【Python大数据笔记_day11_Hadoop进阶之MR和YARNZooKeeper】
MR
单词统计流程
已知文件内容: hadoop hive hadoop spark hive flink hive linux hive mysql input结果: k1(行偏移量) v1(每行文本内容)0 hadoop hive hadoop spark hive 30 flink hive linux hive mysql map结果:k2(split切割后的单词) v2(拼接1) hadoop 1hive 1hadoop 1spark 1hive 1flink 1hive 1linu 1hive 1mysql 1 分区/排序/规约/分组结果:k2(排序分组后的单词) v2(每个单词数量的集合)flink [1]hadoop [1,1]hive [1,1,1,1]linux [1] mysql [1]spark [1] reduce结果:k3(排序分组后的单词) v3(聚合后的单词数量)flink 1hadoop 2hive 4linux 1mysql 1spark 1 output结果: 注意: 输出目录一定不要存在,否则报错flink 1hadoop 2hive 4linux 1mysql 1spark 1
MR底层原理

map阶段
第一阶段是把输入目录下文件按照一定的标准逐个进行逻辑切片,形成切片规划。默认情况下Split size 等于 Block size。每一个切片由一个MapTask处理(当然也可以通过参数单独修改split大小) 第二阶段是对切片中的数据按照一定的规则解析成对。默认规则是把每一行文本内容解析成键值对。key是每一行的起始位置(单位是字节),value是本行的文本内容。(TextInputFormat) 第三阶段是调用Mapper类中的map方法。上阶段中每解析出来的一个,调用一次map方法。每次调用map方法会输出零个或多个键值对 第四阶段是按照一定的规则对第三阶段输出的键值对进行分区。默认是只有一个区。分区的数量就是Reducer任务运行的数量。默认只有一个Reducer任务 第五阶段是对每个分区中的键值对进行排序。首先,按照键进行排序,对于键相同的键值对,按照值进行排序。比如三个键值对<2,2>、<1,3>、<2,1>,键和值分别是整数。那么排序后的结果是<1,3>、<2,1>、<2,2>。 如果有第六阶段,那么进入第六阶段;如果没有,直接输出到文件中 第六阶段是对数据进行局部聚合处理,也就是combiner处理。键相等的键值对会调用一次reduce方法。经过这一阶段,数据量会减少。本阶段默认是没有的。 注意: 不要死记硬背,要结合自己的理解,转换为自己的话术,用于面试
shuffle阶段
shuffle是Mapreduce的核心,它分布在Mapreduce的map阶段和reduce阶段。一般把从Map产生输出开始到Reduce取得数据作为输入之前的过程称作shuffle。 Collect阶段:将MapTask的结果输出到默认大小为100M的环形缓冲区,保存的是key/value,Partition分区信息等 Spill阶段:当内存中的数据量达到一定的阀值(80%)的时候,就会将数据写入本地磁盘,在将数据写入磁盘之前需要对数据进行一次排序的操作,如果配置了combiner,还会将有相同分区号和key的数据进行排序 Merge阶段:把所有溢出的临时文件进行一次合并操作,以确保一个MapTask最终只产生一个中间数据文件 Copy阶段: ReduceTask启动Fetcher线程到已经完成MapTask的节点上复制一份属于自己的数据,这些数据默认会保存在内存的缓冲区中,当内存的缓冲区达到一定的阀值的时候,就会将数据写到磁盘之上 Merge阶段:在ReduceTask远程复制数据的同时,会在后台开启两个线程对内存到本地的数据文件进行合并操作。 Sort阶段:在对数据进行合并的同时,会进行排序操作,由于MapTask阶段已经对数据进行了局部的排序,ReduceTask只需保证Copy的数据的最终整体有效性即可。 注意: 不要死记硬背,要结合自己的理解,转换为自己的话术,用于面试
reduce阶段
第一阶段是Reducer任务会主动从Mapper任务复制其输出的键值对。Mapper任务可能会有很多,因此Reducer会复制多个Mapper的输出。 第二阶段是把复制到Reducer本地数据,全部进行合并,即把分散的数据合并成一个大的数据。再对合并后的数据排序。 第三阶段是对排序后的键值对调用reduce方法。键相等的键值对调用一次reduce方法,每次调用会产生零个或者多个键值对。最后把这些输出的键值对写入到HDFS文件中。 注意: 不要死记硬背,要结合自己的理解,转换为自己的话术,用于面试
YARN
yarn提交mr流程

1.客户端提交一个MR程序给ResourceManager(校验请求是否合法...) 2.如果请求合法,ResourceManager随机选择一个NodeManager用于生成appmaster(应用程序控制者,每个应用程序都单独有一个appmaster) 3.appmaster会主动向ResourceManager的应用管理器(application manager)注册自己,告知自己的状态信息,并且保持心跳 4.appmaster会根据任务情况计算自己所需要的container资源(cpu,内存...),主动向ResourceManager的资源调度器(resource scheduler)申请并获取这些container资源 5.appmaster获取到container资源后,把对应指令和container分发给其他NodeManager,让NodeManager启动task任务(maptask任务,reducetask任务) 6.NodeManager要和appmaster保持心跳,把自己任务计算进度和状态信息等同步给appmaster,(注意当maptask任务完成后会通知appmaster,appmaster接到消息后会通知reducetask去maptask那儿拉取数据)直到最后任务完成 7.appmaster会主动向ResourceManager注销自己(告知ResourceManager可以把自己的资源进行回收了,回收后自己就销毁了)
调度器
调度器的配置在yarn-site.xml查找,如果没有就去yarn-default.xml中找 网址: https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-common/yarn-default.xml 配置项和默认值如下yarn.resourcemanager.scheduler.class=org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
先进先出调度器

FIFO Scheduler: 把应用按提交的顺序排成一个队列,在进行资源分配的时候,先给队列中最头上的应用进行分配资源,待最头上的应用需求满足后再给下一个分配,以此类推。 好处: 能够保证每一个任务都能拿到充足的资源, 对于大任务的运行非常有好处 弊端: 如果先有大任务后有小任务,会导致后续小任务无资源可用, 长期处于等待状态 应用: 测试环境
公平调度器

