OpenShift 4 - 部署 RHODS 环境,运行 AI/ML 应用(视频)
《OpenShift / RHEL / DevSecOps 汇总目录》
说明:本文已经在 OpenShift 4.14 + RHODS 1.33 的环境中验证
文章目录
- RHODS 简介
- 安装 RHODS 环境
- 运行环境说明
- 用 RHODS Operator 安装环境
- 创建 Jupyter Notebook 运行环境
- 开发调式 AI/ML 应用
- 部署运行 AI/ML 应用
- 视频
- 参考
RHODS 简介
Red Hat OpenShift AI 是一个专注于人工智能的产品组合,为人工智能/ML 实验和模型的整个生命周期提供工具,其中包括 Red Hat OpenShift Data Science (RHODS)。RHODSe 是红帽 OpenShift AI 的核心构成软件,它是红帽驱动的社区开源软件 Open Data hub 的企业版。
RHODS 是面向混合云的开源 ML 平台。它向数据科学家和开发人员提供了一个完全受支持的环境,以便在部署到生产环境之前进行快速开发、训练和测试ML 模型。RHODS 提供了 ML 常用的 Jupyter notebooks-as-a-service、TensorFlow 和 PyTorch 等工具环境以及用于模型服务和数据科学管道的 MLOps 组件,而且还对这些组件以及流程进行了集成,使得开箱即用。
RHODS 是独立于 OpenShift 的产品,它即可在红帽托管的公有云上部署运行,也可在用户自管的 OpenShift 环境中部署运行。
安装 RHODS 环境
运行环境说明
- 本文使用的是单机版 OpenShift Local 4.14 环境。
- 本文除了要以容器的方式运行部署 RHODS(包含 Jupyter notebooks、ML 运行监控等)环境,还要部署测试应用(至少分配 8G 内存),因此为整个 OpenShift Local 的虚机提供了 20vCore + 48GB 内存 + 250GB 硬盘。
- 运行 RHODS 的硬件环境是否需要有 GPU 取决于在其上运行的 ML 模型是否强制需要。如有需要,可在配有 GPU 资源的 OpenShift 上为运行的 ML 声明分配 GPU。但如无强制需要和声明,ML 模型可在 CPU 上运行。由于本文意为演示 RHODS,OpenShift 运行环境没有配 GPU,ML 直接运行在 CPU 上。
用 RHODS Operator 安装环境
- 在 OpenShift 的 OperatorHub 中找到并使用默认配置安装 Red Hat OpenShift Data Science Operator。
- 在 redhat-ods-operator 项目中使用默认配置创建一个 Red Hat OpenShift Data Science 实例。
- 完成后会在 OpenShift 中创建以下 4 个项目:redhat-ods-applications、redhat-ods-monitoring、redhat-ods-operator、 redhat-notebook。安装完后对应的项目中部署的资源如下面几个截图:
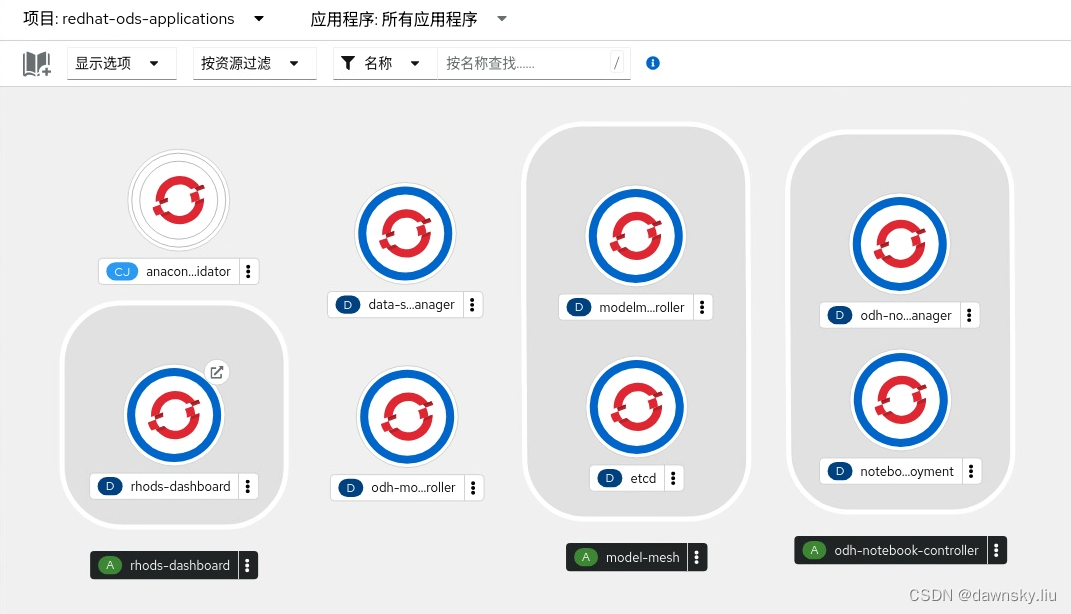

