pytorch中.to(device) 和.cuda()的区别
在PyTorch中,使用GPU加速可以显著提高模型的训练速度。在将数据传递给GPU之前,需要将其转换为GPU可用的格式。
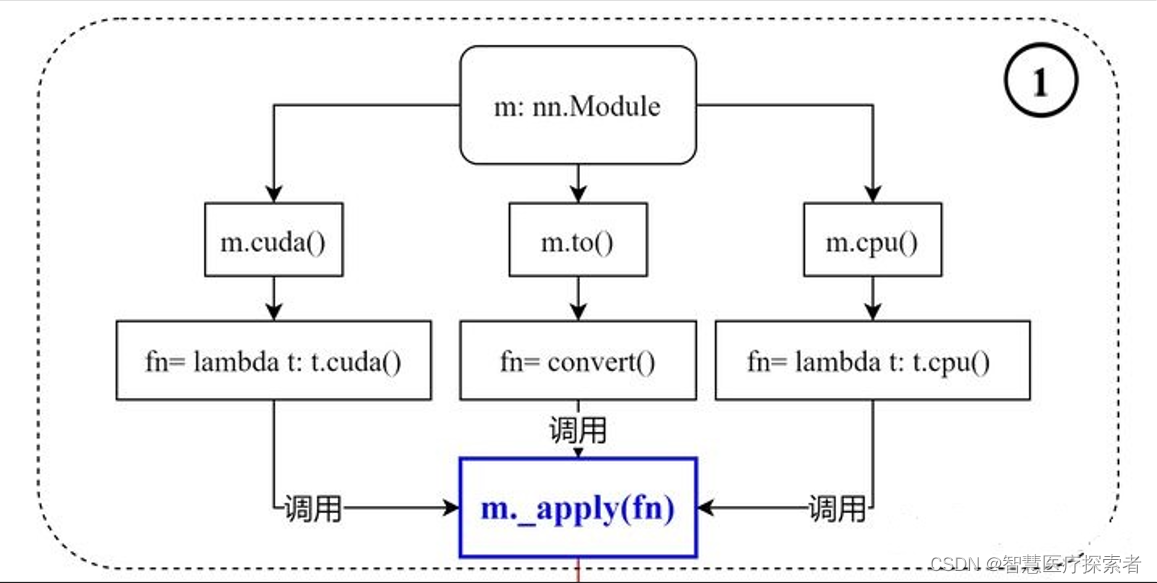
函数原型如下:
def cuda(self: T, device: Optional[Union[int, device]] = None) -> T:return self._apply(lambda t: t.cuda(device))def cpu(self: T) -> T:return self._apply(lambda t: t.cpu())def to(self, *args, **kwargs):...def convert(t):if convert_to_format is not None and t.dim() == 4:return t.to(device, dtype if t.is_floating_point() else None, non_blocking, memory_format=convert_to_format)return t.to(device, dtype if t.is_floating_point() else None, non_blocking)return self._apply(convert)1 .to(device)
.to(device)是PyTorch中的一个方法,可以将张量、模型转换为指定设备(如CPU或GPU)可用的格式。示例代码如下:
import torch# 创建一个张量
x = torch.Tensor([[1, 2, 3], [4, 5, 6]])
print(x)# 将张量转换为GPU可用的格式
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
x = x.to(device)
print(x)运行结果如下:
tensor([[1., 2., 3.],[4., 5., 6.]])
tensor([[1., 2., 3.],[4., 5., 6.]], device='cuda:0')在上述代码中,我们首先创建了一个形状为(2, 3)的张量x,然后使用x.to(device)将其转换为GPU可用的格式。其中,device是一个torch.device对象,可以使用torch.cuda.is_available()函数来判断是否支持GPU加速。
import torch
from torch import nn
from torch import optim# 创建一个模型
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.fc1 = nn.Linear(3, 2)self.fc2 = nn.Linear(2, 1)def forward(self, x):x = self.fc1(x)x = self.fc2(x)return xnet = Net()# 将模型参数和优化器转换为GPU可用的格式
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net = net.to(device)
print(net)
optimizer = optim.SGD(net.parameters(), lr=0.01)运行结果显示如下:
Net((fc1): Linear(in_features=3, out_features=2, bias=True)(fc2): Linear(in_features=2, out_features=1, bias=True)
)在上述代码中,首先创建了一个模型net,然后使用net.to(device)将其模型参数转换为GPU可用的格式。
2 .cuda()
.cuda()是PyTorch中的一个方法,可以将张量、模型转换为GPU可用的格式,示例代码如下:
import torch# 创建一个张量
x = torch.Tensor([[1, 2, 3], [4, 5, 6]])
print(x)# 将张量转换为GPU可用的格式
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
x = x.cuda()
print(x)运行结果显示如下:
tensor([[1., 2., 3.],[4., 5., 6.]])
tensor([[1., 2., 3.],[4., 5., 6.]], device='cuda:0')在上述代码中,我们首先创建了一个形状为(2, 3)的张量x,然后使用x.cuda()将其转换为GPU可用的格式。
import torch
from torch import nn
from torch import optim# 创建一个模型
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.fc1 = nn.Linear(3, 2)self.fc2 = nn.Linear(2, 1)def forward(self, x):x = self.fc1(x)x = self.fc2(x)return xnet = Net()# 将模型参数和优化器转换为GPU可用的格式
net = net.cuda()
optimizer = optim.SGD(net.parameters(), lr=0.01)在上述代码中,首先创建了一个模型net,然后使用net.cuda()将模型转换为GPU可用的格式。
3 总结
推荐使用to(device)的方式,主要原因在于这样的编程方式更加易于扩展,而cuda()必须要求机器有GPU,否则需要修改所有代码;to(device)的方式则不受此限制,device既可以是CPU也可以是GPU;
相关文章:
pytorch中.to(device) 和.cuda()的区别
在PyTorch中,使用GPU加速可以显著提高模型的训练速度。在将数据传递给GPU之前,需要将其转换为GPU可用的格式。 函数原型如下: def cuda(self: T, device: Optional[Union[int, device]] None) -> T:return self._apply(lambda t: t.cuda…...

