续的内存区,并且需要显示的初始化内存堆,除此之外其它操作都和第四种内存管理策略十分相似。
相关文章:
FreeRTOS内存管理分析
目录 heap_1.c内存管理算法 heap_2.c内存管理算法 heap_3.c内存管理算法 heap_4.c内存管理算法 heap_5.c内存管理算法 内存管理对应用程序和操作系统来说非常重要,而内存对于嵌入式系统来说是寸土寸金的资源,FreeRTOS操作系统将内核与内存管理分开实…...

hashMap索引原理
平日里面经常使用map这种数据结构,令人称奇的是他的访问速度为什么那么快?为什么可以通过key以接近O(1)的速度查找? 一、基础数据结构特点分析 1.1数组 查找的时间复杂度为O(1) 插入时间复杂度为O(n) 1.2链表 查找的时间复杂度为O(n) 插…...

qcow2、raw、vmdk等镜像格式工具
如果没有qemu,可以从这里下载安装:https://qemu.weilnetz.de/w64/...
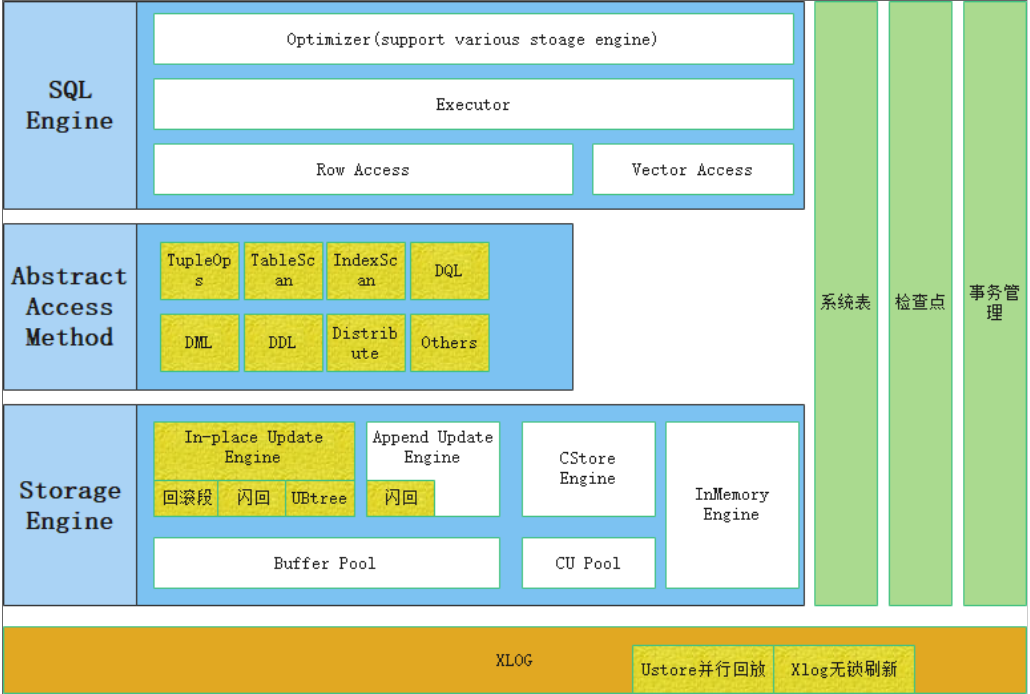
GaussDB新特性Ustore存储引擎介绍
1、 Ustore和Astore存储引擎介绍 Ustore存储引擎,又名In-place Update存储引擎(原地更新),是openGauss 内核新增的一种存储模式。此前的版本使用的行存储引擎是Append Update(追加更新)模式。相比于Append…...
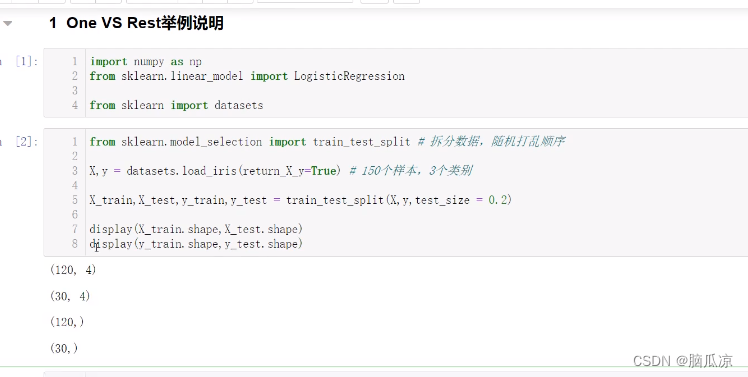
人工智能基础_机器学习046_OVR模型多分类器的使用_逻辑回归OVR建模与概率预测---人工智能工作笔记0086
首先我们来看一下什么是OVR分类.我们知道sigmoid函数可以用来进行二分类,那么多分类怎么实现呢?其中一个方法就是使用OVR进行把多分类转换成二分类进行计算. OVR,全称One-vs-Rest,是一种将多分类问题转化为多个二分类子问题的策略。在这种策略中,多分类问题被分解为若干个二…...
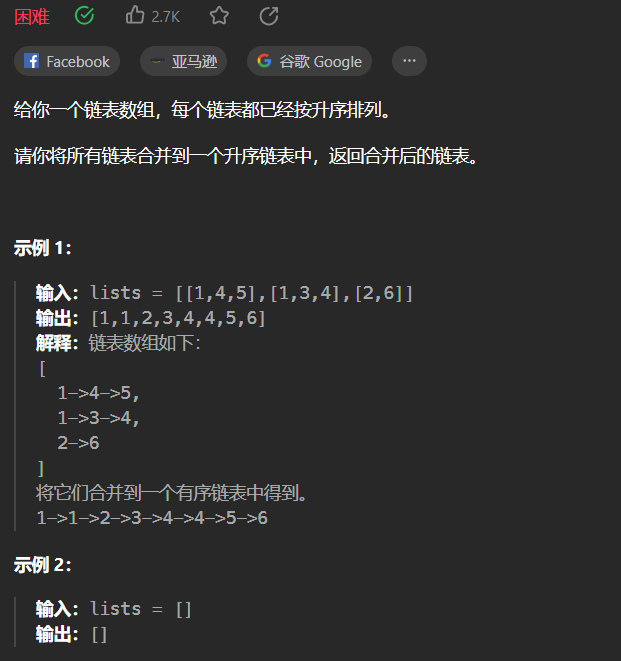
【LeetCode刷题-链表】--23.合并K个升序链表
23.合并K个升序链表 方法:顺序合并 在前面已经知道合并两个升序链表的前提下,用一个变量ans来维护以及合并的链表,第i次循环把第i个链表和ans合并,答案保存到ans中 /*** Definition for singly-linked list.* public class List…...

