JAVA SQL
--
/* */
-- 简单查询:
-- 查询所有字段: select * from 表名
-- *:通配符,代表所有
select * from employees
-- 查询部分字段: select 列名1,列名2,.. from 表名
-- 查询员工ID,员工姓名,员工的工资
select employee_id,salary,first_name from employees
-- 查询表的所有字段
SELECT employee_id,salary,first_name,last_name,email,phone_number,job_id,commission_pct,manager_id,department_id,hiredate from employees
-- +、-、*、/、%
-- 查询员工ID+员工原本工资+员工工资计算之后的结果
select employee_id,salary,salary+100,salary-100,salary*100,salary/100,salary%100 from employees
SELECT employee_id,first_name,first_name-100 from employees
-- 别名: 列名 as "别名" | 列名 '别名' | 列名 别名
-- 查询员工ID,员工姓名,员工工资并起别名
-- 只有别名的单引号或双引号可省
select employee_id as 员工ID,first_name 员工姓名,salary 工资 from employees
-- distinct: 去重 distinct 列名
-- 查询员工所属的岗位ID都有哪些
select distinct job_id from employeesm
-- 查询岗位ID和部门ID并去重
select distinct job_id,department_id from employees
-- case-when 分支判断
-- 一个分支结构至多执行出一个结果
-- 对应一个字段的值
-- 查询员工ID,员工工资,员工工资的标准: 12000以上:高薪 8000-19999:中薪 5000-7999:一般 低于5000:低薪
select employee_id,salary,
CASE
when salary>=12000 then '高薪'
when salary>=8000 then '中薪'
when salary>=5000 then '一般'
else '低薪'
END as 工资标准
from employees
-- describe 表名:查看表详情
DESCRIBE employees
desc employees
-- 条件查询:where子句
-- select 列名1,列名2,.. from 表名 [where 条件]
-- 筛选运算符:> < = >= <= !=
-- from-->where-->select
-- 查询工资大于10000的员工信息
select * -- 3. 再查询符合条件的数据的列值
from employees -- 1. 先确定操作哪张表
where salary>10000 -- 2. 先对数据进行筛选
-- 查询部门ID小于50的员工ID+员工姓名+部门ID+工资
select employee_id,first_name,department_id,salary
from employees
WHERE department_id<50
-- 查询起始名为Steven的员工信息
select *
from employees
where binary first_name='Steven'
-- 多条件: where 条件1 连接符 条件2
-- 并且: and 或者: or
-- 查询员工ID<120并且工资高于8000的员工信息
select *
from employees
where employee_id<120 and salary>8000
-- 查询员工ID<120或者工资高于8000的员工信息
select *
from employees
where employee_id<120 or salary>8000
-- where 列名 [not] between 起始值 and 结束值
-- 查询工资在10000-15000之间的员工信息
select *
from employees
where salary between 10000 and 15000
-- 相当于:
select *
from employees
where salary>=10000 and salary<=15000
-- 查询工资不在10000-15000之间的员工信息
select *
from employees
where salary not between 10000 and 15000
-- where 列名 [not] in(值1,值2,...)
-- 查询部门ID为10,20,30的员工信息
select *
from employees
where department_id in(10,20,30)
-- 相当于:
select *
from employees
where department_id=10 or department_id=20 or department_id=30
-- 查询部门Id不为10,20,30的员工信息
select *
from employees
where department_id not in(10,20,30)
-- 相当于:
select *
from employees
where department_id!=10 and department_id!=20 and department_id!=30
-- where 列名 is [not] null
-- 查询没有提成的员工信息
select *
from employees
where commission_pct is null
-- 查询有提成的员工信息
select *
from employees
where commission_pct is not null
-- where 列名 [not] like '通配模式'
-- %: 匹配长度0-n的内容
-- _: 匹配长度为1的内容
-- 查询起始名以s开头的员工信息
select *
from employees
where first_name like 's%'
-- 查询起始名第2位为s的员工信息
select *
from employees
where first_name like '_s%'
-- 查询起始名以s结尾的员工信息
select *
from employees
where first_name like '%s'
-- 查询起始名长度为5的员工信息
select *
from employees
where first_name like '_____'
-- 查询起始名长度不为5的员工信息
select *
from employees
where first_name not like '_____'
-- 单行函数: 函数名(一行数据)
-- 1. concat(内容1,内容2,内容3,..):将括号内的内容进行拼接返回
-- 将员工姓名拼接查询
select concat(first_name,'-',last_name) 员工姓名
from employees
-- 2. length(列名): 获取内容的长度
-- 查询员工起始名+起始名的长度
select first_name,length(first_name) from employees
-- 查询起始名长度等于5的员工信息
select *
from employees
where LENGTH(first_name)=5
-- 查询完整姓名长度>10的员工信息
select *
from employees
where LENGTH(CONCAT(first_name,last_name))>10
-- 3. sysdate()|now():获取当前系统时间
select sysdate() from employees
select now() from employees
-- dual:虚拟表,只会得到一个结果
select now() from dual
select now()
-- 4. mod(值1,值2):获取值1%值2的结果
-- 计算10%3的结果
select mod(10,3)
-- 计算员工工资%100的结果
select mod(salary,100) from employees
-- 5. date_format(日期,'转换的字符串格式')
-- 将员工的入职日期转换为对应格式的字符串
select hiredate,DATE_FORMAT(hiredate,'%Y-%m-%d %H:%i:%s') from employees
-- 提取员工的入职年份
select hiredate,date_format(hiredate,'%Y') from employees
-- 提取当前系统时间中的年份
select date_format(NOW(),'%Y')
select date_format('2023-11-20 16:51:03','%Y')
-- 查询在2000年以后入职的员工信息
select *
from employees
where DATE_FORMAT(hiredate,'%Y')='2000'
-- 6.str_to_date('日期格式的字符串','转换的日期格式'):将日期格式的字符串转换为日期类型
-- 把'2023-11-20 16:51:03'转换为对应的日期类型
select STR_TO_DATE('2023-11-20 16:51:03','%Y-%m-%d %H:%i:%s')
select STR_TO_DATE('2023-11-20 16:51:03','%Y-%m-%d')
select STR_TO_DATE('2023-11-20 16:51:03','%Y-%m-%d')
-- 8.查询入职日期在 1997-5-1 到 1997-12-31 之间的所有员工信息
select *
from employees
where hiredate between '1992-1-1' and '1997-12-31'
-- 15.打印员工级别
select hiredate,
CASE
when date_format(hiredate,'%Y')<=1995 then '资深员工'
when date_format(hiredate,'%Y')<=2000 then '普通员工'
else '新员工'
END as 员工级别
from employees
-- 排序:order by 对查询结果做排序显示
-- asc :从小到大 默认的
-- desc:从大到小
-- 根据员工工资进行从高到低的查看
select employee_id,first_name,salary
from employees
order by salary desc
-- 查询部门id为20的员工信息并根据工资升序排序
select employee_id,first_name,salary,department_id -- 3. 确定查看字段
from employees -- 1. 确定基于哪张表操作