Mysql 递归查询子类Id的所有父类Id
文章目录 问题描述先看结果表结构展示实现递归查询集合查询结果修复数据 问题描述 最近开发过程中遇到一个问题,每次添加代理关系都要去递归查询一下它在不在这个代理关系树上.很麻烦也很浪费资源.想着把代理关系的父类全部存起来 先看结果 表结构展示 表名(t_agent_user_rela…...

设计模式 之单例模式
单例模式是一种创建型设计模式,它确保一个类只有一个实例,并提供全局访问点,使得该实例可以在程序的任何地方被访问。单例模式经常用于管理共享资源或限制对象创建数量的情况下。 实现一个单例模式需要注意以下几个关键点: 构造…...
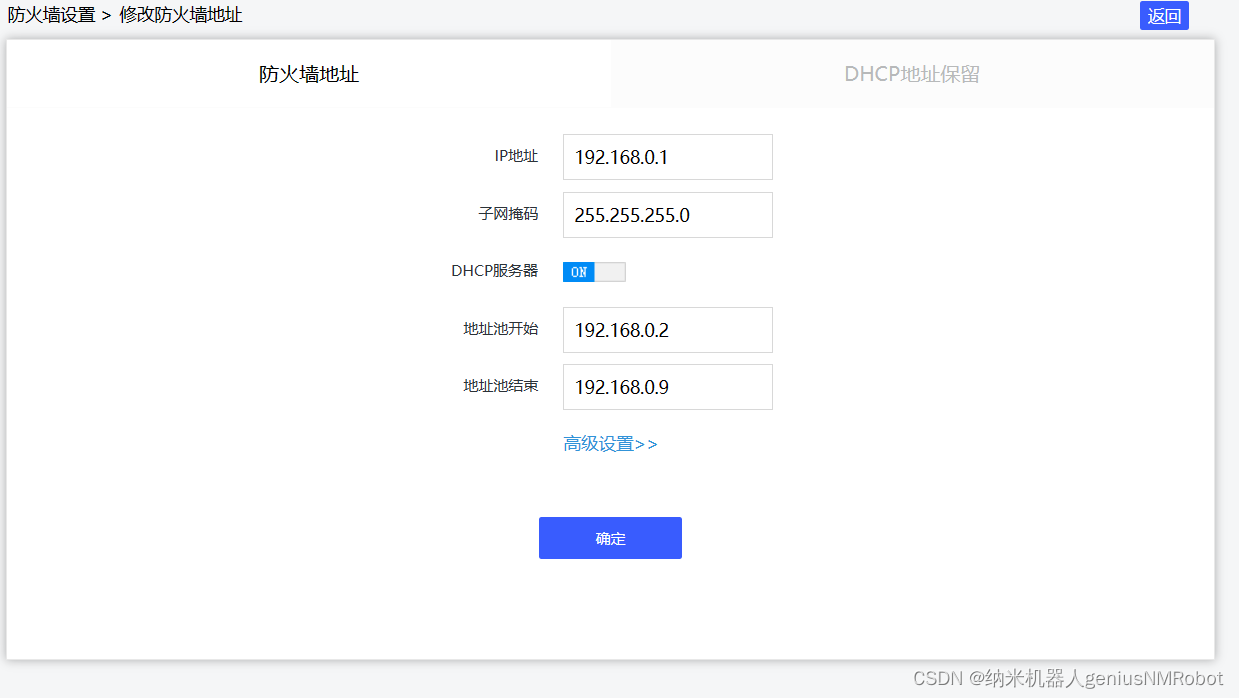
ros2不同机器通讯时IP设置
看到这就是不同机器的IP地址,为了避免在路由器为不同的机器使用DHCP分配到上面的地址,可以设置DHCP分配的范围:(我的路由器是如下设置的,一般路由器型号都不一样,自己找一下) 防火墙设置-----&…...
Nginx模块开发之http过滤器filter
文章目录 什么是过滤模块Nginx相关数据结构介绍ngx_module_t的数据结构ngx_http_module_t数据结构ngx_command_s数据结构 