Redis面试内容,Redis过期策略,Redis持久化方式,缓存穿透、缓存击穿和缓存雪崩,以及解决办法
文章目录
- 一、redis
- 什么是Redis
- Redis使用场景
- 1、缓存
- 2、数据共享[分布式](https://so.csdn.net/so/search?q=分布式&spm=1001.2101.3001.7020)
- 3、分布式锁
- 4、全局ID
- 5、计数器
- 6、限流
- 7、位统计
- Redis有5中数据类型: SSHLZ
- Redis中一个key的值每天12点过期,给我一个你的解决方式
- 定期扫描策略
- 惰性策略
- 从节点的过期策略
- Redis对于超过内存限制的处理
- Redis 提供了几种可选策略来进行处理,这些策略在 4.0 之前四种,4.0之后又新增了两种
- 浅谈LRU与LFU
- redis 集群模式与哨兵模式的区别
- 1、主从复制(Replication)
- 1.1 主从数据库
- 1.2 主从复制的特点
- 1.3 主从复制的优缺点
- 2、哨兵([Sentinel](https://so.csdn.net/so/search?q=Sentinel&spm=1001.2101.3001.7020))
- 2.1 Redis哨兵主要功能
- 2.2 Redis哨兵高可用原理
- 2.3 Redis哨兵故障切换的过程
- 2.4 Redis哨兵模式的工作方式
- 2.5 Redis哨兵模式的优缺点
- 3、集群(Cluster)
- 3.1 Redis-Cluster集群的配置
- 3.2 Redis-Cluster集群的特点
- 3.3 Redis-Cluster集群的工作方式
- 3.4 Redis-Cluster集群的优缺点
- redis 持久化 —— RDB(Redis DataBase)和 AOF(Append Only File)
- 一、redis持久化----两种方式
- 二、redis持久化----RDB
- 三、redis持久化----AOF
- 四、redis持久化----AOF重写
- 五、redis持久化----如何选择RDB和AOF
- 六、Redis的两种持久化方式也有明显的缺点
- redids事务 ACID
- Redis 的事务需要先划分出三个阶段
- 从严格意义上来说,Redis 是没有事务的。因为事务必须具备四个特点:
- 原子性
- 一致性
- 隔离性
- 持久性
- 谈一谈缓存穿透、缓存击穿和缓存雪崩,以及解决办法
今天来跟大家分享一下个人对Redis方面的理解,话不多说,直接上内容。。。
redis的面试
一、redis
什么是Redis
Redis(Remote Dictionary Server) 是一个使用 C 语言编写的,开源的(BSD许可)高性能非关系型(NoSQL)的键值对数据库。
Redis 可以存储键和五种不同类型的值之间的映射。键的类型只能为字符串,值支持五种数据类型:S字符串、S集合、H散列表、L列表、Z有序集合。
与传统数据库不同的是 Redis 的数据是存在内存中的,所以读写速度非常快,因此 redis 被广泛应用于缓存方向,每秒可以处理超过 10万次读写操作,是已知性能最快的Key-Value DB。另外,Redis 也经常用来做分布式锁。除此之外,Redis 支持事务 、持久化、LUA脚本、LRU驱动事件、多种集群方案。
Redis使用场景
1、缓存
String类型
例如:热点数据缓存(例如报表、明星出轨),对象缓存、全页缓存、可以提升热点数据的访问数据。
2、数据共享分布式
String 类型,因为 Redis 是分布式的独立服务,可以在多个应用之间共享
例如:分布式Session
3、分布式锁
String 类型setnx方法,只有不存在时才能添加成功,返回true
public static boolean getLock(String key) {Long flag = jedis.setnx(key, "1");if (flag == 1) {jedis.expire(key, 10);}return flag == 1;
}public static void releaseLock(String key) {jedis.del(key);
}
4、全局ID
int类型,incrby,利用原子性
incrby userid 1000
分库分表的场景,一次性拿一段
5、计数器
int类型,incr方法
例如:文章的阅读量、微博点赞数、允许一定的延迟,先写入Redis再定时同步到数据库
6、限流
int类型,incr方法
以访问者的ip和其他信息作为key,访问一次增加一次计数,超过次数则返回false
7、位统计
String类型的bitcount(1.6.6的bitmap数据结构介绍)
字符是以8位二进制存储的
Redis有5中数据类型: SSHLZ
- String (字符串)
- Set (集合)
- Hash (散列)
- List (列表)
- Zset (有序集合)
Redis中一个key的值每天12点过期,给我一个你的解决方式
链接:【精选】Redis对于过期key的处理_redis过期key_不会说话的刘同学的博客-CSDN博客
对于过期键的处理,Redis一共提供了两种过期策略,不同的策略也会影响Redis的性能
下面我就来具体讲讲这两种过期策略
定期扫描策略
Redis会将每个设置了过期时间的key放入一个独立的字典中,之后会定时遍历这个字典来删除到期的key
