zookeeper应用之分布式队列
队列这种数据结构都不陌生,特点就是先进先出。有很多常用的消息中间件可以有现成的该部分功能,这里使用zookeeper基于发布订阅模式来实现分布式队列。对应的会有一个生产者和一个消费者。
这里理论上还是使用顺序节点。生产者不断产生新的顺序子节点,消费者watcher监听节点新增事件来消费消息。
生产者:
CuratorFramework client = ...
client.start();
String path = "/testqueue";
client.create().creatingParentsIfNeeded().withMode(CreateMode.PERSISTENT_SEQUENTIAL).forPath(path,"11".getBytes());消费者:
CuratorFramework client = ...
client.start();
String path = "/testqueue";
PathChildrenCache pathCache = new PathChildrenCache(client,path,true);
pathCache.getListenable().addListener(new PathChildrenCacheListener() {@Overridepublic void childEvent(CuratorFramework client, PathChildrenCacheEvent event) throws Exception {if(event.getType() == PathChildrenCacheEvent.Type.CHILD_ADDED){ChildData data = event.getData();//handle msgclient.delete().forPath(data.getPath());}}
});
pathCache.start();
使用curator queue:
先来使用基本的队列类DistributedQueue。
DistributedQueue的初始化需要提交准备几个参数:
client连接就不多说了:
CuratorFramework client = ...
QueueSerializer:这个主要是用来指定对消息data进行序列化和反序列化
这里就搞一个简单的字符串类型:
QueueSerializer<String> serializer = new QueueSerializer<String>() {@Overridepublic byte[] serialize(String item) {return item.getBytes();}@Overridepublic String deserialize(byte[] bytes) {return new String(bytes);}
};
QueueConsumer消息consumer,当有新消息来的时候会调用consumer.consumeMessage()来处理消息
这里也搞个简单的string类型的处理consumer
QueueConsumer<String> consumer = new QueueConsumer<String>() {@Overridepublic void consumeMessage(String s) throws Exception {System.out.println("receive msg:"+s);}@Overridepublic void stateChanged(CuratorFramework curatorFramework, ConnectionState connectionState) {//TODO}
};
队列消息发布:
//队列节点路径
String queuePath = "/queue";
//使用上面准备的几个参数构造DistributedQueue对象
DistributedQueue<String> queue = QueueBuilder.builder(client,consumer,serializer,queuePath).buildQueue();
queue.start();
//调用put方法生产消息
queue.put("hello");
queue.put("msg");
Thread.sleep(2000);
queue.put("3");
这样在启动测试程序在,consumer的consumeMessage方法就会收到queue.put的消息。
这里有个问题有没有发现,在初始化queue的时候需要指定consumer,那岂不是只能同一个程序中生产消费,何来的分布式?
其实这里在queue对象创建的时候consumer可以为null,这个时候queue就只生产消息。具体的逻辑需要看下DistributedQueue类的源码。
在DistributedQueue类的构造函数有一步设置isProducerOnly属性
isProducerOnly = (consumer == null);
然后在start()方法会根据isProducerOnly来判断启动方式
if ( !isProducerOnly || (maxItems != QueueBuilder.NOT_SET) )
{childrenCache.start();
}if ( !isProducerOnly )
{service.submit(new Callable<Object>(){@Overridepublic Object call(){runLoop();return null;}});
}
这里看到consumer为空,两个if不成立,不会初始化对那个的消息消费逻辑wather监听。只需要在另一个程序里创建queue启动时指定consumer即可。
源码分析
先从消息的发布也就是put方法
首先调用makeItemPath()获取创建节点路径:
ZKPaths.makePath(queuePath, QUEUE_ITEM_NAME);
这里QUEUE_ITEM_NAME=“queue-”。
然后调用internalPut()方法来创建节点路径
//先累加消息数量putCount
putCount.incrementAndGet();
//使用serializer序列化消息数据
byte[] bytes = ItemSerializer.serialize(multiItem, serializer);
//根据background来创建节点
if ( putInBackground )
{doPutInBackground(item, path, givenMultiItem, bytes);
}
else
{doPutInForeground(item, path, givenMultiItem, bytes);
}
看doPutInForeground里就是具体的创建节点了
//创建节点
client.create().withMode(CreateMode.PERSISTENT_SEQUENTIAL).forPath(path, bytes);
//哦,错了这里putCount不是总消息数,是正在创建消息数,创建完再回减
synchronized(putCount)
{putCount.decrementAndGet();putCount.notifyAll();