相关宏定义filter(过滤器)实现Nginx模块开发流程Nginx 模块执行具体实现流程create_loc_confmerge_loc_confpostconfiguration修改…...

26 - 原型模式与享元模式:提升系统性能的利器
原型模式和享元模式,前者是在创建多个实例时,对创建过程的性能进行调优;后者是用减少创建实例的方式,来调优系统性能。这么看,你会不会觉得两个模式有点相互矛盾呢? 其实不然,它们的使用是分场…...

【Web安全】sqlmap的使用笔记及示例
【Web安全】sqlmap的使用笔记 文章目录 【Web安全】sqlmap的使用笔记1. 目标2. 脱库2.1. 脱库(补充) 3. 其他3.1. 其他(补充) 4. 绕过脚本tamper讲解 1. 目标 操作作用必要示例-u指定URL,检测注入点sqlmap -u http://…...
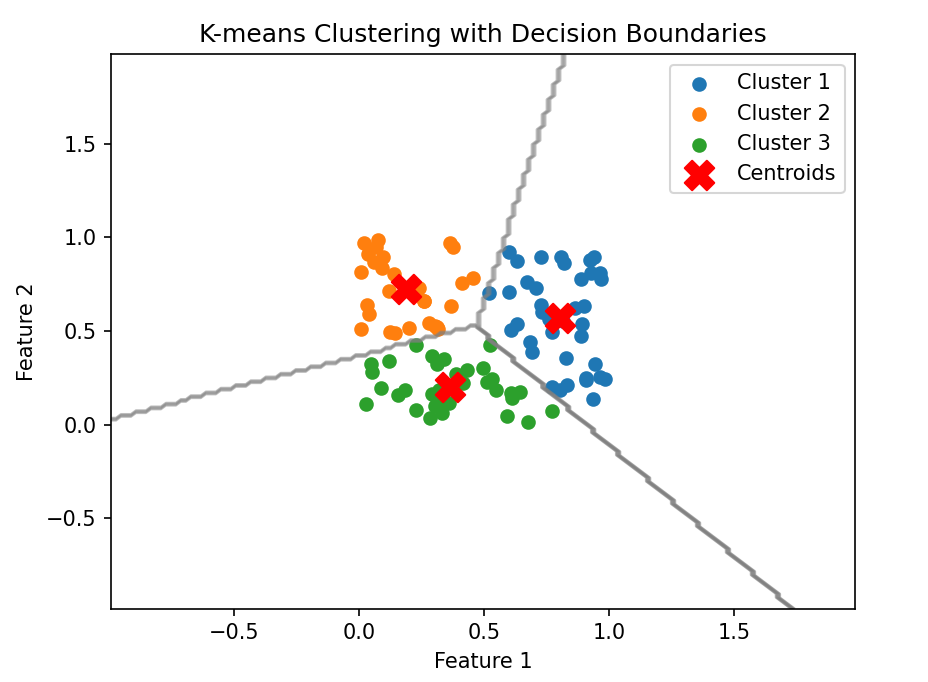
机器学习第12天:聚类
文章目录 机器学习专栏 无监督学习介绍 聚类 K-Means 使用方法 实例演示 代码解析 绘制决策边界 本章总结 机器学习专栏 机器学习_Nowl的博客-CSDN博客 无监督学习介绍 某位著名计算机科学家有句话:“如果智能是蛋糕,无监督学习将是蛋糕本体&a…...

