使用ExLlamaV2量化并运行EXL2模型
量化大型语言模型(llm)是减少这些模型大小和加快推理速度的最流行的方法。在这些技术中,GPTQ在gpu上提供了惊人的性能。与非量化模型相比,该方法使用的VRAM几乎减少了3倍,同时提供了相似的精度水平和更快的生成速度。
ExLlamaV2是一个旨在从GPTQ中挤出更多性能的库。由于新的内核,它还经过了优化,可以进行(非常)快速的推理。并且它还引入了一种新的量化格式EXL2,它为如何存储权重带来了很大的灵活性。

在本文中,我们将介绍如何量化EXL2格式的基本模型,以及如何运行它们。当然如果你喜欢使用现有的已经量化好的模型,TheBloke 仍然是第一选择。
量化EXL2模型
首先需要安装ExLlamaV2库:
pip install exllamav2#为了使用官方的一些脚本,我们还要把官方的代码clone到本地git clone https://github.com/turboderp/exllamav2
我们使用出色的zephyr-7B-beta,这是一种使用DPO进行微调的Mistral-7B模型。它声称在MT测试台上的表现优于Llama-2 70b的效果,这对于一个小十倍的模型来说是非常好的结果。
使用以下命令下载zephyr-7B-beta(这可能需要一段时间,因为模型大约是15gb):
git lfs installgit clone https://huggingface.co/HuggingFaceH4/zephyr-7b-beta
GPTQ还需要一个校准数据集,该数据集用于通过比较基本模型及其量化版本的输出来衡量量化过程的影响。我们将使用wikitext数据集,直接下载测试文件如下:
wget https://huggingface.co/datasets/wikitext/resolve/9a9e482b5987f9d25b3a9b2883fc6cc9fd8071b3/wikitext-103-v1/wikitext-test.parquet
准备工作完成后,就可以利用ExLlamaV2库提供的convert.py脚本来进行量化了,主要的参数是:
-i:以HF格式(FP16)转换的基模型路径。
-o:存放临时文件和最终输出的工作目录路径。
-c:校准数据集的路径(Parquet格式)。
-b:目标平均加权位数(bpw)。例如,4.0 bpw将给出4位精度的存储权重。
让我们使用带有以下参数的convert.py脚本开始量化过程:
mkdir deephub-quantpython python exllamav2/convert.py \-i base_model \-o deephub-quant \-c wikitext-test.parquet \-b 5.0
这里就需要一个GPU来量化这个模型。根据官方文档指出,7B型号需要大约8 GB的VRAM, 70B型号需要大约24 GB的VRAM。zephyr-7b-beta在白嫖的谷歌Colab的T4 GPU,经过了2小时10分钟完成了量化。
ExLlamaV2利用GPTQ算法来降低权重的精度,同时最大限度地减少对输出的影响。GPTQ算法的更多详细信息可以参考我们以前的文章。
量化过程使用现有脚本非常的简单。那么还有最后一个问题,为什么要使用“EXL2”格式而不是常规的GPTQ格式呢?EXL2带来了哪些新功能?
它支持不同级别的量化:它不局限于4位精度,可以处理2、3、4、5、6和8位量化。
它可以在一个模型和每一层中混合不同的精度,以保留最重要的权重和具有更多bit的层。
ExLlamaV2在量化过程中使用了这种额外的灵活性。它会自动尝试不同的量化参数,并测量了它们引入的误差。除了尽量减少错误之外,ExLlamaV2还会将必须达到平均位数作为参数(这个我们在以前文章中也有介绍)。所以我们可以创建一个混合的量化模型,例如,每个权重的平均位数为3.5或4.5。
ExLlamaV2另外一个好处是它创建的不同参数的基准被保存在measurement.json文件中。我们可以直接看到具体的信息:
"key": "model.layers.0.self_attn.q_proj","numel": 16777216,"options": [{"desc": "0.05:3b/0.95:2b 32g s4","bpw": 2.1878662109375,"total_bits": 36706304.0,"err": 0.011161142960190773,"qparams": {"group_size": 32,"bits": [3,2],"bits_prop": [0.05,0.95],"scale_bits": 4}},
比如上面的内容,ExLlamaV2使用了5%的3位精度和95%的2位精度,平均值为2.188 bpw,组大小为32。这导致了一个明显的误差,所以在选择最佳参数时要考虑到这个误差,通过查看json文件的结果,我们可以判断出这次量化是否符合我们的要求,并且进行调整。
使用ExLlamaV2进行推理
模型已经量子化了,下面就是使用模型进行推理了。首先需要将基本配置文件从base_model目录复制到新的deephub-quant目录,代码如下:
!rm -rf deephub-quant/out_tensor!rsync -av --exclude='*.safetensors' --exclude='.*' ./base_model/ ./deephub-quant/
最直接的方法是使用ExLlamaV2 repo中的test_inference.py脚本(注意,我在这里没有使用聊天模板):
python exllamav2/test_inference.py -m quant/ -p "I have a dream"
与GGUF/llama.cpp或GPTQ等其他量化技术和工具相比,生成速度也非常快(在T4 GPU上每秒56.44个令牌)。
也可以使用chatcode.py脚本的聊天版本来获得更大的灵活性:
python exllamav2/examples/chatcode.py -m deephub-quant -mode llama
总结
ExLlamaV2已经被集成到几个常见的后端中,比如oobabooga的文本生成web UI。但是它需要FlashAttention 2和CUDA 12.1(这在windows中可能需要费一些时间)。
ExLlamaV2与GPTQ或llama.cpp等其他解决方案相比,可以自定义量化我们的模型。在量化之后,它每秒提供的令牌数量更多(更快)。这对于定制化的需求来说是非常有帮助的。
最后,本文代码:
https://avoid.overfit.cn/post/ce9c31f9650943bfa220f48f3ee2f430
作者:Maxime Labonne
相关文章:
使用ExLlamaV2量化并运行EXL2模型
量化大型语言模型(llm)是减少这些模型大小和加快推理速度的最流行的方法。在这些技术中,GPTQ在gpu上提供了惊人的性能。与非量化模型相比,该方法使用的VRAM几乎减少了3倍,同时提供了相似的精度水平和更快的生成速度。 ExLlamaV2是一个旨在从…...
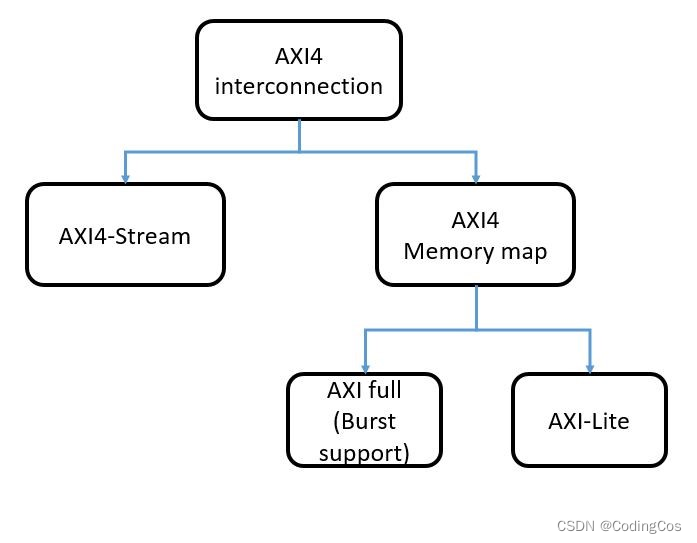
【ARM AMBA AXI 入门 15 -- AXI-Lite 详细介绍】
请阅读【ARM AMBA AXI 总线 文章专栏导读】 文章目录 AXI LiteAXI-Full 介绍AXI Stream 介绍AXI Lite 介绍AXI Full 与 AIX Lite 差异总结AXI Lite AMBA AXI4 规范中包含三种不同的协议接口,分别是: AXI4-FullAXI4-LiteAXI4-Stream 上图中的 AXI FULL 和 AIX-Lite 我们都把…...

【开源】基于Vue.js的天然气工程业务管理系统的设计和实现
项目编号: S 021 ,文末获取源码。 \color{red}{项目编号:S021,文末获取源码。} 项目编号:S021,文末获取源码。 目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块三、使用角色3.1 施工人员3.2 管理员 四…...
SpringBoot : ch04 整合数据源
前言 Spring Boot 是当今最流行的 Java 开发框架之一,它以简洁、高效的特点帮助开发者快速构建稳健的应用程序。在实际项目中,涉及到数据库操作的需求时,我们需要对数据源进行整合。本文将重点介绍如何在 Spring Boot 中整合数据源ÿ…...

