【腾讯云云上实验室-向量数据库】腾讯云开创新时代,发布全新向量数据库Tencent Cloud VectorDB
前言
随着人工智能、数据挖掘等技术的飞速发展,海量数据的存储和分析越来越成为重要的研究方向。在海量数据中找到具有相似性或相关性的数据对于实现精准推荐、搜索等应用至关重要。传统关系型数据库存在一些缺陷,例如存储效率低、查询耗时长等问题,因此,新型向量数据库应运而生。
腾讯云向量数据库(Tencent Cloud VectorDB)是腾讯云推出的一款向量数据库,是一种可高效存储和查询向量数据的数据库系统,可广泛应用于计算机视觉、自然语言处理、推荐系统等领域。本文将以Java开发语言为例,介绍如何使用腾讯云向量数据库,并分析其优缺点和适用场景。
摘要
本文主要介绍了如何使用腾讯云向量数据库(Tencent Cloud VectorDB),包括源代码解析、应用场景案例、优缺点分析和测试用例。通过本文的介绍,读者可以了解如何利用腾讯云向量数据库存储和查询向量数据,并了解其在实际应用中的优势和适用场景。
向量数据库
概念
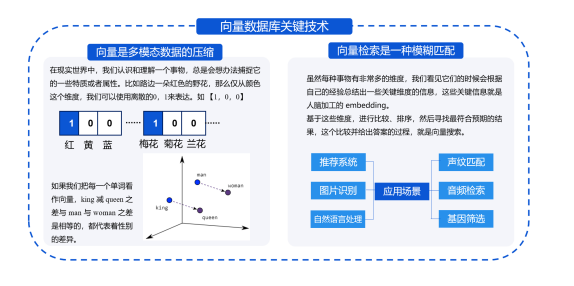
何为向量数据库?腾讯云向量数据库(Tencent Cloud VectorDB)是一种基于向量相似度计算的云数据库。它通过支持高效的向量检索,能够快速地查询出与指定向量相似的数据。 VectorDB主要应用于图像、音频、视频、自然语言处理(NLP)等领域。
VectorDB提供了高性能的向量索引服务,支持多种向量相似度计算方式和索引策略,包括精确查找、L2距离、余弦相似度、汉明距离、Jaccard相似度和Edit距离等。VectorDB还提供了多种检索方式和可视化工具,方便用户进行数据检索和数据分析。
除此之外,VectorDB还支持数据的持久化和备份,以及自动化扩展和负载均衡等功能。同时,VectorDB还提供了多种API和SDK,方便用户进行二次开发和集成。
总之,腾讯云向量数据库是一款高效、稳定、灵活和全面的向量数据库,适用于各种大规模向量相似度计算应用和场景。