Fair Scheduler :不需要保留集群的资源,因为它会动态在所有正在运行的作业之间平衡资源 , 当一个大job提交时,只有这一个job在运行,此时它获得了所有集群资源;当后面有小任务提交后,Fair调度器会分配一半资源给这个小任务,让这两个任务公平的共享集群资源。 好处: 保证每个任务都有资源可用, 不会有大量的任务等待在资源分配上 弊端: 如果大任务非常的多, 就会导致每个任务获取资源都非常的有限, 也会导致执行时间会拉长 应用: CDH商业版本的hadoop
容量调度器
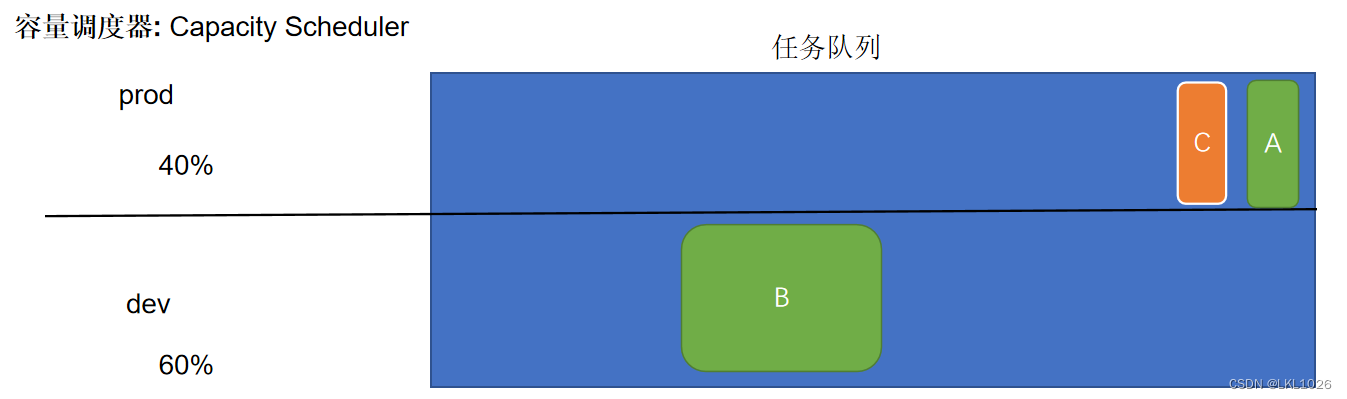
Capacity Scheduler: 为每个组织分配专门的队列和一定的集群资源,这样整个集群就可以通过设置多个队列的方式给多个组织提供服务了。在每个队列内部,资源的调度是采用的是先进先出(FIFO)策略。 好处: 可以保证多个任务都可以使用一定的资源, 提升资源的利用率 弊端: 如果遇到非常的大的任务, 此任务不管运行在那个队列中, 都无法使用到集群中所有的资源, 导致大任务执行效率比较低,当任务比较繁忙的时候, 依然会出现等待状态 应用: apache开源版本的hadoop
示例:
调度器的使用是通过yarn-site.xml配置文件中的 yarn.resourcemanager.scheduler.class参数进行配置的,默认采用Capacity Scheduler调度器 下面是一个简单的Capacity调度器的配置文件,文件名为capacity-scheduler.xml。

