【论文阅读笔记】Supervised Contrastive Learning
【论文阅读笔记】Supervised Contrastive Learning
摘要
- 自监督批次对比方法扩展到完全监督的环境中,以有效利用标签信息
- 提出两种监督对比损失的可能版本
介绍
- 交叉熵损失函数的不足之处,对噪声标签的不鲁棒性和可能导致交叉的边际,降低了泛化能。
- 监督对比损失:将同一类别的所有样本作为正样本,并将批次中其余部分的样本作为负样本进行对比
- 自监督对比对比损失:将每一个锚点(图像的增强版本)与整个批次的其余样本形成的负样本集进行对比。
- 通过黑白小狗照片的展示,考虑类别标签信息会导致嵌入空间中相同类别的元素比自监督情况下更加紧密地对齐
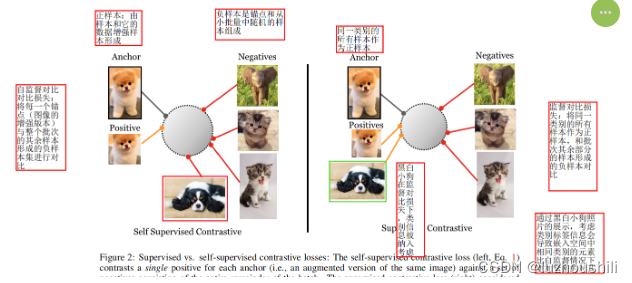
- 自监督对比学习:在嵌入空间中将一个锚点和一个正样本拉在一起,并将锚点与许多负样本进行推散。没有标签可用,正样本通常由样本的数据增强形成,而负样本由锚点和从小批量随机选择的样本组成。
- 对比学习通过比较正样本和负样本之间的关系来学习有意义的表示,而无需使用标签信息。
- 创新点在于考虑除了许多负样本之外,还有很多正样本,这与自监督对比学习不同,后者通常只使用单一正样本
- 允许每一个锚点有多个正样本是对比学习在完全监督设置下的一项创新。
- 相对于交叉熵损失更稳健
相关工作
- 相对于交叉熵损失,该损失对于超参数的选择更加不敏感。这意味着在使用该损失时,调整超参数的需求相对较小,更容易在不同的任务和设置中获得良好的性能。
- 这句话指出了交叉熵损失的缺点,主要包括对噪声的敏感性、对抗性示例的存在以及边际不足。
- 这句话提到了自监督学习领域的最新进展。
- 三元组损失是一种用于监督学习的损失函数。在这种损失函数中,每个锚点都与一个正样本和一个负样本配对。正样本通常来自同一类别,而负样本则来自其他类别。这种损失的目标是使得锚点与正样本之间的距离尽可能小,而与负样本之间的距离尽可能大,从而促使模型学到更好的表示。在提供的链接中,可能包含了更详细的关于三元组损失的信息。
- 自监督对比损失是一种损失函数,其使用方式类似于三元组损失,但有一些关键的区别。在自监督对比损失中,每个锚点样本仍然有一个对应的正样本,但与三元组损失不同的是,每个锚点会使用许多负样本对。这些负样本对通常是通过在整个批次中随机选择样本来形成的。
