YOLOv5 分类模型 数据集加载 3
YOLOv5 分类模型 数据集加载 3 自定义类别
flyfish
YOLOv5 分类模型 数据集加载 1 样本处理
YOLOv5 分类模型 数据集加载 2 切片处理
YOLOv5 分类模型的预处理(1) Resize 和 CenterCrop
YOLOv5 分类模型的预处理(2)ToTensor 和 Normalize
YOLOv5 分类模型 Top 1和Top 5 指标说明
YOLOv5 分类模型 Top 1和Top 5 指标实现
之前的处理方式是类别名字是文件夹名字,类别ID是按照文件夹名字的字母顺序
现在是类别名字是文件夹名字,按照文件列表名字顺序 例如
classes_name=['n02086240', 'n02087394', 'n02088364', 'n02089973', 'n02093754',
'n02096294', 'n02099601', 'n02105641', 'n02111889', 'n02115641']
n02086240 类别ID是0
n02087394 类别ID是1
代码处理是
if classes_name is None or not classes_name:classes, class_to_idx = self.find_classes(self.root)print("not classes_name")else:classes = classes_nameclass_to_idx ={cls_name: i for i, cls_name in enumerate(classes)}print("is classes_name")
完整
import time
from models.common import DetectMultiBackend
import os
import os.path
from typing import Any, Callable, cast, Dict, List, Optional, Tuple, Union
import cv2
import numpy as npimport torch
from PIL import Image
import torchvision.transforms as transformsimport sysclasses_name=['n02086240', 'n02087394', 'n02088364', 'n02089973', 'n02093754', 'n02096294', 'n02099601', 'n02105641', 'n02111889', 'n02115641']class DatasetFolder:def __init__(self,root: str,) -> None:self.root = rootif classes_name is None or not classes_name:classes, class_to_idx = self.find_classes(self.root)print("not classes_name")else:classes = classes_nameclass_to_idx ={cls_name: i for i, cls_name in enumerate(classes)}print("is classes_name")print("classes:",classes)print("class_to_idx:",class_to_idx)samples = self.make_dataset(self.root, class_to_idx)self.classes = classesself.class_to_idx = class_to_idxself.samples = samplesself.targets = [s[1] for s in samples]@staticmethoddef make_dataset(directory: str,class_to_idx: Optional[Dict[str, int]] = None,) -> List[Tuple[str, int]]:directory = os.path.expanduser(directory)if class_to_idx is None:_, class_to_idx = self.find_classes(directory)elif not class_to_idx:raise ValueError("'class_to_index' must have at least one entry to collect any samples.")instances = []available_classes = set()for target_class in sorted(class_to_idx.keys()):class_index = class_to_idx[target_class]target_dir = os.path.join(directory, target_class)if not os.path.isdir(target_dir):continuefor root, _, fnames in sorted(os.walk(target_dir, followlinks=True)):for fname in sorted(fnames):path = os.path.join(root, fname)if 1: # 验证:item = path, class_indexinstances.append(item)if target_class not in available_classes:available_classes.add(target_class)empty_classes = set(class_to_idx.keys()) - available_classesif empty_classes:msg = f"Found no valid file for the classes {', '.join(sorted(empty_classes))}. "return instancesdef find_classes(self, directory: str) -> Tuple[List[str], Dict[str, int]]:classes = sorted(entry.name for entry in os.scandir(directory) if entry.is_dir())if not classes:raise FileNotFoundError(f"Couldn't find any class folder in {directory}.")class_to_idx = {cls_name: i for i, cls_name in enumerate(classes)}return classes, class_to_idxdef __getitem__(self, index: int) -> Tuple[Any, Any]:path, target = self.samples[index]sample = self.loader(path)return sample, targetdef __len__(self) -> int:return len(self.samples)def loader(self, path):print("path:", path)#img = cv2.imread(path) # BGR HWCimg=Image.open(path).convert("RGB") # RGB HWCreturn imgdef time_sync():return time.time()#sys.exit()
