使用Pytorch从零开始构建RNN
在这篇文章中,我们将了解 RNN(即循环神经网络),并尝试通过 PyTorch 从头开始实现其中的部分内容。是的,这并不完全是从头开始,因为我们仍然依赖 PyTorch autograd 来计算梯度并实现反向传播,但我仍然认为我们也可以从这个实现中收集到有价值的见解。
有关 RNN 的简要介绍性概述,我建议您查看上一篇文章,其中我们不仅探讨了 RNN 是什么及其工作原理,还探讨了如何使用 Keras 实现 RNN 模型。这次,我们将使用 PyTorch,但采取更实际的方法从头开始构建一个简单的 RNN。
完全免责声明,这篇文章很大程度上改编自PyTorch 教程这个 PyTorch 教程。我修改并改变了预处理和训练中涉及的一些步骤。我仍然建议您将其作为补充材料查看。考虑到这一点,让我们开始吧。
数据准备
任务是建立一个简单的分类模型,可以根据名字正确确定一个人的国籍。更简单地说,我们希望能够分辨出特定名称的来源。
下载
我们将使用 PyTorch 教程中的一些标记数据。我们只需输入即可下载
!curl -O https://download.pytorch.org/tutorial/data.zip; unzip data.zip
此命令将下载文件并将其解压到当前目录中,文件夹名称为data.
现在我们已经下载了所需的数据,让我们更详细地看一下数据。首先,这是我们需要的依赖项。
import os
import random
from string import ascii_lettersimport torch
from torch import nn
import torch.nn.functional as F
from unidecode import unidecode_ = torch.manual_seed(42)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
我们首先指定一个目录,然后尝试打印出其中的所有标签。然后我们可以构建一个字典,将语言映射到数字标签。
data_dir = "./data/names"lang2label = {file_name.split(".")[0]: torch.tensor([i], dtype=torch.long)for i, file_name in enumerate(os.listdir(data_dir))
}
我们看到一共有18种语言。我将每个标签包装为张量,以便我们可以在训练期间直接使用它们。
lang2label
{'Czech': tensor([0]),'German': tensor([1]),'Arabic': tensor([2]),'Japanese': tensor([3]),'Chinese': tensor([4]),'Vietnamese': tensor([5]),'Russian': tensor([6]),'French': tensor([7]),'Irish': tensor([8]),'English': tensor([9]),'Spanish': tensor([10]),'Greek': tensor([11]),'Italian': tensor([12]),'Portuguese': tensor([13]),'Scottish': tensor([14]),'Dutch': tensor([15]),'Korean': tensor([16]),'Polish': tensor([17])}
让我们将语言数量存储在某个变量中,以便稍后在模型声明中使用它,特别是当我们指定最终输出层的大小时。
num_langs = len(lang2label)
预处理
现在,让我们对名称进行预处理。我们首先要用来unidecode标准化所有名称并删除任何锐利符号或类似符号。例如,
unidecode("Ślusàrski")
'Slusarski'
一旦我们有了解码后的字符串,我们就需要将其转换为张量,以便模型可以处理它。这可以首先通过构建映射来完成char2idx,如下所示。
char2idx = {letter: i for i, letter in enumerate(ascii_letters + " .,:;-'")}
num_letters = len(char2idx); num_letters
59
我们看到我们的字符词汇表中共有 59 个标记。这包括空格和标点符号,例如 .,:;-' . This also means that each name will now be expressed as a tensor of size (num_char, 59) ; in other words, each character will be a tensor of size (59,)。我们现在可以构建一个完成此任务的函数,如下所示:
def name2tensor(name):tensor = torch.zeros(len(name), 1, num_letters)for i, char in enumerate(name):tensor[i][0][char2idx[char]] = 1return tensor
如果你仔细阅读代码,你会发现输出张量的大小是(num_char, 1, 59),这与上面的解释不同。嗯,这个额外维度的原因是我们在本例中使用的批量大小为 1。在 PyTorch 中,RNN 层期望输入张量的大小为(seq_len, batch_size, input_size)。由于每个名称都有不同的长度,因此为了简单起见,我们不会对输入进行批处理,而只是将每个输入用作单个批处理。有关更详细的讨论,请查看此论坛讨论。
name2tensor()让我们使用虚拟输入快速验证函数的输出。
name2tensor("abc")
tensor([[[1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0.]],[[0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0.]],[[0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0.]]])
数据集创建
现在我们需要构建包含所有预处理步骤的数据集。让我们将所有解码和转换的张量收集在一个列表中,并附上标签。可以从文件名轻松获取标签,例如german.txt.
tensor_names = []
target_langs = []for file in os.listdir(data_dir):with open(os.path.join(data_dir, file)) as f:lang = file.split(".")[0]names = [unidecode(line.rstrip()) for line in f]for name in names:try:tensor_names.append(name2tensor(name))target_langs.append(lang2label[lang])except KeyError:pass
我们可以将其包装在 PyTorchDataset类中,但为了简单起见,我们只使用一个好的旧for循环将这些数据输入到我们的模型中。由于我们处理的是普通列表,因此我们可以轻松地使用sklearn’strain_test_split()将训练数据与测试数据分开。
from sklearn.model_selection import train_test_splittrain_idx, test_idx = train_test_split(range(len(target_langs)), test_size=0.1, shuffle=True, stratify=target_langs
)train_dataset = [(tensor_names[i], target_langs[i])for i in train_idx
]test_dataset = [(tensor_names[i], target_langs[i])for i in test_idx
]
让我们看看我们有多少训练和测试数据。请注意,我们使用的 test_size为 0.1。
print(f"Train: {len(train_dataset)}")
print(f"Test: {len(test_dataset)}")
Train: 18063
Test: 2007
模型
我们将构建两个模型:一个简单的 RNN(将从头开始构建)和一个使用 PyTorch 层的基于 GRU 的模型。
简单循环神经网络
现在我们可以构建我们的模型了。这是一个非常简单的 RNN,它采用单个字符张量表示作为输入,并产生一些预测和隐藏状态,可在下一次迭代中使用。请注意,它只是一些在隐藏状态计算期间应用了 sigmoid 非线性的全连接层。
class MyRNN(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(MyRNN, self).__init__()self.hidden_size = hidden_sizeself.in2hidden = nn.Linear(input_size + hidden_size, hidden_size)self.in2output = nn.Linear(input_size + hidden_size, output_size)def forward(self, x, hidden_state):combined = torch.cat((x, hidden_state), 1)hidden = torch.sigmoid(self.in2hidden(combined))output = self.in2output(combined)return output, hiddendef init_hidden(self):return nn.init.kaiming_uniform_(torch.empty(1, self.hidden_size))
我们init_hidden()在每个新批次开始时都会打电话。为了更容易训练和学习,我决定使用kaiming_uniform_()来初始化这些隐藏状态。
我们现在可以构建模型并开始训练它。
hidden_size = 256
learning_rate = 0.001model = MyRNN(num_letters, hidden_size, num_langs)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
我意识到训练这个模型非常不稳定,正如你所看到的,损失上下跳跃了很多。尽管如此,我不想为难我的 13 英寸 MacBook Pro,所以我决定在两个epochs停止。
num_epochs = 2
