PyTorch微调终极指南1:预训练模型调整
如今,在训练深度学习模型时,通过根据自己的数据微调预训练模型来进行迁移学习(transfer learning)已成为首选方法。 通过微调这些模型,我们可以利用他们的专业知识并使它们适应我们的特定任务,从而节省宝贵的时间和计算资源。
本系列分为四篇文章,侧重于微调模型的不同方面,本文为第一篇,我们将深入研究定义预训练模型并配置它以适合你的目标任务。
定义模型包括一系列重要决策,包括选择适当的架构、定制模型头、配置损失函数和学习率、设置所需的浮点精度以及确定冻结或微调哪些层等等 更多的。 在本文中,我们将详细探讨每个方面,提供有价值的见解,帮助你有效定义和微调模型。
在线工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器
1、加载预训练模型
在加载预训练模型之前,清楚地了解你的具体问题并相应地选择合适的架构至关重要。 虽然这项任务似乎具有挑战性,但重要的是不要随机选择模型架构。 考虑你的业务需求并选择符合这些需求的合适架构。

DensNet 架构示例
例如,如果要对分类进行微调,并且优先考虑低延迟,那么像 MobileNet 这样的架构将是一个不错的选择。 通过做出明智的架构决策,你可以优化微调实验以获得更好的结果。
请注意,你可以从多个来源加载预训练模型以进行微调。 在本文中,我指的是 timm(Pytorch 图像模型)和 Torchvision 模型
以下是从 torchvision 加载预训练的 resnet50 模型的示例:
# From torchvision.models
from torchvision import models
model = models.resnet50(pretrained=False)或者从 timm(Pytorch 图像模型)加载预训练模型:
import timm# from timm
pretrained_model_name = "resnet50"
model = timm.create_model(pretrained_model_name, pretrained=False)需要注意的是,无论预训练模型的来源如何,所需的关键修改是调整模型的全连接 FC 层(或者可以是线性/分类器/头部)。 此外,对于你的目标任务,可以合并额外的线性层。 我们将在下一节中进一步探讨这一点。
2、修改模型头
修改模型的头部对于使其与你的特定目标任务保持一致至关重要。 预训练模型在大型数据集(如用于图像分类的 ImageNet)上进行训练,或在文本数据(如 BooksCorpus 和 Wikipedia)上进行训练以进行文本生成。 通过修改模型的头部,预训练的模型可以适应新任务并利用其学到的有价值的特征,从而增强其在新任务中的性能。