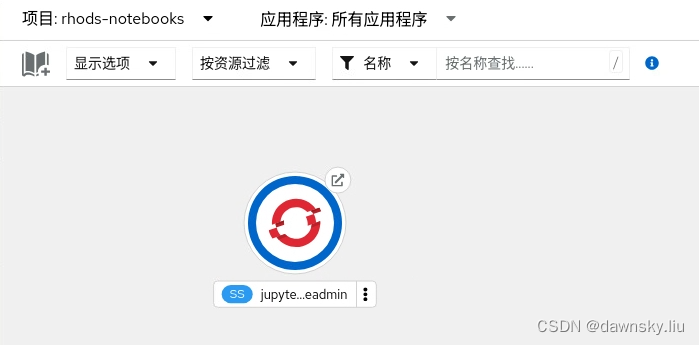
- 打开 redhat-ods-applications 项目中的 rhods-dashboard 路由地址。登录后即可看到如下图的 OpenShift Data Science 的控制台。
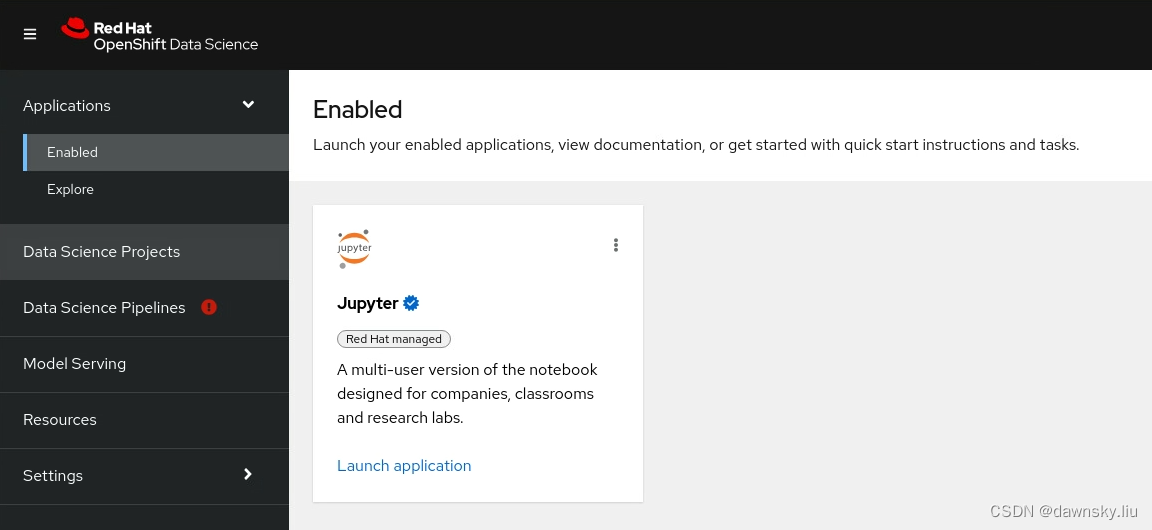
创建 Jupyter Notebook 运行环境
- 点击上图的 Jupyter 的 Launch application 进入Start a notebook server 页面,
- 在 Start a notebook server 页面中选中 TensorFlow 2023.1(该环境支持运行 