若依框架导出下载pdf/excel以及导入打印等
一、打印文件 // 报表打印 handlePdf(row) {wayAPI(row.billcode).then((res) > {var binaryData [];binaryData.push(res);let url window.URL.createObjectURL(new Blob(binaryData, {type: "application/pdf"})); window.open("/static/pdf/web/v…...

汇编-PROC定义子过程(函数)
过程定义 过程用PROC和ENDP伪指令来声明, 并且必须为其分配一个名字(有效的标识符) 。目前为止, 我们所有编写的程序都包含了一个main过程, 例如: 当要创建的过程不是程序的启动过程时, 就用RET指令来结束它。RET强制…...

服务器主机安全的重要性及防护策略
在数字化时代,服务器主机安全是任何组织都必须高度重视的问题。无论是大型企业还是小型企业,无论是政府机构还是个人用户,都需要确保其服务器主机的安全,以防止数据泄露、网络攻击和系统瘫痪等严重后果。 一、服务器主机安全的重…...

PDF转成图片
使用开源库Apache PDFBox将PDF转换为图片 依赖 <dependency><groupId>org.apache.pdfbox</groupId><artifactId>fontbox</artifactId><version>2.0.4</version> </dependency> <dependency><groupId>org.apache…...

Qt无边框设计
//指定窗口为无边框 this->setWindowFlags(Qt::FramelessWindowHint | Qt::WindowMinMaxButtonsHint);重写鼠标事件: void mousePressEvent(QMouseEvent* event) override; void mouseMoveEvent(QMouseEvent* event) override;定义位置: QPoint dif…...
高级语法)
规则引擎Drools使用,0基础入门规则引擎Drools(二)高级语法
文章目录 系列文章索引五、规则属性1、enabled属性2、dialect属性3、salience属性4、no-loop属性5、activation-group属性6、agenda-group属性7、auto-focus属性8、timer属性9、date-effective属性10、date-expires属性 六、Drools高级语法1、global全局变量2、query查询3、fun…...

C语言二十三弹---求第N项斐波那契数列的值
C语言求第N项斐波那契数列的值 定义:斐波那契数列指的是这样一个数列:1,1,2,3,5,8,13,21,34,55,89…自然中的斐波那契数列࿰…...

Pickcode:教孩子们编码的新视觉语言
Pickcode 通过视觉课程、聊天机器人、游戏和绘图来教授编程。 Pickcode 是一种新的语言和编辑器,可以直观地指导用户编写代码来制作聊天机器人、动画图画和游戏。Pickcode 旨在让用户在学习更高级的语言之前能够充满信心地开始学习编码。 Pickcode 可视化编程语言…...