Redis默认每秒进行10次过期扫描,过期扫描不会遍历过期字典中所有的key,而是采用了一种简单的贪心策略,如下:
- (1) 从过期字典中随机选择出 20 个key
- (2) 删除这 20 个key中已经过期的key
- (3) 如果过期的key的比例超过1/4,那就重复步骤 (1)
这种随机从字典里选择删除key在一定程度下可以保证主线程在处理过期key的时候不会占用太多的时间
但是如果Redis实例中所有的key都在同一时间过期,那么Redis会持续扫描过期字典集合,直到过期字典中过期的key比例低于 1/4,Redis才会停止扫描,这就会导致Redis会在过期key清理上花费很多的时间,从而导致其他的命令无法执行
因此Redis为了解决这一问题,Redis也给扫描时间设置了一个上限,默认不会超过 25ms,但是这种方案还是会有缺陷
如果客户端发送了一个命令,此时服务器正在进行过期扫描,那么客户端的这一请求至少需要等待 25ms 后才能进行处理,如果客户端的超时时间设置得要比 25ms 低,那么就会出现大量得链接超时,从而造成业务端的异常
我们在做业务处理的时候,给大量的key不要设置为同一过期时间,应当给过期key设置一个随机的时间
惰性策略
定时扫描策略由于是随机的从过期字典里选取key再进行删除,因此也会有"漏网之鱼"
为了避免这种情况,Redis在定时扫描策略的基础上还加了一个惰性策略
惰性策略就是在客户端访问这个key的时候,如果这个过期key还存在,那么还会对key的过期时间进行检查,如果过期了就立即删除并且不会把值返回给客户端
惰性策略是直接对定时扫描策略的增强,弥补了定时扫描策略的不足
从节点的过期策略
使用Redis就难免会使用到集群,从节点不会主动的进行过期扫描,任然还是以数据同步的方式来对过期数据进行处理
主节点在key到期时,会在AOF文件里增加一条del指令,然后再同步到所有的从节点,从节点执行这条 del 指令来删除过期的 key
由于主从同步数据是异步进行的,如果主节点过期的key的del指令没有及时同步到从节点的话,就会出现主从数据不一致
Redis对于超过内存限制的处理
上面我们就已经提到Redis的过期key处理,但是想一下如果Redis中所有的key都没有设置过期时间又或者key的过期时间非常的长,只要key还没过期,所有的key都会存在于Redis中,只要Redis没有宕机,久而久之Redis的内存容量就会超出物理内存限制,此时如果再有数据传入,那么Redis就会将数据存放直接保存到磁盘中
这种与磁盘频繁的交互会让Redis的性能急剧下降,此时Redis就是去了原本存在的意义
为了防止Redis发生与磁盘交互的行为,Redis提供了最大内存的使用限制,我们可以在 conf 配置参数 maxmemory 来限制Redis的使用内存
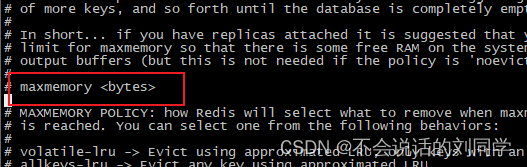
当然这里只配置了内存使用限制还不行,还需要配置处理策略(当内存使用超过了内存使用限制时该怎么做),同样也需要在 conf 文件中配置 maxmemory-policy 参数
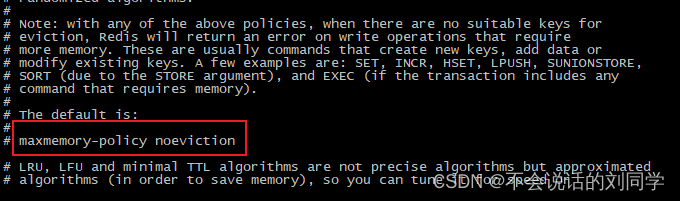
Redis 提供了几种可选策略来进行处理,这些策略在 4.0 之前四种,4.0之后又新增了两种
noeviction: 不会继续服务写请求,读请求可以继续进行。这样可以保证不会丢失数据,但是会让线上的业务不能持续运行。这也是默认的处理策略
volatile-lru:尝试淘汰设置了过期时间的key,最少使用的key优先被淘汰。没有设置过期时间的key不会被淘汰,这样可以保证需要持久化的数据不会突然丢失
volatile-lru: 与 volatile-lru 不同的是,它会使用 LFU 算法淘汰设置了过期时间的key
volatile-ttl:跟上面几乎一样,不过淘汰的策略不是LRU,而是比较key的剩余寿命ttl的值,ttl越小越优先被淘汰
volatile-random:跟上面几乎一样,不过淘汰的key是过期key集合中随机的key
allkeys-lru:区别于volatile-lru,这个策略要淘汰的key对象是全体的key集合,而不只是过期的key集合。这意味着一些没有设置过期时间的key也会被淘汰
allkeys-lfu:与allkeys-lru算法不同的是,算法淘汰设置了过期时间的key
allkeys-random:跟上面几乎一样,不过淘汰的key是随机的key。
上面的 volatile-xxx 策略只会针对已经设置了过期时间的 key 进行淘汰,allkeys-xxx 策略会对所有的key 进行淘汰
如果客户端不会设置key的过期时间,那么可以选择 allkeys-xxx 策略,如果需要保证数据的持久化,那么就可以选择 volatile-xxx 策略,因为这种策略只针对于设置了过期时间的key,没有设置过期时间的key不会被LRU算法淘汰
浅谈LRU与LFU
上面的淘汰策略里使用到了一种LRU和LFU的淘汰算法机制,我们再来看看这两种机制的区别
LRU全称 Least Recently Used,即最近最少使用,意思是当数据最近被访问了,那么在未来被访问的几率会比较大
我们可以把LRU理解为是一个双向链表结构,所有的数据都在这条链表中,当访问了链表中某个元素时,会把被访问元素移动到链表的头部,在淘汰的时候会把靠近链表末尾的元素给淘汰掉
假设现在有A、B、C、D、E四个元素,对应在链表中