where department_id=20 -- 2. 对数据进行筛选
order by salary -- 4. 对查看字段按照规则排序显示
-- order by 列名1 asc|desc,列名2 asc|desc
-- 当列1值相同时才会根据列2进行排序
-- 查询员工id,姓名、工资,根据工资升序排序,如果工资相同,则根据id降序排序
SELECT employee_id,first_name,salary
from employees
ORDER BY salary,employee_id desc
-- 单行函数:以行为单位进行操作,一行得到一个结果
-- 组函数:以组为单位进行操作,一组得到一个结果
/* 1. max(列名):获取最大值
2. min(列名):获取最小值
3. sum(列名):获取总和
4. avg(列名):获取平均值
5. count(列名):统计值的个数
注意: 所有组函数都不会操作null值
*/
-- group by: 手动分组 group by 列名
-- 规则:分组列值相同的行为同一组数据
-- 查询共有哪些部门id及每个部门多少人
SELECT department_id,count(employee_id)-- 3. 基于分组结果进行查询
FROM employees -- 1. 确定基于员工表操作
group by department_id -- 2. 根据部门id进行分组
-- 查询都有那些岗位及每个岗位有多少人,每个岗位的最高薪资
select job_id,count(*),MAX(salary)
from employees
group by job_id
-- 查询部门id为10,20,30的部门的最高薪资和最低薪资
SELECT department_id,max(salary),MIN(salary) -- 4. 对分组完数据进行查询
from employees -- 1. 确定数据来源
where department_id in(10,20,30) -- 2. 对数据进行筛选
group by department_id -- 3. 对筛选的数据进行分组
-- 查询job_id长度<=5的岗位的各个人数
SELECT job_id,count(employee_id)
FROM employees
WHERE LENGTH(job_id)<=5
GROUP BY job_id
-- having子句: 做条件筛选,在分组之后执行
-- 查询平均工资高于6000的部门id
SELECT department_id,AVG(salary) -- 4 对分组筛选结果进行查询
FROM employees -- 1. 确定数据来源
group by department_id -- 2. 根据部门id进行分组
having AVG(salary)>6000 -- 3. 对分组数据进行筛选
-- where和having的区别:
-- where:先筛选后分组,效率高
-- having:先分组再筛选,效率低
-- 筛选条件需要用到组函数,只能使用having,否则where优先
-- 查询部门id<50并且部门平均薪资大于6000的部门id,平均薪资并按照部门id降序显示
-- select from where having group by order by
SELECT department_id,AVG(salary) -- 5. 对最终数据进行查询
FROM employees -- 1.确定数据来源
WHERE department_id<50 -- 2. 对数据做分组前的筛选
group by department_id -- 3. 对筛选完的数据进行分组
having AVG(salary)>6000 -- 4. 对分组完的数据再次筛选
order by department_id desc-- 6. 对查询结果进行排序
-- 1. 确定数据来源
-- 2. 操作数据,确定最终数据
-- 3. 确定查询字段
-- 4. 确定查看方式
-- limit 查看的起始下标,查看条数:限制查看的条目数
-- 可以与任意查询关键字结合,必须写在最后,因为其一定最后执行
-- 查看工资最高的前十名员工信息
SELECT *
FROM employees
order by salary DESC
-- limit 0,10
limit 10
-- 查看平均工资最高的前三个部门id
-- ORDER BY、GROUP BY、LIMIT
SELECT department_id,AVG(salary)
FROM employees
GROUP BY department_id
ORDER BY AVG(salary) DESC
LIMIT 3
-- select 列名... from 表名 where 列名 =|in (子SQL语句)
-- 执行:由内而外,先执行子SQL,再执行外层sql
-- 单值子查询:子SQL得到的结果是单行单列的
-- 查询员工id为110号员工所在的部门信息
select *
from departments
-- 部门id= 110号员工所在的部门id
where department_id = (select department_id from employees where employee_id=110)
-- 查询id为110号员工的直接领导的员工信息
select *
from employees
-- 员工id= 110号员工的领导id
-- where employee_id=(select manager_id from employees where employee_id=110)
-- 员工id=108 员工id in(108)
where employee_id in (select manager_id from employees where employee_id=110)
-- where多值子查询:子SQL返回的是单列多行的结果
-- 查询工资>10000的员工所在的部门信息
select *
from departments
-- 部门id in 工资>10000的员工所属的部门id
where department_id in (select department_id from employees where salary>10000)
-- from子查询: 将子SQL的查询结果临时看做一张表,起个别名进行外层SQL的查询操作
-- 查询工资最高的前3名员工的平均薪资
select avg(salary) from (SELECT *
from employees
order by salary DESC
LIMIT 3) as e
-- select AVG(salary) from e
-- 表连接: 将多个表通过连接条件进行结合,将多表数据结合为一个整体,进行后续的查询和处理操作
-- 连接条件:必须是有关联关系的字段
-- 分类: 内连接|左外连接|右外连接|全外连接|自连接
-- 语法: from 表名1 [连接形式]join 表名2 on 连接条件
-- 内连接:对连接双方的表同时做约束,双方的数据都必须满足连接条件才能展示到最终的临时表中
-- 查询所有员工信息及其所属部门信息
select e.*,d.*
from employees e join departments d on e.department_id=d.department_id
-- 查询100号员工所对应的员工ID,姓名,工资,部门ID,部门名称
SELECT employee_id,first_name,salary,e.department_id,department_name
from employees e join departments d ON e.department_id=d.department_id
where employee_id=100
-- 11. 查询平均薪资最高的前三个部门所有的员工信息及部门名称
SELECT e.*,d.department_name
FROM employees e JOIN departments d ON e.department_id = d.department_id
WHERE d.department_id in (
(SELECT d.department_id
FROM employees e JOIN departments d ON e.department_id = d.department_id
GROUP BY d.department_id
ORDER BY AVG(salary) DESC
LIMIT 0,1),(SELECT d.department_id
FROM employees e JOIN departments d ON e.department_id = d.department_id
GROUP BY d.department_id
ORDER BY AVG(salary) DESC
LIMIT 1,1),(SELECT d.department_id
FROM employees e JOIN departments d ON e.department_id = d.department_id
GROUP BY d.department_id
ORDER BY AVG(salary) DESC
LIMIT 2,1)
)
SELECT e.*,d.department_name
FROM employees e JOIN departments d ON e.department_id = d.department_id
group by e.department_id
order by AVG(salary) DESC
LIMIT 3
-- 12. 显示各个部门经理的基本工资 注:部门表的 manager_id 代表该部门的领导编号
SELECT employee_id,salary
FROM employees e JOIN departments d ON e.employee_id = d.manager_id
SELECT employee_id,salary
FROM employees e JOIN departments d ON e.department_id=d.department_id
where e.employee_id=d.manager_id
select salary
from employees
where employee_id in(select manager_id from departments)
-- 13. 查询各个部门的信息及所在的地址
SELECT d.department_name,l.*
FROM locations l JOIN departments d ON l.location_id = d.location_id
-- 14. 查询拥有部门最多的地址信息和部门名称
SELECT l.*,d.department_name
FROM locations l JOIN departments d ON l.location_id = d.location_id
WHERE l.location_id = (
-- 部门最多的地址ID
select location_id
from departments
group by location_id
order by count(*) DESC
limit 1
)
-- 15. 查询工资最高的员工ID,姓名,工资,岗位ID,岗位全称