Docker Swarm总结
目录 1、swarm 理论基础 1.1 简介 1.2 节点架构 1.3 服务架构 1.4 服务部署模式 2、swarm 集群搭建 2.1 需求 2.2 克隆主机 2.3 启动5个docker宿主机 2.4 查看 swarm 激活状态 2.5 关闭防火墙 2.6 swarm 初始化 2.7 添加 worker 节点 2.8 添加 manager 节点 3…...

特殊token的特殊用途
特殊token的特殊用途 特殊voc设计传统的特殊token 用途特殊用途例子特殊voc设计 普通token1 。。。。普通token1000,特殊token1,,,,,特殊token100 ,特殊指示token1,,,特殊指示token100 传统的特殊token 用途 在您提供的示例中,有1000个普通 token(从普通 token …...
苹果Siri怎么打开?教你两招轻松唤醒!
苹果Siri助手是苹果公司开发的智能语音助手。作为智能语音助手,Siri可以理解用户的指令,并给出相应的回答或执行相应的操作,帮助大家完成各种任务,比如发送短信、查询天气、播放音乐、设置提醒等等。 然而,还有一些小…...

分类问题的评价指标
一、logistic regression logistic regression也叫做对数几率回归。虽然名字是回归,但是不同于linear regression,logistic regression是一种分类学习方法。 同时在深度神经网络中,有一种线性层的输出也叫做logistic,他是被输入…...

Hive 定义变量 变量赋值 引用变量
Hive 定义变量 变量赋值 引用变量 变量 hive 中变量和属性命名空间 命名空间权限描述hivevar读写用户自定义变量hiveconf读写hive相关配置属性system读写java定义额配置属性env只读shell环境定义的环境变量 语法 Java对这个除env命名空间内容具有可读可写权利; …...
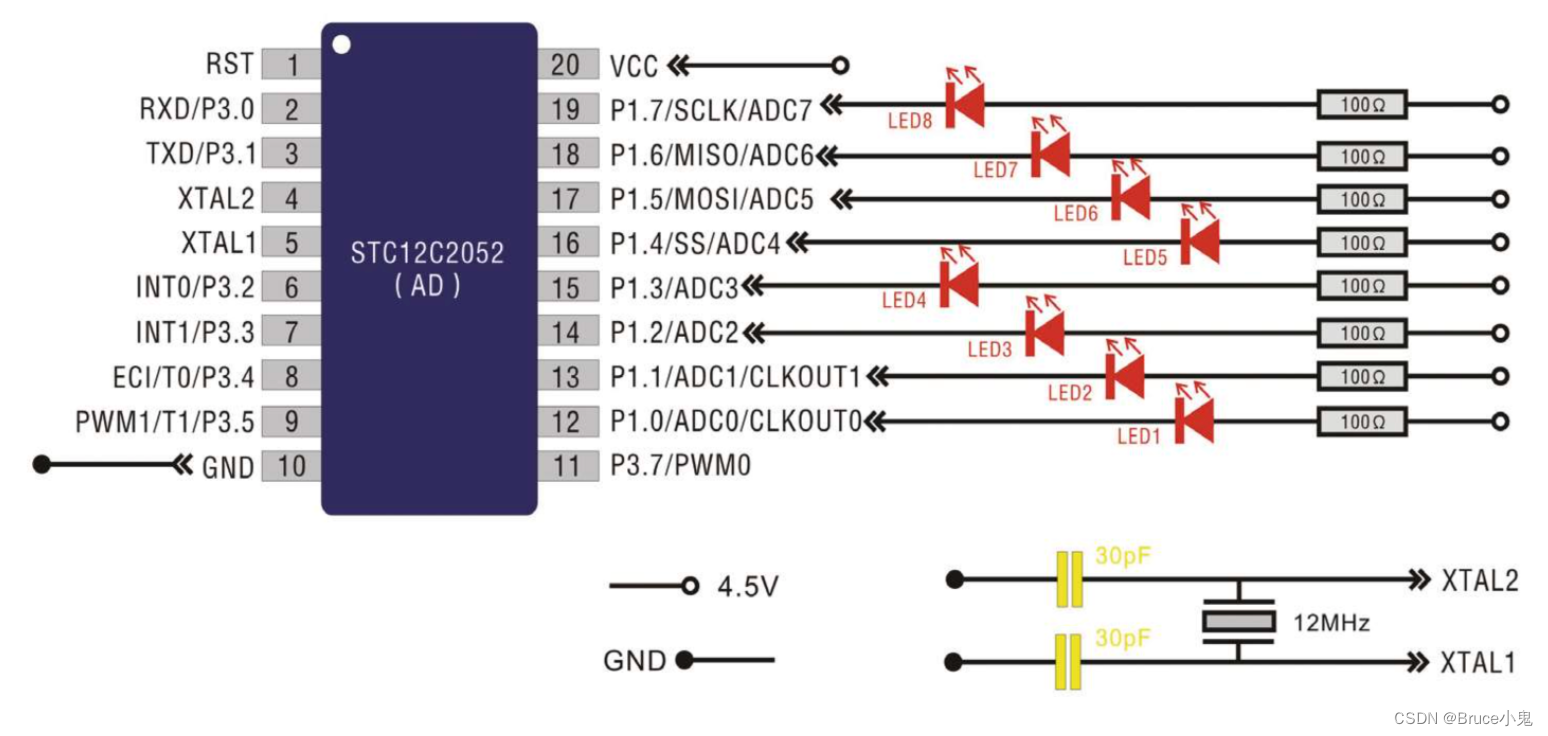
51单片机LED灯渐明渐暗实验
51单片机LED灯渐明渐暗实验 1.概述 这篇文章介绍使用单片机控制两个LED彩灯亮度渐明渐暗效果,详细介绍了操作步骤以及完整的程序代码,动手就能制作的小实验。 2.操作步骤 2.1.硬件搭建 1.硬件准备 名称型号数量单片机STC12C2052AD1LED彩灯无2晶振1…...