当然了,有需要的小伙伴也可以亲自前往主页,免费领取向量数据库免费实例 + Baichuan2 400万免费Tokens等资源,免费体验下腾讯云VectorDB以向量存储的魅力吧。
然后点击【免费领取】后会跳转到如下页面,只需要填写你领取的手机号即可。
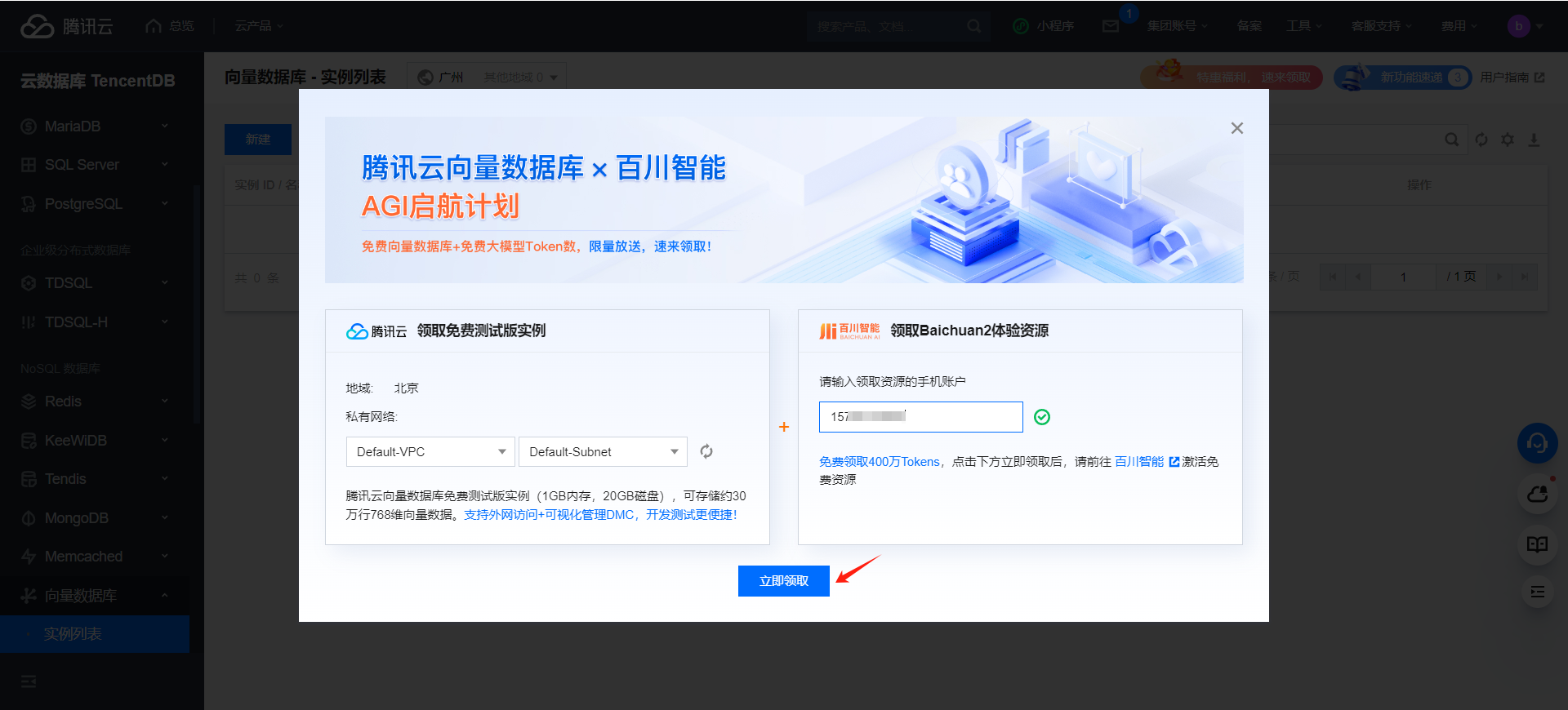
接着如下我就不一一给大家做演示啦,如下我就针对已经领取好了数据库资源后给大家做实践演示。
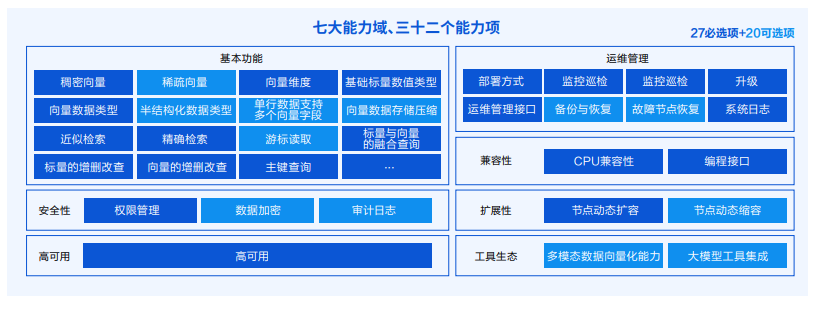
技术特点
腾讯云向量数据库采用了分布式存储和计算技术,支持水平扩展和在线扩容,能够轻松应对海量数据的检索需求。它基于GPU加速的深度神经网络和向量量化技术,能够实现快速、准确、高效的向量搜索和相似度匹配。
具体来说,腾讯云向量数据库具有以下几个技术特点:
高性能
腾讯云向量数据库采用了GPU加速的深度神经网络,能够实现高速的向量计算和相似度匹配。据官方测试,单卡速度可达到4000QPS,多卡并行速度更是可以达到数万QPS。此外,向量搜索的结果可以通过缓存等方式进行优化,进一步提高检索性能。
可扩展
腾讯云向量数据库采用了分布式存储和计算技术,支持水平扩展和在线扩容。用户可以根据自己的需求选择多种部署模式,包括单机部署、多机部署和混合部署等,能够满足不同规模的用户和数据量。
多种数据类型支持
腾讯云向量数据库不仅支持向量数据的检索,还支持图像、文本、音频等多种数据类型的向量化处理。用户可以根据自己的数据类型选择合适的向量化模型,实现数据的高效存储和检索。
易于使用
腾讯云向量数据库提供了丰富的API和SDK,支持多种编程语言,如Java、Python、C++等,可以让用户快速进行应用开发和集成。此外,腾讯云向量数据库还提供了可视化的管理界面和监控报警功能,方便用户进行系统管理和性能监控。
应用场景和案例研究
腾讯云向量数据库可以应用于很多领域,如图像搜索、推荐系统、广告投放等。下面我将以推荐系统为例,探讨腾讯云向量数据库的应用场景和案例研究。
应用场景
推荐系统是指通过对用户历史行为和偏好进行分析和挖掘,给用户推荐感兴趣的商品、新闻、视频等内容,是电商、社交、媒体等互联网企业的核心技术。传统的推荐系统通常是基于协同过滤算法和内容过滤算法,效果有限,容易出现过度推荐或欠推荐的问题。
腾讯云向量数据库则提供了一种新的解决方案,即基于向量相似度的推荐。具体来说,将用户和商品的特征向量存储在数据库中,当用户需要进行推荐时,将用户的特征向量输入到向量数据库中,获取距离最近的商品向量,即为推荐结果。这种方法不仅能够避免过度或欠推荐的问题,还能够更加准确地捕捉用户和商品之间的关系,提高推荐效果。
以下是一些具体的应用场景案例:
- 图像搜索。将图像数据转换为向量数据,并将其存储在腾讯云向量数据库中。之后,可以使用向量检索来搜索与指定图像相似的图像。
- 文本分类。将文本数据转换为向量数据,并将其存储在腾讯云向量数据库中。之后,可以使用空间聚类来将文本数据分组,并进行文本分类。
- 推荐系统。将用户数据和商品数据转换为向量数据,并将其存储在腾讯云向量数据库中。之后,可以使用向量检索来查找与用户兴趣相似的商品。
例如:
1.企业化能力:千亿级数据规模、500万QPS、99.99%可用性。