当访问了 D 元素的时候,D 元素会被移动到链表头部

越靠近链表头部的位置就表示最近被访问到,越靠近链表末尾的位置就表示不会被访问到,这样在链表末尾的 C、E 就有可能会被淘汰掉
Redis 使用的时一种近似LRU算法,它跟LRU算法不太一样,之所以不完全使用LRU算法,是因为其需要消耗大量的额外内存,需要对现有的数据结构进行较大的改造
Redis为了实现近似LRU算法,给每个key增加了一个额外的小字段,这个字段的长度是 24 个bit,也就是最后一次被访问的时间戳
这个算法也很简单,就是随机采样出 5 (可以通过 maxmemory_samples 参数设置) 个key, 然后进行淘汰掉,如果淘汰后还是超出最大的内存限制,那就继续随机采样淘汰,直到内存低于最大内存限制为止
这里要注意的是,这个采样是根据淘汰策略来的,如果是 allkeys-xxx 策略,那么就是从所有的 key 字段中随机采样,如果是 volatile-xxx 策略,就从带过期时间的key字典中随机采样
LFU全称 Least frequently used ,使用频次最少的,即为不经常使用的 ,意思是当数据访问的频率或次数很低,那么在未来访问的几率也很低
与LRU不同的是,LFU主要关注数据访问的频率或次数,而LRU关注的是数据的最近有没有被访问
在数据被访问的时候,LFU 会把访问的频率或次数记录下来,当需要淘汰的时候会把访问频率或次数低的数据给淘汰掉,相对于LRU来说,LFU没有那么复杂
我们还是以A、B、C、D、E 五个元素为例,假设它们对应的访问频次为 10、4、9、2、6
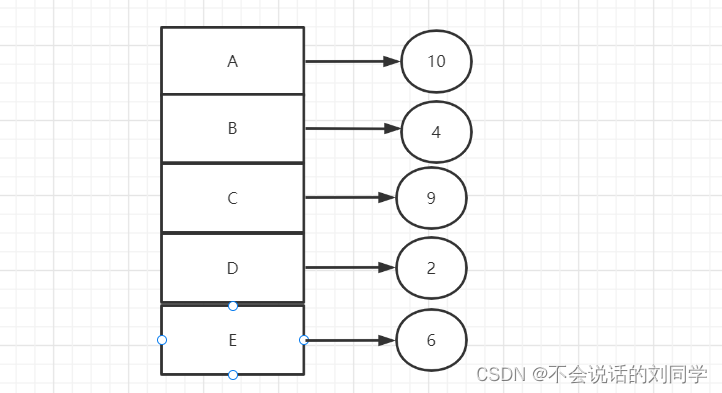
假设 C 元素被访问了一次,那么 C 的频次就会加 1 ,从 9 变成 10 ,那么当需要对数据进行淘汰的时候,其中的 B 和 D 元素的访问频率是最低的,就有可能会被淘汰
LFU 在Redis 4.0 之后才被引入进来,具体要使用那种淘汰策略,还需要依据具体的场景来选择
1.如何保证顺序性
2若何保证不重复消费
redis 集群模式与哨兵模式的区别
Redis Cluster是Redis的分布式集群解决方案,在 3.0 版本正式推出。在3.0之前的集群方案主要是主从复制和哨兵机制,3种方案各有优缺点。
-
主从复制(Replication)主要是备份数据、读写分离、负载均衡,一个Master可以有多个Slaves服务器作为备份。
-
哨兵(Sentinel)是为了高可用,可以管理多个Redis服务器,提供了监控,提醒以及自动的故障转移的功能。sentinel发现master挂了后,就会从slave(从服务器)中重新选举一个master(主服务器)。
-
集群(cluster)则是为了解决单机Redis容量有限/能力有限的问题,将数据按一定的规则分配到多台机器,提高并发量,内存/QPS不受限于单机,可受益于分布式集群高扩展性。
1、主从复制(Replication)
同Mysql主从复制的原因一样,Redis虽然读取写入的速度都特别快,但是也会产生读压力特别大的情况。为了解决单点数据库问题,分担读压力,Redis支持主从复制(把数据复制多个副本部署到其他节点上),读写分离,实现Redis的高可用性,冗余备份保证数据和服务的高度可靠性。一个Master可以有多个Slaves。
①从数据库向主数据库发送sync(数据同步)命令。
②主数据库接收同步命令后,会保存快照,创建一个RDB文件。
③当主数据库执行完保持快照后,会向从数据库发送RDB文件,而从数据库会接收并载入该文件。
④主数据库将缓冲区的所有写命令发给从服务器执行。
⑤以上处理完之后,之后主数据库每执行一个写命令,都会将被执行的写命令发送给从数据库。
注意:在Redis2.8之后,主从断开重连后会根据断开之前最新的命令偏移量进行增量复制.
1.1 主从数据库
在复制的概念中,数据库分为两类,一类是主数据库(master),另一类是从数据库(slave)。主数据库可以进行读写操作,当写操作导致数据变化时会自动将数据同步给从数据库。而从数据库一般是只读的,并接受主数据库同步过来的数据。一个主数据库可以拥有多个从数据库,而一个从数据库只能拥有一个主数据库。
1.2 主从复制的特点
- 主数据库可以进行读写操作,当读写操作导致数据变化时会自动将数据同步给从数据库
- 从数据库一般都是只读的,并且接收主数据库同步过来的数据
- 一个master可以拥有多个slave,但是一个slave只能对应一个master
- slave挂了不影响其他slave的读和master的读和写,重新启动后会将数据从master同步过来
- master挂了以后,不影响slave的读,但redis不再提供写服务,master重启后redis将重新对外提供写服务
- master挂了以后,不会在slave节点中重新选一个master
1.3 主从复制的优缺点
优点:
-
支持主从复制,主机会自动将数据同步到从机,数据备份的同时可以进行读写分离,提高服务器性能;
-
为了分载Master的读操作压力,Slave服务器可以为客户端提供只读操作的服务,写服务仍然必须由Master来完成;
-
Slave同样可以接受其它Slaves的连接和同步请求,这样可以有效的分载Master的同步压力;
-
Master Server是以非阻塞的方式为Slaves提供服务。所以在Master-Slave同步期间,客户端仍然可以提交查询或修改请求;
-
Slave Server同样是以非阻塞的方式完成数据同步。在同步期间,如果有客户端提交查询请求,Redis则返回同步之前的数据;
缺点: -
Redis不具备自动容错和恢复功能,主机从机的宕机都会导致前端部分读写请求失败,需要等待机器重启或者手动切换前端的IP才能恢复;
-
主机宕机,宕机前有部分数据未能及时同步到从机,切换IP后还会引入数据不一致的问题,降低了系统的可用性;
-
如果多个Slave断线了,需要重启的时候,尽量不要在同一时间段进行重启。因为只要Slave启动,就会发送sync请求和主机全量同步,当多个 Slave 重启的时候,可能会导致 Master IO剧增从而宕机。
-
Redis较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂;
2、哨兵(Sentinel)
主从同步/复制的模式,当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。这不是一种推荐的方式,更多时候,我们优先考虑哨兵模式。哨兵是Redis集群架构中非常重要的一个组件,哨兵的出现主要是解决了主从复制出现故障时需要人为干预的问题。
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