美团面试:微服务如何拆分?原则是什么?
尼恩说在前面 在40岁老架构师 尼恩的读者交流群(50)中,最近有小伙伴拿到了一线互联网企业如美团、字节、如阿里、滴滴、极兔、有赞、希音、百度、网易的面试资格,遇到很多很重要的面试题: 微服务如何拆分? 微服务拆分的规范和原则…...
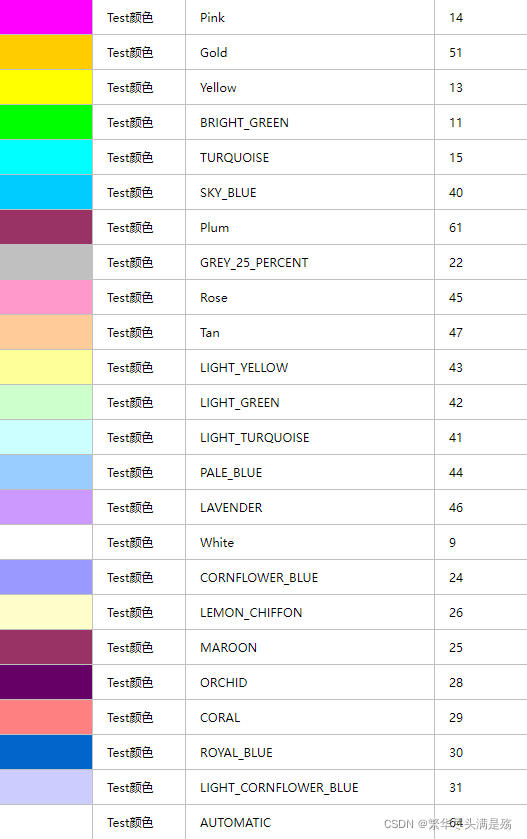
easyExcel注解详情
前言11个注解字段注解 类注解基础综合示例补充颜色总结 11个注解 ExcelProperty ColumnWith 列宽 ContentFontStyle 文本字体样式 ContentLoopMerge 文本合并 ContentRowHeight 文本行高度 ContentStyle 文本样式 HeadFontStyle 标题字体样式 HeadRowHeight 标题高度 HeadStyle…...