CUDA、Python 和 TensorFlow);Container Size 选择 Small。
- 点击 Start Server 按钮后会出现 Starting server 窗口显示创建环境的进度。由于这个过程会下载相应的 Image,所以需要等一段时间。完成后会显示下图:
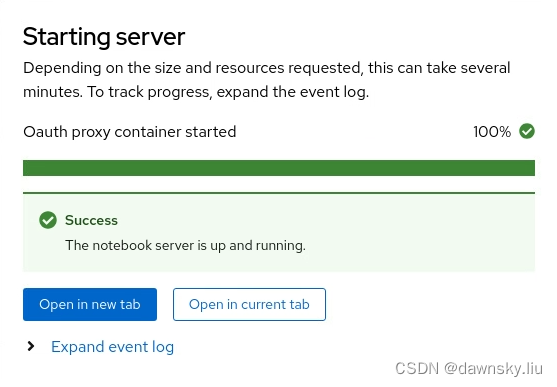
- 点击上图的 Open in new tab 后会出现 Jupyter 页面。
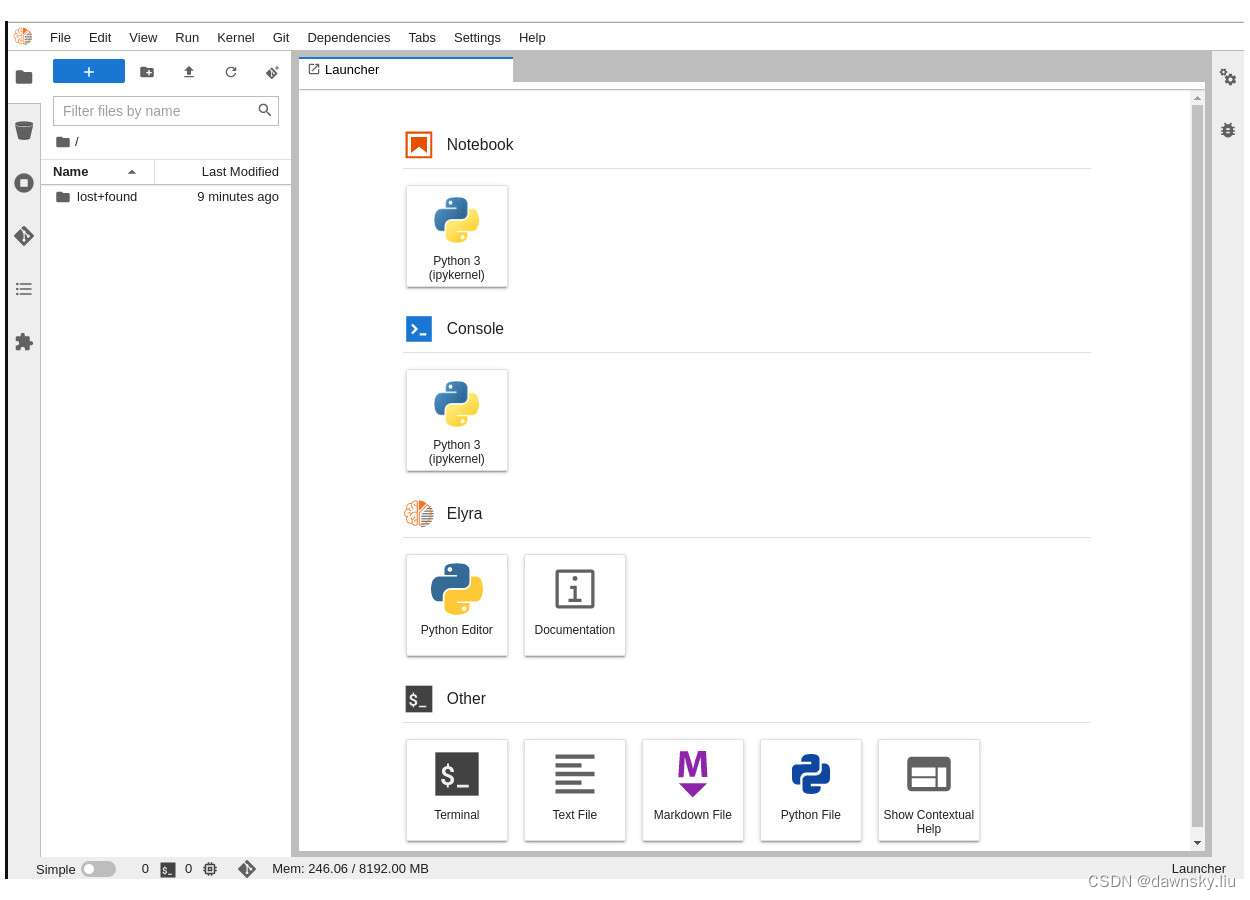
开发调式 AI/ML 应用
- 点击上图 Git 图标,然后再选择 Clone a Repository。