在这个配置中,在root队列下面定义了两个子队列prod和dev,分别占40%和60%的容量
<property><!-- 队列分为两份 prod 和 dev --><name>yarn.scheduler.capacity.root.queues</name><value>prod,dev</value> </property><property><!--prod占比 40%--><name>yarn.scheduler.capacity.root.prod.capacity</name><value>40</value> </property> <property><!--dev占比 60%--><name>yarn.scheduler.capacity.root.dev.capacity</name><value>60</value> </property> <property><!-- dev的最大占比 75%--><name>yarn.scheduler.capacity.root.dev.maximum-capacity</name><value>75</value> </property>prod由于没有设置maximum-capacity属性,它有可能会占用集群全部资源。 dev的maximum-capacity属性被设置成了75%,所以即使prod队列完全空闲dev也不会占用全部集群资源,也就是说,prod队列仍有25%的可用资源用来应急。
ZooKeeper
ZK概述
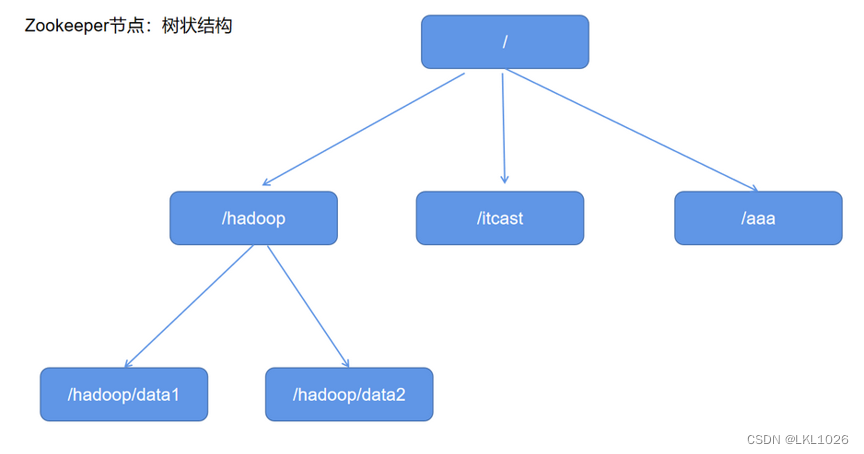
ZooKeeper概念: Zookeeper是一个分布式协调服务的开源框架。本质上是一个分布式的小文件存储系统 ZooKeeper作用: 主要用来解决分布式集群中应用系统的一致性问题。 ZooKeeper结构: 采用树形层次结构,ZooKeeper树中的每个节点被称为—Znode。且树中的每个节点可以拥有子节点
ZK集群环境
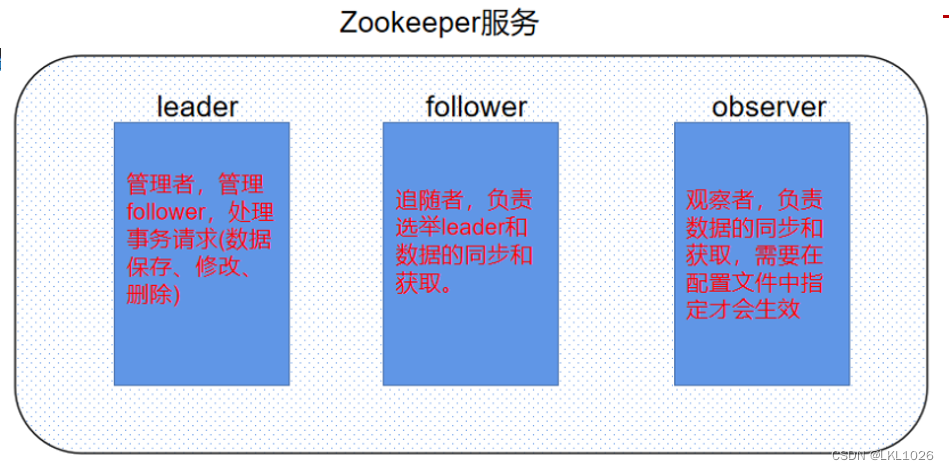
zookeeper概念: 分布式协调服务 zookeeper的服务角色分别为:leader: 管理者 ,负责管理follower,处理所有的事务请求(数据的保存,修改,删除)follower: 追随者,负责选举(选举leader)和数据的同步及获取observer: 观察者,负责数据的同步及获取(需要在配置文件中指定才能生效)zookeeper应用: 搭建hadoop高可用环境时,至少需要两个hadoop服务(NameNode和ResourceManager),一主一备,主服务对外提供业务功能,备用服务等待主服务不可用时,启用备用服务器对外提供业务功能
ZK启动和使用
配置环境变量
配置zookeeper环境变量(注意三台都单独配置!!!)
可以使用CRT客户端发送以下命令到三台
[root@nodex ~]# echo 'export ZOOKEEPER_HOME=/export/server/zookeeper' >> /etc/profile [root@nodex ~]# echo 'export PATH=$PATH:$ZOOKEEPER_HOME/bin' >> /etc/profile [root@nodex ~]# source /etc/profile
启动集群
启动zookeeper服务(注意三台都单独需要启动!!!)
可以使用CRT客户端发送以下命令到三台
[root@nodex ~]# zkServer.sh start还可以查看服务状态: [root@node]# zkServer.sh status
关闭zk服务的命令是: [root@node]# zkServer.sh stop
客户端连接
连接服务
方式1:直接连接本地: [root@node1 ~]# zkCli.sh
方式2:连接其他节点: [root@node1 ~]# zkCli.sh -server 节点地址
[root@node1 ~]# zkCli.shZK的shell命令
查看所有shell命令: help create [-s] [-e] 节点绝对路径 节点数据: 创建数据节点 注意: -s代表序列化节点 -e代表临时节点 delete 节点绝对路径 [version]: 删除一级节点 注意: 此方式如果有子节点是不能删除的 rmr 节点绝对路径: 删多层除节点(如果有子节点也可以删除) set 节点绝对路径 data [version]: 设置 /修改节点数据 get 节点绝对路径 [watch]: 获取数据 注意: watch是监听 ls 节点绝对路径 : 查看节点信息 举例: 查看根路径下节点 ls / ls2 节点绝对路径 : 查看节点详情信息 history: 查看操作历史 quit: 退出
[root@node1 ~]# zkCli.sh
...
WatchedEvent state:SyncConnected type:None path:null
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper]
[zk: localhost:2181(CONNECTED) 1] create /binzi 666
Created /binzi
[zk: localhost:2181(CONNECTED) 2] create /binzi/b1 111
Created /binzi/b1
[zk: localhost:2181(CONNECTED) 3] create /binzi/b2 222
Created /binzi/b2
[zk: localhost:2181(CONNECTED) 4] ls /
[binzi, zookeeper]
[zk: localhost:2181(CONNECTED) 5] ls /binzi
[b2, b1]
[zk: localhost:2181(CONNECTED) 6] set /binzi 888
...
[zk: localhost:2181(CONNECTED) 7] get /binzi
888
...
[zk: localhost:2181(CONNECTED) 8] delete /binzi/b1
[zk: localhost:2181(CONNECTED) 9] ls /binzi
[b2]
# 注意: delete不能删除有子节点的节点
[zk: localhost:2181(CONNECTED) 10] delete /binzi
Node not empty: /binzi
# rmr可以删除多层节点
[zk: localhost:2181(CONNECTED) 11] rmr /binzi
[zk: localhost:2181(CONNECTED) 12] ls /
[zookeeper]
[zk: localhost:2181(CONNECTED) 13] history
...
[zk: localhost:2181(CONNECTED) 14] quit
Quitting...shut down
[root@node1 ~]# ZK的节点特性和分类
节点特性
ZooKeeper的数据模型,在结构上和标准文件系统的非常相似,都是采用树形层次结构,和文件系统的目录树一样,ZooKeeper树中的每个节点可以拥有子节点。 但也有不同之处: Znode兼具文件和目录两种特点: Znode没有文件和目录之分,Znode既有像文件一样存储数据,也能像目录一样作为路径标识的一部分 Znode具有原子性操作: 读操作将获取与节点相关的所有数据,写操作也将替换掉节点的所有数据 Znode存储数据大小有限制: 每个Znode的数据大小至多1M,当时常规使用中应该远小于此值 Znode通过路径引用: 路径必须是绝对的,因此他们必须由斜杠字符来开头。除此以外,他们必须是唯一的,也就是说每一个路径只有一个表示,因此这些路径不能改变。 默认有/zookeeper节点用以保存关键的管理信息。
节点分类
节点分类: 永久普通节点,临时普通节点,永久序列化节点,临时序列化节点创建永久普通节点: create /节点 数据创建临时普通节点: create -e /节点 数据创建永久序列化节点: create -s /节点 数据创建临时序列化节点: create -e -s /节点 数据注意: 临时节点不能创建子节点
节点属性
每个znode都包含了一系列的属性,通过命令get /节点,可以获得节点的属性 注意: 对于zk来说,每次的变化都会产生一个唯一的事务id,zxid(ZooKeeper Transaction Id)。通过zxid,可以确定更新操作的先后顺序。例如,如果zxid1小于zxid2,说明zxid1操作先于zxid2发生,zxid对于整个zk都是唯一的,即使操作的是不同的znode。 cZxid :Znode创建的事务id。 ctime :Znode创建时的时间戳.
mZxid :Znode被修改的事务id,即每次对当前znode的修改都会更新mZxid。 mtime :Znode最新一次更新发生时的时间戳.
pZxid :Znode的子节点列表变更的事务ID,添加子节点或删除子节点就会影响子节点列表 cversion :子节点进行变更的版本号。添加子节点或删除子节点就会影响子节点版本号
dataVersion:数据版本号,每次对节点进行set操作,dataVersion的值都会增加1(即使设置的是相同的数据),可有效避免了 数据更新时出现的先后顺序问题。 aclVersion : 权限变化列表版本 access control list Version ephemeralOwner : 字面翻译临时节点拥有者,永久节点值为: 0x0,临时节点值为:会话ID (不是0x0的就是临时节点) dataLength : Znode数据长度 numChildren: 当前Znode子节点数量(不包括子子节点)
ZK集群特点
1. 全局数据一致: 集群中每个服务器保存一份相同的数据副本,client无论连接到哪个服务器,展示的数据都是一致的,这是最重要的特征;2. 可靠性: 如果消息被其中一台服务器接受,那么将被所有的服务器接受。3. 顺序性: 包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息a在消息b前发布,则在所有Server上消息a都将在消息b前被发布;偏序是指如果一个消息b在消息a后被同一个发送者发布,a必将排在b前面。4. 数据更新原子性: 一次数据更新要么成功(半数以上节点成功),要么失败,不存在中间状态;5. 实时性: Zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。
watch监听机制
ZooKeeper中,引入了Watcher机制来实现数据发布/订阅功能,一个典型的发布/订阅模型系统定义了一种一对多的订阅关系,能让多个订阅者同时监听某一个主题对象,当这个主题对象自身状态变化时,会通知所有订阅者,使他们能够做出相应的处理。 ZooKeeper允许客户端向服务端注册一个Watcher监听,当服务端的一些事件触发了这个Watcher,那么就会向指定客户端发送一个事件通知来实现分布式的通知功能。
watch监听机制过程: 客户端向服务端注册Watcher 服务端事件发生触发Watcher 客户端回调Watcher得到触发事件情况 Watch监听机制注册格式: get /节点绝对路径 watch Watch监听机制特点:先注册再触发: Zookeeper中的watch机制,必须客户端先去服务端注册监听,这样事件发送才会触发监听,通知给客户端一次性触发: 事件发生触发监听,一个watcher event就会被发送到设置监听的客户端,这种效果是一次性的,后续再次发生同样的事件,不会再次触发。异步发送: watcher的通知事件从服务端发送到客户端是异步的。通知内容: 通知状态(keeperState),事件类型(EventType)和节点路径(path)
示例
node1上创建临时节点
[zk: localhost:2181(CONNECTED) 1] create -e /master 1111
Created /masternode2上设置监听
[zk: localhost:2181(CONNECTED) 28] get /master watchnode1退出
[zk: localhost:2181(CONNECTED) 2] quitnode2查看消息
[zk: localhost:2181(CONNECTED) 29]
WATCHER::WatchedEvent state:SyncConnected type:NodeDeleted path:/masterZK应用
1. 数据发布/订阅数据发布/订阅系统,就是发布者将数据发布到ZooKeeper的一个节点上,提供订阅者进行数据订阅,从而实现动态更新数据的目的,实现配置信息的集中式管理和数据的动态更新。主要用到知识点: 监听机制2. 提供集群选举在分布式环境下,不管是主从架构集群,还是主备架构集群,要求在服务的时候有且有一个正常的对外提供服务,我们称之为master。 当master出现故障之后,需要重新选举出的新的master。保证服务的连续可用性。zookeeper可以提供这样的功能服务。 主要用到知识点: znode唯一性、临时节点短暂性、监听机制。选举概述: 选举要求: 过半原则,所以搭建集群一般奇数,只要某个node节点票数过半立刻成为leader集群第一次启动: 启动follower每次投票后,他们会相互同步投票情况,如果票数相同,谁的myid大,谁就当选leader,一旦确定了leader,后面来的默认就是follower,即使它的myid大,leader也不会改变(除非leader宕机了)leader宕机后启动: 每一个leader当老大的时候,都会产生新纪元epoch,且每次操作完节点数据都会更新事务id(高32位_低32位) ,当leader宕机后,剩下的follower就会综合考虑几个因素选出最新的leader,先比较最后一次更新数据事务id(高32位_低32位),谁的事务id最大,谁就当选leader,如果更新数据的事务id都相同的情况下,就需要再次考虑myid,谁的myid大,谁就当选leader
hadoop高可用(主备切换)
概述
hadoop2.x之后,Cloudera提出了QJM/Qurom Journal Manager,这是一个基于Paxos算法(分布式一致性算法)实现的HDFS HA方案,它给出了一种较好的解决思路和方案,QJM主要优势如下:不需要配置额外的高共享存储,降低了复杂度和维护成本。消除spof(单点故障)。系统鲁棒性(Robust)的程度可配置、可扩展。
在HA架构里面SecondaryNameNode已经不存在了,为了保持standby NN, 实时的与Active NN的元数据保持一致,他们之间交互通过JournalNode进行操作同步。
任何修改操作在 Active NN上执行时,JournalNode进程同时也会记录修改log到至少半数以上的JN中,这时 Standby NN 监测到JN 里面的同步log发生变化了会读取 JN 里面的修改log,然后同步到自己的目录镜像文件里面
当发生故障时,Active的 NN 挂掉后,Standby NN 会在它成为Active NN 前,读取所有的JN里面的修改日志,这样就能高可靠的保证与挂掉的NN的目录镜像文件一致,然后无缝的接替它的职责,维护来自客户端请求,从而达到一个高可用的目的。
在HA模式下,datanode需要确保同一时间有且只有一个NN能命令DN。为此:每个NN改变状态的时候,向DN发送自己的状态和一个序列号。
DN在运行过程中维护此序列号,当failover时,新的NN在返回DN心跳时会返回自己的active状态和一个更大的序列号。DN接收到这个返回则认为该NN为新的active。
如果这时原来的active NN恢复,返回给DN的心跳信息包含active状态和原来的序列号,这时DN就会拒绝这个NN的命令。
Failover Controller HA模式下,会将FailoverController部署在每个NameNode的节点上,作为一个单独的进程用来监视NN的健康状态。
FailoverController主要包括三个组件: HealthMonitor: 监控NameNode是否处于unavailable或unhealthy状态。当前通过RPC调用NN相应的方法完成。
ActiveStandbyElector: 监控NN在ZK中的状态。
ZKFailoverController: 订阅HealthMonitor 和ActiveStandbyElector 的事件,并管理NN的状态,另外zkfc还 负责解决fencing(也就是脑裂问题)。
JournalNode进程作用: 任何修改操作在 Active NN上执行时,JournalNode进程同时也会记录修改log到至少半数以上的JN中,这时 Standby NN 监测到JN 里面的同步log发生变化了会读取 JN 里面的修改log,然后同步到自己的目录镜像文件里面DFSZKFailoverController进程作用: 1. 健康监测:周期性的向它监控的NN发送健康探测命令,从而来确定某个NameNode是否处于健康状态,如果机器宕机,心跳失败,那么zkfc就会标记它处于一个不健康的状态2.会话管理:如果NN是健康的,zkfc就会在zookeeper中保持一个打开的会话,如果NameNode同时还是Active状态的,那么zkfc还会在Zookeeper中占有一个类型为短暂类型的znode,当这个NN挂掉时,这个znode将会被删除,然后备用的NN将会得到这把锁,升级为主NN,同时标记状态为Active3.master选举:通过在zookeeper中维持一个短暂类型的znode,来实现抢占式的锁机制,从而判断那个NameNode为Active状态4.当宕机的NN新启动时,它会再次注册zookeper,发现已经有znode锁了,便会自动变为Standby状态,如此往复循环,保证高可靠