S7-1200PLC 作为MODBUSTCP服务器通信(多客户端访问)
S7-1200PLC作为MODBUSTCP服务器端通信编程应用,详细内容请查看下面文章链接: ModbusTcp通信(S7-1200PLC作为服务器端)-CSDN博客文章浏览阅读239次。S7-200Smart plc作为ModbusTcp服务器端的通信S7-200SMART PLC ModbusTCP通信(ModbusTcp服务器)_s7-200 modbustcp-CSDN博客文…...

泰勒多项式
泰勒展开 f ( x ) P n ( x ) R n ( x ) f(x)P_n(x)R_n(x) f(x)Pn(x)Rn(x) P n ( x ) ∑ 0 n f ( k ) ( x 0 ) k ! ( x − x 0 ) k P_n(x)\sum_0^n\frac{f^{(k)}(x_0)}{k!}(x-x_0)^k Pn(x)∑0nk!f(k)(x0)(x−x0)k R n ( x ) f ( n 1 ) ( ξ x 0 ) ( n 1 ) !…...
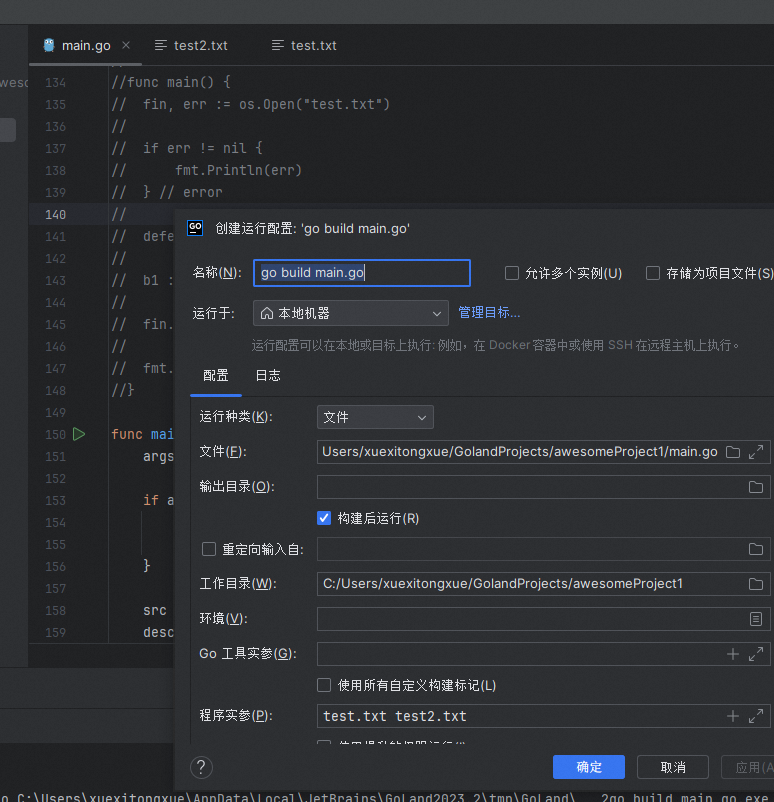
【Hello Go】Go语言文本文件处理