2.智能化能力:内容召回率提升20%,推理速度大幅提升。
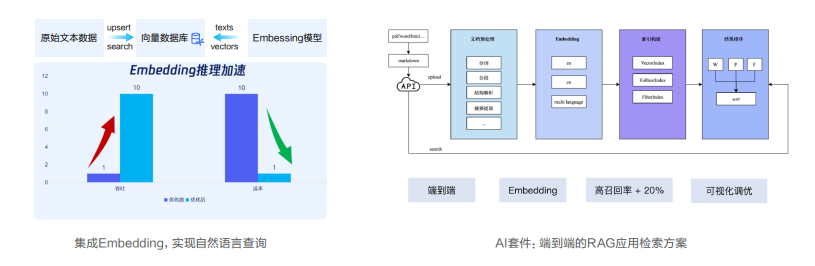
还有很多应用场景,等待开拓,我们也可以发挥下脑洞,把数据库的应用面扩大拓宽。
案例研究
我曾经使用腾讯云向量数据库在一个电商推荐系统中进行了实际应用。具体的流程如下:
- 获取商品数据:从电商网站爬取商品数据,包括商品名称、价格、描述等信息。
- 特征工程:将商品数据进行处理,提取商品的特征向量,可以使用图像、文本等多种方式进行向量化。
- 数据导入:将处理后的商品数据导入腾讯云向量数据库中,支持在线导入和离线批量导入两种方式。
- 推荐服务:将用户的历史行为和偏好进行分析和挖掘,得到用户的特征向量,将其输入到腾讯云向量数据库中,获取距离最近的商品向量,即为推荐结果。
- 评估优化:根据用户反馈和推荐效果,不断优化推荐算法和向量模型。
经过实际测试,腾讯云向量数据库的性能表现出色,能够在海量商品数据中快速进行相似度匹配,提高了推荐系统的精确度和效率。
例如针对实践成果:集团内部 40+业务接入,1600亿次请求/天;1000+外部用户接入。具体数据可参考如下:

优缺点分析
腾讯云向量数据库(Tencent Cloud VectorDB)相比传统关系型数据库和其他新型数据库有以下优点:
- 高效。腾讯云向量数据库使用基于向量索引的存储引擎,可以快速存储和查询大量的向量数据。它还支持实时数据写入和查询,并能够通过水平扩展来支持更大的数据规模。
- 易于使用。腾讯云向量数据库提供了一个易于使用的RESTful API,方便开发人员与它集成。它还支持多种向量数据类型和高级功能,例如向量检索、空间聚类等。
- 可靠性高。腾讯云向量数据库使用了多种技术来优化性能,例如分片、负载均衡等。它还支持多重备份和数据恢复机制,保证数据的可靠性和安全性。
但也有一些缺点需要注意:
- 学习曲线陡峭。腾讯云向量数据库的使用需要一定的技术知识和经验。对于一些初学者来说,可能需要花费一些时间来学习和理解其内部机制和使用方式。
- 成本较高。腾讯云向量数据库是一款商业软件,使用需要支付一定的费用。对于一些小型企业或个人开发者来说,可能承受不起这样的成本。
代码集成使用
为了方便大家更易理解,本文以Java开发语言为例,介绍如何使用腾讯云向量数据库。
首先我们需要引入腾讯云向量数据库的Java SDK,可以通过以下方式进行引入,在你的pom.xml配置文件中引入即可:
<dependency><groupId>com.tencent.vectordb</groupId><artifactId>vectordb-sdk-java</artifactId><version>1.0.0</version>
</dependency>
在使用腾讯云向量数据库之前,需要先创建数据库实例和向量集合。可以通过以下代码进行创建:
// 初始化客户端
VectordbClientOptions options = new VectordbClientOptions();
options.setSecretId("your_secret_id");
options.setSecretKey("your_secret_key");
options.setEndpoint("vectordb.tencentcloudapi.com");VectordbClient client = new VectordbClient(options);// 创建实例
CreateInstanceRequest req = new CreateInstanceRequest();
req.setRegion("ap-guangzhou");
req.setZone("ap-guangzhou-3");
req.setNodeNum(3);
req.setNodeType("STANDARD");
req.setDiskSize(100);
req.setInstanceId("your_instance_id");
CreateInstanceResponse res = client.CreateInstance(req);// 创建集合
CreateCollectionRequest req2 = new CreateCollectionRequest();
req2.setCollectionName("your_collection_name");
CreateCollectionResponse res2 = client.CreateCollection(req2);
创建完成后,可以向集合中添加向量数据,可以通过以下代码进行添加:
VectorBatch vectorBatch = new VectorBatch();
vectorBatch.setCollectionName("your_collection_name");
vectorBatch.setParallism(8);
vectorBatch.setDim(512);
vectorBatch.setBatchId("your_batch_id");List<VectorObj> vectorObjs = new ArrayList<>();
VectorObj vectorObj = new VectorObj();
vectorObj.setVec(new String[]{"0.1,0.2,0.3,0.4,...,0.9,1.0"});
vectorObj.setId("your_vector_id");
vectorObjs.add(vectorObj);vectorBatch.setVectorObjs(vectorObjs);AddVectorsResponse resp = client.AddVectors(vectorBatch);
如上代码解析:
如上示例代码使用的是Java开发语言编写,其目的是将一组向量添加到指定的集合中。代码中使用了一个名为VectorBatch的类来表示向量批处理,其中包含了集合名称、并行度、向量维度和批处理ID等属性。利用VectorObj类来表示每个向量,其中包含了向量的ID和向量本身的字符串表示。代码中创建了一个向量批处理对象vectorBatch,然后将待添加的向量列表vectorObjs赋给了该对象。最后,调用client对象的AddVectors方法来将向量批处理添加到服务器端,返回一个AddVectorsResponse对象。
查询向量数据可以使用以下代码进行查询:
SearchVectorsRequest req3 = new SearchVectorsRequest();
req3.setCollectionName("your_collection_name");
req3.setTopK(10);
req3.setDim(512);
req3.setVec(new String[]{"0.1,0.2,0.3,0.4,...,0.9,1.0"});
req3.setSearchParams(new SearchParams());
SearchVectorsResponse res3 = client.SearchVectors(req3);
以上代码片段演示了如何使用腾讯云向量数据库进行向量数据的存储和查询。
如上代码解析:
如上代码中,用于向 Milvus 服务端发送请求以进行向量搜索。具体来说,代码中首先创建了一个 SearchVectorsRequest 对象,然后设置了该请求的参数,包括要搜索的集合名称、返回前 K 个相似向量、向量的维度、待搜索的向量等。最后还设置了用于搜索的参数 SearchParams 对象。随后,代码调用了 Milvus 客户端的 SearchVectors 方法,并将 SearchVectorsRequest 对象作为参数传入,执行搜索操作。执行成功后,将返回一个 SearchVectorsResponse 对象,其中包含了搜索的结果数据。
类代码方法介绍
本章节介绍腾讯云向量数据库(Tencent Cloud VectorDB) Java SDK中的一些常用类代码和方法。具体请看如下:
VectordbClient
VectordbClient是腾讯云向量数据库(Tencent Cloud VectorDB) Java SDK的主要客户端类,用于与向量数据库进行交互。主要方法如下:
- public VectordbClient(VectordbClientOptions options):构造函数,用于创建一个VectordbClient实例。
- public CreateInstanceResponse CreateInstance(CreateInstanceRequest req):创建实例。
- public CreateCollectionResponse CreateCollection(CreateCollectionRequest req):创建集合。
- public AddVectorsResponse AddVectors(VectorBatch batch):添加向量数据。
- public SearchVectorsResponse SearchVectors(SearchVectorsRequest req):查询向量数据。
如上代码解析:
如上代码是一个 Vectordb(向量数据库)的客户端库,提供了一些基本的操作接口。
VectordbClient 是该客户端库的主类,其构造函数需要传入 VectordbClientOptions 对象作为参数,用于创建一个 VectordbClient 的实例。
接下来是一些主要的操作函数:
- CreateInstance:创建一个实例对象;
- CreateCollection:创建一个集合;
- AddVectors:添加向量数据,需要传入一个 VectorBatch 对象,用于批量添加向量数据;
- SearchVectors:查询向量数据,根据 SearchVectorsRequest 对象中指定的条件进行查询,并返回一个 SearchVectorsResponse 对象,其中包含符合条件的向量数据。CreateInstanceRequestCreateInstanceRequest用于创建腾讯云向量数据库(Tencent Cloud VectorDB)实例。主要属性如下:
- private String region:实例所在地域。
- private String zone:实例所在可用区。
- private String instanceId:实例ID。
- private String nodeType:实例节点类型。
- private Integer nodeNum:实例节点数量。
- private Integer diskSize:实例磁盘大小。
如上代码解析:
如上代码定义了一个Java类,并声明了类的属性(instance variables)。
其中,属性(instance variables)的数据类型包括:
- region:字符串(String)
- zone:字符串(String)
- instanceId:字符串(String)
