Amazon Generative AI 新世界 | 基于 Amazon 扩散模型原理的代码实践之采样篇
以前通过论文介绍 Amazon 生成式 AI 和大语言模型(LLMs)的主要原理之外,在代码实践环节主要还是局限于是引入预训练模型、在预训练模型基础上做微调、使用 API 等等。很多开发人员觉得还不过瘾,希望内容可以更加深入。因此,本文将讲解基于扩散模型原理的代码实践,将尝试用代码完整从底层开始洞悉扩散模型(Diffusion Models)的工作原理,而不再仅仅止步于引入预训练模型或使用 API 完成工作。

1、扩散模型系列内容概述
基于扩散模型(Diffusion Models)的大模型,例如:Stable Diffusion、Midjourney、DALL-E 等能够仅通过提示词(Prompt)就能够生成图像。我们希望通过编写这个“扩散模型原理”代码实践系列,使用代码来探究和诠释这些应用背后算法的原理。
这个由四篇文章组成的“扩散模型原理” 代码实践系列中,我们将:
- 探索基于扩散的生成人工智能的前沿世界,并从头开始创建自己的扩散模型
- 深入了解扩散过程和驱动扩散过程的模型,而不仅仅是预先构建的模型和 API
- 通过进行采样、训练扩散模型、构建用于噪声预测的神经网络以及为个性化图像生成添加背景信息,获得实用的编码技能
- 在整个系列的最后,我们将有一个模型,可以作为我们继续探索应用扩散模型的起点
我将会用四集的篇幅,逐行代码来构建扩散模型(Diffusion Model)。这四部分分别是:
- 噪声采样(Sampling)
- 训练扩散模型(Training)
- 添加上下文(Embedding & Adding Context)
- 噪声快速采样(Fast Sampling)
这四部分的完整代码可参考GitHub:https://github.com/hanyun2019/difussion-model-code-implementation
本文是“扩散模型原理” 代码实践系列的第一部分:噪声采样(Sampling)。
Amazon 亚马逊云服务免费体验链接:
https://aws.amazon.com/cn/free/?sc_channel=seo&sc_campaign=blog1102
2、扩散模型的目标
中国有句古语:起心动念。因此,既然我们要开始从底层揭开扩散模型(Diffusion Model)的面纱,首先是否应该要想清楚一个问题:使用扩散模型的目标是什么?
本文将讨论扩散模型的目标,以及如何利用各种游戏角色图像(例如:精灵图像)训练数据来增强模型的能力,然后让扩散模型自己去生成更多的游戏角色图像(例如:生成某种风格的精灵图像等)。
假设下面是你已经有的精灵图像数据集(来自 ElvGames 的 FrootsnVeggies 和 kyrise 精灵图像集),你想要更多的在这些数据集中没有的大量精灵图像,你该如何实现这个现在看起来不可能完成的任务?
- 《FrootsnVeggies》 https://zrghr.itch.io/froots-and-veggies-culinary-pixels
- 《kyrise》 https://kyrise.itch.io/

面对这个看上去不可能完成的任务,扩散模型(Diffusion Model)就能帮上忙了。你有很多训练数据,比如你在这里看到的游戏中精灵角色的图像,这是你的训练数据集。而你想要更多训练数据集中没有的精灵图像。你可以使用神经网络,按照扩散模型过程为你生成更多这样的精灵。扩散模型能够生成这样的精灵图像。这就是我们这个系列要讨论的有趣话题。
以这个精灵图像数据集为例,扩散模型能够学习到精灵角色的通用特征,例如某种精灵的身体轮廓、头发颜色甚至腰带配饰细节等。
神经网络学习生成精灵图像的概念是什么呢?它可能是一些精致的细节,比如精灵的头发颜色、腰带配饰等;也可能是一些大致的轮廓,比如头部轮廓、身体轮廓、或者介于两者之间的其它轮廓等。而做到这一点的一种方法,即通过获取数据并能够专注更精细的细节或轮廓的方法,实际上是添加不同级别的噪声(noise)。因此,这只是在图像中添加噪声,它被称为 “噪声过程”(noising process)。
这个思路其实是受到了物理学的启发,场景很类似一滴墨水滴到一杯清水里的全过程。最初我们确切地知道墨水滴落在那里;但是随着时间的推移,我们会看到墨水扩散到清水中直到它完全消失(或者说完全和清水融为一体)。
如下图所示,我们从最左边的图像“Bob the Sprite”开始,当添加噪音时,它会消失,直到我们辨别不出它到底是哪个精灵。