乐划锁屏插画大赏热度持续,进一步促进价值内容的创造与传播
锁屏,原本只是为了防止手机在口袋里“误触”而打造的功能,现如今逐渐成为文化传播领域的热门入口。乐划锁屏不断丰富锁屏内容和场景玩法,通过打造“乐划锁屏插画大赏”系列活动为广大内容创作者提供了更多展示自我的机会,丰富平台内容。 从2020年到2023年,乐划锁屏插画大赏已连…...

【ArcGIS Pro微课1000例】0034:矢量数据几何校正案例(Spatial Adjustment)
本案例讲解矢量数据几何校正,根据一个矢量数据去校正另外一个矢量数据。 文章目录 一、加载实验数据二、空间校正三、注意事项一、加载实验数据 在ArcGIS Pro中加载数据效果如下: design:需要校正的数据图层plan+roadcenter:目标图层可以看到,design图层没有在正确的位置…...

2023亚太杯数学建模B题:玻璃温室中的微气候法规,思路模型代码论文
问题B 玻璃温室中的微气候法规 赛题思路:思路获取见文末名片,第一时间更新 温室作物的产量受到各种气候因素的影响,包括温度、湿度和风速[1]。其中,适 宜的温度和风速是植物生长[2]的关键。为了调节玻璃温室内的温度、风速等气…...
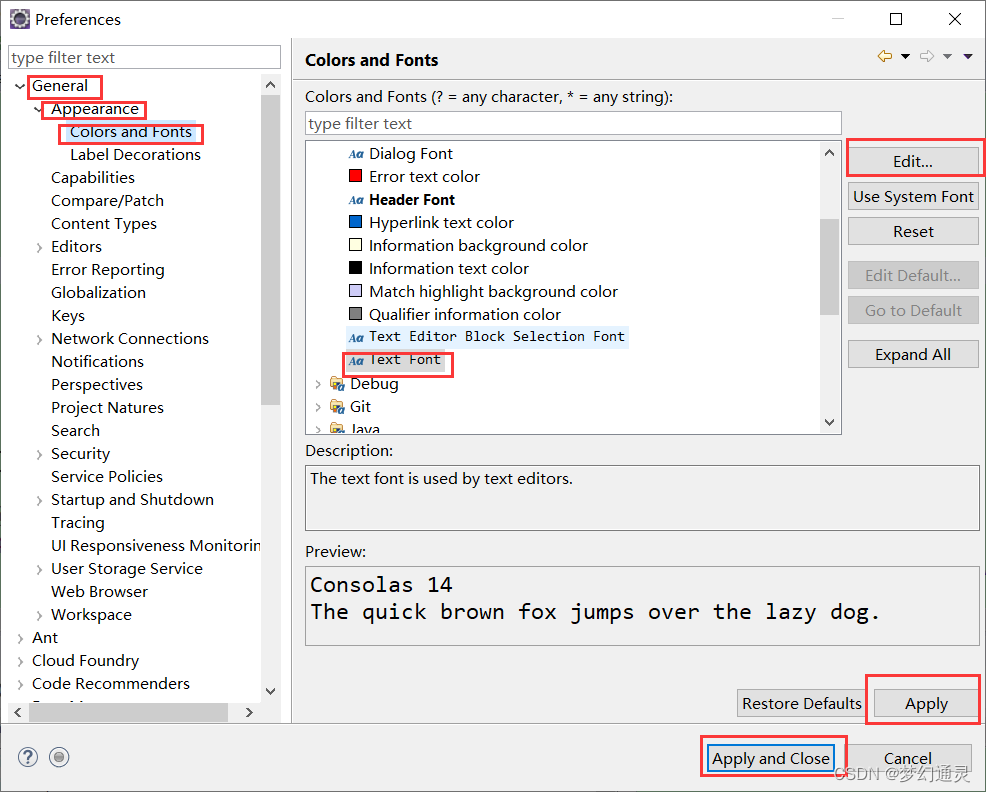
Eclipse常用设置-乱码
在用Eclipse进行Java代码开发时,经常会遇到一些问题,记录下来,方便查看。 一、properties文件乱码 常用的配置文件properties里中文的乱码,不利于识别。 处理流程:Window -> Preferences -> General -> Ja…...