}//如果有对应的lisener依次调用
putListenerContainer.forEach(listener -> {if ( item != null ){listener.putCompleted(item);}else{listener.putMultiCompleted(givenMultiItem);}
});
消息的发布就完成了。
然后是消息的consumer,这里肯定是使用的watcher。这里还是回到前面start方法处根据isProducerOnly属性判断有两步操作:
1、childrenCache.start();
childrenCache初始化是在queue的构造函数里
childrenCache = new ChildrenCache(client, queuePath)
其start方法会调用
private final CuratorWatcher watcher = new CuratorWatcher()
{@Overridepublic void process(WatchedEvent event) throws Exception{if ( !isClosed.get() ){sync(true);}}
};private final BackgroundCallback callback = new BackgroundCallback(){@Overridepublic void processResult(CuratorFramework client, CuratorEvent event) throws Exception{if ( event.getResultCode() == KeeperException.Code.OK.intValue() ){setNewChildren(event.getChildren());}}};void start() throws Exception{sync(true);}private synchronized void sync(boolean watched) throws Exception{if ( watched ){//走这里client.getChildren().usingWatcher(watcher).inBackground(callback).forPath(path);}else{client.getChildren().inBackground(callback).forPath(path);}}这里先把代码都贴上,看到内部定义了一个watcher和callback。这里inBackground就是watcher到事件使用callback进行处理,最后是调用到setNewChildren方法
private synchronized void setNewChildren(List<String> newChildren)
{if ( newChildren != null ){Data currentData = children.get();//将数据设置到children变量里,消息版本+1children.set(new Data(newChildren, currentData.version + 1));//notifyAll() 等待线程获取消息notifyFromCallback();}
}
这里有引入了一个children变量,然后将数据设置到了该变量里。
private final AtomicReference<Data> children = new AtomicReference<Data>(new Data(Lists.<String>newArrayList(), 0));
children其实是线程间通信一个共享数据容器变量。这里设置了数据,然后具体的数据消费在下一步。
2、线程池里丢了个任务去执行runLoop();方法。
回到DistributedQueue.start的第二步,执行runLoop()方法,看名字就应该知道了一直轮询获取消息。
还是来看代码吧
private void runLoop()
{long currentVersion = -1;long maxWaitMs = -1;//while一直轮询while ( state.get() == State.STARTED ){try{//从childrenCache里获取数据ChildrenCache.Data data = (maxWaitMs > 0) ? childrenCache.blockingNextGetData(currentVersion, maxWaitMs, TimeUnit.MILLISECONDS) : childrenCache.blockingNextGetData(currentVersion);currentVersion = data.version;List<String> children = Lists.newArrayList(data.children);sortChildren(children); // makes sure items are processed in the correct orderif ( children.size() > 0 ){maxWaitMs = getDelay(children.get(0));if ( maxWaitMs > 0 ){continue;}}else{continue;}/**处理数据 这里取出消息后会删除节点,然后使用serializer反序列化节点数据,调用consumer.consumeMessage来处理消息**/processChildren(children, currentVersion);}}}
}
这里获取数据使用了childrenCache.blockingNextGetData
synchronized Data blockingNextGetData(long startVersion, long maxWait, TimeUnit unit) throws InterruptedException
{long startMs = System.currentTimeMillis();boolean hasMaxWait = (unit != null);long maxWaitMs = hasMaxWait ? unit.toMillis(maxWait) : -1;//数据版本没变一直wait等待while ( startVersion == children.get().version ){if ( hasMaxWait ){long elapsedMs = System.currentTimeMillis() - startMs;long thisWaitMs = maxWaitMs - elapsedMs;if ( thisWaitMs <= 0 ){break;}wait(thisWaitMs);}else{wait();}}return children.get();
}
这里就有wait阻塞等消息,当消息来时候会被唤醒。
其它类型队列:
curator对优先队列(DistributedPriorityQueue)、延迟队列(DistributedDelayQueue)都有对应的实现,有兴趣的自己看吧。
相关文章:

zookeeper应用之分布式队列
队列这种数据结构都不陌生,特点就是先进先出。有很多常用的消息中间件可以有现成的该部分功能,这里使用zookeeper基于发布订阅模式来实现分布式队列。对应的会有一个生产者和一个消费者。 这里理论上还是使用顺序节点。生产者不断产生新的顺序子节点&am…...
取数游戏2(动态规划java)
取数游戏2 题目描述 给定两个长度为n的整数列A和B,每次你可以从A数列的左端或右端取走一个数。假设第i次取走的数为ax,则第i次取走的数的价值vibi⋅ax,现在希望你求出∑vi的最大值。 输入格式 第一行一个数T ,表示有T 组数据。…...

Spring Boot中配置文件生效位置
1. 配置文件位置 首先小伙伴们要明白,Spring Boot 默认加载的配置文件是 application.properties 或者 application.yaml,properties优先级高于yaml。默认的加载位置一共有五个,五个位置可以分为两类: 从 classpath 下加载&…...
AIGC创作系统ChatGPT网站系统源码,支持最新GPT-4-Turbo模型
一、AI创作系统 SparkAi创作系统是基于OpenAI很火的ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如…...
【JavaEE】操作系统与进程
作者主页:paper jie_博客 本文作者:大家好,我是paper jie,感谢你阅读本文,欢迎一建三连哦。 本文录入于《JavaEE》专栏,本专栏是针对于大学生,编程小白精心打造的。笔者用重金(时间和精力)打造&…...
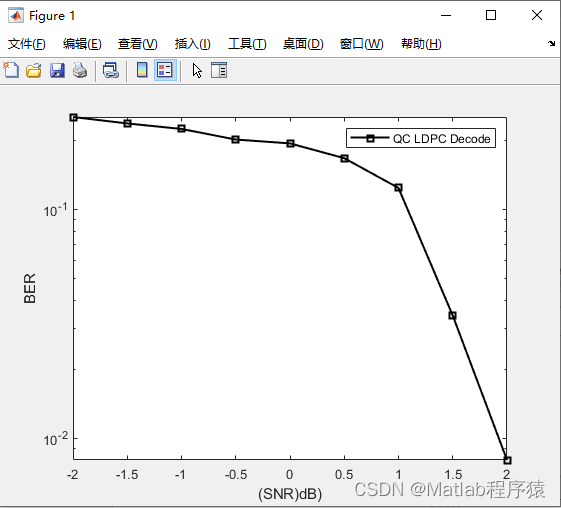
【MATLAB源码-第86期】基于matlab的QC-LDPC码性能仿真,输出误码率曲线。
操作环境: MATLAB 2022a 1、算法描述 QC-LDPC(准循环低密度奇偶校验)编码是一种高效的错误校正编码方式,广泛应用于通信系统和数据存储中以提高数据的可靠性。它是低密度奇偶校验(LDPC)编码的一种特殊形…...
)
【0236】聊一聊PG内核中的命令标签(Command Tags、CommandTag、tag_behavior)
1. 什么是命令标签(Command Tags) 当客户端向PG服务下发一个请求时,postgres进程在读取到用户的请求缓冲区之后,需要对从中解析出用户的具体请求,比如:CREATE TABLE、CREATE DATABASE、DROP TABLE、SELECT等具体操作,这里除了会用到后面即将讲的词法分析解析器flex之外…...
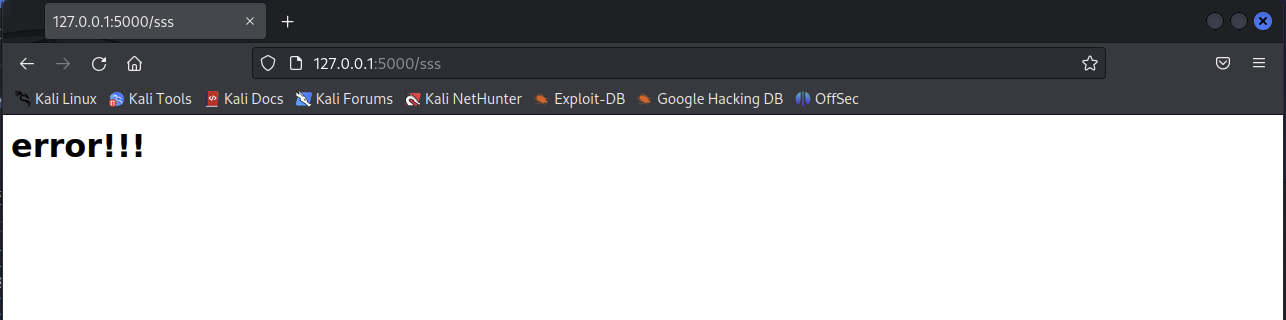
Python武器库开发-flask篇之error404(二十七)
flask篇之error404(二十七) 首先,我们先进入模板的界面创建一个404的html页面 cd templates vim 404.html404.html的内容如下: <h1>error!!!</h1>在 Flask 应用程序中,当用户访问一个不存在的页面的时候,会出现 4…...
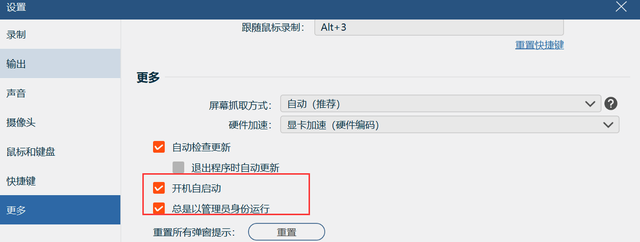
录屏软件自动开启录视频,是如何实现的?
工作要留痕,作为职场人的一项必备技能,因此许多人在做一些重要操作的时候,就会提前开启录屏软件,把操作的每一个步骤进行录制,以避免在出现问题的时候进行检查。当每天都需要在固定的时间点重复某项工作的时候…...