以这个 Bob 精灵图像为例,以下详细描述通过添加不同阶段噪声,到精灵训练数据集的全过程。
在最左边图像“Bob the Sprite!”的时候,我们想让神经网络知道:“这就是 Bob ,它是一个精灵”。
到了“Probably Bob”的时候,我们想让神经网络知道:“你知道,这里有一些噪声”,不过通过一些细节它看起来像“Bob the Sprite!”。
到了“Well, Bob or Fred”这个图像时,变得只能看到精灵的模糊轮廓了。那么在这里我们感觉到这可能是精灵,但可能是精灵 Bob 、精灵 Fred ,或者是精灵 Nance ,这时我们可能想让神经网络为这些精灵图像推荐更通用的细节,比如:在此基础上为 Bob 建议一些细节,或者你会为 Fred 建议一些细节等。
到了最后“No Idea”这个图像时,虽然已经无法辨认图像的特征,我们仍然希望它看起来更像精灵。这时,我们仍然想让神经网络知道:“我希望你通过这张完全嘈杂的图像,通过提炼出精灵可能样子的轮廓,来把它变成更像精灵的图像”。
这就是整个“噪声过程”(noising process),即随着时间的推移逐渐增加噪声的过程,如同把一滴墨水完全扩散到一杯清水之中。我们需要训练的那个神经网络,就是希望它能够把不同的嘈杂图像变成美丽精灵。这就是我们的目标,即扩散模型的目标。
要让神经网络做到这一点,就是要让它学会去除添加的噪声。从“No Idea”这个图像开始(这时只是纯粹的噪声),到开始看起来像里面可能有精灵,再到长得像精灵 Bob ,到最后就是精灵 Bob。
这里要强调的是:“No Idea”这个图像的噪声非常重要,因为它是正态分布(normal distribution)的。换句话说,也就是这个图像的像素每一个都是从正态分布(又称 “高斯分布”)中采样的。
因此,当你希望神经网络生成一个新的精灵时,比如精灵 Fred ,你可以从该正态分布中采样噪声,然后你可以使用神经网络逐渐去除噪声来获得一个全新的精灵!除了你训练过的所有精灵之外,你还可以获得更多的精灵。

恭喜你,你已经找到了生成大量的全新美丽精灵的理论方法!接下来就是代码实践了。
在下一章里,我们将用代码展示为了实现正态分布噪声采样,而主动在迭代阶段添加噪声的方法;和没有添加噪声方法的模型输出结果对比测试。这将是一次很有趣和难忘的扩散模型工作原理奇妙体验。
3、噪声采样的代码实践
首先我们将讨论采样。我们将详细介绍采样的细节以及它在多个不同的迭代中是如何工作的。
3.1、创建 Amazon SageMaker Notebook 实例
篇幅所限,本文不再赘述如何创建 Amazon SageMaker Notebook 实例。
如需详细了解,可参考以下官方文档:
https://docs.aws.amazon.com/zh_cn/sagemaker/latest/dg/gs-setup-working-env.html
3.2、代码说明
本实验的完整示例代码可参考:
https://github.com/hanyun2019/difussion-model-code-implementation/blob/dm-project-haowen-mac/L1_Sampling.ipynb
示例代码的 notebook 在 Amazon SageMaker Notebook 测试通过,内核为 conda_pytorch_p310 ,实例为一台 ml.g5.2xlarge 实例,如下图所示。
3.3、采样过程说明
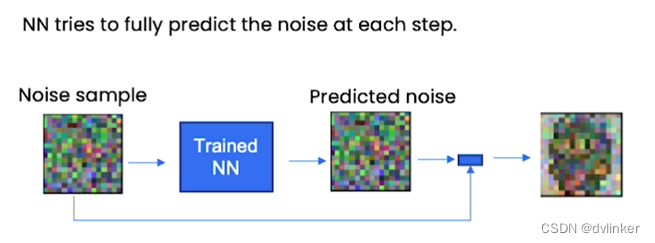
首先假设你有一个噪声样本(noise sample),你把这个噪声样本输入到一个已经训练好的神经网络中。这个神经网络已经知道精灵图像的样子,它接下来的主要工作是预测噪声。请注意:这个神经网络预测的是噪声而不是精灵图像,然后我们从噪声样本中减去预测的噪声,来得到更像精灵图像的输出结果。
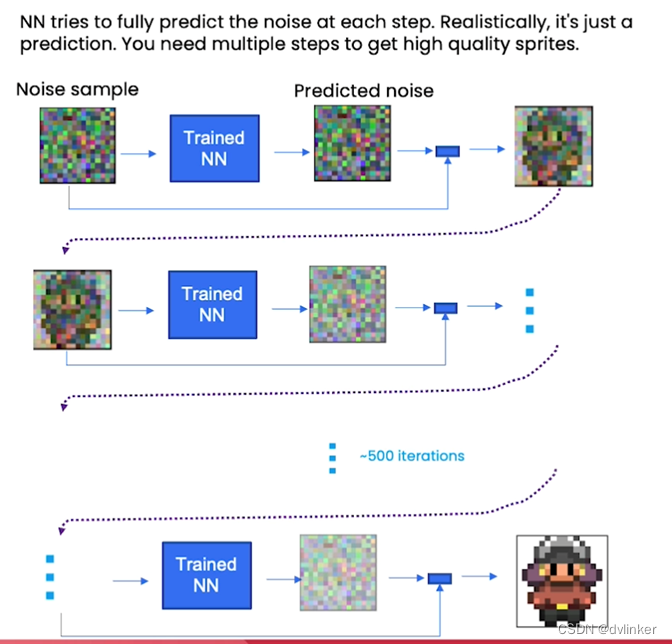
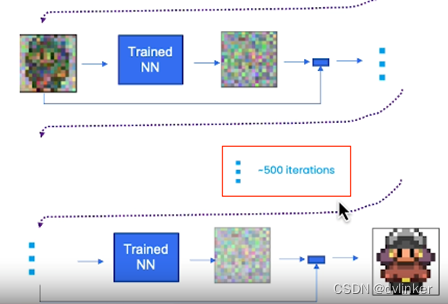
由于只是对噪声的预测,它并不能完全消除所有噪声,因此需要多个步骤才能获得高质量的样本。比如我们希望在 500 次这样的迭代之后,能够得到看起来非常像精灵图像的输出结果。
我们先看一段伪代码,从算法实现上高屋建瓴地看下整个逻辑结构:

