为什么选择B+树作为数据库索引结构?
背景
首先,来谈谈B树。为什么要使用B树?我们需要明白以下两个事实:
【事实1】
不同容量的存储器,访问速度差异悬殊。以磁盘和内存为例,访问磁盘的时间大概是ms级的,访问内存的时间大概是ns级的。有个形象的比喻,若一次内存访问需要1秒,则一次外存访问需要1天。所以,现在的存储系统,都是分级组织的。
最常用的数据尽可能放在更高层、更小的存储器中,只有在当前层找不到,才向更低层、更大的存储器中寻找。这也就解释了,当处理大规模数据的时候(指无法将数据一次性存入内存),算法的实际运行时间,往往取决于数据在不同存储级别之间的IO次数。因此,要想提升速度,关键在于减少IO。
【事实2】
磁盘读取数据是以数据块(block)(或者:页,page)为基本单位的,位于同一数据块中的所有数据都能被一次性全部读取出来。
换句话说,从磁盘中读1B,与读1KB几乎一样快!因此,想要提升速度,应该利用外存批量访问的特点,在一些文章中,也称其为磁盘预读。系统之所以这么设计,是基于一个著名的局部性原理:
当一个数据被用到时,其附近的数据也通常会马上被使用,程序运行期间所需要的数据通常比较集中
B树
假设有10亿条记录(100010001000),如果使用平衡二叉搜索树(Balanced Binary Search Tree, BBST),最坏的情况下,查找需要log(2, 10^9) = 30次 I/O 操作,且每次只能读出一个关键字(即如果这次读出来的关键字不是我要查找的,就要再进行一次I/O去读取数据)。如果换成B树,会是怎样的情况呢?
B 树是为了磁盘或其它辅助存储设备而设计的一种多叉平衡搜索树。多级存储系统中使用B树,可针对外部查找,大大减少I/O次数。通过B树,可充分利用外存对批量访问的高效支持,将此特点转化为优点。每下降一层,都以超级结点为单位(超级结点就是指一个结点内包含多个关键字),从磁盘中读入一组关键字。那么,具体多大为一组呢?
一个节点存放多少数据视磁盘的数据块大小而定,比如磁盘中1 block的大小有1024KB,假设每个关键字的大小为 4 Byte,则可设定每一组的大小m = 1024 KB / 4 Byte = 256。目前,多数数据库系统采用 m = 200~300。假设取m = 256,则B树存储1亿条数据的树的高度大概是 log(256, 10^9) = 4,也就是单次查询所需要进行的I/O次数不超过 4 次,由此大大减少了I/O次数。
一般来说,B树的根节点常驻于内存中,B树的查找过程是这样的:首先,由于一个节点内包含多个(比如,是256个)关键码,所以需要先顺序/二分来查找,如果找到则查找成功;如果失败,则根据相应的引用从磁盘中读入下一层的节点数据(这里就涉及到一次磁盘I/O),同样的在节点内顺序查找,如此往复进行…事实上,B树查找所消耗的时间很大一部分花在了I/O上,所以减少I/O次数是非常重要的。
B树的定义
B树就是平衡的多路搜索树,所谓的m阶B树,即m路平衡搜索树。根据维基百科的定义,一棵m阶B树需满足以下要求:
- 每个结点至多含有m个分支节点(m>=2)。
- 除根结点之外的每个非叶结点,至少含有┌m/2┐个分支。
- 若根结点不是叶子结点,则至少有2个孩子。
- 一个含有k个孩子的非叶结点包含k-1个关键字。(每个结点内的关键字按升序排列)
- 所有的叶子结点都出现在同一层。实际上这些结点并不存在,可以看作是外部结点。