- 这种损失函数的目标是通过拉近同一类别样本的表示,并将不同类别样本的表示推开,从而在嵌入空间中形成更好的聚类。这通过在训练时将每个锚点与来自同一类别和其他类别的样本进行对比来实现。这种对比损失的设计使得模型能够学到数据的更有意义的表示,而无需使用显式的类别标签。
Method
-
对于给定的数据批次,首先对每个样本进行两次数据增强,从而获得两个增强版本的批次。这两个副本表示数据的两个不同视图,以提供更多的信息。
-
然后,这两个增强版本的批次都通过编码器网络进行前向传播,其中编码器网络将每个样本映射到一个2048维度的归一化嵌入。这个嵌入是表示样本在嵌入空间中的位置的向量。
-
这个过程的关键点是,通过在两个增强版本上进行前向传播,模型能够学习到更具鲁棒性和泛化能力的特征表示,而无需使用显式的标签信息。这些学到的表示可以在后续的任务中进行微调或用于其他下游任务。
-
步骤
-
数据准备: 对于输入的数据批次,进行两次数据增强,生成两个批次的副本,以提高模型对数据的鲁棒性和泛化性能。
-
编码器网络: 通过编码器网络,对两个副本进行前向传播,得到每个样本的2048维度的归一化嵌入,形成在高维空间中的紧凑表示。
-
投影网络: 在训练阶段,通过投影网络对表示进行下一步传播,提炼特征以更好地支持监督学习任务。在推断阶段,投影网络被丢弃。
-
损失计算: 在投影网络的输出上设置一个监督对比损失,该损失用于引导模型学习有助于分类的特征表示。
-
分类器训练: 为了在具体的分类任务中使用训练好的模型,冻结表示后,训练一个线性分类器,并使用交叉熵损失来优化分类器,以实现更好的分类性能。
-
-
自监督对比学习: 通过自监督对比学习方式,学习数据的表示。这是通过在数据批次上引入对比损失,使得相同样本的不同视图之间更加相似,不同样本之间更加分散,从而促使模型学到更具有区分性和泛化性的表示。
-
监督微调: 利用自监督学习得到的表示,通过监督学习任务对这些表示进行微调。这是通过在冻结的表示上添加一个线性分类器,使用监督学习的交叉熵损失来微调模型,使其适应具体的分类目标。这个过程在冻结了大部分网络参数的情况下,只更新分类器的参数。
-
一组N个随机采样的样本/标签对(N个数据点,每个数据点包括一个样本和相应的标签)。训练时的相应批次包含2N对。这意味着每个样本会有两个随机增强版本,即每个数据点有两个样本。记作 x2k 和 x2k-1,它们是 xk 的两个随机增强版本。这里 k 表示样本的索引