- 在弹出的 Clone a repo 窗口中提供 https://github.com/rh-aiservices-bu/licence-plate-workshop.git,然后点击 Clone。完成 Clone 后可以在 Jupyter 中看到如下图的 license-plate-workshop 应用的文件和目录。

- 依次打开开头为 01 到 04 的 Jupyter 文件,然后点击 Start the selected the cells and advance 按钮逐步执行。
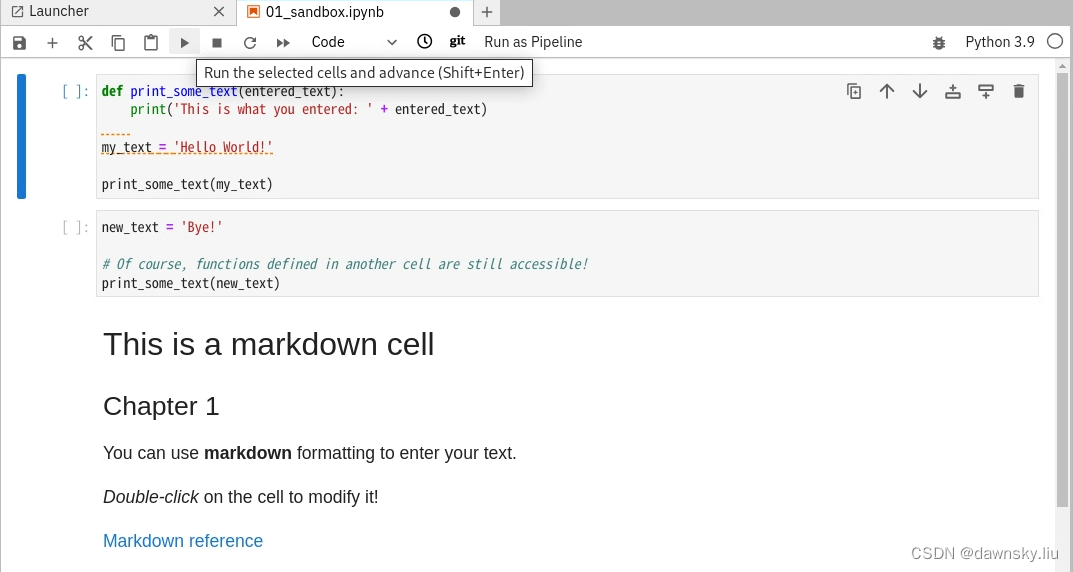
- 在完成下一节 “部署运行 AI/ML 应用” 后再打开开头 05 的 Jupyter 文件。先将 my_image 和 my_route 改为 car.jpg 和 ML 应用的路由地址。然后运行即可看到从 car.jpg 文件中识别的车牌。

部署运行 AI/ML 应用
- 在 OpenShift 的 “开发者” 视图中,创建 ai-app 项目。
- 进入“添加”,再进入 Git 仓库。
- 在 Git Repo URL 中提供 https://github.com/rh-aiservices-bu/licence-plate-workshop.git。
- 在 “显示高级路由选项” 里去掉 “安全路由” 选项。
- 最后点击 “创建”。
- OpenShift 会创建一个 “构建” 来生成该 ML 应用的镜像,然后再部署生成的 ML 应用镜像。
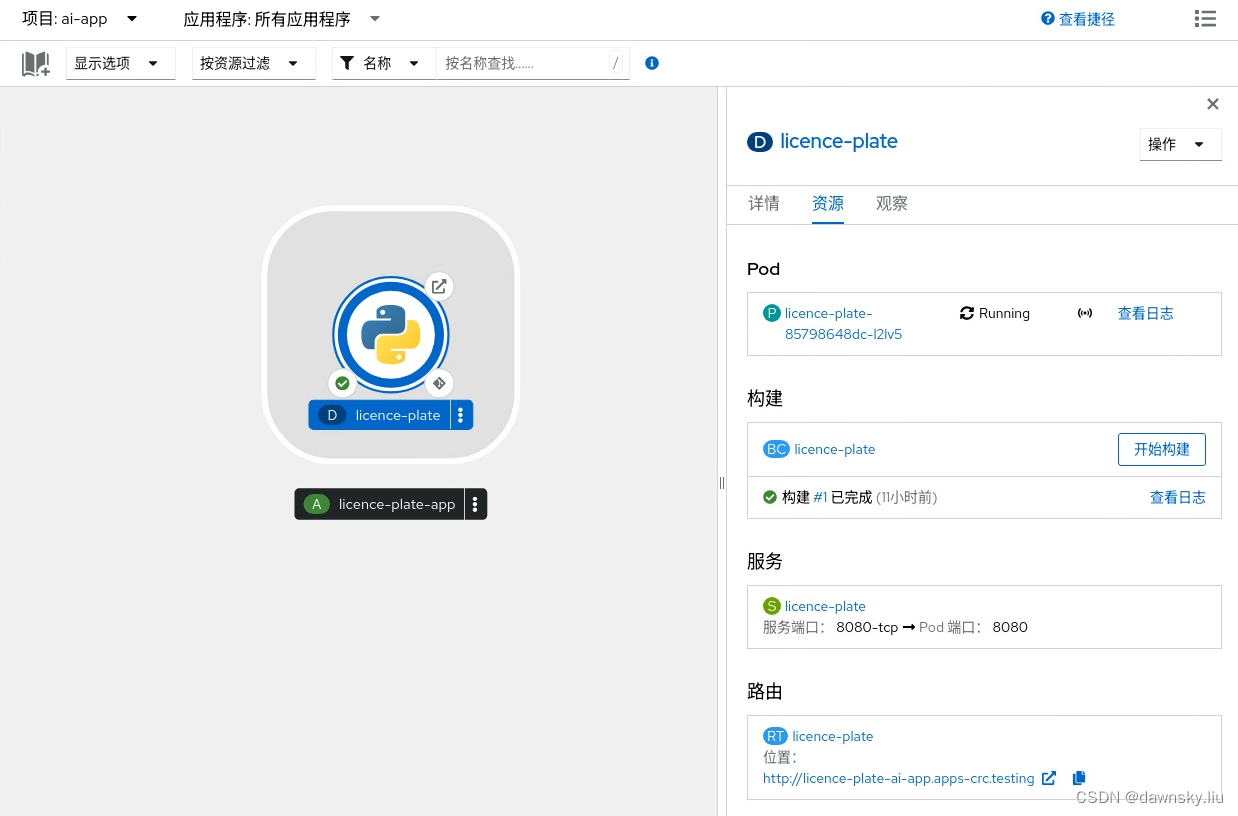
- 在完成部署后,可以通过上图的 “路由” 打开 ML 应用页面,会显示下图运行状态。