适用于目标任务的预训练模型的视觉描述,具有头部修改之外的附加层
例如,可以修改 RestNet head 进行分类任务:
import torch.nn as nn
import timmnum_classes = 4 # Replace num_classes with the number of classes in your data# Load pre-trained model from timm
model = timm.create_model('resnet50', pretrained=True)# Modify the model head for fine-tuning
num_features = model.fc.in_features
model.fc = nn.Linear(num_features, num_classes)或者,在修改 RestNet 头以进行分类任务的同时,添加额外的线性层以增强模型的预测能力(ps - 这只是一个说明性示例):
import torch.nn as nn
import timmnum_classes = 4 # Replace num_classes with the number of classes in your data# Load pre-trained model from timm
model = timm.create_model('resnet50', pretrained=True)# Modify the model head for fine-tuning
num_features = model.fc.in_features# Additional linear layer and dropout layer
model.fc = nn.Sequential(nn.Linear(num_features, 256), # Additional linear layer with 256 output featuresnn.ReLU(inplace=True), # Activation function (you can choose other activation functions too)nn.Dropout(0.5), # Dropout layer with 50% probabilitynn.Linear(256, num_classes) # Final prediction fc layer
)或者修改 RestNet 头来执行回归任务:
model = timm.create_model('resnet50', pretrained=True)# Modify the model head for regression
num_features = model.fc.in_features
model.fc = nn.Linear(num_features, 1) # Regression task has a single output需要注意的一件事是,模型并不总是具有我们修改输出特征(例如 num_classes)的 FC(全连接)层。 模型的架构可能有所不同,我们需要修改的层的名称和位置也可能有所不同。
在许多预训练模型中,尤其是在卷积神经网络 (CNN) 架构中,模型末尾通常有一个线性层或 FC 层来执行最终分类。 然而,这不是严格的规则,并且某些模型可能具有不同的结构。
要识别需要修改的层,可以执行以下操作:
import torch
import timm# Load pre-trained model from timm
model = timm.create_model('resnet50', pretrained=True)
print(model)
打印的模型架构显示了需要修改的特定最后一层的标识
通过打印模型,可以看到其架构并确定要修改的适当层。 寻找用作最终分类层的线性或 FC 层,并将其替换为与类数量或任务要求相匹配的新层。
3、设置优化器、学习率、权重衰减和动量
在微调中,学习率、损失函数和优化器是相互关联的组件,它们共同影响模型适应新任务的能力,同时利用从预训练中获得的知识。 精心选择的学习率确保模型以合理的速度有效收敛,精心选择的损失函数使训练过程中的损失最小化与目标任务保持一致,适当的优化器有效地优化模型的参数。
微调需要对这些组件进行仔细的实验和迭代调整,以达到适当的平衡并在微调模型中达到所需的性能水平。
3.1 优化器
要更详细地了解如何选择合适的优化器进行微调,我建议参考这篇博客。
优化器根据反向传播期间计算的梯度确定用于更新模型参数的算法。 不同的优化器,例如 SGD、Adam 或 RMSprop,具有不同的参数更新规则和收敛特性。 优化器的选择可以显着影响模型训练和微调模型的最终性能。 选择最合适的优化器需要考虑任务的性质、数据集的大小和可用的计算资源等因素。
3.2 学习率、动量和权重衰减
在定义优化器时,我们还必须设置学习率(LR),它是一个超参数,用于确定优化过程中每次迭代的步长。 它控制模型参数在反向传播过程中根据计算出的梯度进行更新的程度。 选择合适的学习率至关重要,因为将其设置得太高可能会导致优化过程振荡或发散或超出最佳解决方案,而将其设置太低可能会导致收敛缓慢或陷入局部极小值。
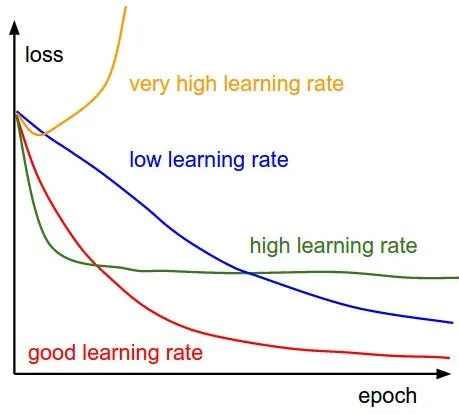
除了学习率之外,定义优化器时还需要考虑其他重要的超参数,例如权重衰减和动量(特定于 SGD)。 让我们快速浏览一下这两个超参数:
- 权重衰减,也称为 L2 正则化,是一种用于防止过度拟合并鼓励模型学习更简单、更通用的表示的技术。
- 动量用于随机梯度下降 (SGD),以加速收敛并逃离局部最小值。
import torch.optim as optim# Define your optimizer with weight decay
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9, weight_decay=0.001)# Define your optimizer with weight decay
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=0.0001)3.3 选择损失函数
要探索并选择适合你的目标任务的损失函数,我建议参考有关损失函数的 PyTorch 官方文档。