print_interval = 3000for epoch in range(num_epochs):random.shuffle(train_dataset)for i, (name, label) in enumerate(train_dataset):hidden_state = model.init_hidden()for char in name:output, hidden_state = model(char, hidden_state)loss = criterion(output, label)optimizer.zero_grad()loss.backward()nn.utils.clip_grad_norm_(model.parameters(), 1)optimizer.step()if (i + 1) % print_interval == 0:print(f"Epoch [{epoch + 1}/{num_epochs}], "f"Step [{i + 1}/{len(train_dataset)}], "f"Loss: {loss.item():.4f}")
Epoch [1/2], Step [3000/18063], Loss: 0.0390
Epoch [1/2], Step [6000/18063], Loss: 1.0368
Epoch [1/2], Step [9000/18063], Loss: 0.6718
Epoch [1/2], Step [12000/18063], Loss: 0.0003
Epoch [1/2], Step [15000/18063], Loss: 1.0658
Epoch [1/2], Step [18000/18063], Loss: 1.0021
Epoch [2/2], Step [3000/18063], Loss: 0.0021
Epoch [2/2], Step [6000/18063], Loss: 0.0131
Epoch [2/2], Step [9000/18063], Loss: 0.3842
Epoch [2/2], Step [12000/18063], Loss: 0.0002
Epoch [2/2], Step [15000/18063], Loss: 2.5420
Epoch [2/2], Step [18000/18063], Loss: 0.0172
现在我们可以测试我们的模型。我们可以查看其他指标,但准确性是迄今为止最简单的,所以我们就这样吧。
num_correct = 0
num_samples = len(test_dataset)model.eval()with torch.no_grad():for name, label in test_dataset:hidden_state = model.init_hidden()for char in name:output, hidden_state = model(char, hidden_state)_, pred = torch.max(output, dim=1)num_correct += bool(pred == label)print(f"Accuracy: {num_correct / num_samples * 100:.4f}%")
Accuracy: 72.2471%
该模型的准确率高达 72%。这非常糟糕,但考虑到模型非常简单,而且我们只训练了两个 epoch 的模型,我们可以放松下来,享受短暂的快乐,因为知道简单的 RNN 模型至少能够学到一些东西。
让我们通过一些具体示例来看看我们的模型表现如何。下面是一个接受字符串作为输入并输出解码预测的函数。
label2lang = {label.item(): lang for lang, label in lang2label.items()}def myrnn_predict(name):model.eval()tensor_name = name2tensor(name)with torch.no_grad():hidden_state = model.init_hidden()for char in tensor_name:output, hidden_state = model(char, hidden_state)_, pred = torch.max(output, dim=1)model.train() return label2lang[pred.item()]
我不知道这些名字是否真的在训练或测试集中;这些只是我想出的一些随机名称,我认为这些名称相当合理。瞧,结果是有希望的。
myrnn_predict("Mike")
'English'
myrnn_predict("Qin")
'Chinese'
myrnn_predict("Slaveya")
'Russian'
该模型似乎已将所有名称分类为正确的类别!
PyTorch GRU
这很酷,我可能可以停在这里,但我想看看这个自定义模型与使用 PyTorch 层的模型相比如何。对于我们简单的 RNN 来说,GRU 可能不太公平,但让我们看看它的表现如何。
class GRUModel(nn.Module):def __init__(self, num_layers, hidden_size):super(GRUModel, self).__init__()self.num_layers = num_layersself.hidden_size = hidden_sizeself.gru = nn.GRU(input_size=num_letters, hidden_size=hidden_size, num_layers=num_layers,)self.fc = nn.Linear(hidden_size, num_langs)def forward(self, x):hidden_state = self.init_hidden()output, hidden_state = self.gru(x, hidden_state)output = self.fc(output[-1])return outputdef init_hidden(self):return torch.zeros(self.num_layers, 1, self.hidden_size).to(device)
让我们声明模型和与之配套的优化器。请注意,我们使用的是两层 GRU,它已经比我们当前的 RNN 实现多了一层。
model = GRUModel(num_layers=2, hidden_size=hidden_size)
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
for epoch in range(num_epochs):random.shuffle(train_dataset)for i, (name, label) in enumerate(train_dataset):output = model(name)loss = criterion(output, label)optimizer.zero_grad()loss.backward()optimizer.step()if (i + 1) % print_interval == 0:print(f"Epoch [{epoch + 1}/{num_epochs}], "f"Step [{i + 1}/{len(train_dataset)}], "f"Loss: {loss.item():.4f}")
Epoch [1/2], Step [3000/18063], Loss: 1.8497
Epoch [1/2], Step [6000/18063], Loss: 0.4908
Epoch [1/2], Step [9000/18063], Loss: 1.0299
Epoch [1/2], Step [12000/18063], Loss: 0.0855
Epoch [1/2], Step [15000/18063], Loss: 0.0053
Epoch [1/2], Step [18000/18063], Loss: 2.6417
Epoch [2/2], Step [3000/18063], Loss: 0.0004
Epoch [2/2], Step [6000/18063], Loss: 0.0008
Epoch [2/2], Step [9000/18063], Loss: 0.1446
Epoch [2/2], Step [12000/18063], Loss: 0.2125
Epoch [2/2], Step [15000/18063], Loss: 3.7883
Epoch [2/2], Step [18000/18063], Loss: 0.4862
训练一开始看起来比较稳定,但我们确实在第二个时期结束时看到了奇怪的跳跃。部分原因是我没有对此 GRU 模型使用梯度裁剪,并且应用裁剪后我们可能会看到更好的结果。
让我们看看这个模型的准确性。
num_correct = 0model.eval()with torch.no_grad():for name, label in test_dataset:output = model(name)_, pred = torch.max(output, dim=1)num_correct += bool(pred == label)print(f"Accuracy: {num_correct / num_samples * 100:.4f}%")
Accuracy: 81.4150%
我们得到的这个模型的准确率约为 80%。这比我们的简单 RNN 模型要好,这在某种程度上是预料之中的,因为它有一个附加层并且使用了更复杂的 RNN 单元模型。
让我们看看这个模型如何预测给定的一些原始名称字符串。
def pytorch_predict(name):model.eval()tensor_name = name2tensor(name)with torch.no_grad():output = model(tensor_name)_, pred = torch.max(output, dim=1)model.train()return label2lang[pred.item()]
pytorch_predict("Jake")
'English'
pytorch_predict("Qin")
'Chinese'
pytorch_predict("Fernando")
'Spanish'
pytorch_predict("Demirkan")
'Russian'
最后一个很有趣,因为这是我一位土耳其好朋友的名字。该模型显然无法告诉我们这个名字是土耳其语,因为它没有看到任何标记为土耳其语的数据点,但它告诉我们这个名字可能属于它所训练的 18 个标签中的哪个国籍。这显然是错误的,但在某些方面也许相差并不远。例如,至少它没有说日语。对于该模型来说,这也不是完全公平的游戏,因为有许多名字可能被描述为跨国的:也许有一个俄罗斯人的名字叫 Demirkan。
结论
通过实现这个 RNN,我学到了很多关于 RNN 的知识。诚然,它很简单,并且与 PyTorch 基于层的方法有所不同,因为它需要我们手动循环每个字符,但它的低级性质迫使我更多地思考张量维度以及具有张量维度的目的。隐藏状态和输出之间的划分。这也很好地提醒了我们 RNN 是如何难以训练的。
在接下来的文章中,我们将研究序列到序列模型,简称 seq2seq。自从听说 seq2seq 以来,我就对将一种数据形式转换为另一种数据形式的力量着迷。尽管由于本地机器的限制,这些模型无法在 CPU 上进行实际训练,但我认为实现它们本身将是一个令人兴奋的挑战。
本博文译自Jake Tae的博文。
相关文章:

使用Pytorch从零开始构建RNN
在这篇文章中,我们将了解 RNN(即循环神经网络),并尝试通过 PyTorch 从头开始实现其中的部分内容。是的,这并不完全是从头开始,因为我们仍然依赖 PyTorch autograd 来计算梯度并实现反向传播,…...
Linux之实现简易的shell
1.打印提示符并获取命令行 我们在使用shell的时候,发现我们在输入命令是,前面会有:有用户名,版本,当前路径等信息,这里我们可以用环境变量去获取: 1 #include <stdio.h>2 #include <stdlib.h>…...
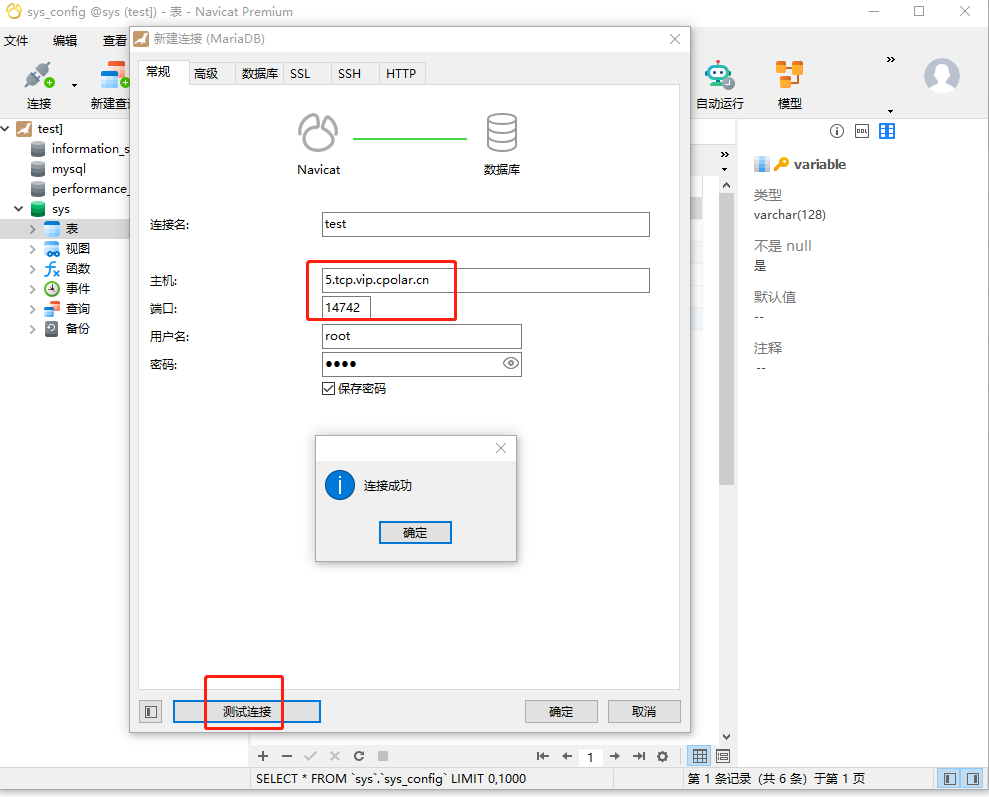
如何实现在公网下使用navicat图形化工具远程连接本地内网的MariaDB数据库
公网远程连接MariaDB数据库【cpolar内网穿透】 文章目录 公网远程连接MariaDB数据库【cpolar内网穿透】1. 配置MariaDB数据库1.1 安装MariaDB数据库1.2 测试局域网内远程连接 2. 内网穿透2.1 创建隧道映射2.2 测试随机地址公网远程访问3. 配置固定TCP端口地址3.1 保留一个固定的…...
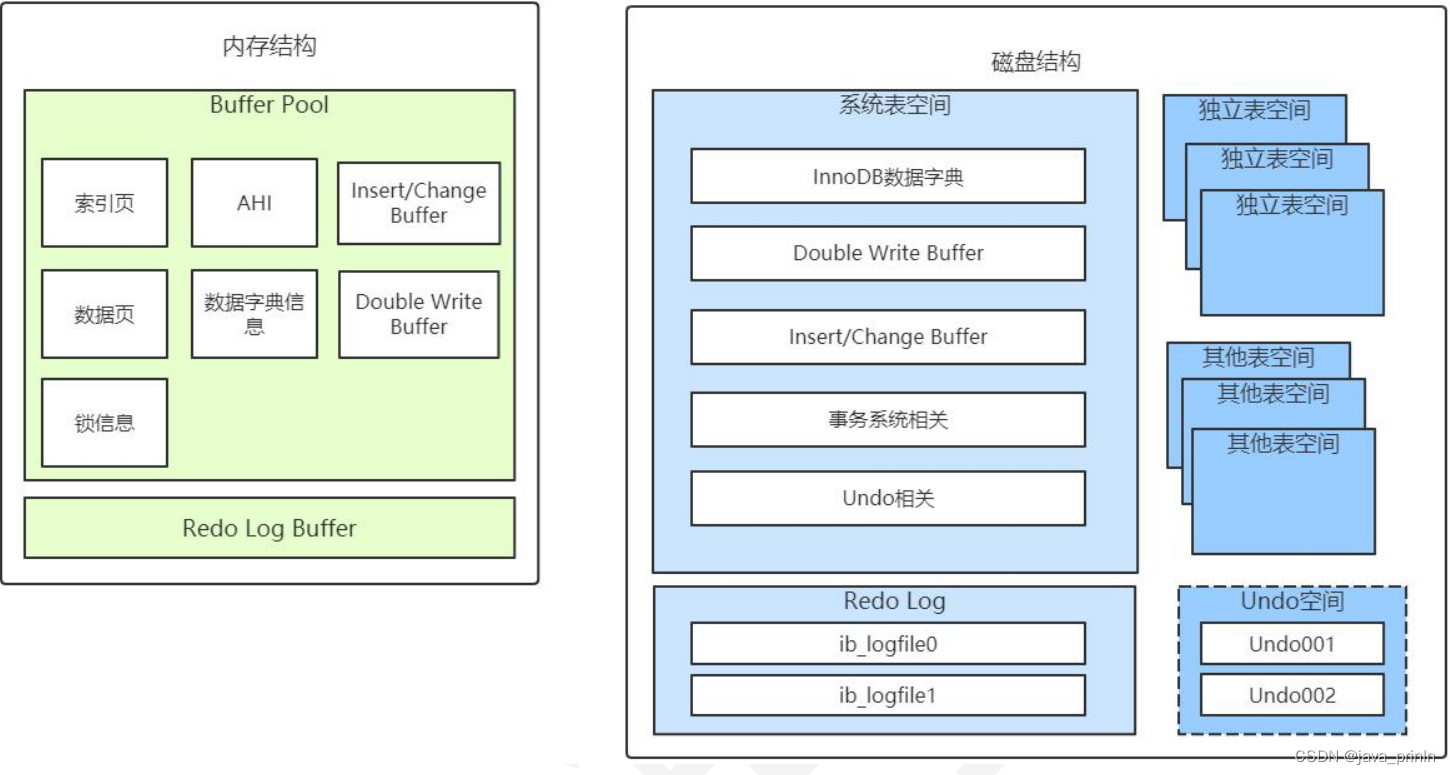
MySQL InnoDB 引擎底层解析(三)
6.3.3. InnoDB 的内存结构总结 InnoDB 的内存结构和磁盘存储结构图总结如下: 其中的 Insert/Change Buffer 主要是用于对二级索引的写入优化,Undo 空间则是 undo 日志一般放在系统表空间,但是通过参数配置后,也可以用独立表空 间…...
浅析基于智能音视频技术的城市重要场馆智能监控系统设计
了解旭帆科技的朋友都知道,旭帆科技一直都乐于和大家分享各类场景的视频解决方案,今天小编就基于智能音视频技术的城市重要场馆智能监控系统设计和大家探讨一下。 基于智能音视频技术的城市重要场馆智能监控系统设计,主要包含以下要素&#x…...