首先我们以随机采样噪声样本(random noise sample)的方式,开始这段旅程。
如果你看过一些关于穿越时间旅行的电影,这整个过程很像是一段时间旅行。想像一下你有一杯墨汁,我们实际上是在用时光倒退(step backwards)的方式;它最初是完全扩散的漆黑墨汁,然后我们会一直追溯到有第一滴墨汁滴入一杯清水的那个最初时分。
然后,我们将采样一些额外噪声(extra noise)。为什么我们需要添加一些额外噪声,这其实是一个很有趣的话题,我们会在本文的后面部分详细探讨这个话题。
这是你实际将原始噪声、那个样本传递回神经网络的地方,然后你会得到一些预测的噪声。而这种预测噪声是经过训练的神经网络想要从原始噪声中减去的噪声,以在最后得到看起来更像精灵图像的输出结果。
最后我们还会用到一种名为 “DDPM” 的采样算法,它代表降噪扩散概率模型。
3.4、导入所需的库文件
现在我们进入通过代码解读扩散模型的部分。首先,我们需要导入 PyTorch 和一些 PyTorch 相关的实用库,以及导入帮助我们设计神经网络的一些辅助函数(helper functions)。
from typing import Dict, Tuple
from tqdm import tqdm
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import models, transforms
from torchvision.utils import save_image, make_grid
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation, PillowWriter
import numpy as np
from IPython.display import HTML
from diffusion_utilities import *3.5、神经网络架构设计
现在我们来设置神经网络,我们要用它来采样。
class ContextUnet(nn.Module):def __init__(self, in_channels, n_feat=256, n_cfeat=10, height=28): # cfeat - context featuressuper(ContextUnet, self).__init__()# number of input channels, number of intermediate feature maps and number of classesself.in_channels = in_channelsself.n_feat = n_featself.n_cfeat = n_cfeatself.h = height #assume h == w. must be divisible by 4, so 28,24,20,16...# Initialize the initial convolutional layerself.init_conv = ResidualConvBlock(in_channels, n_feat, is_res=True)
# Initialize the down-sampling path of the U-Net with two levelsself.down1 = UnetDown(n_feat, n_feat) # down1 #[10, 256, 8, 8]self.down2 = UnetDown(n_feat, 2 * n_feat) # down2 #[10, 256, 4, 4]# original: self.to_vec = nn.Sequential(nn.AvgPool2d(7), nn.GELU())self.to_vec = nn.Sequential(nn.AvgPool2d((4)), nn.GELU())# Embed the timestep and context labels with a one-layer fully connected neural networkself.timeembed1 = EmbedFC(1, 2*n_feat)self.timeembed2 = EmbedFC(1, 1*n_feat)self.contextembed1 = EmbedFC(n_cfeat, 2*n_feat)self.contextembed2 = EmbedFC(n_cfeat, 1*n_feat)# Initialize the up-sampling path of the U-Net with three levelsself.up0 = nn.Sequential(nn.ConvTranspose2d(2 * n_feat, 2 * n_feat, self.h//4, self.h//4), # up-sample nn.GroupNorm(8, 2 * n_feat), # normalize nn.ReLU(),)self.up1 = UnetUp(4 * n_feat, n_feat)self.up2 = UnetUp(2 * n_feat, n_feat)# Initialize the final convolutional layers to map to the same number of channels as the input imageself.out = nn.Sequential(nn.Conv2d(2 * n_feat, n_feat, 3, 1, 1), # reduce number of feature maps #in_channels, out_channels, kernel_size, stride=1, padding=0nn.GroupNorm(8, n_feat), # normalizenn.ReLU(),nn.Conv2d(n_feat, self.in_channels, 3, 1, 1), # map to same number of channels as input)def forward(self, x, t, c=None):"""x : (batch, n_feat, h, w) : input imaget : (batch, n_cfeat) : time stepc : (batch, n_classes) : context label"""# x is the input image, c is the context label, t is the timestep, context_mask says which samples to block the context on# pass the input image through the initial convolutional layerx = self.init_conv(x)# pass the result through the down-sampling pathdown1 = self.down1(x) #[10, 256, 8, 8]down2 = self.down2(down1) #[10, 256, 4, 4]# convert the feature maps to a vector and apply an activationhiddenvec = self.to_vec(down2)# mask out context if context_mask == 1if c is None:c = torch.zeros(x.shape[0], self.n_cfeat).to(x)# embed context and timestepcemb1 = self.contextembed1(c).view(-1, self.n_feat * 2, 1, 1) # (batch, 2*n_feat, 1,1)temb1 = self.timeembed1(t).view(-1, self.n_feat * 2, 1, 1)cemb2 = self.contextembed2(c).view(-1, self.n_feat, 1, 1)temb2 = self.timeembed2(t).view(-1, self.n_feat, 1, 1)#print(f"uunet forward: cemb1 {cemb1.shape}. temb1 {temb1.shape}, cemb2 {cemb2.shape}. temb2 {temb2.shape}")up1 = self.up0(hiddenvec)up2 = self.up1(cemb1*up1 + temb1, down2) # add and multiply embeddingsup3 = self.up2(cemb2*up2 + temb2, down1)out = self.out(torch.cat((up3, x), 1))return out3.6、设置模型训练的超参数
接下来,我们将设置模型训练需要的一些超参数,包括:时间步长、图像尺寸等。
如果对照 DDPM 的论文,其中定义了一个 noise schedule 的概念, noise schedule 决定了在特定时间里步长对图像施加的噪点水平。因此,这部分只是构造一些你记得的缩放因子的 DDPM 算法参数。那些缩放值 S1、S2、S3 ,这些缩放值是在 noise schedule 中计算的。它之所以被称为 “Schedule”,是因为它取决于时间步长。
《DDPM》
https://arxiv.org/pdf/2006.11239.pdf