损失函数衡量模型的预测输出与实际正确答案之间的差异或差距。 它为我们提供了一种了解模型在任务上执行情况的方法。 在微调预训练模型时,选择适合我们正在处理的特定任务的损失函数非常重要。 例如,对于分类任务,常用交叉熵损失,而均方误差更适合回归问题。 选择正确的损失函数可确保模型在训练期间专注于优化所需目标。
import torch.nn as nn# Define the loss function - For classification problem
loss_function = nn.CrossEntropyLoss()# Define the loss function - For regression problem
loss_function = nn.MSELoss() # Mean Squared Error loss另请注意,关于损失函数的选择和处理,可以应用一些额外的考虑因素和技术。 其中一些例子是:
- 自定义损失函数 - 你可能需要修改或自定义损失函数以满足特定要求。 一个例子是对重要的单个类别的错误分类进行 10 倍的惩罚。 下面是一个示例代码,演示了自定义损失的实现,让你了解如何完成它:
import torch
import torch.nn.functional as Fclass CustomLoss(torch.nn.Module):def __init__(self, class_weights):super(CustomLoss, self).__init__()self.class_weights = class_weightsdef forward(self, inputs, targets):ce_loss = F.cross_entropy(inputs, targets, reduction='none')weights = torch.ones_like(targets).float()for class_idx, weight in enumerate(self.class_weights):weights[targets == class_idx] = weightweighted_loss = ce_loss * weightsreturn torch.mean(weighted_loss)# Assuming you have a model and training data
model = YourModel()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# Assuming 5 classes so class_weights = [1.0, 1.0, 1.0, 1.0, 10.0]
criterion = CustomLoss(class_weights=[1.0, 1.0, 1.0, 1.0, 10.0]) # Inside the training loop
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()- 基于指标的损失 - 在某些情况下,模型的性能可能会根据损失本身以外的指标进行评估。 在这种情况下,你可以设计或调整损失函数以直接优化这些指标。
- 正则化 - 在微调过程中可以将正则化方法(例如 L1 或 L2 正则化)纳入损失函数中,以防止过度拟合并提高模型泛化能力。 正则化项可以帮助控制模型的复杂性,并降低过度强调数据中特定模式或特征的风险。 L2 正则化可以通过在优化器中设置weight_decay 值来应用,而L1 正则化需要稍微不同的方法。
L2正则化实现:
# Define a loss function
criterion = nn.CrossEntropyLoss()# L2 regularization
optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=0.01)L1正则化实现:
# Define a loss function
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)# Inside the training loop
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)# L1 regularization
regularization_loss = 0.0
for param in model.parameters():regularization_loss += torch.norm(param, 1)
loss += 0.01 * regularization_loss#Adjust regularization strength as needed4、冻结全部或部分网络
当我们指的是冻结时,这意味着在微调过程中固定特定层或整个网络的权重。 网络冻结允许我们保留预训练模型捕获的知识,同时仅更新某些层以适应目标任务。 因此,这是非常重要的,如果你正在微调预训练模型,则不应忽视这一点。

在微调之前决定是否应该冻结预训练模型的所有层(完整网络)或部分层,这一切都归结为你的特定目标任务。
例如,如果预训练模型已经在与目标任务类似的大规模数据集上进行了训练,那么冻结整个网络可以帮助保留学习到的表示,防止它们被覆盖。 在这种情况下,仅修改模型的头部并从头开始训练。
另一方面,当预训练模型的较低层捕获可能与新任务相关的一般特征时,仅冻结网络的一部分可能会很有用。 通过冻结这些较低层,我们可以利用预训练模型的知识,同时更新较高层以专门研究特定于任务的功能。 这种方法在目标数据集很小或与训练预训练模型的数据集显着不同的情况下特别有用。
要在 PyTorch 中实现冻结,你可以访问模型中的各个层或模块,并将其 require_grad 属性设置为 False。 这可以防止在向后传递过程中计算梯度和更新权重。
下面是一个示例代码,演示了冻结整个网络的实现:
# Freeze all the layers of the pre-trained model
for param in model.parameters():param.requires_grad = False# Modify the model's head for a new task
num_classes = 10
model.fc = nn.Linear(model.fc.in_features, num_classes)仅冻结网络中的卷积层:
# Freeze only the convolutional layers of the pre-trained model
for param in model.parameters():if isinstance(param, nn.Conv2d):param.requires_grad = False# Modify the model's head for a new task
num_classes = 10
model.fc = nn.Linear(model.fc.in_features, num_classes)仅冻结网络中的特定层:
# Freeze specific layers (e.g.,the first two convolutional layers) of the pre-trained model
for name, param in model.named_parameters():if 'conv1' in name or 'layer1' in name:param.requires_grad = False# Modify the model's head for a new task
num_classes = 10
model.fc = nn.Linear(model.fc.in_features, num_classes)需要注意的是,冻结图层应该经过深思熟虑,考虑到任务和数据集的具体要求。 这是利用预先训练的知识和让模型有效适应新任务之间的微妙平衡。
5、定义模型浮点精度
快速总结定义模型浮点精度是指深度学习模型计算时用来表示数值的数据类型。 在 PyTroch 中,32 位(float32 或 FP32)和 16 位(float16 或 FP16 或半精度)是两种常用的浮点精度。