dataset = DatasetFolder(root="/media/a/flyfish/source/yolov5/datasets/imagewoof/val")#image, label=dataset[7]#
weights = "/home/a/classes.pt"
device = "cpu"
model = DetectMultiBackend(weights, device=device, dnn=False, fp16=False)
model.eval()
print(model.names)
print(type(model.names))mean=[0.485, 0.456, 0.406]
std=[0.229, 0.224, 0.225]
def preprocess(images):#实现 PyTorch Resizetarget_size =224img_w = images.widthimg_h = images.heightif(img_h >= img_w):# hwresize_img = images.resize((target_size, int(target_size * img_h / img_w)), Image.BILINEAR)else:resize_img = images.resize((int(target_size * img_w / img_h),target_size), Image.BILINEAR)#实现 PyTorch CenterCropwidth = resize_img.widthheight = resize_img.heightcenter_x,center_y = width//2,height//2left = center_x - (target_size//2)top = center_y- (target_size//2)right =center_x +target_size//2bottom = center_y+target_size//2cropped_img = resize_img.crop((left, top, right, bottom))#实现 PyTorch ToTensor Normalizeimages = np.asarray(cropped_img)print("preprocess:",images.shape)images = images.astype('float32')images = (images/255-mean)/stdimages = images.transpose((2, 0, 1))# HWC to CHWprint("preprocess:",images.shape)images = np.ascontiguousarray(images)images=torch.from_numpy(images)#images = images.unsqueeze(dim=0).float()return imagespred, targets, loss, dt = [], [], 0, [0.0, 0.0, 0.0]
# current batch size =1
for i, (images, labels) in enumerate(dataset):print("i:", i)im = preprocess(images)images = im.unsqueeze(0).to("cpu").float()print(images.shape)t1 = time_sync()images = images.to(device, non_blocking=True)t2 = time_sync()# dt[0] += t2 - t1y = model(images)y=y.numpy()#print("y:", y)t3 = time_sync()# dt[1] += t3 - t2#batch size >1 图像推理结果是二维的#y: [[ 4.0855 -1.1707 -1.4998 -0.935 -1.9979 -2.258 -1.4691 -1.0867 -1.9042 -0.99979]]tmp1=y.argsort()[:,::-1][:, :5]#batch size =1 图像推理结果是一维的, 就要处理下argsort的维度#y: [ 3.7441 -1.135 -1.1293 -0.9422 -1.6029 -2.0561 -1.025 -1.5842 -1.3952 -1.1824]#print("tmp1:", tmp1)pred.append(tmp1)#print("labels:", labels)targets.append(labels)#print("for pred:", pred) # list#print("for targets:", targets) # list# dt[2] += time_sync() - t3pred, targets = np.concatenate(pred), np.array(targets)
print("pred:", pred)
print("pred:", pred.shape)
print("targets:", targets)
print("targets:", targets.shape)
correct = ((targets[:, None] == pred)).astype(np.float32)
print("correct:", correct.shape)
print("correct:", correct)
acc = np.stack((correct[:, 0], correct.max(1)), axis=1) # (top1, top5) accuracy
print("acc:", acc.shape)
print("acc:", acc)
top = acc.mean(0)
print("top1:", top[0])
print("top5:", top[1])
相关文章:

YOLOv5 分类模型 数据集加载 3
YOLOv5 分类模型 数据集加载 3 自定义类别 flyfish YOLOv5 分类模型 数据集加载 1 样本处理 YOLOv5 分类模型 数据集加载 2 切片处理 YOLOv5 分类模型的预处理(1) Resize 和 CenterCrop YOLOv5 分类模型的预处理(2)ToTensor 和 …...

『亚马逊云科技产品测评』活动征文|AWS 存储产品类别及其适用场景详细说明
授权声明:本篇文章授权活动官方亚马逊云科技文章转发、改写权,包括不限于在 Developer Centre, 知乎,自媒体平台,第三方开发者媒体等亚马逊云科技官方渠道 目录 前言、AWS 存储产品类别 1、Amazon Elastic Block Store (EBS) …...
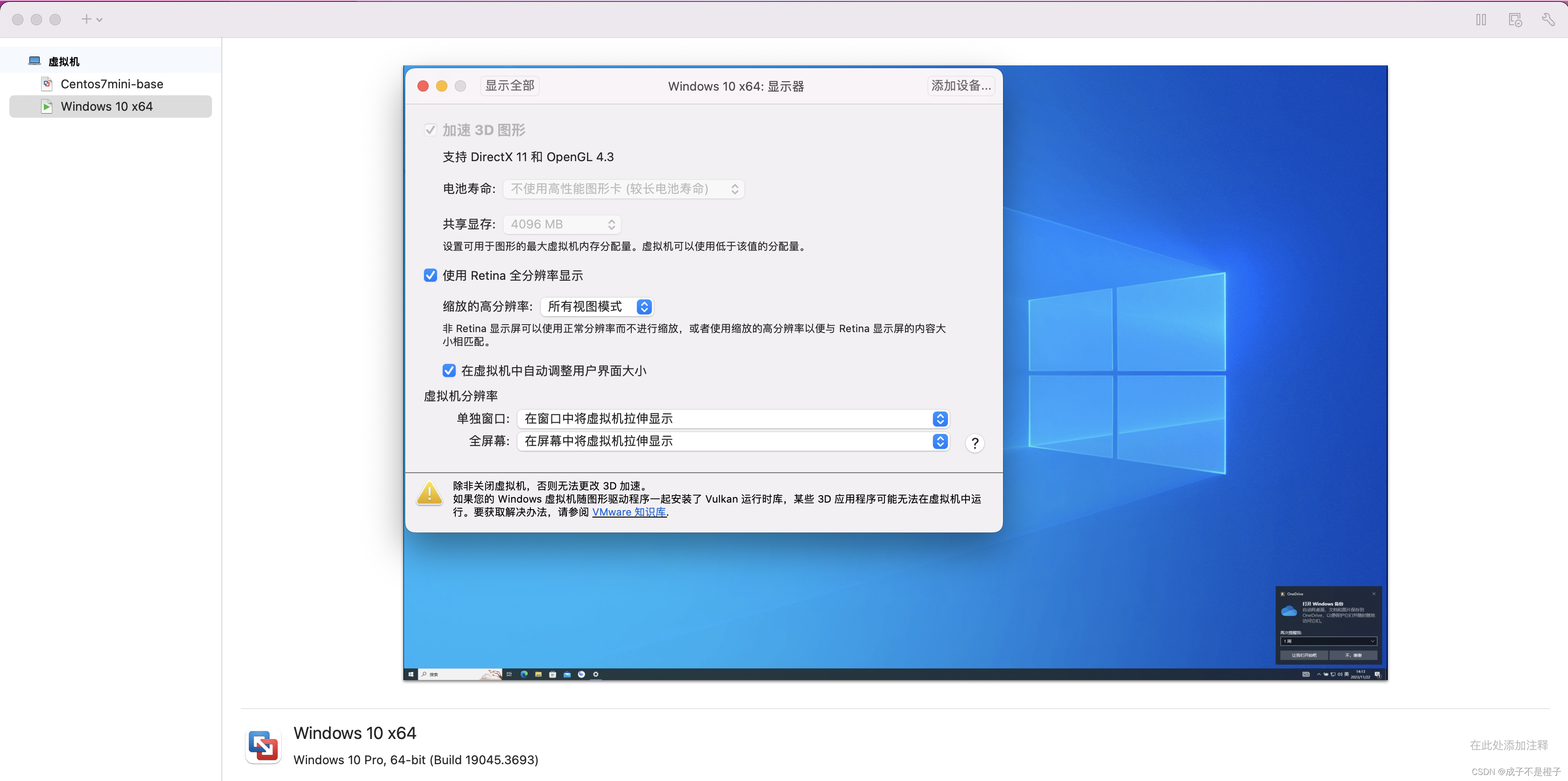
Mac | Vmware Fusion | 分辨率自动还原问题解决
1. 问题 Mac的Vmware Fusion在使用Windows10虚拟机时,默认显示器配置如下: 开机进入系统并变更默认分辨率后,只要被 ⌘Tab 切换分辨率就会还原到默认,非常影响体验。 2. 解决方式 调整 设置 -> 显示器 -> 虚拟机分辨率…...