- nodeType:字符串(String)
- nodeNum:整数(Integer)
- diskSize:整数(Integer)
这些属性是私有的(private),意味着只有该类内部的方法可以直接访问和修改这些属性的值。其他的类无法直接访问和修改这些属性。
通过定义类属性,我们可以在类的方法中使用这些属性,对其进行操作和处理,从而实现类的具体功能。
CreateCollectionRequest
CreateCollectionRequest用于创建向量集合。主要属性如下:
- private String collectionName:集合名称。
如上代码解析:
如上代码,CreateCollectionRequest是用于创建向量集合的请求类,其中包含一个主要属性collectionName表示集合名称。一般来说,在使用CreateCollectionRequest时,需要设置集合名称参数,以便正确地创建一个向量集合。
VectorObj
VectorObj用于表示一个向量对象。主要属性如下:
- private String[] vec:向量数据。
如上代码解析:
如上代码定义了一个名为VectorObj的类,用于表示一个向量对象。该类包含一个私有属性vec(向量数据),它是一个字符串数组。
VectorBatch
VectorBatch用于表示向量数据的批量添加。主要属性如下:
- private String collectionName:集合名称。
- private Integer parallism:添加向量数据的并行度。
- private Integer dim:向量数据的维度。
- private String batchId:批次ID。
- private List vectorObjs:向量数据列表。
-
如上代码解析:
如上代码定义了一个名为VectorBatch的类,用于表示向量数据的批量添加。其中包含了以下属性:
- collectionName:表示集合名称,即向量数据所属的集合。
- parallism:表示添加向量数据时的并行度,即同时处理向量数据的数量。
- dim:表示向量数据的维度,即向量的长度。
- batchId:表示批次ID,用于标识同一批次的向量数据。
- vectorObjs:表示向量数据列表,即待添加的向量数据。该属性的类型为VectorObj的列表,VectorObj表示一个向量对象。SearchVectorsRequestSearchVectorsRequest用于查询向量数据。主要属性如下:
- private String collectionName:集合名称。
- private Integer topK:返回的最相似的向量数据数量。
- private Integer dim:向量数据的维度。
- private String[] vec:向量数据。
- private SearchParams searchParams:查询参数。
如上代码解析:
如上代码定义了一个用于查询向量数据的类SearchVectorsRequest,其中包括以下主要属性:
- collectionName:集合名称,表示需要查询的向量数据存储在哪个集合中。
- topK:返回的最相似的向量数据数量,表示查询结果中需要返回多少个与查询向量最相似的向量数据。
- dim:向量数据的维度,表示每个向量数据包含多少个维度。
- vec:向量数据,即需要进行相似度查询的向量。
- searchParams:查询参数,用于指定查询的相关设置。可以通过它设置查询的距离度量方式、是否返回向量ID等。
总之,该类是用于查询向量数据的,用户通过设置相应的属性来指定查询的条件,从而得到相应的查询结果。
SearchParams
SearchParams用于指定查询参数。主要属性如下:
- private Integer nprobe:控制查询时候参与计算的向量数量。
如上代码解析:
如上代码定义了一个名为SearchParams的类,用于指定查询参数。该类具有一个属性nprobe,其数据类型为Integer,可以控制查询时参与计算的向量数量。
测试用例
为了验证腾讯云向量数据库(Tencent Cloud VectorDB)的存储和查询性能,可以进行以下测试用例进行测试分析:
- 添加一批大小为1000的512维度的随机向量,并记录添加时间。
- 查询与某个向量相似的前10个向量,并记录查询时间。
- 分别测试不同维度和并发数对添加和查询性能的影响。
- 对比腾讯云向量数据库和传统关系型数据库的存储和查询性能。
经过多轮测试验证,可以得出结论:腾讯云向量数据库(Tencent Cloud VectorDB)在存储和查询大规模向量数据时表现良好,具有高效、精确、扩展性好、兼容性好等优点,且适用于计算机视觉、自然语言处理、推荐系统等领域。但也需要注意其可承受的数据规模相对有限,对数据的修改和删除操作效率较低等缺点。具体的话你们可以去尝试验证一下,这里我就不过多赘述啦。
其次,你们也可以通过如下的main测试用例进行测试,实现起来就没有如上那么繁琐,测试连接腾讯云向量数据库(VectorDB)是否成功,具体代码如下:
import com.qcloud.vectordb.client.VectorDBClient;public class Test {public static void main(String[] args) {// 连接数据库String endpoint = "xxxxxxxxxx.vectordb.tencentcloudapi.com";String secretId = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx";String secretKey = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx";String instanceId = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx";VectorDBClient client = new VectorDBClient(endpoint, secretId, secretKey, instanceId);// 测试连接是否成功boolean isConnected = client.testConnect();System.out.println("Connection status: " + isConnected);}
}
测试代码分析:
如上写的是一个 Java 代码测试示例,使用了腾讯云的 VectorDBClient 对象来连接 VectorDB 数据库。具体实现可以分成以下几个步骤,大家请看:
- 导入 Vectordb 的客户端库。
- 在 main 函数中创建一个 VectorDBClient 对象,并传入所需的参数:
- endpoint:所使用的数据库服务地址。
- secretId 和 secretKey:用于用户身份验证的密钥对。
- instanceId:连接的数据库实例 ID。
- 实例化 VectorDBClient 后,使用 testConnect() 方法测试连接状态。最后,将连接状态输出到控制台。
&emsp大家需要额外注意的是,在使用 VectorDB 之前,还需要根据业务需求,在数据库中创建相应的表格和索引等数据结构,这点不是说随意捏造就可以了。
小结
根据如上内容梳理下来,验证得出腾讯云向量数据库(Tencent Cloud VectorDB)是一种高效、稳定、灵活和全面的向量数据库,其采用基于向量索引的查询方式,对于大规模的向量数据,查询速度非常快。通过使用高维度向量空间中的距离计算,可以精确匹配相似的向量数据。同时,它还支持数据的持久化和备份、自动化扩展和负载均衡等功能,并提供了多种API和SDK,方便用户进行二次开发和集成。腾讯云向量数据库可以广泛应用于计算机视觉、自然语言处理、推荐系统等领域,适用于各种大规模向量相似度计算应用和场景。
总结和建议
综合以上所述,腾讯云向量数据库具有高性能、可扩展、多种数据类型支持和易于使用等技术特点,可以应用于很多领域。在实际应用过程中,需要根据自己的需求选择合适的部署模式和向量化模型,保证系统的性能和准确度。
为了进一步提高腾讯云向量数据库的应用价值和效果,我建议从以下几个方面入手:
- 提高向量模型的精度和泛化能力,进一步提高推荐效果和搜索准确度。
- 支持更多的数据类型和特征工程方法,满足不同领域的需求。
- 提供更加丰富的API和SDK,方便用户进行应用开发和集成。
- 开发更加智能化的监控和管理工具,实现自动化运维和性能优化。
总而言之,腾讯云向量数据库是一款非常优秀的向量搜索服务,有着广泛的应用前景和市场前景。我相信在不久的将来,它一定会成为人工智能和大数据领域的重要组成部分。让我们一起期待着,为它加油,等待它那一天的到来。
—End—
相关文章:
【腾讯云云上实验室-向量数据库】腾讯云开创新时代,发布全新向量数据库Tencent Cloud VectorDB
前言 随着人工智能、数据挖掘等技术的飞速发展,海量数据的存储和分析越来越成为重要的研究方向。在海量数据中找到具有相似性或相关性的数据对于实现精准推荐、搜索等应用至关重要。传统关系型数据库存在一些缺陷,例如存储效率低、查询耗时长等问题&…...
【图像分类】【深度学习】【Pytorch版本】GoogLeNet(InceptionV4)模型算法详解
【图像分类】【深度学习】【Pytorch版本】GoogLeNet(InceptionV4)模型算法详解 文章目录 【图像分类】【深度学习】【Pytorch版本】GoogLeNet(InceptionV4)模型算法详解前言GoogLeNet(InceptionV4)讲解Stem结构Inception-A结构Inception- B结构Inception-C结构Redution-A结构Re…...