- float32 — 这种精度提供了宽动态范围和高数值精度,允许精确计算,但会消耗更多内存。 FP32 使用 32 位来表示数字。
- float16 — 这种较低的精度可以减少模型的内存占用和计算要求,从而潜在提高效率和速度。 然而,它可能会导致数值精度损失,并可能影响模型的准确性或收敛性。 FP16 使用 16 位来表示一个数字。
- FP16 和 FP32 被称为单精度,两者都有自己的优点和缺点,正如我们在上面的指针中看到的那样。 为了利用两者的优势,我们在训练管道中结合了 FP16 和 FP32 浮点精度的混合精度。 混合精度可提高计算效率、减少内存占用、加速训练并增加模型容量。
对于混合精度训练更详细的理解,我建议参考这篇文章。
以下是如何使用自动混合精度 (AMP) 库在 PyTorch 训练管道中实现混合精度训练的示例:
import torch
from torch import nn, optim
from torch.cuda.amp import autocast, GradScaler# Define your model and optimizer
model = YourModel()
optimizer = optim.Adam(model.parameters(), lr=0.001)# Define loss function
criterion = nn.CrossEntropyLoss()# Define scaler for automatic scaling of gradients
scaler = GradScaler()# Define your training loop
for epoch in range(num_epochs):for batch_idx, (data, targets) in enumerate(train_loader):data, targets = data.to(device), targets.to(device)# Zero the gradientsoptimizer.zero_grad()# Enable autocasting for mixed precisionwith autocast():# Forward passoutputs = model(data)loss = criterion(outputs, targets)# Perform backward pass and gradient scalingscaler.scale(loss).backward()# Update model parametersscaler.step(optimizer)scaler.update()# Print training progressif batch_idx % log_interval == 0:print(f"Epoch {epoch+1}/{num_epochs} | Batch {batch_idx}/{len(train_loader)} | Loss: {loss.item():.4f}")在上面的示例中, GradScaler() 对象用于执行梯度缩放。 以下是所使用方法的细分:
scaler.scale(loss):此方法通过缩放器确定的适当因子来缩放损失值。 它返回将用于反向传播的缩放损失。scaler.step(optimizer):此方法使用反向传播过程中计算的梯度来更新优化器的参数。 它像往常一样执行优化器步骤,但考虑了缩放器执行的梯度缩放。scaler.update():该方法调整缩放器在下一次迭代中使用的缩放因子。 它通过根据梯度大小动态调整比例来帮助防止下溢或溢出问题。 它在scaler.step(optimizer)之后调用。
使用 GradScaler() 和相关方法的目的是减轻使用较低精度 (FP16) 计算时可能出现的潜在数值不稳定问题。 通过适当缩放损失和梯度,缩放器可确保优化器的更新保持在稳定范围内。
使用 PyTorch 的 AMP 库实现混合精度训练可以有效利用 FP16 计算,从而提高训练速度并减少内存使用量,同时保持使用 FP32 进行准确权重更新所需的精度。
虽然混合精确训练可以带来多种好处,但在某些情况下它可能不适合或可能损害训练过程。
使用混合精确训练的潜在危害包括:
- 由于 FP16 而导致数值精度损失,这种精度损失可能会导致模型精度降低,特别是在需要高精度的任务中。 当涉及数值精度关键任务时,混合精度可能不适合。
- 由于训练期间的数值不稳定,下溢和溢出的脆弱性增加,这可能会影响模型的收敛和性能。
- 由于混合精度而增加了复杂性,这需要额外的考虑,例如管理精度转换、缩放梯度以及处理与精度不匹配相关的可能问题。
- 如果你的模型遇到严重的梯度爆炸或消失问题,在混合精度训练中切换到较低精度计算(FP16)可能会使这些问题恶化。 在这种情况下,在考虑混合精度训练之前解决潜在的不稳定问题至关重要。
6、训练模型和验证模式
微调模型时,加载预训练模型后默认处于训练模式。 但是,我们可以在推理或验证期间将模型切换到验证模式。 这些模式变化会相应地改变模型的行为。

6.1 训练模式
当模型处于训练模式时,它会启用训练过程中所需的特定操作,例如计算梯度、更新参数以及应用 dropout 等正则化技术。 在此模式下,模型的行为就像正在训练数据集上进行训练一样,并准备好从数据中学习。
model.train() # sets model in training mode6.2 验证模式
当模型处于评估模式时,它会禁用某些仅在训练期间所需的操作,例如计算梯度、dropout 和更新参数。 当你想要评估模型在未见过的数据上的性能时,通常在验证或测试期间使用此模式。
model.val() # sets model in validation mode在微调过程中将模型设置为正确的模式非常重要,因为将模型设置为正确的模式可确保每个阶段(训练或评估)的一致行为和正确操作。 这会带来准确的结果、高效的资源利用,并防止过度拟合或标准化不一致等问题。
7、单 GPU 和多 GPU
GPU 对于深度学习和微调任务至关重要,因为它们擅长执行高度并行计算,从而显着加快训练过程。 如果可以使用多个 GPU,可以利用它们的集体力量来进一步加速训练。