机器人AI开发革命:LeRobot如何让端到端学习触手可及?
机器人AI开发革命:LeRobot如何让端到端学习触手可及? 【免费下载链接】lerobot 🤗 LeRobot: Making AI for Robotics more accessible with end-to-end learning 项目地址: https://gitcode.com/GitHub_Trending/le/lerobot 还在为机器…...

从零构建Discord AI助手:基于Dify API与Discord.js的完整实践指南
1. 项目概述:打造你的专属 Discord AI 助手 最近在折腾一个挺有意思的项目,把 Dify 上构建的 AI 应用直接搬到了 Discord 里。想象一下,你花了不少心思在 Dify 上训练了一个客服机器人、一个游戏攻略助手,或者一个代码调试专家&a…...

新手开发者如何通过Taotoken文档和示例快速上手API调用
新手开发者如何通过Taotoken文档和示例快速上手API调用 1. 注册账号与获取API Key 要开始使用Taotoken的API服务,首先需要注册账号并获取API Key。访问Taotoken官网完成注册流程后,登录控制台,在"API密钥管理"页面可以创建新的AP…...

如何使用Dawn主题打造现代化电商体验:Online Store 2.0核心功能详解
如何使用Dawn主题打造现代化电商体验:Online Store 2.0核心功能详解 【免费下载链接】dawn Shopifys first source available reference theme, with Online Store 2.0 features and performance built-in. 项目地址: https://gitcode.com/gh_mirrors/da/dawn …...
)
【2026最新】保姆级安装VMware教程(附安装包)
VMware Workstation 17 安装与使用指南 在当今软件开发、系统测试和学习研究的领域中,虚拟化技术扮演着至关重要的角色。而 VMware Workstation 正是桌面虚拟化领域的标杆级产品,它允许您在一台物理计算机上同时运行多个不同的操作系统,极大…...

R 4.5并行任务调度失衡问题全解析,深度解读mc.cores自动降级机制与NUMA感知绑定方案
更多请点击: https://intelliparadigm.com 第一章:R 4.5并行计算效率优化概览 R 4.5 引入了对 parallel 包的深度增强,显著提升了多核 CPU 利用率与任务调度粒度控制能力。相比 R 4.4,其 fork 集群初始化延迟降低约 37%ÿ…...

二刷 LeetCode:118. 杨辉三角 198. 打家劫舍 复盘笔记
目录 一、118. 杨辉三角 题目回顾 思路复盘 代码实现(Java) 易错点 & 二刷心得 二、198. 打家劫舍 题目回顾 思路复盘 基础 DP 实现(Java) 空间优化版(O (1) 空间) 易错点 & 二刷心得 …...

Xenos DLL注入器:5分钟解决Windows进程注入难题
Xenos DLL注入器:5分钟解决Windows进程注入难题 【免费下载链接】Xenos Windows dll injector 项目地址: https://gitcode.com/gh_mirrors/xe/Xenos 你是否曾经面对Windows进程注入的复杂操作感到无从下手?想象一下,你需要测试一个自定…...
失效——Tidyverse 2.0自动化流水线6大断点诊断清单)
R Markdown渲染中断、pandoc超时、theme_set()失效——Tidyverse 2.0自动化流水线6大断点诊断清单
更多请点击: https://intelliparadigm.com 第一章:R Markdown渲染中断的根因定位与修复策略 常见中断场景识别 R Markdown 渲染中断通常表现为 knitr 执行卡顿、HTML 输出空白、或控制台抛出 pandoc 错误。根本原因多集中于三类:依赖冲突&a…...

别再只发Odometry了!ROS 2中里程计消息与TF2坐标变换的绑定发布实战
ROS 2里程计与TF2坐标变换的深度绑定实践 在机器人开发中,里程计数据是导航系统的核心输入之一。很多开发者在使用ROS 2时,虽然能够正确发布nav_msgs/Odometry消息,却经常遇到RViz显示异常或导航栈无法正常工作的问题。这通常是因为忽略了里…...