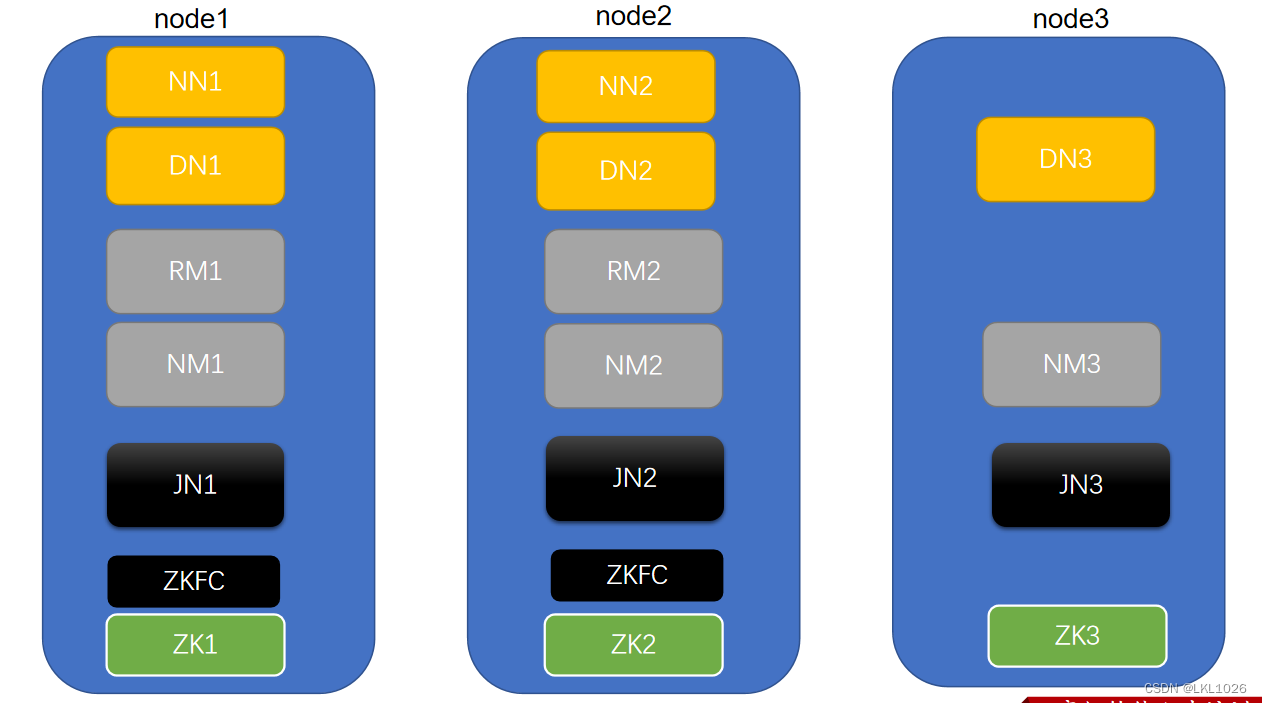
高可用服务
NN: NameNode DN: DataNodeRM: ResourceManager NM: NodeManagerJN: JournalNode ZK: ZooKeeper ZKFC: DFSZKFailoverController
启动hadoop高可用环境
# 1.先恢复快照到高可用环境# 2.三台服务器启动zookeeper服务
[root@node1 ~]# zkServer.sh start
[root@node2 ~]# zkServer.sh start
[root@node3 ~]# zkServer.sh start# 3.在node1中启动hadoop集群
[root@node1 ~]# start-all.sh# 4.检查服务
[root@node1 ~]# jps
[root@node2 ~]# jps
[root@node3 ~]# jps
NameNode高可用:
web链接:
node1:50070
node2:50070
可以使用==kill -9 NN进程号==把其中主服务杀掉,观察效果,然后使用 ==hdfs --daemon start namenode== 重启,再次观察效果