SQL知多少?这篇文章让你从小白到入门
个人网站 本文首发公众号小肖学数据分析 SQL(Structured Query Language)是一种用于管理和处理关系型数据库的编程语言。 对于想要成为数据分析师、数据库管理员或者Web开发人员的小白来说,学习SQL是一个很好的起点。 本文将为你提供一个…...

centos7安装MySQL—以MySQL5.7.30为例
centos7安装MySQL—以MySQL5.7.30为例 本文以MySQL5.7.30为例。 官网下载 进入MySQL官网:https://www.mysql.com/ 点击DOWNLOADS 点击链接; 点击如上链接: 选择对应版本: 点击下载。 安装 将下载后的安装包上传到/usr/local下…...

3.计算机网络补充
2.5 HTTPS 数字签名:发送端将消息使⽤ hash 函数⽣成摘要,并使⽤私钥加密后得到“数字签名”,并将其附在消息之后。接收端使⽤公钥对“数字签名”解密,确认发送端身份,之后对消息使⽤ hash 函数处理并与接收到的摘要对…...
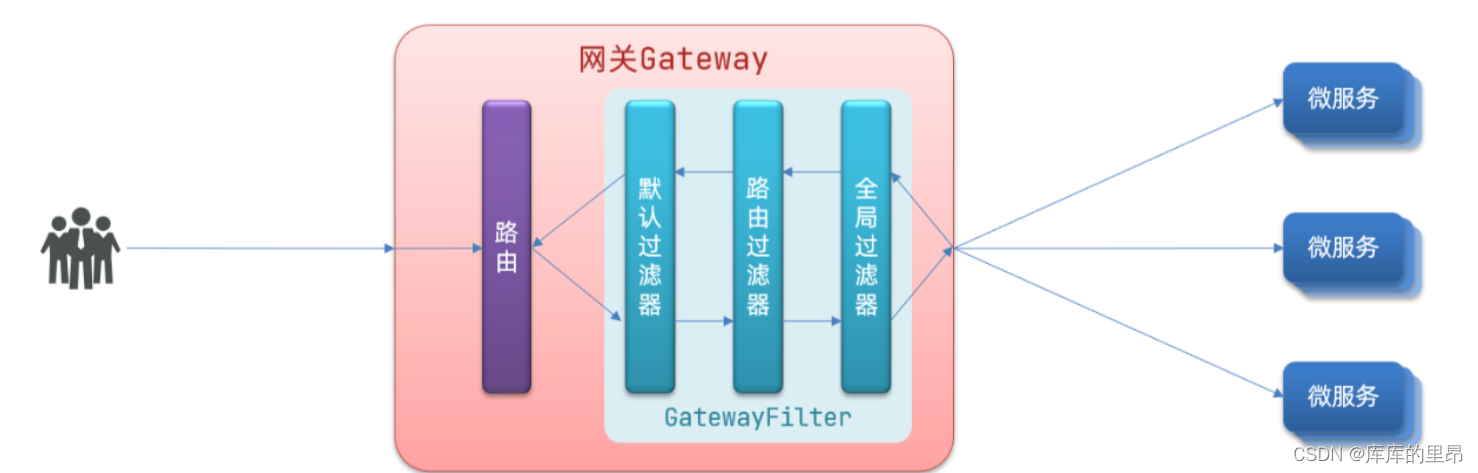
【云原生】Spring Cloud Alibaba 之 Gateway 服务网关实战开发
目录 一、什么是网关 ⛅网关的实现原理 二、Gateway 与 Zuul 的区别? 三、Gateway 服务网关 快速入门 ⛄需求 ⏳项目搭建 ✅启动测试 四、Gateway 断言工厂 五、Gateway 过滤器 ⛽过滤器工厂 ♨️全局过滤器 六、源码地址 ⛵小结 一、什么是网关 Spri…...
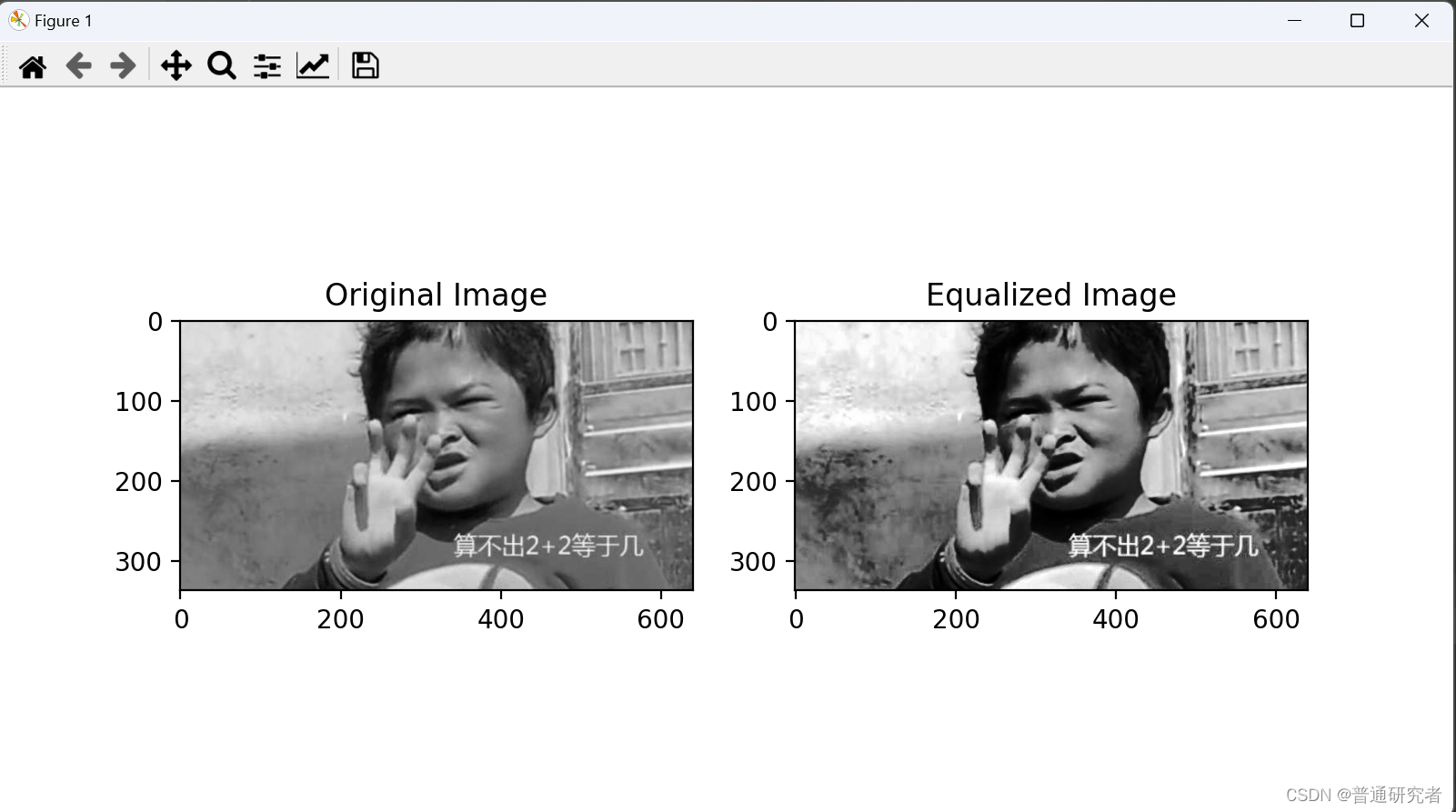
opencv-直方图均衡化
直方图均衡化是一种用于增强图像对比度的图像处理技术。它通过调整图像的灰度级别分布,使得图像中各个灰度级别的像素分布更均匀,从而提高图像的对比度。 在OpenCV中,你可以使用cv2.equalizeHist()函数来进行直方图均衡化。 以下是一个简单…...