文本文件处理 字符串处理字符串操作ContainsJoinindexrepeatReplaceSplitTrimFields 字符串转换AppendFormatParse 正则表达式Json处理编码Json通过结构体生产Json通过map生产json 解码Json解析到结构体解析到interface 文件操作相关api介绍建立和打开文件关闭文件写文件读文件…...
ppt录屏制作微课,轻松打造精品课程
微课作为一种新型的教学方式逐渐受到广大师生的欢迎。微课具有方便快捷、内容丰富、互动性强等特点,可以有效地帮助教师传达知识,提高学生的学习效果。其中,ppt录屏制作微课就是一种常见的方式。本文将介绍ppt录屏的使用方法,帮助…...
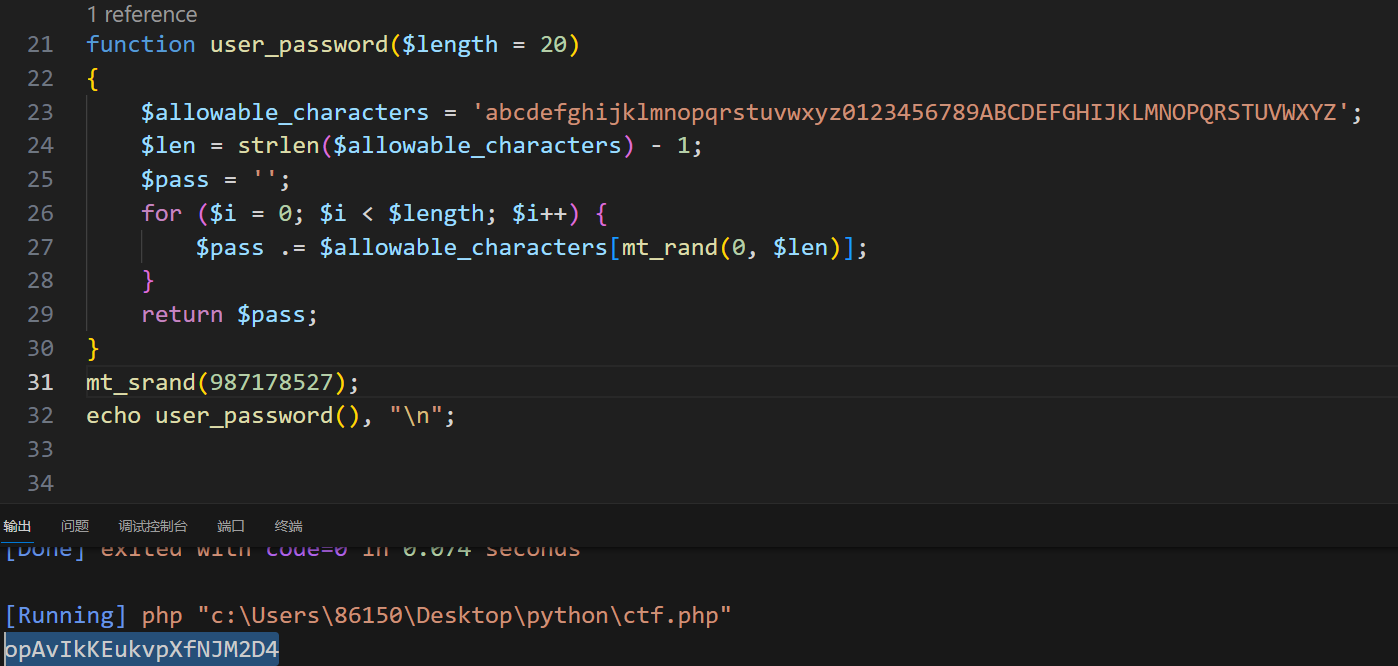
php伪随机数
利用工具 php_mt_seed <?php // php 7.2function white_list() {return mt_rand();}echo white_list(), "\n";echo white_list(), "\n";echo white_list(), "\n"; 输入命令: ./php_mt_seed 1035656029 <?phpmt_srand(181095…...