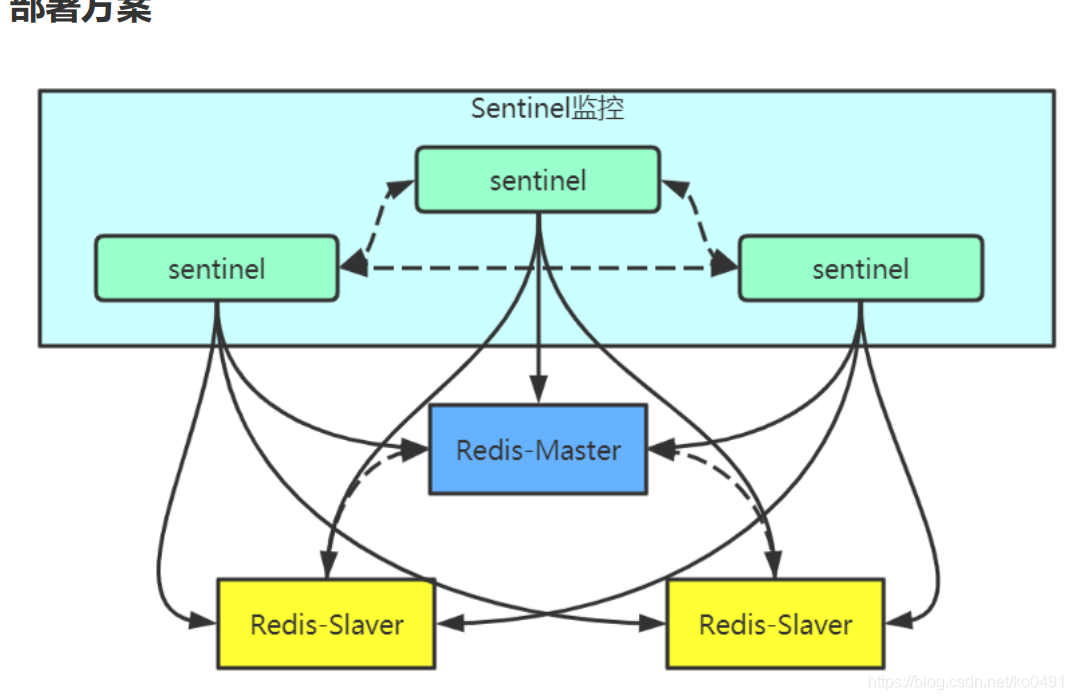
Redis Sentinel是社区版本推出的原生高可用解决方案,其部署架构主要包括两部分:Redis Sentinel集群和Redis数据集群。
其中Redis Sentinel集群是由若干Sentinel节点组成的分布式集群,可以实现故障发现、故障自动转移、配置中心和客户端通知。Redis Sentinel的节点数量要满足2n+1(n>=1)的奇数个。
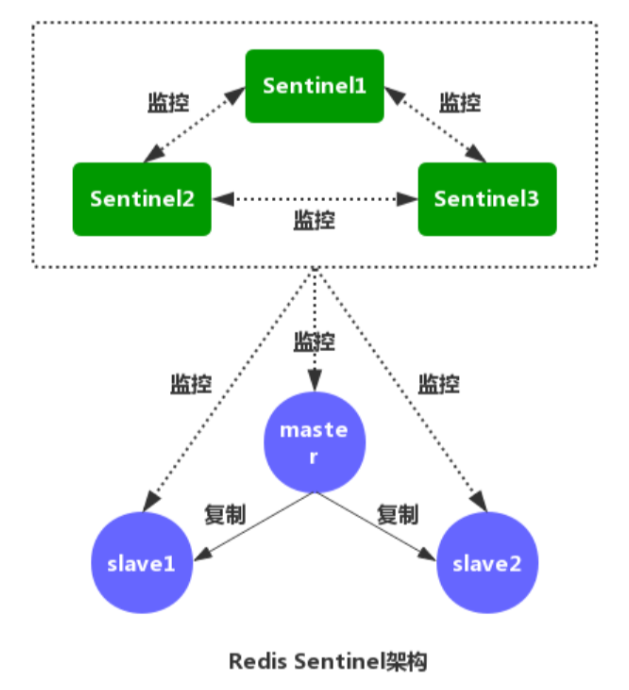
规划
Redis-Master :192.168.181.130 6379
Redis-slave1 :192.168.181.131 6379
Redis-slave2 :192.168.181.132 6379
Redis-Sentinel1:192.168.181.130 26379
Redis-Sentinel2:192.168.181.131 26379
Redis-Sentinel3:192.168.181.132 26379
2.1 Redis哨兵主要功能
-
集群监控:负责监控Redis master和slave进程是否正常工作
-
消息通知:如果某个Redis实例有故障,那么哨兵负责发送消息作为报警通知给管理员
-
故障转移:如果master node挂掉了,会自动转移到slave node上
-
配置中心:如果故障转移发生了,通知client客户端新的master地址
2.2 Redis哨兵高可用原理
当主节点出现故障时,由Redis Sentinel自动完成故障发现和转移,并通知应用方,实现高可用性。
- 哨兵机制建立了多个哨兵节点(进程),共同监控数据节点的运行状况。
- 同时哨兵节点之间也互相通信,交换对主从节点的监控状况。
- 每隔1秒每个哨兵会向整个集群:Master主服务器+Slave从服务器+其他Sentinel(哨兵)进程,发送一次ping命令做一次心跳检测。
这个就是哨兵用来判断节点是否正常的重要依据,涉及两个概念:主观下线和客观下线。
- 主观下线:一个哨兵节点判定主节点down掉是主观下线。
- 客观下线:只有半数哨兵节点都主观判定主节点down掉,此时多个哨兵节点交换主观判定结果,才会判定主节点客观下线。
基本上哪个哨兵节点最先判断出这个主节点客观下线,就会在各个哨兵节点中发起投票机制Raft算法(选举算法),最终被投为领导者的哨兵节点完成主从自动化切换的过程。
2.3 Redis哨兵故障切换的过程
假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行 failover 过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象称为主观下线。当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行 failover 操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线。对于客户端而言,一切都是透明的。
2.4 Redis哨兵模式的工作方式
- 每个Sentinel(哨兵)进程以每秒钟一次的频率向整个集群中的Master主服务器,Slave从服务器以及其他Sentinel(哨兵)进程发送一个 PING 命令。
- 如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被 Sentinel(哨兵)进程标记为主观下线(SDOWN)
- 如果一个Master主服务器被标记为主观下线(SDOWN),则正在监视这个Master主服务器的所有 Sentinel(哨兵)进程要以每秒一次的频率确认Master主服务器的确进入了主观下线状态
- 当有足够数量的 Sentinel(哨兵)进程(大于等于配置文件指定的值)在指定的时间范围内确认Master主服务器进入了主观下线状态(SDOWN), 则Master主服务器会被标记为客观下线(ODOWN)
- 在一般情况下, 每个 Sentinel(哨兵)进程会以每 10 秒一次的频率向集群中的所有Master主服务器、Slave从服务器发送 INFO 命令。
- 当Master主服务器被 Sentinel(哨兵)进程标记为客观下线(ODOWN)时,Sentinel(哨兵)进程向下线的 Master主服务器的所有 Slave从服务器发送 INFO 命令的频率会从 10 秒一次改为每秒一次。
- 若没有足够数量的 Sentinel(哨兵)进程同意 Master主服务器下线, Master主服务器的客观下线状态就会被移除。若 Master主服务器重新向 Sentinel(哨兵)进程发送 PING 命令返回有效回复,Master主服务器的主观下线状态就会被移除。
2.5 Redis哨兵模式的优缺点
优点:
哨兵模式是基于主从模式的,所有主从的优点,哨兵模式都具有。
主从可以自动切换(自动化故障恢复),系统更健壮,可用性更高。
缺点:
Redis较难支持在线动态扩容,在集群容量达到上限时在线扩容会变得很复杂。
Redis 数据节点中 slave 节点作为备份节点不提供服务.
3、集群(Cluster)
Redis 的哨兵模式基本已经可以实现高可用,读写分离 ,但是在这种模式下每台 Redis 服务器都存储相同的数据,浪费内存且有木桶效应,所以在redis3.0上加入了 Cluster 集群模式,实现了 Redis 的分布式存储,也就是说每台 Redis 节点上存储不同的内容。
Redis Cluster是社区版推出的Redis分布式集群解决方案,主要解决Redis分布式方面的需求,比如,当遇到单机内存,并发和流量等瓶颈的时候,Redis Cluster能起到很好的负载均衡的目的。
Redis Cluster着眼于提高并发量。集群至少需要3主3从,且每个实例使用不同的配置文件,主从不用配置,集群会自己选。
在redis-cluster架构中,redis-master节点一般用于接收读写,而redis-slave节点则一般只用于备份, 其与对应的master拥有相同的slot集合,若某个redis-master意外失效,则再将其对应的slave进行升级为临时redis-master。
当有请求是在向slave发起时,会直接重定向到对应key所在的master来处理。 但如果不介意读取的是redis-cluster中有可能过期的数据并且对写请求不感兴趣时,则亦可通过readonly命令,将slave设置成可读,然后通过slave获取相关的key,达到读写分离。具体可以参阅redis官方文档等相关内容。