hdu-lcy算法培训班 入门第一讲 数学基础
习题 F题...

获取ip属地(ip2region本地离线包-超简单)
背景 最近有涉及要显示ip属地,但我想白嫖,结果就是白嫖的api接口太慢了,要延迟3到4秒左右,很影响体验,而且不一定稳定。 结果突然看到了这个【ip2region】开源项目,离线识别ip属地,精度自己测…...
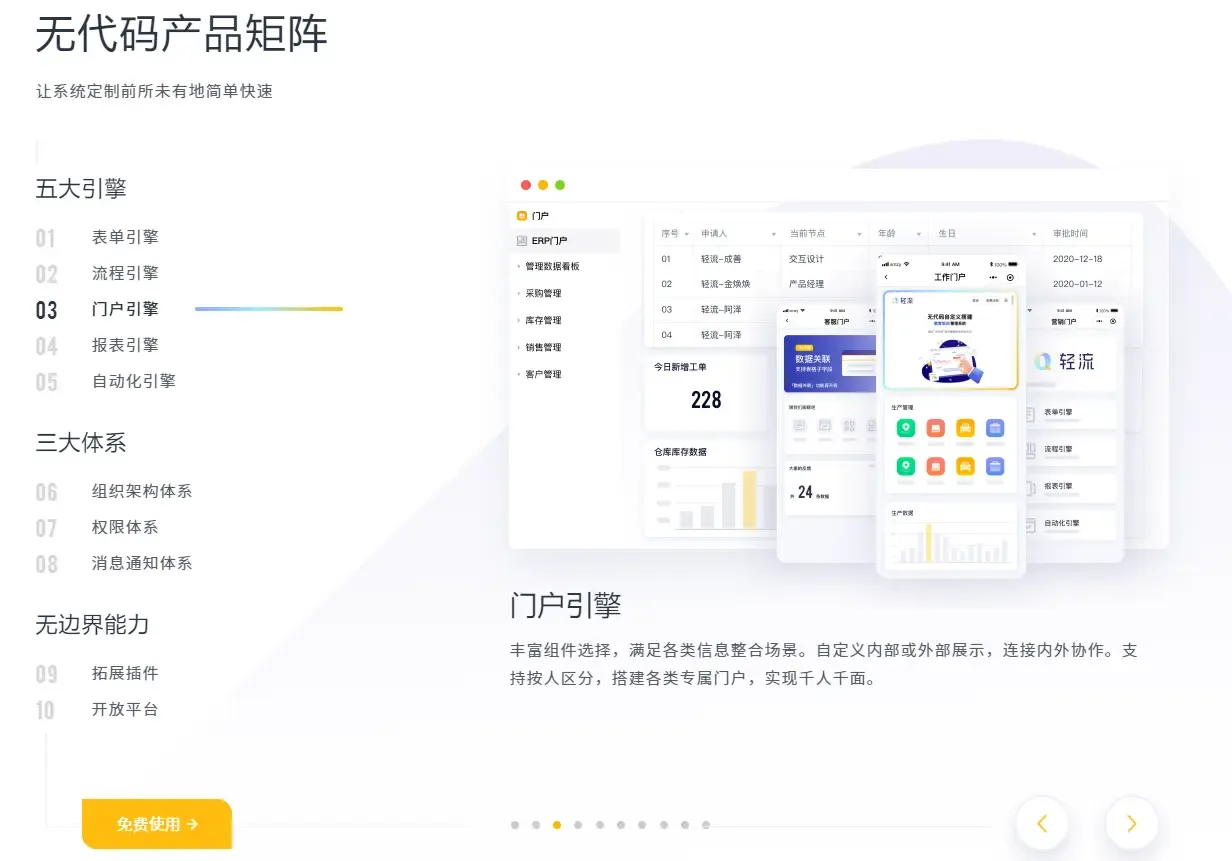
主流的低代码平台有哪些?程序员应该如何与低代码相处?
本文主要阐述低代码的概念,介绍目前主流的低代码平台,总结低代码平台的典型特征、存在优势以及未来发展趋势。并站在程序员的角度,分析如何在已经到来的低代码战争中,找到自己的定位,一展所长。 什么是低代码ÿ…...