SELECT employee_id,first_name,salary,e.job_id,job_title
FROM employees e JOIN jobs j ON e.job_id = j.job_id
ORDER BY salary DESC
LIMIT 1
-- 16. 查询拥有员工最多的岗位信息
SELECT *
FROM jobs
WHERE job_id = (
SELECT job_id
FROM employees
group by job_id
ORDER BY COUNT(*) DESC
LIMIT 1
)
-- 左外连接: left [outer] join
-- 特点: 左表不受约束,右表受约束
-- 查询所有的员工信息和对应的部门信息
SELECT e.*,d.*
from employees e left join departments d on e.department_id=d.department_id
-- 查询100号员工的员工信息何其对应的部门信息
SELECT e.*,d.*
from employees e left join departments d on e.department_id=d.department_id
where employee_id=100
-- 查询部门ID为10,20,30的部门信息及其地址信息
select d.*,l.*
from departments d left join locations l on d.location_id=l.location_id
where department_id in(10,20,30)
-- 右外连接: right [outer] join
-- 右表不受约束,左表受约束
-- 查询所有的部门信息和对应的员工信息
select e.*,d.*
from employees e right join departments d ON e.department_id=d.department_id
-- 查询100号员工的员工信息何其对应的部门信息
SELECT e.*,d.*
from employees e right join departments d on e.department_id=d.department_id
where employee_id=100
-- 查询部门ID为10,20,30的部门信息及其地址信息
select d.*,l.*
from departments d right join locations l on d.location_id=l.location_id
where department_id in(10,20,30)
-- 右外: 查询所有的员工信息和对应的部门信息
SELECT e.*,d.*
from departments d right join employees e on e.department_id=d.department_id
-- 左外: 查询所有的部门信息和对应的员工信息
select e.*,d.*
from departments d left join employees e ON e.department_id=d.department_id
-- 全外连接: 查询结果1 union|union all 查询结果2
-- union : 可以去重
-- union all: 不去重
-- 两个查询结果的字段个数,字段内容必须保持一致
-- 查询员工ID,员工姓名,工资
select employee_id,first_name,salary from employees
union
-- union all
select employee_id,salary,department_id from employees
-- 查询所有的员工信息和其部门信息
select e.*,d.*
from employees e left join departments d on e.department_id=d.department_id
union all
select e.*,d.*
from employees e left join departments d on e.department_id=d.department_id
-- 自连接: 参与连接的双方是同一张表
-- 1. 将同张表之间的不同字段作为连接条件
-- 2. 将同张表的同一字段作为连接条件
-- select查询字段必须标明表名:表名.列名
-- 1. 查询员工ID,姓名,工资,领导的员工ID,领导的姓名
SELECT e1.employee_id 员工ID,e1.first_name 员工姓名,e1.salary 员工工资,e1.manager_id 员工的领导ID,e2.first_name 领导姓名
-- e1:获取员工信息 e2:获取领导信息 连接条件:员工的领导ID=领导的员工ID
from employees e1 left join employees e2 on e1.manager_id=e2.employee_id
-- 查询工资相同的两两员工信息
SELECT e1.employee_id,e1.first_name,e1.salary,e2.employee_id,e2.first_name,e2.salary
from employees e1 left join employees e2 on e1.salary=e2.salary
-- 去重:
where e1.employee_id<e2.employee_id
-- 单表的普通查询
-- 子查询
-- 表连接
-- 表连接-自连接
1. 查询字段来自于一张表且无不确定数据且属于同一行
2. 查询字段来自于一张表且有不确定数据且属于同一行
3. 查询字段来自于不同的表
4. 查询字段来自于一张表但不属于同一行
-- 多表连接:
from 表1 [left|right] join 表2 on 连接条件
[left|right] join 表3 on 连接条件
...
-- 查询员工ID,姓名,工资,所属部门ID,部门名称,所在地址ID,地址街道
-- 员工表,部门表,地址表
SELECT employee_id,first_name,salary,d.department_id,department_name,l.location_id,street_address
from employees e left join departments d on e.department_id=d.department_id
-- 连接地址表
left join locations l on d.location_id=l.location_id
SELECT employee_id,first_name,salary,d.department_id,department_name,l.location_id,street_address
from departments d left join employees e on e.department_id=d.department_id
-- 连接地址表
left join locations l on d.location_id=l.location_id
-- 建库: create database [if not exists] 数据库名 [default charset 字符集]
-- if not exists: 不存在再执行创建,如果存在,则不做操作
-- default charset 字符集: 设置数据库的默认编码集
create database test
create database if not exists test default charset utf8mb4
-- 删库: drop database [if exists] 数据库
-- if exists:如果存在再执行删除,不存在则不做操作
drop database test
drop database if exists test
-- 建表:
create table [if not exists] 表名(
字段名 数据类型 [约束],
字段名 数据类型 [约束],
...[最后一行内容末尾不能添加,]
)
-- 约束:
-- 1. 主键:使当前字段成为唯一标识列,非空+唯一的,一张表至多存在一个
-- 2. 非空:字段的值不能为空
-- 3. 唯一:字段的值不能重复,不约束null值
-- 非空+唯一 != 主键
-- 4. 默认:给字段设置默认值,当字段为设置值时,默认使用默认值
-- 5. 外键:字段值不可自定义,必须来自于另一张表的某个字段
-- 必须结合另一张表使用
-- foreign key(需要添加外键约束的字段名) references 其他表的表名(其他表中的连接字段)
-- 不约束null值
-- person表:id、姓名、年龄、性别、生日、身高
create table t_person(
person_id int primary key, -- 主键
person_name varchar(20) not null unique,-- 非空
age TINYINT UNSIGNED,-- 无符号数,没有负数
sex enum('男','女','奥特曼') default'奥特曼',
birthday datetime,
height decimal(4,1)
)
create table t_person(
person_id int ,
person_name varchar(20) not null,-- 非空
age TINYINT UNSIGNED,-- 无符号数,没有负数
sex enum('男','女','奥特曼') default'奥特曼',
birthday datetime,
height decimal(4,1),
-- 表级约束
primary key(person_id),-- 给person_id添加主键约束
unique(height) -- 给身高字段添加唯一约束
)
desc t_person
desc employees
-- 删表:drop table [if exists] 表名
drop table t_person
-- 学生表:学生id,学生姓名,学生年龄,学生成绩,班级id(外键约束-关联班级表的班级id)
-- 班级表:班级id,班级名称,班级人数
-- 建表:先建没有外键约束的表-->有外键约束的表
-- 删表:与建表顺序相反
-- 先建班级
create table t_class(
class_id int,
class_name varchar(10) not null,
number int,
PRIMARY KEY(class_id)
)
-- 再建学生
create table t_student(
student_id int,
student_name varchar(20) not null,
age TINYINT,
score DECIMAL(3,1),
class_id int,
-- 约束
primary key(student_id),
-- 外键约束
FOREIGN key(class_id) REFERENCES t_class(class_id)
)
desc t_student
desc t_class
-- 删表
drop table t_class
drop table t_student
相关文章:

JAVA SQL
-- /* */ -- 简单查询: -- 查询所有字段: select * from 表名 -- *:通配符,代表所有 select * from employees -- 查询部分字段: select 列名1,列名2,.. from 表名 -- 查询员工ID,员工姓名,员工的工资 select employee_id,salary,first_name from employees -- 查…...

[Linux] 进程入门
💻文章目录 📄前言计算机的结构体系与概念冯诺依曼体系结构操作系统概念目的与定位 进程概念描述进程-PCBtask_struct检查进程利用fork创建子进程 进程状态进程状态查看僵尸进程孤儿进程 📓总结 📄前言 作为一名程序员,…...
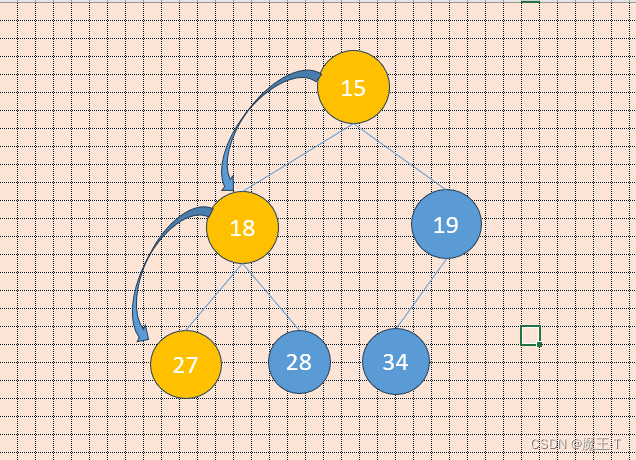
深入解析数据结构与算法之堆
文章目录 🥦引言:🥦什么是堆🥦大顶堆与小顶堆🧄大顶堆(Max Heap)🧄小顶堆(Min Heap) 🥦堆的表示🧄数组表示:🧄…...
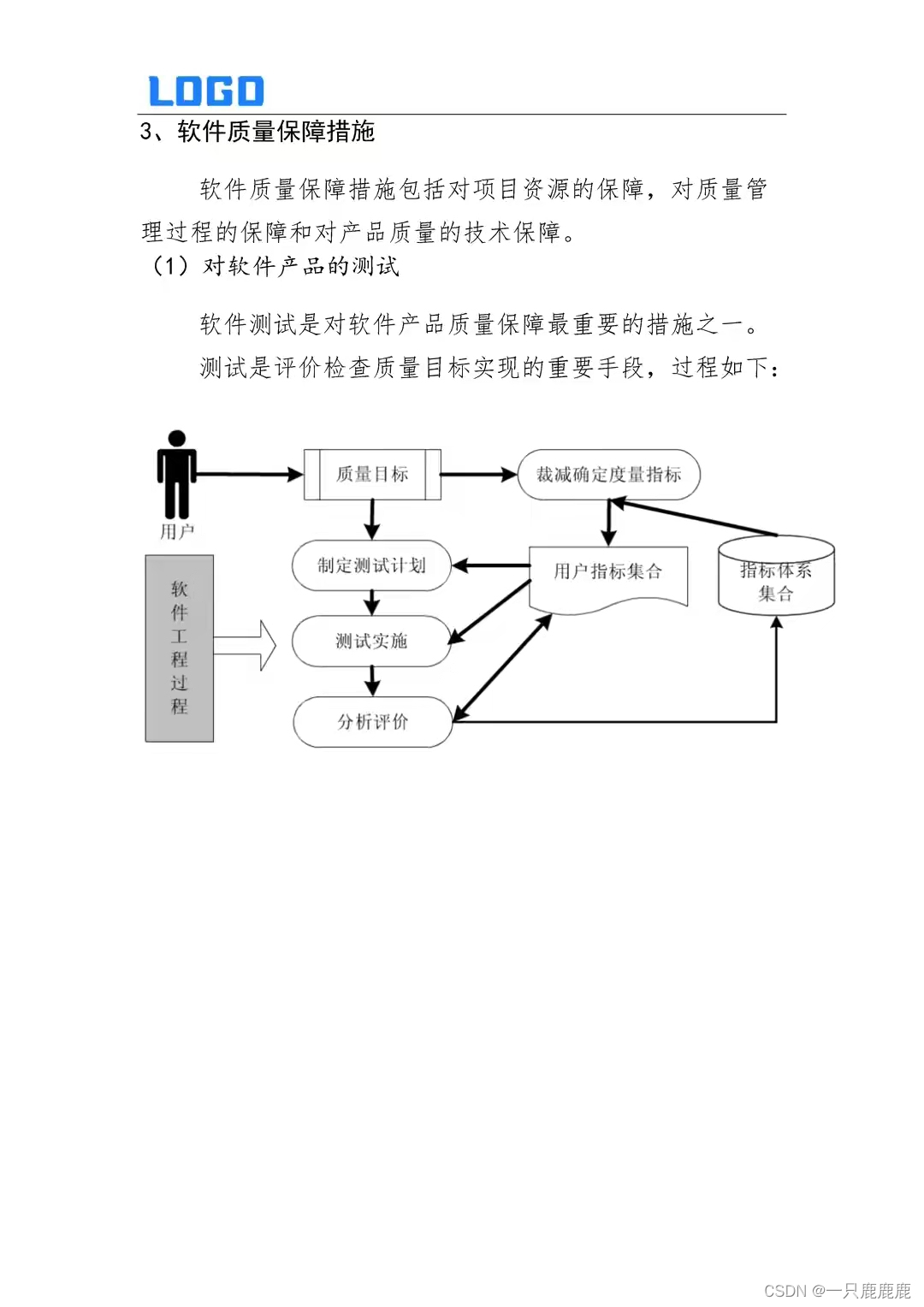
信息化项目质量保证措施
...
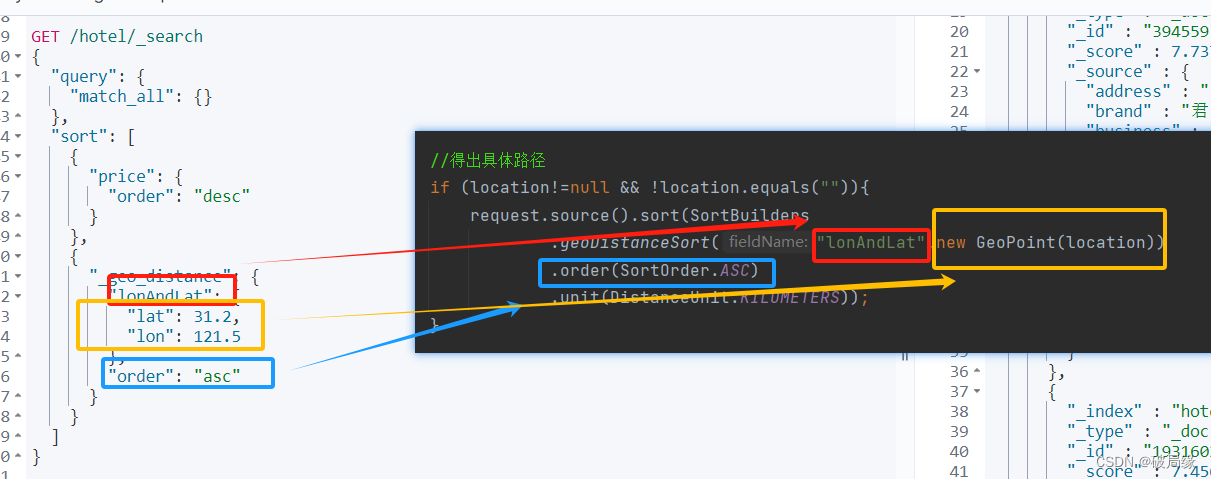
es的优势
系列文章目录 提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加 例如:第一章 Python 机器学习入门之pandas的使用 提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目…...
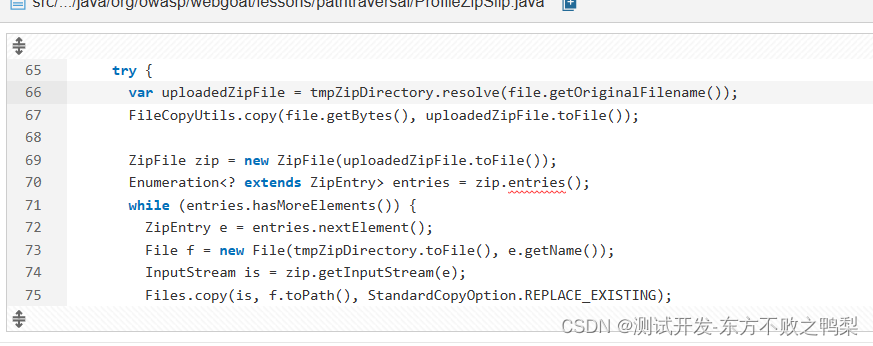
sonar对webgoat进行静态扫描
安装sonar并配置 docker安装sonarqube,sonarQube静态代码扫描 - Joson6350 - 博客园 (cnblogs.com) 对webgoat进行sonar扫描 扫描结果 bugs Change this condition so that it does not always evaluate to "false" 意思是这里的else if语句不会执行…...