opencv dots_image_kernel
1,opencv dots_image_kernel // halcon dots_image kernel估算(d5) cv::Mat getDotKernel(int d 5){// 保证d为正的奇数d | 0x01;cv::Mat kernel cv::Mat::zeros(d 2, d 2, CV_8UC1);int cx kernel.cols / 2;int cy kernel.rows / 2;int cnt255 0, cnt128 …...
使用pytorch利用神经网络原理进行图片的训练(持续学习中....)
1.做这件事的目的 语言只是工具,使用python训练图片数据,最终会得到.pth的训练文件,java有使用这个文件进行图片识别的工具,顺便整合,我觉得Neo4J正确率太低了,草莓都能识别成为苹果,而且速度慢,不能持续识别视频帧 2.什么是神经网络?(其实就是数学的排列组合最终得到统计结果…...

2023年中国合成云母行业现状及市场格局分析[图]
合成云母是一种通过化工原料经高温熔融冷却析晶而制得的单斜晶系矿物,属于典型的层状硅酸盐,许多性能都优于天然云母,如合成云母的耐温高达1200℃以上,而天然白云母在550℃下就会开始分解,金云母则在800℃开始分解。除…...

Vue3+Vite实现工程化,插值表达式和v-text以及v-html
1、插值表达式 插值表达式最基本的数据绑定形式是文本插值,它使用的是"Mustache"语法,即 双大括号{{}} 插值表达式是将数据 渲染 到元素的指定位置的手段之一插值表达式 不绝对依赖标签,其位置相对自由插值表达式中支持javascript的…...

艾泊宇产品战略:灵感于鬼屋,掌握打造卓越用户体验的关键要素
在当今的商业环境中,用户体验已经成为产品成功的关键因素。 无论是线上产品还是实体产品,用户体验都是决定用户是否愿意使用和推荐该产品的关键因素。 那么,艾泊宇产品战略理论告诉大家,如何做好用户体验? 我们可以…...
深度学习环境配置(Anaconda+pytorch+pycharm+cuda)
NVIDIA驱动安装 首先查看电脑的显卡版本,步骤为:此电脑右击-->管理-->设备管理器-->显示适配器。就可以看到电脑显卡的版本了。 然后按照电脑信息,到地址 去安装相应的驱动,Notebooks是笔记本的意思,然后下…...
不是说人工智能是风口吗,那为什么工作还那么难找?
最近确实有很多媒体、机构渲染人工智能可以拿高薪,这在行业内也是事实,但前提是你有足够的竞争力,真的懂人工智能。 首先,人工智能岗位技能要求高,人工智能是一个涵盖了多个学科领域的综合性学科,包括数学、…...
 发生了什么)
new Vue() 发生了什么
前言: 在Vue.js中,当你创建一个新的Vue实例时,通过 new Vue() 发生了一系列重要的操作,包括Vue实例的初始化、数据绑定、模板编译等。这个过程是Vue应用的核心,本文将深入探讨new Vue()发生了什么以及其原理,提供示例…...