华为---OSPF网络虚连接(Virtual Link)简介及示例配置
【1】OSPF网络虚连接(Virtual Link)简介 为了避免区域间的环路,OSPF规定不允许直接在两个非骨干区域之间发布路由信息,只允许在一个区域内部或者在骨干区域和非骨干区域之间发布路由信息。因此,每个ABR都必须连接到骨干…...

Python函数式编程:让你的代码更优雅更简洁
概要 函数式编程(Functional Programming)是一种编程范式,它将计算视为函数的求值,并且避免使用可变状态和循环。 函数式编程强调的是函数的计算,而不是它的副作用。 在函数式编程中,函数是第一类公民&a…...
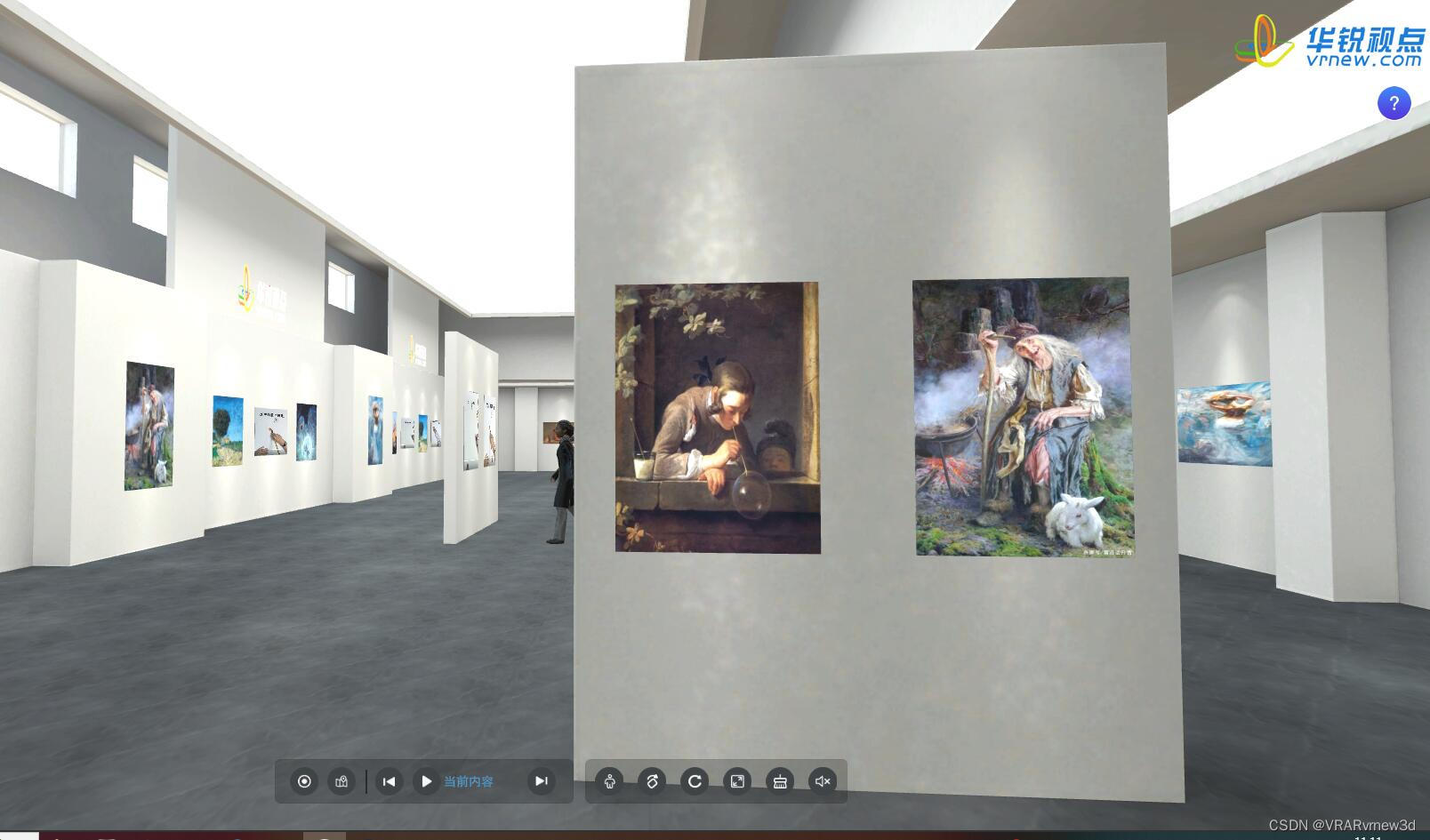
艺术作品3D虚拟云展厅能让客户远程身临其境地欣赏美
艺术品由于货物昂贵、易碎且保存难度大,因此在艺术品售卖中极易受时空限制,艺术品三维云展平台在线制作是基于web端将艺术品的图文、模型及视频等资料进行上传搭配,构建一个线上艺术品3D虚拟展厅,为艺术家和观众提供了全新的展示和…...
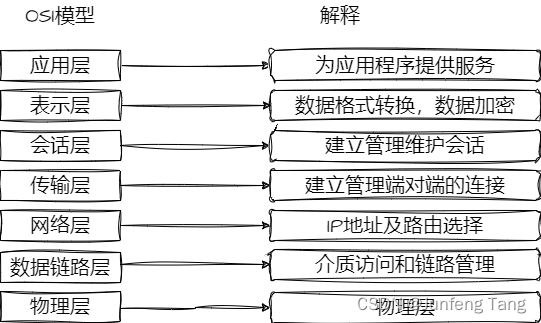
负载均衡简介
负载均衡 负载均衡(Load Balance,简称 LB)是高并发、高可用系统必不可少的关键组件,目标是 尽力将网络流量平均分发到多个服务器上,以提高系统整体的响应速度和可用性。 负载均衡的分类和OSI模型息息相关,…...
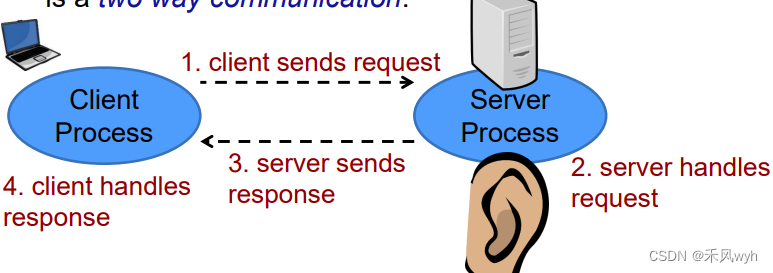
【高级网络程序设计】Week2-1 Sockets
一、The Basics 1. Sockets 定义An abstraction of a network interface应用 use the Socket API to create connections to remote computers send data(bytes) receive data(bytes) 2. Java network programming the java network libraryimport java.net.*;similar to…...