active: namenode主服务 standby: namenode备份服务
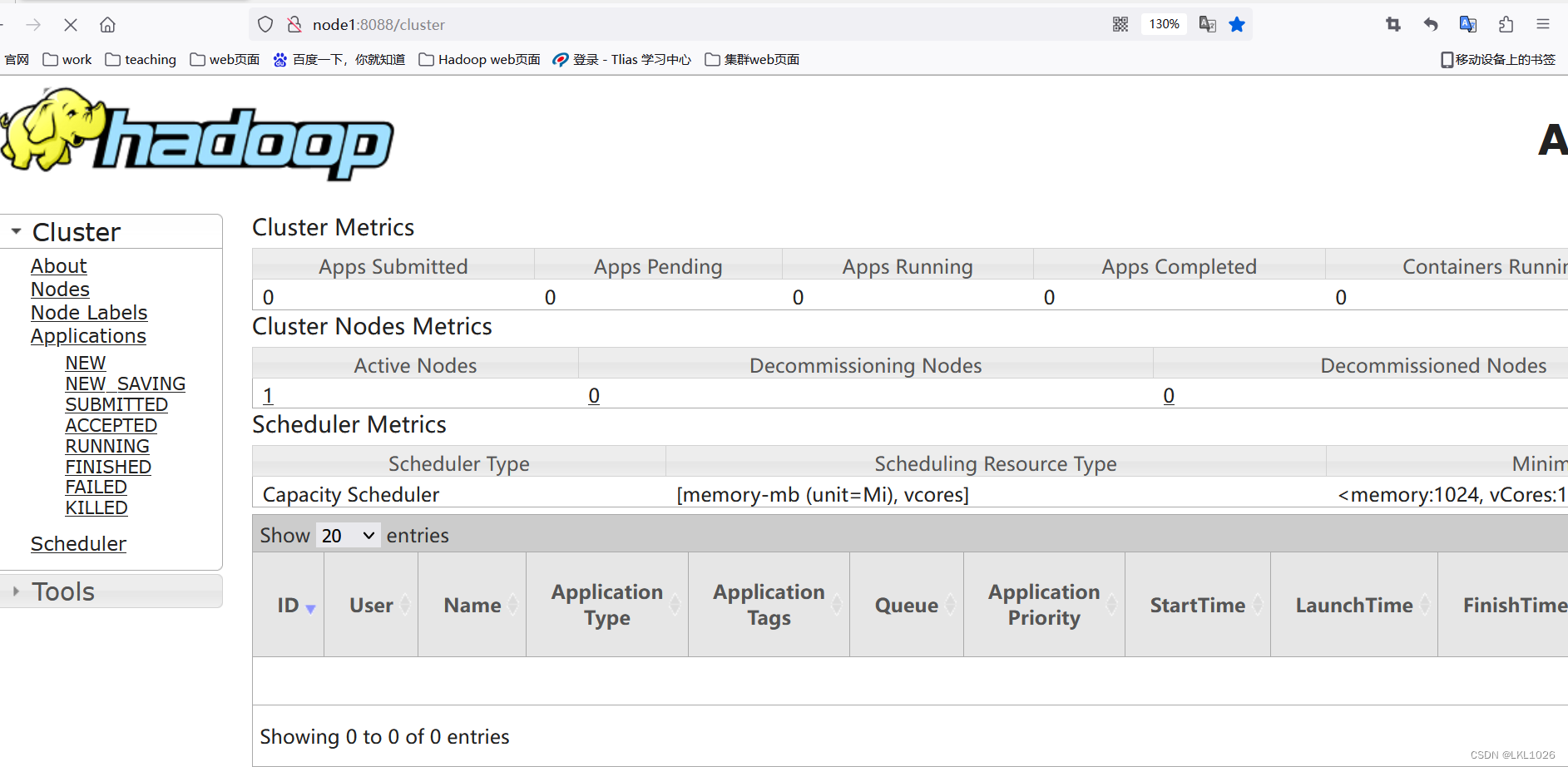
ResourceManager高可用
web链接:
node1:8088
node2:8088
可以使用==kill -9 RM进程号==把其中主服务杀掉,观察效果,然后使用 ==yarn --daemon start resourcemanager== 重启,再次观察效果
注意: 两个服务同时启动,按照上述链接去访问会自动跳到同一个主节点页面
相关文章:
【Python大数据笔记_day11_Hadoop进阶之MR和YARNZooKeeper】
MR 单词统计流程 已知文件内容: hadoop hive hadoop spark hive flink hive linux hive mysql input结果: k1(行偏移量) v1(每行文本内容)0 hadoop hive hadoop spark hive 30 flink hive linux hive mysql map结果:k2(split切割后的单词) v2(拼接…...

飞桨——总结PPOCRLabel中遇到的坑
操作系统:win10 python环境:python3.9 paddleocr项目版本:2.7 1.报错:ModuleNotFoundError: No module named Polygon(已解决) 已解决所以没有复现报错内容 尝试方法一:直接使用pip命令安装&…...

LeetCode(30)长度最小的子数组【滑动窗口】【中等】
目录 1.题目2.答案3.提交结果截图 链接: 长度最小的子数组 1.题目 给定一个含有 n 个正整数的数组和一个正整数 target 。 找出该数组中满足其总和大于等于 target 的长度最小的 连续子数组 [numsl, numsl1, ..., numsr-1, numsr] ,并返回其长度。如果…...
Niushop 开源商城 v5.1.7:支持PC、手机、小程序和APP多端电商的源码
Niushop 系统是一款基于 ThinkPHP6 开发的电商系统,提供了丰富的功能和完善的商品机制。该系统支持普通商品和虚拟商品,并且针对虚拟商品还提供了完善的核销机制。同时,它也支持新时代的商业模式,如拼团、分销和多门店砍价等营销活…...
Navmesh 寻路
用cocos2dx引擎简单实现了一下navmesh的多边形划分,然后基于划分多边形的a*寻路。以及路径拐点优化算法 用cocos主要是方便使用一些渲染接口和定时器。重点是实现的原理。 首先画了一个带有孔洞的多边形 //多边形的顶点数据Vec2(100, 100),Vec2(300, 200),Vec2(50…...