模拟shell小程序
接下来利用我们当前的知识,撰写一个简单的shell外壳程序。 1.shell原理 shell的原理是实际上就是运行了一个父进程,然后创建出子进程,最后使用进程替换调用,替换成其他程序。 2.shell实现 2.1.死循环 首先一个shell一旦运行起…...

webpack配置全局scss
webpack配置全局scss 效果:a.vue使用index.scss中定义的$mainWidth就无需 import "xxxxxxx/index.scss"文件 src/assets/styles/index.scss $mainWidth: 1280px; $red: red src/views/a.vue .aaa {color: $red; } vue.config.js module.exports {…...

想面试前端工程师,必须掌握哪些知识和技能?【云驻共创】
在当今的数字化时代,前端工程师扮演着至关重要的角色。他们负责设计和开发用户界面,使得用户能够与应用程序或网站进行互动。为了找到最出色的前端工程师,你需要了解哪些技能和知识是必备的,同时也要掌握一些面试技巧和常见的面试…...

京东数据分析(京东数据采集):2023年10月京东平板电视行业品牌销售排行榜
鲸参谋监测的京东平台10月份平板电视市场销售数据已出炉! 根据鲸参谋电商数据分析平台的相关数据显示,10月份,京东平台上平板电视的销量将近77万,环比增长约23%,同比则下降约30%;销售额为21亿,环…...
 或者 运算符来执行多条命令)
在 Linux 中,可以使用分号 (;) 或者 运算符来执行多条命令
在 Linux 中,你可以使用分号 (;) 或者 && 运算符来执行多条命令。 使用分号 (;) 分隔多条命令: command1 ; command2 这样会依次执行 command1 和 command2,不管前面的命令是否成功。 使用 && 运算符分隔多条命令࿱…...

一些必备的 Redis 命令 | Navicat
Redis 是一种快速的内存数据结构存储系统,因其处理键值对的能力而备受推崇。在本文,我们将探索一些不可或缺的 Redis 命令(不包括之前介绍过的涉及键的命令),解锁这个强大工具的真正潜力。同时,我们也将了解…...

神经网络常用激活函数详解
🎀个人主页: https://zhangxiaoshu.blog.csdn.net 📢欢迎大家:关注🔍点赞👍评论📝收藏⭐️,如有错误敬请指正! 💕未来很长,值得我们全力奔赴更美好的生活&…...
UVA11584划分成回文串 Partitioning by Palindromes
划分成回文串 Partitioning by Palindromes 题面翻译 回文子串(palind) 问题描述: 当一个字符串正序和反序是完全相同时,我们称之为“回文串”。例如“racecar”就是一个回文串,而“fastcar”就不是。现在给一个字符串s,把它分…...