quickapp_快应用_requestHeader
和客户端相同,在进行请求交互中,后端会需要获取当前设备信息,此时需要使用应用上下文app与设备信息 应用版本号 const app require(system.app)app.getInfo().versionName // versionName:应用版本名称 (manifest.json中versio…...
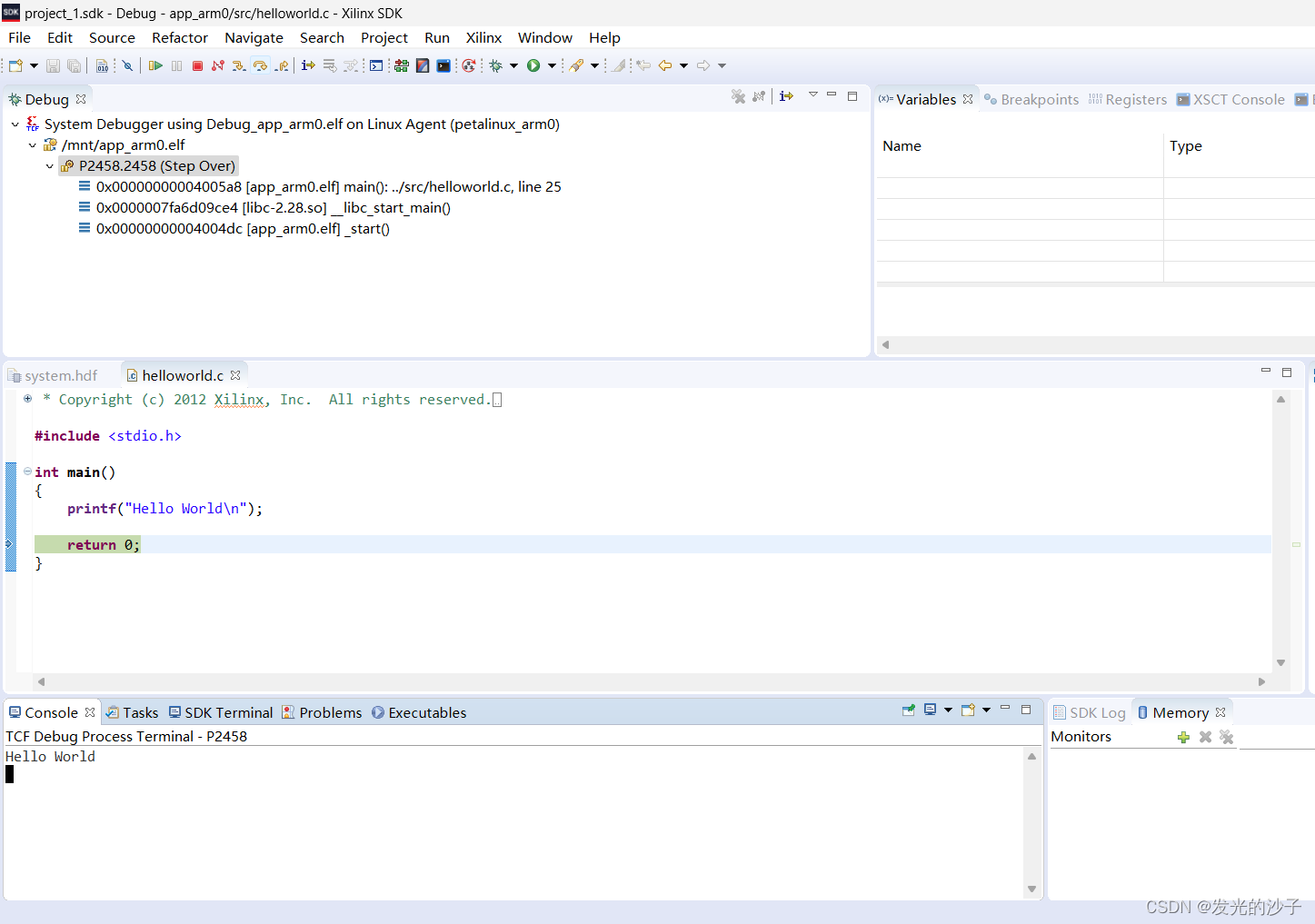
FPGA----ZCU106使用petalinux 2019.1的第一个app开发
1、petalinux在zcu106上的构建参见前文 FPGA----ZCU106使用petalinux 2019.1(全网最详)-CSDN博客文章浏览阅读31次。本文完成了Vivado 2019.1版本下的基于ZCU106的全部linux系统移植https://blog.csdn.net/qq_37912811/article/details/1345197352、我们…...
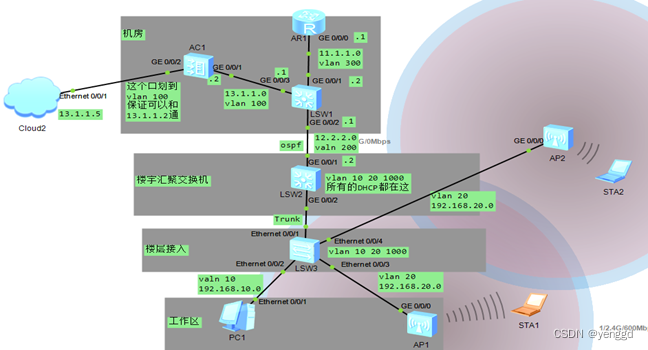
华为ac+fit漫游配置案例
Ap漫游配置: 其它配置上面一样,ap管理dhcp和业务dhcp全在汇聚交换机 R1: interface GigabitEthernet0/0/0 ip address 11.1.1.1 255.255.255.0 ip route-static 12.2.2.0 255.255.255.0 11.1.1.2 ip route-static 192.168.0.0 255.255.0.0 11.1.1.2 lsw1: vlan batch 100 200…...