- 最后可继续完成上一节的最后一步,运行 05 文件,从客户端调用 ML 应用。
视频
参考
https://ai-on-openshift.io/getting-started/openshift-data-science
https://redhat-scholars.github.io/rhods-lp-workshop
https://cloud.redhat.com/blog/scaling-model-serving-with-red-hat-openshift-data-science
https://developers.redhat.com/learn/openshift-data-science
https://redhat-scholars.github.io/cloudnative-tutorials/openshift-data-science-object-detection.html
https://myopenshiftblog.com/installing-openshift-data-science-ods-in-self-managed-environment
https://medium.com/@contact.av.rh/unleashing-the-full-potential-of-rhods-for-model-fine-tuning-and-inferencing-99a67b65e74e
相关文章:
OpenShift 4 - 部署 RHODS 环境,运行 AI/ML 应用(视频)
《OpenShift / RHEL / DevSecOps 汇总目录》 说明:本文已经在 OpenShift 4.14 RHODS 1.33 的环境中验证 文章目录 RHODS 简介安装 RHODS 环境运行环境说明用 RHODS Operator 安装环境创建 Jupyter Notebook 运行环境 开发调式 AI/ML 应用部署运行 AI/ML 应用视频参…...

MySQL 的执行原理(二)
5.3. MySQL 的查询成本 5.3. MySQL 的查询成本 MySQL 执行一个查询可以有不同的执行方案,它会选择其中成本最低,或者 说代价最低的那种方案去真正的执行查询。不过我们之前对成本的描述是非常模 糊的,其实在 MySQL 中一条查询语句的执行成本…...
 和 =any(?) 用法/性能对比)
postgres in (?,?) 和 =any(?) 用法/性能对比
刚刚回顾了一下 JDBC 操作 SQL Server 时如何传入列表参数,即如何给 in (?) 条件直接传入一个列表参数,然而本质上是不支持,最终不得不展开为 in (?, ?,...?) 针对每个元素单独设置参数,不定长的参数对于重用已编译 PreparedS…...

46. Qt Android调用Java代码进行辅助开发 -- 框架搭建
1. 说明 使用Qt进行android开发时,某种情况下使用C++的知识或者Qt提供的方法是无法满足功能需求的,即使通过各种手段能够勉强实现功能,也非常的麻烦。此时,就需要Java来辅助实现了。在Qt中提供了调用Java代码的接口,比较方便。本片博客先介绍如何搭建一个能够调用java代码…...

NX二次开发UF_CAM_PREF_set_logical_value 函数介绍
文章作者:里海 来源网站:https://blog.csdn.net/WangPaiFeiXingYuan UF_CAM_PREF_set_logical_value Defined in: uf_cam_prefs.h int UF_CAM_PREF_set_logical_value(UF_CAM_PREF_t pref, logical value ) overview 概述 This function sets the lo…...