-
对于监督学习,原始的自监督对比损失公式无法处理由于存在标签而已知多个样本属于同一类的情况。在监督学习中,通常会有多个样本属于相同的类别,而原始的自监督对比损失是为自监督学习设计的,其中每个样本只有一个正样本。
-
在监督学习中,正样本通常来自同一类别,而负样本来自其他类别。由于多个正样本可能属于同一类别,原始自监督对比损失需要进行适当修改以处理这种情况。文章进一步介绍了两种修改方案,即公式2和公式3,来适应监督学习中存在多个正样本的情况。这些修改允许每个锚点有多个正样本,从而更好地处理监督学习任务
-
这段话指出在监督学习的背景下,需要修改损失函数以适应已知同一类别的多个样本的情况。在原始的自监督对比损失中,损失函数假定每个锚点只有一个正样本。然而,在监督学习中,由于已知同一类别的多个样本,需要对损失函数进行修改,以允许每个锚点有多个正样本。
-
监督对比学习与三元组损失[53]密切相关,三元组损失是监督学习中广泛使用的损失函数之一。在附录中,我们展示了当使用一个正样本和一个负样本时,三元组损失是对比损失的一个特例。当使用多个负样本时,我们表明SupCon损失等同于N-pairs损失[45]。
-
- AutoAugment:自动搜索数据增强策略的方法,通过在训练集上进行搜索。属于自适应的数据增强方法
-
RandAugment:随机数据增强方法,通过在每一个训练批次中应用不同的增强,增加对多样性和不同视角的学习
-
SimAugment:SimAugment是一种基于相似性的数据增强方法,他利用多个随即增强操作堆叠在一起,创建一个更强大和多样性的增强策略
-
泛化性能: SupCon 在不同数据集和任务上都表现得更好,具有更强的泛化能力。
-
最先进准确度: 使用 AutoAugment 策略,该方法取得了新的最先进的准确度。
-
对比学习与数据增强结合: 结合对比学习和先进的数据增强技术可能产生更好的性能,这强调了方法的综合效果。
相关文章:
【论文阅读笔记】Supervised Contrastive Learning
【论文阅读笔记】Supervised Contrastive Learning 摘要 自监督批次对比方法扩展到完全监督的环境中,以有效利用标签信息提出两种监督对比损失的可能版本 介绍 交叉熵损失函数的不足之处,对噪声标签的不鲁棒性和可能导致交叉的边际,降低了…...
数据库管理工具,你可以用Navicat,但我选DBeaver!
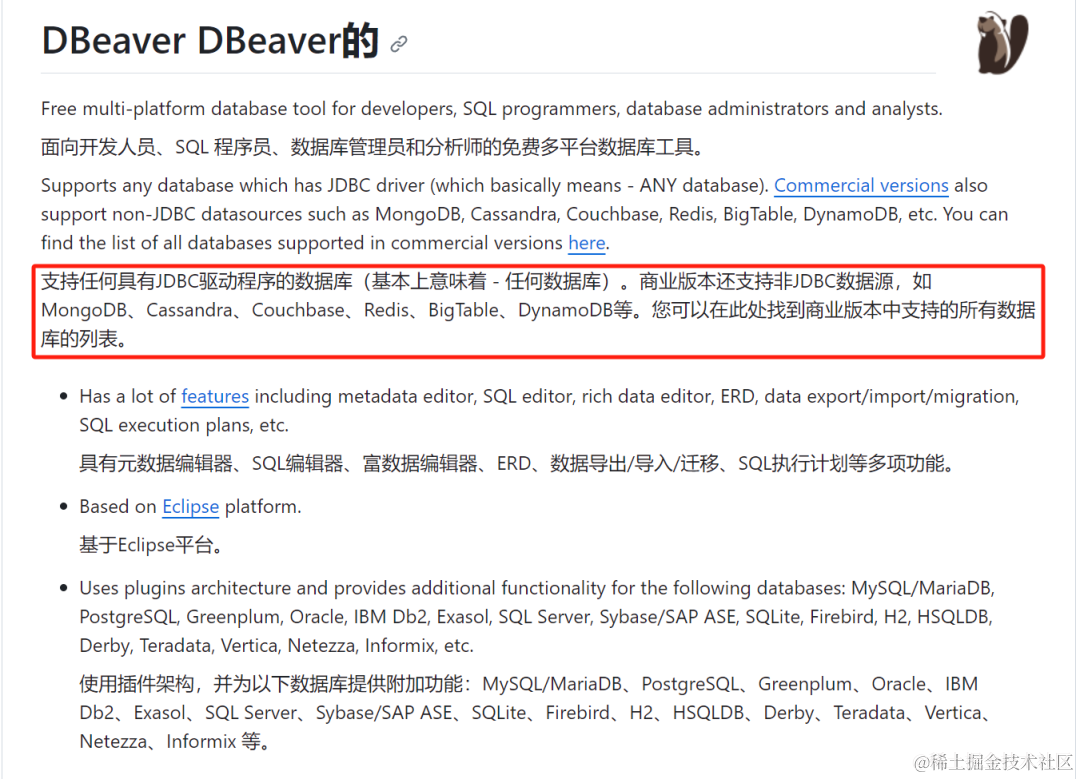
大家好,我是豆小匠。数据库GUI工具哪家强,众人遥指Navicat。 可是Navicat老贵了。 如果公司有正版授权的还好,如果没有正版授权,还不给你用盗版,那才叫绝绝子。 好了,主角登场,DBeaver&#x…...