根据节点的分支的上下限,也可以称其为(┌m/2┐, m)树。比如,阶数m=4时,这样的B树也可以称为(2,4)树。(事实上,(2,4)树是一棵比较特殊的B树,它和红黑树有着特别的渊源!后面谈及红黑树时会谈到。)
并且,每个内部结点的关键字都作为其子树的分隔值。比如,某结点含有2个关键字(假设为a1和a2),也就是说该结点含有3个子树。那么,最左子树的关键字均小于a1;中间子树的关键字介于a1~a2;最右子树的关键字均大于a2。
示例,一棵3阶的B树是这个样子:
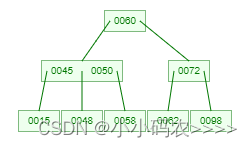
B树的高度(了解)
当树的高度最大时,则每个结点含有的关键字数应该尽量少。根据定义,根结点至少有2个孩子(即1个关键字),除根结点之外的非叶结点至少有┌m/2┐个孩子(即┌m/2┐-1个关键字),为了描述方便,这里令p = ┌m/2┐。
- 第1层 1个结点 (含1个关键字)
- 第2层 2个结点 (含2*(p-1)个关键字)
- 第3层 2p个结点 (含2p*(p-1)^2个关键字)
- …
- 第h层 2p^(h-2)个结点
故总的结点个数n≥ 1+(p-1)*[2+2p+2p2+…+2p(h-2)]≥ 2p^(h-1)-1
从而推导出 h ≤ log_p[(n+1)/2] + 1 (其中p为底数,p=┌m/2┐)
最小高度
当树的高度最低时,则每个结点的关键字都至多含有m个孩子(即m-1个关键字),则有
n ≤ (m-1)*(1 + m + m^2 +...+ m^(h-1)) = m^h - 1
从而推导出 h ≥ log_m(n+1) (其中m为底数)
B+树
B+树的定义
B+树是B树的一个变体,B+树与B树最大的区别在于:
- 叶子结点包含全部关键字以及指向相应记录的指针,而且叶结点中的关键字按大小顺序排列,相邻叶结点用指针连接。
- 非叶结点仅存储其子树的最大(或最小)关键字,可以看成是索引。
一棵3阶的B+树示例:(好好体会和B树的区别,两者的关键字是一样的)
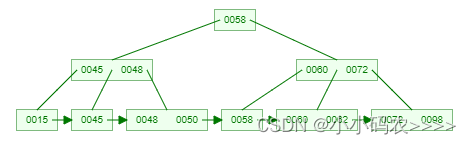
问:为什么说B+树比B树更适合实际应用中操作系统的文件索引和数据库索引?
答: - B+树更适合外部存储。由于内结点不存放真正的数据(只是存放其子树的最大或最小的关键字,作为索引),一个结点可以存储更多的关键字,每个结点能索引的范围更大更精确,也意味着B+树单次磁盘IO的信息量大于B树,I/O的次数相对减少。
- MySQL是一种关系型数据库,区间访问是常见的一种情况,B+树叶结点增加的链指针,加强了区间访问性,可使用在区间查询的场景;而使用B树则无法进行区间查找。
出处:cnblogs.com/kkbill/p/11381783.html
相关文章:
为什么选择B+树作为数据库索引结构?
背景 首先,来谈谈B树。为什么要使用B树?我们需要明白以下两个事实: 【事实1】 不同容量的存储器,访问速度差异悬殊。以磁盘和内存为例,访问磁盘的时间大概是ms级的,访问内存的时间大概是ns级的。有个形象…...
什么是神经网络(Neural Network,NN)
1 定义 神经网络是一种模拟人类大脑工作方式的计算模型,它是深度学习和机器学习领域的基础。神经网络由大量的节点(或称为“神经元”)组成,这些节点在网络中相互连接,可以处理复杂的数据输入,执行各种任务…...