opencv-重点知识
OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉库,提供了大量用于图像处理和计算机视觉任务的工具和算法。以下是一些OpenCV中的重点知识: 图像加载与显示: 使用cv2.imread()加载图像。使用cv2.imshow()显示…...

上海亚商投顾:北证50指数大涨 机器人概念股掀涨停潮
上海亚商投顾前言:无惧大盘涨跌,解密龙虎榜资金,跟踪一线游资和机构资金动向,识别短期热点和强势个股。 一.市场情绪 三大指数昨日震荡反弹,黄白二线有所分化,题材热点轮动表现。北证50指数大涨超3%&#…...
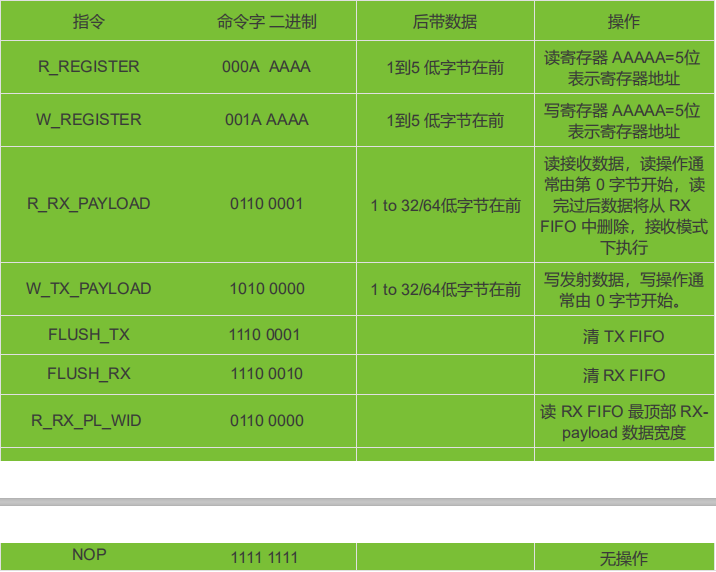
2.4G无线收发芯片 XL2400P使用手册
XL2400P 系列芯片是工作在 2.400~2.483GHz 世界通用 ISM 频段的单片无线收发芯片。该芯片集成射 频收发机、频率收生器、晶体振荡器、调制解调器等功能模块,并且支持一对多组网和带 ACK 的通信模 式。发射输出功率、工作频道以及通信数据率均可配置。芯片已将多颗外…...