以下是如何利用多个 GPU(如果有可用)的示例:
# Define your model
model = MyModel()
model = model.to(device) # Move the model to the desired device (CPU or GPU)# Check if multiple GPUs are available
if torch.cuda.device_count() > 1:print("Using", torch.cuda.device_count(), "GPUs for training.")model = nn.DataParallel(model) # Wrap the model with DataParallel# Define your loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)此代码片段首先使用 torch.cuda.device_count() 检查多个 GPU 是否可用。 如果有多个 GPU,则模型将使用 nn.DataParallel 进行包装,从而允许其利用所有可用的 GPU 进行训练。 每个 GPU 同时处理一部分数据,从而缩短训练时间。 如果仅存在一个 GPU,则代码将在该 GPU 上运行,而不使用 nn.DataParallel。
8、结束语
在 PyTorch 微调终极指南的第一部分中,我们探索了微调预训练模型以适应我们的特定任务所涉及的基本步骤。 通过利用迁移学习,我们可以节省大量时间和计算资源,同时取得令人印象深刻的结果。 在本文中,我们学习了如何加载预训练模型,调整其头部架构以匹配目标任务,以及自定义学习率、优化器和权重衰减等超参数以优化微调过程。 此外,我们还研究了选择适当的损失函数以及冻结网络特定部分以进行更受控的微调的好处。
此外,我们还讨论了定义模型浮点精度的重要性以及微调期间在训练和验证模式之间切换的重要性。 此外,我们还探讨了如何充分利用单 GPU 和多 GPU 设置来加速训练并提高性能。
在本系列的第 2 部分中,我们将更深入地研究先进技术,以提高微调模型的准确性和泛化能力。 我们将探索数据增强、学习率计划、梯度裁剪和集成等方法,以进一步提高模型在多样化和具有挑战性的数据集上的性能。
原文链接:PyTorch微调终极指南(1) - BimAnt
相关文章:
PyTorch微调终极指南1:预训练模型调整
如今,在训练深度学习模型时,通过根据自己的数据微调预训练模型来进行迁移学习(transfer learning)已成为首选方法。 通过微调这些模型,我们可以利用他们的专业知识并使它们适应我们的特定任务,从而节省宝贵…...
Uptime Kuma 企业微信群机器人告警
curl https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key693axxx6-7aoc-4bc4-97a0-0ec2sifa5aaa \-H Content-Type: application/json \-d {"msgtype": "text","text": {"content": "hello world"}}企业微信群机器人ke…...

【网络安全】-网络安全的分类详解
文章目录 介绍1. 网络层安全(Network Layer Security)理论实操使用VPN保护隐私 2. 应用层安全(Application Layer Security)理论实操使用密码管理器 3. 端点安全(Endpoint Security)理论实操定期更新防病毒…...

php利用ZipArchive类实现文件压缩与解压
github项目 1、Linux 安装zlib库 cd /usr/local/src wget https://zlib.net/current/zlib.tar.gz tar -zxvf zlib.tar.gz cd zlib-1.3 ./configure make && make install 2、zlib的使用 $all_name all.zip;// 创建ZipArchive对象$zip_all new ZipArchive();if ($z…...