数据库的三范式(Normalization)
数据库的三范式(Normalization)是关系数据库设计中的基本理论原则,旨在减少数据冗余和提高数据库的数据组织结构。三范式通过将数据分解为更小的表,并通过关系建立连接,使得数据库设计更加灵活、规范和容易维护。在这篇…...
【代码随想录】刷题笔记Day32
前言 实在不想做项目,周末和npy聊了就业的焦虑,今天多花点时间刷题!刷刷刷刷! 93. 复原 IP 地址 - 力扣(LeetCode) 分割startindex类似上一题,难点在于:判断子串合法性(0~255)、&…...
|LeetCode416. 分割等和子集)
LeetCode算法题解(动态规划,背包问题)|LeetCode416. 分割等和子集
LeetCode416. 分割等和子集 题目链接:416. 分割等和子集 题目描述: 给你一个 只包含正整数 的 非空 数组 nums 。请你判断是否可以将这个数组分割成两个子集,使得两个子集的元素和相等。 示例 1: 输入:nums [1,5,…...
Java Class 类文件格式看这一篇就够了
本文将揭开Java Class文件的神秘面纱,带你了解Class文件的内部结构,并从Class文件结构的视角告诉你: 为什么Java Class字节码文件可以“写一次,遍地跑”?为什么常量池的计数从1开始,而不是和java等绝大多数…...
『亚马逊云科技产品测评』活动征文|构建生态农场家禽系统
『亚马逊云科技产品测评』活动征文|构建生态农场家禽系统 授权声明:本篇文章授权活动官方亚马逊云科技文章转发、改写权,包括不限于在 Developer Centre, 知乎,自媒体平台,第三方开发者媒体等亚马逊云科技官方渠道 前…...