ZC序列理论学习及仿真
文章目录 前言一、ZC 序列理论1、基本概念2、表达式3、ZC 序列一些定义①、自相关②、循环移位③、循环自相关④、循环互相关二、ZC 序列性质1、性质 1:恒包络,即等模2、性质 2:零循环自相关3、性质 3:固定循环互相关4、其他性质①、傅里叶变换后仍是 ZC 序列②、低峰均比③…...
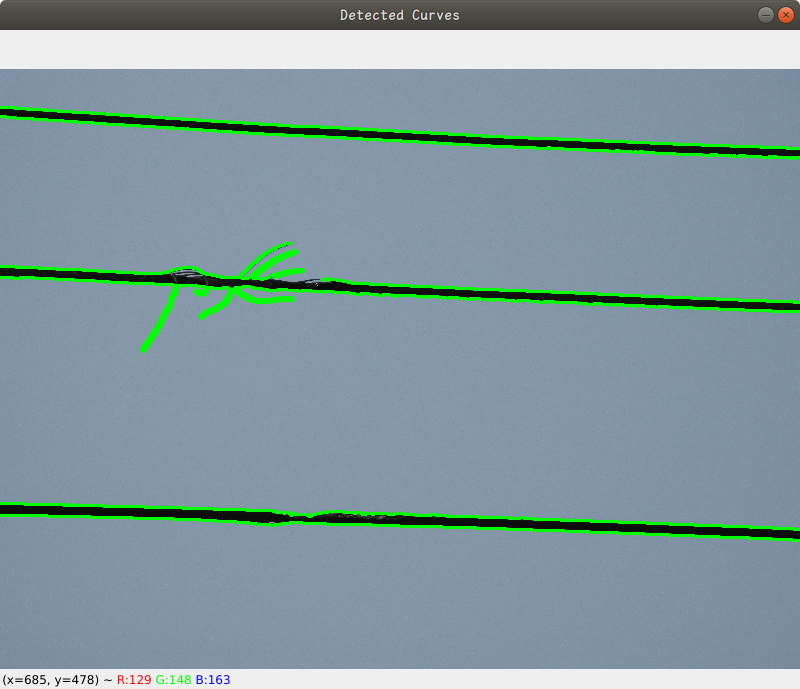
利用OpenCV实现图片中导线的识别
下面是一个需求,识别图片中的导线,要在图像中检测导线,我们需要采用不同于直线检测的方法。由于OpenCV没有直接的曲线检测函数,如同它对直线提供的HoughLines或HoughLinesP,检测曲线通常需要更多的图像处理步骤和算法&…...
)
关于VITS和微软语音合成的效果展示(仙王的日常生活第1-2209章)
目录 说明微软VITS 合成效果展示 说明 自己尝试了VITS和微软这两个语音合成功能。甚至使用了微软的效果来训练VITS,出乎意料,效果居然不错,没有大佐的口音。 微软 微软中最好听的,感情最顺滑的,应该是“云希”莫属。…...