为什么录屏没声音?实用技巧大放送!
录屏已成为我们在数字时代记录和分享内容的重要方式之一。但有时,您可能会遇到录制视频却没有声音的问题。这个问题可能出现在不同的录屏软件中,导致许多人感到疑惑。在本文中,我们将探讨为什么录屏没声音,并提供两种解决方案&…...
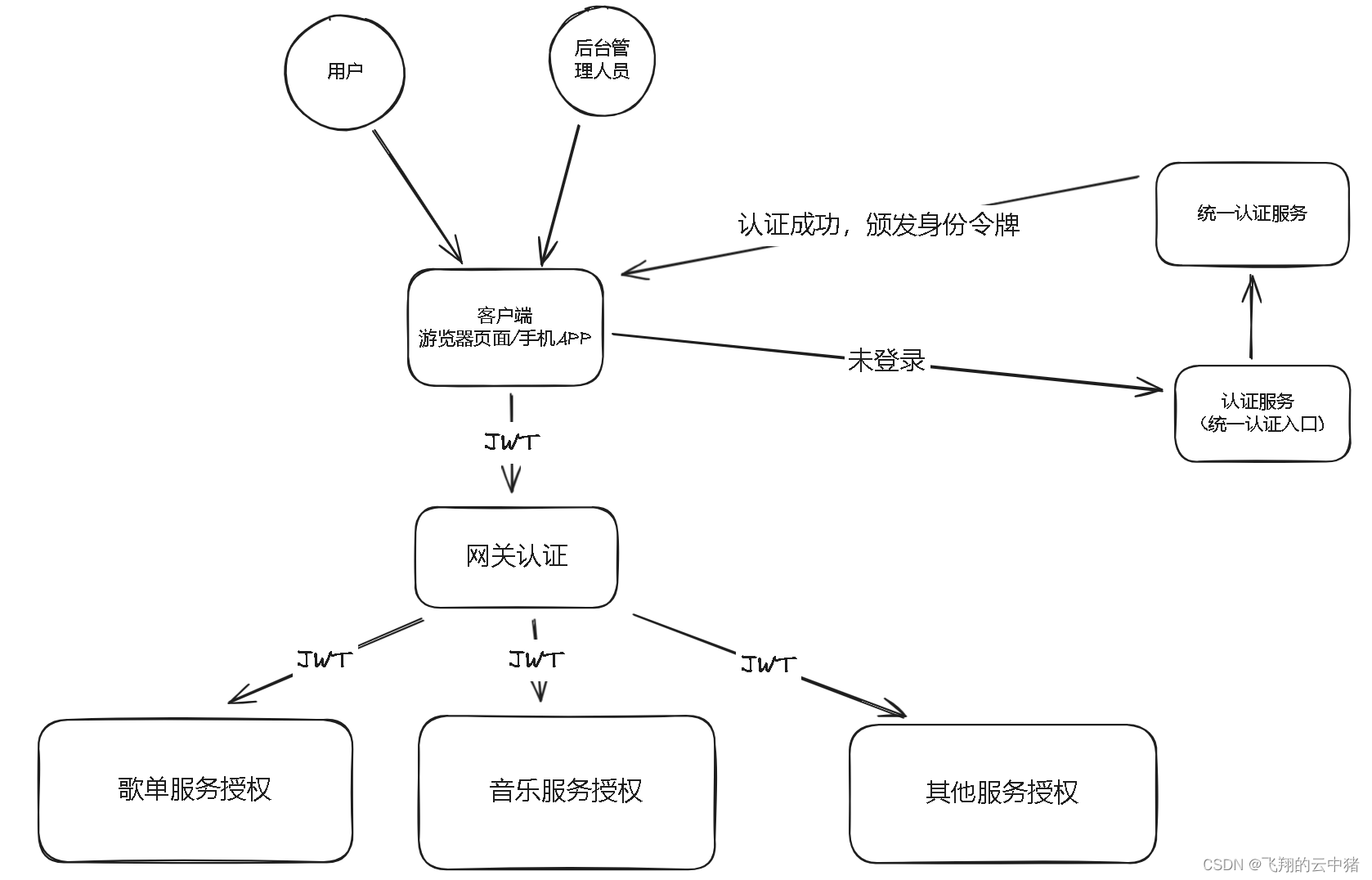
分布式系统的认证授权
一.分布式系统的认证授权大致架构 以云音乐系统为例: 注:一般情况下,我们会把认证的部分的接口提取为一个单独的认证服务模块中。 二.单点登录(Single Sign On) 单点登录,Single Sign On,简称…...
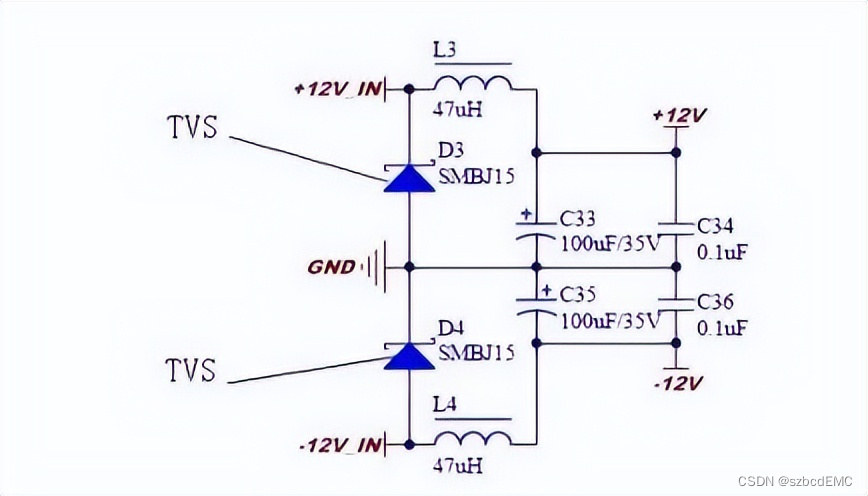
TVS瞬态抑制二极管的工作原理和特点?|深圳比创达电子EMC
TVS二极管一般是用来防止端口瞬间的电压冲击造成后级电路的损坏。防止端口瞬间的电压冲击造成后级电路的损坏。有单向与双向之分,单向TVS一般应用于直流供电电路,双向TVS应用于交流供电电路。 TVS产品的额定瞬态功率应大于电路中可能出现的最大瞬态浪涌…...