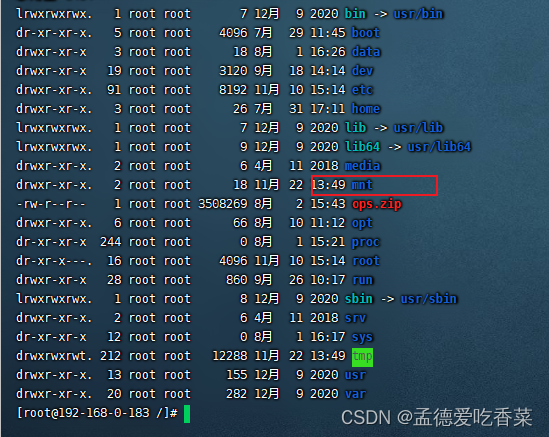
Jenkins 配置节点交换内存
查看交换内存 free -hswapon -s创建swap文件 dd if/dev/zero of/mnt/swap bs1M count1024启用交换文件 设置权限 chmod 600 /mnt/swap设置为交换空间 mkswap /mnt/swap启用交换 swapon /mnt/swap设置用户组 chown root:root /mnt/swap查看 swapon -s重启系统也能生效还需要修…...
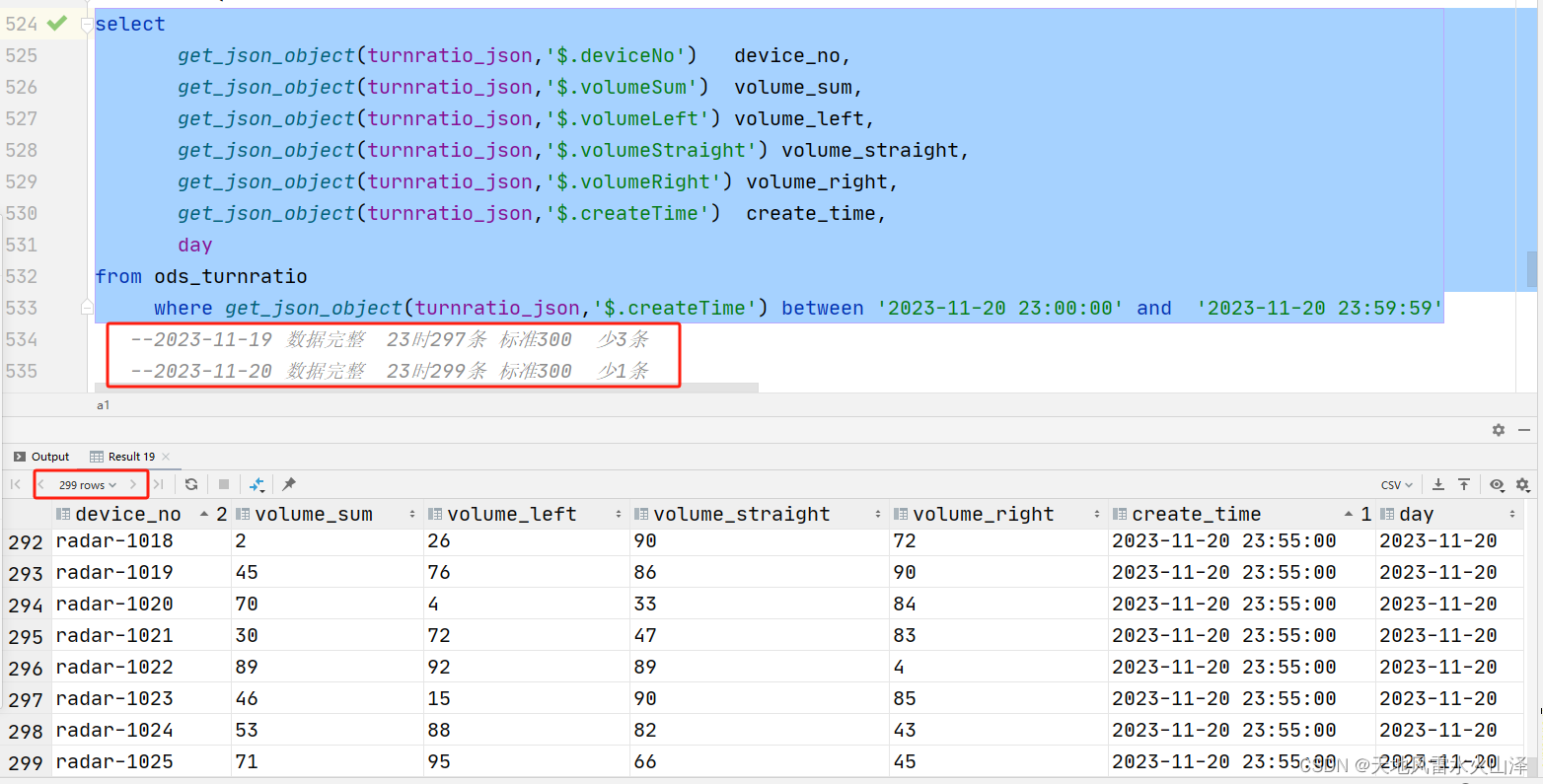
二百零七、Flume——Flume实时采集5分钟频率的Kafka数据直接写入ODS层表的HDFS文件路径下
一、目的 在离线数仓中,需要用Flume去采集Kafka中的数据,然后写入HDFS中。 由于每种数据类型的频率、数据大小、数据规模不同,因此每种数据的采集需要不同的Flume配置文件。玩了几天Flume,感觉Flume的使用难点就是配置文件 二、…...
【实验】配置用户自动获取IPv6地址的案例
【赠送】IT技术视频教程,白拿不谢!思科、华为、红帽、数据库、云计算等等编辑https://xmws-it.blog.csdn.net/article/details/117297837?spm1001.2014.3001.5502https://xmws-it.blog.csdn.net/article/details/117297837?spm1001.2014.3001.5502【…...