普乐蛙VR航天航空巡展项目来到了第七站——绵阳科博会
Hi~ 你有一份邀约请查收 11月22日—26日绵阳科博会 普乐蛙展位号:B馆科技体验区(1) 邀你体验趣味VR科普,探索科技新发展 第十一届中国(绵阳)科技城国际科技博览会 绵阳科博会自2013年创办以来,已连续成功举办十届,已有近7000家单位…...
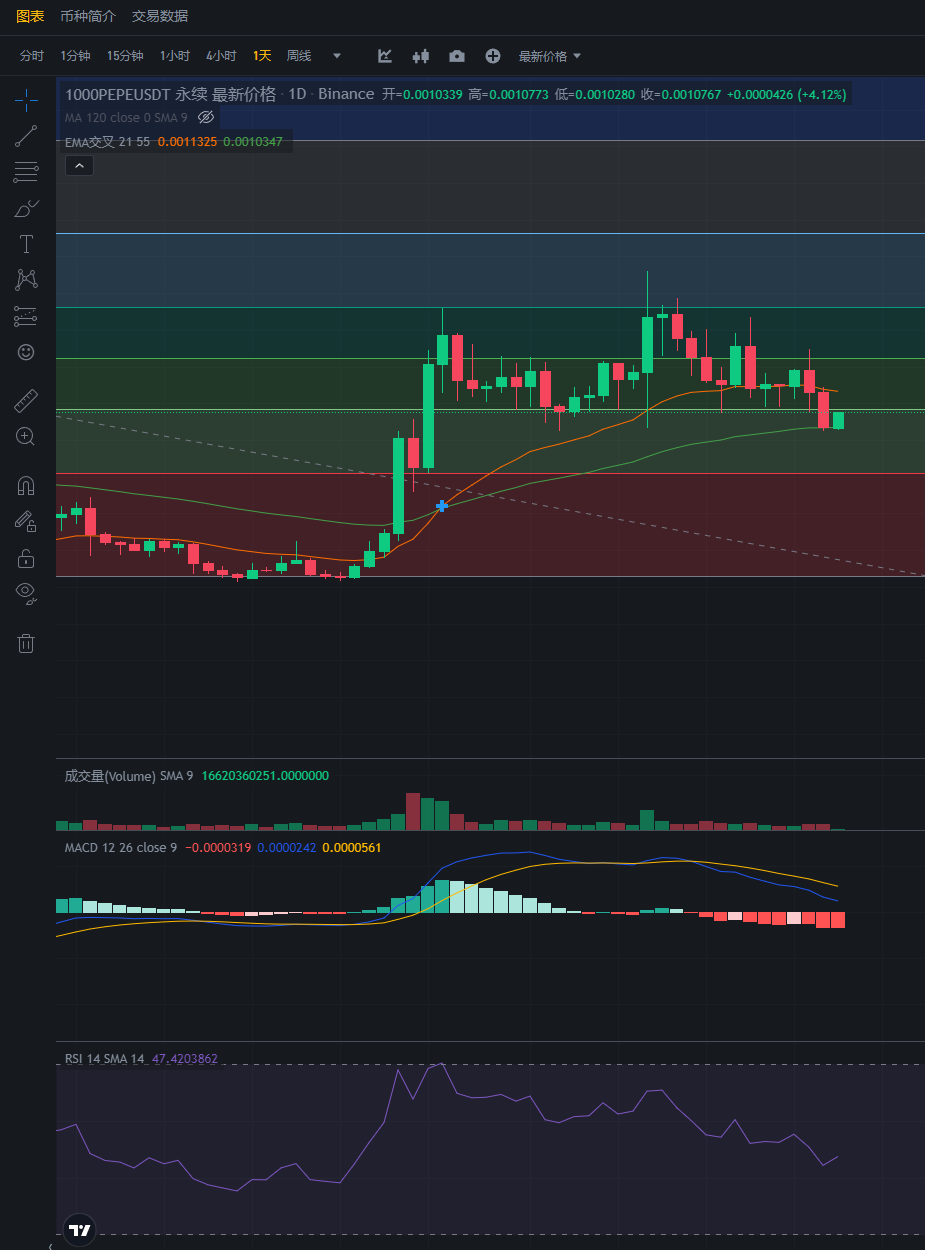
行情分析——加密货币市场大盘走势(11.22)
大饼昨日晚上打了止损,笔者入场了空单,目前来看上涨乏力,下跌是必然的,昨日的下跌跌破了蓝色上涨趋势线,而今日白天开始反弹,别着急抄底,下跌还没有结束。 空单策略:入场36500 止盈…...
QT--MP3项目数据库数据表设计与实现_歌曲搜索
QSqlQuery类:...

gzip 压缩优化大 XML 响应的处理方法
当处理大型XML响应时,我们经常会面临内存限制和性能问题。 在处理这个问题时,我们可以使用Python的requests库和lxml库来解决。下面是解决方案的步骤: 1. 使用requests库发送HTTP请求获取XML响应。 2. 检查响应的Content-Encoding标头&…...