15 Go的并发
概述 在上一节的内容中,我们介绍了Go的类型转换,包括:断言类型转换、显式类型转换、隐式类型转换、strconv包等。在本节中,我们将介绍Go的并发。Go语言以其强大的并发模型而闻名,其并发特性主要通过以下几个元素来实现…...

管理体系标准
管理体系标准 什么是管理体系? 管理体系是组织管理其业务的相互关联部分以实现其目标的方式。这些目标可能涉及许多不同的主题,包括产品或服务质量、运营效率、环境绩效、工作场所的健康和安全等等。 系统的复杂程度取决于每个组织的具体情况。对于某…...

【Java 进阶篇】揭秘 Jackson:Java 对象转 JSON 注解的魔法
嗨,亲爱的同学们!欢迎来到这篇关于 Jackson JSON 解析器中 Java 对象转 JSON 注解的详细解析指南。JSON(JavaScript Object Notation)是一种常用于数据交换的轻量级数据格式,而 Jackson 作为一款优秀的 JSON 解析库&am…...

②【Hash】Redis常用数据类型:Hash [使用手册]
个人简介:Java领域新星创作者;阿里云技术博主、星级博主、专家博主;正在Java学习的路上摸爬滚打,记录学习的过程~ 个人主页:.29.的博客 学习社区:进去逛一逛~ Redis Hash ②Redis Hash 操作命令汇总1. hset…...

十七、SpringAMQP
目录 一、SpringAMQP的介绍: 二、利用SpringAMQP实现HelloWorld中的基础消息队列功能 1、因为publisher和consumer服务都需要amqp依赖,因此这里把依赖直接放到父工程mq-demo中 2、编写yml文件 3、编写测试类,并进行测试 三、在consumer…...
的调优技巧和实战)
Java虚拟机(JVM)的调优技巧和实战
JVM是Java应用程序的运行环境,它负责管理Java应用程序的内存分配、垃圾收集等重要任务。然而,JVM的默认设置并不总是适合所有应用程序,因此需要根据应用程序的需求进行调优。通过对JVM进行调优,可以大大提高Java应用程序的性能和可…...
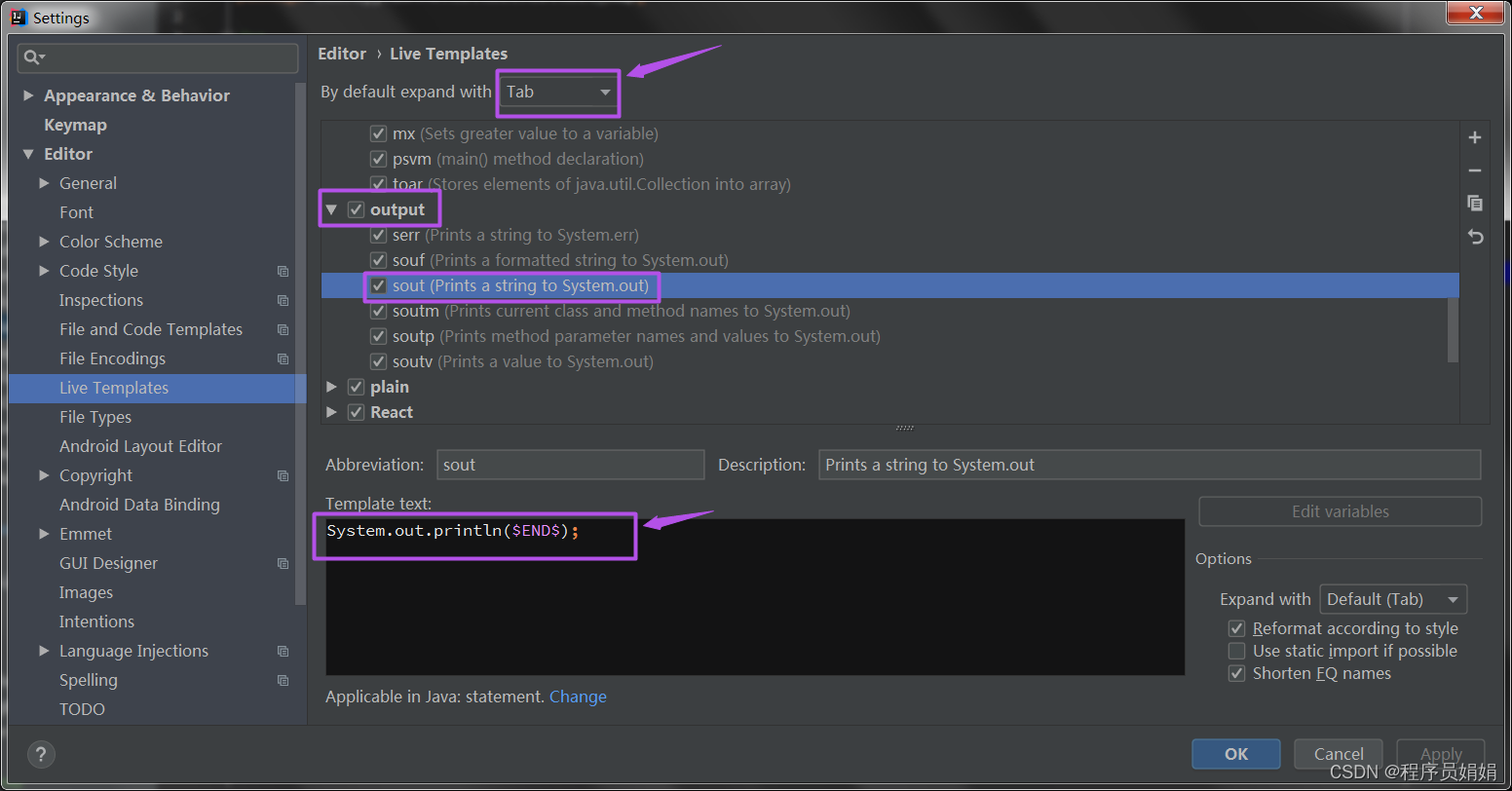
idea中的sout、psvm快捷键输入,不要太好用了
目录 一、操作环境 二、psvm、sout 操作介绍 2.1 psvm,快捷生成main方法 2.2 sout,快捷生成打印方法 三、探索 psvm、sout 底层逻辑 一、操作环境 语言:Java 工具: 二、psvm、sout 操作介绍 2.1 psvm,快捷生成m…...