强化学习笔记
这里写自定义目录标题 参考资料基础知识16.3 有模型学习16.3.1 策略评估16.3.2 策略改进16.3.3 策略迭代16.3.3 值迭代 16.4 免模型学习16.4.1 蒙特卡罗强化学习16.4.2 时序差分学习Sarsa算法:同策略算法(on-policy):行为策略是目…...

经典双指针算法试题(一)
📘北尘_:个人主页 🌎个人专栏:《Linux操作系统》《经典算法试题 》《C》 《数据结构与算法》 ☀️走在路上,不忘来时的初心 文章目录 一、移动零1、题目讲解2、讲解算法原理3、代码实现 二、复写零1、题目讲解2、讲解算法原理3、…...
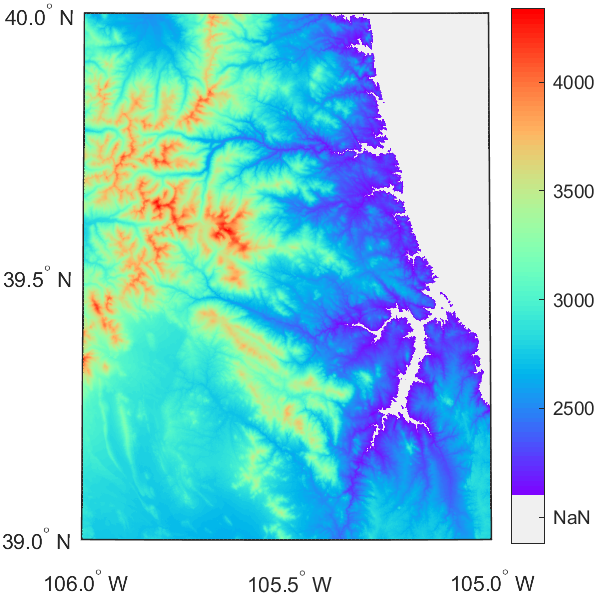
MATLAB | 绘图复刻(十三) | 带NaN图例的地图绘制
有粉丝问我地图绘制如何添加NaN,大概像这样: 或者这样: 直接上干货: 原始绘图 假设我们有这样的一张图地图,注意运行本文代码需要去matlab官网下载Mapping Toolbox工具箱,但是其实原理都是相似的&…...

netty整合websocket(完美教程)
websocket的介绍: WebSocket是一种在网络通信中的协议,它是独立于HTTP协议的。该协议基于TCP/IP协议,可以提供双向通讯并保有状态。这意味着客户端和服务器可以进行实时响应,并且这种响应是双向的。WebSocket协议端口通常是80&am…...