数字化文旅系统,让景区营销变得更加简单!
随着互联网的普及和信息技术的不断发展,越来越多的消费者开始通过互联网来获取旅游信息、预订旅游产品和服务。因此,文旅行业需要紧跟时代步伐,借助数字化技术来提高服务质量和效率,满足消费者对于便捷、个性化的需求。 1. 强大功…...

配置命令别名
vim ~/.bashrc 配置命令别名 alias knkubectl -n alias kkubectl 配置golang环境变量 export GOPATH/root/go export GO111MODULEon export GOPROXY"http://mirros.yun.ali.com.cn:8848/goproxy" export GOROOT/usr/local/go export PATH$PATH:$GOPATH/bi…...

zookeeper应用之分布式队列
队列这种数据结构都不陌生,特点就是先进先出。有很多常用的消息中间件可以有现成的该部分功能,这里使用zookeeper基于发布订阅模式来实现分布式队列。对应的会有一个生产者和一个消费者。 这里理论上还是使用顺序节点。生产者不断产生新的顺序子节点&am…...
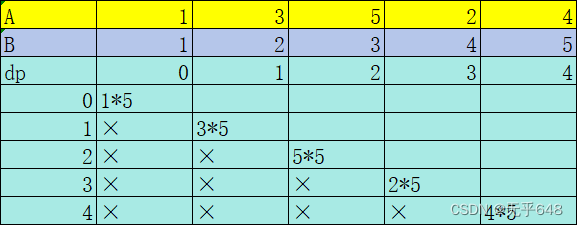
取数游戏2(动态规划java)
取数游戏2 题目描述 给定两个长度为n的整数列A和B,每次你可以从A数列的左端或右端取走一个数。假设第i次取走的数为ax,则第i次取走的数的价值vibi⋅ax,现在希望你求出∑vi的最大值。 输入格式 第一行一个数T ,表示有T 组数据。…...

终极指南:5步掌握KrkrzExtract XP3资源解包工具
终极指南:5步掌握KrkrzExtract XP3资源解包工具 【免费下载链接】KrkrzExtract The next generation of KrkrExtract 项目地址: https://gitcode.com/gh_mirrors/kr/KrkrzExtract 你是否曾经面对krkrz引擎的XP3格式资源文件感到束手无策?想要修改…...

快手视频怎么去水印?快手去掉水印在线解析提取方法|2026在线工具对比
快手作为主流短视频平台,每天都有大量优质内容产生。但平台加上的水印让素材的二次利用变得困难——无论是自媒体创作者搜集素材、还是普通用户想要保存喜欢的视频,水印都会成为痛点。那么快手视频去水印的正确打开方式是什么?有哪些靠谱的在…...

天赐范式第33天:算子流C++迁移实录:NS方程256×256方腔流引擎的设计、排险与验证框架
摘要:天赐范式的19原生算子及其衍生的6个二阶审视算子(MΣ、ρ、δ、Con、λ、C未参与),已在环境治理、全灾种应急等项目中完成Python原型验证。但范式不能只活在解释器里。本文记录了将这套算子体系完整迁移至C裸机环境的技术过程…...

终极英雄联盟回放分析工具:5步掌握ROFL播放器的完整使用指南
终极英雄联盟回放分析工具:5步掌握ROFL播放器的完整使用指南 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player 还在为英雄联盟…...

基于LLM的智能文档生成:从代码理解到自动化文档工程实践
1. 项目概述:当文档生成遇上智能体最近在折腾一个挺有意思的项目,叫effect-llm-docs。简单来说,这是一个利用大型语言模型(LLM)来自动化生成、更新和维护项目文档的工具。如果你和我一样,经历过项目迭代飞快…...

VSCode 2026容器化调试全面升级:从Docker Compose到Kind集群的零配置热重载实操手册
更多请点击: https://intelliparadigm.com 第一章:VSCode 2026容器化调试增强教程 VSCode 2026 引入了原生支持 OCI 容器运行时的调试代理(Dev Container Debug Agent),可直接在容器内启动语言服务、断点注入与内存快…...

四大科技巨头狂砸7250亿美元:AI算力军备竞赛白热化
早上刷新闻的时候,看到一个数字让我愣住了——7250亿美元。 这不是某家公司的市值,也不是某个国家的GDP,而是谷歌、亚马逊、微软、Meta这四家科技巨头,计划在2026年投入的AI基础设施总预算。 同比增长77%。 这个数字背后ÿ…...

2026-5-6
...

构建AI提示词锻造炉:从碎片化到工程化的高效管理实践
1. 项目概述:为什么我们需要一个AI提示词锻造炉?如果你和我一样,每天都在和ChatGPT、Cursor、Claude这些AI助手打交道,那你一定经历过这样的时刻:面对一个复杂任务,你明明记得上周写过一个绝佳的提示词&…...

PCB焊点质量电子设备可靠性核心基石
在电子制造领域,PCB 焊点是连接元器件与电路板的 “神经节点”,既是电气信号传输的通道,也是机械固定的关键结构。一个微小的焊点失效,可能导致整个设备功能瘫痪,因此焊点质量直接决定电子设备的稳定性、使用寿命与安全…...