超参数介绍:
- beta1:DDPM 算法的超参数
- beta2:DDPM 算法的超参数
- height:图像的长度和高度
- noise schedule(噪声调度):确定在某个时间步长应用于图像的噪声级别;
- S1,S2,S3:缩放因子的值
如下面代码所示,我们在这里设置的时间步长(timesteps)是 500 ;图像尺寸参数 height 设置为 16 ,表示这是 16 乘 16 的正方形图像;DDPM 的超参数 beta1 和 beta2 等等。
# hyperparameters# diffusion hyperparameters
timesteps = 500
beta1 = 1e-4
beta2 = 0.02# network hyperparameters
device = torch.device("cuda:0" if torch.cuda.is_available() else torch.device('cpu'))
n_feat = 64 # 64 hidden dimension feature
n_cfeat = 5 # context vector is of size 5
height = 16 # 16x16 image
save_dir = './weights/'请记住,你正在浏览 500 次的步骤,因为你正在经历你在这里看到的缓慢去除噪音的 500 次迭代。
以下代码块将构建 DDPM 论文中定义的时间步长(noise schedule):
# construct DDPM noise schedule
b_t = (beta2 - beta1) * torch.linspace(0, 1, timesteps + 1, device=device) + beta1
a_t = 1 - b_t
ab_t = torch.cumsum(a_t.log(), dim=0).exp()
ab_t[0] = 1接下来实例化模型:
# construct model
nn_model = ContextUnet(in_channels=3, n_feat=n_feat, n_cfeat=n_cfeat, height=height).to(device)3.7、添加额外噪声的输出测试
首先测试的是添加额外噪声的输出测试。可以重点关注下变量 z 。
在每次迭代之后,我们通过设置“z = torch.randn_like(x)”来添加额外的采样噪声,以让噪声输入符合正态分布:
# helper function; removes the predicted noise (but adds some noise back in to avoid collapse)
def denoise_add_noise(x, t, pred_noise, z=None):if z is None:z = torch.randn_like(x)noise = b_t.sqrt()[t] * zmean = (x - pred_noise * ((1 - a_t[t]) / (1 - ab_t[t]).sqrt())) / a_t[t].sqrt()接下来加载该模型:
# load in model weights and set to eval mode
nn_model.load_state_dict(torch.load(f"{save_dir}/model_trained.pth", map_location=device))
nn_model.eval()
print("Loaded in Model")以下代码段实现了前面介绍过的 DDPM 采样算法:
# sample using standard algorithm
@torch.no_grad()
def sample_ddpm(n_sample, save_rate=20):# x_T ~ N(0, 1), sample initial noisesamples = torch.randn(n_sample, 3, height, height).to(device) # array to keep track of generated steps for plottingintermediate = [] for i in range(timesteps, 0, -1):print(f'sampling timestep {i:3d}', end='\r')# reshape time tensort = torch.tensor([i / timesteps])[:, None, None, None].to(device)# sample some random noise to inject back in. For i = 1, don't add back in noisez = torch.randn_like(samples) if i > 1 else 0eps = nn_model(samples, t) # predict noise e_(x_t,t)samples = denoise_add_noise(samples, i, eps, z)if i % save_rate ==0 or i==timesteps or i<8:intermediate.append(samples.detach().cpu().numpy())intermediate = np.stack(intermediate)return samples, intermediate运行模型以获得预测的噪声:
eps = nn_model(samples, t) # predict noise e_(x_t,t)最后降噪:
samples = denoise_add_noise(samples, i, eps, z)现在,让我们来可视化采样随时间推移的样子。这可能需要几分钟,具体取决于你在哪种硬件上运行。在本系列的第四集中,我们还将介绍一种快速采样(Fast Sampling)技术,这个在第四集中我们在详细讨论。
点击开始按钮来查看不同时间线上,模型生成的精灵图像,动图显示如下所示。
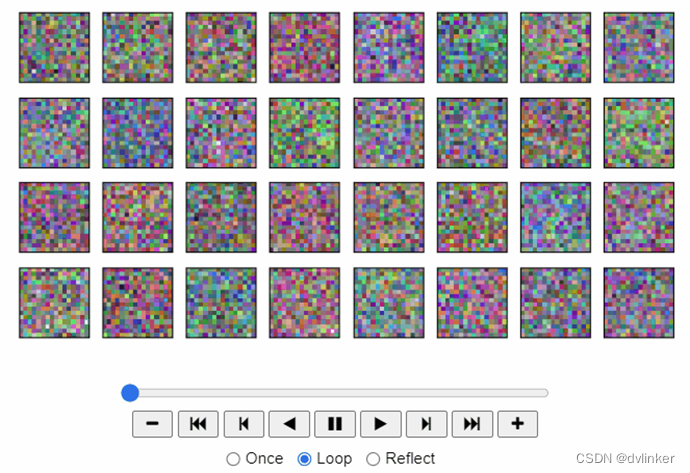
如果以上动图无法在手机上正常显示,可以参考下面这三张,我在不同时间线上分别做了截图。