[github配置] 远程访问仓库以及问题解决
作者:20岁爱吃必胜客(坤制作人),近十年开发经验, 跨域学习者,目前于新西兰奥克兰大学攻读IT硕士学位。荣誉:阿里云博客专家认证、腾讯开发者社区优质创作者,在CTF省赛校赛多次取得好成绩。跨领域…...

mysql5.6 删除用户/ drop user
目录 前言查看用户删除用户删除没有用户名的用户 前言 CentOS5.6.51 MySQL Community Server (GPL)查看MySQL的版本 查看用户 mysql> select Host,User from user; ----------------------- | Host | User | ----------------------- | 10.0.101.112 | root …...
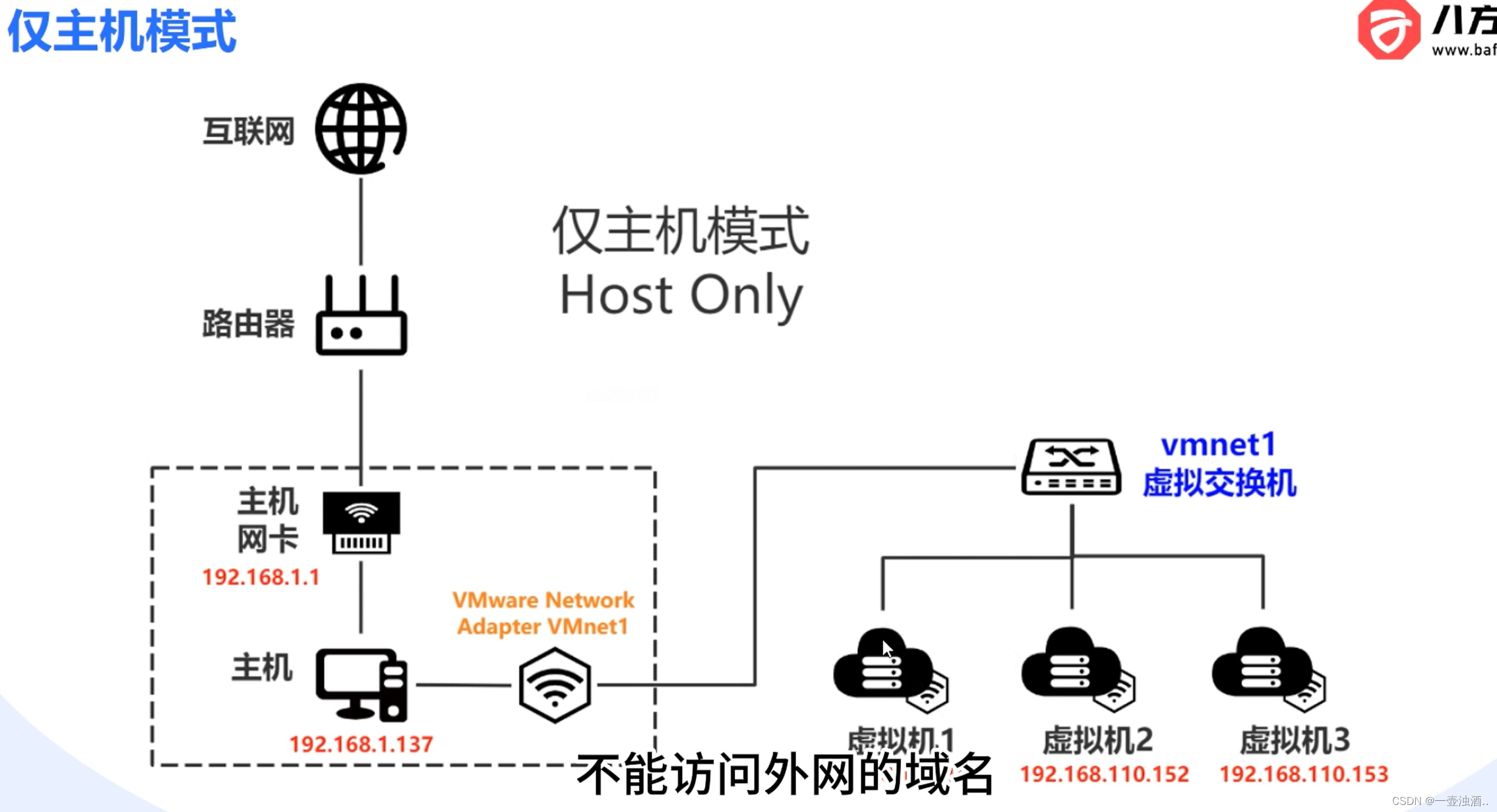
VMware三种网络模式
桥接模式 NAT(网络地址转换模式) Host-Only(仅主机模式) 参考: vmware虚拟机三种网络模式 - 知乎 (zhihu.com)...
的调优技巧和实战2)
Java虚拟机(JVM)的调优技巧和实战2
JVM是Java应用程序的运行环境,它负责管理Java应用程序的内存分配、垃圾收集等重要任务。在JVM的默认设置下,可能存在一些性能问题,因此需要进行调优。在本次分享中,作者将介绍一些实用的JVM实战调优技巧,以提高Java应用…...