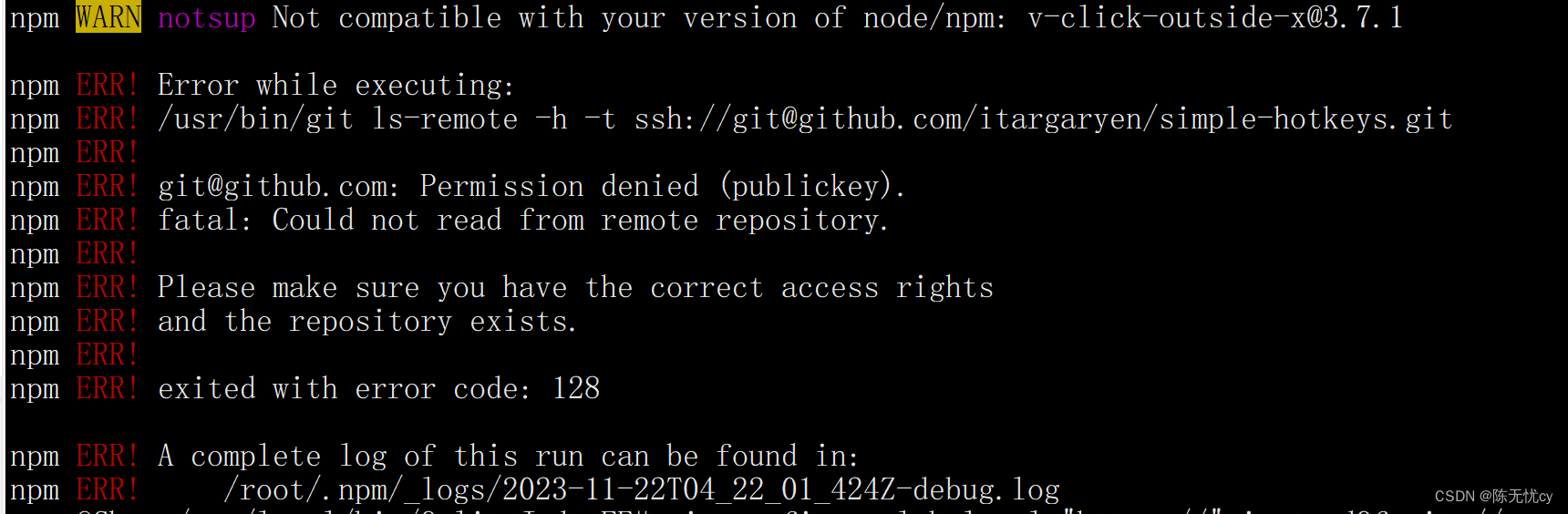
npm install安装报错
npm WARN notsup Not compatible with your version of node/npm: v-click-outside-x3.7.1 npm ERR! Error while executing: npm ERR! /usr/bin/git ls-remote -h -t ssh://gitgithub.com/itargaryen/simple-hotkeys.git 解决办法1:(没有解决我的问题…...
Spring Boot创建和使用(重要)
Spring的诞生是为了简化Java程序开发的! Spring Boot的诞生是为了简化Spring程序开发的! Spring Boot就是Spring框架的脚手架,为了快速开发Spring框架而诞生的!! Spring Boot的优点: 快速集成框架&#x…...