YOLOv5 分类模型 数据集加载 3
YOLOv5 分类模型 数据集加载 3 自定义类别 flyfish YOLOv5 分类模型 数据集加载 1 样本处理 YOLOv5 分类模型 数据集加载 2 切片处理 YOLOv5 分类模型的预处理(1) Resize 和 CenterCrop YOLOv5 分类模型的预处理(2)ToTensor 和 …...

『亚马逊云科技产品测评』活动征文|AWS 存储产品类别及其适用场景详细说明
授权声明:本篇文章授权活动官方亚马逊云科技文章转发、改写权,包括不限于在 Developer Centre, 知乎,自媒体平台,第三方开发者媒体等亚马逊云科技官方渠道 目录 前言、AWS 存储产品类别 1、Amazon Elastic Block Store (EBS) …...
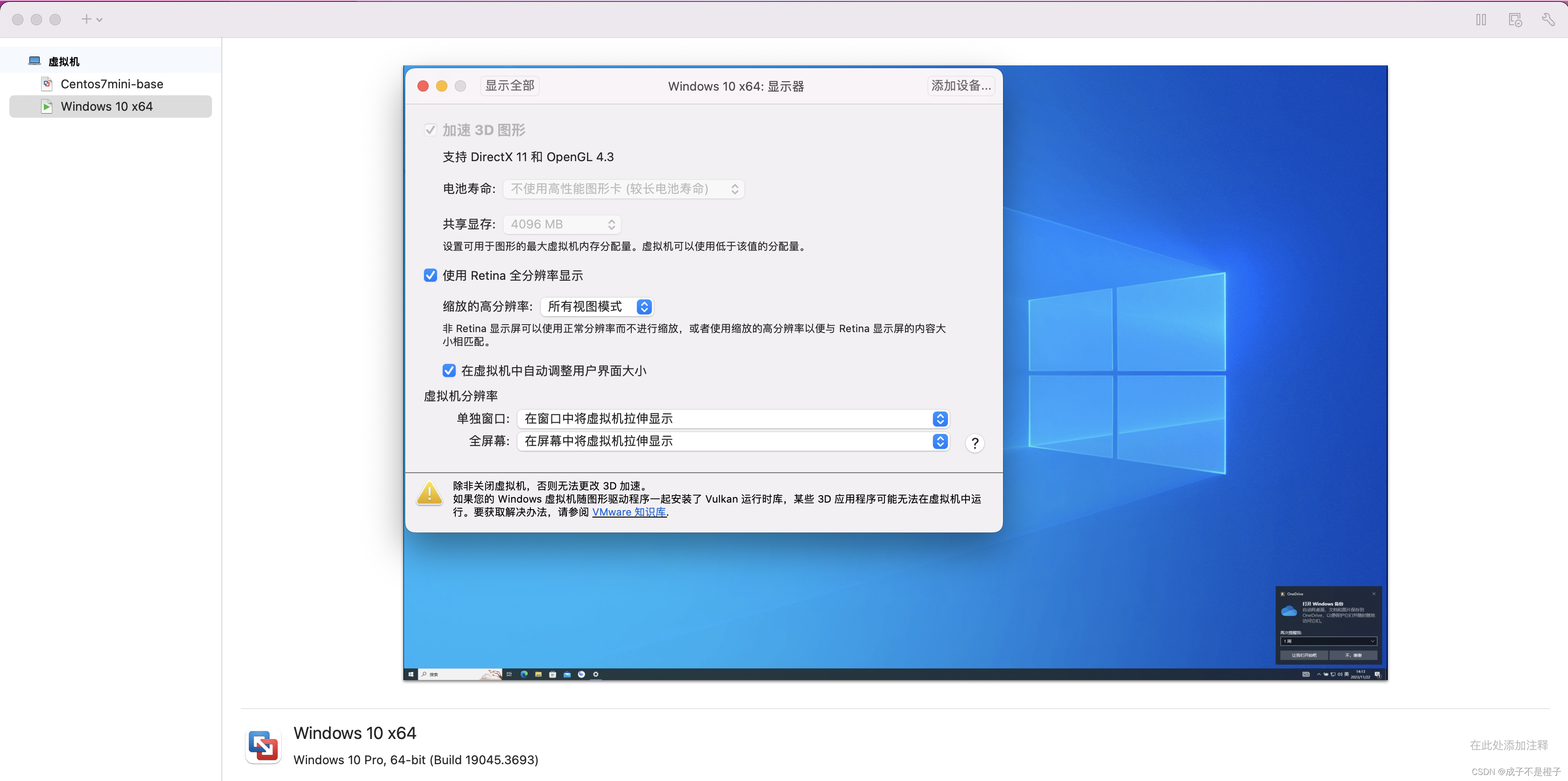
Mac | Vmware Fusion | 分辨率自动还原问题解决
1. 问题 Mac的Vmware Fusion在使用Windows10虚拟机时,默认显示器配置如下: 开机进入系统并变更默认分辨率后,只要被 ⌘Tab 切换分辨率就会还原到默认,非常影响体验。 2. 解决方式 调整 设置 -> 显示器 -> 虚拟机分辨率…...

SQL知多少?这篇文章让你从小白到入门
个人网站 本文首发公众号小肖学数据分析 SQL(Structured Query Language)是一种用于管理和处理关系型数据库的编程语言。 对于想要成为数据分析师、数据库管理员或者Web开发人员的小白来说,学习SQL是一个很好的起点。 本文将为你提供一个…...

centos7安装MySQL—以MySQL5.7.30为例
centos7安装MySQL—以MySQL5.7.30为例 本文以MySQL5.7.30为例。 官网下载 进入MySQL官网:https://www.mysql.com/ 点击DOWNLOADS 点击链接; 点击如上链接: 选择对应版本: 点击下载。 安装 将下载后的安装包上传到/usr/local下…...