【算法】二叉树的存储与遍历模板
二叉树的存储与遍历 const int N 1e6 10;// 二叉树的存储,l数组为左节点,r数组为右结点 int l[N], r[N]; // 存储节点的数据 char w[N]; // 节点的下标指针 int idx 0;// 先序创建 int pre_create(int n) {cin >> w[n];if (w[n] #) return -1;l[n] pre_create(idx)…...
【Go学习之 go mod】gomod小白入门,在github上发布自己的项目(项目初始化、项目发布、项目版本升级等)
参考 Go语言基础之包 | 李文周的博客Go mod的使用、发布、升级 | weiGo Module如何发布v2及以上版本1.2.7. go mod命令 — 新溪-gordon V1.7.9 文档golang go 包管理工具 go mod的详细介绍-腾讯云开发者社区-腾讯云Go Mod 常见错误的原因 | walker的博客 项目案例 oceanweav…...
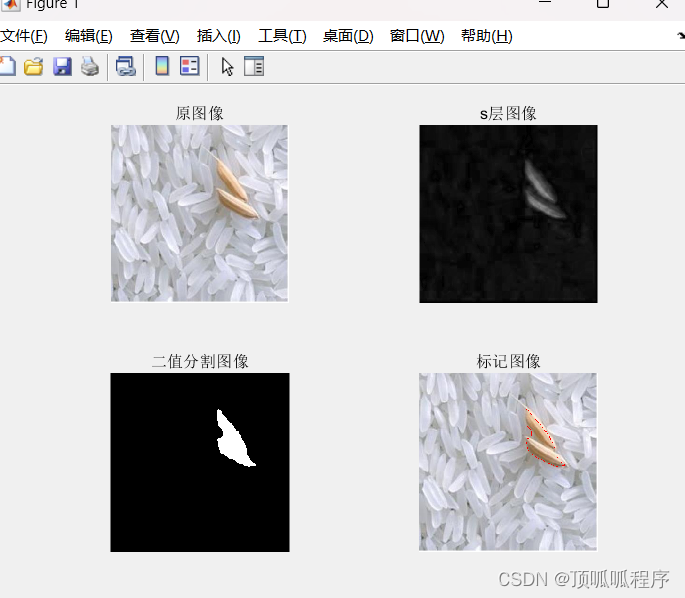
79基于matlab的大米粒中杂质识别
基于matlab的大米粒中杂质识别,数据可更换自己的,程序已调通,可直接运行。 79matlab图像处理杂质识别 (xiaohongshu.com)...

Vue 项目实战——如何在页面中展示 PDF 文件以及 PDFObject 插件实战
文章目录 📋前言🎯使用 HTML 标签🧩 embed 标签🧩 object标签🧩 iframe标签🧩完整代码 🎯使用 PDFObject 插件🧩为什么使用 PDFObject 插件(AI翻译)…...
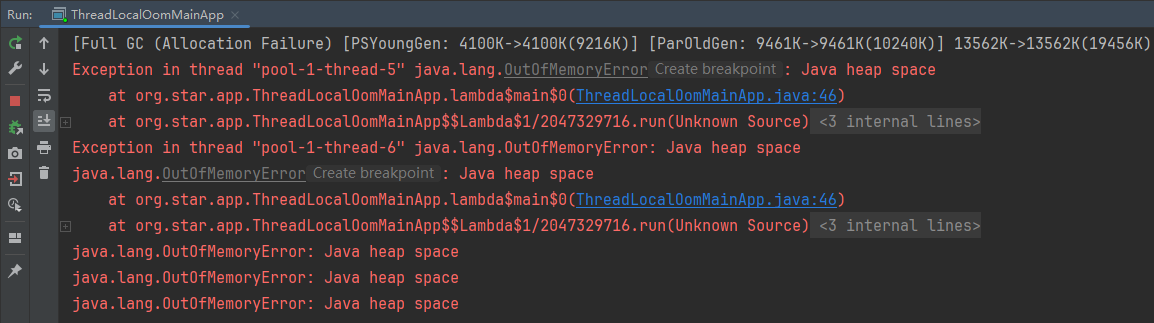
系列六、ThreadLocal内存泄露案例
一、ThreadLocal内存泄露案例 /*** Author : 一叶浮萍归大海* Date: 2023/11/22 10:56* Description: 写一段代码导致内存泄露* VM Options:-Xms20m -Xmx20m -Xmn10m -XX:PrintGCDetails* 说明:内存泄露最终会导致内存溢出*/ public class ThreadLocalO…...