Java面试附答案:掌握关键技能,突破面试难题!
问题:什么是大O表示法?它在Java中的应用是什么? 回答: 大O表示法是一种用来衡量算法复杂度的方法,它描述了算法的时间复杂度和空间复杂度的增长速度。它使用符号O(n)来表示算法的渐进时间复杂度,其中n表示…...
API自动化测试:如何构建高效的测试流程
一、引言 在当前的软件开发环境中,API(Application Programming Interface)扮演了极为重要的角色,连接着应用的各个部分。对API进行自动化测试能够提高测试效率,降低错误,确保软件产品的质量。本文将通过实…...
字母异位词分组
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。 字母异位词 是由重新排列源单词的所有字母得到的一个新单词。 示例 1: 输入: strs [“eat”, “tea”, “tan”, “ate”, “nat”, “bat”] 输出: [[“bat”],[“nat”,“tan…...
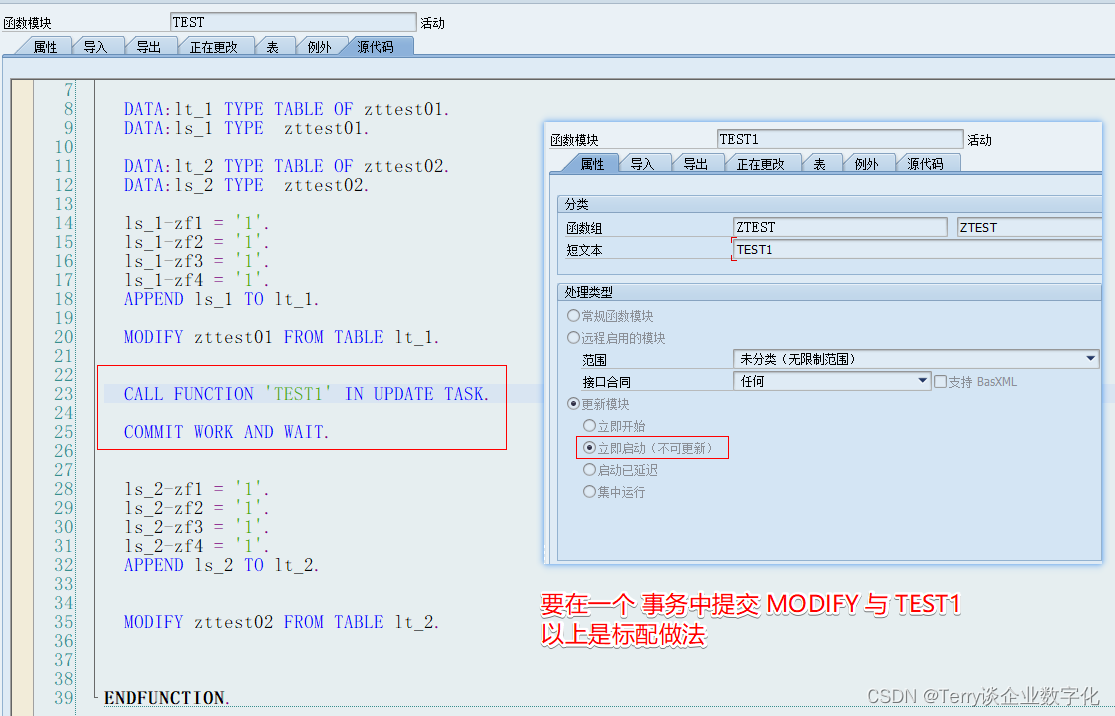
SAP_ABAP_面试篇_关于Function Module函数的三种处理类型
关于 Function Module 这个技术点,在面试过程中一般会考察以下几个问题: 1 函数处理类型的更新模式 一般会问到异步和事务(逻辑单元 LUW),异步函数的调试方式、SM13监控更新函数的执行过程(V1 与 V2 模式…...

CentOS简介、ISO类型、CentOS7安装与配置以及远程连接。
目录 1.CentOS简介 2.CentOS ISO类型 3.CentOS7安装与配置 4.远程连接 1.CentOS简介 CentOS(Community Enterprise Operating System,中文意思是社区企业操作系统)是Linux发行版之一,它是来自于Red Hat Enterprise Linux依照…...
Audition 2024 24.0.0.46(音频剪辑)
Audition 2024是一款非常棒的音频编辑和混合软件,提供了广泛的工具和功能,用于创建、编辑、混合和设计音效。这款软件旨在加速音频和视频制作工作流程,提供具有原始音效的高质量混音。其界面构成清晰,操作简便,适合专业…...

Hive小文件处理
MR任务 mr任务参考链接 set hive.exec.reducers.max3 set hive.exec.dynamic.partition.mode true; --使用动态分区时,设置为ture。 set hive.exec.dynamic.partition.mode nonstrict; --动态分区模式,默认值:strict,表示必须…...