3.计算机网络补充
2.5 HTTPS 数字签名:发送端将消息使⽤ hash 函数⽣成摘要,并使⽤私钥加密后得到“数字签名”,并将其附在消息之后。接收端使⽤公钥对“数字签名”解密,确认发送端身份,之后对消息使⽤ hash 函数处理并与接收到的摘要对…...
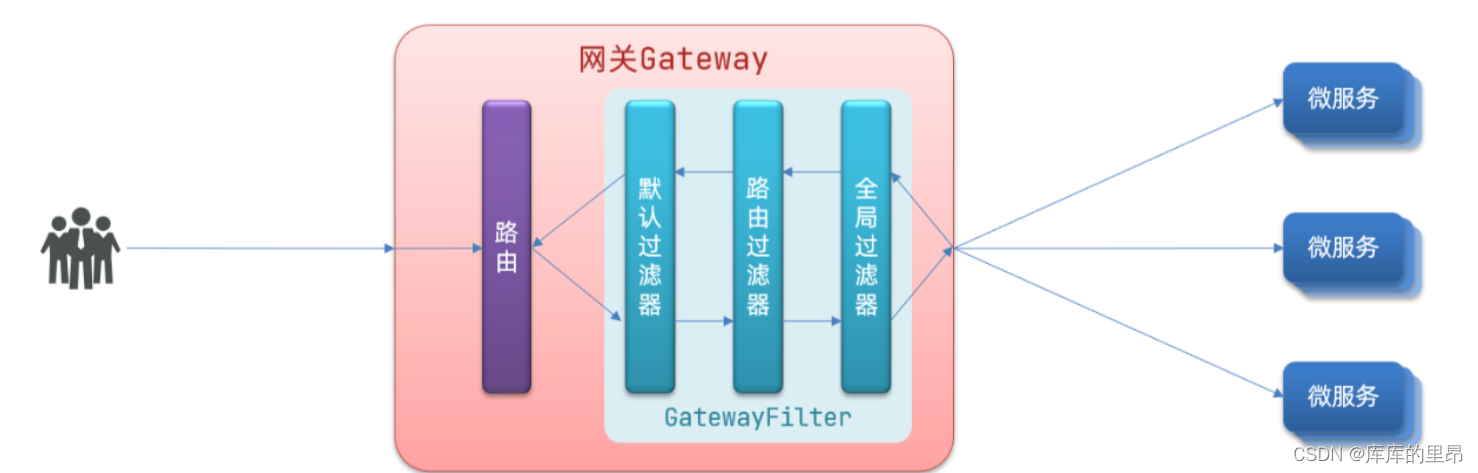
【云原生】Spring Cloud Alibaba 之 Gateway 服务网关实战开发
目录 一、什么是网关 ⛅网关的实现原理 二、Gateway 与 Zuul 的区别? 三、Gateway 服务网关 快速入门 ⛄需求 ⏳项目搭建 ✅启动测试 四、Gateway 断言工厂 五、Gateway 过滤器 ⛽过滤器工厂 ♨️全局过滤器 六、源码地址 ⛵小结 一、什么是网关 Spri…...
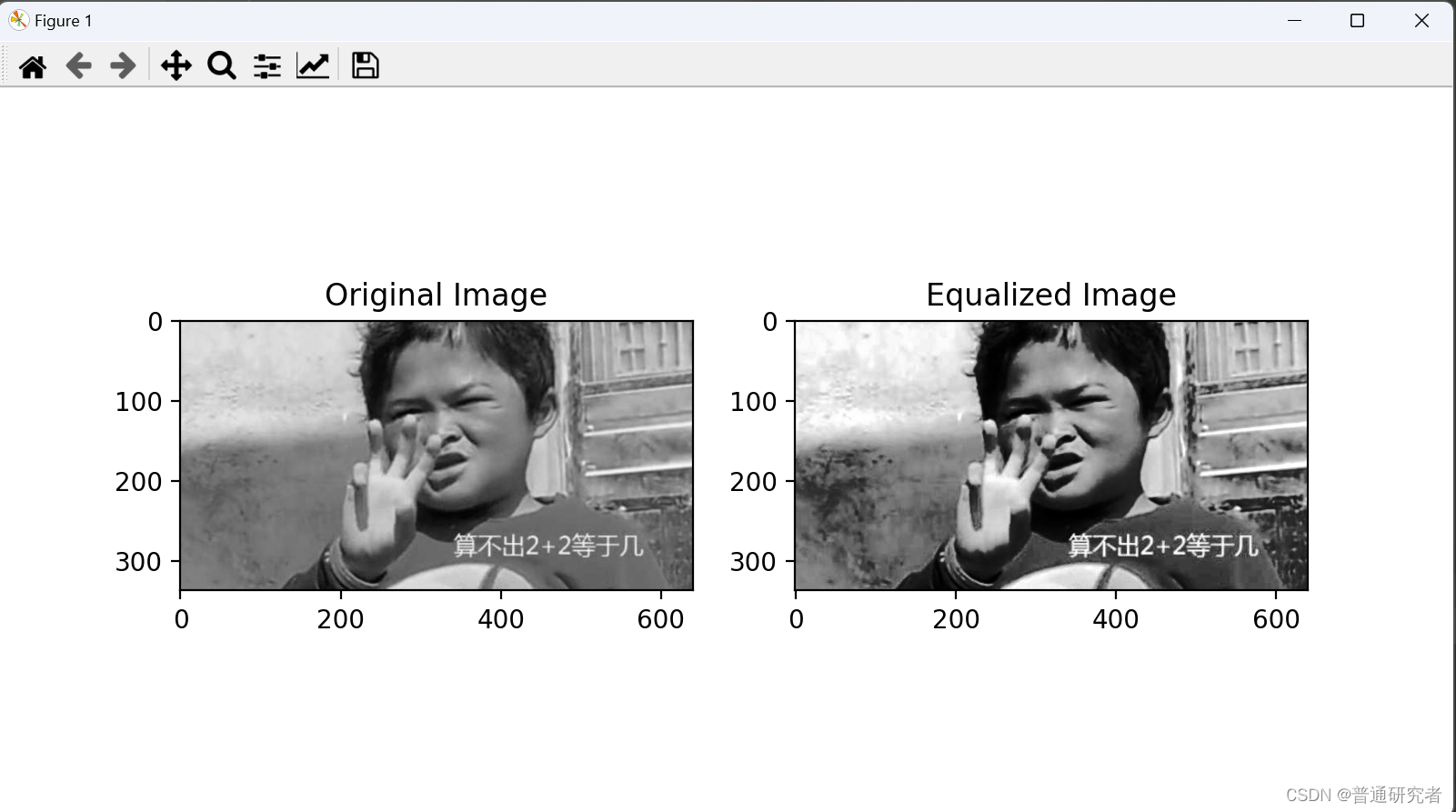
opencv-直方图均衡化
直方图均衡化是一种用于增强图像对比度的图像处理技术。它通过调整图像的灰度级别分布,使得图像中各个灰度级别的像素分布更均匀,从而提高图像的对比度。 在OpenCV中,你可以使用cv2.equalizeHist()函数来进行直方图均衡化。 以下是一个简单…...
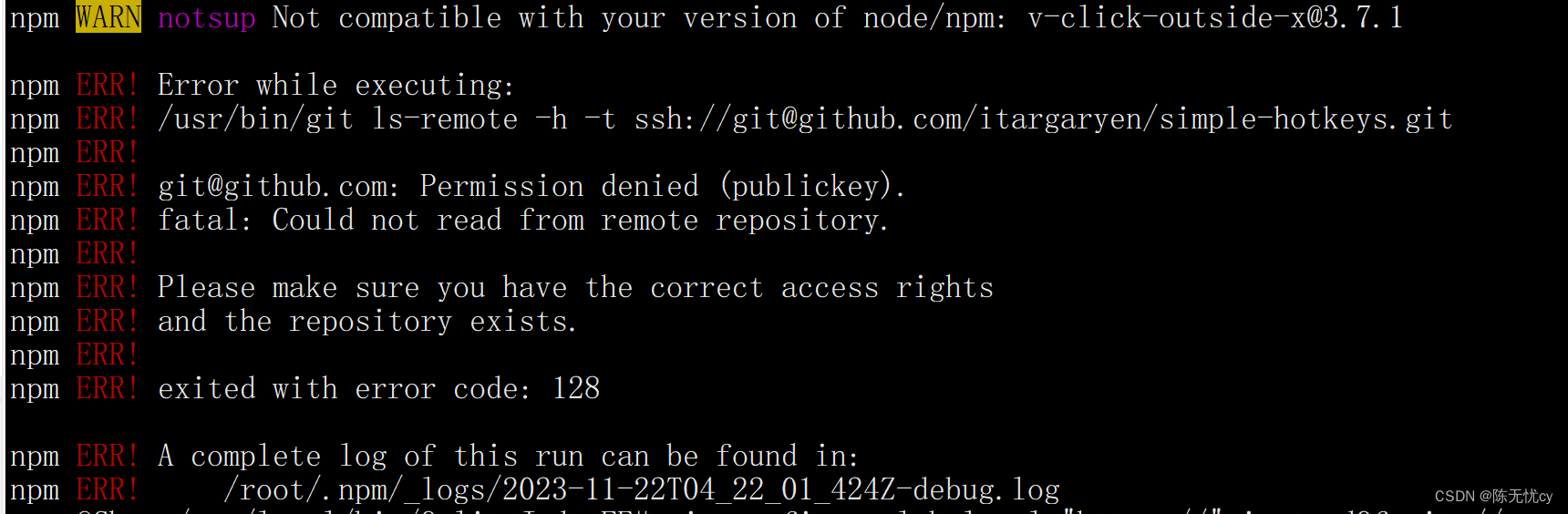
npm install安装报错
npm WARN notsup Not compatible with your version of node/npm: v-click-outside-x3.7.1 npm ERR! Error while executing: npm ERR! /usr/bin/git ls-remote -h -t ssh://gitgithub.com/itargaryen/simple-hotkeys.git 解决办法1:(没有解决我的问题…...
Spring Boot创建和使用(重要)
Spring的诞生是为了简化Java程序开发的! Spring Boot的诞生是为了简化Spring程序开发的! Spring Boot就是Spring框架的脚手架,为了快速开发Spring框架而诞生的!! Spring Boot的优点: 快速集成框架&#x…...