3.8、未添加额外噪声的输出测试
对于我们不添加噪音的输出测试,代码方面其实实现很简单,就是是将变量 z 设置为零,然后将其传入。代码如下所示。
# incorrectly sample without adding in noise
@torch.no_grad()
def sample_ddpm_incorrect(n_sample):# x_T ~ N(0, 1), sample initial noisesamples = torch.randn(n_sample, 3, height, height).to(device) # array to keep track of generated steps for plottingintermediate = [] for i in range(timesteps, 0, -1):print(f'sampling timestep {i:3d}', end='\r')# reshape time tensort = torch.tensor([i / timesteps])[:, None, None, None].to(device)# don't add back in noisez = 0eps = nn_model(samples, t) # predict noise e_(x_t,t)samples = denoise_add_noise(samples, i, eps, z)if i%20==0 or i==timesteps or i<8:intermediate.append(samples.detach().cpu().numpy())intermediate = np.stack(intermediate)return samples, intermediate让我们来看看不添加噪音方式的输出结果,如下图所示:输出变形了!

这显然不是我们想要的结果。可见,在这个神经网络的架构设计中,在每个迭代阶段添加额外噪声,来保持输入噪声符合正态分布是很关键的一个步骤。
4、总结
作为 “扩散模型工作原理”代码实践系列的第一篇,本文通过两段不同代码块的实现,来对比了两种扩散模型的采样方法:
1)添加额外噪声的方法;
2)不添加额外噪声的方法。
总的来说,就是扩散模型的神经网络输入应该是符合正态分布的噪声样本。由于在迭代过程中,噪声样本减去模型预测的噪声之后得到的样本已经不符合正态分布了,所以容易导致输出变形。因此,在每次迭代之后,我们需要根据其所处的时间步长来添加额外的采样噪声,以让输入符合正态分布。这可以保证模型训练的稳定性,以避免模型的预测结果由于接近数据集的均值,而导致的输出结果变形。
Amazon 亚马逊云服务免费体验链接:
https://aws.amazon.com/cn/free/?sc_channel=seo&sc_campaign=blog1102