go语言学习之旅之Go语言函数
学无止境,今天继续学习go语言的基础内容 Go语言函数 Go 语言函数定义格式如下 func function_name( [parameter list] ) [return_types] {函数体}函数定义解析 func:函数由 func 开始声明 function_name:函数名称,函数名和参数…...
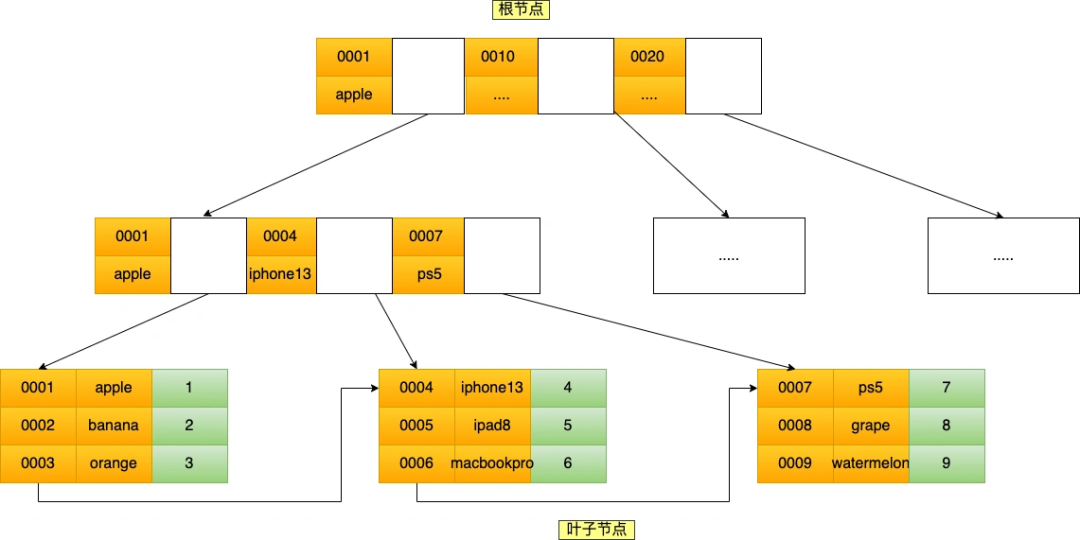
mysql的联合索引最左匹配原则问题
MySQL的联合索引 联合索引的最左匹配原则会一直向右匹配直到遇到范围查询(>、<、between、like) 就会停止匹配。 这个结论并不全对!去掉 「between 和 like 」这个结论就没问题了 经过实验的证明,我得出的结论是这样的: 联合索引的最…...
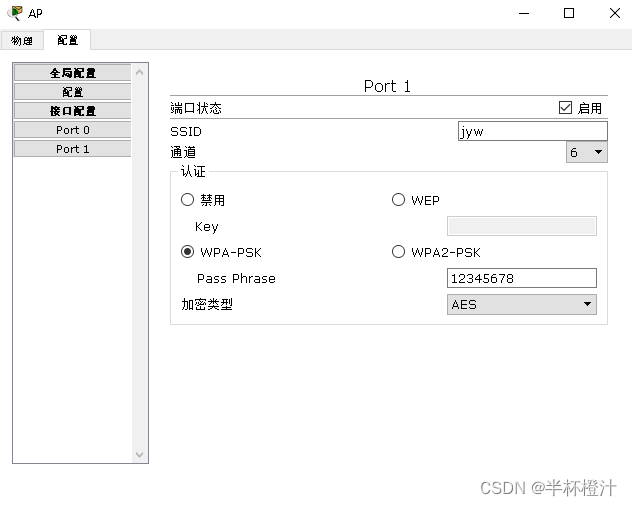
三层交换机实现不同VLAN间通讯
默认时,同一个VLAN中的主机才能彼此通信,那么交换机上的VLAN用户之间如何通信? 要实现VLAN之间用户的通信,就必须借助路由器或三层交换机来完成。 下面以三层交换机为例子说明: 注意: 1.交换机与三层交换…...

C#枚举的使用
在C#中经常会用到枚举,是比较常用的定义一组常量集合的数据类型。我们使用枚举可以更方便理解和阅读代码,增强代码可读性,也在某种程度上提升了编程逻辑和维度。 基本语法: enum MyEnum {Value1,Value2,Value3,//...…...
.Net6使用WebSocket与前端进行通信
1. 创建类WebSocketTest: using System.Net.WebSockets; using System.Text;namespace WebSocket.Demo {public class WebSocketTest{//当前请求实例System.Net.WebSockets.WebSocket socket null;public async Task DoWork(HttpContext ctx){socket await ctx.We…...
)
hadoop 编写开启关闭集群脚本, hadoop hdfs,yarn开启关闭脚本。傻瓜式hadoop脚本 hadoop(九)
1. 三台机器: hadoop22, hadoop23, hadoop24 2. hdfs在22机器启动,yarn在hadoop23机器 3. 脚本需要hadoop用户启动才可以 4. 脚本必须在hadoop22机器运行。如果想在所有机器都能运行,你可以自己修改脚本 4. 脚本: #!/bin/bas…...