2020年下半年试题一:论信息系统项目的成本管理
论文题目 1.概要叙述你参与过的信息系统项目(项目的背景、项目规模、发起单位、目的、项目内容、组织结构、项目周期、交付的成果等),并说明你在其中承担的工作(项目背景要求本人真实经历,不得抄袭及杜撰)。…...

9. 回文数 --力扣 --JAVA
题目 给你一个整数 x ,如果 x 是一个回文整数,返回 true ;否则,返回 false 。 回文数是指正序(从左向右)和倒序(从右向左)读都是一样的整数。 例如,121 是回文࿰…...
ChainLight zkSync Era漏洞揭秘
1. 引言 ChainLight研究人员于2023年9月15日,发现了zkSync Era主网的ZK电路的一个soundness bug,并于2023年9月17日,向Matter Labs团队报告了该问题。Matter Labs团队修复了该问题,并奖励了ChainLight团队5万USDC——为首个zkSync…...
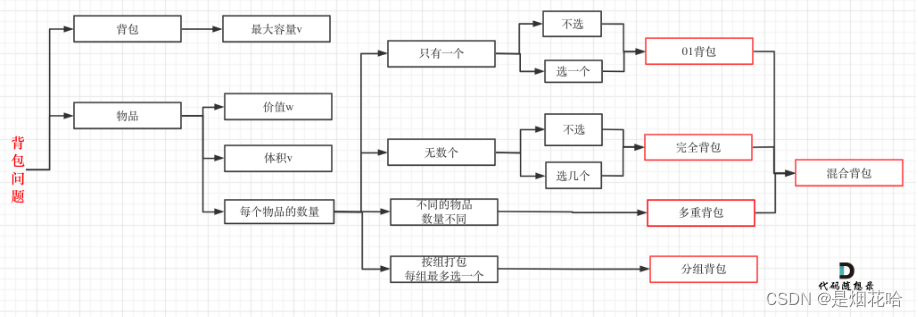
01背包与完全背包学习总结
背包问题分类见下图 参考学习点击:代码随想录01背包讲解 01背包问题: 核心思路: 1、先遍历物品个数,再遍历背包容量。因为容量最先是最大的,往背包里放物品,所以背包容量在慢慢减少,但背包容量…...
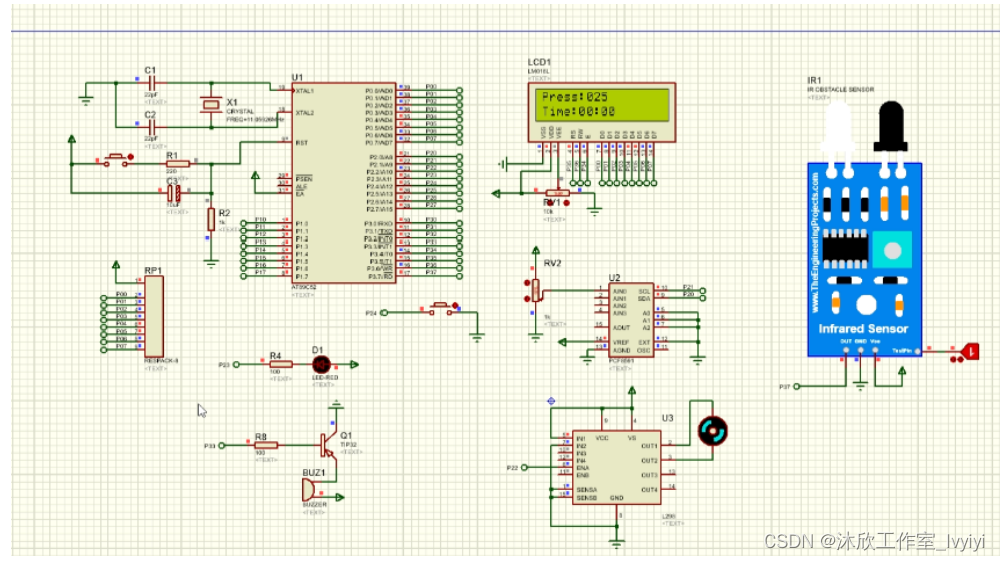
基于单片机的公共场所马桶设计(论文+源码)
1.系统设计 本课题为公共场所的马桶设计,其整个系统架构如图2.1所示,其采用STC89C52单片机为核心控制器,结合HC-SR04人体检测模块,压力传感器,LCD1602液晶,蜂鸣器,L298驱动电路等构成整个系统&…...

注解案例:山寨Junit与山寨JPA
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO 联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬 上篇讲了什么是注解&am…...
(D前缀和+贪心加血量))
Codeforces Round 822 (Div. 2)(D前缀和+贪心加血量)
A.选三条相邻的边遍历一次求最小值 #include<bits/stdc.h> using namespace std; const int N 1e610,mod1e97; #define int long long int n,m; vector<int> g[N]; int a[N]; void solve() {cin>>n;int res2e18;for(int i1;i<n;i) cin>>a[i];sort…...
不停的挖掘硬盘的最大潜能
从 NAS 上退休的硬盘被用在了监控的存储上了。 随着硬盘使用寿命的接近尾声,感觉就是从高附加值数据到低附加值数据上。监控数据只会保留那么几个月的时间,很多时候都会被覆盖重新写入。 有人问为什么监控数据不保留几年的,那是因为监控数据…...

Java游戏之飞翔的小鸟
前言 飞翔的小鸟 小游戏 可以作为 java入门阶段的收尾作品 ; 需要掌握 面向对象的使用以及了解 多线程,IO流,异常处理,一些java基础等相关知识。一 、游戏分析 1. 分析游戏逻辑 (1)先让窗口显示出来&#x…...