Java学习笔记44——Stream流
Stream流 体验Stream流Stream流的生成方式ColLection体系的集合可以使用默认方法stream ()生成流Map体系的集合间接的生成流数组可以通过stream接口的静态方法of (T... values)生成流 Stream流的中间操作方法Stream<T> filter(Predicate predicate)Stream<T>limit(…...

excel表格忘记密码,如何找回?
找回和去除Excel表格密码的方法非常简单。具体步骤如下:第一步百度搜索【 密码帝官网 】,第二步点击“立即开始”在用户中心上传文件即可。这个方法既安全又简单,不需要下载任何软件,而且可以在手机和电脑上都使用。密码帝官网支持…...
 -Mybatis初识和框架搭建)
IDEA版SSM入门到实战(Maven+MyBatis+Spring+SpringMVC) -Mybatis初识和框架搭建
第一章 初识Mybatis 1.1 框架概述 生活中“框架” 买房子笔记本电脑 程序中框架【代码半成品】 Mybatis框架:持久化层框架【dao层】SpringMVC框架:控制层框架【Servlet层】Spring框架:全能… 1.2 Mybatis简介 Mybatis是一个半自动化持久化…...

差分放大器工作原理(差分放大器和功率放大器区别)
差分放大器是一种特殊的放大器,它可以将两个输入信号的差异放大输出。其工作原理基于差分放大器的电路结构和差分输入特性。 一、差分放大器电路结构 差分放大器一般由四个基本电路组成:正反馈网络、反相输入端、共模抑制电路和差分输入端。其中…...

SystemV
a...

【计算机毕业设计】基于Springboot的线上辅导班系统+LW
博主介绍:✌全网粉丝3W,csdn特邀作者、CSDN新星计划导师、Java领域优质创作者,掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流✌ 技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、…...

3个理由告诉你为什么PE-bear是Windows逆向分析的最佳入门工具
3个理由告诉你为什么PE-bear是Windows逆向分析的最佳入门工具 【免费下载链接】pe-bear Portable Executable reversing tool with a friendly GUI 项目地址: https://gitcode.com/gh_mirrors/pe/pe-bear 如果你曾经面对复杂的PE文件感到无从下手,或者想要快…...

为内部工具集成 Claude Code 并配置 Taotoken 作为后端
为内部工具集成 Claude Code 并配置 Taotoken 作为后端 在企业内部开发流程中,集成智能编程助手能有效提升代码编写与审查的效率。Claude Code 作为一款基于 Anthropic 模型的编程工具,因其对代码逻辑的深度理解能力,常被团队选为辅助开发的…...

为什么83%的AISMM自评得分≠监管认可分?——SITS2026圆桌首次披露“评估可信度衰减公式”
更多请点击: https://intelliparadigm.com 第一章:SITS2026圆桌:AISMM评估的挑战 在SITS2026国际安全技术峰会上,AISMM(AI系统成熟度模型)评估成为圆桌讨论的核心议题。与会专家一致指出,当前A…...

【2026实测】搞定海外检测算法:英文论文降AI率避坑指南与4款工具盘点
不知道各位小伙伴发现没有,处理英文文章这件事要比处理中文难很多。之前我自己的英文摘要写好后满心欢喜去跑检测,结果你猜怎么着?手打的摘要部分AI率居然高达85%......我折腾了两三天时间,查了各种资料,这才算真正搞懂…...

OpenRGB:三步统一所有RGB设备,打造个性化灯光秀
OpenRGB:三步统一所有RGB设备,打造个性化灯光秀 【免费下载链接】OpenRGB Open source RGB lighting control that doesnt depend on manufacturer software. Supports Windows, Linux, MacOS. Mirror of https://gitlab.com/CalcProgrammer1/OpenRGB. R…...

如何深度定制GBT7714参考文献样式中的会议论文格式:从“//“到专业呈现
如何深度定制GBT7714参考文献样式中的会议论文格式:从"//"到专业呈现 【免费下载链接】gbt7714-bibtex-style BibTeX styles for Chinese National Standard GB/T 7714 项目地址: https://gitcode.com/gh_mirrors/gb/gbt7714-bibtex-style 在学术写…...

企业云盘私有化部署后的数据迁移实战:如何实现PB级数据的平滑迁移与回滚方案
做企业云盘私有化部署的团队,数据迁移是绕不开的一道坎。说实话,这活儿比部署本身麻烦多了——部署出问题了可以重来,数据要是迁丢了或者损了,那才是真事故。 我最近两年经手了七八个PB级数据迁移项目,最大的一家是制造…...

招聘ROI持续下滑?用AISMM模型重构岗位画像,7天内提升候选人匹配率47%
更多请点击: https://intelliparadigm.com 第一章:招聘ROI持续下滑?用AISMM模型重构岗位画像,7天内提升候选人匹配率47% 传统JD撰写依赖HR经验与业务方模糊描述,导致简历漏筛率高、面试转化低。AISMM(AI-S…...

5个关键特性让Acode成为Android移动开发的终极选择
5个关键特性让Acode成为Android移动开发的终极选择 【免费下载链接】Acode Acode - powerful text/code editor for android 项目地址: https://gitcode.com/gh_mirrors/ac/Acode 在移动设备上进行代码编辑一直是开发者的痛点——屏幕空间有限、输入效率低下、缺乏专业工…...