shell脚本字典创建遍历打印
解释: 代码块中包含了每个用法的详细解释 #!/bin/bash# 接收用户输入的两个数 echo "请输入第一个数:" read num1 echo "请输入第二个数:" read num2# 创建一个关联数组 declare -A dict1 declare -A dict2# 定义键和值…...

【设计模式】聊聊职责链模式
原理和实现 模板模式变化的是其中一个步骤,而责任链模式变化的是整个流程。 将请求的发送和接收解耦合,让多个接收对象有机会可以处理这个请求,形成一个链条。不同的处理器负责自己不同的职责。 定义接口 public interface Filter {/*** …...
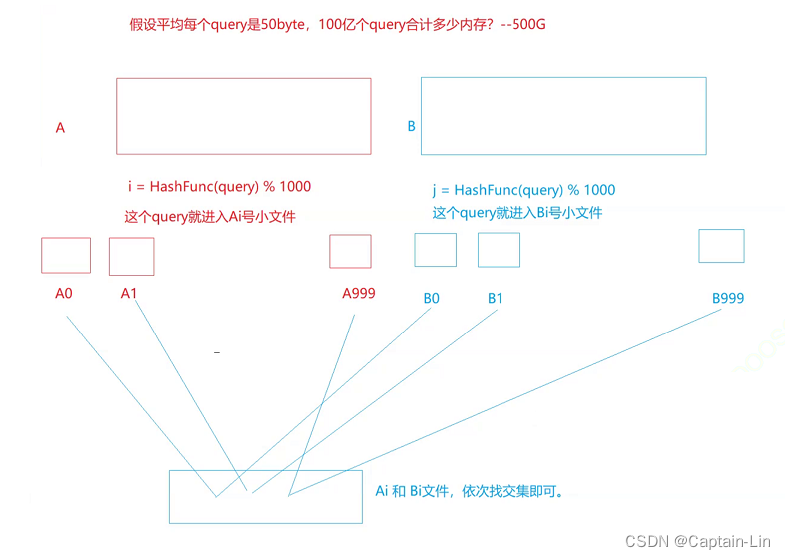
【C++进阶之路】第五篇:哈希
文章目录 一、unordered系列关联式容器1.unordered_map(1)unordered_map的介绍(2)unordered_map的接口说明 2. unordered_set3.性能对比 二、底层结构1.哈希概念2.哈希冲突3.哈希函数4.哈希冲突解决(1)闭散…...