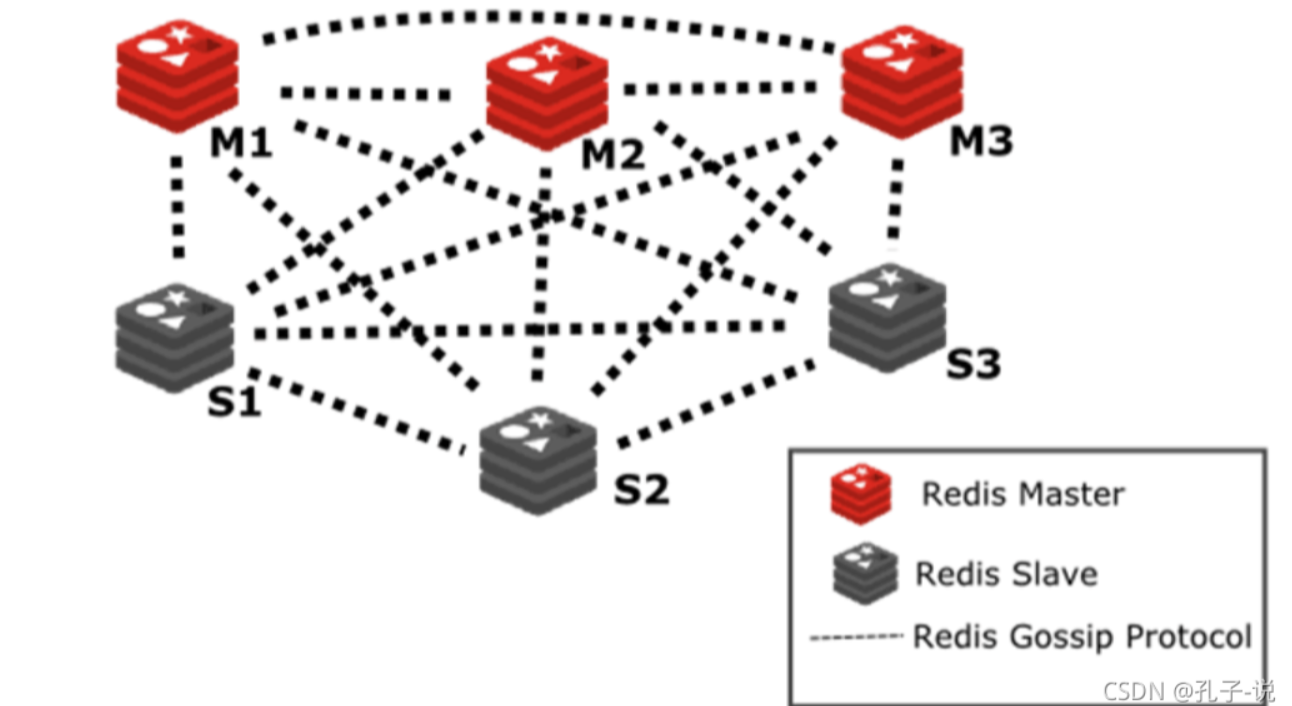
3.1 Redis-Cluster集群的配置
使用集群,只需要将每个数据库节点的cluster-enable配置打开即可。根据官方推荐,集群部署至少要 3 台以上的master节点(因为选举投票的机制,所以必须为奇数),最好使用 3 主 3 从六个节点的模式。在测试环境中,只能在一台机器上面开启6个服务实例来模拟。
3.2 Redis-Cluster集群的特点
所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
节点的fail是通过集群中超过半数的节点检测失效时才生效。
客户端与 Redis 节点直连,不需要中间代理层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
所有的节点都是一主一从(也可以是一主多从),其中从节点不提供服务,仅作为备用
支持在线增加、删除节点
客户端可以连接任何一个主节点进行读写
3.3 Redis-Cluster集群的工作方式
在 Redis 的每一个节点上,都有这么两个东西,一个是插槽(slot),它的的取值范围是:0-16383。还有一个就是cluster,可以理解为是一个集群管理的插件。当我们的存取的 Key到达的时候,Redis 会根据 crc16的算法得出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作。
Redis 集群使用数据分片(sharding)而非一致性哈希(consistency hashing)来实现: 一个 Redis 集群包含 16384 个哈希槽(hash slot), 数据库中的每个键都属于这 16384 个哈希槽的其中一个, 集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽, 其中 CRC16(key) 语句用于计算键 key 的 CRC16 校验和 。
集群中的每个节点负责处理一部分哈希槽。 举个例子, 一个集群可以有三个哈希槽, 其中:
节点 A 负责处理 0 号至 5500 号哈希槽。
节点 B 负责处理 5501 号至 11000 号哈希槽。
节点 C 负责处理 11001 号至 16384 号哈希槽。
这种将哈希槽分布到不同节点的做法使得用户可以很容易地向集群中添加或者删除节点。
为了保证高可用,redis-cluster集群引入了主从模式,一个主节点对应一个或者多个从节点,当主节点宕机的时候,就会启用从节点。当其它主节点ping一个主节点A时,如果半数以上的主节点与A通信超时,那么认为主节点A宕机了。如果主节点A和它的从节点A1都宕机了,那么该集群就无法再提供服务了。
3.4 Redis-Cluster集群的优缺点
优点
解决分布式负载均衡的问题。具体解决方案是分片/虚拟槽slot。
可实现动态扩容
P2P模式,无中心化
缺点
为了性能提升,客户端需要缓存路由表信息
Slave在集群中充当“冷备”,不能缓解读压力
redis 持久化 —— RDB(Redis DataBase)和 AOF(Append Only File)
关于Redis,目前都是使用Redis作为数据缓存,缓存的目标主要是那些需要经常访问的数据,或计算复杂而耗时的数据。缓存的效果就是减少了数据库读的次数,减少了复杂数据的计算次数,从而提高了服务器的性能。
一、redis持久化----两种方式
1、redis提供了两种持久化的方式,分别是RDB(Redis DataBase)和AOF(Append Only File)。
2、RDB,简而言之,就是在不同的时间点,将redis存储的数据生成快照并存储到磁盘等介质上;
3、AOF,则是换了一个角度来实现持久化,那就是将redis执行过的所有写指令记录下来,在下次redis重新启动时,只要把这些写指令从前到后再重复执行一遍,就可以实现数据恢复了。
4、其实RDB和AOF两种方式也可以同时使用,在这种情况下,如果redis重启的话,则会优先采用AOF方式来进行数据恢复,这是因为AOF方式的数据恢复完整度更高。
5、如果你没有数据持久化的需求,也完全可以关闭RDB和AOF方式,这样的话,redis将变成一个纯内存数据库,就像memcache一样。
二、redis持久化----RDB
1、RDB方式,是将redis某一时刻的数据持久化到磁盘中,是一种快照式的持久化方法。
2、redis在进行数据持久化的过程中,会先将数据写入到一个临时文件中,待持久化过程都结束了,才会用这个临时文件替换上次持久化好的文件。正是这种特性,让我们可以随时来进行备份,因为快照文件总是完整可用的。
3、对于RDB方式,redis会单独创建(fork)一个子进程来进行持久化,而主进程是不会进行任何IO操作的,这样就确保了redis 极高的性能。
4、如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。
5、虽然RDB有不少优点,但它的缺点也是不容忽视的。如果你对数据的完整性非常敏感,那么RDB方式就不太适合你,因为即使你每5分钟都持久化一次,当redis故障时,仍然会有近5分钟的数据丢失。所以,redis还提供了另一种持久化方式,那就是AOF。
三、redis持久化----AOF
1、AOF,英文是Append Only File,即只允许追加不允许改写的文件。
2、如前面介绍的,AOF方式是将执行过的写指令记录下来,在数据恢复时按照从前到后的顺序再将指令都执行一遍,就这么简单。
3、我们通过配置redis.conf中的appendonly yes就可以打开AOF功能。如果有写操作(如SET等),redis就会被追加到AOF文件的末尾。
4、默认的AOF持久化策略是每秒钟fsync一次(fsync是指把缓存中的写指令记录到磁盘中),因为在这种情况下,redis仍然可以保持很好的处理性能,即使redis故障,也只会丢失最近1秒钟的数据。
5、如果在追加日志时,恰好遇到磁盘空间满、inode满或断电等情况导致日志写入不完整,也没有关系,redis提供了redis-check-aof工具,可以用来进行日志修复。
6、因为采用了追加方式,如果不做任何处理的话,AOF文件会变得越来越大,为此,redis提供了AOF文件重写(rewrite)机制,即当AOF文件的大小超过所设定的阈值时,redis就会启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集。举个例子或许更形象,假如我们调用了100次INCR指令,在AOF文件中就要存储100条指令,但这明显是很低效的,完全可以把这100条指令合并成一条SET指令,这就是重写机制的原理。