手撕A*算法(详解A*算法)
A*算法原理 全局路径规划算法,根据给定的起点和终点在全局地图上进行总体路径规划。 导航中使用A*算法计算出机器人到目标位置的最优路线,一般作为规划的参考路线 // 定义地图上的点 struct Point {int x,y; // 栅格行列Point(int x, int y):x(x),y(y){…...

生产排期与MES/ERP系统打通,实操方法详解 —— 2026企业级智能体自动化选型与实战指南
在2026年的工业4.0深化阶段,制造企业已从单纯的数字化转型迈向“全面智能化”时代。生产排程作为工厂的“大脑”,其与MES(制造执行系统)及ERP(企业资源计划)系统的深度打通,不再是可选的优化项&…...

Phi-3-mini-4k-instruct-gguf实战:基于C++的高性能推理服务开发
Phi-3-mini-4k-instruct-gguf实战:基于C的高性能推理服务开发 1. 为什么选择C开发推理服务 在实时对话和智能客服这类对延迟敏感的在线服务场景中,C凭借其接近硬件的性能优势成为首选。与Python等解释型语言相比,C能直接管理内存、避免垃圾…...
Pixel Aurora Engine 赋能低代码平台:在Dify中集成AI图像生成能力
Pixel Aurora Engine 赋能低代码平台:在Dify中集成AI图像生成能力 1. 低代码平台与AI图像生成的完美结合 想象一下,你正在开发一个电商网站,需要为成千上万的商品自动生成展示图片。传统方式需要雇佣设计师团队,成本高昂且效率低…...
Pixel Epic智识终端参数详解:‘逻辑发散概率’对研报创新性影响分析
Pixel Epic智识终端参数详解:逻辑发散概率对研报创新性影响分析 1. 产品概述与核心价值 Pixel Epic智识终端是一款革命性的研究报告辅助工具,它将枯燥的科研过程转化为一场充满探索乐趣的像素RPG冒险。基于AgentCPM-Report大模型构建,这款工…...

Win11Debloat:免费Windows系统优化工具终极指南,轻松提升44%性能
Win11Debloat:免费Windows系统优化工具终极指南,轻松提升44%性能 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other change…...

为什么92%的MCP插件在VS Code 1.89+版本崩溃?——基于17个真实生产环境日志的协议兼容性根因分析
更多请点击: https://intelliparadigm.com 第一章:MCP协议演进与VS Code 1.89版本兼容性断层全景图 MCP(Microsoft Code Protocol)并非官方命名,而是开发者社区对 VS Code 扩展宿主通信机制的泛称,特指自 …...

当“伪造借书证”遇上现代API密钥管理:从一篇课文聊聊身份认证与访问控制的安全演进
从借书证到API密钥:身份认证技术的百年安全进化史 二十世纪初的美国南方,一位黑人青年用伪造的借书证叩开了知识的大门;百年后的数字世界,开发者们用API密钥访问云端资源。两种看似迥异的场景,却揭示了相同的安全命题&…...

ARM CoreSight ETM11CS调试架构与信号接口设计
1. ARM CoreSight ETM11CS调试架构解析在嵌入式系统开发中,实时指令跟踪是定位复杂问题的关键手段。ETM11CS作为ARM CoreSight调试架构中的关键组件,其信号接口设计直接决定了调试数据的可靠性和实时性。与传统的JTAG调试不同,ETM采用实时指令…...

Freyr-js技术架构深度解析:多服务集成与音频处理流程
Freyr-js技术架构深度解析:多服务集成与音频处理流程 【免费下载链接】freyr-js A tool for downloading songs from music streaming services like Spotify and Apple Music. 项目地址: https://gitcode.com/gh_mirrors/fr/freyr-js Freyr-js是一款功能强大…...

GPSTest支持的全球卫星系统大盘点:从GPS到北斗的完整指南
GPSTest支持的全球卫星系统大盘点:从GPS到北斗的完整指南 【免费下载链接】gpstest The #1 open-source Android GNSS/GPS test program 项目地址: https://gitcode.com/gh_mirrors/gp/gpstest GPSTest是一款功能强大的开源Android全球导航卫星系统ÿ…...