选择PC示波器的10种理由!
PC示波器(PCs)在测试仪器领域中的关键项目上正迅速地取代传统的数字存储示波器(DSOs),其中有十个理由: 小巧和便携示波器利用你的PC显示器实现大屏幕和精细彩色显示信号存储只受限于你的PC存储器大小捕捉波…...
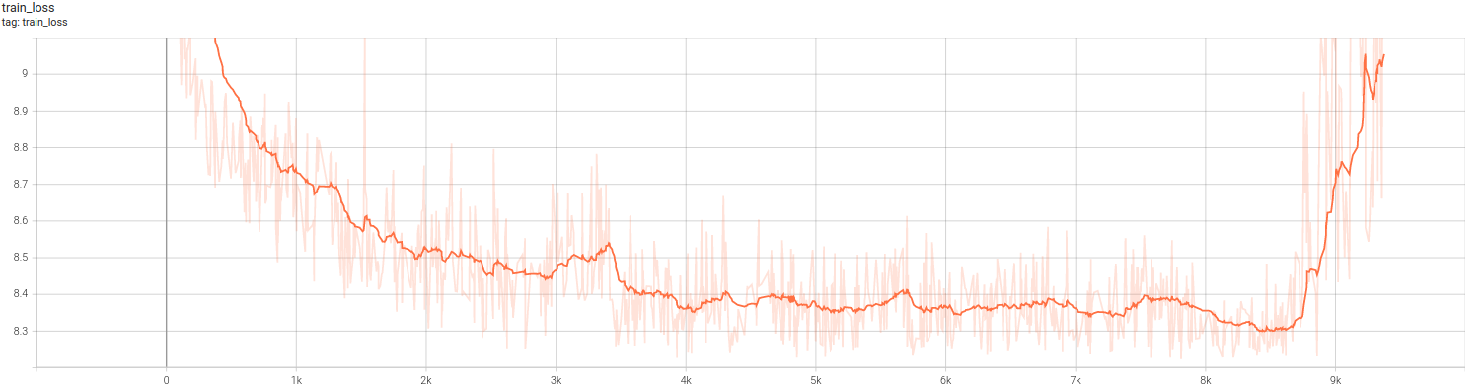
【pytorch深度学习 应用篇02】训练中loss图的解读,训练中的问题与经验汇总
文章目录 loss图解析train loss ↘ \searrow ↘ ↗ \nearrow ↗ 先降后升 loss图解析 train loss ↘ \searrow ↘ 不断下降,test loss ↗ \nearrow ↗ 不断上升:原因很多,我是把workers1,batchSize8192train loss ↘ \searro…...