7、在进行AOF重写时,仍然是采用先写临时文件,全部完成后再替换的流程,所以断电、磁盘满等问题都不会影响AOF文件的可用性,这点大家可以放心。
8、AOF方式的另一个好处,我们通过一个“场景再现”来说明。某同学在操作redis时,不小心执行了FLUSHALL,导致redis内存中的数据全部被清空了,这是很悲剧的事情。不过这也不是世界末日,只要redis配置了AOF持久化方式,且AOF文件还没有被重写(rewrite),我们就可以用最快的速度暂停redis并编辑AOF文件,将最后一行的FLUSHALL命令删除,然后重启redis,就可以恢复redis的所有数据到FLUSHALL之前的状态了。是不是很神奇,这就是AOF持久化方式的好处之一。但是如果AOF文件已经被重写了,那就无法通过这种方法来恢复数据了。
9、虽然优点多多,但AOF方式也同样存在缺陷,比如在同样数据规模的情况下,AOF文件要比RDB文件的体积大。而且,AOF方式的恢复速度也要慢于RDB方式。
如果你直接执行BGREWRITEAOF命令,那么redis会生成一个全新的AOF文件,其中便包括了可以恢复现有数据的最少的命令集。
10、如果运气比较差,AOF文件出现了被写坏的情况,也不必过分担忧,redis并不会贸然加载这个有问题的AOF文件,而是报错退出。这时可以通过以下步骤来修复出错的文件:
1.备份被写坏的AOF文件
2.运行redis-check-aof –fix进行修复
3.用diff -u来看下两个文件的差异,确认问题点
4.重启redis,加载修复后的AOF文件
四、redis持久化----AOF重写
1、AOF重写的内部运行原理,我们有必要了解一下。
2、在重写即将开始之际,redis会创建(fork)一个“重写子进程”,这个子进程会首先读取现有的AOF文件,并将其包含的指令进行分析压缩并写入到一个临时文件中。
3、与此同时,主工作进程会将新接收到的写指令一边累积到内存缓冲区中,一边继续写入到原有的AOF文件中,这样做是保证原有的AOF文件的可用性,避免在重写过程中出现意外。
4、当“重写子进程”完成重写工作后,它会给父进程发一个信号,父进程收到信号后就会将内存中缓存的写指令追加到新AOF文件中。
5、当追加结束后,redis就会用新AOF文件来代替旧AOF文件,之后再有新的写指令,就都会追加到新的AOF文件中了。
五、redis持久化----如何选择RDB和AOF
1、对于我们应该选择RDB还是AOF,官方的建议是两个同时使用。这样可以提供更可靠的持久化方案。
2、redis的备份和还原,可以借助第三方的工具redis-dump。
六、Redis的两种持久化方式也有明显的缺点
1、RDB需要定时持久化,风险是可能会丢两次持久之间的数据,量可能很大。
2、AOF每秒fsync一次指令硬盘,如果硬盘IO慢,会阻塞父进程;风险是会丢失1秒多的数据;在Rewrite过程中,主进程把指令存到mem-buffer中,最后写盘时会阻塞主进程。
redids事务 ACID
Redis 的事务需要先划分出三个阶段
事务开启:使用 MULTI 可以标志着执行该命令的客户端从非事务状态切换至事务状态;
命令入队:MULTI 开启事务之后,非 WATCH、EXEC、DISCARD、MULTI
等特殊命令,客户端的命令不会被立即执行,而是放入一个事务队列;
如果收到 EXEC 命令,事务队列里的命令将会被执行;
如果收到 DISCARD 命令,则事务被丢弃。
命令入队过程如果出错(如使用了不存在的命令),则事务队列会被拒接执行;
执行事务:执行事务期间出现了异常(如命令和操作的数据类型不匹配),事务队列的里的命令还是继续执行下去,直到全部命令执行完,不会回滚。
WATCH 可用于监控 redis 变量值,在命令 EXEC 之前,redis 里的数据是有机会被其他客户端的命令修改的。使用 WATCH
监控的变量被修改后,执行 EXEC 时则会返回执行失败的 nil 回复
从严格意义上来说,Redis 是没有事务的。因为事务必须具备四个特点:
原子性(Atomicity)
一致性(Consistency)
隔离性(Isolation)
持久性(Durability)
Redis 是做不到这四点,只是具备其中一些特征,redis的事务是个伪事务,而且不支持回滚。
原子性
EXEC命令执行前:
在命令入队时就报错,(如内存不足,命令名称错误),redis 就会报错并且记录下这个错误。此时,客户还能继续提交命令操作;等到执行EXEC时,redis 就会拒绝执行所有提交的命令操作,返回事务失败的结果 nil。
EXEC命令执行后:
命令和操作的数据类型不匹配,但 redis 实例没有检查出错误。在执行完 EXEC 命令以后,redis 实际执行这些指令,就会报错。此时事务是不会回滚的,但事务队列的命令还是继续被执行。事务的原子性无法保证。
EXEC执行时发生故障:
如果 redis 开启了 AOF 日志,那么,只会有部分的事务操作被记录到 AOF 日志中。需要使用 redis-check-aof 工具检查 AOF 日志文件,这个工具可以把未完成的事务操作从 AOF 文件中去除。事务的原子性得到保证。
一致性
EXEC命令执行前:
入队报错事务会被放弃执行,具有一致性。
EXEC命令执行后:
实际执行时报错,错误的指令不会执行,正确的指令可以正常执行,一致性可以保证。
EXEC执行时发生故障:
RDB 模式,RDB 快照不会在事务执行时执行,事务结果不会保存在RDB;
AOF 模式,可以使用 redis-check-aof 工具检查 AOF 日志文件,把未完成的事务操作从 AOF 文件中去除。可以保证一致性。
隔离性
EXEC 命令执行前:
隔离性需要通过 WATCH 机制保证。因为 EXEC 命令执行前,其他客户端命令可以被执行,相关变量会被修改;但可以使用 WATCH 机制监控相关变量。一旦相关变量被修改,则 EXEC 后则事务失败返回,具有隔离性。
EXEC 命令执行后:
Redis 是单线程执行,事务队列里的命令和其他客户端的命令只能二选一被顺序执行,因此具有隔离性
持久性
如果 redis 没有使用 RDB 或 AOF,事务的持久化是不存在的;
RDB 模式:那么在一个事务执行后,而下一次的 RDB快照还未执行前,如果发生了实例宕机,数据丢失,这种情况下,事务修改的数据也是不能保证持久化;
AOF 模式:因为 AOF 模式的三种配置选项 no、everysec 和 always
都会存在数据丢失的情况。所以,事务的持久性属性也还是得不到保证。
总结
- Redis 的事务机制可以保证一致性和隔离性;
- 但是无法保证持久性;
- 具备了一定的原子性,但不支持回滚。
谈一谈缓存穿透、缓存击穿和缓存雪崩,以及解决办法