这个系列之后的文章,我们将继续深入了解扩散过程和执行该过程的模型,帮助大家在更深层次的理解扩散模型;并且通过自己动手从头构建扩散模型,而不是仅仅引用预训练好的模型或使用模型的 API ,来对扩散模型底层实现原理的理解更加深刻。下一篇文章我们将用代码来实践扩散模型的训练,敬请期待。
5、参考资料
1)DeepLearning.AI short course “How Diffusion Models Work”
https://www.deeplearning.ai/short-courses/how-diffusion-models-work/
2)Sprites by ElvGames, FrootsnVeggies and kyrise
《FrootsnVeggies》
https://zrghr.itch.io/froots-and-veggies-culinary-pixels
《kyrise》
https://kyrise.itch.io/
3)Code reference, This code is modified from https://github.com/cloneofsimo/minDiffusion
4)DDPM & DDIM papers
Diffusion model is based on Denoising Diffusion Probabilistic Models and Denoising Diffusion Implicit Models
《Denoising Diffusion Probabilistic Models》
https://arxiv.org/abs/2006.11239
《Denoising Diffusion Implicit Models》
https://arxiv.org/abs/2010.02502
相关文章:
Amazon Generative AI 新世界 | 基于 Amazon 扩散模型原理的代码实践之采样篇
以前通过论文介绍 Amazon 生成式 AI 和大语言模型(LLMs)的主要原理之外,在代码实践环节主要还是局限于是引入预训练模型、在预训练模型基础上做微调、使用 API 等等。很多开发人员觉得还不过瘾,希望内容可以更加深入。因此&#x…...
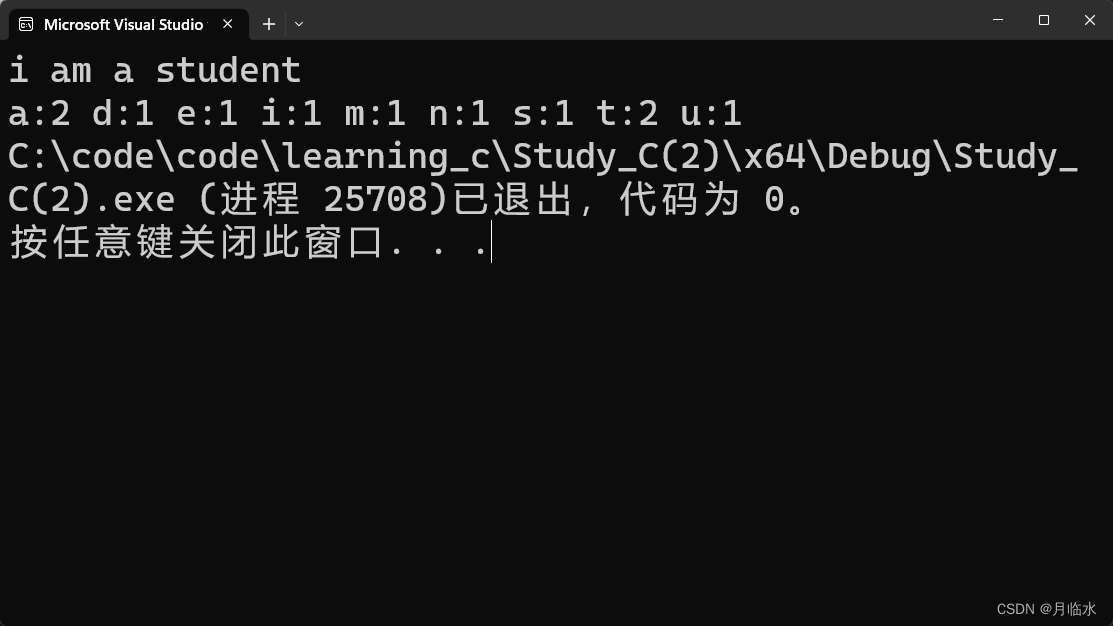
使用C语言统计一个字符串中每个字母出现的次数
每日一言 Wishing is not enough; we must do. 光是许愿望是不够的; 我们必须行动。 题目 输入一个字符串,统计在该字符串中每个字母出现的次数 例如: 输入:i am a student 输出:a:2 d:1 e:1 i:1 m:1 n:1 s:1 t:2 u:1 大体思路…...

中国出海主力系列专访之三七互娱:亚马逊云科技助力三七互娱海外“出圈”之路
如果问,在众多的中国出海赛道中哪一条拥有基数最大的粉丝拥趸?以网络游戏、社交媒体、直播、短视频为代表的泛娱乐赛道便成为当仁不让的领跑者。 在东京、新加坡、开罗、伦敦、纽约、慕尼黑等国际都市,当地的年轻人会随时随地的打开“中国造”…...