uniapp 微信小程序如何实现多个item列表的分享
以下代码是某个循环里面的item <button class"cu-btn" style"background-color: transparent;padding: 0;"open-type"share" :data-tree"item.treeId" :data-project"item.projectId"v-if"typeId1 && userI…...
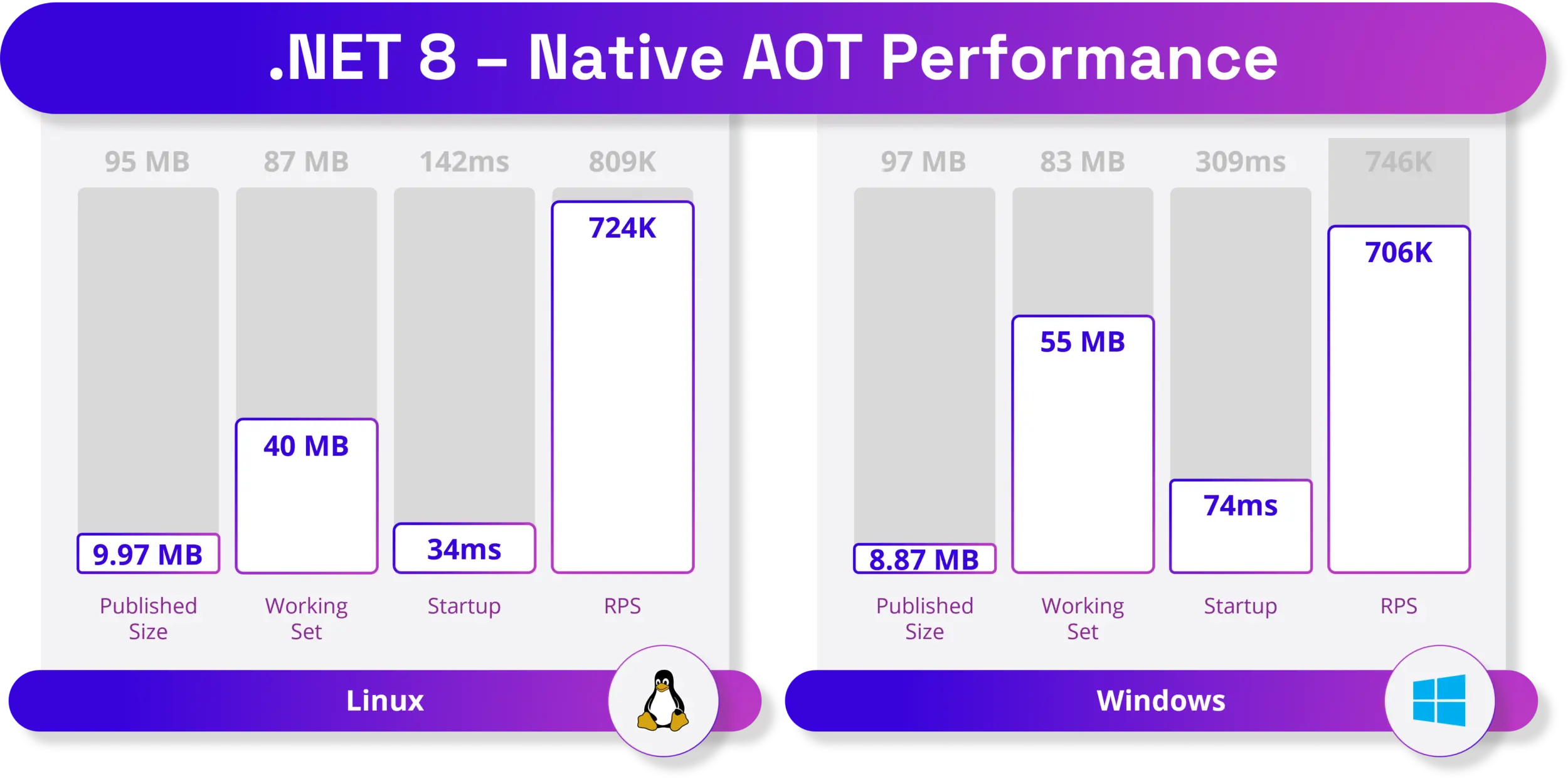
.NET 8 正式 GA 遥遥领先
.NET 8 一正式 已正式 GA。 微软称 .NET 8 提供了数以千计的性能、稳定性和安全性改进,以及平台和工具增强功能,有助于提高开发者的工作效率和创新速度。 比如 .NET 8 为 Android 和 WASM 引入了全新的 AOT 模式、改进 System.Text.Json,以…...

2216. 美化数组的最少删除数 --力扣 --JAVA
题目 给你一个下标从 0 开始的整数数组 nums ,如果满足下述条件,则认为数组 nums 是一个 美丽数组 : nums.length 为偶数对所有满足 i % 2 0 的下标 i ,nums[i] ! nums[i 1] 均成立 注意,空数组同样认为是美丽数组。…...

DDD 领域驱动设计
文章目录 请解释下什么是 DDD 领域驱动设计DDD 的四层领域模型是怎样的?包含哪些基础概念?DDD 中的贫血模型和充血模型有什么区别在 DDD 中,如何处理模型的聚合和聚合根DDD 中的实体和值对象有什么区别?在 DDD 中,如何…...
转型做视频了,博客就是稿子,继续坚持写博客,同时发布视频,能写博客说明思路清晰了,能再讲明白,理解就更透彻了,紧跟上时代发展。
1,今天特别记录下,B站给开通了《合集》功能 最近使用视频制作了几个视频。播放量还不错,最好的已经到了 2.6K了。 然后粉丝也涨到了 200个。 添加链接描述 紧跟时代:从写博客到录视频,粉丝大涨,突破200个&…...