相关文章:
Redis面试内容,Redis过期策略,Redis持久化方式,缓存穿透、缓存击穿和缓存雪崩,以及解决办法
文章目录 一、redis什么是RedisRedis使用场景1、缓存2、数据共享[分布式](https://so.csdn.net/so/search?q分布式&spm1001.2101.3001.7020)3、分布式锁4、全局ID5、计数器6、限流7、位统计 Redis有5中数据类型: SSHLZRedis中一个key的值每天12点过期ÿ…...

爱上C语言:scanf、gets以及getchar输入字符串你真的懂了吗
🚀 作者:阿辉不一般 🚀 你说呢:不服输的你,他们拿什么赢 🚀 专栏:爱上C语言 🚀作图工具:draw.io(免费开源的作图网站) 如果觉得文章对你有帮助的话,还请点赞…...

ubuntu Setforeground 前台应用切换
场景分析 有这样一个系统,一个服务主进程用于接收指令,其它服务是独立的gui 程序,服务进程根据命令将对应的gui 程序切换到前台。 windows 平台有Setforeground 这个api,可以根据进程ID,将某个应用的窗口切换到前台。…...

【Java 进阶篇】从Java对象到JSON:Jackson的魔法之旅
在现代的软件开发中,处理数据的能力是至关重要的。而当我们谈及数据格式时,JSON(JavaScript Object Notation)通常是首选。为了在Java中轻松地将对象转换为JSON,我们需要一种强大而灵活的工具。这时,Jackso…...
HarmonyOS ArkTS语言,运行Hello World(二)
一、认识DevEco Studio界面 进入IDE后,我们首先了解一下基础的界面。整个IDE的界面大致上可以分为四个部分,分别是代码编辑区、通知栏、工程目录区以及预览区。 代码编辑区 1、中间的是代码编辑区,你可以在这里修改你的代码,以…...
四、文件包含漏洞
一、文件包含漏洞 解释:文件包含漏洞是一种注入型漏洞,其本质就是输入一段用户能够控制的脚本或者代码,并让服务端执行;其还能够使得服务器上的源代码被读取,在PHP里面我们把可重复使用的函数写入到单个文件中&#x…...

Java中基于SSM框架的数据保存方法与日期处理
一、详解 在SSM框架中,保存数据通常涉及到服务层和数据访问层。服务层处理业务逻辑,而数据访问层负责与数据库进行交互。 二、代码 Override public void save(Student student) { Date date new Date(); SimpleDateFormat format new Sim…...
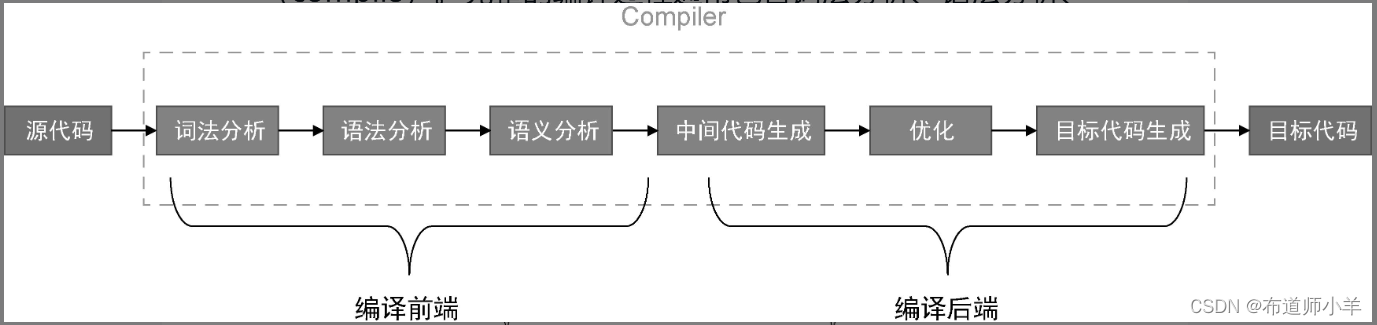
编译器核心技术概览
编译技术是一门庞大的学科,我们无法对其做完善的讲解。但不同用途的编译器或编译技术的难度可能相差很大,对知识的掌握要求也会相差很多。如果你要实现诸如 C、JavaScript 这类通用用途语言(general purpose language),…...
本地训练,开箱可用,Bert-VITS2 V2.0.2版本本地基于现有数据集训练(原神刻晴)
按照固有思维方式,深度学习的训练环节应该在云端,毕竟本地硬件条件有限。但事实上,在语音识别和自然语言处理层面,即使相对较少的数据量也可以训练出高性能的模型,对于预算有限的同学们来说,也没必要花冤枉…...

守护进程的理解
什么是守护进程 daemon False # 是否以守护进程方式运行,True守护,False 非守护 在这段代码中,daemon 变量的值决定了进程是否以守护进程方式运行。如果 daemon 的值为 True,则表示进程将以守护进程方式运行,否则为…...

VMware虚拟机的安装教程
安装VMware虚拟机的步骤如下: 首先,你需要从VMware官方网站(https://www.vmware.com)下载VMware虚拟机软件安装程序。 一旦下载完成,双击运行安装程序。 在安装程序启动后,你将看到一个欢迎界面。点击"…...
Linux环境搭建(tomcat,jdk,mysql下载)
是否具备环境(前端node,后端环境jdk)安装jdk,配置环境变量 JDK下载 - 编程宝库 (codebaoku.com) 进入opt目录 把下好的安装包拖到我们的工具中 把解压包解压 解压完成,可以删除解压包 复制解压文件的目录,配置环境变量…...

80万条中文ChatGPT多轮对话数据集
80万条中文ChatGPT多轮对话数据集 代码代码地址代码解析 代码 import json import numpy as np from tqdm import tqdm import redef find_chinese_text(text):pattern re.compile(r[^\u4e00-\u9fff])return pattern.sub(, text)with open("E:/data_sets/multiturn_chat…...

阿里云ECS服务器如何搭建并连接FTP,完整步骤
怎么用终端连接服务器就不多说了,直接开始搭建FTP。 我是用root账号执行的命令,如果不使用root账号,注意在命令前面加sudo。 一、安装FTP 我这里安装的是vsftpd。 1、检查是否已安装vsftpd: vsftpd -v如果出现了版本信息&…...

uni-app 使用uni.getLocation获取经纬度配合腾讯地图api获取当前地址
前言 最近在开发中需要根据经纬度获取当前位置信息,传递给后端,用来回显显示当前位置 查阅uni-app文档,发现uni.getLocation () 可以获取到经纬度,但是在小程序环境没有地址信息 思考怎么把经纬度换成地址,如果经纬度…...