ArrayList中放的是一个对象,如何同时根据对象中的三个字段对List进行排序
import java.util.ArrayList; import java.util.Collections; import java.util.Comparator;public class YourObject {private int field1;private String field2;private double field3;// 构造函数和其他代码public int getField1() {return field1;}public String getField…...

MONGODB 的基础 NOSQL注入基础
首先来学习一下nosql 这里安装就不进行介绍 只记录一下让自己了解mongodb ubuntu 安装后 进入 /usr/bin ./mongodb即可进入然后可通过 进入的url链接数据库 基本操作 show dbshow dbsshow tablesuse 数据库名插入数据db.admin.insert({json格式的数据})例如 db.admin.inse…...
单链表实现【队列】
目录 队列的概念及其结构 队列的实现 数组队列 链式队列 队列的常见接口的实现 主函数Test.c 头文件&函数声明Queue.h 头文件 函数声明 函数实现Queue.c 初始化QueueInit 创建节点Createnode 空间释放QueueDestroy 入队列QueuePush 出队列QueuePop 队头元…...

游友云-风启之旅-Windrose-模组安装教程
前言: 部分模组只需要服务端安装即可,具体请阅读模组介绍 服务器不建议装太多高倍率,目前bug较多容易崩服 模组可能会影响存档,注意备份!! 推荐服务器:yy.0play.cn 下载模组: 打…...

PromptUI:AI提示词驱动的UI灵感库,从截图到代码的现代全栈实践
1. 项目概述:PromptUI,一个为UI设计注入AI动力的灵感库作为一个长期在Web和移动端开发一线摸爬滚打的开发者,我深知从零开始构思一个界面有多耗神。你可能会花几个小时在Dribbble或Behance上寻找灵感,但找到的截图往往只是一个静态…...

3分钟搭建专业战斗分析:GBFR Logs实时DPS监控工具完全指南
3分钟搭建专业战斗分析:GBFR Logs实时DPS监控工具完全指南 【免费下载链接】gbfr-logs GBFR Logs lets you track damage statistics with a nice overlay DPS meter for Granblue Fantasy: Relink. 项目地址: https://gitcode.com/gh_mirrors/gb/gbfr-logs …...

3大核心突破:让老旧Mac设备重获新生的技术革命方案
3大核心突破:让老旧Mac设备重获新生的技术革命方案 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 在苹果生态系统中,硬件淘汰周期往往…...

自动化项目引导:从环境搭建到新人上手的工程实践
1. 项目概述与核心价值最近在梳理团队新成员入职流程时,发现了一个普遍存在的痛点:无论公司规模大小,新人的“上手期”总是充满了混乱和低效。信息散落在各个角落,工具权限申请像闯关,代码库在哪、怎么跑起来、遇到问题…...

为什么 Claude Code 没有一句废话?扒光它的底层提示词,我悟了!
往期热门文章: 1、面试官尬笑:你说半天就能读完一个开源项目源码,不就是用 AI 吗?我说:是用 DeepWiki,而且是 Codemap 模式! 2、Claude Code、Cursor 和 Codex,到底选哪个࿱…...

FanControl终极配置指南:3步实现Windows风扇精准温控
FanControl终极配置指南:3步实现Windows风扇精准温控 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/…...

Code Claw:用手机遥控VSCode,实现移动AI编程
1. 项目概述:当手机成为你的AI编程遥控器作为一名在开发一线摸爬滚打了十多年的程序员,我经历过无数次这样的场景:灵感在通勤路上、在咖啡厅、甚至在睡前突然闪现,但手边没有电脑,只能眼睁睁看着它溜走。或者ÿ…...

Gitee:中国企业DevOps转型的本土化加速器
在数字化转型浪潮席卷各行各业的当下,DevOps作为提升软件交付效率的关键方法论,正成为企业技术架构升级的核心战场。Gitee作为国内领先的一站式DevOps平台,凭借其独特的本土化优势与全流程功能覆盖,正在帮助越来越多的中国企业突破…...

避坑指南:Qt QML地图开发中QtLocation插件加载失败、坐标偏移及手势冲突的解决方案
Qt QML地图开发避坑实战:插件加载、坐标偏移与手势冲突的深度解决方案 当你在Qt QML项目中集成地图功能时,可能会遇到三个令人头疼的问题:QtLocation插件加载失败、地图坐标显示偏移,以及多个手势处理器之间的冲突。这些问题往往…...