小众市场:探索跨境电商中的利基领域
随着全球数字化和互联网的普及,跨境电子商务已经成为了一个蓬勃发展的产业。从亚马逊到阿里巴巴,大型电商平台已经占据了很大一部分市场份额。 然而,在这个竞争激烈的领域,寻找小众市场和利基领域可能是一种成功的策略。本文将探…...

C++中的mutable关键字
mutable是C中的一个关键字,它用来修饰类的成员变量。 当我们将一个成员变量声明为mutable时,就意味着这个成员变量可以被类的任何方法修改,即使这个方法是const类型的。这是因为mutable关键字可以打破const类型的限制,使得const类…...
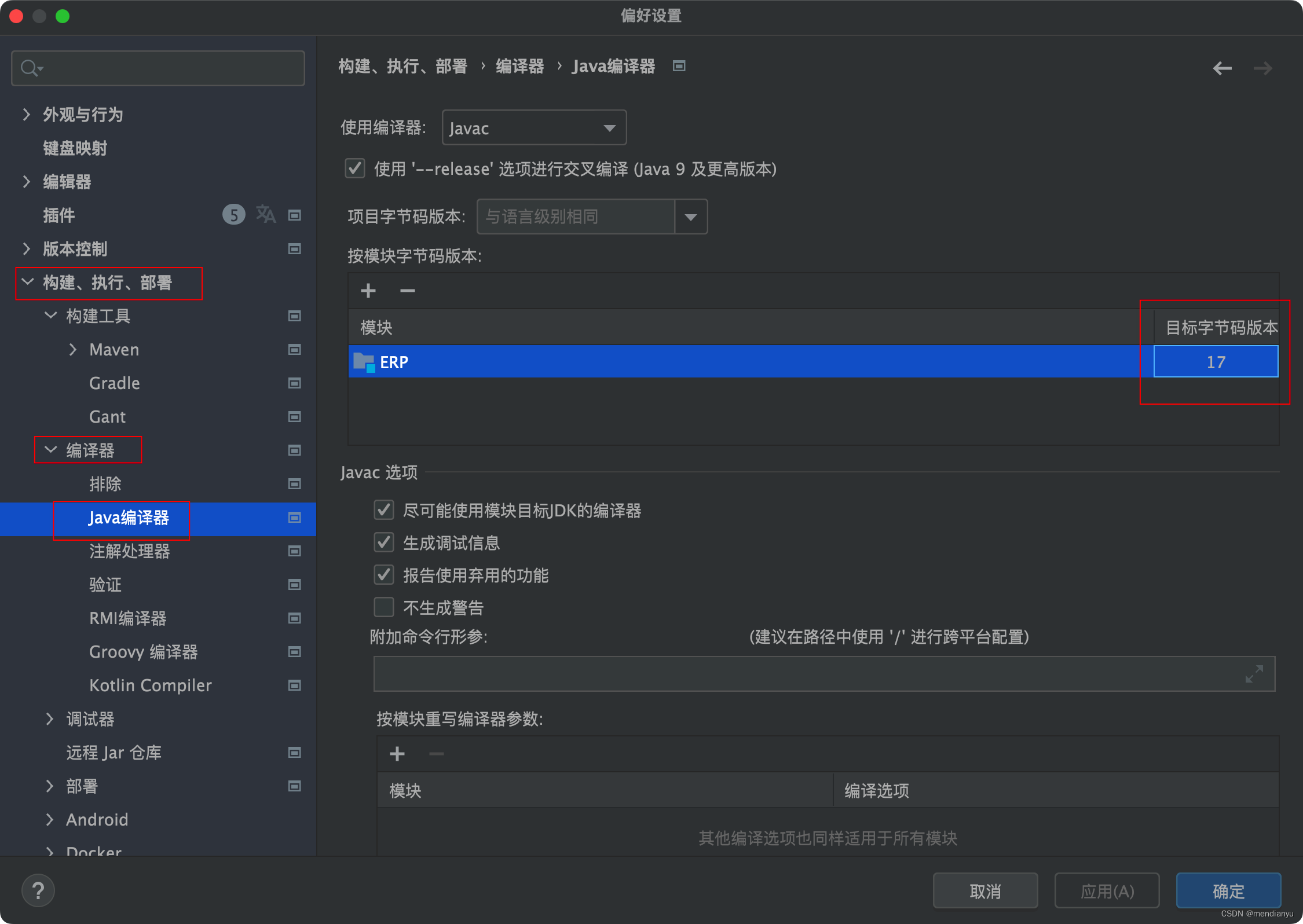
java: 无效的目标发行版: 17 问题解决
今天在写完类点击运行后显示java: 无效的目标发行版: 17 网上查询了一番,发现有几个地方需要注意。 还有一个就是设置中,下面的就是我本次问题所在,不知道为什么,他自动添加了下面的东西 一个方法是把目标字节码版本改为正确的&a…...