cocos2dx Animate3D (一)
3D相关的动画都是继承Grid3DAction 本质上是用GirdBase进行创建动画的小块。 Shaky3D 晃动特效 // 持续时间(时间过后不会回到原来的样子) // 整个屏幕被分成几行几列 // 晃动的范围 // z轴是否晃动 static Shaky3D* create(float initWithDuration, const Size& …...
2023年最新PyCharm环境搭建教程(含Python下载安装)
文章目录 写在前面PythonPython简介Python生态圈Python下载安装 PyCharmPyCharm简介PyCharm下载安装PyCharm环境搭建 写在后面 写在前面 最近博主收到了好多小伙伴的吐槽称不会下载安装python,博主听到后非常的扎心,经过博主几天的熬夜加班,…...
3D火山图绘制教程
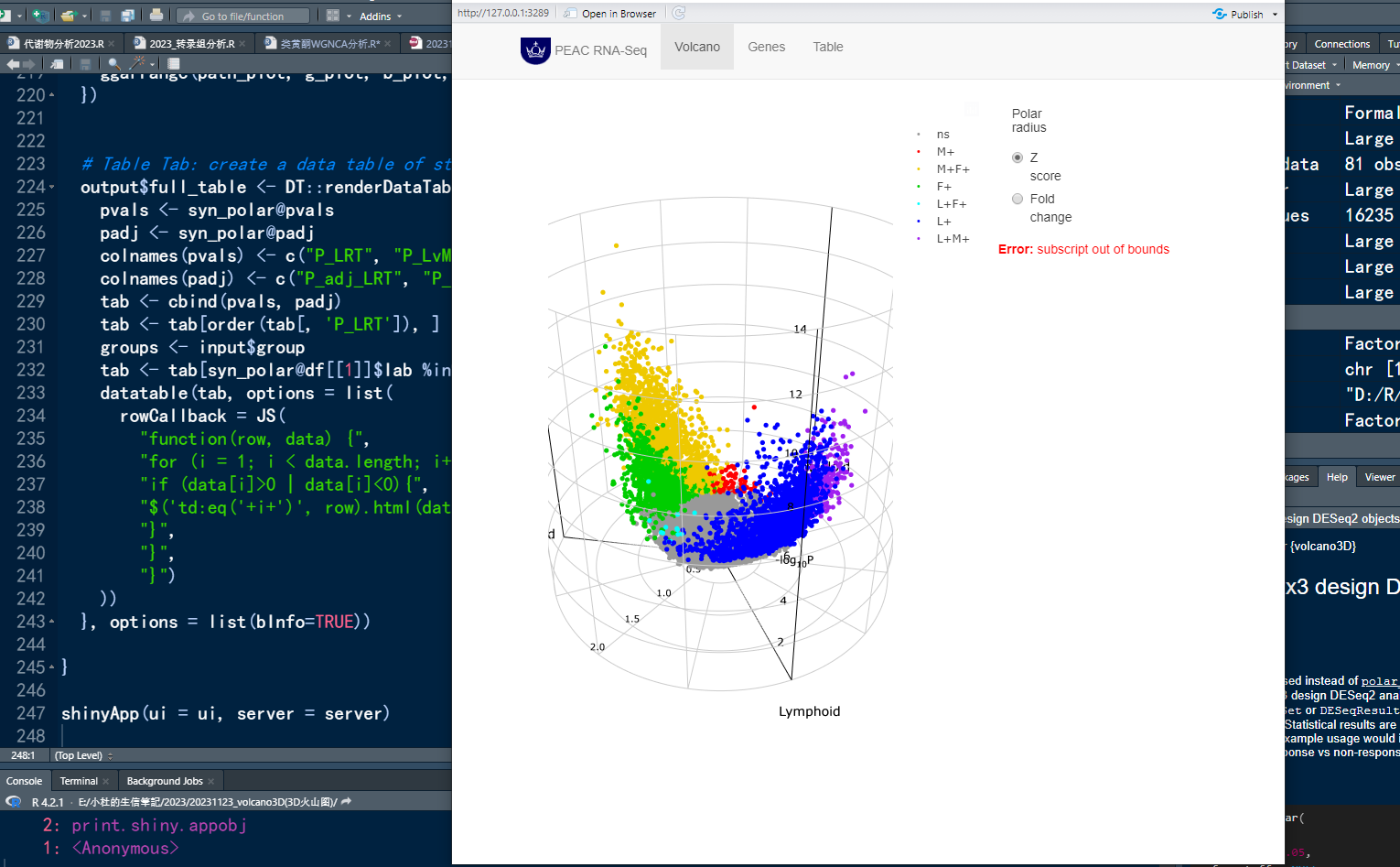
一边学习,一边总结,一边分享! 本期教程内容 **注:**本教程详细内容 Volcano3D绘制3D火山图 一、前言 火山图是做差异分析中最常用到的图形,在前面的推文中,我们也推出了好几期火山图的绘制教程࿰…...

跳跃游戏[中等]
优质博文:IT-BLOG-CN 一、题目 给你一个非负整数数组nums,你最初位于数组的第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。判断你是否能够到达最后一个下标,如果可以,返回true;否则,返…...

华为昇腾开发板共享Windows网络上网的方法
作者:朱金灿 来源:clever101的专栏 为什么大多数人学不会人工智能编程?>>> 具体参考文章:linux(内网)通过window 上网。具体是两步:一是在windows上设置internet连接共享。二是打开Atlas 200I D…...

为 Claude Code 配置 Taotoken 作为其大模型服务提供商
为 Claude Code 配置 Taotoken 作为其大模型服务提供商 1. 准备工作 在开始配置前,请确保已具备以下条件:已注册 Taotoken 账号并获取有效的 API Key,同时拥有可运行的 Claude Code 环境。Taotoken 提供的 API Key 可在控制台的「API 密钥管…...

终极二维码修复指南:QRazyBox让损坏的二维码重获新生
终极二维码修复指南:QRazyBox让损坏的二维码重获新生 【免费下载链接】qrazybox QR Code Analysis and Recovery Toolkit 项目地址: https://gitcode.com/gh_mirrors/qr/qrazybox 你是否遇到过重要二维码因打印模糊、物理损坏或存储问题而无法扫描的困境&…...

2026年计算机科学论文降AI工具推荐:算法研究和软件工程部分降AI指南
2026年计算机科学论文降AI工具推荐:算法研究和软件工程部分降AI指南 帮同学选过降AI工具,综合价格、效果、保障来看,推荐嘎嘎降AI(www.aigcleaner.com)。 4.8元,达标率99.26%,计算机论文降AI的…...

Spring Data JPA进阶:基于Criteria API与动态实体图的复杂报表性能压榨
哈喽,大家好。 在很多Java开发者的技术栈鄙视链里,提到复杂报表和动态查询,大家的第一反应往往是:“JPA太重了,处理不了复杂查询,赶紧换MyBatis或者直接写原生SQL吧。” 确实,如果你在生产环境…...

企业内如何通过Taotoken实现API调用的审计与安全管控
企业内如何通过Taotoken实现API调用的审计与安全管控 1. 企业API调用的核心安全挑战 在企业环境中使用大模型API时,技术负责人通常面临三个维度的管控难题:密钥分发难以追踪、部门间用量无法隔离、请求来源缺乏审计。传统直连厂商API的方式往往需要为每…...

【Dify 2026日志审计终极指南】:覆盖采集、脱敏、溯源、告警、留存5大环节的GDPR+等保3.0双合规落地方案
更多请点击: https://intelliparadigm.com 第一章:Dify 2026日志审计全链路合规治理总览 Dify 2026 版本将日志审计能力深度融入平台治理内核,构建覆盖采集、传输、存储、分析、告警与归档六大环节的全链路合规闭环。该体系严格遵循《GB/T 3…...

Element UI单选框样式改造指南:告别默认样式,打造个性化radio和radio-button
Element UI单选框深度定制实战:从样式覆盖到高级交互设计 Element UI作为Vue生态中最受欢迎的组件库之一,其单选框组件el-radio和el-radio-button在表单场景中应用广泛。但当我们面对品牌化设计需求时,默认样式往往显得力不从心。本文将带你突…...

200+小说网站一键下载:novel-downloader终极离线阅读解决方案
200小说网站一键下载:novel-downloader终极离线阅读解决方案 【免费下载链接】novel-downloader 一个可扩展的通用型小说下载器。 项目地址: https://gitcode.com/gh_mirrors/no/novel-downloader 在数字阅读时代,你是否曾担心心爱的小说突然消失…...

Gofile多线程下载方案:突破限速瓶颈的高效文件传输实战指南
Gofile多线程下载方案:突破限速瓶颈的高效文件传输实战指南 【免费下载链接】gofile-downloader Download files from https://gofile.io 项目地址: https://gitcode.com/gh_mirrors/go/gofile-downloader 在数字化协作日益频繁的今天,从Gofile平…...

LabVIEW调用Matlab脚本的两种方法,我为什么最终放弃了公式节点?
LabVIEW调用Matlab脚本的两种方法,我为什么最终放弃了公式节点? 作为一名长期在测试测量领域工作的工程师,我几乎每天都要和LabVIEW打交道。当项目需要复杂算法支持时,Matlab总是我的首选工具。但在实际工程中,如何优…...