docker下移除不使用的镜像、容器、卷、网络
Prune images docker image prune移除没有标签并且没有被容器引用的镜像,这种镜像称为 dangling(摇晃的) 镜像。 示例1:docker image prune 删除了redis,无标签且无引用 docker ps -a CONTAINER ID IMAGE COMMAND CREATED STA…...
C语言基本算法之选择排序
目录 概要: 代码如下 运行结果如下 概要: 它和冒泡排序一样,都是把数组元素按顺序排列,但是方法不同,冒泡排序是把较小值一个一个往后面移,选择排序则是直接找出最小值,可以这个说ÿ…...
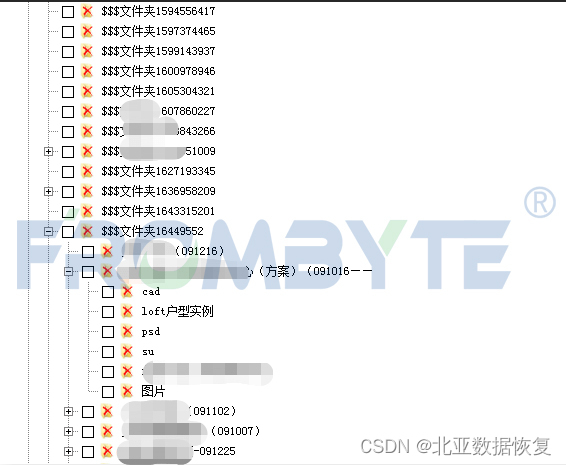
服务器数据恢复—raid5上层NTFS分区误删除/格式化的数据恢复案例
NTFS是windows操作系统服务器应用最为广泛的文件系统之一。理论上,NTFS文件系统格式化操作虽然不会对数据造成太大的影响,但是有可能会出现部分文件目录结构丢失的情况。下面介绍一台服务器误操作导致raid5阵列上层的NTFS分区被格式化后如何逆向操作恢复…...
【漏洞复现】IP-guard WebServer 存在远程命令执行漏洞
漏洞描述 IP-guard是由溢信科技股份有限公司开发的一款终端安全管理软件,旨在帮助企业保护终端设备安全、数据安全、管理网络使用和简化IT系统管理。 免责声明 技术文章仅供参考,任何个人和组织使用网络应当遵守宪法法律,遵守公共秩序,尊重社会公德,不得利用网络从事危…...

人工智能学习阶段有哪些?
人工智能学习阶段有哪些? 人工智能是一个跨学科、跨领域的杂交学科,未来的趋势来看,人工智能的出现使人们的生活变得更美好、更便捷,许多小伙伴想学习人工智能,其实看似人工智能比较杂多,无从下手,我们只要从以下7个阶…...

vue 中为什么需要虚拟DOM、VDOM 是如何生成的、VDOM 如何做 diff 的?
一、vue 中为什么需要虚拟DOM 1.1本概念 基本上所有框架都引入了虚拟 DOM 来对真实 DOM 进行抽象,也就是现在大家所熟知的VNode 和VDOM Virtual DOM 就是用js 对象来描述真实 DOM,是对真实 DOM 的抽象,由于直接操作 DOM 性能低但是is 层的操…...

数据分析思维与模型:相关分析法
相关分析法是一种用于研究两个或多个变量之间关系强度和方向的统计方法。这种方法在多个领域,如经济学、心理学、社会科学和自然科学中都有广泛应用。其核心是通过计算相关系数来量化变量之间的相关性。以下是相关分析法的一些基本概念和步骤: 选择变量…...

【算法萌新闯力扣】:两句话中的不常见单词
力扣热题:两句话中的不常见单词 开篇 今天是备战蓝桥杯的第19天,今天到目前刷了4道力扣算法题。其中,这道题是对我来说收获最大的一道,让我更熟练地掌握了一些算法题中方法,于是来与大家分享一下。 题目链接: 884.两…...

Xilinx Zynq-7000系列FPGA任意尺寸图像缩放,提供两套工程源码和技术支持
目录 1、前言免责声明 2、相关方案推荐FPGA图像处理方案FPGA图像缩放方案 3、设计思路详解HLS 图像缩放介绍 4、工程代码1:图像缩放 HDMI 输出PL 端 FPGA 逻辑设计PS 端 SDK 软件设计 5、工程代码2:图像缩放 LCD 输出PL 端 FPGA 逻辑设计PS 端 SDK 软件设…...
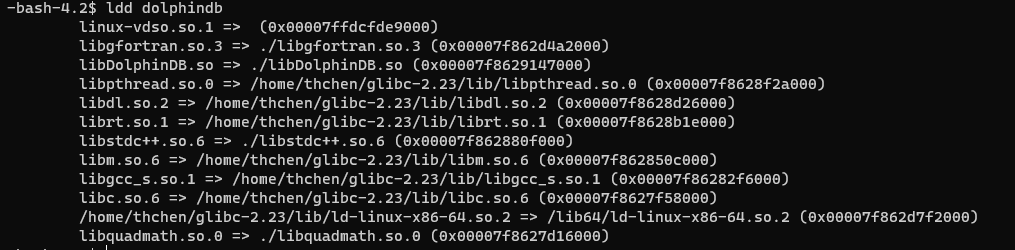
基于 Glibc 版本升级的 DolphinDB 数据查询性能优化实践
在高并发查询、查询需要涉及很多个分区的情况下,低版本的 glibc(低于2.23)会严重影响查询性能。需要升级 glibc 解决该问题优化性能。我们撰写了本文,通过 patchelf 工具修改可执行文件和动态库的 rpath,达到无需升级系…...