工业控制系统安全补丁管理:IT与OT差异、实战流程与深度防御
1. 工业安全补丁管理的核心困境:当IT思维遇上OT现实如果你在IT部门工作,习惯了每周二凌晨的自动补丁更新,或者对“零日漏洞”的响应时间以小时计,那么当你第一次接触工业控制系统(ICS)或运营技术࿰…...

Godot游戏集成Nakama服务器:开源后端引擎与实时对战开发指南
1. 项目概述:当游戏服务器遇上开源引擎如果你正在用Godot引擎开发一款需要在线功能的游戏,比如多人对战、排行榜、实时聊天或者玩家数据云端存储,那你大概率绕不开一个核心问题:后端服务器怎么搞?自己从头搭建一套&…...

一码溯源坚守本心 京尚重构智慧厨房品质新生态
在消费升级与健康理念普及的当下,食品接触器具的品质与安全备受关注。京尚智慧厨房正式推出“一锅一码一匠心”全链条溯源体系,以数字化技术实现从泥到火的生产全程可追溯,用透明化管理彰显品牌责任与硬核实力,为行业树立品质新标…...

干货!万字长文解析 Agent 框架中的上下文管理策略
0x01. 背景 (1)什么叫上下文工程(Context Engineering)? “上下文工程”简单来说,就是在一些LLM的约束下(如上下文窗口大小、注意力长度的限制),优化上下文token的效用…...

3D NAND闪存技术:从量产到普及的挑战与演进
1. 项目概述:当3D NAND遇上量产与市场的十字路口2013年底,当三星宣布开始大规模生产128Gb的3D NAND闪存时,整个存储行业都为之震动。这感觉就像大家还在努力把平房(2D NAND)盖得更密、更小,突然有人宣布要盖…...

KORG logue SDK音频开发实战:从DSP原理到嵌入式音乐合成器编程
1. 项目概述:深入KORG logue SDK的音频开发世界如果你是一位嵌入式开发者,同时对音乐合成器抱有浓厚的兴趣,那么“korginc/logue-sdk”这个项目标题,很可能已经让你心跳加速了。这不仅仅是GitHub上的一个代码仓库,它更…...
 从零开始:Tushare环境配置与基础数据获取)
(初阶) 从零开始:Tushare环境配置与基础数据获取
去年接触到量化投资这个概念时,我面对的第一个问题不是策略怎么写、回测怎么做,而是——数据从哪来?市面上主流的金融数据终端动辄上万一年,对个人量化爱好者来说实在吃不消。 幸运的是,我遇到了Tushare。这是一个完全…...

别再傻傻分不清了!AMBA AHB2和AHB-Lite到底差在哪?给SoC新手的保姆级对比指南
AMBA AHB2与AHB-Lite协议深度对比:从设计哲学到芯片选型实战 在SoC设计的浩瀚宇宙中,总线协议如同连接各个功能模块的神经网络。当我第一次面对AMBA总线家族中这对"双胞胎"——AHB2和AHB-Lite时,那种困惑感至今记忆犹新。它们看似相…...

软件定义无线电与认知无线电技术解析及应用
1. 无线通信技术演进:从硬件定义到软件智能 三十多年前,当我第一次以初级射频工程师的身份踏入实验室时,我们还在使用分立晶体管搭建电路,一个简单的接收机可能需要花费数周时间手工调试。如今,我的智能手机里集成了数…...

NCCL EP架构设计与GPU通信优化实践
1. NCCL EP架构设计解析NCCL EP的核心创新在于将MoE通信从传统的CPU协调模式转变为GPU直接发起的通信范式。这种设计充分利用了现代GPU的计算与通信能力,实现了通信与计算的紧密耦合。整个系统架构可分为三个关键层次:通信基础设施层:基于NCC…...