算法刷题-动态规划2
算法刷题-动态规划2 珠宝的最高价值下降路径最小和 珠宝的最高价值 题目 大佬思路 多开一行使得代码更加的简洁 移动到右侧和下侧 dp[ i ][ j ]有两种情况: 第一种是从上面来的礼物最大价值:dp[ i ][ j ] dp[ i - 1 ][ j ] g[ i ][ j ] 第二种是从左…...

【Vue】自定义指令
hello,我是小索奇,精心制作的Vue系列持续发放,涵盖大量的经验和示例,如果对您有用,可以点赞收藏哈~ 自定义指令 自定义指令就是自己定义的指令,是对 DOM 元素进行底层操作封装 ,程序化地控制 DOMÿ…...

MFC 中创建并显示二维码
1.创建并显示 QRcode* pQR_Encode; pQR_Encode QRcode_encodeString("12345678901234567890", 0, QR_ECLEVEL_H, QR_MODE_8, 1); if (pQR_Encode) { int nBmpWidth pQR_Encode->width; //获取控件的边界大小 CRect rect; Ge…...

NX二次开发UF_CAM_set_clear_plane_tag 函数介绍
文章作者:里海 来源网站:https://blog.csdn.net/WangPaiFeiXingYuan UF_CAM_set_clear_plane_tag Defined in: uf_cam_planes.h int UF_CAM_set_clear_plane_tag(tag_t object_tag, tag_t target_tag ) overview 概述 Set the tag of a clearance pl…...

计算机网络:数据链路层
0 本节主要内容 问题描述 解决思路 1 问题描述 数据链路层主要面临四个问题: 封装成帧;透明传输;差错检测;实现相邻节点之间的可靠通信。 1.1 子问题1:封装成帧 怎么知道数据从哪里开始?到哪里结束&a…...

电线电缆行业生产管理怎么数字化?
行业介绍 随着市场环境的变化和现代生产管理理念的不断更新,电缆的生产模式也在发生转变,批量小,规格多,交期短的新型制造需求逐年上升,所以企业车间管理的重要性越发凸显,作为企业良性运营的关键…...

计算机网络之数据链路层
一、概述 1.1概述 物理层发出去的信号需要通过数据链路层才知道是否到达目的地;才知道比特流的分界线 链路(Link):从一个结点到相邻结点的一段物理线路,中间没有任何其他交换结点数据链路(Data Link):把实现通信协议的硬件和软件…...
)
前端新手Vue3+Vite+Ts+Pinia+Sass项目指北系列文章 —— 系列文章(目录)
系列文章目录 第一章 技术栈简介 (开篇) 第二章 环境部署 (Node等环境安装) 第三章 项目创建 (Vite项目初始化) 第四章 认识项目目录 (项目整体介绍) 第五章 组件库安装和使用(Element-Plus基础配置) 第六章 样式格式化 (Sass配置) 第七章 路由配置 (vue-router深入解读) 第八…...

uniapp 给小程序添加分享功能
在 Uni-app 中,要为小程序添加分享功能,你可以通过使用小程序的自定义分享组件或通过配置页面的分享信息来实现。下面我将分别介绍这两种方法。 方法一:使用小程序的自定义分享组件 在小程序中,你可以创建一个自定义的分享组件&…...

npm命令
node -v --查看版本 npm install --安装npm npm config get registry --查看npm当前镜像 npm config set registry https://registry.npmmirror.com --设置淘宝镜像 npm版本管理工具...

Halcon Solution Guide I basics(3): Region Of Interest(有兴趣区域/找重点)
文章目录 文章专栏前言文章解读前言创建ROI案例1:直接截取ROI手动截取ROI 总结ROI套路获取窗口句柄截取ROI区域获取有效区域 Stop组合 文章专栏 Halcon开发 Halcon学习 练习项目gitee仓库 CSDN Major 博主Halcon文章推荐 前言 今天来看第三章内容,既然是…...

以太坊铭文聚合交易平台 Scorpio,铭文爆发的新推手?
在今年 3 月,Ordinals 凭空问世,定义了一套在比特币网络运行的序数协议,使得 Token 和 NFT 能在比特币网络上实现并稳定运行,拉来了比特币铭文市场的新序幕。而在此后,在包括 BRC20 等在内的一系列应用的出现ÿ…...
Socket通信之网络协议基本原理
一台机器将自己想要表达的内容,按照某种约定好的格式发送出去,当另外一台机器收到这些信息后,也能够按照约定好的格式解析出来,从而准确、可靠地获得发送方想要表达的内容。这种约定好的格式就是网络协议(Networking P…...

linux 开发板以太网通过Ubuntu上外网方法
在开发板嵌入式设备,有一个mgbe网卡,用网线与连接soc的网卡,和外接网卡,将网卡usb接口插入电脑,选择接入到Ubuntu系统 在Ubuntu将能识别到这个外接网卡,这样就可以通过Ubuntu和soc通讯了, 如下…...