CentOS基Docker容器时区配置解决方案
配置Docker容器的时区对于确保应用程序正确处理日期和时间至关重要。当使用CentOS作为基础镜像时,可以通过以下两种方法配置时区: 方法一:在Dockerfile中设置时区 这种方法涉及在构建Docker镜像的过程中设置时区。 步骤 选择基础镜像&…...
探索 Material 3:全新设计系统和组件库的介绍
探索 Material 3:全新设计系统和组件库的介绍 一、Material 3 简介1.1 Material 3 的改进和更新1.2 Material 3 的优势特点 二、Material 3 主题使用2.1 使用 Material3 主题2.2 使用 Material3 主题颜色 三、Material 3 组件使用3.1 MaterialButton:支持…...
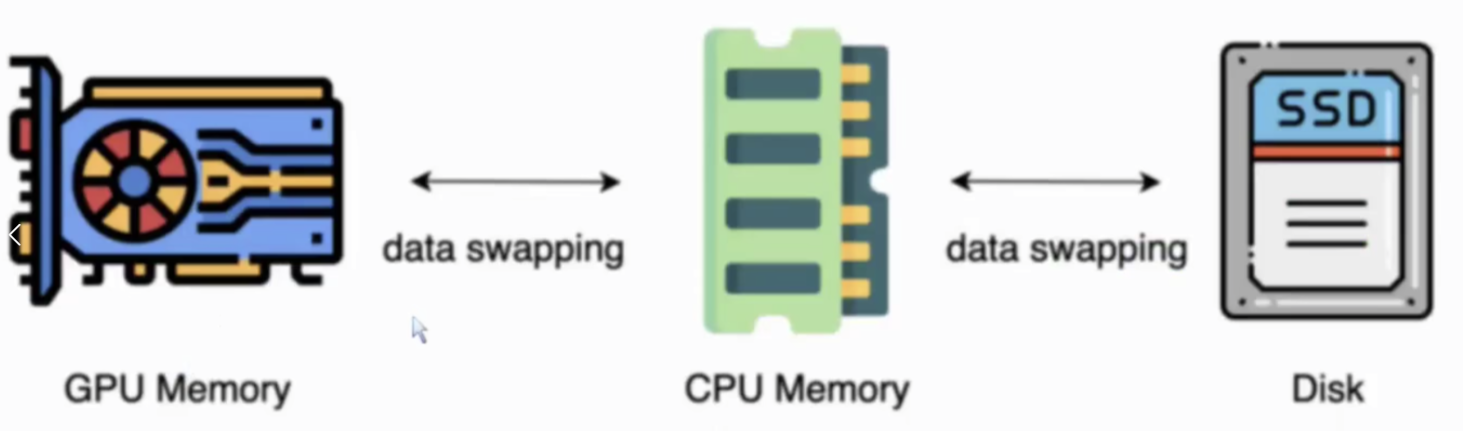
《多GPU大模型训练与微调手册》
全参数微调 Lora微调 PTuning微调 多GPU微调预备知识 1. 参数数据类型 torch.dtype 1.1 半精度 half-precision torch.float16:fp16 就是 float16,1个 sign(符号位),5个 exponent bits(指数位),10个 ma…...
)
【C++】const与类(const修饰函数的三种位置)
目录 const基本介绍 正文 前: 中: 后: 拷贝构造使用const 目录 const基本介绍 正文 前: 中: 后: 拷贝构造使用const const基本介绍 const 是 C 中的修饰符,用于声明常量或表示不可修改的对象、函数或成员函数。 我们已经了解了const基本用法,我们先进行…...

深度学习在图像识别中的革命性应用
深度学习在图像识别中的革命性应用标志着计算机视觉领域的重大进步。以下是深度学习在图像识别方面的一些革命性应用: 1. **卷积神经网络(CNN)的崭新时代**: - CNN是深度学习在图像识别中的核心技术,通过卷积层、池化…...

R语言读文件“-“变成“.“
R语言读取文件时发生"-"变成"." 如果使用read.table函数,需要 check.namesFALSE data <- read.table("data.tsv", headerTRUE, row.names1, check.namesFALSE)怎样将"."还原为"-" 方法一:gsub函…...
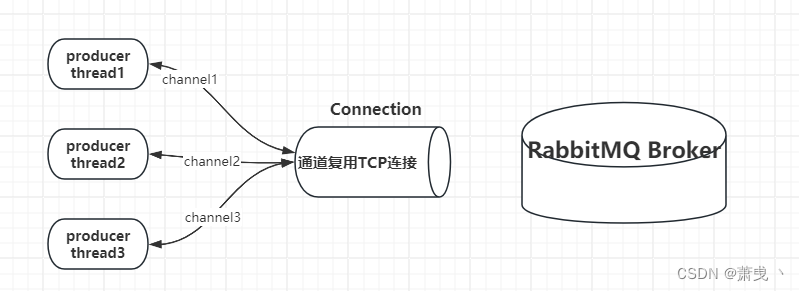
RabbitMQ 基础操作
概念 从计算机术语层面来说,RabbitMQ 模型更像是一种交换机模型。 Queue 队列 Queue:队列,是RabbitMQ 的内部对象,用于存储消息。 RabbitMQ 中消息只能存储在队列中,这一点和Kafka相反。Kafka将消息存储在topic&am…...