【顺序表的应用-通讯录的实现】
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 前言 一、顺序表的应用 1. 基于动态顺序表实现通讯录 1、功能要求 2、代码实现 二、通讯录的代码实现 1.通讯录的底层结构(顺序表) (1)思路展示 (2)底层代码实现(顺序表…...
[Spring Cloud] Nacos 实战 + Aws云服务器
文章目录 前言一、拥有一台Aws Linux服务器1.1、选择Ubuntu版本Linux系统1.2、创建新密钥对1.3、网络设置1.4、配置成功,启动实例1.5、回到实例区域1.6、进入具体的实例1.7、设置安全组 二、在Mac上连接Aws云服务,并安装配置JDK112.1、解决离奇的错误2.2…...

SpringCloud微服务注册中心:Nacos介绍,微服务注册,Ribbon通信,Ribbon负载均衡,Nacos配置管理详细介绍
微服务注册中心 注册中心可以说是微服务架构中的”通讯录“,它记录了服务和服务地址的映射关系。在分布式架构中,服务会注册到这里,当服务需要调用其它服务时,就这里找到服务的地址,进行调用。 微服务注册中心 服务注…...
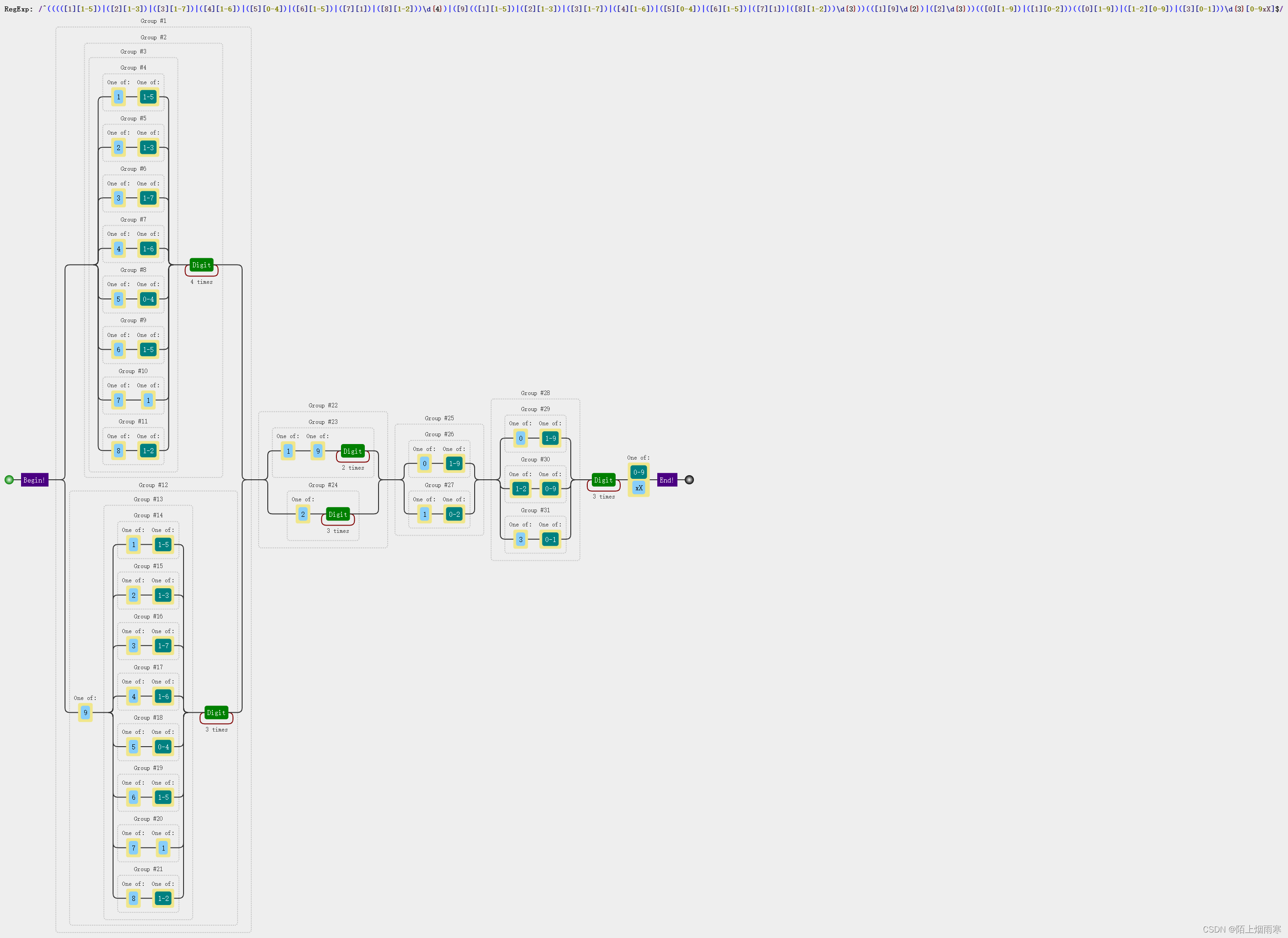
身份证号码校验
根据《新版外国人永久居留身份证适配性改造要点》,公司需要把代码中对身份证的校验进行优化 就文档内容可以看到需要优化的要点是: 新版永居证号码以 9 开头 受理地区代码出生日期顺序码校验码;(共18位) egÿ…...