STM32调试踩坑记:Keil5里数组越界是如何“偷走”我变量值的?
STM32调试侦探手记:Keil5中数组越界如何“篡改”你的变量 当我在调试一个CANFD通信项目时,遇到了一个诡异的现象——明明没有对SensorValue数组进行任何赋值操作,但它的值却莫名其妙地改变了。这就像侦探小说中的密室杀人案,变量在…...

如何永久保存微信聊天记录?3步实现本地备份与深度分析
如何永久保存微信聊天记录?3步实现本地备份与深度分析 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeCha…...

ComfyUI-Manager完整指南:如何快速搭建和管理你的AI工作流
ComfyUI-Manager完整指南:如何快速搭建和管理你的AI工作流 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various c…...

告别凌乱!Juliet 连接器为串行 TTL 连接带来整洁可靠新方案
串行 TTL 连接现状如果你曾用树莓派(Raspberry Pi)等嵌入式设备做过实验,或者经历过 OpenWrt 路由器固件更新失败,就会知道常规操作:把 USB 转串行 TTL 适配器连接到主板上标有 RX、TX 和 GND 的三个神奇引脚。这就打开…...

LLM提示词工程化实践:开源模板库提升AI对话效率与质量
1. 项目概述:一个为大型语言模型准备的“提示词武器库”如果你和我一样,经常和ChatGPT、Claude或者本地部署的Llama这类大语言模型打交道,那你肯定有过这样的体验:同一个问题,换种问法,得到的答案质量天差地…...

3个核心功能:猫抓浏览器插件帮你高效下载网页视频和音频资源
3个核心功能:猫抓浏览器插件帮你高效下载网页视频和音频资源 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat-Catc…...

庄子给普通人的生存启迪
庄子给普通人的生存启迪:只求生存,不奢望其它——一套最低功耗的生存操作系统 一、序言:当“活着”成为最高目标 在你之前分析过的所有人物中——高俅在权力寄生中赢了每一局却输了整个时代,宋江被“忠君”认知病毒锁死走向自我毁灭,黄巢、李自成因认知破产而将江山拱手…...

Floom:一键将Python脚本部署为Web服务与API的开源方案
1. 项目概述:从代码到云服务的“一键魔法” 如果你和我一样,是个喜欢用Python写点小工具来解决实际问题的开发者,那你肯定也经历过这样的困境:写了个挺有用的脚本,比如自动整理周报、批量处理图片,或者调用…...

Linux下Cursor IDE自动化安装脚本:一键部署与桌面集成指南
1. 项目概述:一个为Linux用户定制的Cursor IDE自动化安装脚本 如果你和我一样,是一个长期在Linux环境下工作的开发者,那么对于“安装软件”这件事,可能已经形成了一套复杂的肌肉记忆:打开浏览器、找到官网、下载对应架…...

浏览器扩展开发实战:实现网页搜索框自动聚焦与键盘导航优化
1. 项目概述:一个提升网页搜索效率的浏览器扩展 如果你和我一样,是个重度键盘使用者,那么你一定经历过这种场景:打开一个电商网站或者在线词典,准备搜索商品或单词时,手不得不离开键盘,挪动鼠标…...