python 基于gdal,richdem,pysheds实现 实现洼填、D8流向,汇流累计量计算,河网连接,分水岭及其水文分析与斜坡单元生成
python gdal实现水文分析算法及其斜坡单元生成 实现洼填、D8流向,汇流累计量计算,河网连接,分水岭 # utf-8 import richdem as rdre from River import * from pysheds.grid import Grid import time from time import time,sleep import numpy as np from osgeo import g…...

帝国cms开发一个泛知识类的小程序的历程记录
#帝国cms小程序# 要开发一个泛知识类的小程序,要解决以下几个问题。 1。知识内容的分类。 2。知识内容的内容展示。 3。知识内容的价格设置。 4。用户体系,为简化用户的操作,在用户进行下载的时候,请用户输入手机号ÿ…...

Kafka官方生产者和消费者脚本简单使用
问题 怎样使用Kafka官方生产者和消费者脚本进行消费生产和消费?这里假设已经下载了kafka官方文件,并已经解压. 生产者配置文件 producer_hr.properties bootstrap.servers10.xx.xx.xxx:9092,10.xx.xx.xxx:9092,10.xx.xx.xxx:9092 compression.typenone security.protocolS…...

如何开发干洗店用的小程序
洗护行业现在都开始往线上的方向发展了,越来越多的干洗店都推出了上门取送服务,那么就需要开发一个干洗店专用的小程序去作为用户和商家的桥梁,这样的小程序该如何开发呢? 一、功能设计:根据干洗店的业务需求和小程序的…...

回溯算法详解
目录 什么是回溯? 回溯常用来解决什么问题? 回溯的效率如何? 回溯在面试中的考察频率 如何学好回溯? 回溯通用模板 什么是回溯? 回溯:你处理了之后,再进行”撤销“处理,”撤销…...

边云协同架构设计
文章目录 一. "边云协同"是什么?二. "边云协同"主要包括6种协同2.1 资源协同2.2 数据协同2.3 智能协同2.4 应用管理协同2.5 业务管理协同2.6 服务协同 三. "边云协同"的优势 其它相关推荐: 系统架构之微服务架构 系统架构…...

【c++】——类和对象(下) 万字解答疑惑
作者:chlorine 专栏:c专栏 目录 🚩再谈构造函数 🎓构造函数体赋值 🎓初始化列表 🚩explicit关键字 🚩static成员 🎓概念 面试题:计算创建多少个类对象 🎓特性 【问题】(非)…...

Appium自动化测试:通过appium的inspector功能无法启动app的原因
在打开appium-desktop程序,点击inspector功能,填写app的配置信息,启动服务提示如下: 报错信息: An unknown server-side error occurred while processing the command. Original error: Cannot start the cc.knowyo…...

易点易动设备管理系统:提升企业设备维修效率的工具
在现代企业运营中,设备的正常运行和及时维修至关重要。然而,传统的设备维修管理方法往往效率低下、易出错,给企业带来了不小的困扰。为了解决这一问题,易点易动设备管理系统应运而生。作为一款先进的智能化系统,易点易…...

JVM中判断对象是否需要回收的方法
在堆里面存放着Java 世界中几乎所有的对象实例,垃圾收集器在对堆进行回收前,第一件事情就是要确定这些对象之中哪些还“ 存活 ” 着,哪些已经 “ 死去 ”。 引用计数算法 引用计数法是一种内存管理技术,它是通过对每个对象进行引用…...