第十一章 将对象映射到 XML - 控制流属性的映射形式
文章目录 第十一章 将对象映射到 XML - 控制流属性的映射形式控制流属性的映射形式控制预计属性的可用性禁用映射%XML.Adapter 中的方法 第十一章 将对象映射到 XML - 控制流属性的映射形式 控制流属性的映射形式 对于流属性,XMLPROJECTION 的选项如下:…...

torchvision中的标准ResNet50网络结构
注:仅用以记录学习 打印出来的网络结构如下: from torchvision import models model models.resnet50(pretrainedFalse) print("model: ", model) 结构: ResNet((conv1): Conv2d(3, 64, kernel_size(7, 7), stride(2, 2), padd…...
)
Java 多线程之 synchronized (互拆锁/排他锁/非观锁)
文章目录 一、概述二、使用方法三、测试示例 一、概述 在Java中,synchronized 关键字用于实现线程之间的同步。提供了一种简单而强大的机制来控制多个线程之间的并发访问,确保共享资源的安全性和一致性。它解决了多线程环境中的竞态条件、数据竞争和内存…...

08-MLOps与工程落地——工作流编排:Kubeflow
工作流编排:Kubeflow(Kubernetes原生ML流水线、组件化、分布式训练) 一、Kubeflow概述 1.1 什么是Kubeflow? import matplotlib.pyplot as plt from matplotlib.patches import Rectangle, FancyBboxPatch import warnings warnin…...

你的AMD Ryzen电脑性能被锁住了?这个免费工具帮你解锁隐藏潜能
你的AMD Ryzen电脑性能被锁住了?这个免费工具帮你解锁隐藏潜能 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: ht…...

从“水仙花数”到“背包问题”:新手程序员如何用C语言打通算法任督二脉?
从“水仙花数”到“背包问题”:新手程序员如何用C语言打通算法任督二脉? 第一次接触算法时,我盯着屏幕上那行"Hello World"发呆——明明已经能写出让计算机打招呼的代码,为什么看到"时间复杂度O(n)"这种描述时…...

从零到自动化:用Python+PyNX快速上手UG二次开发,告别C语言恐惧
从零到自动化:用PythonPyNX快速上手UG二次开发,告别C语言恐惧 UG NX作为工业设计领域的标杆软件,其二次开发能力一直是工程师提升效率的利器。但传统基于C/C的开发方式让许多设计师望而却步——复杂的语法、繁琐的内存管理、漫长的编译过程&a…...

S32K3安全启动实战:从HSE固件安装到SMR配置的完整避坑指南
S32K3安全启动实战:从HSE固件安装到SMR配置的完整避坑指南 在嵌入式系统开发中,安全启动功能已成为保护设备固件完整性和防止未授权代码执行的关键防线。NXP S32K3系列微控制器通过硬件安全引擎(HSE)提供了强大的安全启动能力,但实际配置过程…...

MCP 2026低代码平台集成:为什么87%的POC失败源于这6个元数据映射盲区?
更多请点击: https://intelliparadigm.com 第一章:MCP 2026低代码平台集成的元数据治理共识 在 MCP 2026 低代码平台中,元数据治理不再仅是后台管理任务,而是贯穿模型设计、组件复用、跨环境部署与合规审计的核心契约机制。平台通…...

基于事件驱动的消息镜像插件:解耦业务与通知的配置化实践
1. 项目概述:一个解决消息同步痛点的开源利器如果你正在开发一个需要跨多个平台或群组同步消息的应用,比如一个集成了多个即时通讯工具(如微信、钉钉、飞书)的客服机器人,或者一个需要在不同社区频道间广播通知的运营工…...

AI代理工作流框架Primer:结构化引导AI编码,从模糊想法到可运行软件
1. Primer项目概述:用AI代理构建真实软件的“脚手架”如果你和我一样,尝试过让AI编码助手(比如Claude Code、Cursor、Codex)去构建一个完整的项目,大概率会遇到一个共同的困境:任务描述太模糊,A…...

Hi-Fi音频动态范围解析与DAC芯片实测指南
1. Hi-Fi音频动态范围的本质与测量盲区动态范围(Dynamic Range)作为音频系统最核心的指标之一,本质上描述的是系统能够重现的最弱信号与最强信号之间的比值。在技术文档中通常以分贝(dB)为单位表示,计算公式…...
问题分析)
Dubbo通信异常(channel is closed)问题分析
一、问题概述 ### 1.1 报错信息 系统运行过程中,消费者服务(support-t1-web)调用Dubbo服务时出现通信异常,具体报错如下: org.apache.dubbo.remoting.RemotingException: message can not send, because channel is…...