DependencyProperty.Register:wpf 向别的xaml传递参数
一.使用背景:在A.xaml中嵌入B.xaml,并且向B.xaml传递参数。 函数介绍: public static DependencyProperty Register(string name, Type propertyType, Type ownerType );name(string): 依赖属性的名称。在…...
uvm白皮书练习_ch2_ch231_加入transaction
2.3 为验证平平台加入各种组件 uvm白皮书练习_ch2_ch231_加入transaction 代码部分 top_tb.sv timescale 1ns / 1ps include "uvm_macros.svh"import uvm_pkg::*; /*只能现在*/include "my_if.sv" include "my_transaction.sv" include "…...

python-泛型实现,类型检查
python-泛型实现,类型检查 泛型类型泛型类 在Python中,没有像Java中的泛型那样的明确语法来指定类型参数。Python是一种动态类型语言,可以灵活地处理不同类型的对象。 然而,如果你希望在Python中添加泛型的注释或提示,…...

使用 Taotoken CLI 工具一键配置团队开发环境
使用 Taotoken CLI 工具一键配置团队开发环境 1. Taotoken CLI 工具概述 Taotoken CLI 工具(taotoken/taotoken)是为开发者提供的命令行工具,旨在简化团队开发环境中的大模型接入配置流程。通过该工具,团队管理员可以快速为成员…...
)
仅限前200名车载开发者获取:Dify车规版定制内核补丁包(含SPI Flash磨损均衡优化+看门狗协同重启模块)
更多请点击: https://intelliparadigm.com 第一章:Dify车载智能问答系统开发概述 Dify 是一个开源的低代码大模型应用开发平台,支持快速构建具备上下文感知、多轮对话与知识增强能力的智能问答系统。在车载场景中,其轻量级部署能…...

AI公平性检测:多阶段审计框架与性别偏见解决方案
1. 项目背景与核心问题去年参与某金融风控项目时,我们团队发现一个诡异现象:同一套AI评分模型对女性客户的拒贷率比男性高出23%。排查后发现训练数据中女性样本仅占38%,且历史放贷记录存在隐性性别歧视。这个案例让我意识到,AI偏见…...

免费开源桌面分区管理工具NoFences:3步快速整理Windows桌面图标
免费开源桌面分区管理工具NoFences:3步快速整理Windows桌面图标 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 还在为Windows桌面上杂乱无章的图标而烦恼吗&…...

免费漫画下载终极方案:E-Hentai下载器完整使用指南
免费漫画下载终极方案:E-Hentai下载器完整使用指南 【免费下载链接】E-Hentai-Downloader Download E-Hentai archive as zip file 项目地址: https://gitcode.com/gh_mirrors/eh/E-Hentai-Downloader 你是否厌倦了在E-Hentai网站上逐页保存漫画的繁琐过程&a…...

Flutter Launcher Icons配置模板详解:XML、HTML和图标资源生成原理
Flutter Launcher Icons配置模板详解:XML、HTML和图标资源生成原理 【免费下载链接】flutter_launcher_icons Flutter Launcher Icons - A package which simplifies the task of updating your Flutter apps launcher icon. Fully flexible, allowing you to choos…...

3个策略:如何用Jd-Auto-Shopping实现90%抢购成功率
3个策略:如何用Jd-Auto-Shopping实现90%抢购成功率 【免费下载链接】Jd-Auto-Shopping 京东商品补货监控及自动下单 项目地址: https://gitcode.com/gh_mirrors/jd/Jd-Auto-Shopping 在电商大促的秒杀战场上,手动操作往往只能望"货"兴叹…...

互补强化学习:提升样本效率的协同进化架构
1. 项目概述:当经验与策略开始对话在强化学习领域,我们常常面临一个根本性矛盾:策略网络需要大量试错才能积累有效经验,而试错过程本身又依赖策略的质量。这种"鸡生蛋蛋生鸡"的困境,使得传统强化学习在复杂环…...

2026届最火的降重复率工具推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在现如今人工智能辅助写作愈发普遍的状况下,很多创作者急需处理文本里残留的那种…...

终极OBS多平台直播插件指南:obs-multi-rtmp一键同步推流到所有平台
终极OBS多平台直播插件指南:obs-multi-rtmp一键同步推流到所有平台 【免费下载链接】obs-multi-rtmp OBS複数サイト同時配信プラグイン 项目地址: https://gitcode.com/gh_mirrors/ob/obs-multi-rtmp 你是否曾在直播时面临这样的困境:想要同时在B…...