ArcGIS如何处理并加载Excel中坐标数据?
做GIS行业的各位肯定免不了跟数据打交道,其中数据的处理说复杂也复杂,因为我们要花时间去做数据的转换及调整工作,那说简单也简单,因为我们有很多的工具可以使用,那么今天我就给大家带来处理Excel中的GIS数据中的其中一…...

PiliPlus实战手册:解锁纯净跨平台B站观影体验
PiliPlus实战手册:解锁纯净跨平台B站观影体验 【免费下载链接】PiliPlus PiliPlus 项目地址: https://gitcode.com/gh_mirrors/pi/PiliPlus 在广告泛滥、体验割裂的官方客户端之外,一个基于Flutter开发的跨平台B站客户端PiliPlus正悄然改变你的观…...

高效Instagram视频下载器:三分钟掌握免费下载技巧
高效Instagram视频下载器:三分钟掌握免费下载技巧 【免费下载链接】instagram-video-downloader Simple website made with Next.js for downloading instagram videos with an API that can be used to integrate it in other applications. 项目地址: https://…...

MultiDIC:多视角三维视觉测量与实验力学分析的开源创新工具
MultiDIC:多视角三维视觉测量与实验力学分析的开源创新工具 【免费下载链接】MultiDIC Matlab 3D Digital Image Correlation Toolbox 项目地址: https://gitcode.com/gh_mirrors/mu/MultiDIC MultiDIC作为一款专业的MATLAB工具箱,为三维视觉测量…...
)
保姆级避坑指南:在VMware Workstation 17上搞定macOS Ventura虚拟机(附Intel/AMD配置差异)
VMware Workstation 17上完美运行macOS Ventura虚拟机的终极指南 在Windows环境下运行macOS虚拟机一直是开发者和技术爱好者的热门需求,尤其是对于需要跨平台测试或体验苹果生态的用户。然而,这个过程充满了各种技术陷阱和兼容性问题。本文将深入探讨在V…...

Showdown.js 完整指南:轻松实现 Markdown 到 HTML 双向转换
Showdown.js 完整指南:轻松实现 Markdown 到 HTML 双向转换 【免费下载链接】showdown A bidirectional Markdown to HTML to Markdown converter written in Javascript 项目地址: https://gitcode.com/gh_mirrors/sh/showdown 想要在网页中优雅展示 Markdo…...

TIDAL音乐下载器终极指南:tidal-dl-ng让您轻松收藏高品质音乐
TIDAL音乐下载器终极指南:tidal-dl-ng让您轻松收藏高品质音乐 【免费下载链接】tidal-dl-ng TIDAL Media Downloader Next Generation! Up to HiRes / TIDAL MAX 24-bit, 192 kHz. 项目地址: https://gitcode.com/gh_mirrors/ti/tidal-dl-ng 还在为TIDAL平台…...

基于Docker与Claude SDK构建AI代理:Nagi项目架构解析与实战
1. 项目概述:构建你的个人AI副驾 如果你和我一样,每天的工作流被Slack、Discord、Asana等工具切割得支离破碎,总是在不同应用间切换,重复着“复制-粘贴-提问-等待”的循环,那么你大概也幻想过能有一个“数字副驾”。它…...

从DAVID结果到发表级图表:手把手用Excel搞定KEGG通路富集条形图与热图
从DAVID结果到发表级图表:Excel实战KEGG通路富集可视化全流程 生物信息学分析中,KEGG通路富集结果的可视化是论文写作的关键环节。许多研究者虽然能熟练使用DAVID完成分析,却常卡在数据整理和图表美化这一"最后一公里"。本文将手把…...

别只改Nginx配置!从HTTP协议层拆解206状态码与CONTENT_LENGTH_MISMATCH的坑
从HTTP协议层拆解206状态码与CONTENT_LENGTH_MISMATCH的深层逻辑 视频播放失败时控制台弹出的net::ERR_CONTENT_LENGTH_MISMATCH 206 (Partial Content)错误,往往让开发者陷入反复调整Nginx配置的循环。但真正的问题可能隐藏在HTTP协议层与数据传输机制的配合间隙中…...

告别低效重复:ChatGPT 5.5 + GPT Image 2 重塑开发者工作流
摘要: 在 2026 年的今天,开发者的工作流正在经历一场静默的革命。本文将通过实测案例,展示如何利用 ChatGPT 5.5 的代码理解能力与 GPT Image 2 的视觉生成能力,结合 VS Code 插件与 API 调用,实现从架构设计、代码生成…...