Python 性能分析实战:接口从 50ms 飙到 500ms,我会先查什么?
Python 性能分析实战:接口从 50ms 飙到 500ms,我会先查什么? Python 很优雅,但优雅不等于天然高性能。真正成熟的 Python 编程,不是看到慢就立刻改代码,而是先问一句:慢在哪里?CPU、…...

Windows组策略编辑器终极指南:Policy Plus解锁全版本系统配置能力
Windows组策略编辑器终极指南:Policy Plus解锁全版本系统配置能力 【免费下载链接】PolicyPlus Local Group Policy Editor plus more, for all Windows editions 项目地址: https://gitcode.com/gh_mirrors/po/PolicyPlus 还在为Windows家庭版无法使用组策略…...

利用 Taotoken 模型广场为新产品选择性价比最高的文本生成模型
利用 Taotoken 模型广场为新产品选择性价比最高的文本生成模型 1. 理解模型选型的关键维度 为新产品选择文本生成模型时,需要综合考虑多个关键因素。首先是模型能力与产品需求的匹配度,例如生成内容的长度、创意性、逻辑性等。其次是成本因素ÿ…...

终极RDPWrap指南:免费解锁Windows远程桌面多用户并发连接
终极RDPWrap指南:免费解锁Windows远程桌面多用户并发连接 【免费下载链接】rdpwrap RDP Wrapper Library 项目地址: https://gitcode.com/gh_mirrors/rd/rdpwrap 你是否曾因Windows家庭版或专业版无法支持多用户同时远程连接而感到困扰?想要在个人…...
)
【紧急更新】Hugging Face v4.45+强制变更的3项微调配置规则(未迁移者48小时内将触发训练中断)
更多请点击: https://intelliparadigm.com 第一章:Hugging Face v4.45微调配置变更的背景与影响全景 Hugging Face Transformers 库自 v4.45 版本起对训练配置体系进行了结构性重构,核心变化聚焦于 TrainingArguments 类的参数语义统一、弃…...

如何用Label Studio破解AI数据标注的三大难题:从多模态处理到主动学习闭环
如何用Label Studio破解AI数据标注的三大难题:从多模态处理到主动学习闭环 【免费下载链接】label-studio Label Studio is a multi-type data labeling and annotation tool with standardized output format 项目地址: https://gitcode.com/GitHub_Trending/la/…...

5大创新技术重构多平台直播弹幕实时采集系统
5大创新技术重构多平台直播弹幕实时采集系统 【免费下载链接】BarrageGrab 抖音快手bilibili直播弹幕wss直连,非系统代理方式,无需多开浏览器窗口 项目地址: https://gitcode.com/gh_mirrors/ba/BarrageGrab 在直播电商、游戏直播和内容创作领域&…...
)
用ESP32C3和Arduino IDE,5分钟搞定MiniMax大模型API调用(附完整代码)
ESP32C3极简实战:5分钟用Arduino IDE对接MiniMax大模型API 当物联网遇上生成式AI,硬件开发者的创意边界被彻底打破。ESP32C3作为乐鑫科技推出的RISC-V架构芯片,以其低功耗、低成本和高集成度成为智能硬件项目的首选。而MiniMax作为国内领先的…...

雷电与操作冲击电压下,空气间隙绝缘怎么配合?手把手解读伏秒特性曲线
电力系统绝缘配合实战:伏秒特性曲线的工程应用解析 当一道闪电劈向高压输电线路时,系统如何在微秒级时间内做出反应?这个看似简单的问题背后,隐藏着电力系统绝缘配合的核心技术——伏秒特性曲线的精妙应用。作为电力工程师的"…...

不懂这个,一人企业必死
一人企业必死局:搞不懂这个核心死穴,做代运营、智能体服务,轻则白干重则负债 作者:智能体架构师卢成 | Agent Architect | 意图工程卢成 今天不讲风口、不讲变现,只给所有做一人企业、做To B代运营、做智能体企业服务的…...