python 基于gdal,richdem,pysheds实现 实现洼填、D8流向,汇流累计量计算,河网连接,分水岭及其水文分析与斜坡单元生成
python gdal实现水文分析算法及其斜坡单元生成 实现洼填、D8流向,汇流累计量计算,河网连接,分水岭 # utf-8 import richdem as rdre from River import * from pysheds.grid import Grid import time from time import time,sleep import numpy as np from osgeo import g…...

帝国cms开发一个泛知识类的小程序的历程记录
#帝国cms小程序# 要开发一个泛知识类的小程序,要解决以下几个问题。 1。知识内容的分类。 2。知识内容的内容展示。 3。知识内容的价格设置。 4。用户体系,为简化用户的操作,在用户进行下载的时候,请用户输入手机号ÿ…...

Kafka官方生产者和消费者脚本简单使用
问题 怎样使用Kafka官方生产者和消费者脚本进行消费生产和消费?这里假设已经下载了kafka官方文件,并已经解压. 生产者配置文件 producer_hr.properties bootstrap.servers10.xx.xx.xxx:9092,10.xx.xx.xxx:9092,10.xx.xx.xxx:9092 compression.typenone security.protocolS…...

如何开发干洗店用的小程序
洗护行业现在都开始往线上的方向发展了,越来越多的干洗店都推出了上门取送服务,那么就需要开发一个干洗店专用的小程序去作为用户和商家的桥梁,这样的小程序该如何开发呢? 一、功能设计:根据干洗店的业务需求和小程序的…...

回溯算法详解
目录 什么是回溯? 回溯常用来解决什么问题? 回溯的效率如何? 回溯在面试中的考察频率 如何学好回溯? 回溯通用模板 什么是回溯? 回溯:你处理了之后,再进行”撤销“处理,”撤销…...

ai辅助pid开发:让快马平台智能推荐参数并生成优化控制结构代码
最近在做一个化工反应釜的温度控制项目,发现传统PID调参实在太费时间了。正好试用了InsCode(快马)平台的AI辅助开发功能,整个过程顺畅了很多。这里分享下AI如何帮我们解决非线性时变系统的控制难题。 被控对象特性分析 这个反应釜系统有几个头疼的特点&…...
缺陷到__pycache__污染链(仅限CI/CD工程师内部解密))
【绝密】Python配置热加载失效的底层机制:从importlib.reload()缺陷到__pycache__污染链(仅限CI/CD工程师内部解密)
更多请点击: https://intelliparadigm.com 第一章:Python配置热加载失效的全局现象与影响面 Python 应用在微服务与云原生场景中广泛依赖配置热加载(Hot Reload)机制实现运行时参数动态更新,但实践中该能力常因环境、…...

2026年权威解读:GEO优化系统贴牌源头服务商哪家强?横向测评TOP5公司避坑攻略
当用户不再依赖传统搜索引擎输入关键词,转而直接向ChatGPT、DeepSeek、豆包等AI大模型提问“上海哪家宠物寄养靠谱?”“本地连锁宠物店推荐”时,企业营销的主战场已经发生了根本性迁移。这种变革催生了GEO(生成式引擎优化…...

ComfyUI Impact Pack终极指南:5个高效技巧解锁AI图像增强的强大功能
ComfyUI Impact Pack终极指南:5个高效技巧解锁AI图像增强的强大功能 【免费下载链接】ComfyUI-Impact-Pack Custom nodes pack for ComfyUI This custom node helps to conveniently enhance images through Detector, Detailer, Upscaler, Pipe, and more. 项目地…...

告别卡顿!深入浅出UE网络同步:角色移动、状态插值与延迟补偿实战解析
告别卡顿!深入浅出UE网络同步:角色移动、状态插值与延迟补偿实战解析 当你在射击游戏中瞄准敌人头部扣动扳机,却发现子弹"穿模"而过;当你的角色在跑动时突然瞬移回两秒前的位置;当多人混战中总有人抱怨"…...

3步解锁Wallpaper Engine资源:你的创意素材提取解决方案指南
3步解锁Wallpaper Engine资源:你的创意素材提取解决方案指南 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg 你是否曾经被Wallpaper Engine精美的动态壁纸所吸引&#x…...
)
Pydantic v2 vs v3 + typing.TypedDict vs NotRequired:Python类型配置选型决策树(含性能压测对比表)
更多请点击: https://intelliparadigm.com 第一章:Python类型配置演进全景图 Python 的类型系统并非一蹴而就,而是历经从无类型约束到渐进式类型检查的深刻演进。早期 Python(3.0 之前)完全依赖运行时动态推断&#x…...

用Python的SciPy和Matplotlib搞定三方演化博弈仿真:从微分方程到可视化分析
Python实战:三方演化博弈仿真与可视化全流程解析 在经济学、生物学和社会科学的研究中,演化博弈论正成为分析群体行为动态的强大工具。与传统的静态博弈不同,演化博弈关注策略如何在群体中随时间变化而传播,这种动态视角更贴近现实…...

3分钟在Windows上安装APK:APK-Installer极简指南
3分钟在Windows上安装APK:APK-Installer极简指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾在Windows电脑上下载了安卓应用安装包(…...
)
别再傻傻分不清!一文搞懂蓝牙BR/EDR、BLE和LE2M到底有啥区别(附应用场景选择指南)
蓝牙技术全景解析:从BR/EDR到LE2M的实战选型指南 当你打开手机连接无线耳机时,是否想过背后是哪种蓝牙协议在默默工作?市面上超过90%的物联网设备都搭载了蓝牙模块,但开发者常陷入技术选型的迷雾。本文将用真实产品案例࿰…...