当电网遇上路网:如何用‘拥堵收费’和‘电价’引导用户行为?一个系统工程师的解读
电力与交通的协同博弈:用价格杠杆重塑城市能源流动 清晨七点半的都市高架桥上,电动汽车与燃油车混杂在早高峰的车流中,而几公里外的变电站正经历着用电负荷的陡升。这两个看似独立的系统——电网与路网——实际上正在上演一场精妙的双人舞。当…...

Chaplin:5分钟搭建本地唇语识别系统,让电脑读懂你的唇语
Chaplin:5分钟搭建本地唇语识别系统,让电脑读懂你的唇语 【免费下载链接】chaplin A real-time silent speech recognition tool. 项目地址: https://gitcode.com/gh_mirrors/chapl/chaplin 还在为嘈杂环境无法语音输入而烦恼?Chaplin…...

Windows网络协议终极指南:Impacket在红队攻防中的10个关键应用
Windows网络协议终极指南:Impacket在红队攻防中的10个关键应用 【免费下载链接】impacket Impacket is a collection of Python classes for working with network protocols. 项目地址: https://gitcode.com/gh_mirrors/im/impacket Impacket是一个专注于网…...

PKHeX自动化插件终极指南:5步打造完美合法宝可梦
PKHeX自动化插件终极指南:5步打造完美合法宝可梦 【免费下载链接】PKHeX-Plugins Plugins for PKHeX 项目地址: https://gitcode.com/gh_mirrors/pk/PKHeX-Plugins 还在为宝可梦数据合法性而烦恼吗?手动调整个体值、技能组合和特性配置不仅耗时耗…...

别再傻傻分不清了!一文搞懂FMEA、FTA、FMECA、FRACAS在项目里到底怎么用
工程实战指南:FMEA、FTA、FMECA、FRACAS四大工具的精准选择与协同应用 刚接手第一个可靠性工程项目时,面对满屏的FMEA、FTA缩写和同事口中频繁出现的FMECA、FRACAS,我一度陷入工具选择的迷茫。直到在一次产品召回事件后,才真正理解…...

对比直接使用厂商API体验Taotoken在密钥管理与审计上的便利
Taotoken 密钥管理与审计功能实践观察 1. 多厂商密钥管理的传统挑战 在接入多个大模型服务时,团队通常需要为每个厂商单独申请和管理 API Key。这种方式下,每个 Key 具有不同的权限范围、有效期和调用限制,管理员需要维护复杂的密钥清单。当…...
让散点图瞬间高级)
拯救你的图表审美:用Matplotlib内置色彩映射(cmap)让散点图瞬间高级
拯救你的图表审美:用Matplotlib内置色彩映射(cmap)让散点图瞬间高级 在科研论文、商业报告或数据分析项目中,一张精心设计的图表往往比千言万语更能清晰传达信息。然而,许多人在使用Matplotlib绘制散点图时,…...

视觉语言模型在具身导航中的评估与实践
1. 项目背景与核心价值在智能体与物理世界交互的研究中,具身导航(Embodied Navigation)一直是关键挑战。NaviTrace这个项目直指一个前沿问题:当前火热的视觉语言模型(VLMs),在实际导航任务中到底…...

UV展开技术:ABF++与LSCM算法对比与优化实践
1. UV展开技术背景与核心挑战UV展开作为三维模型纹理映射的基础环节,直接影响着后续贴图绘制的精度与效率。在游戏开发、影视动画等数字内容创作领域,艺术家们经常需要处理数百万面片的高模展开工作。传统展开方法在处理复杂拓扑结构时容易出现拉伸、重叠…...

如何快速提升云顶之弈水平:免费战术覆盖工具的终极指南
如何快速提升云顶之弈水平:免费战术覆盖工具的终极指南 【免费下载链接】TFT-Overlay Overlay for Teamfight Tactics 项目地址: https://gitcode.com/gh_mirrors/tf/TFT-Overlay 想象一下,在激烈的云顶之弈对局中,你不再需要频繁切换…...