自然语言处理:Transformer与GPT
Transformer和GPT(Generative Pre-trained Transformer)是深度学习和自然语言处理(NLP)领域的两个重要概念,它们之间存在密切的关系但也有明显的不同。 1 基本概念 1.1 Transformer基本概念 Transformer是一种深度学…...

如何免费解锁原神60帧限制:终极FPS解锁工具完全指南
如何免费解锁原神60帧限制:终极FPS解锁工具完全指南 【免费下载链接】genshin-fps-unlock unlocks the 60 fps cap 项目地址: https://gitcode.com/gh_mirrors/ge/genshin-fps-unlock 你是否在原神中体验过画面卡顿、动作不够流畅的困扰?当其他游…...
)
为什么92%的PR团队在2026 AI大会媒体申报中首轮被拒?——解密评审委员会内部打分表(含权重分配与否决红线)
更多请点击: https://intelliparadigm.com 第一章:2026 AI技术大会媒体合作全景图谱 2026 AI技术大会已正式启动全球媒体合作生态共建计划,覆盖技术媒体、垂直产业平台、学术传播渠道及新兴AIGC内容分发网络四大支柱。本次合作不再局限于传统…...

OpenAI发布三款音频模型,欲借差异化路线“通吃”语音AI市场!
OpenAI发布三款音频模型昨天凌晨,OpenAI发布了三款音频模型:GPT-Realtime-2、GPT-Realtime-Translate和GPT-Realtime-Whisper。OpenAI官网称,新模型能让开发者构建可在用户说话时“推理、翻译和转写”的实时语音产品,且三款模型已…...

Soul App联合高校共同开源模块SoulX-Duplug,推动语音交互技术升级
近期,Soul App AI团队联合上海交通大学X-LANCE Lab与西北工业大学ASLPNPU团队,共同开源全双工语音对话控制模块SoulX-Duplug,并同步推出评测基准SoulX-Duplug-Eval。该项目围绕实时语音交互中的关键控制问题展开,为完善现有语音系…...

百年传动革新|盖茨个人出行解决方案:重新定义二轮 / 四轮骑行体验
在全球出行产业向电动化、轻量化、高效化快速转型的当下,传动系统作为核心部件,直接决定设备性能、可靠性与用户体验。盖茨作为全球流体动力与传动解决方案的标杆企业,凭借百年技术积淀与持续材料科学创新,构建了覆盖二轮 / 四轮、…...
)
LM386电路噪音大、声音失真?别急着换芯片,先检查这5个地方(附示波器实测对比)
LM386电路噪音大、声音失真?别急着换芯片,先检查这5个地方(附示波器实测对比) 当你兴奋地搭建完LM386功放电路,却发现喇叭里传出恼人的噪音或是失真的声音时,先别急着怀疑芯片质量问题。作为一款久经考验的…...
)
用CenterFusion在nuScenes数据集上训练自己的3D目标检测模型:保姆级全流程解析(从数据准备到可视化评估)
用CenterFusion在nuScenes数据集上训练3D目标检测模型:从数据准备到可视化评估的全流程实战指南 自动驾驶技术的快速发展对3D目标检测提出了更高要求。nuScenes作为当前最全面的多模态自动驾驶数据集之一,为研究者提供了丰富的传感器数据。本文将带您深入…...

systemd Service 详细说明
systemd Service 详细说明 什么是 systemd? systemd 是 Linux 系统的初始化系统和服务管理器,负责在系统启动时启动和管理各种服务(后台进程)。 为什么要使用服务管理器? 想象一下,您有一个机器人控制程序需要一直运行: 如果直接运行 python3 robot.py,关闭终端程序…...

时变路网下考虑时间满意度的L连锁公司配送路径【附代码】
✅ 博主简介:擅长数据搜集与处理、建模仿真、程序设计、仿真代码、论文写作与指导,毕业论文、期刊论文经验交流。 ✅ 如需沟通交流,扫描文章底部二维码。(1)路段行程时间深度时空预测与顾客时间满意度建模:…...

GanttProject终极指南:免费开源项目管理工具完整教程
GanttProject终极指南:免费开源项目管理工具完整教程 【免费下载链接】ganttproject Official GanttProject repository. 项目地址: https://gitcode.com/gh_mirrors/ga/ganttproject GanttProject是一款功能强大的免费开源项目管理软件,专注于甘…...